- Производительность. Многопроцессорные системы

Содержание
- 2. 4096tb@gmail.com Тема письма: БГУИР. … . Ковалевский Вячеслав Викторович
- 3. Лекция 5. Структура процессора. Архитектуры CISC и RISC. Архитектура процессора Intel . План лекции: Структура процессора.
- 4. Лекция 6. Адресация. Режимы работы процессора. Управление памятью. План лекции: Адресация памяти. Непосредственная, прямая и косвенная
- 5. Лекция 7. Производительность. Многопроцессорные системы План лекции: Иерархия памяти. Кэш. Развитие архитектуры IA-32. FPU. Конвейеризация команд
- 6. Иерархия памяти
- 7. Иерархия памяти
- 8. Иерархия памяти
- 9. Иерархия памяти
- 10. Computer memory hierarchy
- 11. Повышение производительности Развитие архитектуры IA-32. Кэш. FPU.
- 12. Производительность Это количество выполняемых за такт команд IPC – Instructions per cycle (команды выполняемые за такт)
- 13. Скорость света не превысить! 300 000 km/s - скорость света в вакууме 300 000 m/ms 300
- 14. Параллелизм Параллелизм: на уровне команд (ILP – Instruction Level Parallelism) на уровне процессов (TLP – Thread
- 15. Конвейеризация (Рipelining) Реализация обработки команд внутри процессора в несколько этапов Идея состоит в использовании разных устройств
- 16. Конвейер инструкций Таненбаум, с.59 (рис. 2.5)
- 17. Латентность конвейера Таненбаум, с.59 (рис. 2.5)
- 18. Конвейер
- 19. Intel Pentium IV Суперскалярная архитектура (как и все Pentium’ы ) «Гиперконвейерная технология» (сверхдлинный конвейер: 5 стадий
- 20. Согласно Флинту SISD (Single Instruction, Single Data) SIMD (Single Instructions, Multiple Data) MISD (Multiple Instruction, Single
- 21. Пути достижения параллелизма Потоковая архитектура ОКМД (одна операция над многими данными – MMX, XMM, SSE) МКМД
- 22. Суперскалярная архитектура Таненбаум, с.59 (рис. 2.5)
- 23. Hyper-Threading Одно физическое ядро «успевает» обрабатывать два потока команд. Операционная система «видит» два процессора.
- 25. Multiprocessor systems
- 26. SMP-системы (Symmetrical Multi Processor systems).
- 27. Закон Амдала Speedup - относительное ускорение f- часть кода, которая может быть распараллелена n - число
- 28. α - часть кода, которая не распараллеливается (1 − α = f или 1 − f
- 29. SMP SMP: использование нескольких процессоров не приводит к ожидаемому приросту производительности
- 30. NUMA-системы (Non-Uniform Memory Access systems).
- 31. Кластеры Основная «область применения» кластеров: Cуперкомпьютеры
- 32. Кластеры
- 33. HyperТhreading (Гипертрейдинг)
- 34. SMP - Symmetrical MultiProcessing
- 35. Двухъядерный процессор
- 36. Intel Smithfield Ядро Smithfield – это два обычных Prescott в одном кристалле
- 37. «Классическая» двухпроцессорная SMP-система с двухъядерными процессорами
- 38. SUMA Slightly Uniform Memory Architecture ("почти однородная архитектура памяти") Основа SUMA – последовательная шина HyperTransport
- 39. AMD Toledo AMD Toledo
- 40. Пример двухпроцессорной двухядерной системы на Opteron 2хх и чипсете AMD 82хх. HT обозначает HyperTransport
- 41. AMD Opteron Dual-Core Architecture
- 42. Intel & AMD Разница между реализациями AMD и Intel с «технологической» точки зрения долгое время заключалась
- 43. Когерентность кэш-памяти
- 44. Когерентность кэш-памяти Протоколы поддержания когерентности кэшей: у процессоров Intel - «MESI», у процессоров AMD - «MOESI».
- 45. Write-Through
- 46. MESI MESI (Modified, Exclusive, Shared, Invalid) Modified - состояние (выделено желтым) соответствует измененной строке в кэш-памяти,
- 47. Кэш Чтение корректных данных и модификация
- 48. Кэш Чтение «устаревших» данных
- 49. MOESI MOESI (Modified, Owner, Exclusive, Shared, Invalid) Modified - состояние (выделено желтым) соответствует измененной строке в
- 50. Кэш Чтение «устаревших» данных
- 51. Кэш Чтение корректных данных и модификация
- 52. Pentium 4 Processor With HT
- 53. Pentium D Processor
- 54. Pentium 4 Processor With HT
- 55. Dual Gore Pentium Processor Extreme Edition
- 56. Реализация IA-64 Intel Itanium2
- 57. IA-32 / IA-64
- 58. Реализация IA-64: Intel Itanium2 Наиболее кардинальным нововведением IA-64 по сравнению с RISC является «явный параллелизм команд»
- 59. EPIC EPIC (Explicitly Parallel Instruction Computing) - явный параллелизм на уровне команд VLIW (Very long instruction
- 60. В обеих архитектурах явный параллелизм представлен уже на уровне команд, управляющих одновременной работой функциональных исполнительных устройств
- 61. Itanium 2 Конвейер в Itanium 2 состоит из 8 этапов, способен за один такт обрабатывать до
- 62. Функциональные устройства
- 63. Itanium 2 Каждая из инструкций при разборе связки направляется на соответствующий ее типу конвейер: (A) целочисленное
- 64. Формат связки команд IA-64 Связка имеет длину 128 разрядов. Она включает 3 поля – «слота» для
- 65. http://www.ixbt.com/cpu/ia64.html 14
- 66. IA-64 IA-64 перекладывает всю работу по оптимизации потока команд на компилятор. Каждый 128-битный пакет содержит шаблон
- 67. IA-64 Компиляторы для IA-64 используют технологию "отмеченных команд" (predication) для устранения потерь производительности из-за неправильно предсказанных
- 68. Конвейер Itanium Устройство предварительной обработки инструкций в порядке их следования в программном коде (front end). Исполнение
- 69. Конвейер CPU с внеочередным исполнением команд
- 70. Out-of-order Processor Pipeline (2)
- 71. 80-ядерный процессор Intel Teraflops Research Chip
- 72. Технология Teraflops основан на техпроцессе 65 нм. Процессор построен на одной подложке, объединившей 80 независимых процессорных
- 73. Ядро Intel Teraflops Каждое ядро состоит из блока обработки Processing Engine (PE), выполняющего все вычисления и
- 74. Роутер ядра используется для передачи данных и команд в сети между ядрами. Роутер каждого ядра имеет
- 75. Частоты и управление питанием
- 76. Синхронизация Разработчикам очень трудно обеспечить появление частотного сигнала в одно и то же время во всех
- 77. Чип может работать на нескольких скоростях, в зависимости от рабочего напряжения. При частоте 4 ГГц чип
- 78. Перспективы Процессор с производительностью, измеряющейся с приставкой тера- является переломным этапом. Intel заявляет, что следующим шагом
- 79. Что дальше?
- 81. Скачать презентацию

4096tb@gmail.com
Тема письма:
БГУИР. … .
Ковалевский Вячеслав Викторович
4096tb@gmail.com
Тема письма:
БГУИР. … .
Ковалевский Вячеслав Викторович

Лекция 5. Структура процессора. Архитектуры CISC и RISC. Архитектура процессора Intel
Лекция 5. Структура процессора. Архитектуры CISC и RISC. Архитектура процессора Intel

Лекция 6. Адресация. Режимы работы процессора.
Управление памятью.
План лекции:
Адресация памяти. Непосредственная,
Лекция 6. Адресация. Режимы работы процессора.
Управление памятью.
План лекции:
Адресация памяти. Непосредственная,

Лекция 7. Производительность. Многопроцессорные системы
План лекции:
Иерархия памяти. Кэш. Развитие архитектуры IA-32.
Лекция 7. Производительность. Многопроцессорные системы
План лекции:
Иерархия памяти. Кэш. Развитие архитектуры IA-32.

Иерархия памяти
Иерархия памяти
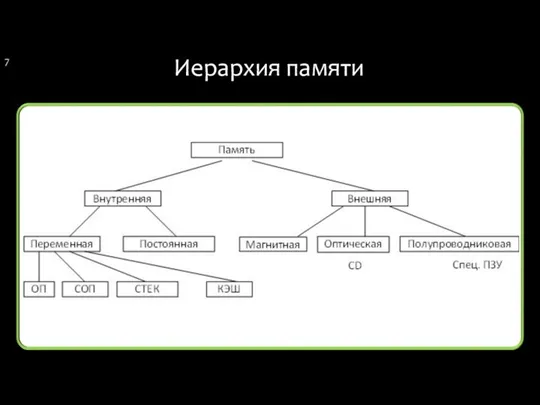
Иерархия памяти
Иерархия памяти
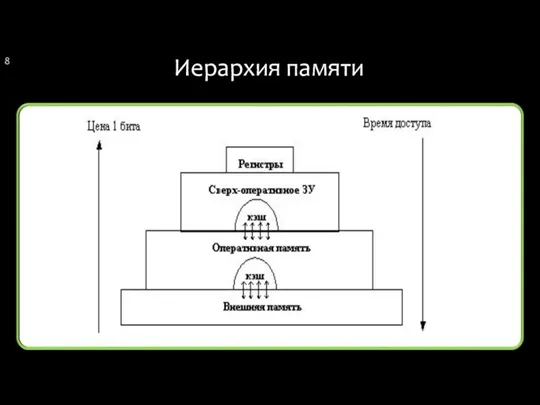
Иерархия памяти
Иерархия памяти
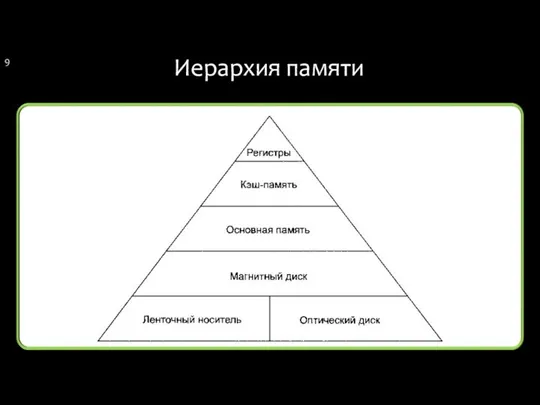
Иерархия памяти
Иерархия памяти
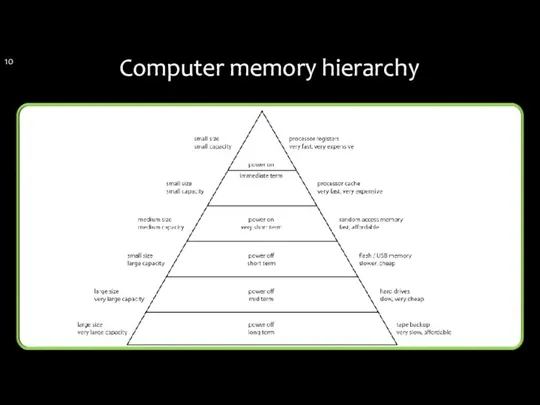
Computer memory hierarchy
Computer memory hierarchy

Повышение производительности
Развитие архитектуры IA-32. Кэш. FPU.
Повышение производительности
Развитие архитектуры IA-32. Кэш. FPU.

Производительность
Это количество выполняемых за такт команд
IPC – Instructions per cycle
(команды
Производительность
Это количество выполняемых за такт команд
IPC – Instructions per cycle
(команды

Скорость света не превысить!
300 000 km/s - скорость света в вакууме
300
Скорость света не превысить!
300 000 km/s - скорость света в вакууме
300

Параллелизм
Параллелизм:
на уровне команд
(ILP – Instruction Level Parallelism)
на уровне
Параллелизм
Параллелизм:
на уровне команд
(ILP – Instruction Level Parallelism)
на уровне

Конвейеризация
(Рipelining)
Реализация обработки команд внутри процессора в несколько этапов
Идея состоит в
Конвейеризация
(Рipelining)
Реализация обработки команд внутри процессора в несколько этапов
Идея состоит в
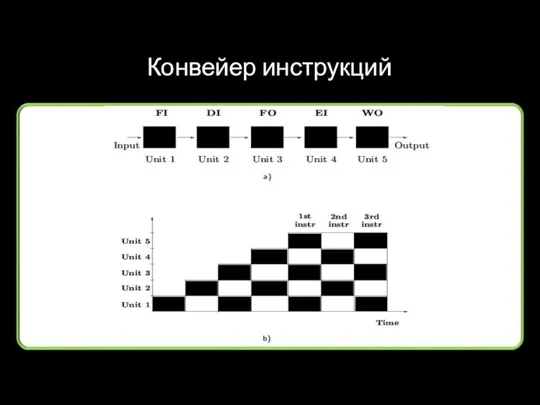
Конвейер инструкций
Таненбаум, с.59 (рис. 2.5)
Конвейер инструкций
Таненбаум, с.59 (рис. 2.5)
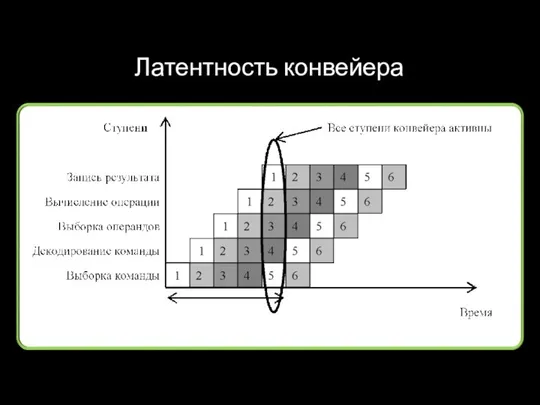
Латентность конвейера
Таненбаум, с.59 (рис. 2.5)
Латентность конвейера
Таненбаум, с.59 (рис. 2.5)
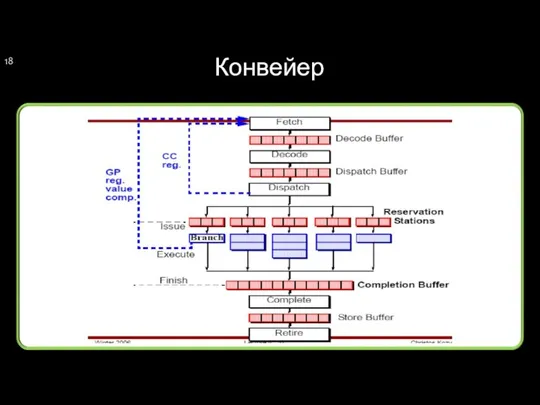
Конвейер
Конвейер

Intel Pentium IV
Суперскалярная архитектура (как и все Pentium’ы )
«Гиперконвейерная технология»
Intel Pentium IV
Суперскалярная архитектура (как и все Pentium’ы )
«Гиперконвейерная технология»

Согласно Флинту
SISD (Single Instruction, Single Data)
SIMD (Single Instructions, Multiple Data)
MISD (Multiple
Согласно Флинту
SISD (Single Instruction, Single Data)
SIMD (Single Instructions, Multiple Data)
MISD (Multiple

Пути достижения параллелизма
Потоковая архитектура
ОКМД (одна операция над многими данными – MMX,
Пути достижения параллелизма
Потоковая архитектура
ОКМД (одна операция над многими данными – MMX,
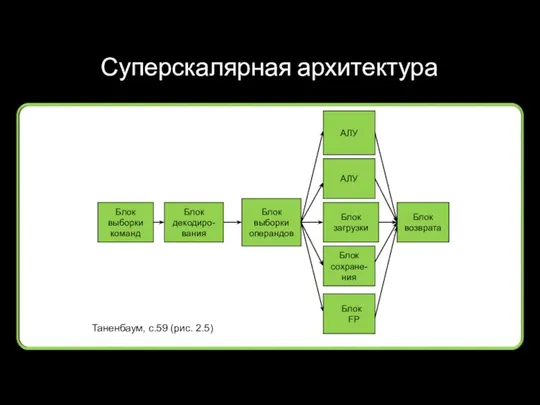
Суперскалярная архитектура
Таненбаум, с.59 (рис. 2.5)
Суперскалярная архитектура
Таненбаум, с.59 (рис. 2.5)

Hyper-Threading
Одно физическое ядро «успевает» обрабатывать два потока команд.
Операционная система «видит»
Hyper-Threading
Одно физическое ядро «успевает» обрабатывать два потока команд.
Операционная система «видит»


Multiprocessor
systems
Multiprocessor
systems
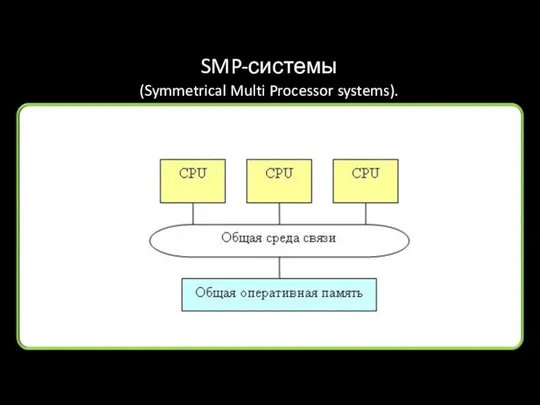
SMP-системы
(Symmetrical Multi Processor systems).
SMP-системы
(Symmetrical Multi Processor systems).

Закон Амдала
Speedup - относительное ускорение
f- часть кода, которая может быть распараллелена
Закон Амдала
Speedup - относительное ускорение
f- часть кода, которая может быть распараллелена

α - часть кода, которая не распараллеливается
(1 − α
α - часть кода, которая не распараллеливается (1 − α
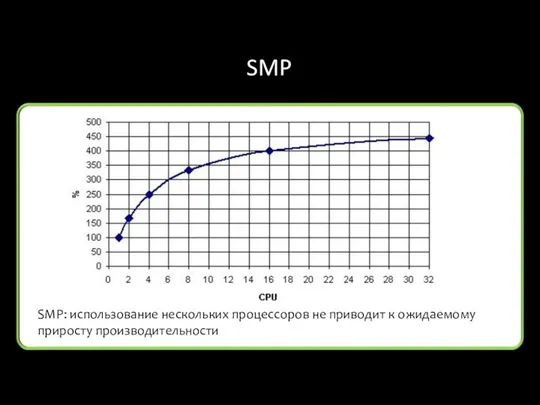
SMP
SMP: использование нескольких процессоров не приводит к ожидаемому приросту производительности
SMP
SMP: использование нескольких процессоров не приводит к ожидаемому приросту производительности
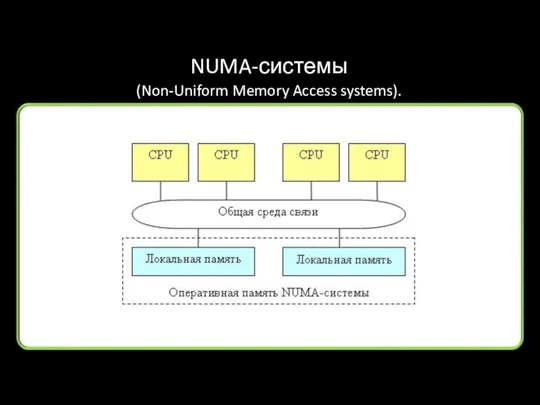
NUMA-системы
(Non-Uniform Memory Access systems).
NUMA-системы
(Non-Uniform Memory Access systems).

Кластеры
Основная «область применения» кластеров:
Cуперкомпьютеры
Кластеры
Основная «область применения» кластеров:
Cуперкомпьютеры
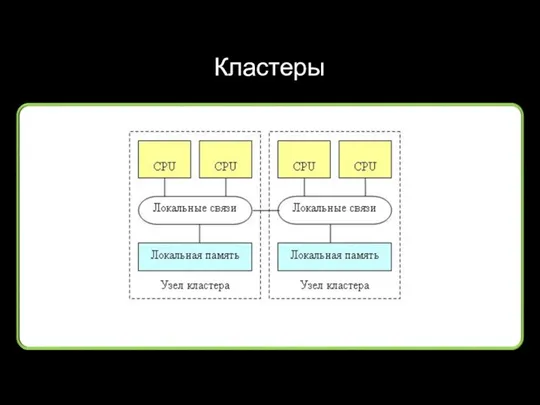
Кластеры
Кластеры

HyperТhreading
(Гипертрейдинг)
HyperТhreading
(Гипертрейдинг)

SMP - Symmetrical MultiProcessing
SMP - Symmetrical MultiProcessing

Двухъядерный процессор
Двухъядерный процессор

Intel Smithfield
Ядро Smithfield – это два обычных Prescott в одном кристалле
Intel Smithfield
Ядро Smithfield – это два обычных Prescott в одном кристалле
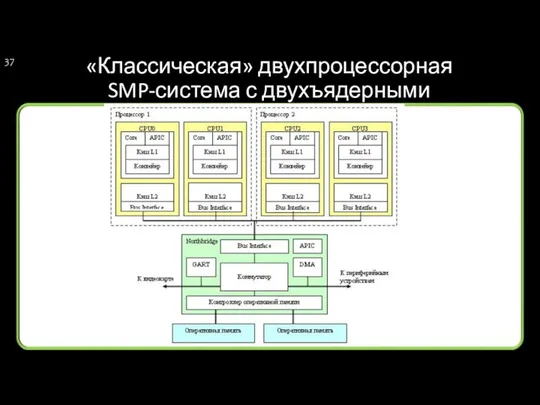
«Классическая» двухпроцессорная SMP-система с двухъядерными процессорами
«Классическая» двухпроцессорная SMP-система с двухъядерными процессорами

SUMA
Slightly Uniform Memory Architecture
("почти однородная архитектура памяти")
Основа SUMA
SUMA
Slightly Uniform Memory Architecture
("почти однородная архитектура памяти")
Основа SUMA

AMD Toledo
AMD Toledo
AMD Toledo
AMD Toledo
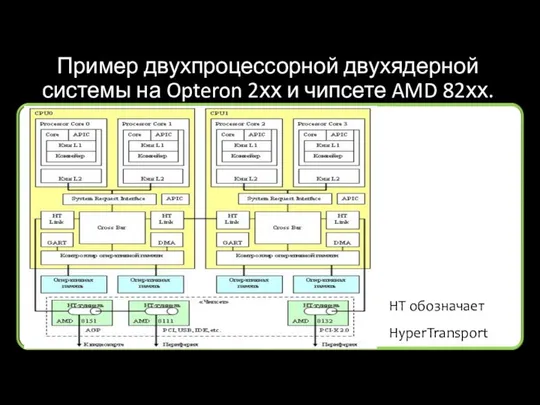
Пример двухпроцессорной двухядерной системы на Opteron 2хх и чипсете AMD 82хх.
Пример двухпроцессорной двухядерной системы на Opteron 2хх и чипсете AMD 82хх.
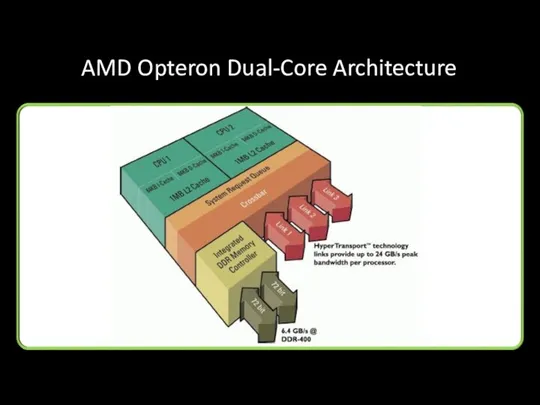
AMD Opteron Dual-Core Architecture
AMD Opteron Dual-Core Architecture

Intel & AMD
Разница между реализациями AMD и Intel с «технологической» точки
Intel & AMD
Разница между реализациями AMD и Intel с «технологической» точки
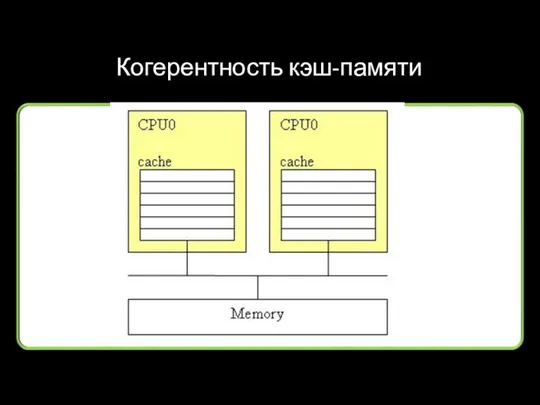
Когерентность кэш-памяти
Когерентность кэш-памяти

Когерентность кэш-памяти
Протоколы поддержания когерентности кэшей:
у процессоров Intel - «MESI»,
у процессоров
Когерентность кэш-памяти
Протоколы поддержания когерентности кэшей:
у процессоров Intel - «MESI»,
у процессоров
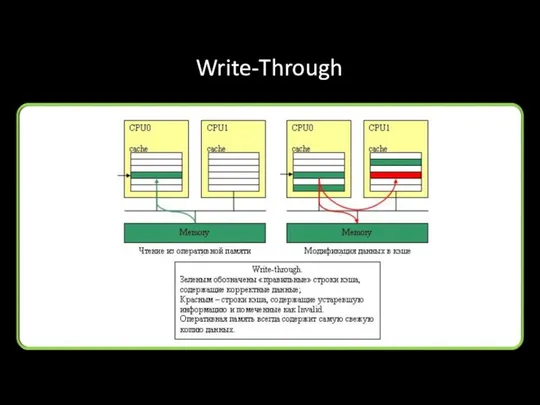
Write-Through
Write-Through

MESI
MESI (Modified, Exclusive, Shared, Invalid)
Modified - состояние (выделено желтым) соответствует
MESI
MESI (Modified, Exclusive, Shared, Invalid)
Modified - состояние (выделено желтым) соответствует
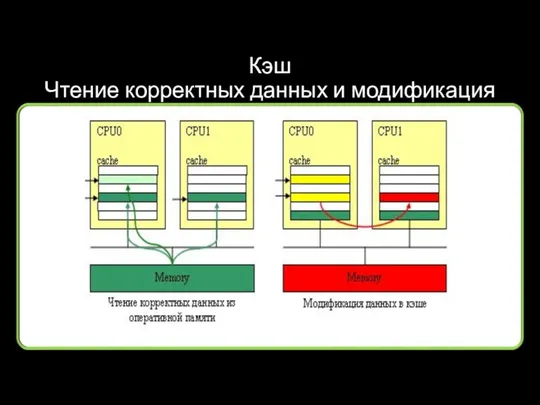
Кэш
Чтение корректных данных и модификация
Кэш
Чтение корректных данных и модификация
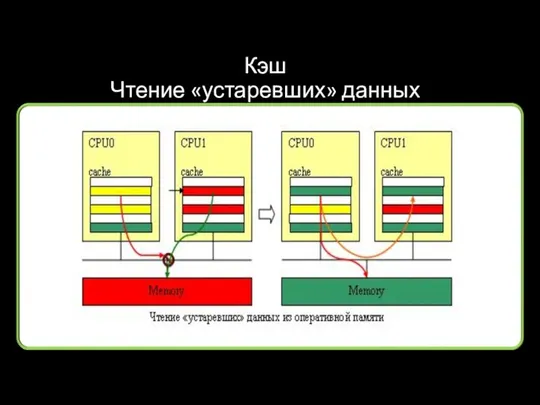
Кэш
Чтение «устаревших» данных
Кэш
Чтение «устаревших» данных

MOESI
MOESI (Modified, Owner, Exclusive, Shared, Invalid)
Modified - состояние (выделено желтым) соответствует
MOESI
MOESI (Modified, Owner, Exclusive, Shared, Invalid)
Modified - состояние (выделено желтым) соответствует
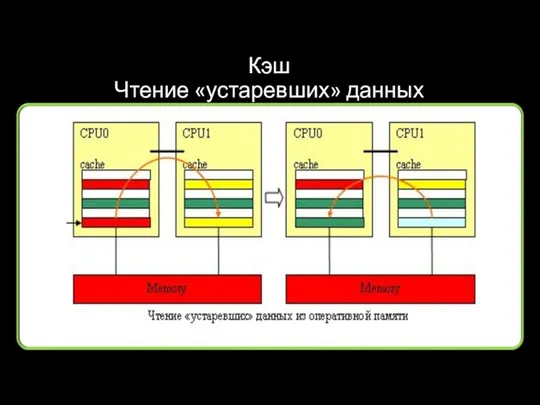
Кэш
Чтение «устаревших» данных
Кэш
Чтение «устаревших» данных
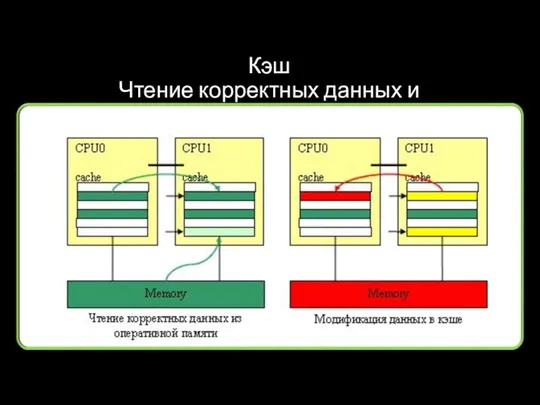
Кэш
Чтение корректных данных и модификация
Кэш
Чтение корректных данных и модификация
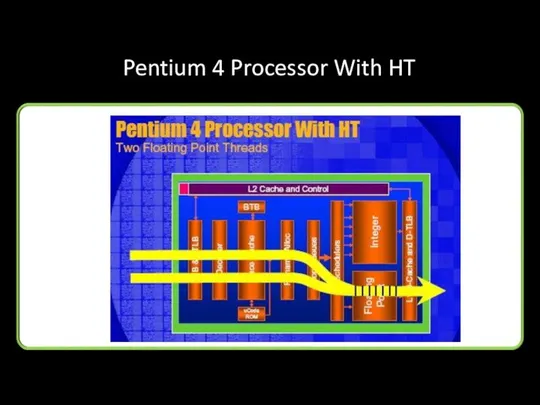
Pentium 4 Processor With HT
Pentium 4 Processor With HT
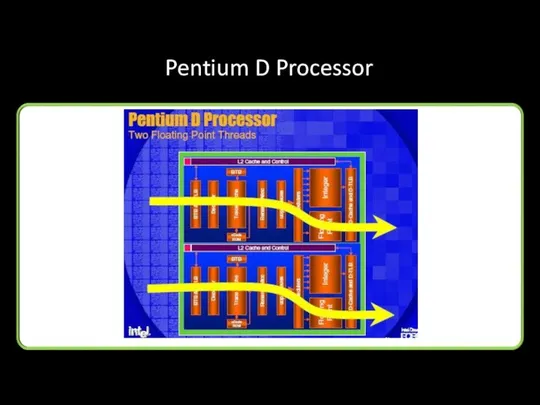
Pentium D Processor
Pentium D Processor
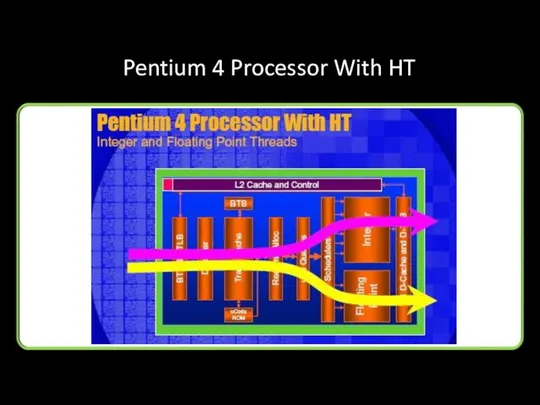
Pentium 4 Processor With HT
Pentium 4 Processor With HT
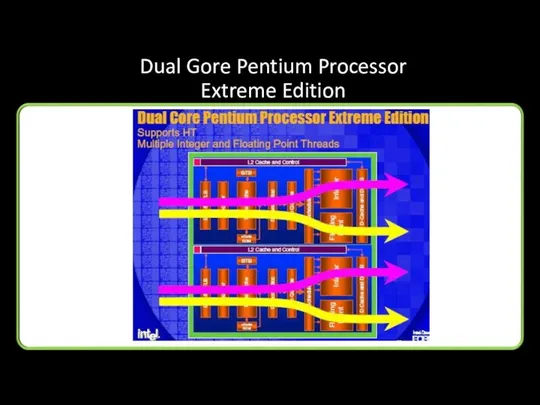
Dual Gore Pentium Processor
Extreme Edition
Dual Gore Pentium Processor
Extreme Edition

Реализация IA-64
Intel Itanium2
Реализация IA-64
Intel Itanium2

IA-32 / IA-64
IA-32 / IA-64

Реализация IA-64:
Intel Itanium2
Наиболее кардинальным нововведением IA-64 по сравнению с RISC является
Реализация IA-64:
Intel Itanium2
Наиболее кардинальным нововведением IA-64 по сравнению с RISC является

EPIC
EPIC (Explicitly Parallel Instruction Computing) - явный параллелизм на уровне команд
EPIC
EPIC (Explicitly Parallel Instruction Computing) - явный параллелизм на уровне команд

В обеих архитектурах явный параллелизм представлен уже на уровне команд, управляющих
В обеих архитектурах явный параллелизм представлен уже на уровне команд, управляющих

Itanium 2
Конвейер в Itanium 2 состоит из 8 этапов,
способен за
Itanium 2
Конвейер в Itanium 2 состоит из 8 этапов, способен за
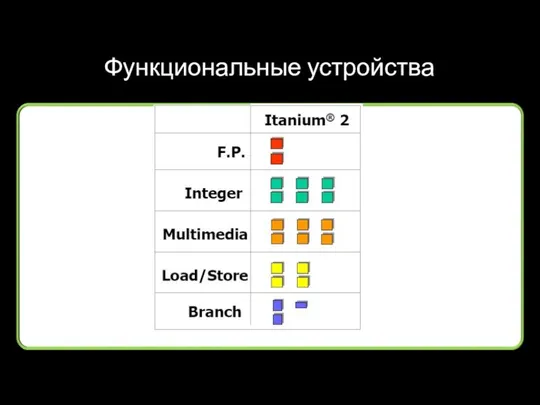
Функциональные устройства
Функциональные устройства

Itanium 2
Каждая из инструкций при разборе связки направляется на соответствующий ее
Itanium 2
Каждая из инструкций при разборе связки направляется на соответствующий ее

Формат связки команд IA-64
Связка имеет длину 128 разрядов.
Она включает
Формат связки команд IA-64
Связка имеет длину 128 разрядов. Она включает

http://www.ixbt.com/cpu/ia64.html
14
http://www.ixbt.com/cpu/ia64.html
14

IA-64
IA-64 перекладывает всю работу
по оптимизации потока команд на компилятор.
Каждый
IA-64
IA-64 перекладывает всю работу
по оптимизации потока команд на компилятор.
Каждый

IA-64
Компиляторы для IA-64 используют технологию "отмеченных команд" (predication) для устранения потерь
IA-64
Компиляторы для IA-64 используют технологию "отмеченных команд" (predication) для устранения потерь

Конвейер Itanium
Устройство предварительной обработки инструкций в порядке их следования в программном
Конвейер Itanium
Устройство предварительной обработки инструкций в порядке их следования в программном
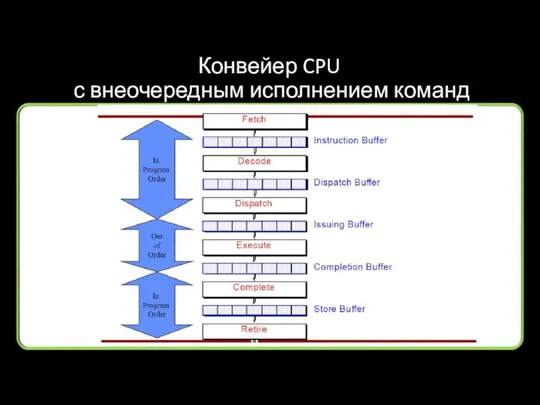
Конвейер CPU
с внеочередным исполнением команд
Конвейер CPU
с внеочередным исполнением команд
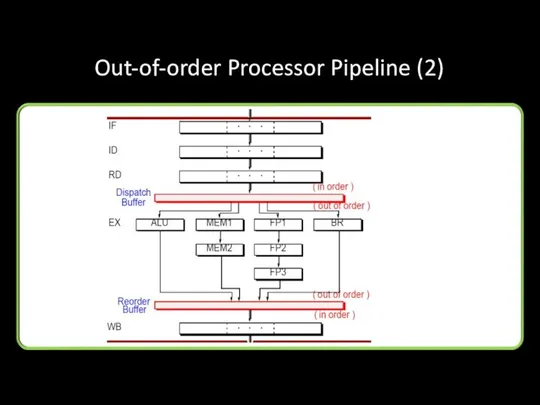
Out-of-order Processor Pipeline (2)
Out-of-order Processor Pipeline (2)

80-ядерный процессор
Intel Teraflops Research Chip
80-ядерный процессор
Intel Teraflops Research Chip

Технология
Teraflops основан на техпроцессе 65 нм.
Процессор построен на одной подложке,
Технология
Teraflops основан на техпроцессе 65 нм.
Процессор построен на одной подложке,
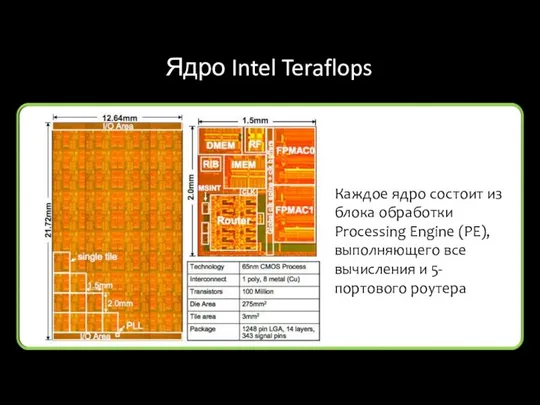
Ядро Intel Teraflops
Каждое ядро состоит из блока обработки Processing Engine
Ядро Intel Teraflops
Каждое ядро состоит из блока обработки Processing Engine

Роутер ядра используется для передачи данных и команд в сети между
Роутер ядра используется для передачи данных и команд в сети между

Частоты и управление питанием
Частоты и управление питанием

Синхронизация
Разработчикам очень трудно обеспечить появление частотного сигнала в одно и то
Синхронизация
Разработчикам очень трудно обеспечить появление частотного сигнала в одно и то

Чип может работать на нескольких скоростях, в зависимости от рабочего напряжения.
Чип может работать на нескольких скоростях, в зависимости от рабочего напряжения.

Перспективы
Процессор с производительностью, измеряющейся с приставкой тера- является переломным этапом.
Intel
Перспективы
Процессор с производительностью, измеряющейся с приставкой тера- является переломным этапом.
Intel
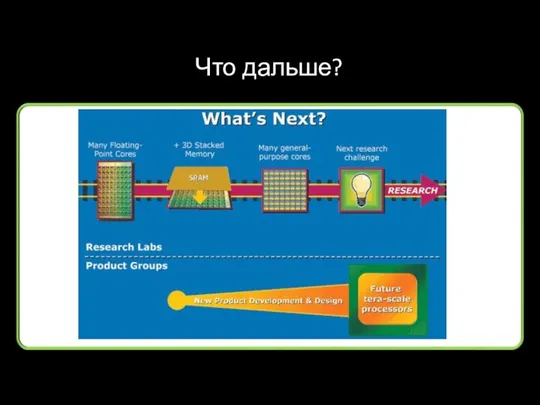
Что дальше?
Что дальше?
 Презентация "Булгаков Михаил" - скачать презентации по МХК
Презентация "Булгаков Михаил" - скачать презентации по МХК Причины коррупции в сфере государственной службы
Причины коррупции в сфере государственной службы Заболевания наружного уха, острый средний отит, мастоидит
Заболевания наружного уха, острый средний отит, мастоидит  Niedersachsen
Niedersachsen Искусство Древнего Китая
Искусство Древнего Китая Россия в XVII веке. Образование, наука и общественное мнение
Россия в XVII веке. Образование, наука и общественное мнение Презентация Структура денежно-кредитного рынка
Презентация Структура денежно-кредитного рынка Электронная почта
Электронная почта Повторение условного оператора
Повторение условного оператора Монументально-декоративное искусство Японии
Монументально-декоративное искусство Японии Беларусь і праблемы міжнароднай бяспекі ў 2000-х гг. Пагрозы
Беларусь і праблемы міжнароднай бяспекі ў 2000-х гг. Пагрозы Доклад на тему: «Педагогика и психология.» Выполнила: Студентка 1 курса 11 группы Сегень Екатерина Руководитель: Москалёва О
Доклад на тему: «Педагогика и психология.» Выполнила: Студентка 1 курса 11 группы Сегень Екатерина Руководитель: Москалёва О Дроссели и трансформаторы источников питания
Дроссели и трансформаторы источников питания Предложение. Эластичность предложения. Работа выполнена учителем экономики МОУ СОШ № 4 Г. Сосновый Бор Ефимовой Е.В.
Предложение. Эластичность предложения. Работа выполнена учителем экономики МОУ СОШ № 4 Г. Сосновый Бор Ефимовой Е.В.  Заполнители из природных плотных каменных пород
Заполнители из природных плотных каменных пород Физическая подготовка альпиниста
Физическая подготовка альпиниста Культура эпохи Возрождения Это,несомненно,золотой век, который вернул свет свободным искусствам.
Культура эпохи Возрождения Это,несомненно,золотой век, который вернул свет свободным искусствам. Основные направления социальной политики Вьетнама
Основные направления социальной политики Вьетнама  Бөлмелер экспликациясы
Бөлмелер экспликациясы Аттестационная работа. Методическая разработка “Датчик воды для Ардуино своими руками”
Аттестационная работа. Методическая разработка “Датчик воды для Ардуино своими руками” Внедрение игровой робототехники в образовательное пространство ОУ СПО
Внедрение игровой робототехники в образовательное пространство ОУ СПО Свадебная атрибутика славян
Свадебная атрибутика славян Обозначения условные приборов и средств автоматизации в схемах
Обозначения условные приборов и средств автоматизации в схемах Производная степенной функции
Производная степенной функции Предметные недели: нетрадиционный подход. И мы сохраним, тебя, русская речь, Великое русское слово. Анна Ахматова.
Предметные недели: нетрадиционный подход. И мы сохраним, тебя, русская речь, Великое русское слово. Анна Ахматова. Схемо- и системотехника электронных средств
Схемо- и системотехника электронных средств Легенда о Святом Валентине. День Святого Валентина в разных странах
Легенда о Святом Валентине. День Святого Валентина в разных странах Организационно-функциональная структура государственного управления в Республике Казахстан
Организационно-функциональная структура государственного управления в Республике Казахстан