- Распараллеливание на компьютерах с общей памятью

Содержание
- 2. Часть 3: Распараллеливание на компьютерах с общей памятью Средства программирования для компьютеров с общей памятью (OpenMP,
- 3. Средства программирования для компьютеров с общей памятью Компьютер с общей памятью (shared memory) Особенность: автоматический обмен
- 4. Средства программирования для компьютеров с общей памятью Основное средство программирования: OpenMP (система директив препроцессора, которые сообщают
- 5. Понятие потока Поток (нить, thread) – блок команд и данных для исполнения на одном из исполняющих
- 6. Понятие потока Нужно знать, что существуют механизмы, которые позволяют пытаться установить связь между реальными, виртуальными и
- 7. Уровни параллелизма 4 уровня Физический (ядра процессора) Виртуальный физический (гиперсрединг, hyperthreading) Системный Программный Инженер-программист всегда программирует
- 8. Упрощённая модель 2-процессорного сервера Физический уровень для 2-процессорного сервера ЯДРО ЯДРО ЯДРО КЭШ 1 КЭШ 1
- 9. Гиперсрединг обычно включён по умолчанию – выключайте, если можете для высокопроизводительных вычислений Виртуальный физический (hyperthreading) уровень
- 10. Операционная система имеет ограниченную видимость архитектуры Уровень операционной системы (тот же сервер) ЯДРО ЯДРО ЯДРО ЯДРО
- 11. Программа практически не видит архитектуры Уровень программы (тот же сервер) ЯДРО ЯДРО ЯДРО ЯДРО ПАМЯТЬ ЯДРО
- 12. Выключайте гиперсрединг в БИОСе по возможности Влияние гиперсрединга ЯДРО ЯДРО ЯДРО ЯДРО КЭШ 1 КЭШ 1
- 13. OS treats all HW threads as equal Влияние операционной системы (перетасовка) ЯДРО ЯДРО ЯДРО ЯДРО КЭШ
- 14. Операционная система видит все потоки как одинаковые Влияние неоднородной (NUMA) памяти ЯДРО ЯДРО ЯДРО ЯДРО КЭШ
- 15. КЭШ 1 Правильное распределение увеличивает производительность программы Влияние распределения потоков по ядрам 1 ЯДРО ЯДРО ЯДРО
- 16. Правильное распределение увеличивает производительность программы Влияние распределения потоков по ядрам 2 ЯДРО ЯДРО ЯДРО ЯДРО КЭШ
- 17. KMP_AFFINITY главный инструмент для привязки потоков друг к другу Инструменты Intel для решения проблем Компиляторы Intel
- 18. Работа с установками affinity KMP_AFFINITY=verbose Выдача OMP: Info #179: KMP_AFFINITY: 2 packages x 8 cores/pkg x
- 19. Рекомендации Если вы видите Неустойчивое время работы программы Плохую масштабируемость с N на 2N или с
- 20. Особенности параллельных программ Основа – обычная последовательная программа Дополнена директивами препроцессора, которые сообщают компилятору информацию о
- 21. Представление об управляющих конструкциях OpenMP Принцип работы: интерпретация куска программы как программы для многих потоков ...
- 22. Представление об управляющих конструкциях OpenMP Директивы компилятора: #pragma omp NAME [clause [clause]…] (Си) $OMP NAME [clause
- 23. Представление об управляющих конструкциях OpenMP Полезные функции void omp_set_num_threads(int num_threads); (Си) subroutine omp_set_num_threads(num_threads) (Фортран) integer num_threads
- 24. Представление об управляющих конструкциях OpenMP Полезные функции для продвинутого параллелизма void omp_init_lock(omp_lock_t *lock); void omp_init_nest_lock(omp_nest_lock_t *lock);
- 25. Представление об управляющих конструкциях OpenMP Пример OpenMP программы #pragma omp parallel for private(i) firstprivate(N) shared(a,b) lastprivate(j)
- 26. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 0) sum=0.0; for (int i=0; i {
- 27. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 1) sum=0.0; #pragma omp parallel for for
- 28. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 2) sum=0.0; #pragma omp parallel for for
- 29. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 3) sum=0.0; #pragma omp parallel for reduction(+:sum)
- 30. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 4) sum=0.0; #pragma omp parallel for reduction(+:sum)
- 31. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 5) sum=0.0; #pragma omp parallel for reduction(+:sum)
- 32. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 6) sum=0.0; #pragma omp parallel for reduction(+:sum)
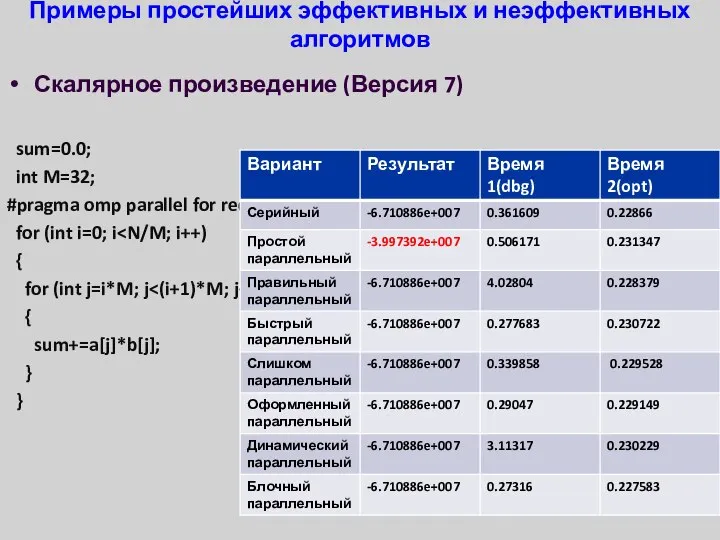
- 33. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 7) sum=0.0; int M=32; #pragma omp parallel
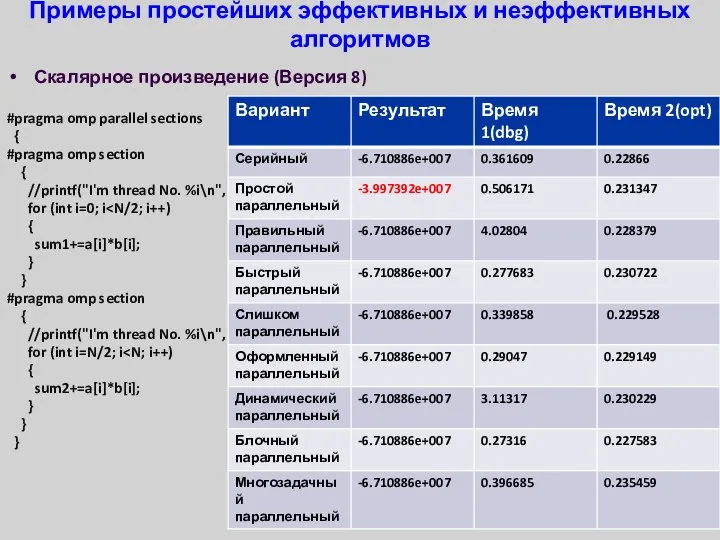
- 34. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 8) #pragma omp parallel sections { #pragma
- 35. Примеры простейших эффективных и неэффективных алгоритмов Итог: Увы, но на другом компьютере результаты могут существенно отличаться
- 36. Синхронизация параллельных вычислений Простейшая конструкция синхронизации: barrier #pragma omp barrier !$omp barrier Исполнение параллельного кода присотанавливается
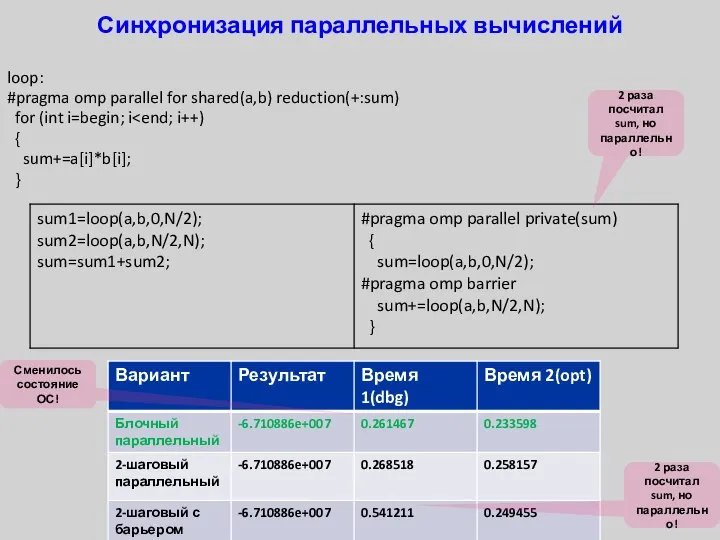
- 37. Синхронизация параллельных вычислений loop: #pragma omp parallel for shared(a,b) reduction(+:sum) for (int i=begin; i { sum+=a[i]*b[i];
- 38. Синхронизация параллельных вычислений Конструкции Single & Master #pragma omp single\master !$omp single\master Исполнение данной части кода
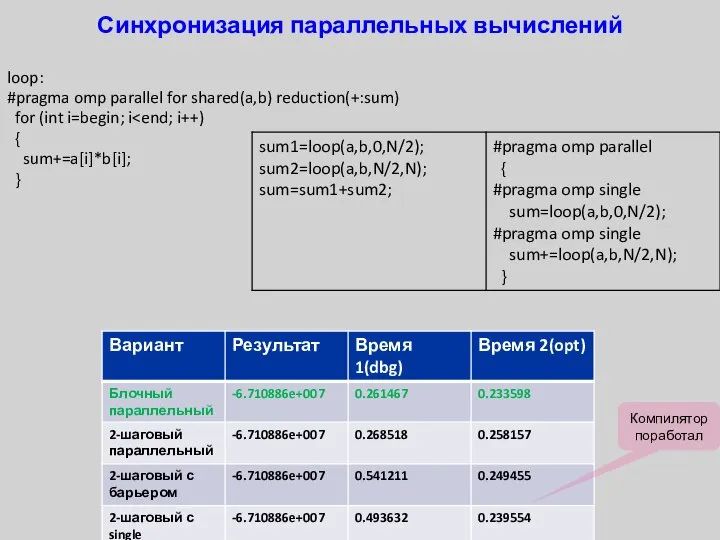
- 39. Синхронизация параллельных вычислений loop: #pragma omp parallel for shared(a,b) reduction(+:sum) for (int i=begin; i { sum+=a[i]*b[i];
- 40. Синхронизация параллельных вычислений Конструкция Critical #pragma omp critical !$omp critical Исполнение данной части кода происходит потоками
- 41. Синхронизация параллельных вычислений loop: #pragma omp parallel for shared(a,b) reduction(+:sum) for (int i=begin; i { sum+=a[i]*b[i];
- 42. Синхронизация параллельных вычислений Конструкция Flush #pragma omp flush !$omp flush Делает видимой всем часть памяти (переменные),
- 43. Немного об OpenMP 4.* OpenMP 4.0 – это ответ на вызов альтернативного стандарта OpenACC Дополнения, связанные
- 44. Резюме Компьютер с общей памятью является простейшим вариантом параллельного компьютера Компьютер с общей памятью исполняет потоки
- 46. Скачать презентацию

Часть 3: Распараллеливание на компьютерах с общей памятью
Средства программирования для компьютеров
Часть 3: Распараллеливание на компьютерах с общей памятью
Средства программирования для компьютеров

Средства программирования для компьютеров с общей памятью
Компьютер с общей памятью (shared
Средства программирования для компьютеров с общей памятью
Компьютер с общей памятью (shared

Средства программирования для компьютеров с общей памятью
Основное средство программирования: OpenMP (система
Средства программирования для компьютеров с общей памятью
Основное средство программирования: OpenMP (система

Понятие потока
Поток (нить, thread) – блок команд и данных для исполнения
Понятие потока
Поток (нить, thread) – блок команд и данных для исполнения

Понятие потока
Нужно знать, что существуют механизмы, которые позволяют пытаться установить связь
Понятие потока
Нужно знать, что существуют механизмы, которые позволяют пытаться установить связь

Уровни параллелизма
4 уровня
Физический (ядра процессора)
Виртуальный физический (гиперсрединг, hyperthreading)
Системный
Программный
Инженер-программист всегда программирует
Уровни параллелизма
4 уровня
Физический (ядра процессора)
Виртуальный физический (гиперсрединг, hyperthreading)
Системный
Программный
Инженер-программист всегда программирует
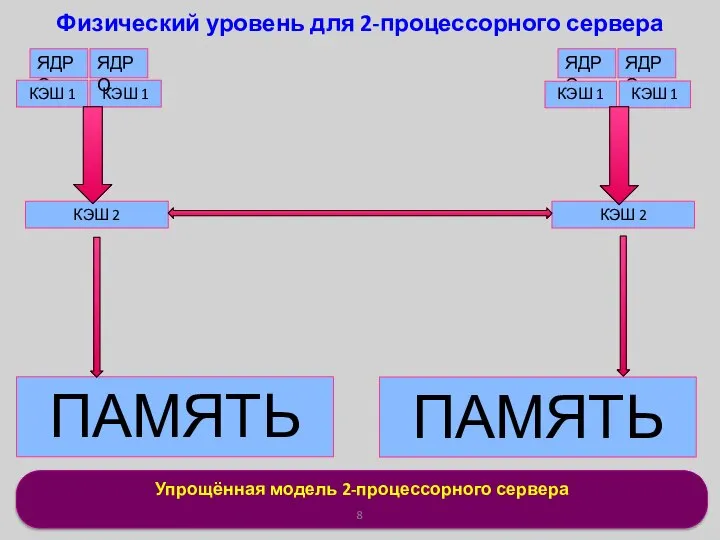
Упрощённая модель 2-процессорного сервера
Физический уровень для 2-процессорного сервера
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ 1
КЭШ 1
КЭШ
Упрощённая модель 2-процессорного сервера
Физический уровень для 2-процессорного сервера
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ 1
КЭШ 1
КЭШ
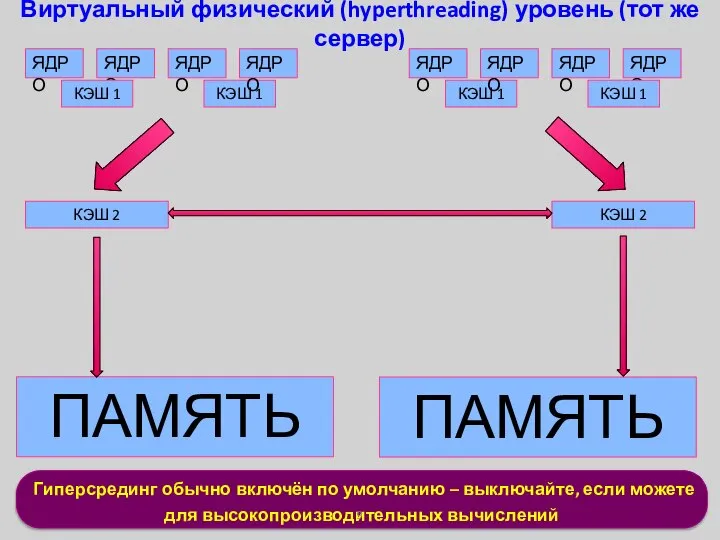
Гиперсрединг обычно включён по умолчанию – выключайте, если можете
для высокопроизводительных
Гиперсрединг обычно включён по умолчанию – выключайте, если можете
для высокопроизводительных

Операционная система имеет ограниченную видимость архитектуры
Уровень операционной системы (тот же сервер)
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ
Операционная система имеет ограниченную видимость архитектуры
Уровень операционной системы (тот же сервер)
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ

Программа практически не видит архитектуры
Уровень программы (тот же сервер)
ЯДРО
ЯДРО
ЯДРО
ЯДРО
ПАМЯТЬ
ЯДРО
ЯДРО
ЯДРО
ЯДРО
Наивная реализация алгоритма
Программа практически не видит архитектуры
Уровень программы (тот же сервер)
ЯДРО
ЯДРО
ЯДРО
ЯДРО
ПАМЯТЬ
ЯДРО
ЯДРО
ЯДРО
ЯДРО
Наивная реализация алгоритма
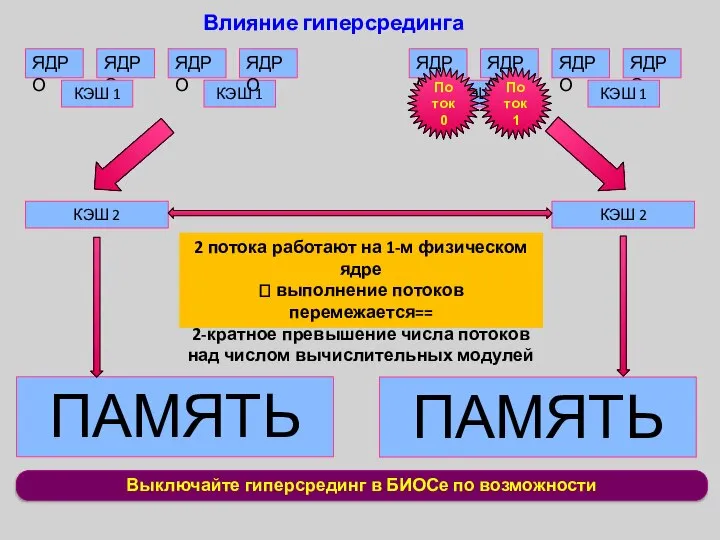
Выключайте гиперсрединг в БИОСе по возможности
Влияние гиперсрединга
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ 1
КЭШ 1
КЭШ 1
КЭШ
Выключайте гиперсрединг в БИОСе по возможности
Влияние гиперсрединга
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ 1
КЭШ 1
КЭШ 1
КЭШ
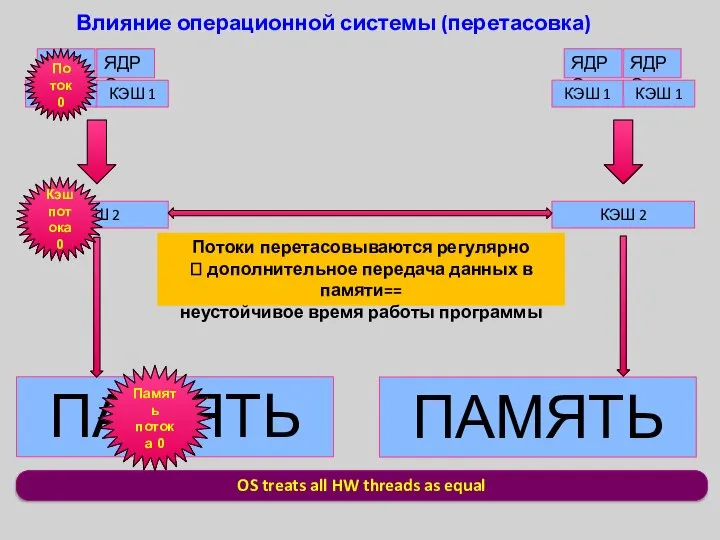
OS treats all HW threads as equal
Влияние операционной системы (перетасовка)
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ
OS treats all HW threads as equal
Влияние операционной системы (перетасовка)
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ
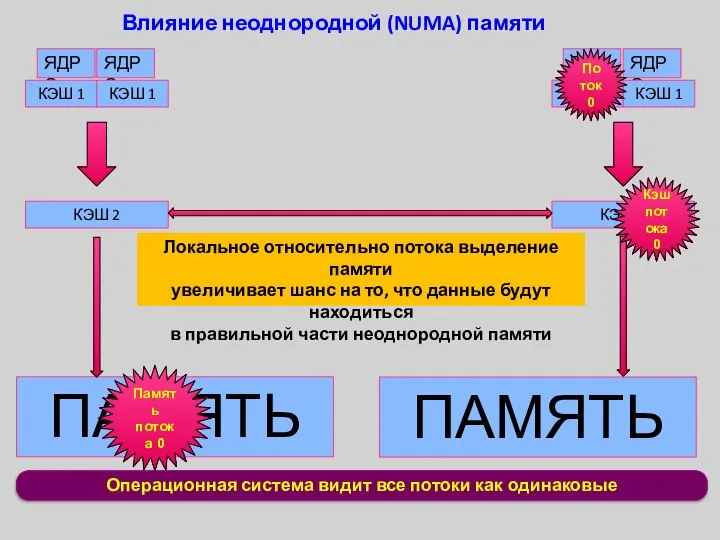
Операционная система видит все потоки как одинаковые
Влияние неоднородной (NUMA) памяти
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ
Операционная система видит все потоки как одинаковые
Влияние неоднородной (NUMA) памяти
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ

КЭШ 1
Правильное распределение увеличивает производительность программы
Влияние распределения потоков по ядрам 1
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ
КЭШ 1
Правильное распределение увеличивает производительность программы
Влияние распределения потоков по ядрам 1
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ
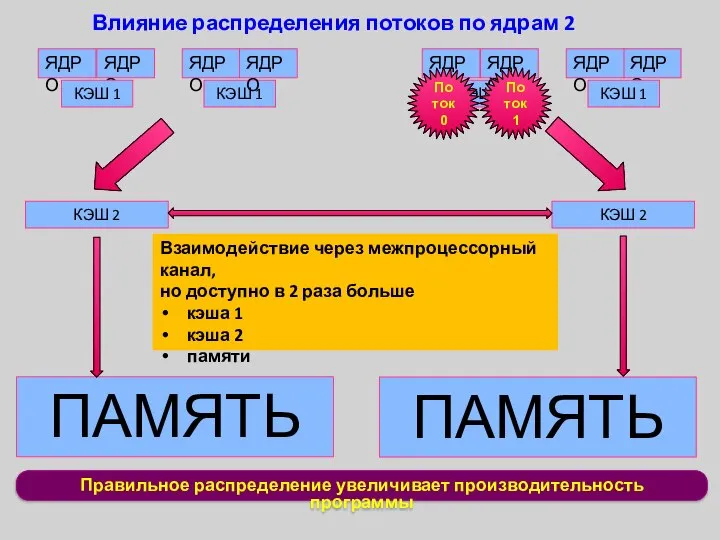
Правильное распределение увеличивает производительность программы
Влияние распределения потоков по ядрам 2
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ
Правильное распределение увеличивает производительность программы
Влияние распределения потоков по ядрам 2
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ

KMP_AFFINITY главный инструмент для привязки потоков друг к другу
Инструменты Intel для
KMP_AFFINITY главный инструмент для привязки потоков друг к другу
Инструменты Intel для

Работа с установками affinity
KMP_AFFINITY=verbose
Выдача
OMP: Info #179: KMP_AFFINITY: 2 packages x 8
Работа с установками affinity
KMP_AFFINITY=verbose
Выдача
OMP: Info #179: KMP_AFFINITY: 2 packages x 8

Рекомендации
Если вы видите
Неустойчивое время работы программы
Плохую масштабируемость с N на 2N
Рекомендации
Если вы видите
Неустойчивое время работы программы
Плохую масштабируемость с N на 2N

Особенности параллельных программ
Основа – обычная последовательная программа
Дополнена директивами препроцессора, которые сообщают
Особенности параллельных программ
Основа – обычная последовательная программа
Дополнена директивами препроцессора, которые сообщают

Представление об управляющих конструкциях OpenMP
Принцип работы: интерпретация куска программы как программы
Представление об управляющих конструкциях OpenMP
Принцип работы: интерпретация куска программы как программы

Представление об управляющих конструкциях OpenMP
Директивы компилятора:
#pragma omp NAME [clause [clause]…] (Си)
$OMP
Представление об управляющих конструкциях OpenMP
Директивы компилятора:
#pragma omp NAME [clause [clause]…] (Си)
$OMP

Представление об управляющих конструкциях OpenMP
Полезные функции
void omp_set_num_threads(int num_threads); (Си)
subroutine omp_set_num_threads(num_threads) (Фортран)
integer
Представление об управляющих конструкциях OpenMP
Полезные функции
void omp_set_num_threads(int num_threads); (Си)
subroutine omp_set_num_threads(num_threads) (Фортран)
integer

Представление об управляющих конструкциях OpenMP
Полезные функции для продвинутого параллелизма
void omp_init_lock(omp_lock_t *lock);
void
Представление об управляющих конструкциях OpenMP
Полезные функции для продвинутого параллелизма
void omp_init_lock(omp_lock_t *lock);
void

Представление об управляющих конструкциях OpenMP
Пример OpenMP программы
#pragma omp parallel for private(i)
Представление об управляющих конструкциях OpenMP
Пример OpenMP программы
#pragma omp parallel for private(i)

Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 0)
sum=0.0;
for (int
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 0)
sum=0.0;
for (int

Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 1)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 1)
sum=0.0;
#pragma omp parallel

Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 2)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 2)
sum=0.0;
#pragma omp parallel

Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 3)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 3)
sum=0.0;
#pragma omp parallel

Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 4)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 4)
sum=0.0;
#pragma omp parallel
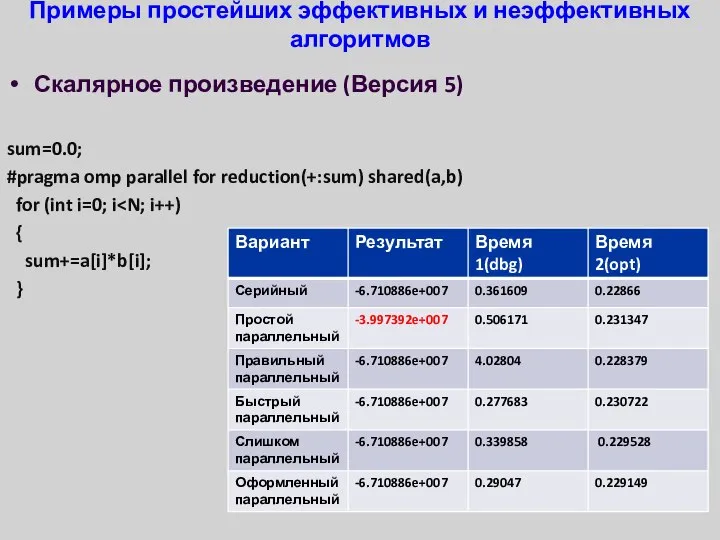
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 5)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 5)
sum=0.0;
#pragma omp parallel
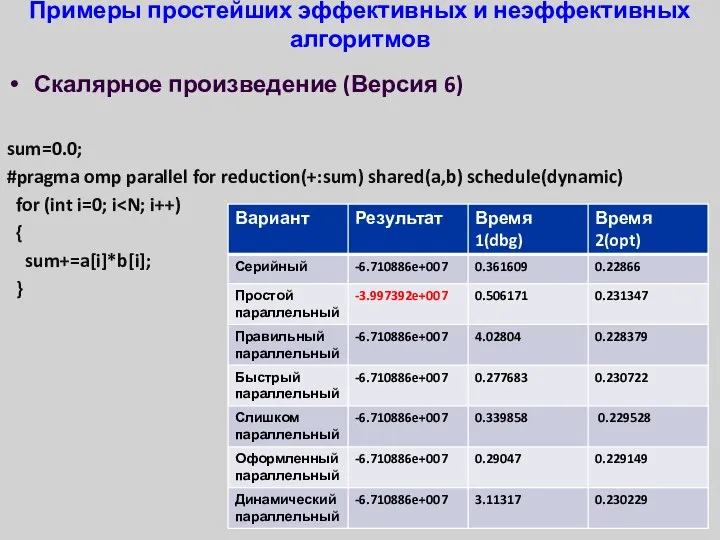
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 6)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 6)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 7)
sum=0.0;
int
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 7)
sum=0.0;
int
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 8)
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 8)
#pragma omp parallel

Примеры простейших эффективных и неэффективных алгоритмов
Итог:
Увы, но на другом компьютере результаты
Примеры простейших эффективных и неэффективных алгоритмов
Итог:
Увы, но на другом компьютере результаты

Синхронизация параллельных вычислений
Простейшая конструкция синхронизации: barrier
#pragma omp barrier
!$omp barrier
Исполнение параллельного кода
Синхронизация параллельных вычислений
Простейшая конструкция синхронизации: barrier
#pragma omp barrier
!$omp barrier
Исполнение параллельного кода
Синхронизация параллельных вычислений
loop:
#pragma omp parallel for shared(a,b) reduction(+:sum)
for (int i=begin;
Синхронизация параллельных вычислений
loop:
#pragma omp parallel for shared(a,b) reduction(+:sum)
for (int i=begin;

Синхронизация параллельных вычислений
Конструкции Single & Master
#pragma omp single\master
!$omp single\master
Исполнение данной части
Синхронизация параллельных вычислений
Конструкции Single & Master
#pragma omp single\master
!$omp single\master
Исполнение данной части
Синхронизация параллельных вычислений
loop:
#pragma omp parallel for shared(a,b) reduction(+:sum)
for (int i=begin;
Синхронизация параллельных вычислений
loop:
#pragma omp parallel for shared(a,b) reduction(+:sum)
for (int i=begin;

Синхронизация параллельных вычислений
Конструкция Critical
#pragma omp critical
!$omp critical
Исполнение данной части кода происходит
Синхронизация параллельных вычислений
Конструкция Critical
#pragma omp critical
!$omp critical
Исполнение данной части кода происходит
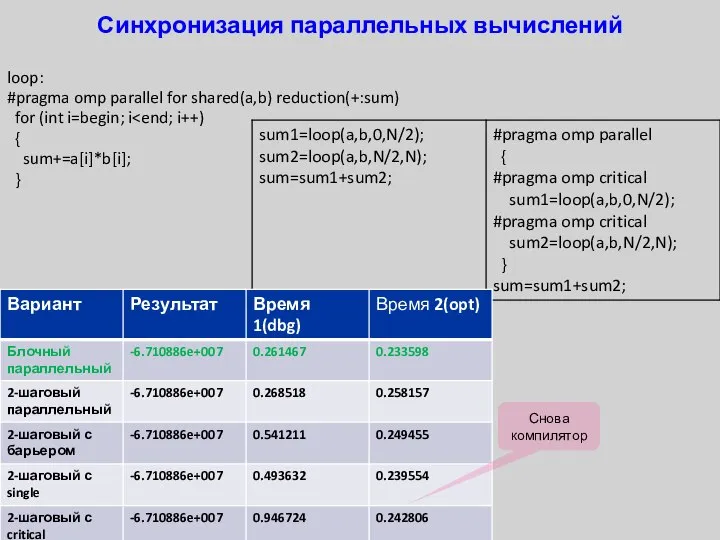
Синхронизация параллельных вычислений
loop:
#pragma omp parallel for shared(a,b) reduction(+:sum)
for (int i=begin;
Синхронизация параллельных вычислений
loop:
#pragma omp parallel for shared(a,b) reduction(+:sum)
for (int i=begin;

Синхронизация параллельных вычислений
Конструкция Flush
#pragma omp flush
!$omp flush
Делает видимой всем часть памяти
Синхронизация параллельных вычислений
Конструкция Flush
#pragma omp flush
!$omp flush
Делает видимой всем часть памяти

Немного об OpenMP 4.*
OpenMP 4.0 – это ответ на вызов альтернативного
Немного об OpenMP 4.*
OpenMP 4.0 – это ответ на вызов альтернативного

Резюме
Компьютер с общей памятью является простейшим вариантом параллельного компьютера
Компьютер с общей
Резюме
Компьютер с общей памятью является простейшим вариантом параллельного компьютера
Компьютер с общей
 Политическая идеология и политическая деятельность
Политическая идеология и политическая деятельность Договор комиссии и его значение
Договор комиссии и его значение  Искусство и духовная жизнь
Искусство и духовная жизнь  Отток клиентов от Дом.ru
Отток клиентов от Дом.ru Инфекционный контроль в хирургическом стационаре. ГУ НИИ Трансплантологии и Искусственных Органов МЗ РФ. Кондрашкина Л.А.,
Инфекционный контроль в хирургическом стационаре. ГУ НИИ Трансплантологии и Искусственных Органов МЗ РФ. Кондрашкина Л.А.,  Пасха. Христос и его крест
Пасха. Христос и его крест Инновационные процессы в образовании
Инновационные процессы в образовании Метод, техника и методика психологического воздействия на этапе следствия. Подготовил: Студен 2-го курса Группы ю-123б
Метод, техника и методика психологического воздействия на этапе следствия. Подготовил: Студен 2-го курса Группы ю-123б  Простые вещества - неметаллы
Простые вещества - неметаллы Презентация Функции руководителя Выполнили студентки 2-го курса экономического факультета направления подготовки финансовый м
Презентация Функции руководителя Выполнили студентки 2-го курса экономического факультета направления подготовки финансовый м Основные понятия деформации среза
Основные понятия деформации среза Электрификация фермы с разработкой внутреннего освещения на основе светодиодов
Электрификация фермы с разработкой внутреннего освещения на основе светодиодов Автоматическая коробка передач
Автоматическая коробка передач Бетонная смесь
Бетонная смесь Социальные эксперименты Антон Гуменский МГИМО, ноябрь 2009
Социальные эксперименты Антон Гуменский МГИМО, ноябрь 2009 Спинной мозг
Спинной мозг  Правописание слов с безударными гласными, глухими и звонкими согласными в корне слов - презентация для начальной школы_
Правописание слов с безударными гласными, глухими и звонкими согласными в корне слов - презентация для начальной школы_ 2014 год Выполнила: воспитатель МБДОУ №20 «Сказка»г. Бор Якушева Елена Андреевна.
2014 год Выполнила: воспитатель МБДОУ №20 «Сказка»г. Бор Якушева Елена Андреевна. «Составление основного производственного плана»
«Составление основного производственного плана» 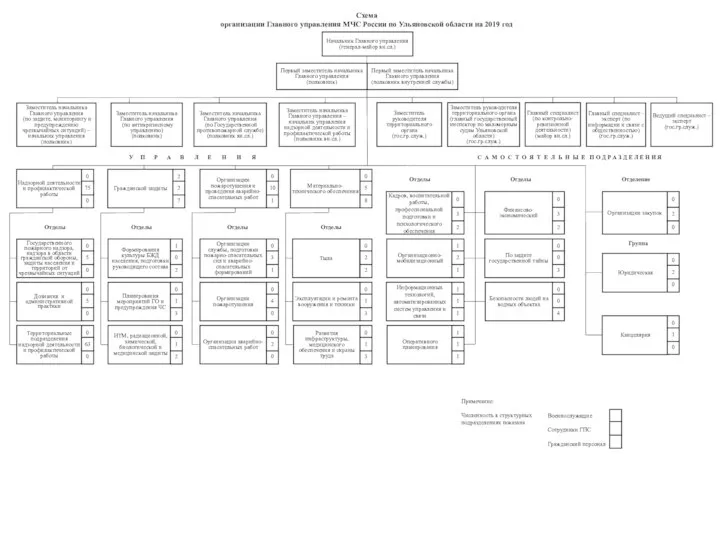 Схема организации Главного управления МЧС России по Ульяновской области на 2019 год
Схема организации Главного управления МЧС России по Ульяновской области на 2019 год Розробка плати балансування та заряду для li-io акумуляторів
Розробка плати балансування та заряду для li-io акумуляторів Национальная система подтверждения соответствия Республики Беларусь. РЕЕСТР
Национальная система подтверждения соответствия Республики Беларусь. РЕЕСТР Честь или участь
Честь или участь Дробященко Наталья Юрьевна Член правления коллегии пенсионных актуариев 5 октября 2006 год
Дробященко Наталья Юрьевна Член правления коллегии пенсионных актуариев 5 октября 2006 год  Разработка реестра ветеранов шахтерского труда с использованием языка веб-программирования PHP и базы данных MySQL
Разработка реестра ветеранов шахтерского труда с использованием языка веб-программирования PHP и базы данных MySQL Существенность в аудите
Существенность в аудите скелет головы
скелет головы ЕГЭ. Игра. История России. Ч. 2.
ЕГЭ. Игра. История России. Ч. 2.