- Развитие концепций и возможностей ОС

Содержание
- 2. Общая картина функционирования компьютерной системы
- 3. Распределение памяти в простой системе пакетной обработки
- 4. Системы пакетной обработки с поддержкой мультипрограммирования
- 5. SMP-архитектура
- 6. Общая структура клиент-серверной системы
- 7. Архитектура компьютерных систем 2/2
- 8. Временной график прерываний процесса, выполняющего вывод
- 9. Два метода ввода-вывода: синхронный и асинхронный
- 10. Таблица состояния устройств
- 11. Устройство диска
- 12. Иерархия устройств памяти
- 13. Использование системного вызова для выполнения ввода-вывода
- 14. Использование базового регистра и регистра границы
- 15. Аппаратная защита адресов памяти
- 16. Передача параметров в таблице
- 17. Исполнение программ в MS-DOS
- 18. Исполнение нескольких программ в UNIX
- 19. Коммуникационные модели Могут реализовываться с помощью общей памяти или передачи сообщений
- 20. Уровни (абстракции) модулей MS-DOS
- 21. Структура системы UNIX
- 22. Уровни абстракции ОС
- 23. Структура уровней абстракции OS/2
- 24. Клиент-серверная структура Windows NT
- 25. Модели ОС без использования виртуальных машин и на основе виртуальных машин
- 26. Виртуальная машина Java
- 27. Диаграмма состояний процесса
- 28. Блок управления процессом (PCB)
- 29. Переключение процессора с одного процесса на другой
- 30. Очередь готовых процессов и очереди для различных устройств ввода-вывода
- 31. Графическое представление диспетчеризации процессов
- 32. Добавление диспетчера выгруженных процессов
- 33. Дерево процессов в системе UNIX
- 34. Ограниченный буфер – реализация с помощью общей памяти Общие данные #define BUFFER_SIZE 1000 /* или другое
- 35. Ограниченный буфер: процесс-производитель item nextProduced; item nextProduced; /* следующий генерируемый элемент */ while (1) { /*
- 36. Ограниченный буфер: процесс-потребитель item nextConsumed; /* следующий используемый элемент */ while (1) { /* бесконечный цикл
- 37. Взаимодействие с помощью сокетов
- 38. Исполнение RPC (C) В.О. Сафонов, 2007
- 39. Удаленный вызов метода (RMI) - Java Remote Method Invocation (RMI) – механизм в Java-технологии, аналогичный RPC
- 40. Выстраивание параметров (marshaling)
- 41. Однопоточные и многопоточные процессы
- 42. Схема модели “много / один”
- 43. Схема модели “один / один”
- 44. Схема модели “много/много”
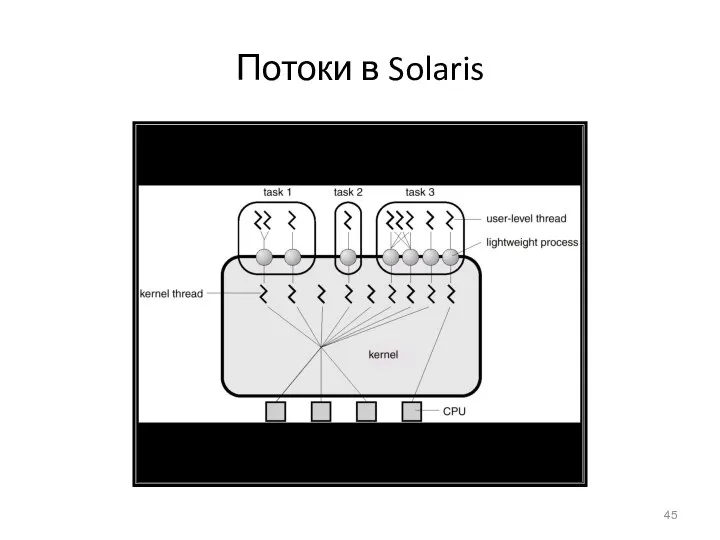
- 45. Потоки в Solaris
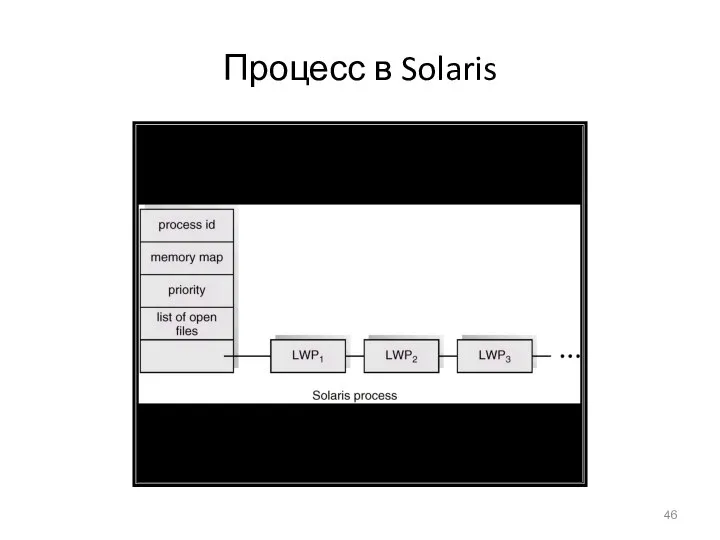
- 46. Процесс в Solaris
- 47. Состояния потоков в Java
- 48. Последовательность активных фаз (bursts) процессора и ввода-вывода
- 49. Гистограмма периодов активности процессора
- 50. Стратегия диспетчеризации First-Come-First-Served (FCFS) Процесс Период активности P1 24 P2 3 P3 3 Пусть порядок процессов
- 51. Стратегия FCFS (продолжение) Пусть порядок процессов таков: P2 , P3 , P1 . Диаграмма Ганта для
- 52. Пример: SJF с опережением Процесс Время появления Время активности P1 0.0 7 P2 2.0 4 P3
- 53. Определение длины следующего периода активности Является лишь оценкой длины. Может быть выполнено с использованием длин предыдущих
- 54. Предсказание длины следующего периода активности
- 55. Примеры экспоненциального усреднения α =0 τn+1 = τn Недавняя история не учитывается. α =1 τn+1 =
- 56. Пример RR (квант времени = 20) Пример RR с квантом времени = 20 Процес Время активности
- 57. Квант времени ЦП и время переключения контекста
- 58. Изменение времени оборота, в зависимости от кванта времени
- 59. Диспетчеризация по принципу многоуровневой очереди
- 60. Многоуровневые аналитические очереди кванты времени 8 (очередь Q0) и 16 (очередь Q1) и пакетными процессами по
- 61. Латентность диспетчера (dispatch latency)– время, требуемое для диспетчера, чтобы остановить один процесс и стартовать другой. Интервал
- 62. Оценка планировщиков ЦП посредством моделирования
- 63. Планирование в Solaris
- 64. Приоритеты в Windows NT 5 и выше
- 65. Ограниченный буфер Имеется общий буфер ограниченной длины. Процесс-производитель добавляет в него сгенерированные элементы, процесс-потребитель использует и
- 66. Ограниченный буфер Процесс-производитель item nextProduced; while (1) { while (counter == BUFFER_SIZE) ; /* do nothing
- 67. Ограниченный буфер Процесс-потребитель item nextConsumed; while (1) { while (counter == 0) ; /* do nothing
- 68. Ограниченный буфер Оператор “count++” может быть реализован на языке ассемблерного уровня как: register1 = counter register1
- 69. Ограниченный буфер Предположим, counter вначале равно 5. Исполнение процессов в совместном режиме (interleaving) приводит к следующему:
- 70. Синхронизация процессов по критическим секциям Рассмотрим проанализированную проблему в общем виде. Пусть имеются n параллельных процессов,
- 71. Первоначальные попытки решения проблемы Есть только два процесса, P0 и P1 Общая структура процесса Pi: do
- 72. Алгоритм 1 Общие переменные: shared int turn; первоначально turn = 0 turn == i ⇒ процесс
- 73. Алгоритм 2 Общие переменные boolean flag[2]; первоначально flag [0] = flag [1] = false. flag [i]
- 74. Алгоритм 3 (Петерсона, 1981) Объединяет общие переменные алгоритмов 1 и 2. Процесс Pi : do {
- 75. Алгоритм булочной (bakery algorithm) алгоритм как бы воспроизводит стратегию автомата в (американской) булочной, где каждому клиенту
- 76. Алгоритм булочной do { choosing[i] = true; number [i] = max (number[0], number[1], …, number[n-1]) +
- 77. Аппаратная поддержка синхронизации Атомарная операция проверки и модификации значения переменной TestAndSet, которая атомарно выполняет считывание и
- 78. Взаимное исключение с помощью TestAndSet Общие данные: boolean lock = false; Процесс Pi do { while
- 79. Аппаратное решение для синхронизации Атомарная перестановка значений двух переменных. Другое распространенное аппаратное решение для синхронизации –
- 80. Взаимное исключение с помощью Swap Общие данные (инициализируемые false): boolean lock; boolean waiting[n]; Процесс Pi do
- 81. Общие семафоры – counting semaphores (по Э. Дейкстре) Семафо́р — объект, позволяющий войти в заданный участок
- 82. Критическая секция для N процессов Общие данные: semaphore mutex; //initially mutex = 1 Процесс Pi: do
- 83. Реализация семафора Семафор, по существу, является структурой из двух полей – целого значения и указателя на
- 84. Реализация Определим семафорные операции следующим образом: wait(S): S.value--; if (S.value добавить текущий процесс к S.L; block;
- 85. Семафоры как общее средство синхронизации Исполнить действие B в процессе Pj только после того, как действие
- 86. Реализация общего семафора S с помощью двоичных семафоров Структуры данных: binary-semaphore S1, S2; int C: Инициализация:
- 87. Реализация операций над семафором S Операция wait: wait(S1); C--; if (C signal(S1); wait(S2); } signal(S1); Операция
- 88. Задача “ограниченный буфер” ограниченный буфер:имеются процесс-производитель и процесс-потребитель, взаимодействующие с помощью циклического буфера ограниченной длины; производитель
- 89. Процесс-производитель ограниченного буфера do { … сгенерировать элемент в nextp … wait(empty); wait(mutex); … добавить nextp
- 90. Процесс-потребитель ограниченного буфера do { wait(full) wait(mutex); … взять (и удалить) элемент из буфера в nextc
- 91. Задача “читатели-писатели” Суть задачи читатели-писатели в следующем: имеется общий ресурс и две группы процессов: читатели (которые
- 92. Процесс-писатель wait(wrt); … выполняется запись … signal(wrt); Процесс-читатель, во-первых, должен увеличить значение readcount, причем обеспечить взаимное
- 93. Процесс-читатель wait(mutex); readcount++; if (readcount == 1){ wait(rt); } signal(mutex); … выполняется чтение … wait(mutex); readcount--;
- 94. Задача “обедающие философы” Общие данные При решении задачи будем использовать массив семафоров chopstick, описывающий текущее состояние
- 95. Задача “обедающие философы” Имеется круглый стол, за которым сидят пять философов (впрочем, их число принципиального значения
- 96. Пример: ограниченный буфер Общие данные: struct buffer { int pool[n]; int count, in, out; } Критические
- 97. Процесс-производитель Процесс-производитель добавляет nextp к общему буферу region buffer when (count проверка переполнения буфера выполняется при
- 98. Процесс-потребитель Процесс-потребитель удаляет элемент из буфера и запоминает его в nextc region buffer when (count >
- 99. Реализация оператора region x when B do S Свяжем с общей переменной x следующие переменные: semaphore
- 100. Мониторы (C. A. R. Hoare) Высокоуровневая конструкция для синхронизации, которая позволяет синхронизировать доступ к абстрактному типу
- 101. Мониторы: условные переменные Для реализации ожидания процесса внутри монитора, вводятся условные переменные: condition x, y; Условные
- 102. Схематическое представление монитора
- 103. Монитор с условными переменными
- 104. Синхронизации Синхронизация в ОС Solaris Система Solaris предоставляет разнообразные виды блокировщиков для поддержки многозадачности, многопоточности (включая
- 105. Пример: обедающие философы monitor dp { enum {thinking, hungry, eating} state[5]; condition self[5]; void pickup(int i)
- 106. Обедающие философы: реализация операций pickup и putdown void pickup(int i) { state[i] = hungry; test[i]; if
- 107. Обедающие философы: реализация операции test void test(int i) { if ( (state[(i + 4) % 5]
- 108. Реализация мониторов с помощью семафоров Используем семафоры mutex – для взаимного исключения процессов, next –для реализации
- 109. Реализация мониторов Для каждой условной переменной x: semaphore x-sem; // (initially = 0) int x-count =
- 110. Реализация мониторов Реализация операции x.signal: if (x-count > 0) { next-count++; signal(x-sem); wait(next); next-count--; } Таким
- 111. Тупики Модель системы Для описания и исследования подобных ситуаций введем формальную модель системы в общем виде.
- 112. Граф распределения ресурсов Множество вершин V и множество дуг E. V подразделяется на два типа вершин:
- 113. Граф распределения ресурсов (продолжение) Процесс Тип ресурса, имеющий 4 экземпляра Pi запрашивает экземпляр ресурса Rj Pi
- 114. Пример графа распределения ресурсов Данный граф изображает систему с тремя процессами и четырьмя видами ресурсов: ресурсы
- 115. Граф распределения ресурсов с тупиком Имеется ситуация циклического ожидания между процессами 1, 2 и 3. Процесс
- 116. Граф распределения ресурсов с циклом, но без тупика В данном случае ( имеется четыре процесса и
- 117. Если граф распределения ресурсов не содержит циклов, то в системе тупиков нет; Если граф распределения ресурсов
- 118. Предотвращение тупиков Основная идея – ограничить методы запросов ресурсов со стороны процессов. Чтобы ограничить возможность взаимного
- 119. Избежание тупиков Методы избежания тупиков требуют, чтобы система обладала дополнительной априорной информацией о процессе и его
- 120. Безопасное состояние системы Б С назовем такое состояние, перевод системы в которое не приведет к появлению
- 121. Граф распределения ресурсов для стратегии избежания тупиков Для реализ стратегии ИТ к данному графу необходимо добавить
- 122. Небезопасное состояние на графе распределения ресурсов
- 123. Алгоритм банкира Алгоритм банкира для безопасного распределения ресурсов операционной системой (с избежанием тупиков) был предложен Э.
- 124. Алгоритм безопасности 1.Пусть Work и Finish – векторы длин m и n, соответственно. Инициализация: Work =
- 125. Алгоритм запроса ресурсов для процесса Pi Request = вектор запросов для процесса Pi. Если Requesti [j]
- 126. Пример (продолжение) Состояние матрицы. Need определяется как (Max – Allocation). Need A B C P0 7
- 127. Пример (продолжение). Запрос процесса P1: (1,0,2) Проверяем, что Request ≤ Available, то есть, (1,0,2) ≤ (3,3,2)
- 128. Случай, когда каждый тип ресурса имеет единственный экземпляр Строим и поддерживаем wait-for граф Вершины - процессы.
- 129. Граф распределения ресурсов и граф wait-for
- 130. Случай, когда ресурсы существуют в нескольких экземплярах для каждого типа Available: Вектор длины m; указывает наличие
- 131. Алгоритм обнаружения тупиков Пусть Work и Finish – векторы длин m и n, соответственно. 1. Инициализация:
- 132. Алгоритм обнаружения: пример Пусть имеются пять процессов P0 - P4 и три типа ресурсов A (7
- 133. Алгоритм обнаружения: продолжение P2 запрашивает дополнительный ресурс типа C. Запрос A B C P0 0 0
- 134. Восстановление после тупика Для выхода из тупика, очевидно, система должна прекратить все заблокированные процессы и освободить
- 135. Управление памятью Основные положения размещения процессов в памяти Любая прога,введ в сист, д.б. размещ в памяти
- 136. Многоэтапная обработка пользовательской программы
- 137. Исходный код программы (в форме текстового файла) на языке высокого уровня или на ассемблере преобразуется компилятором
- 138. Логическое и физическое адресное пространство Концепция логического адресного пространства, связанного с соответствующим физическим адресным пространством, является
- 139. Динамическое перемещение с использованием регистра перемещения
- 140. Динамическая загрузка и динамическая линковка Под динамической загрузкой понимается загрузка подпрограммы в память при первом обращении
- 141. Оверлейная структура для двухпросмотрового ассемблера специальный системный механизм, называемый оверлейная структура (overlay) - организация программы при
- 142. Схема откачки и подкачки Откачка и подкачка (swapping) – это действия операционной системы по откачке (записи)
- 143. Аппаратная поддержка регистров перемещения и границы Смежное распределение памяти Основная память разбивается на две смежных части
- 144. Фрагментация Фрагментация – это дробление памяти на мелкие не смежные свободные области маленького размера. Фрагментация возникает
- 145. Архитектура трансляции адресов адрес обрабатывается системой как структура (p, d):его старшие разряды обозначают номер страницы, младшие
- 146. Пример страничной организации в отличие от непрерывной логической памяти процесса, соотв фреймы стр в осн памяти
- 147. Список свободных фреймов
- 148. Аппаратная поддержка страничной организации: TLB Использование ассоциативной памяти.Таблица страниц – непрерыв область физической памяти. В системе
- 149. Эффективное время поиска (effective access time – EAT) Ассоциативный поиск = ε единиц времени Предположим, что
- 150. Бит valid/invalid в таблице страниц Защита памяти При адресации с пом стран организ возможно, что логич
- 151. Схема двухуровневых таблиц страниц
- 152. Схема адресной трансляции
- 153. Хешированная таблица страниц
- 154. Архитектура инвертированной таблицы страниц
- 155. Пример: разделяемые страницы
- 156. Программа с точки зрения пользователя
- 157. Архитектура сегментной организации памяти Логический адрес ~ пара: , Таблица сегментов – служит для отображения логических
- 158. Аппаратная поддержка сегментного распределения памяти
- 159. Пример сегментной организации памяти
- 160. Совместное использование сегментов
- 161. Схема трансляции адресов в MULTICS
- 162. Трансляция адресов в Intel 386
- 163. Виртуальная память больше, чем физическая память
- 164. Преобразование страничной памяти в непрерывное дисковое пространство
- 165. Пример таблицы страниц, в которой не все страницы присутствуют в памяти
- 166. Этапы обработки ситуации отсутствия страницы в памяти
- 167. Оценка производительности стратегии обработки страницы по требованию Коффициент отказов страниц (Page Fault Rate) 0 ≤ p
- 168. Файлы, отображаемые в память
- 169. Пример: замещение страниц
- 170. Замещение страниц
- 171. График зависимости числа отказов страниц от числа фреймов
- 172. Алгоритм FIFO (First-in-First-Out) Наиболее простой алгоритм замещения страниц – в качестве жертвы всегда выбирается фрейм, первым
- 173. Пример замещения страниц по алгоритму FIFO
- 174. Аномалия Belady при использовании алгоритма FIFO замещения страниц
- 175. Алгоритм Least Recently Used (LRU) Замещается та страница, которая раньше всего использовалась. Строка запросов: 1, 2,
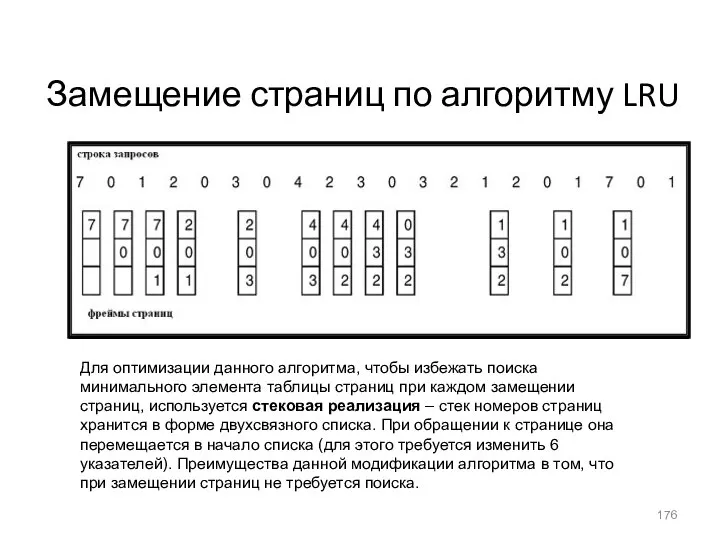
- 176. Замещение страниц по алгоритму LRU Для оптимизации данного алгоритма, чтобы избежать поиска минимального элемента таблицы страниц
- 177. Использование стека для хранения информации о самых недавних обращениях к страницам
- 178. Алгоритмы, близкие к LRU Имеется несколько алгоритмов, близких к алгоритму LRU, в которых реализованы различные идеи
- 179. Алгоритм второго шанса Данный алгоритм имеет след эвристическое обоснование. Странице, кот дольше всего не исп, ей
- 180. Фиксированное выделение Равномерное распределение – например, если имеется 100 фреймов и 5 процессов, каждому выделяется по
- 181. Thrashing Если процессу не выделено достаточное число страниц, коэффициент отказов страниц очень высок. Это приводит к
- 182. Модель рабочего множества thrashing происходит, если сумма размеров локальных потребностей процессов в основной памяти больше общего
- 183. Модель рабочего множества
- 184. Атрибуты файлов Имя (Name) – информация в символьной форме, воспринимаемая человеком. Тип (Type) – необходим для
- 185. Операции над файлом Создание - Create Запись - Write Чтение - Read Поиск позиции внутри файла
- 186. Типы файлов – имя и расширение
- 187. Методы доступа к файлам Последовательный доступ read next write next reset rewrite Прямой доступ read n
- 188. Файл последовательного доступа
- 189. Моделирование последовательного доступа для файла с прямым доступом
- 190. Пример индексного файла и файла, представляющего отношение (relative file)
- 191. Типичная организация файловой системы
- 192. Одноуровневая организация для всех пользователей – проблемы с группировкой и именованием
- 193. Двухуровневая организация Имя пути Возможность иметь одинаковые имена файлов для различных пользователей Эффективный поиск Нет возможности
- 194. Древовидная структура директорий
- 195. Структура директорий в виде ациклического графа (с разделяемыми директориями и файлами)
- 196. Структура директорий в виде произвольного графа
- 197. Дерево смонтированных систем (а) и еще не смонтированная файловая система (b)
- 198. Точка монтирования
- 199. Защита (protection) Создатель файла должен иметь возможность управлять: Списком допустимых операций над файлом Списком пользователей, которым
- 200. Списки доступа и группы (UNIX) Режимы доступа: read, write, execute Три класса пользователей: RWX a) owner
- 201. Типичная структура блока управления файлом
- 202. Схема организации виртуальной файловой системы
- 203. Смежное размещение файла на диске
- 204. Ссылочное размещение файла
- 205. File Allocation Table (FAT)
- 206. Пример индексируемого размещения
- 207. Управление свободной памятью Битовый вектор (n блоков) … 0 1 2 n-1 bit[i] = 0
- 208. Управление свободной памятью (прод.) Битовые шкалы требуют дополнительной памяти. Пример: размер блока = 212 байтов размер
- 209. Связанный список свободной дисковой памяти
- 210. Различные методы размещения кэша для диска
- 211. Ввод-вывод без унифицированной буферной кэш-памяти
- 212. Ввод-вывод с использованием унифицированной буферной кэш-памяти
- 213. Три независимых файловых системы
- 214. Типовая структура шины ПК IDE – типовой интерфейс для подключения внутри корпуса компьютера через шлейфы внутренних
- 215. Расположение портов для устройств на ПК (частично)
- 216. Опрос устройств (polling) Определяет состояние устройства command-ready – готово к выполнению команд; busy – занято; error
- 217. Цикл ввода-вывода, управляемого прерываниями
- 218. Вектор прерываний (событий) в процессоре Intel Pentium Вектор прерываний – резидентный массив, содержащий адреса обработчиков прерываний
- 219. Процесс выполнения DMA (Direct Memory Access) при трад организации i/o контроллер устр-ва исп собст буф память,
- 220. Структура модулей ввода-вывода в ядре Более низкий уровень, уровень драйверов устройств, скрывает различия между контроллерами ввода-вывода
- 221. Характеристики устройств ввода-вывода
- 222. Структура модулей ввода-вывода в ядре UNIX
- 223. Жизненный цикл запроса на ввод-вывод процесс чтения из дискового файла состоит из следующих этапов: -Определяется устройство,
- 224. Взаимодействие между компьютерами Для повышения производительности ввода-вывода и сетевого взаимодействия в системе необходимо: -Сократить число контекстных
- 226. Скачать презентацию
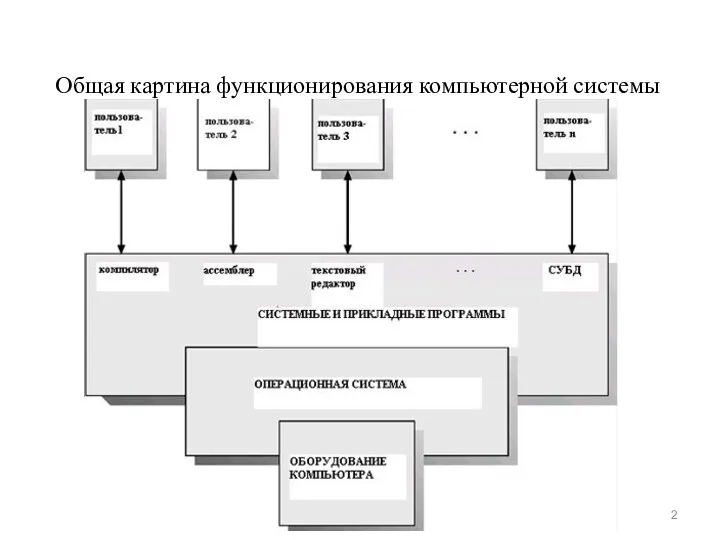
Общая картина функционирования компьютерной системы
Общая картина функционирования компьютерной системы
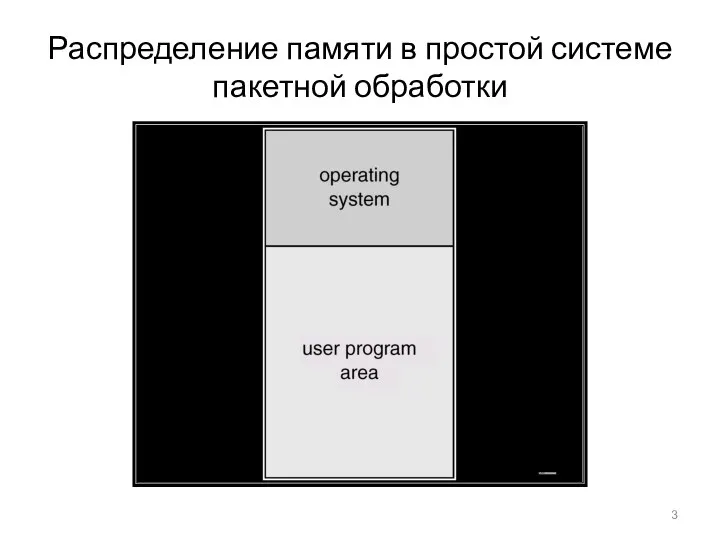
Распределение памяти в простой системе пакетной обработки
Распределение памяти в простой системе пакетной обработки

Системы пакетной обработки с поддержкой мультипрограммирования
Системы пакетной обработки с поддержкой мультипрограммирования
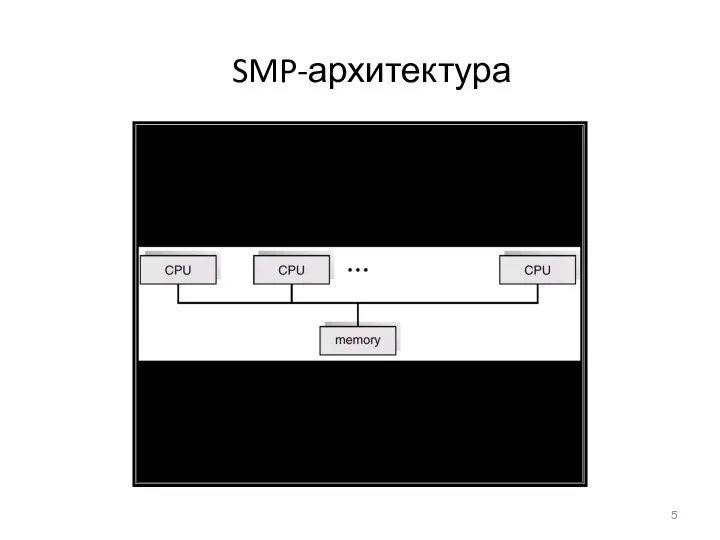
SMP-архитектура
SMP-архитектура
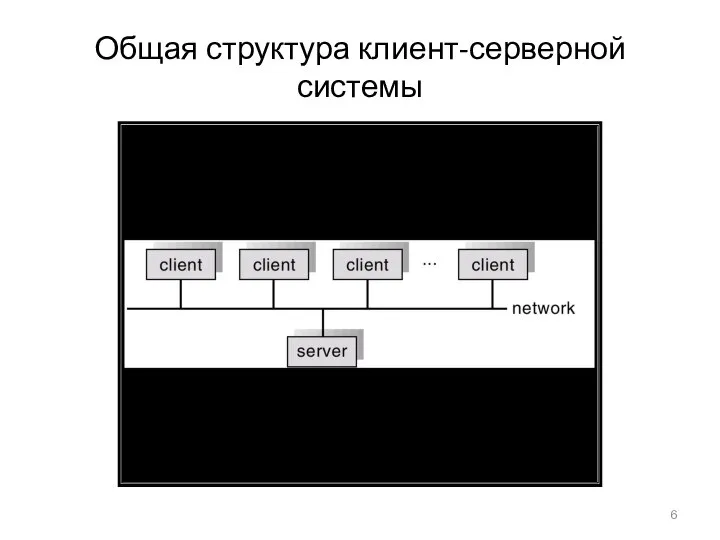
Общая структура клиент-серверной системы
Общая структура клиент-серверной системы
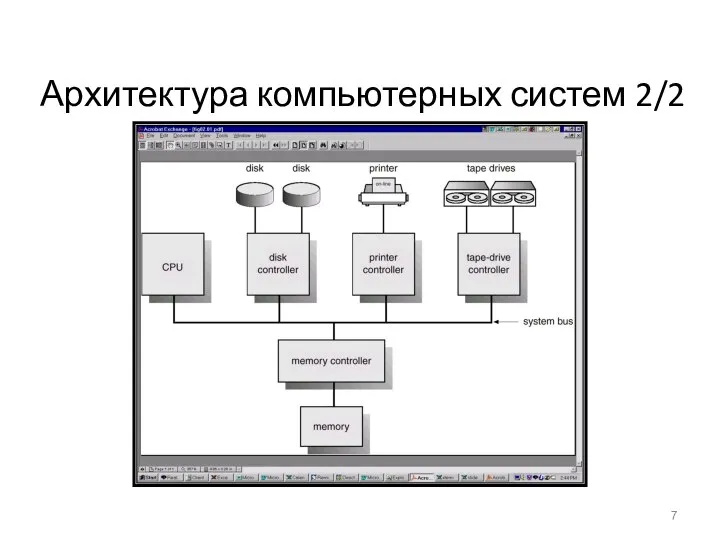
Архитектура компьютерных систем 2/2
Архитектура компьютерных систем 2/2
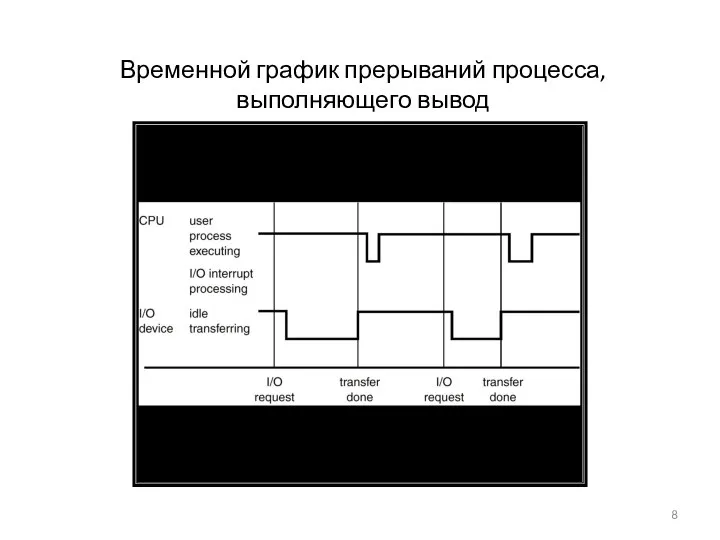
Временной график прерываний процесса, выполняющего вывод
Временной график прерываний процесса, выполняющего вывод
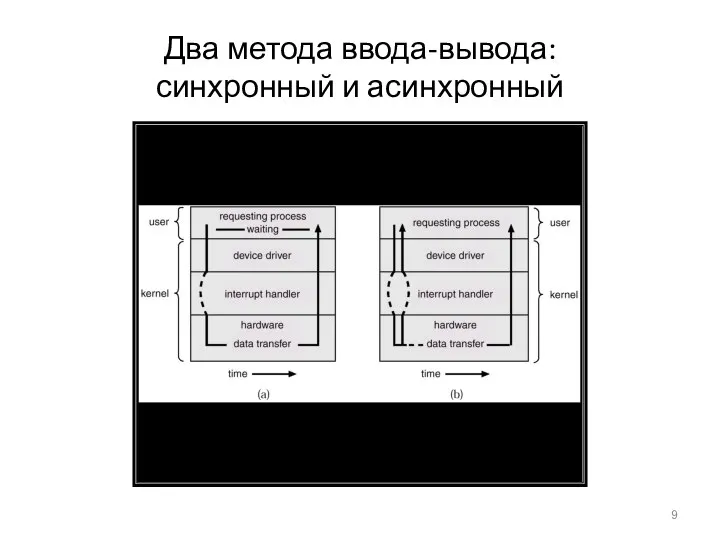
Два метода ввода-вывода:
синхронный и асинхронный
Два метода ввода-вывода:
синхронный и асинхронный
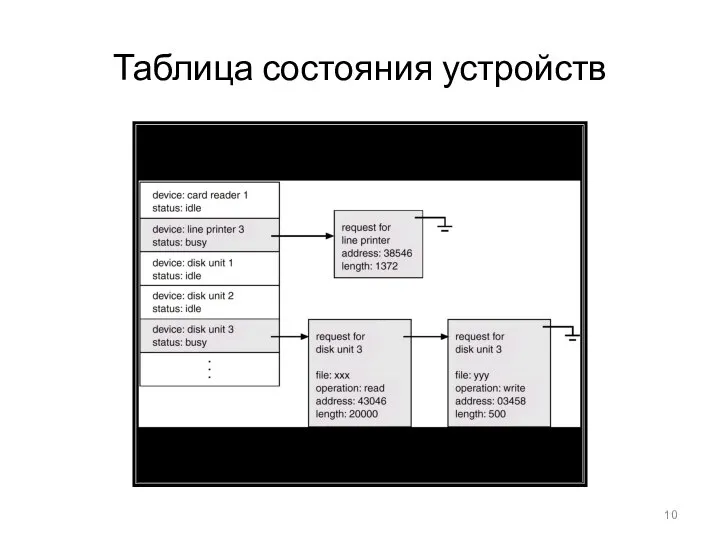
Таблица состояния устройств
Таблица состояния устройств
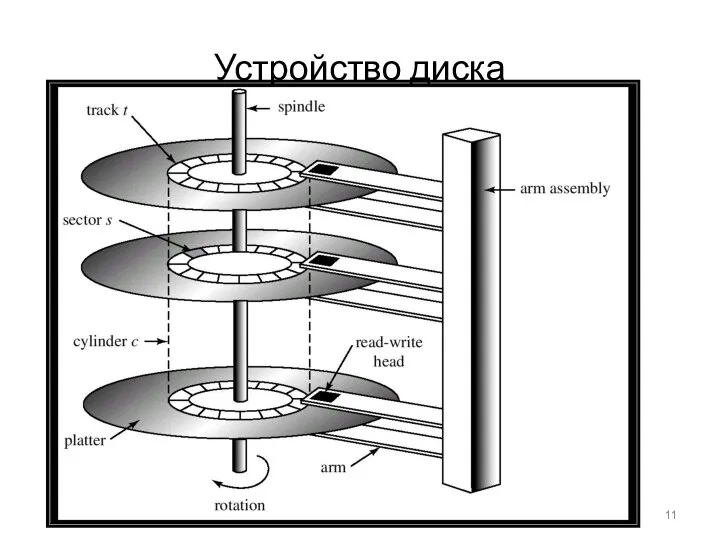
Устройство диска
Устройство диска
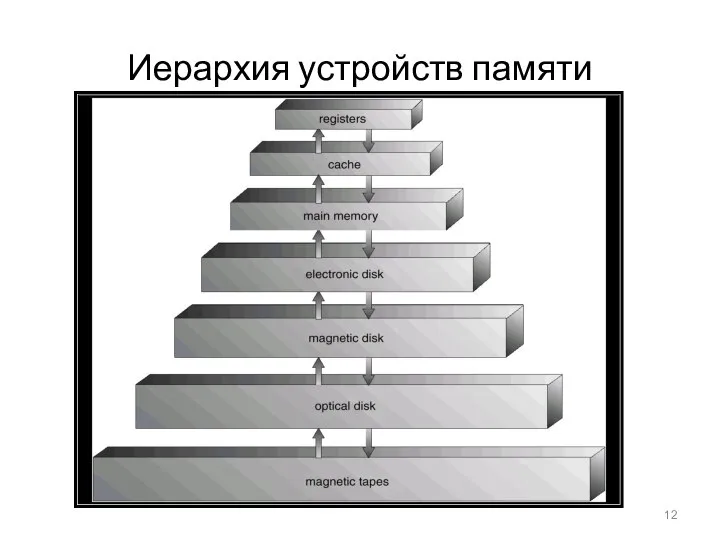
Иерархия устройств памяти
Иерархия устройств памяти
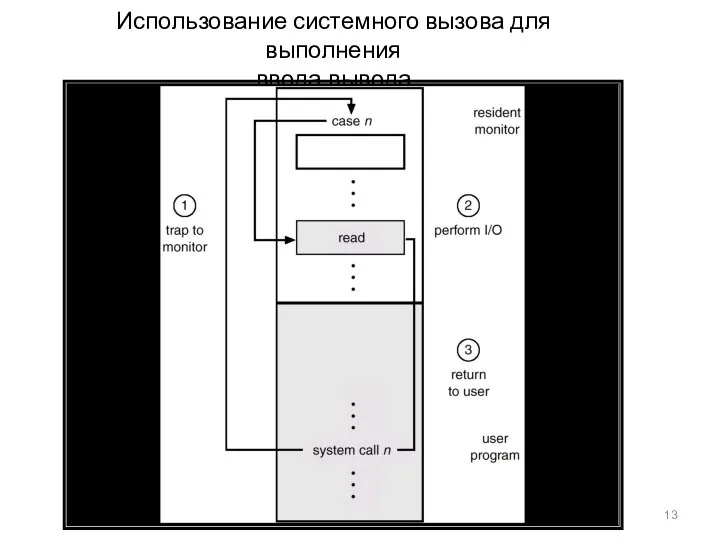
Использование системного вызова для выполнения
ввода-вывода
Использование системного вызова для выполнения
ввода-вывода
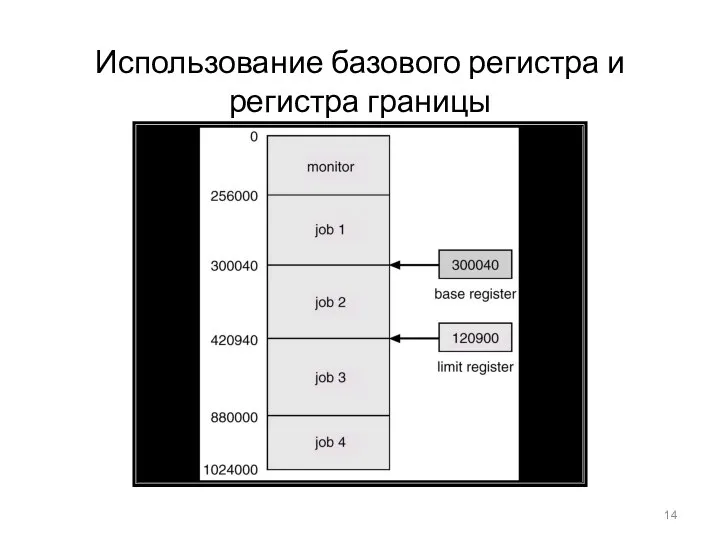
Использование базового регистра и регистра границы
Использование базового регистра и регистра границы
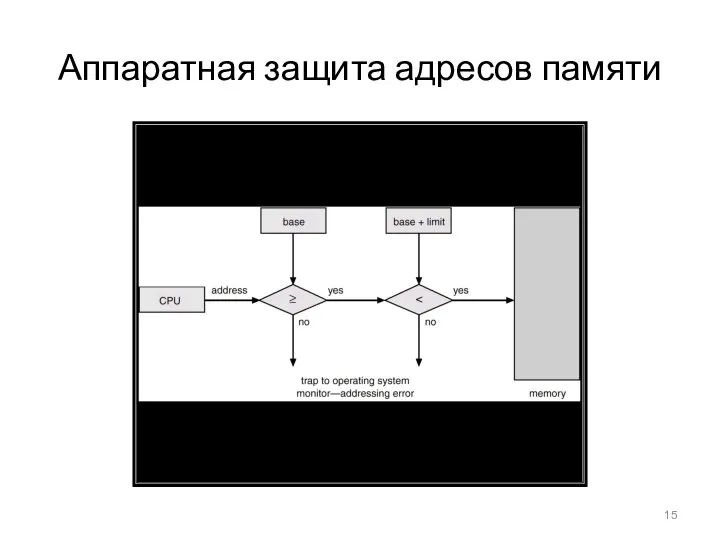
Аппаратная защита адресов памяти
Аппаратная защита адресов памяти
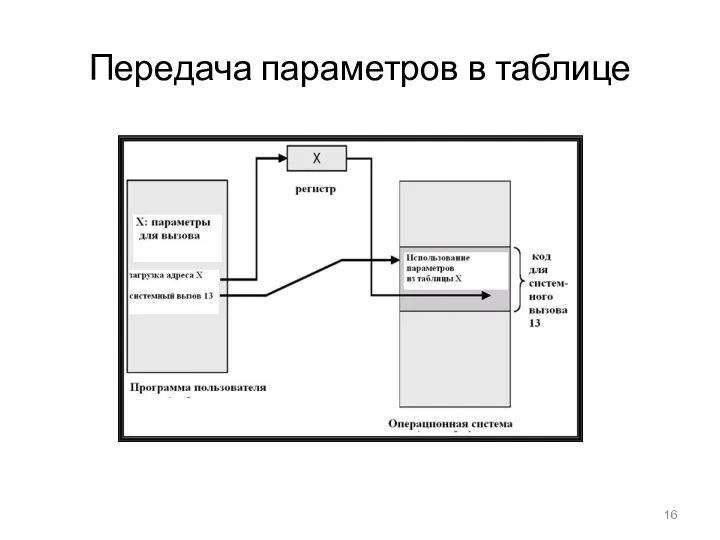
Передача параметров в таблице
Передача параметров в таблице
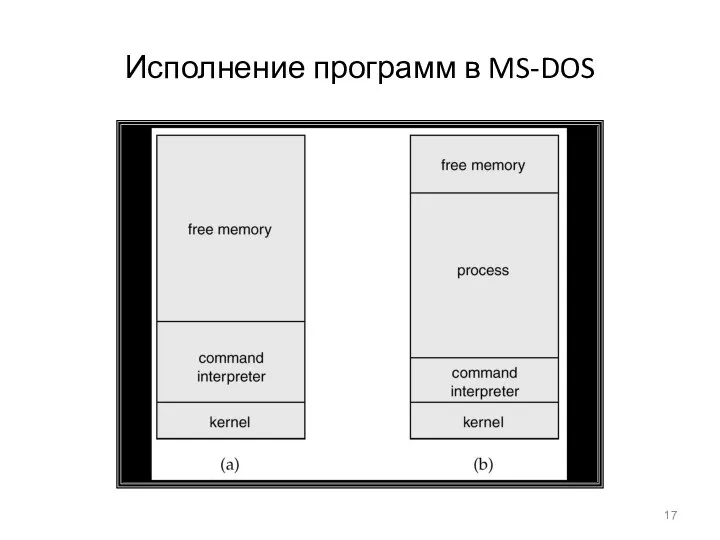
Исполнение программ в MS-DOS
Исполнение программ в MS-DOS
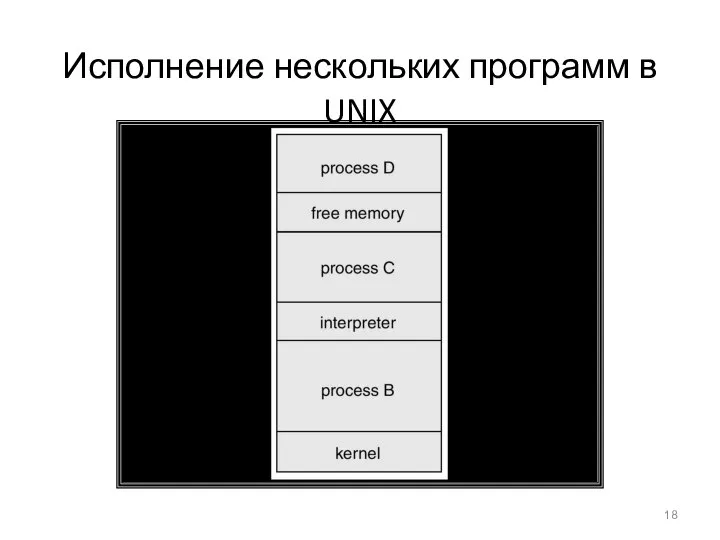
Исполнение нескольких программ в UNIX
Исполнение нескольких программ в UNIX
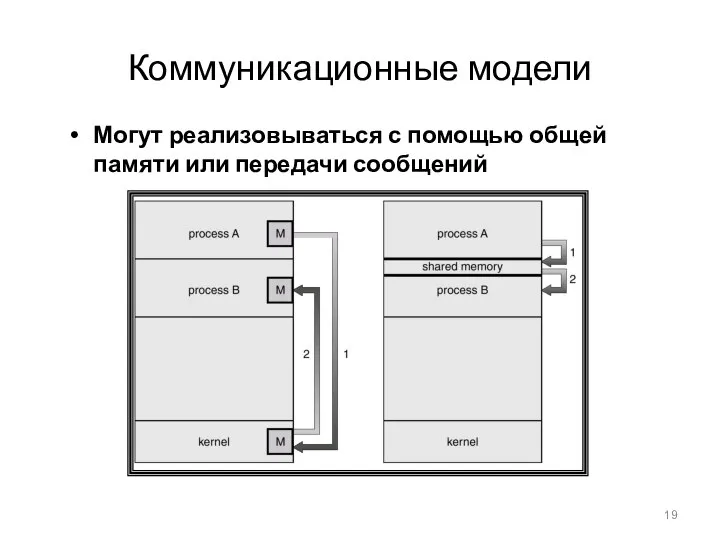
Коммуникационные модели
Могут реализовываться с помощью общей памяти или передачи сообщений
Коммуникационные модели
Могут реализовываться с помощью общей памяти или передачи сообщений
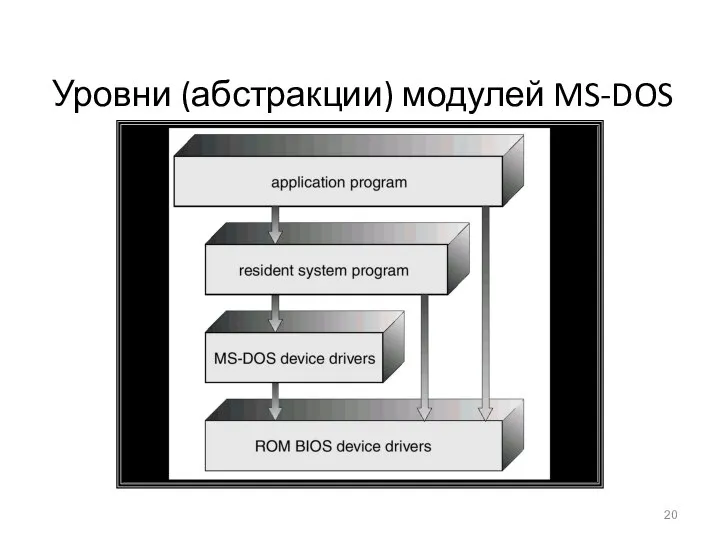
Уровни (абстракции) модулей MS-DOS
Уровни (абстракции) модулей MS-DOS

Структура системы UNIX
Структура системы UNIX
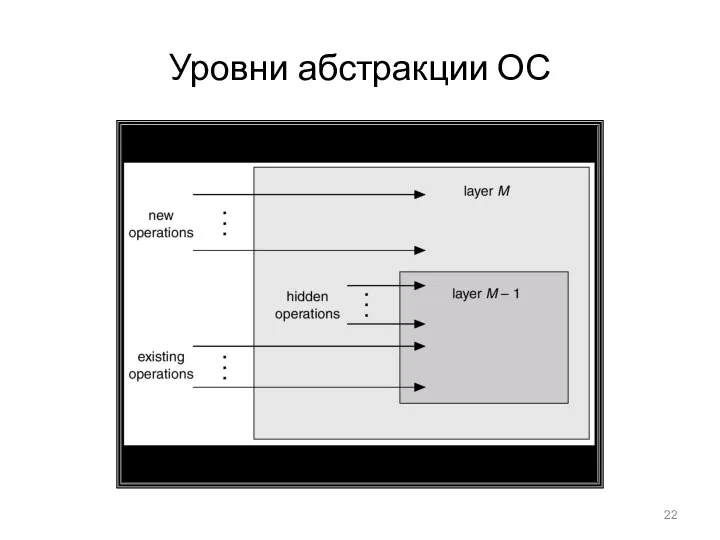
Уровни абстракции ОС
Уровни абстракции ОС
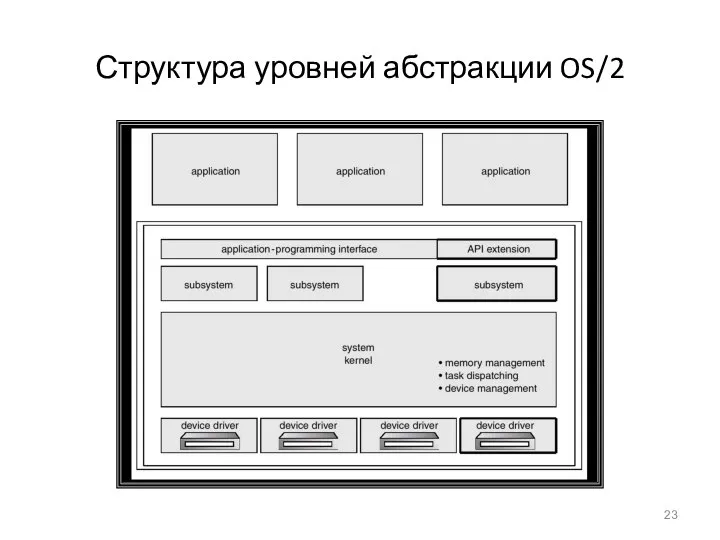
Структура уровней абстракции OS/2
Структура уровней абстракции OS/2
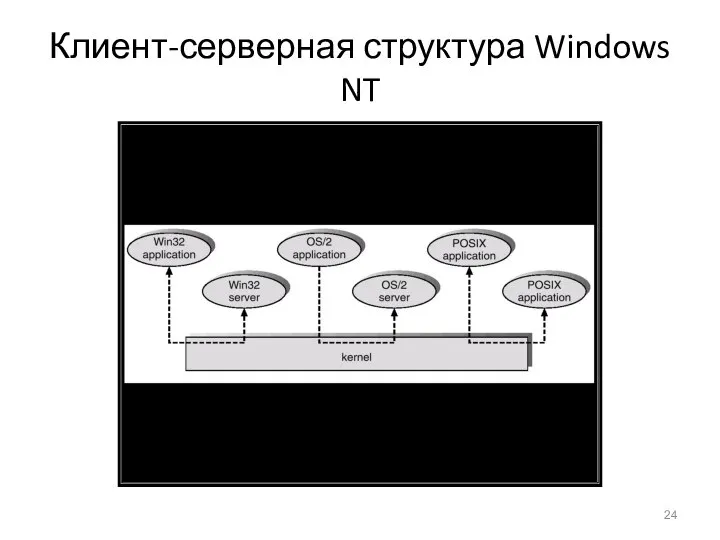
Клиент-серверная структура Windows NT
Клиент-серверная структура Windows NT
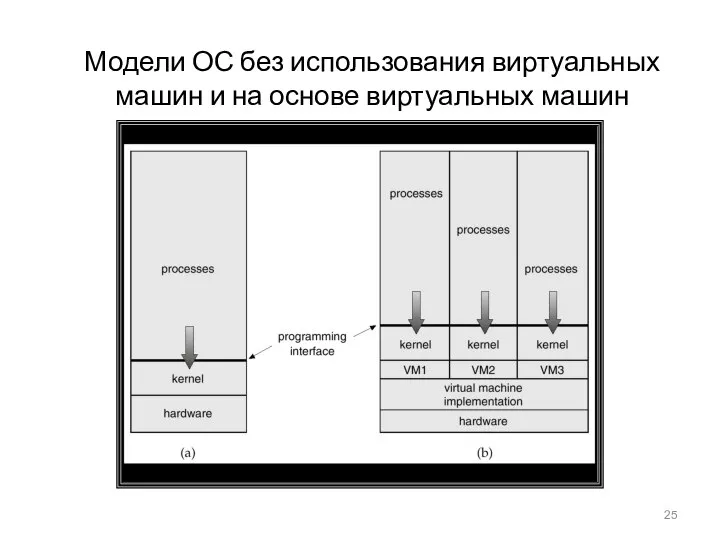
Модели ОС без использования виртуальных машин и на основе виртуальных машин
Модели ОС без использования виртуальных машин и на основе виртуальных машин
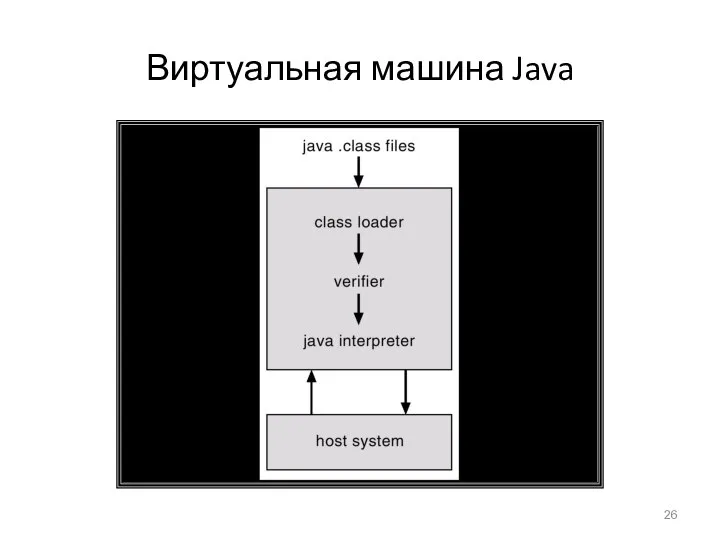
Виртуальная машина Java
Виртуальная машина Java
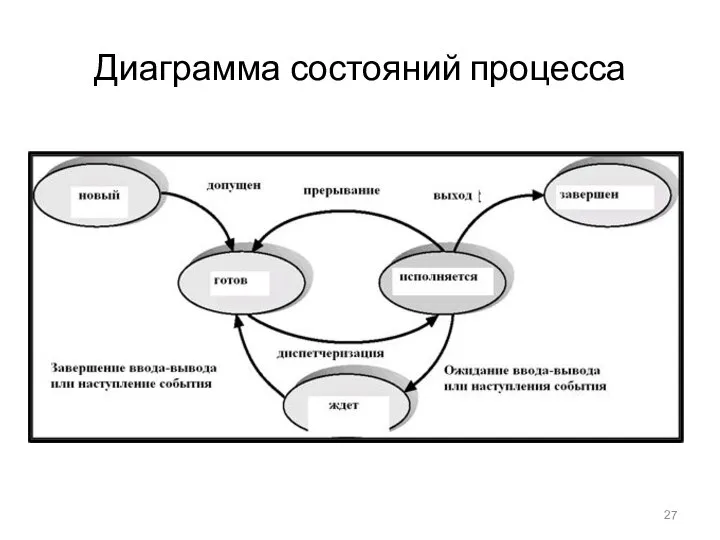
Диаграмма состояний процесса
Диаграмма состояний процесса
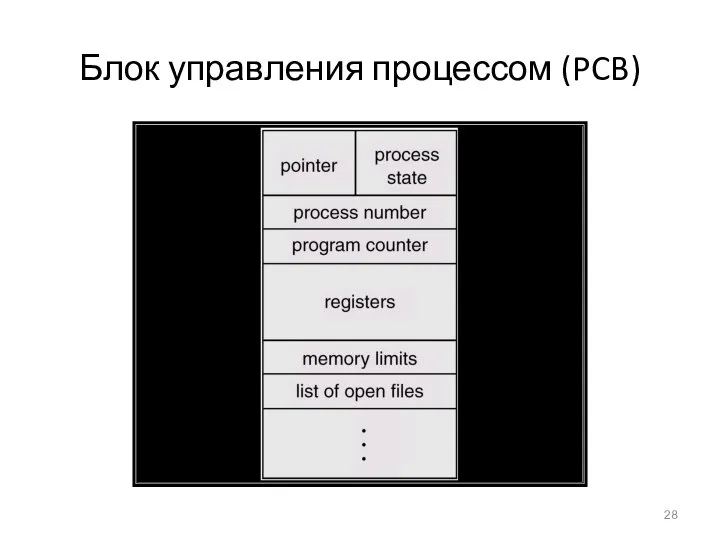
Блок управления процессом (PCB)
Блок управления процессом (PCB)
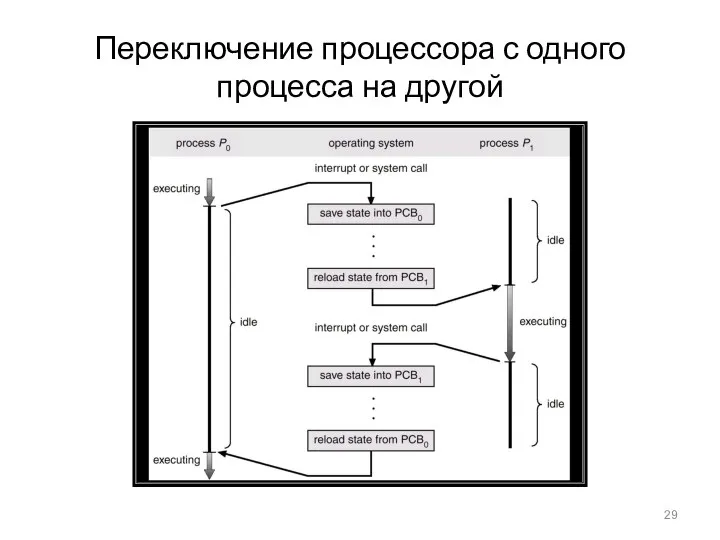
Переключение процессора с одного процесса на другой
Переключение процессора с одного процесса на другой
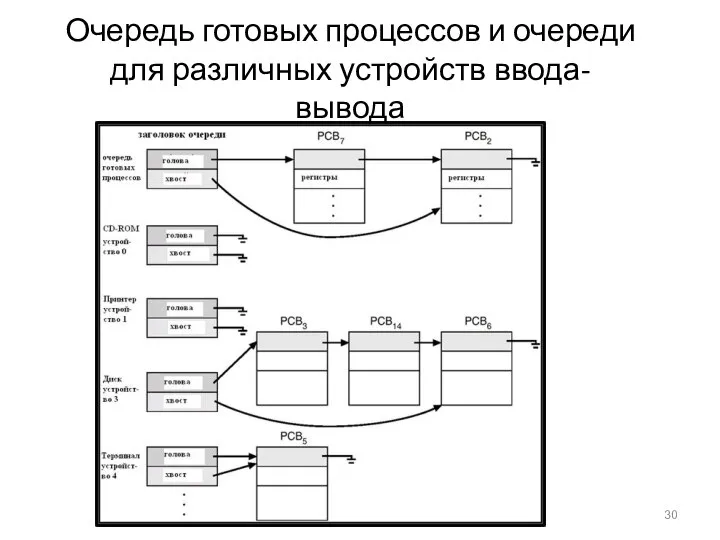
Очередь готовых процессов и очереди для различных устройств ввода-вывода
Очередь готовых процессов и очереди для различных устройств ввода-вывода
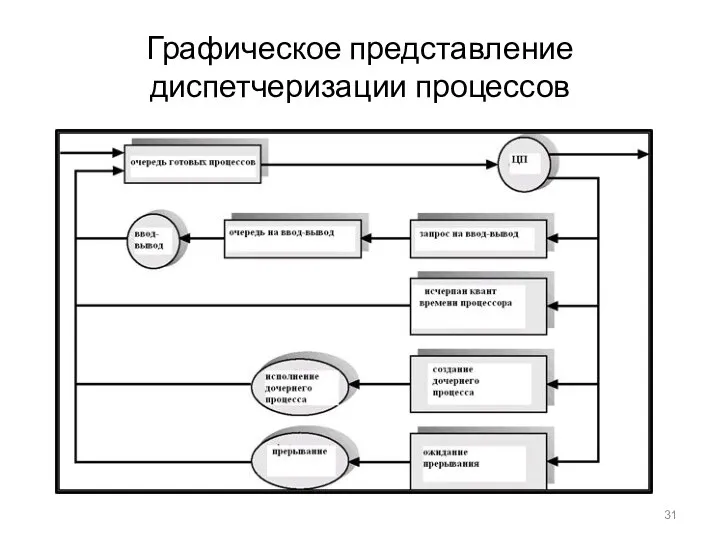
Графическое представление диспетчеризации процессов
Графическое представление диспетчеризации процессов
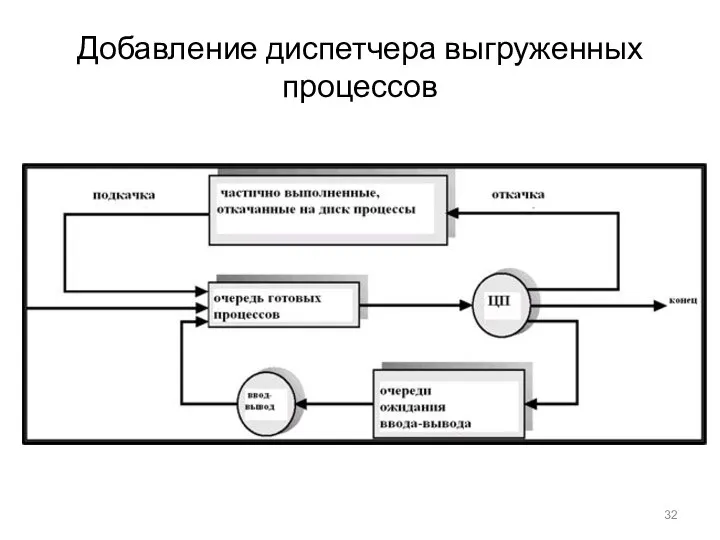
Добавление диспетчера выгруженных процессов
Добавление диспетчера выгруженных процессов
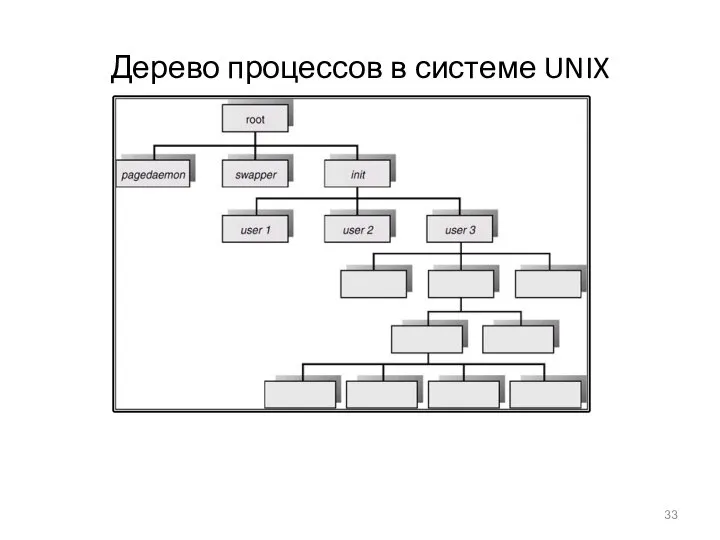
Дерево процессов в системе UNIX
Дерево процессов в системе UNIX

Ограниченный буфер – реализация с помощью общей памяти
Общие данные
#define BUFFER_SIZE 1000
Ограниченный буфер – реализация с помощью общей памяти
Общие данные
#define BUFFER_SIZE 1000

Ограниченный буфер: процесс-производитель
item nextProduced;
item nextProduced; /* следующий генерируемый элемент */
while
Ограниченный буфер: процесс-производитель
item nextProduced;
item nextProduced; /* следующий генерируемый элемент */
while

Ограниченный буфер: процесс-потребитель
item nextConsumed; /* следующий используемый элемент */
while (1)
Ограниченный буфер: процесс-потребитель
item nextConsumed; /* следующий используемый элемент */
while (1)
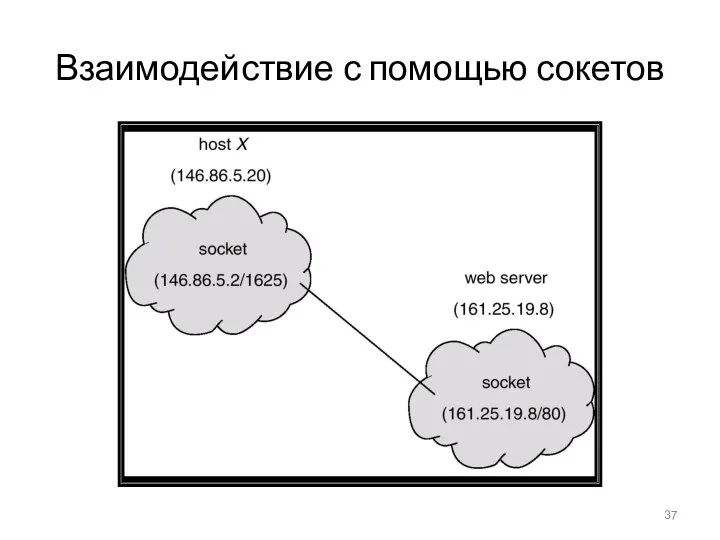
Взаимодействие с помощью сокетов
Взаимодействие с помощью сокетов
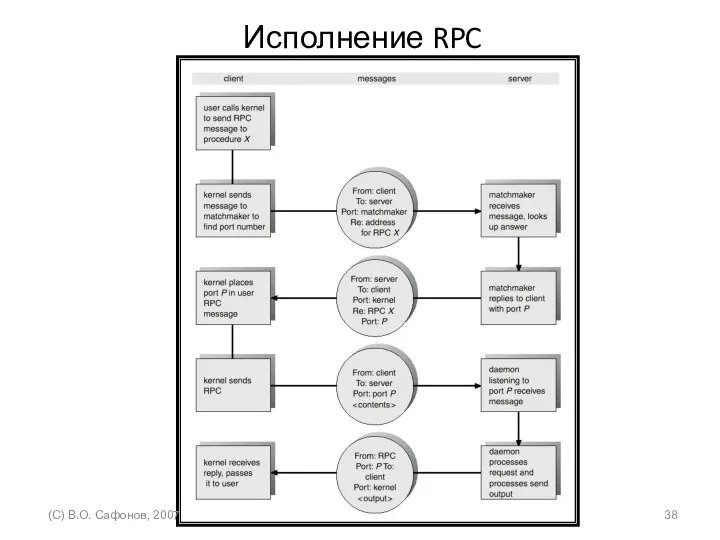
Исполнение RPC
(C) В.О. Сафонов, 2007
Исполнение RPC
(C) В.О. Сафонов, 2007
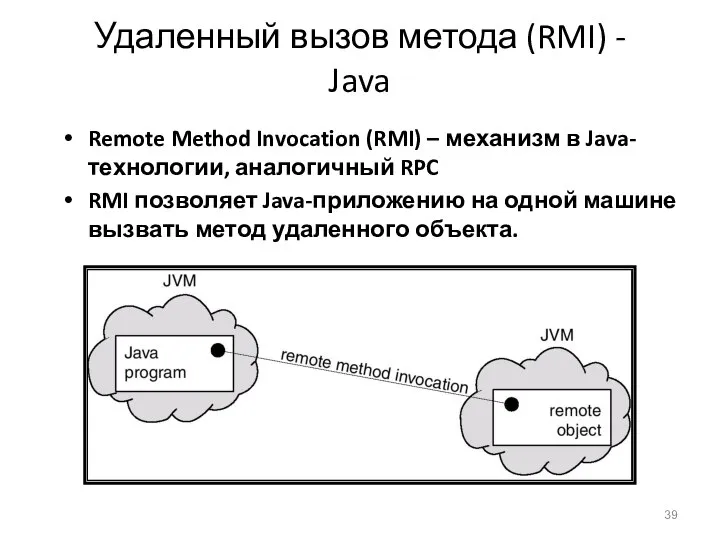
Удаленный вызов метода (RMI) - Java
Remote Method Invocation (RMI) – механизм
Удаленный вызов метода (RMI) - Java
Remote Method Invocation (RMI) – механизм
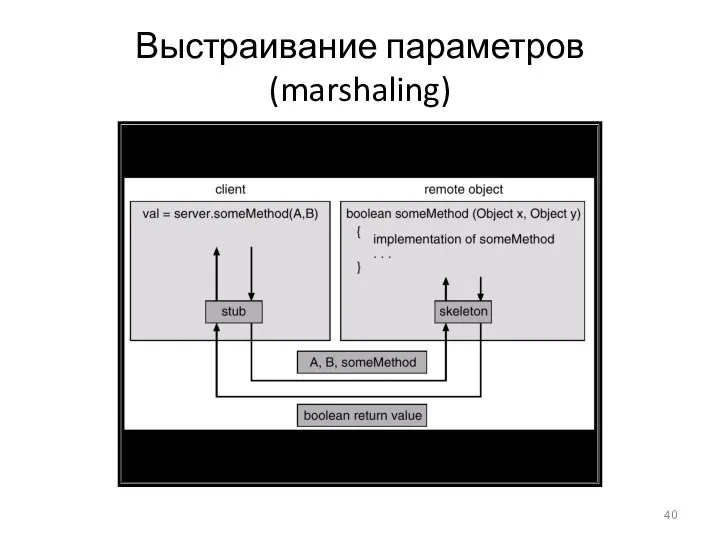
Выстраивание параметров (marshaling)
Выстраивание параметров (marshaling)
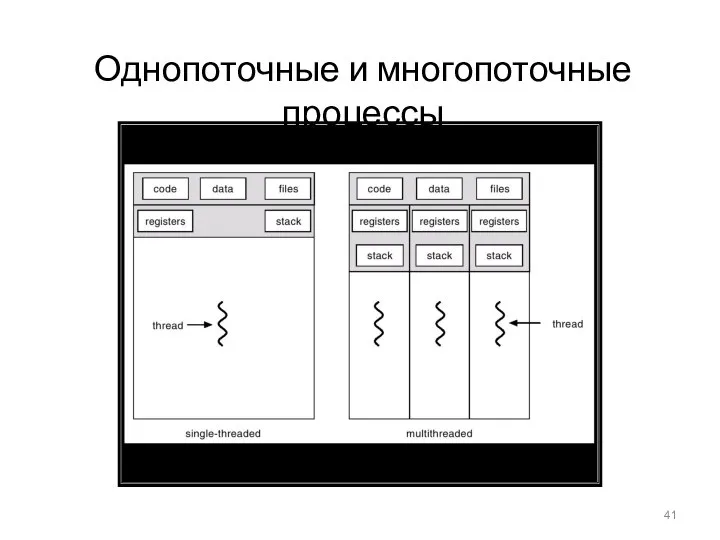
Однопоточные и многопоточные процессы
Однопоточные и многопоточные процессы
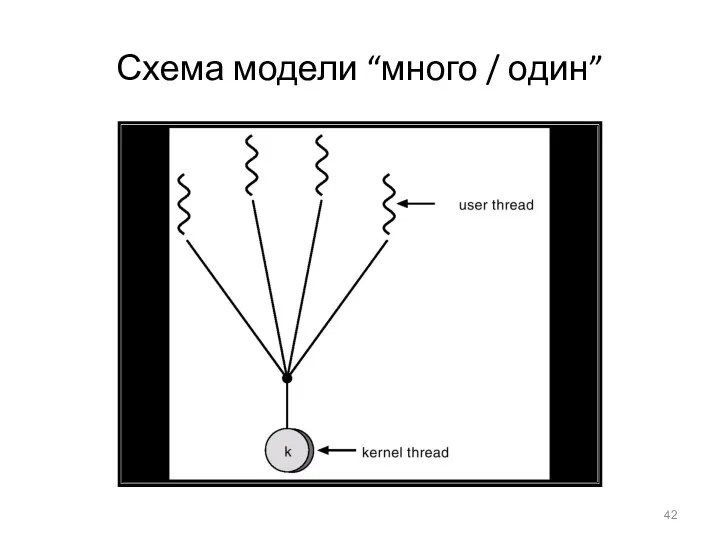
Схема модели “много / один”
Схема модели “много / один”
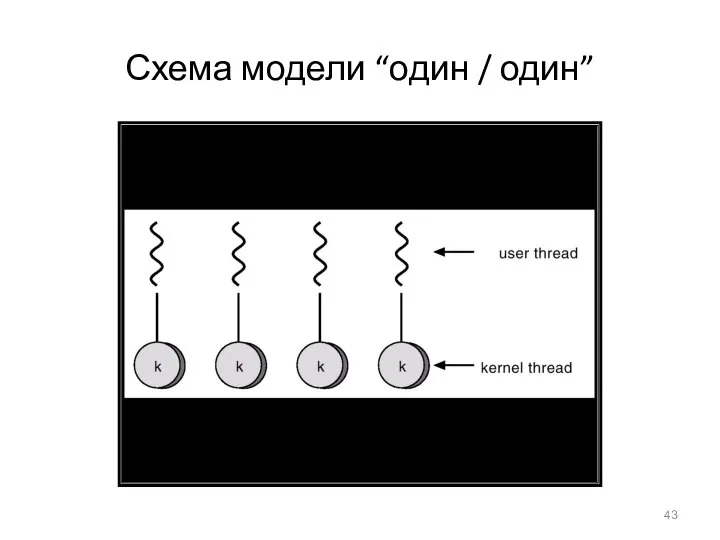
Схема модели “один / один”
Схема модели “один / один”
Схема модели “много/много”
Схема модели “много/много”
Потоки в Solaris
Потоки в Solaris
Процесс в Solaris
Процесс в Solaris
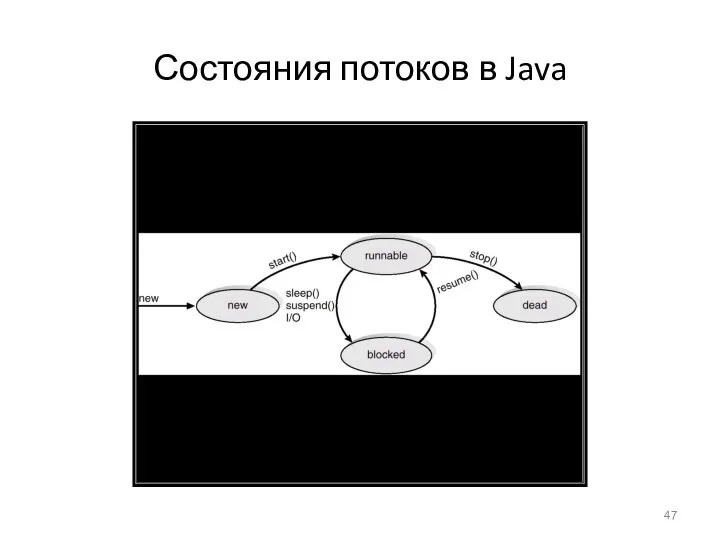
Состояния потоков в Java
Состояния потоков в Java
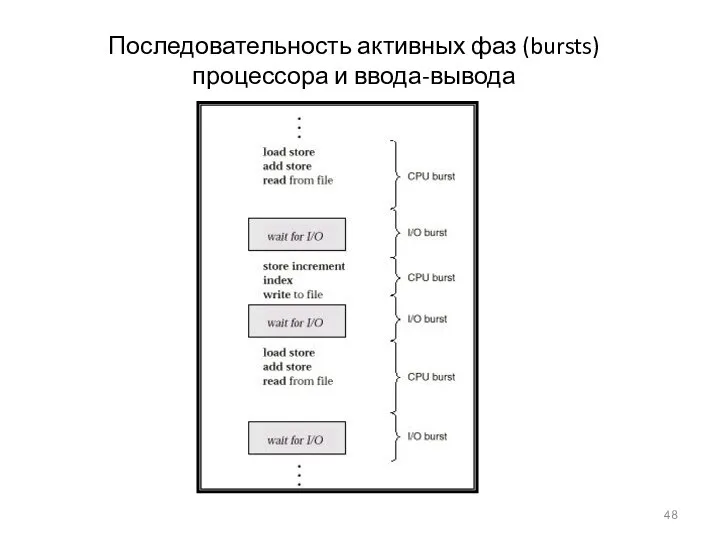
Последовательность активных фаз (bursts) процессора и ввода-вывода
Последовательность активных фаз (bursts) процессора и ввода-вывода
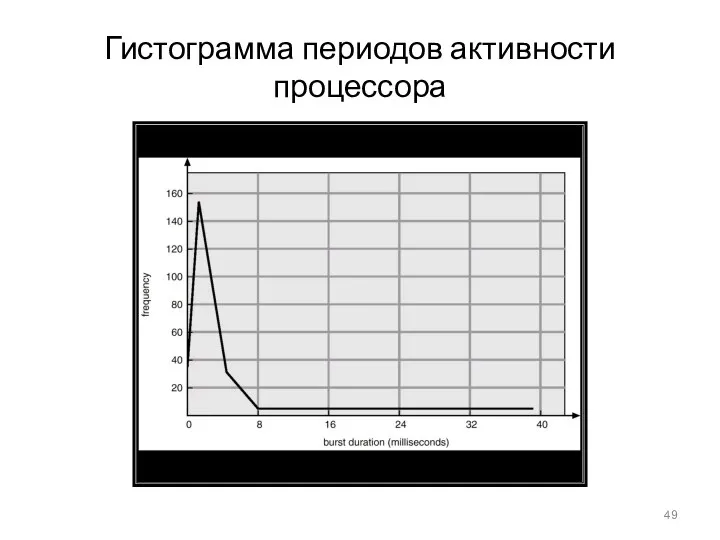
Гистограмма периодов активности процессора
Гистограмма периодов активности процессора

Стратегия диспетчеризации
First-Come-First-Served (FCFS)
Процесс Период активности
P1 24
P2 3
P3 3
Пусть
Стратегия диспетчеризации
First-Come-First-Served (FCFS)
Процесс Период активности
P1 24
P2 3
P3 3
Пусть

Стратегия FCFS (продолжение)
Пусть порядок процессов таков:
P2 , P3 , P1
Стратегия FCFS (продолжение)
Пусть порядок процессов таков:
P2 , P3 , P1
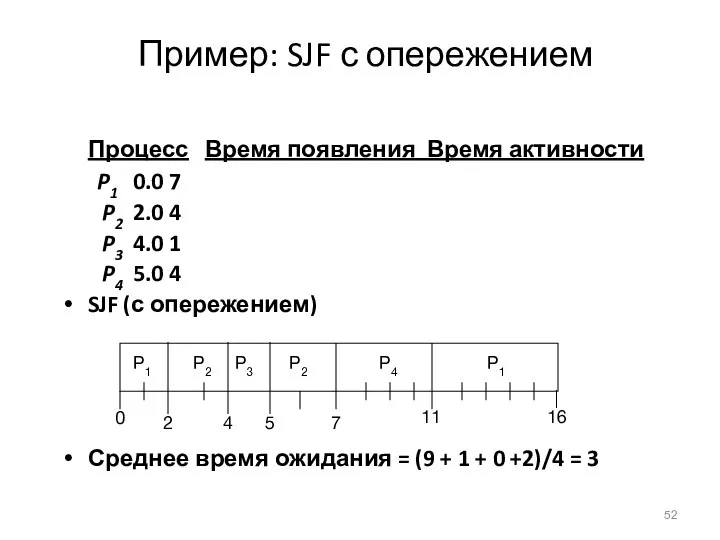
Пример: SJF с опережением
Процесс Время появления Время активности
P1 0.0 7
P2 2.0 4
P3 4.0 1
P4 5.0 4
SJF (с
Пример: SJF с опережением
Процесс Время появления Время активности
P1 0.0 7
P2 2.0 4
P3 4.0 1
P4 5.0 4
SJF (с

Определение длины следующего периода активности
Является лишь оценкой длины.
Может быть выполнено с
Определение длины следующего периода активности
Является лишь оценкой длины.
Может быть выполнено с
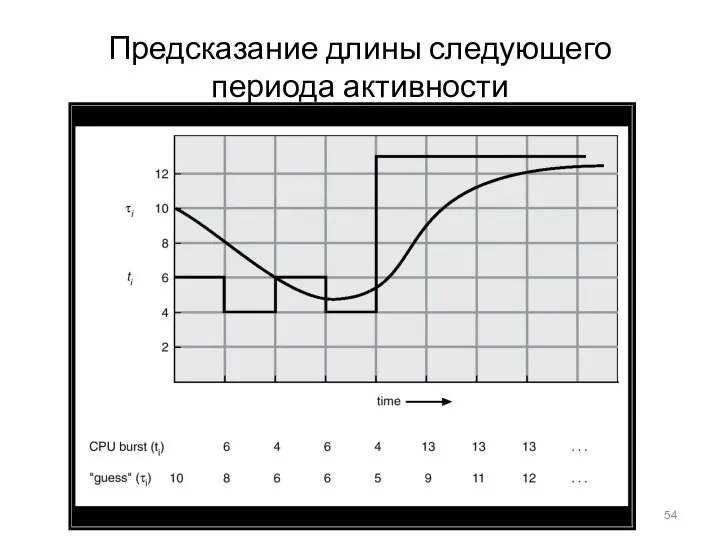
Предсказание длины следующего периода активности
Предсказание длины следующего периода активности

Примеры экспоненциального усреднения
α =0
τn+1 = τn
Недавняя история не учитывается.
α =1
τn+1
Примеры экспоненциального усреднения
α =0
τn+1 = τn
Недавняя история не учитывается.
α =1
τn+1
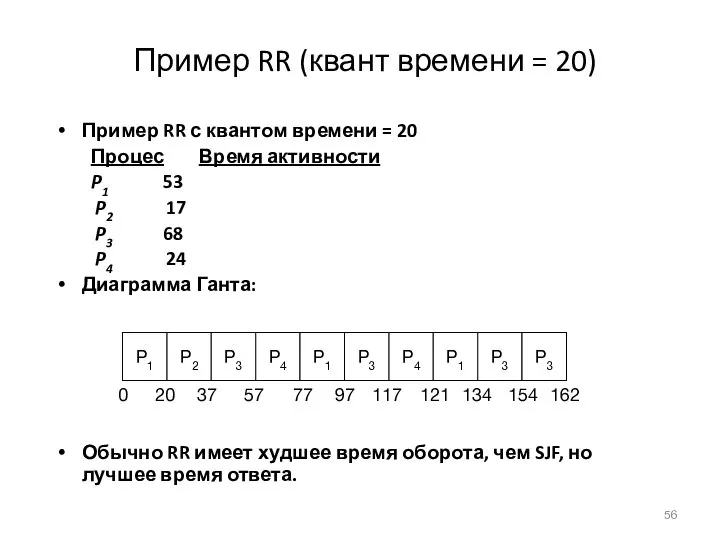
Пример RR (квант времени = 20)
Пример RR с квантом времени =
Пример RR (квант времени = 20)
Пример RR с квантом времени =
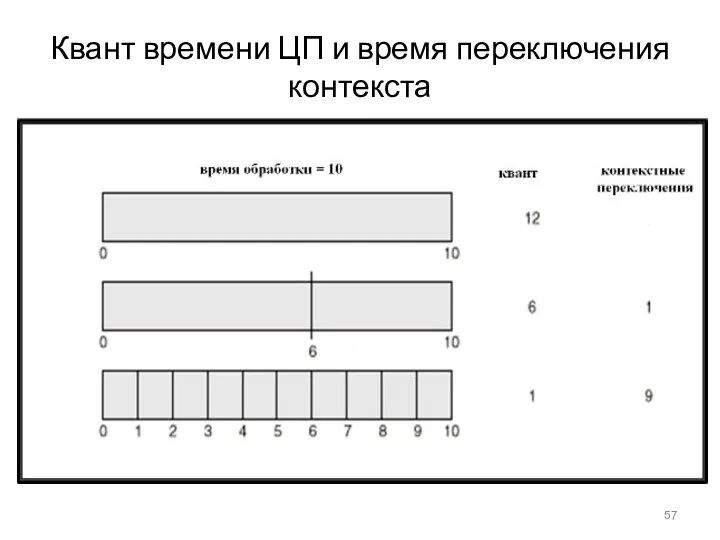
Квант времени ЦП и время переключения контекста
Квант времени ЦП и время переключения контекста
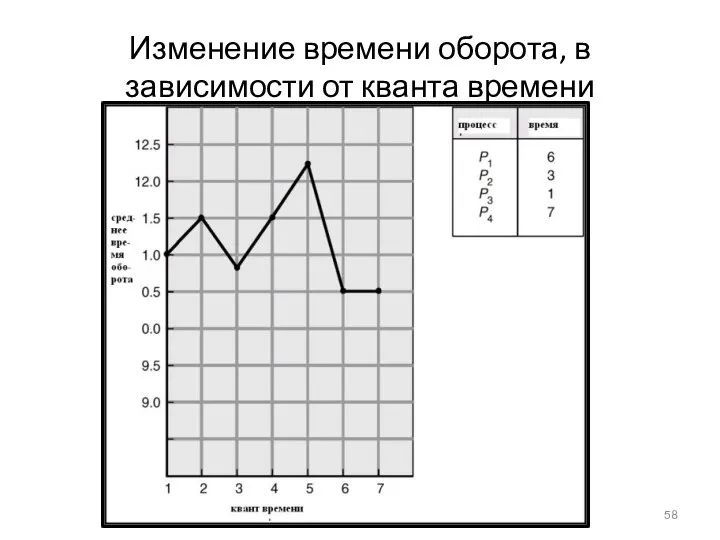
Изменение времени оборота, в зависимости от кванта времени
Изменение времени оборота, в зависимости от кванта времени
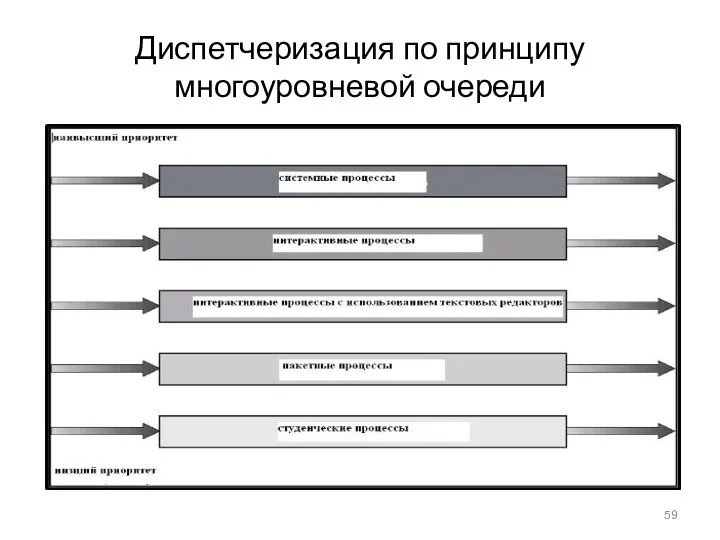
Диспетчеризация по принципу многоуровневой очереди
Диспетчеризация по принципу многоуровневой очереди
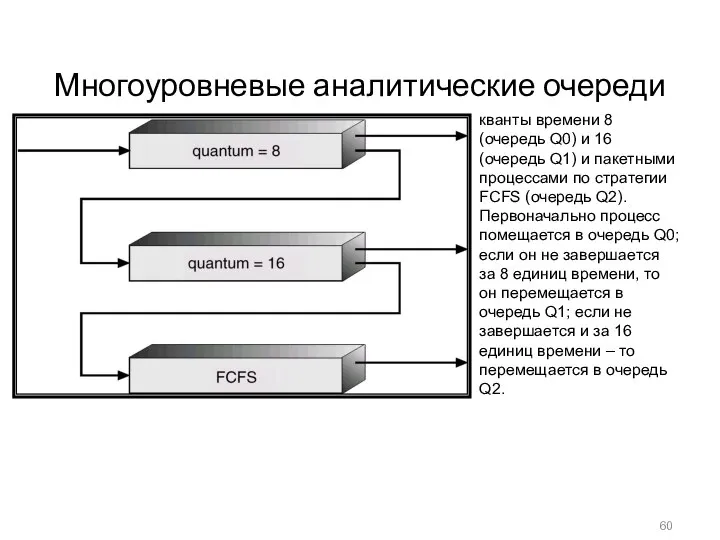
Многоуровневые аналитические очереди
кванты времени 8 (очередь Q0) и 16 (очередь Q1)
Многоуровневые аналитические очереди
кванты времени 8 (очередь Q0) и 16 (очередь Q1)
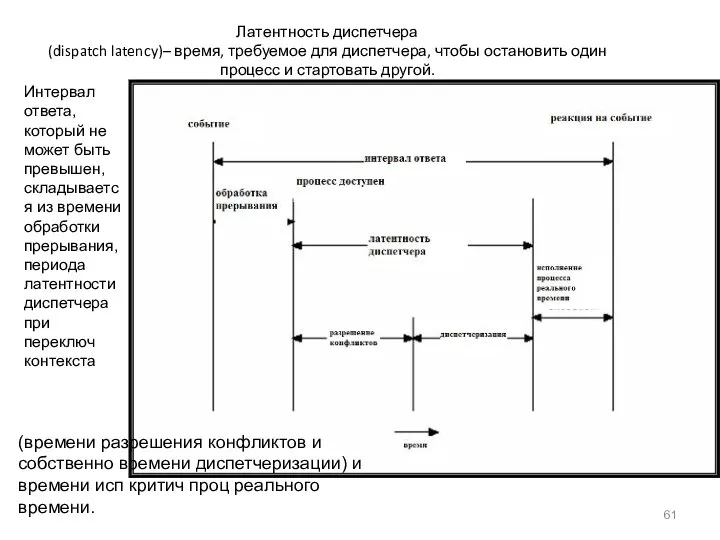
Латентность диспетчера
(dispatch latency)– время, требуемое для диспетчера, чтобы остановить один
Латентность диспетчера (dispatch latency)– время, требуемое для диспетчера, чтобы остановить один
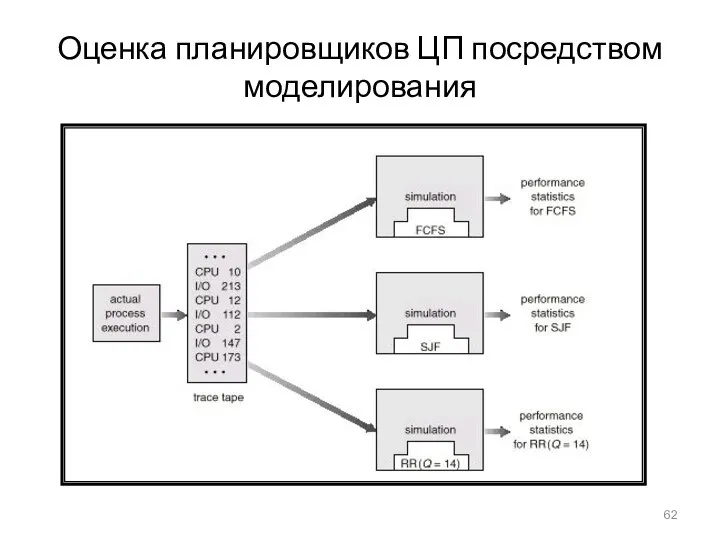
Оценка планировщиков ЦП посредством моделирования
Оценка планировщиков ЦП посредством моделирования
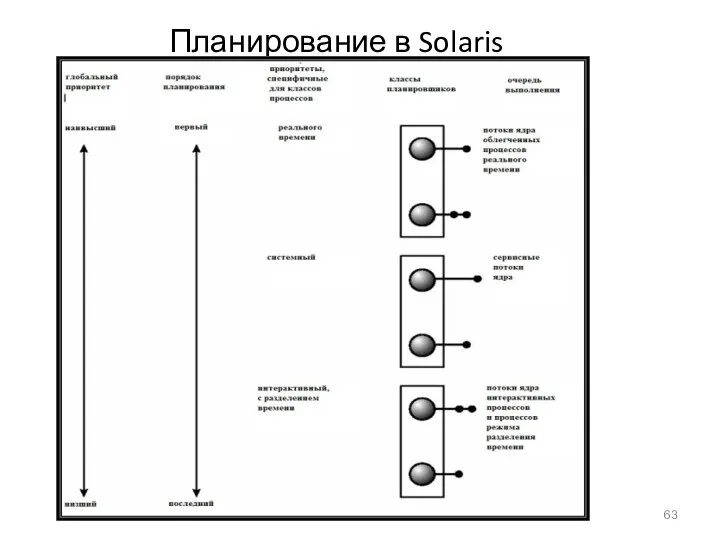
Планирование в Solaris
Планирование в Solaris
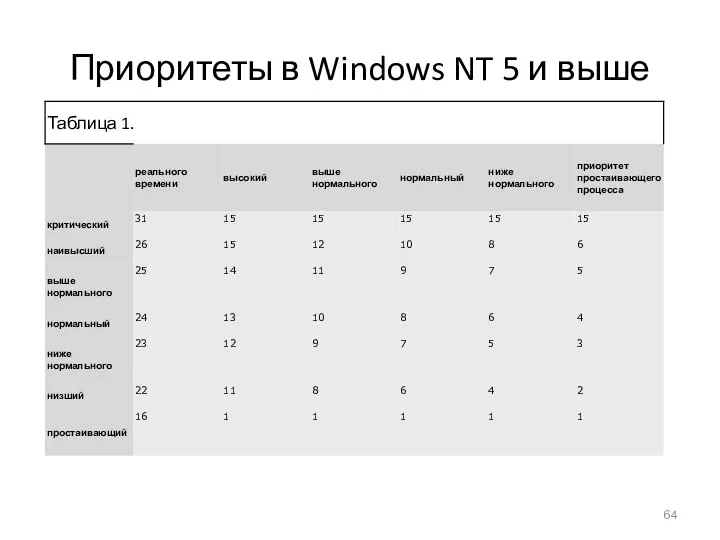
Приоритеты в Windows NT 5 и выше
Приоритеты в Windows NT 5 и выше

Ограниченный буфер
Имеется общий буфер ограниченной длины. Процесс-производитель добавляет в него сгенерированные
Ограниченный буфер
Имеется общий буфер ограниченной длины. Процесс-производитель добавляет в него сгенерированные

Ограниченный буфер
Процесс-производитель
item nextProduced;
while (1) {
while (counter == BUFFER_SIZE)
; /* do
Ограниченный буфер
Процесс-производитель
item nextProduced;
while (1) {
while (counter == BUFFER_SIZE)
; /* do

Ограниченный буфер
Процесс-потребитель
item nextConsumed;
while (1) {
while (counter == 0)
; /* do
Ограниченный буфер
Процесс-потребитель
item nextConsumed;
while (1) {
while (counter == 0)
; /* do

Ограниченный буфер
Оператор “count++” может быть реализован на языке ассемблерного уровня как:
register1
Ограниченный буфер
Оператор “count++” может быть реализован на языке ассемблерного уровня как: register1

Ограниченный буфер
Предположим, counter вначале равно 5. Исполнение процессов в совместном режиме
Ограниченный буфер
Предположим, counter вначале равно 5. Исполнение процессов в совместном режиме

Синхронизация процессов по критическим секциям
Рассмотрим проанализированную проблему в общем виде. Пусть
Синхронизация процессов по критическим секциям
Рассмотрим проанализированную проблему в общем виде. Пусть

Первоначальные попытки решения проблемы
Есть только два процесса, P0 и P1
Общая структура
Первоначальные попытки решения проблемы
Есть только два процесса, P0 и P1
Общая структура

Алгоритм 1
Общие переменные:
shared int turn;
первоначально turn = 0
turn == i
Алгоритм 1
Общие переменные:
shared int turn;
первоначально turn = 0
turn == i
![Алгоритм 2 Общие переменные boolean flag[2]; первоначально flag [0] = flag](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1301813/slide-72.jpg)
Алгоритм 2
Общие переменные
boolean flag[2];
первоначально flag [0] = flag [1] = false.
flag
Алгоритм 2
Общие переменные
boolean flag[2];
первоначально flag [0] = flag [1] = false.
flag

Алгоритм 3 (Петерсона, 1981)
Объединяет общие переменные алгоритмов 1 и 2.
Процесс Pi
Алгоритм 3 (Петерсона, 1981)
Объединяет общие переменные алгоритмов 1 и 2.
Процесс Pi

Алгоритм булочной
(bakery algorithm)
алгоритм как бы воспроизводит стратегию автомата в (американской)
Алгоритм булочной
(bakery algorithm)
алгоритм как бы воспроизводит стратегию автомата в (американской)
![Алгоритм булочной do { choosing[i] = true; number [i] = max](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1301813/slide-75.jpg)
Алгоритм булочной
do {
choosing[i] = true;
number [i] = max (number[0],
Алгоритм булочной
do {
choosing[i] = true;
number [i] = max (number[0],

Аппаратная поддержка синхронизации
Атомарная операция проверки и модификации значения переменной
TestAndSet, которая атомарно
Аппаратная поддержка синхронизации
Атомарная операция проверки и модификации значения переменной
TestAndSet, которая атомарно

Взаимное исключение с помощью TestAndSet
Общие данные:
boolean lock = false;
Процесс Pi
do
Взаимное исключение с помощью TestAndSet
Общие данные:
boolean lock = false;
Процесс Pi
do

Аппаратное решение для синхронизации
Атомарная перестановка значений двух переменных.
Другое распространенное аппаратное решение
Аппаратное решение для синхронизации
Атомарная перестановка значений двух переменных.
Другое распространенное аппаратное решение

Взаимное исключение с помощью Swap
Общие данные (инициализируемые false):
boolean lock;
boolean waiting[n];
Процесс
Взаимное исключение с помощью Swap
Общие данные (инициализируемые false):
boolean lock;
boolean waiting[n];
Процесс

Общие семафоры – counting semaphores (по Э. Дейкстре)
Семафо́р — объект, позволяющий
Общие семафоры – counting semaphores (по Э. Дейкстре)
Семафо́р — объект, позволяющий

Критическая секция для N процессов
Общие данные:
semaphore mutex; //initially mutex =
Критическая секция для N процессов
Общие данные:
semaphore mutex; //initially mutex =

Реализация семафора
Семафор, по существу, является структурой из двух полей – целого
Реализация семафора
Семафор, по существу, является структурой из двух полей – целого

Реализация
Определим семафорные операции следующим образом:
wait(S):
S.value--;
if (S.value < 0) {
добавить
Реализация
Определим семафорные операции следующим образом:
wait(S):
S.value--;
if (S.value < 0) {
добавить

Семафоры как общее средство синхронизации
Исполнить действие B в процессе Pj только
Семафоры как общее средство синхронизации
Исполнить действие B в процессе Pj только

Реализация общего семафора S с помощью двоичных семафоров
Структуры данных:
binary-semaphore S1, S2;
int
Реализация общего семафора S с помощью двоичных семафоров
Структуры данных:
binary-semaphore S1, S2;
int

Реализация операций над семафором S
Операция wait:
wait(S1);
C--;
if (C < 0) {
signal(S1);
wait(S2);
}
signal(S1);
Операция
Реализация операций над семафором S
Операция wait:
wait(S1);
C--;
if (C < 0) {
signal(S1);
wait(S2);
}
signal(S1);
Операция

Задача “ограниченный буфер”
ограниченный буфер:имеются процесс-производитель и процесс-потребитель, взаимодействующие с помощью циклического
Задача “ограниченный буфер”
ограниченный буфер:имеются процесс-производитель и процесс-потребитель, взаимодействующие с помощью циклического

Процесс-производитель ограниченного буфера
do {
…
сгенерировать элемент в nextp
…
wait(empty);
wait(mutex);
…
добавить nextp
Процесс-производитель ограниченного буфера
do {
…
сгенерировать элемент в nextp
…
wait(empty);
wait(mutex);
…
добавить nextp

Процесс-потребитель ограниченного буфера
do {
wait(full)
wait(mutex);
…
взять (и удалить) элемент из буфера
Процесс-потребитель ограниченного буфера
do {
wait(full)
wait(mutex);
…
взять (и удалить) элемент из буфера

Задача “читатели-писатели”
Суть задачи читатели-писатели в следующем: имеется общий ресурс и две группы процессов: читатели (которые
Задача “читатели-писатели”
Суть задачи читатели-писатели в следующем: имеется общий ресурс и две группы процессов: читатели (которые

Процесс-писатель
wait(wrt); …
выполняется запись …
signal(wrt);
Процесс-читатель, во-первых, должен увеличить значение readcount, причем обеспечить
Процесс-писатель
wait(wrt); …
выполняется запись …
signal(wrt);
Процесс-читатель, во-первых, должен увеличить значение readcount, причем обеспечить

Процесс-читатель
wait(mutex);
readcount++;
if (readcount == 1){
wait(rt);
}
signal(mutex);
…
выполняется чтение
…
wait(mutex);
readcount--;
if (readcount == 0){
Процесс-читатель
wait(mutex);
readcount++;
if (readcount == 1){
wait(rt);
}
signal(mutex);
…
выполняется чтение
…
wait(mutex);
readcount--;
if (readcount == 0){
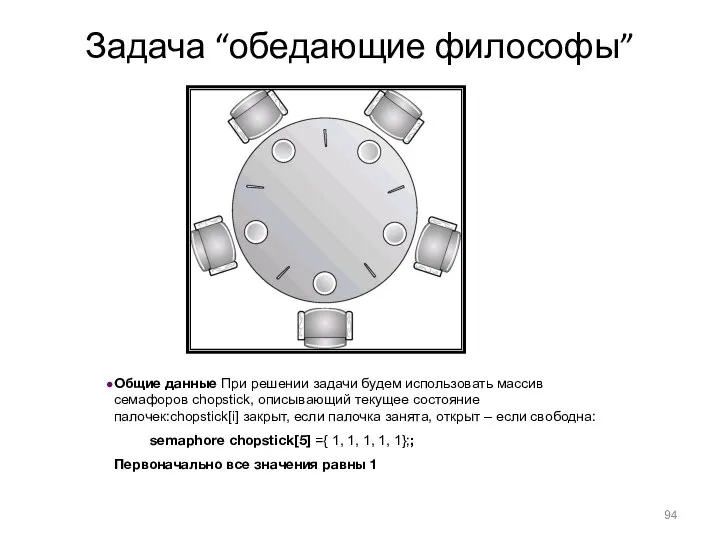
Задача “обедающие философы”
Общие данные При решении задачи будем использовать массив семафоров chopstick,
Задача “обедающие философы”
Общие данные При решении задачи будем использовать массив семафоров chopstick,

Задача “обедающие философы”
Имеется круглый стол, за которым сидят пять философов (впрочем,
Задача “обедающие философы”
Имеется круглый стол, за которым сидят пять философов (впрочем,
![Пример: ограниченный буфер Общие данные: struct buffer { int pool[n]; int](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1301813/slide-95.jpg)
Пример: ограниченный буфер
Общие данные:
struct buffer {
int pool[n];
int count, in, out;
}
Критические области
Пример: ограниченный буфер
Общие данные:
struct buffer {
int pool[n];
int count, in, out;
}
Критические области

Процесс-производитель
Процесс-производитель добавляет nextp к общему буферу
region buffer when (count < n)
Процесс-производитель
Процесс-производитель добавляет nextp к общему буферу
region buffer when (count < n)

Процесс-потребитель
Процесс-потребитель удаляет элемент из буфера и запоминает его в nextc
region buffer
Процесс-потребитель
Процесс-потребитель удаляет элемент из буфера и запоминает его в nextc
region buffer

Реализация оператора
region x when B do S
Свяжем с общей переменной
Реализация оператора
region x when B do S
Свяжем с общей переменной

Мониторы (C. A. R. Hoare)
Высокоуровневая конструкция для синхронизации, которая позволяет синхронизировать
Мониторы (C. A. R. Hoare)
Высокоуровневая конструкция для синхронизации, которая позволяет синхронизировать

Мониторы: условные переменные
Для реализации ожидания процесса внутри монитора, вводятся условные переменные:
condition
Мониторы: условные переменные
Для реализации ожидания процесса внутри монитора, вводятся условные переменные:
condition
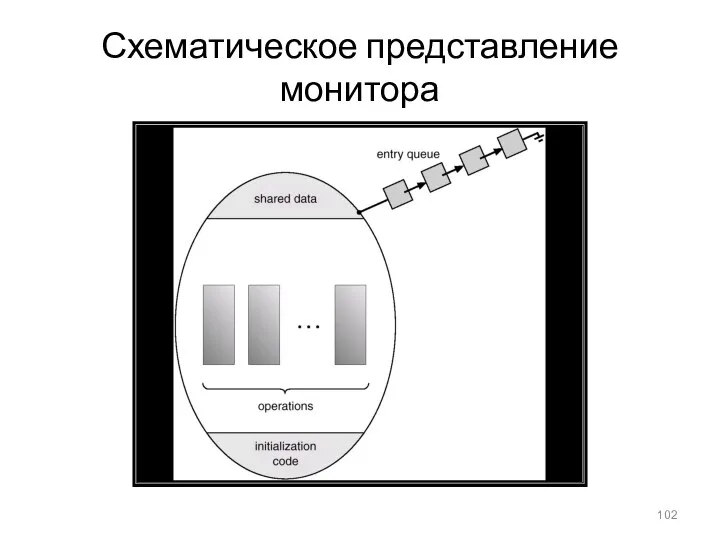
Схематическое представление монитора
Схематическое представление монитора
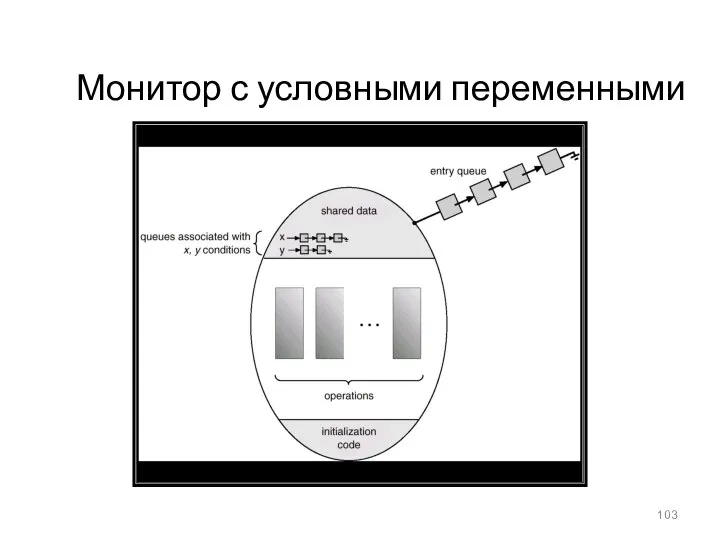
Монитор с условными переменными
Монитор с условными переменными

Синхронизации
Синхронизация в ОС Solaris
Система Solaris предоставляет разнообразные виды блокировщиков для поддержки
Синхронизации
Синхронизация в ОС Solaris
Система Solaris предоставляет разнообразные виды блокировщиков для поддержки
![Пример: обедающие философы monitor dp { enum {thinking, hungry, eating} state[5];](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1301813/slide-104.jpg)
Пример: обедающие философы
monitor dp
{
enum {thinking, hungry, eating} state[5];
condition self[5];
void pickup(int
Пример: обедающие философы
monitor dp
{
enum {thinking, hungry, eating} state[5];
condition self[5];
void pickup(int

Обедающие философы: реализация операций pickup и putdown
void pickup(int i) {
state[i] =
Обедающие философы: реализация операций pickup и putdown
void pickup(int i) {
state[i] =

Обедающие философы: реализация операции test
void test(int i) {
if ( (state[(i +
Обедающие философы: реализация операции test
void test(int i) {
if ( (state[(i +

Реализация мониторов с помощью семафоров
Используем семафоры mutex – для взаимного исключения процессов, next –для
Реализация мониторов с помощью семафоров
Используем семафоры mutex – для взаимного исключения процессов, next –для

Реализация мониторов
Для каждой условной переменной x:
semaphore x-sem; // (initially = 0)
int
Реализация мониторов
Для каждой условной переменной x:
semaphore x-sem; // (initially = 0)
int

Реализация мониторов
Реализация операции x.signal:
if (x-count > 0) {
next-count++;
signal(x-sem);
wait(next);
next-count--;
}
Таким образом, обеспечивается,
Реализация мониторов
Реализация операции x.signal:
if (x-count > 0) {
next-count++;
signal(x-sem);
wait(next);
next-count--;
}
Таким образом, обеспечивается,

Тупики
Модель системы
Для описания и исследования подобных ситуаций введем формальную
Тупики
Модель системы
Для описания и исследования подобных ситуаций введем формальную

Граф распределения ресурсов
Множество вершин V и множество дуг E.
V подразделяется на
Граф распределения ресурсов
Множество вершин V и множество дуг E.
V подразделяется на
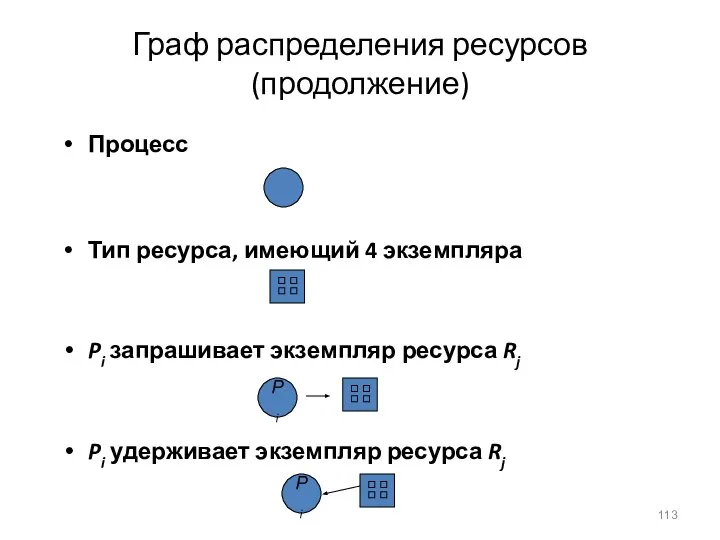
Граф распределения ресурсов (продолжение)
Процесс
Тип ресурса, имеющий 4 экземпляра
Pi запрашивает экземпляр ресурса
Граф распределения ресурсов (продолжение)
Процесс
Тип ресурса, имеющий 4 экземпляра
Pi запрашивает экземпляр ресурса
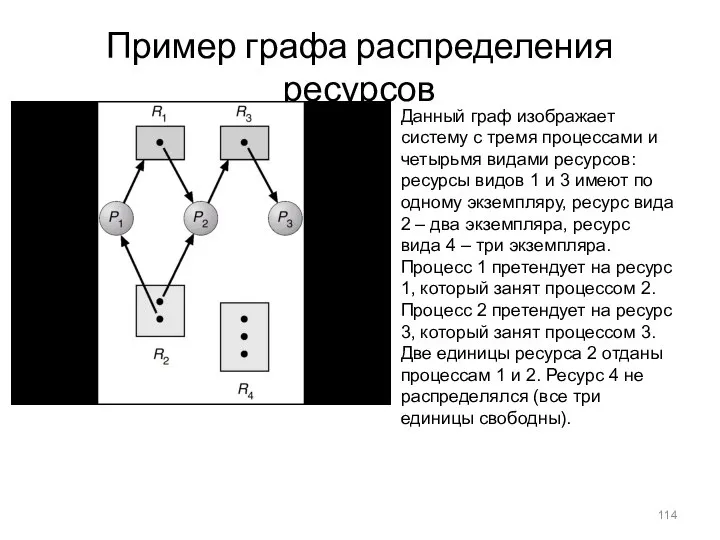
Пример графа распределения ресурсов
Данный граф изображает систему с тремя процессами и
Пример графа распределения ресурсов
Данный граф изображает систему с тремя процессами и
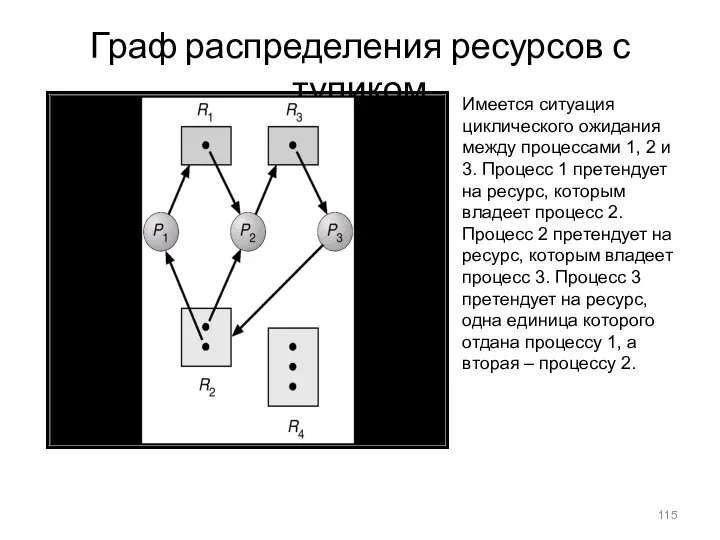
Граф распределения ресурсов с тупиком
Имеется ситуация циклического ожидания между процессами 1,
Граф распределения ресурсов с тупиком
Имеется ситуация циклического ожидания между процессами 1,
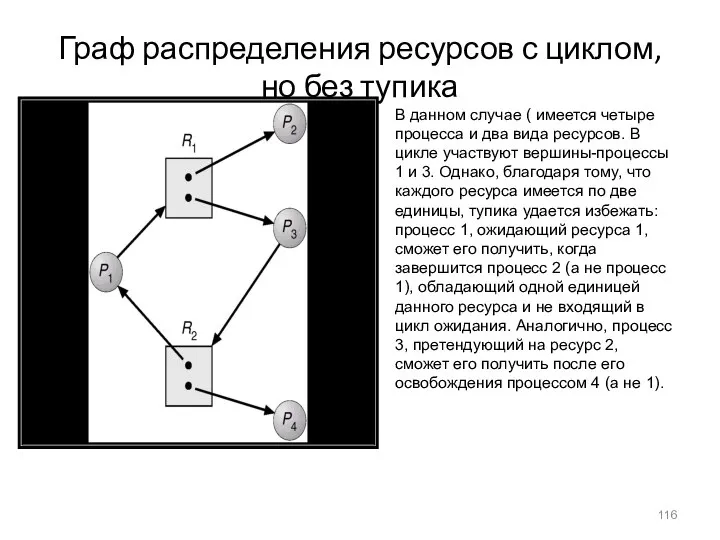
Граф распределения ресурсов с циклом, но без тупика
В данном случае (
Граф распределения ресурсов с циклом, но без тупика
В данном случае (

Если граф распределения ресурсов не содержит циклов, то в системе тупиков
Если граф распределения ресурсов не содержит циклов, то в системе тупиков

Предотвращение тупиков
Основная идея – ограничить методы запросов ресурсов со стороны процессов.
Чтобы
Предотвращение тупиков
Основная идея – ограничить методы запросов ресурсов со стороны процессов.
Чтобы

Избежание тупиков
Методы избежания тупиков требуют, чтобы система обладала дополнительной априорной информацией
Избежание тупиков
Методы избежания тупиков требуют, чтобы система обладала дополнительной априорной информацией

Безопасное состояние системы
Б С назовем такое состояние, перевод системы в которое
Безопасное состояние системы
Б С назовем такое состояние, перевод системы в которое
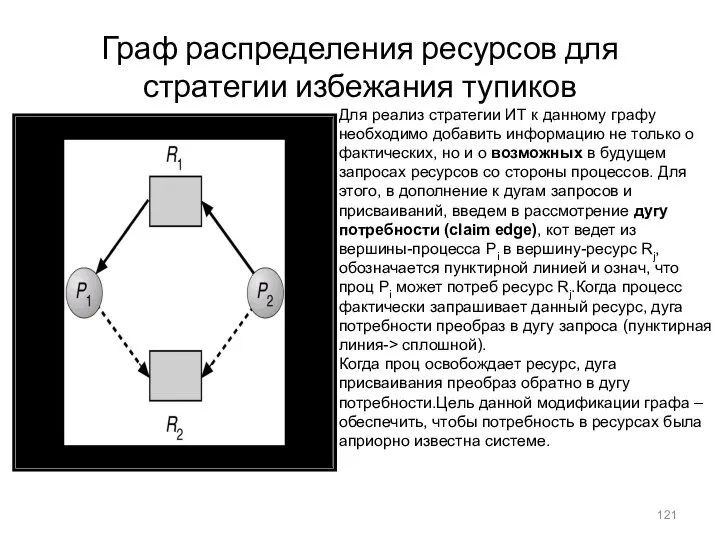
Граф распределения ресурсов для стратегии избежания тупиков
Для реализ стратегии ИТ к
Граф распределения ресурсов для стратегии избежания тупиков
Для реализ стратегии ИТ к
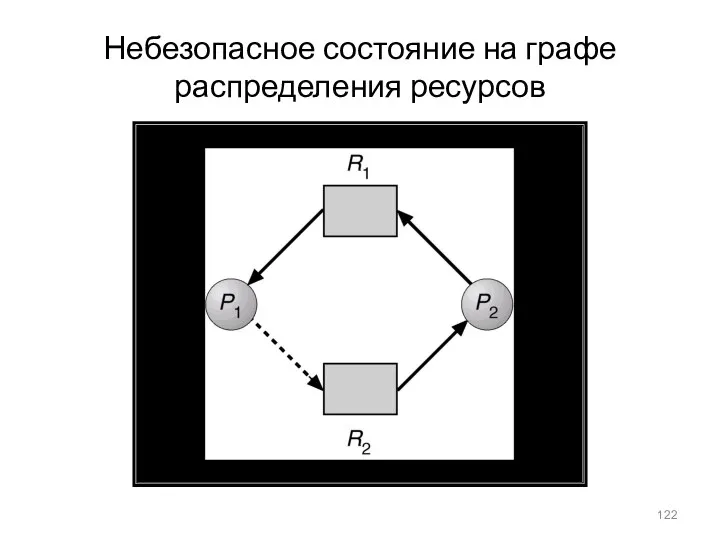
Небезопасное состояние на графе распределения ресурсов
Небезопасное состояние на графе распределения ресурсов

Алгоритм банкира
Алгоритм банкира для безопасного распределения ресурсов операционной системой (с избежанием
Алгоритм банкира
Алгоритм банкира для безопасного распределения ресурсов операционной системой (с избежанием

Алгоритм безопасности
1.Пусть Work и Finish – векторы длин m и n,
Алгоритм безопасности
1.Пусть Work и Finish – векторы длин m и n,

Алгоритм запроса ресурсов для процесса Pi
Request = вектор запросов для процесса
Алгоритм запроса ресурсов для процесса Pi
Request = вектор запросов для процесса

Пример (продолжение)
Состояние матрицы. Need определяется как (Max – Allocation).
Need
A B C
Пример (продолжение)
Состояние матрицы. Need определяется как (Max – Allocation).
Need
A B C

Пример (продолжение).
Запрос процесса P1: (1,0,2)
Проверяем, что Request ≤ Available, то
Пример (продолжение).
Запрос процесса P1: (1,0,2)
Проверяем, что Request ≤ Available, то

Случай, когда каждый тип ресурса имеет единственный экземпляр
Строим и поддерживаем wait-for
Случай, когда каждый тип ресурса имеет единственный экземпляр
Строим и поддерживаем wait-for
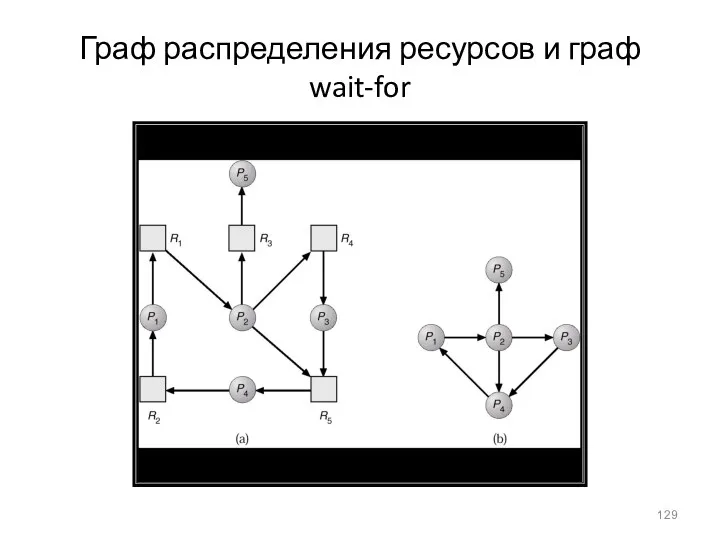
Граф распределения ресурсов и граф wait-for
Граф распределения ресурсов и граф wait-for

Случай, когда ресурсы существуют в нескольких экземплярах для каждого типа
Available: Вектор
Случай, когда ресурсы существуют в нескольких экземплярах для каждого типа
Available: Вектор

Алгоритм обнаружения тупиков
Пусть Work и Finish – векторы длин m и
Алгоритм обнаружения тупиков
Пусть Work и Finish – векторы длин m и

Алгоритм обнаружения: пример
Пусть имеются пять процессов P0 - P4 и три
Алгоритм обнаружения: пример
Пусть имеются пять процессов P0 - P4 и три

Алгоритм обнаружения: продолжение
P2 запрашивает дополнительный ресурс типа C.
Запрос
A B C
P0 0
Алгоритм обнаружения: продолжение
P2 запрашивает дополнительный ресурс типа C.
Запрос
A B C
P0 0

Восстановление после тупика
Для выхода из тупика, очевидно, система должна прекратить все
Восстановление после тупика
Для выхода из тупика, очевидно, система должна прекратить все

Управление памятью
Основные положения размещения процессов в памяти Любая прога,введ в сист,
Управление памятью
Основные положения размещения процессов в памяти Любая прога,введ в сист,
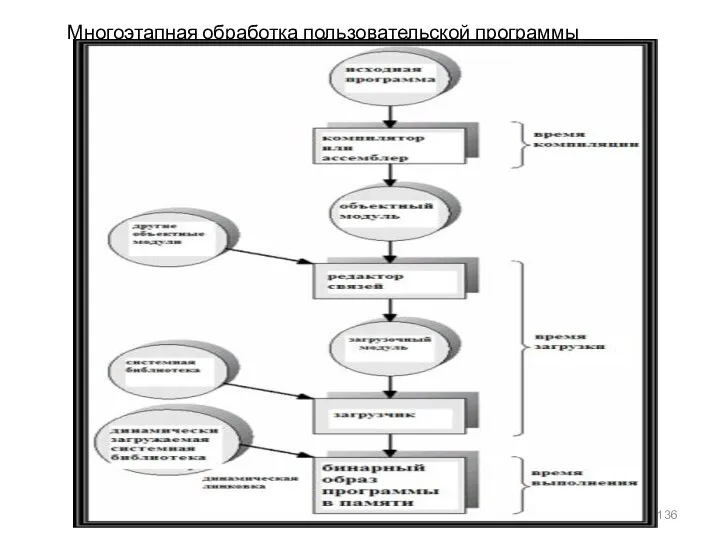
Многоэтапная обработка пользовательской программы
Многоэтапная обработка пользовательской программы

Исходный код программы (в форме текстового файла) на языке высокого уровня или
Исходный код программы (в форме текстового файла) на языке высокого уровня или

Логическое и физическое адресное пространство
Концепция логического адресного пространства, связанного с соответствующим физическим адресным пространством,
Логическое и физическое адресное пространство
Концепция логического адресного пространства, связанного с соответствующим физическим адресным пространством,
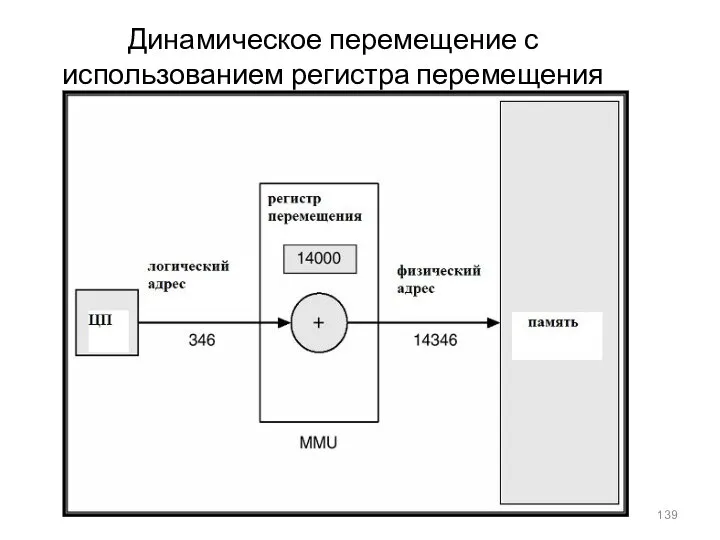
Динамическое перемещение с использованием регистра перемещения
Динамическое перемещение с использованием регистра перемещения

Динамическая загрузка и динамическая линковка
Под динамической загрузкой понимается загрузка подпрограммы в память при первом
Динамическая загрузка и динамическая линковка
Под динамической загрузкой понимается загрузка подпрограммы в память при первом
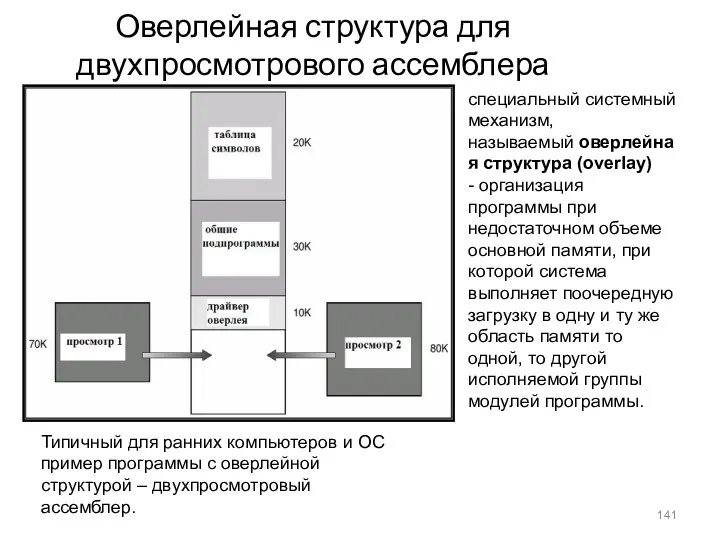
Оверлейная структура для двухпросмотрового ассемблера
специальный системный механизм, называемый оверлейная структура (overlay) - организация программы при
Оверлейная структура для двухпросмотрового ассемблера
специальный системный механизм, называемый оверлейная структура (overlay) - организация программы при
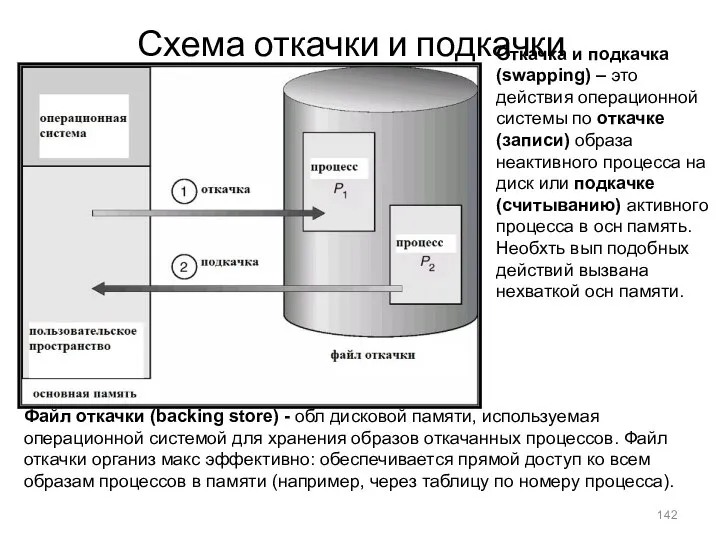
Схема откачки и подкачки
Откачка и подкачка (swapping) – это действия операционной системы
Схема откачки и подкачки
Откачка и подкачка (swapping) – это действия операционной системы
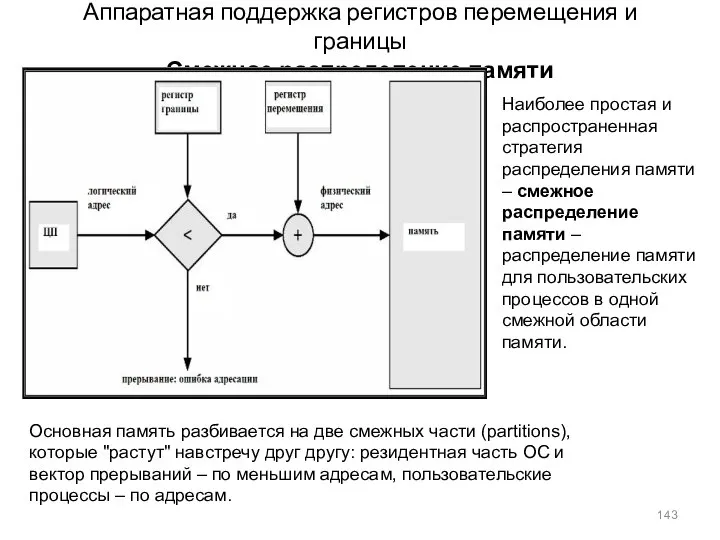
Аппаратная поддержка регистров перемещения и границы
Смежное распределение памяти
Основная память разбивается на
Аппаратная поддержка регистров перемещения и границы
Смежное распределение памяти
Основная память разбивается на

Фрагментация
Фрагментация – это дробление памяти на мелкие не смежные свободные области маленького
Фрагментация
Фрагментация – это дробление памяти на мелкие не смежные свободные области маленького
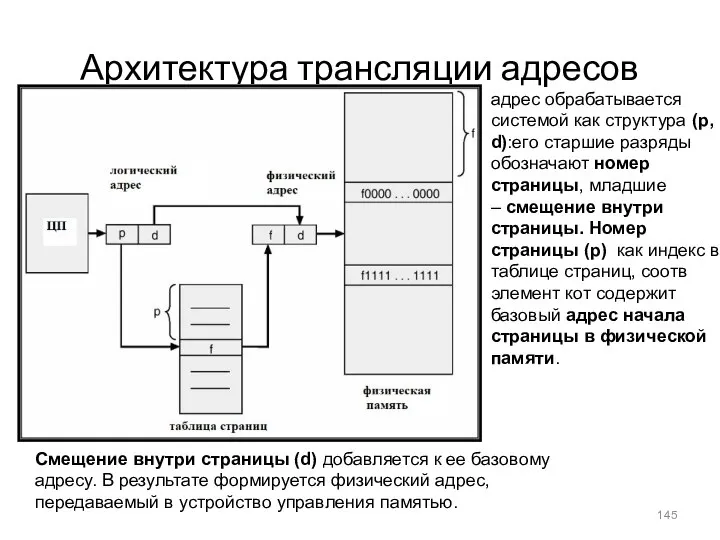
Архитектура трансляции адресов
адрес обрабатывается системой как структура (p, d):его старшие разряды обозначают
Архитектура трансляции адресов
адрес обрабатывается системой как структура (p, d):его старшие разряды обозначают
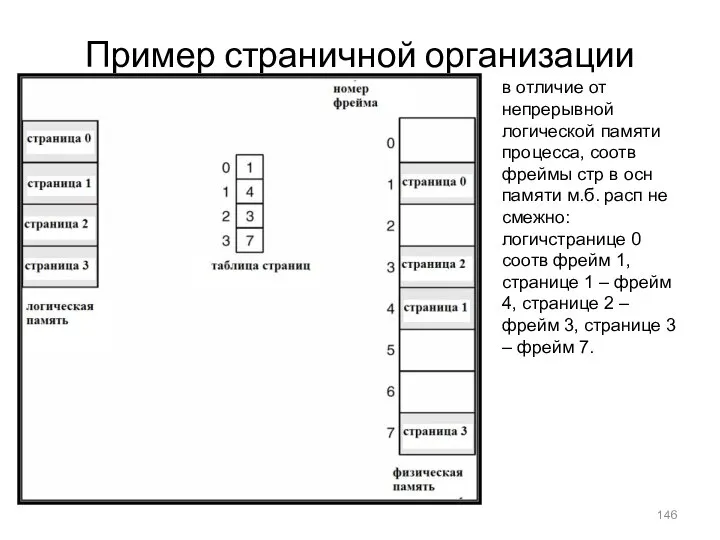
Пример страничной организации
в отличие от непрерывной логической памяти процесса, соотв фреймы
Пример страничной организации
в отличие от непрерывной логической памяти процесса, соотв фреймы

Список свободных фреймов
Список свободных фреймов
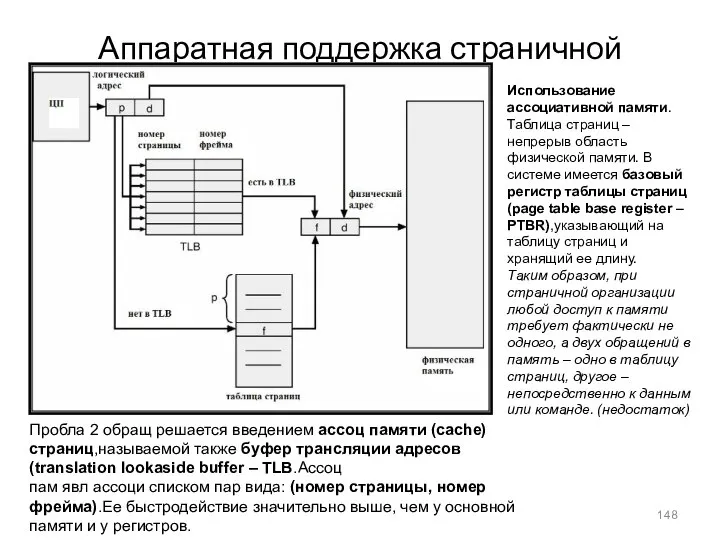
Аппаратная поддержка страничной организации: TLB
Использование ассоциативной памяти.Таблица страниц – непрерыв область
Аппаратная поддержка страничной организации: TLB
Использование ассоциативной памяти.Таблица страниц – непрерыв область

Эффективное время поиска (effective access time – EAT)
Ассоциативный поиск = ε
Эффективное время поиска (effective access time – EAT)
Ассоциативный поиск = ε

Бит valid/invalid в таблице страниц
Защита памяти
При адресации с пом стран организ
Бит valid/invalid в таблице страниц
Защита памяти
При адресации с пом стран организ
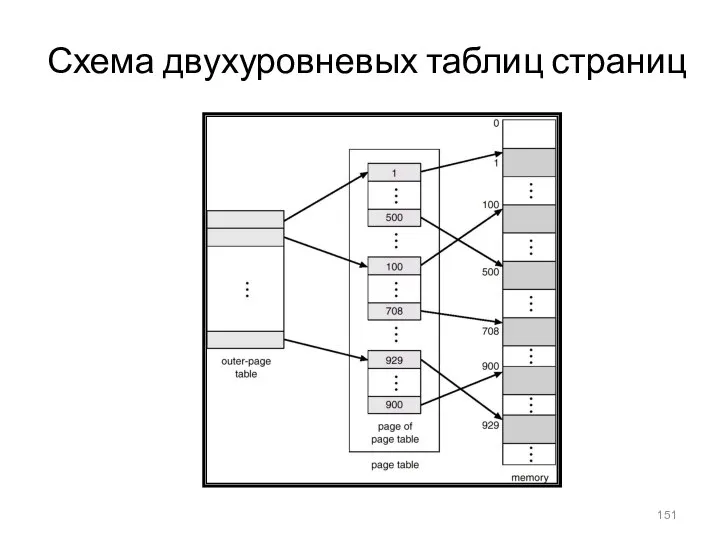
Схема двухуровневых таблиц страниц
Схема двухуровневых таблиц страниц
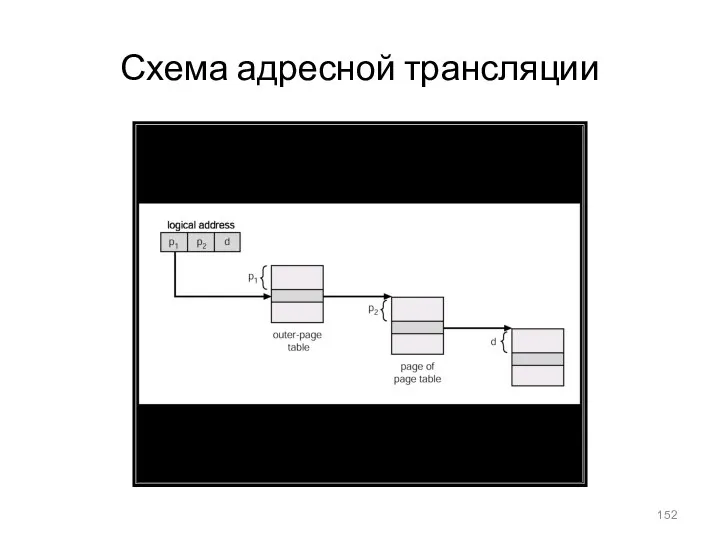
Схема адресной трансляции
Схема адресной трансляции
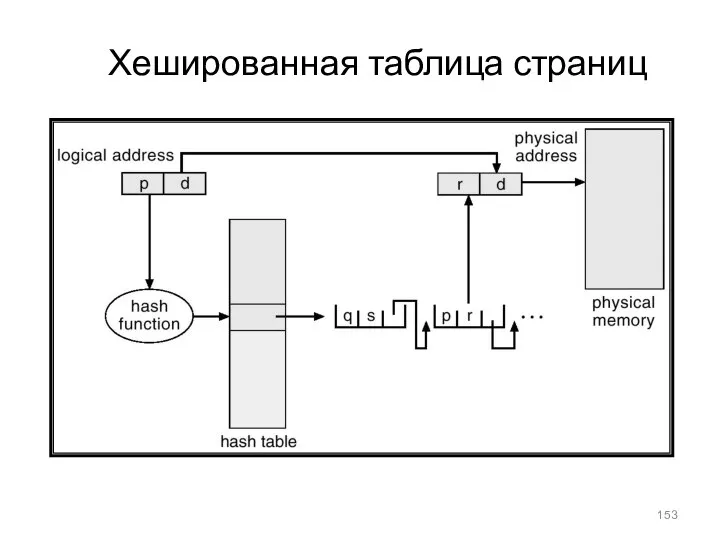
Хешированная таблица страниц
Хешированная таблица страниц
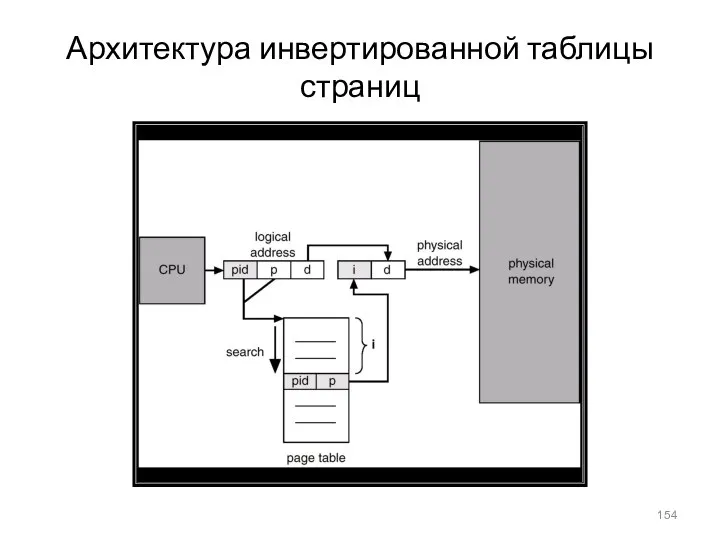
Архитектура инвертированной таблицы страниц
Архитектура инвертированной таблицы страниц
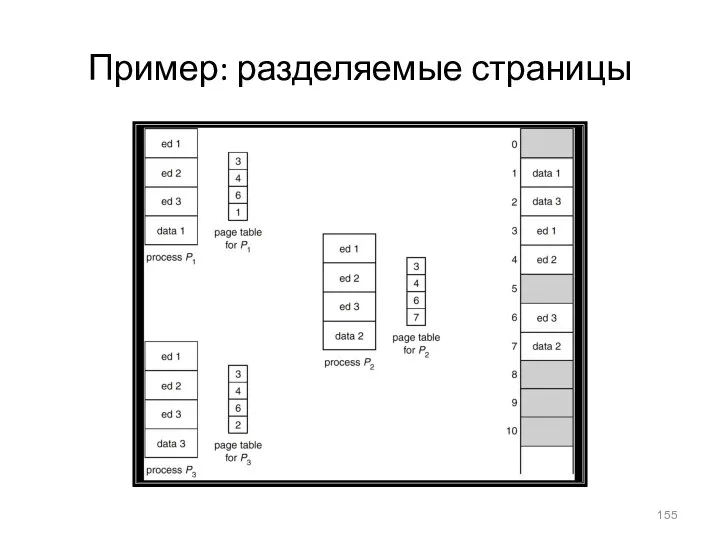
Пример: разделяемые страницы
Пример: разделяемые страницы
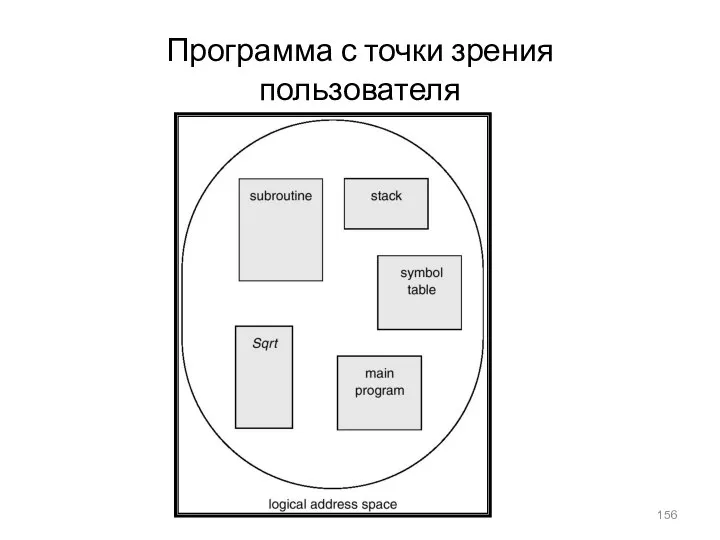
Программа с точки зрения пользователя
Программа с точки зрения пользователя

Архитектура сегментной организации памяти
Логический адрес ~ пара:
,
Таблица сегментов – служит
Архитектура сегментной организации памяти
Логический адрес ~ пара:
Таблица сегментов – служит
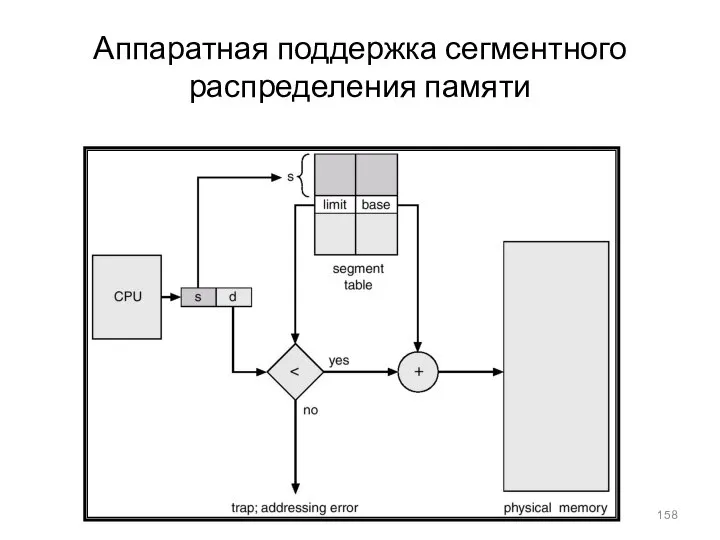
Аппаратная поддержка сегментного распределения памяти
Аппаратная поддержка сегментного распределения памяти
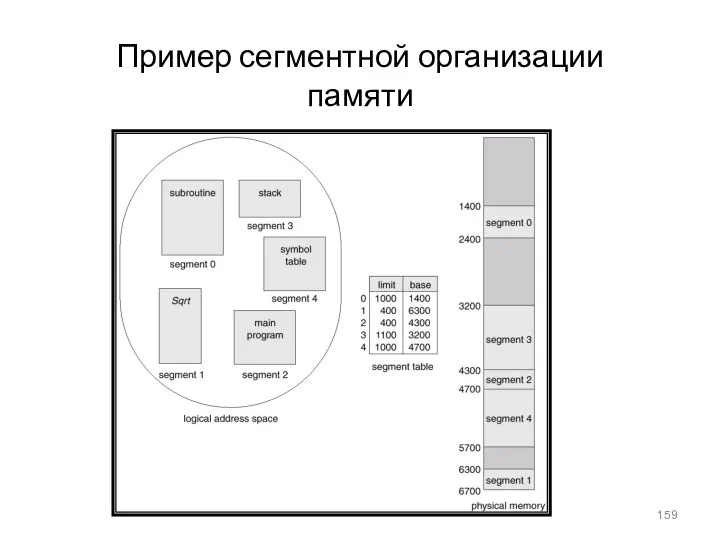
Пример сегментной организации памяти
Пример сегментной организации памяти
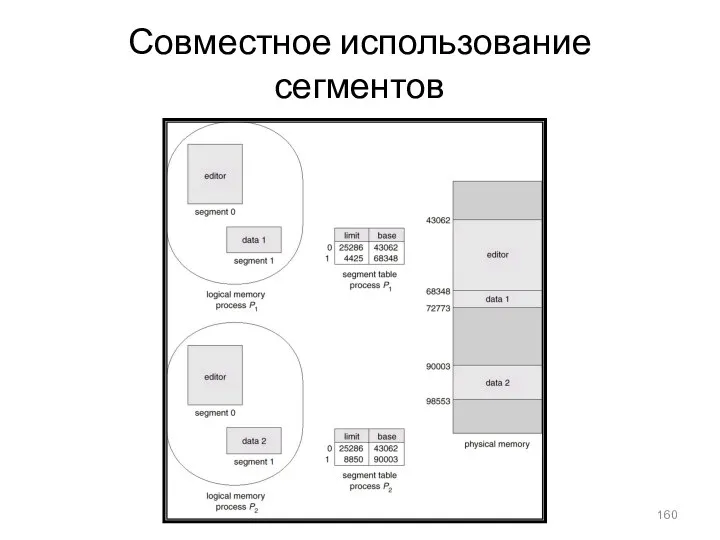
Совместное использование сегментов
Совместное использование сегментов
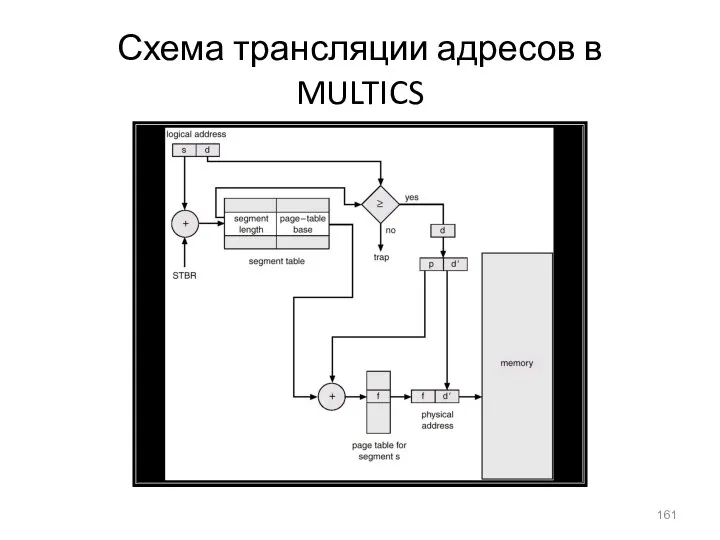
Схема трансляции адресов в MULTICS
Схема трансляции адресов в MULTICS
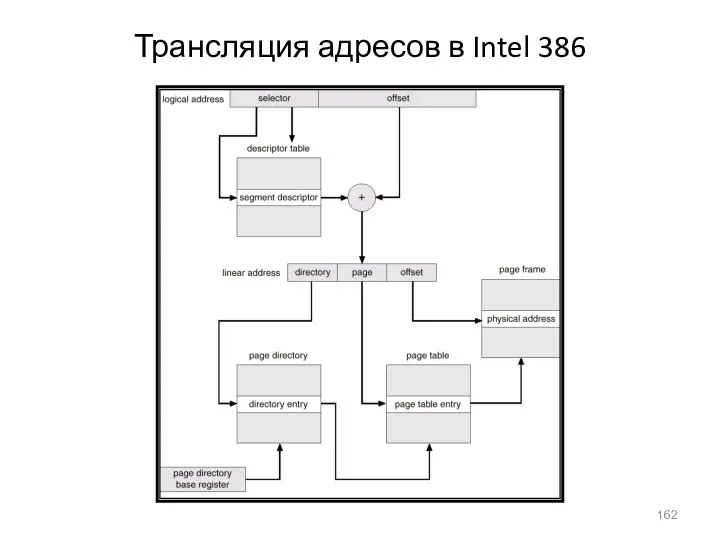
Трансляция адресов в Intel 386
Трансляция адресов в Intel 386
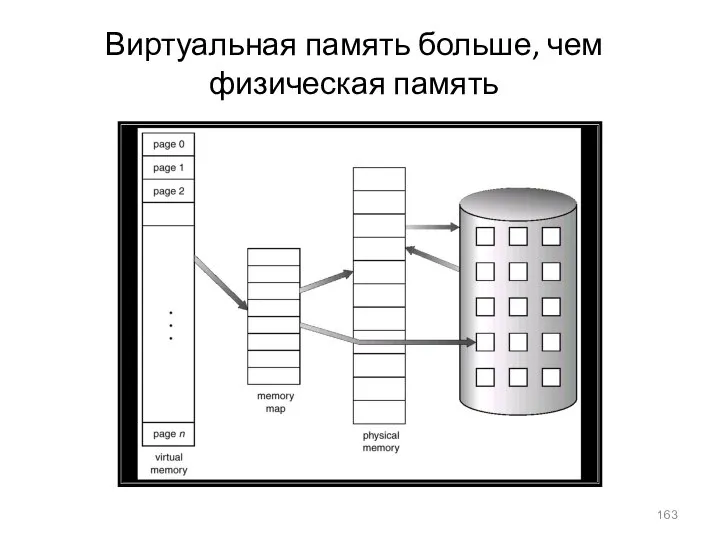
Виртуальная память больше, чем физическая память
Виртуальная память больше, чем физическая память
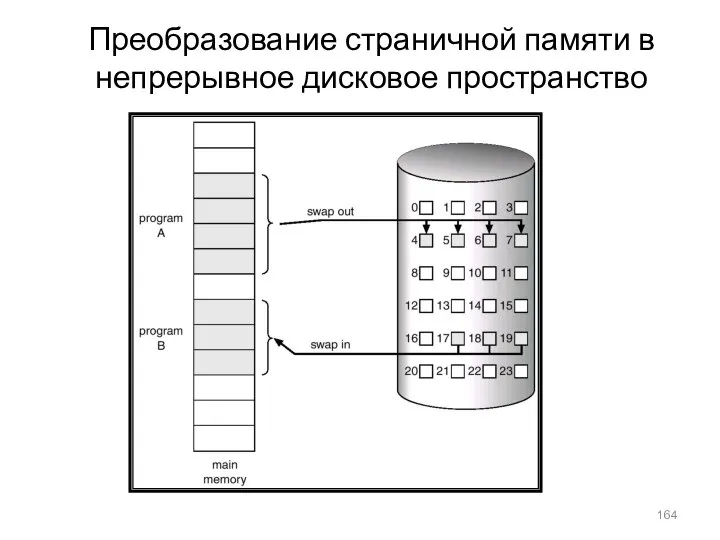
Преобразование страничной памяти в непрерывное дисковое пространство
Преобразование страничной памяти в непрерывное дисковое пространство
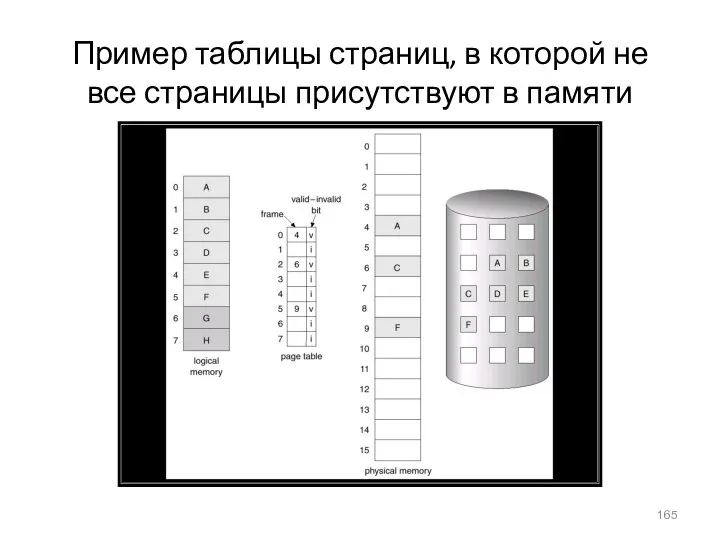
Пример таблицы страниц, в которой не все страницы присутствуют в памяти
Пример таблицы страниц, в которой не все страницы присутствуют в памяти
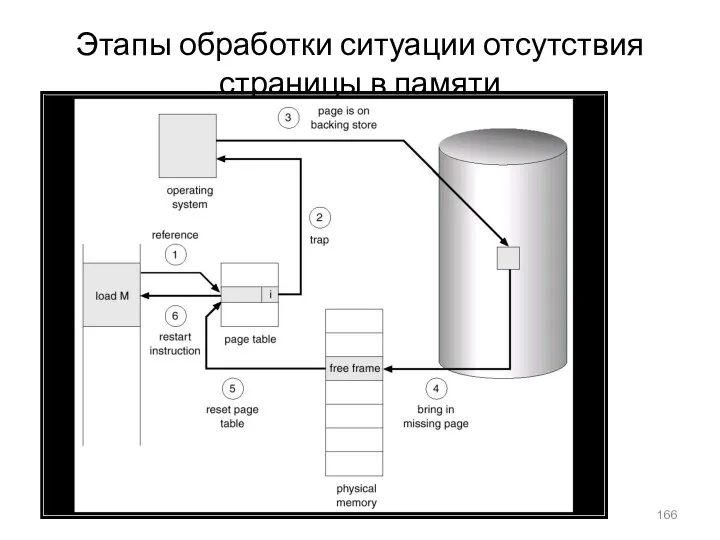
Этапы обработки ситуации отсутствия страницы в памяти
Этапы обработки ситуации отсутствия страницы в памяти

Оценка производительности стратегии обработки страницы по требованию
Коффициент отказов страниц (Page Fault
Оценка производительности стратегии обработки страницы по требованию
Коффициент отказов страниц (Page Fault
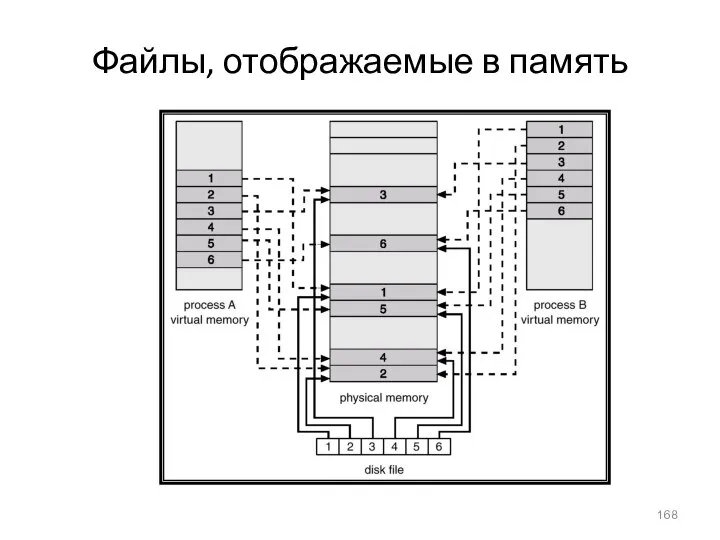
Файлы, отображаемые в память
Файлы, отображаемые в память
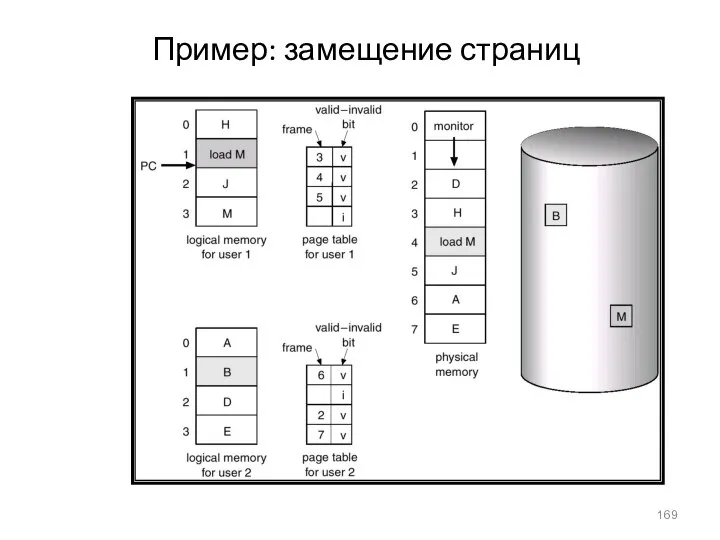
Пример: замещение страниц
Пример: замещение страниц
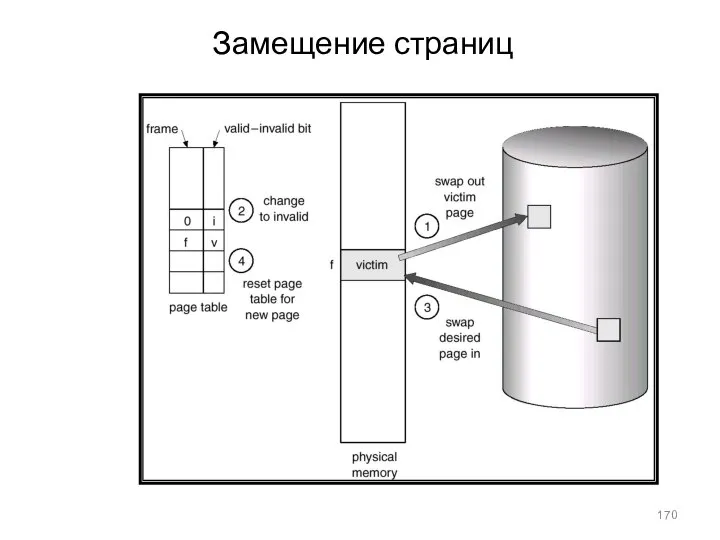
Замещение страниц
Замещение страниц
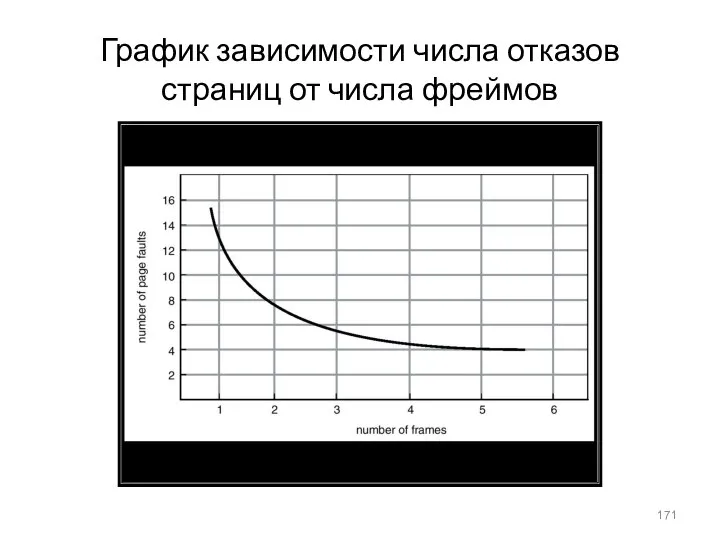
График зависимости числа отказов страниц от числа фреймов
График зависимости числа отказов страниц от числа фреймов

Алгоритм FIFO
(First-in-First-Out)
Наиболее простой алгоритм замещения страниц – в качестве жертвы
Алгоритм FIFO
(First-in-First-Out)
Наиболее простой алгоритм замещения страниц – в качестве жертвы
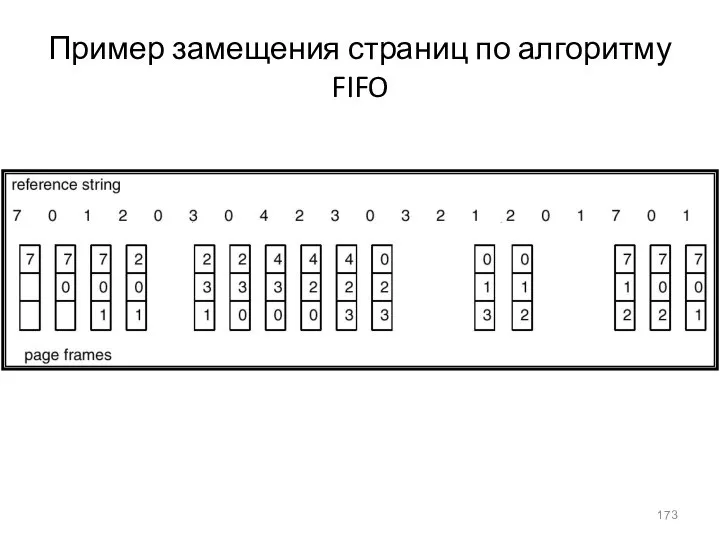
Пример замещения страниц по алгоритму FIFO
Пример замещения страниц по алгоритму FIFO
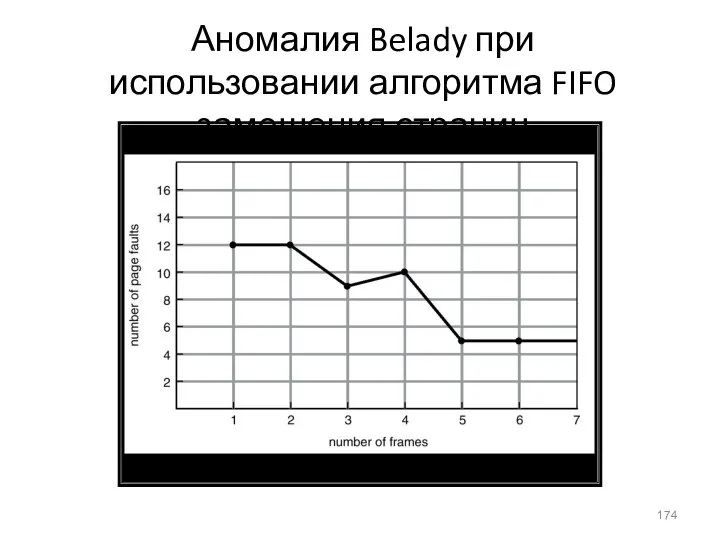
Аномалия Belady при использовании алгоритма FIFO замещения страниц
Аномалия Belady при использовании алгоритма FIFO замещения страниц

Алгоритм Least Recently Used (LRU)
Замещается та страница, которая раньше всего использовалась.
Строка
Алгоритм Least Recently Used (LRU)
Замещается та страница, которая раньше всего использовалась.
Строка
Замещение страниц по алгоритму LRU
Для оптимизации данного алгоритма, чтобы избежать поиска
Замещение страниц по алгоритму LRU
Для оптимизации данного алгоритма, чтобы избежать поиска
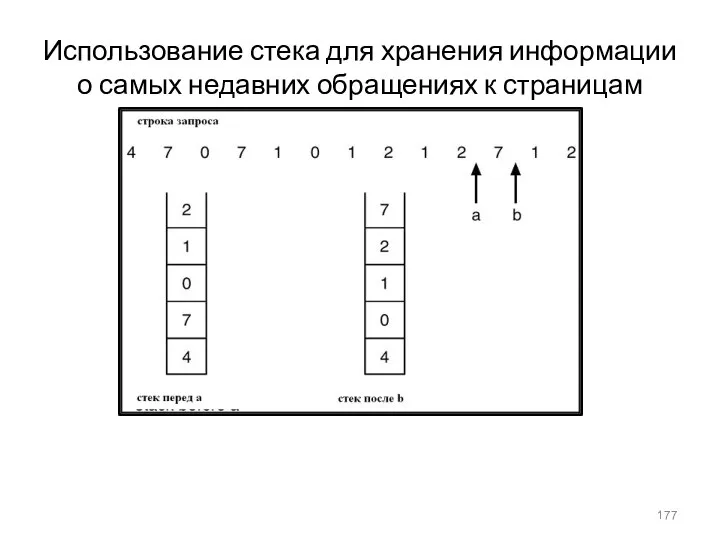
Использование стека для хранения информации о самых недавних обращениях к страницам
Использование стека для хранения информации о самых недавних обращениях к страницам

Алгоритмы, близкие к LRU
Имеется несколько алгоритмов, близких к алгоритму LRU, в
Алгоритмы, близкие к LRU
Имеется несколько алгоритмов, близких к алгоритму LRU, в
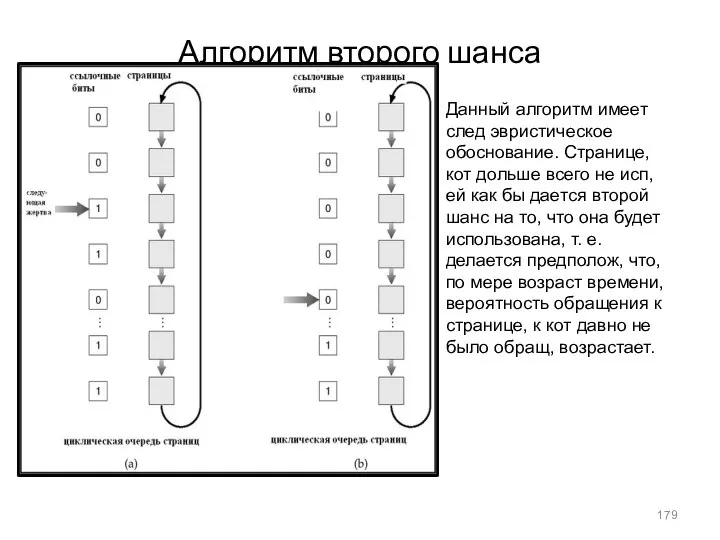
Алгоритм второго шанса
Данный алгоритм имеет след эвристическое обоснование. Странице, кот дольше
Алгоритм второго шанса
Данный алгоритм имеет след эвристическое обоснование. Странице, кот дольше

Фиксированное выделение
Равномерное распределение – например, если имеется 100 фреймов и 5
Фиксированное выделение
Равномерное распределение – например, если имеется 100 фреймов и 5
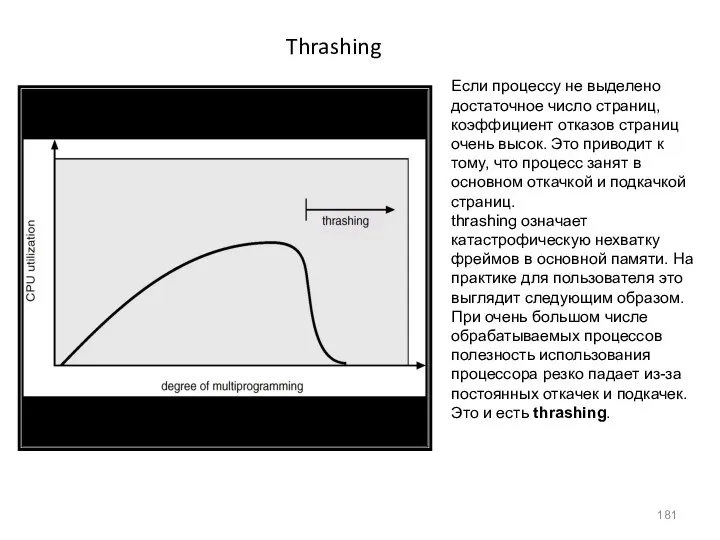
Thrashing
Если процессу не выделено достаточное число страниц, коэффициент отказов страниц очень
Thrashing
Если процессу не выделено достаточное число страниц, коэффициент отказов страниц очень

Модель рабочего множества
thrashing происходит, если сумма размеров локальных потребностей процессов в
Модель рабочего множества
thrashing происходит, если сумма размеров локальных потребностей процессов в
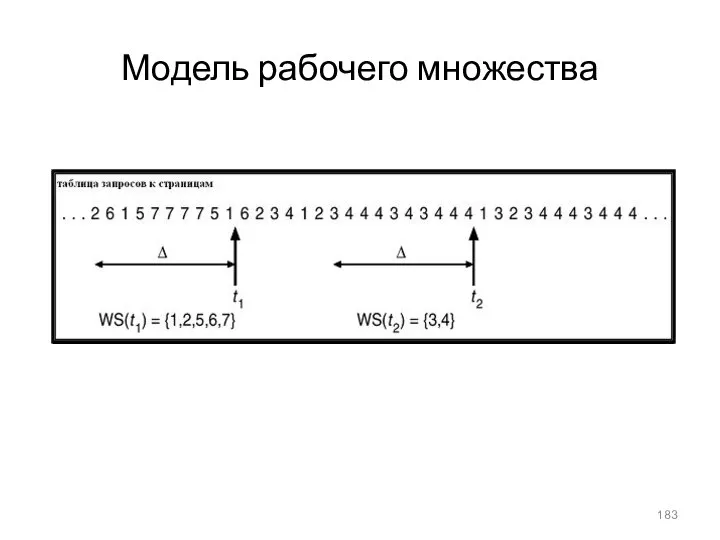
Модель рабочего множества
Модель рабочего множества

Атрибуты файлов
Имя (Name) – информация в символьной форме, воспринимаемая человеком.
Тип (Type)
Атрибуты файлов
Имя (Name) – информация в символьной форме, воспринимаемая человеком.
Тип (Type)

Операции над файлом
Создание - Create
Запись - Write
Чтение - Read
Поиск позиции внутри
Операции над файлом
Создание - Create
Запись - Write
Чтение - Read
Поиск позиции внутри
Типы файлов – имя и расширение
Типы файлов – имя и расширение

Методы доступа к файлам
Последовательный доступ
read next
write next
reset
rewrite
Прямой доступ
read n
write n
position
Методы доступа к файлам
Последовательный доступ
read next
write next
reset
rewrite
Прямой доступ
read n
write n
position

Файл последовательного доступа
Файл последовательного доступа

Моделирование последовательного доступа для файла с прямым доступом
Моделирование последовательного доступа для файла с прямым доступом
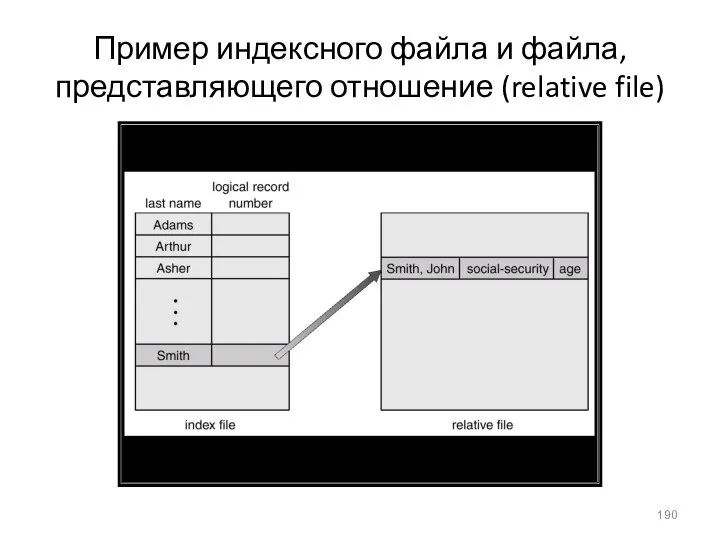
Пример индексного файла и файла, представляющего отношение (relative file)
Пример индексного файла и файла, представляющего отношение (relative file)
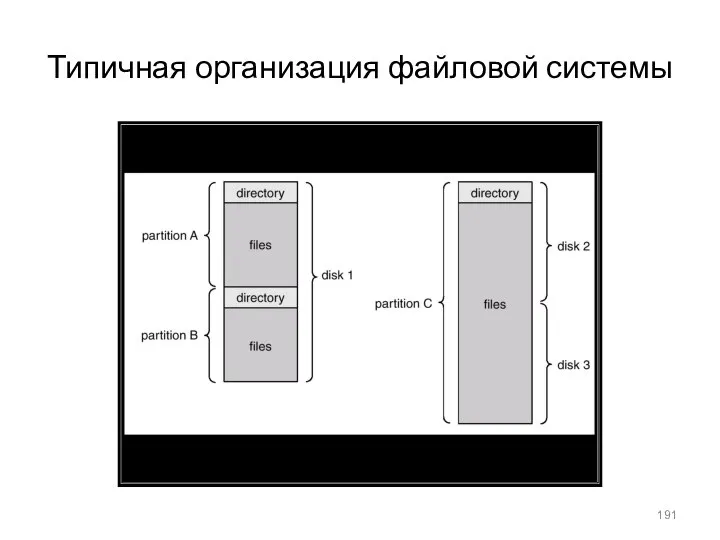
Типичная организация файловой системы
Типичная организация файловой системы
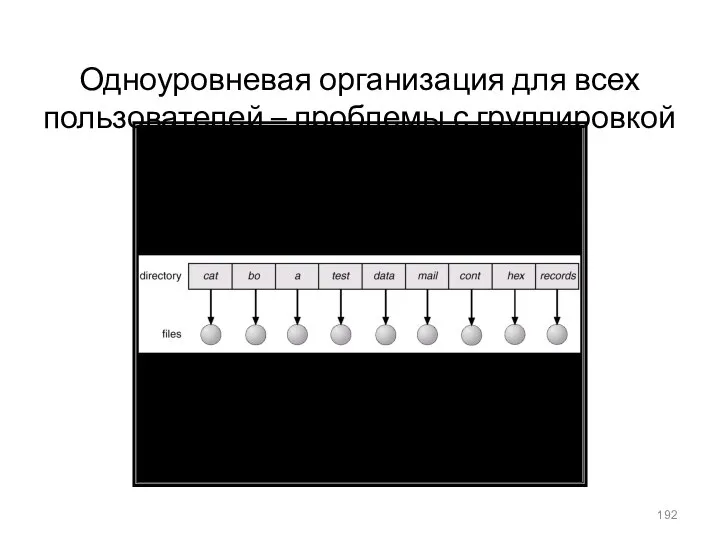
Одноуровневая организация для всех пользователей – проблемы с группировкой и именованием
Одноуровневая организация для всех пользователей – проблемы с группировкой и именованием
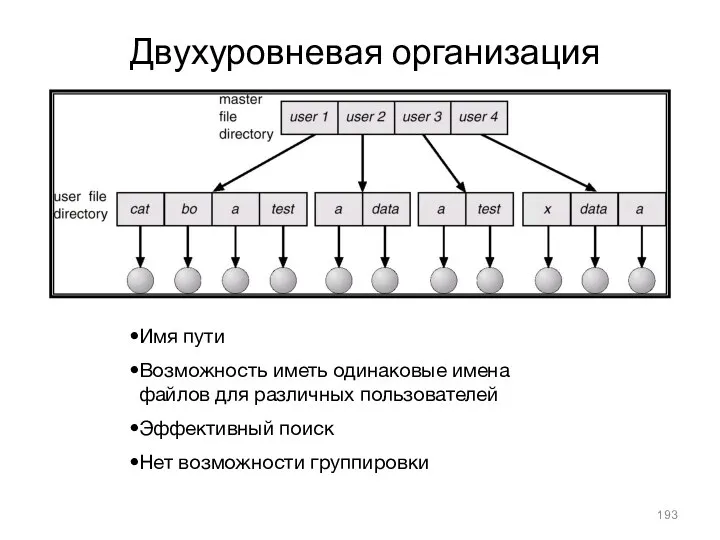
Двухуровневая организация
Имя пути
Возможность иметь одинаковые имена файлов для различных пользователей
Эффективный поиск
Нет
Двухуровневая организация
Имя пути
Возможность иметь одинаковые имена файлов для различных пользователей
Эффективный поиск
Нет
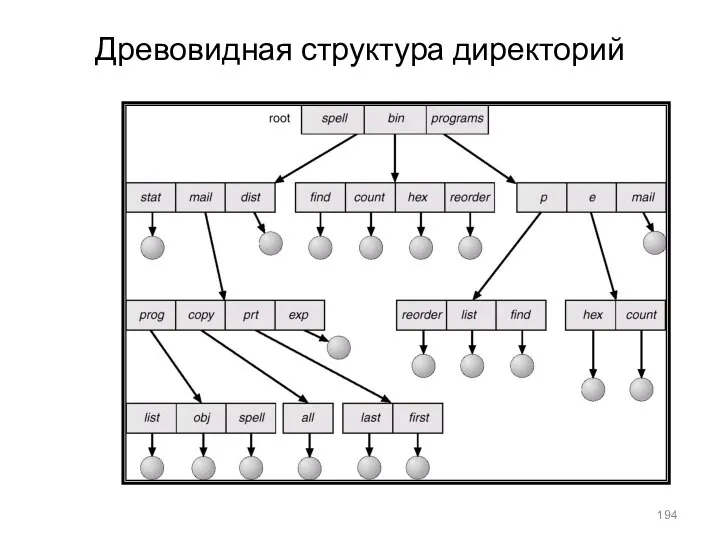
Древовидная структура директорий
Древовидная структура директорий
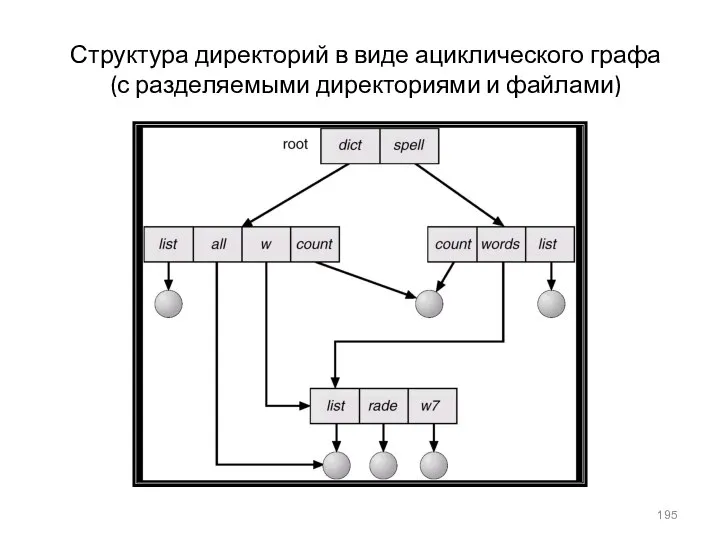
Структура директорий в виде ациклического графа (с разделяемыми директориями и файлами)
Структура директорий в виде ациклического графа (с разделяемыми директориями и файлами)
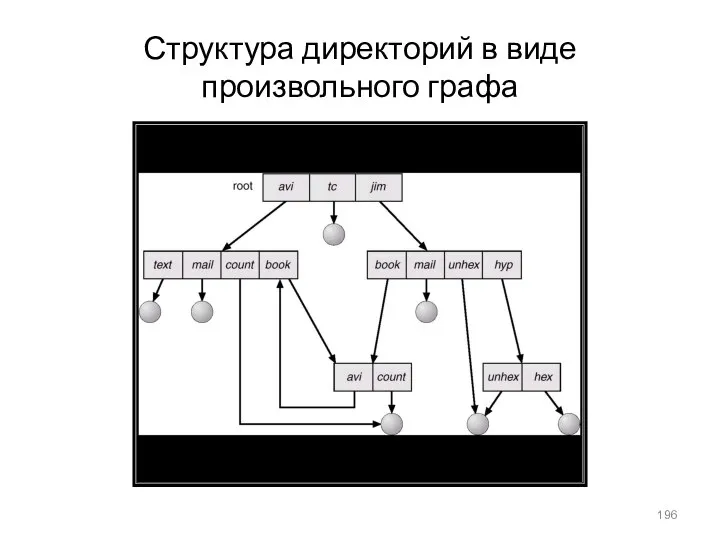
Структура директорий в виде произвольного графа
Структура директорий в виде произвольного графа
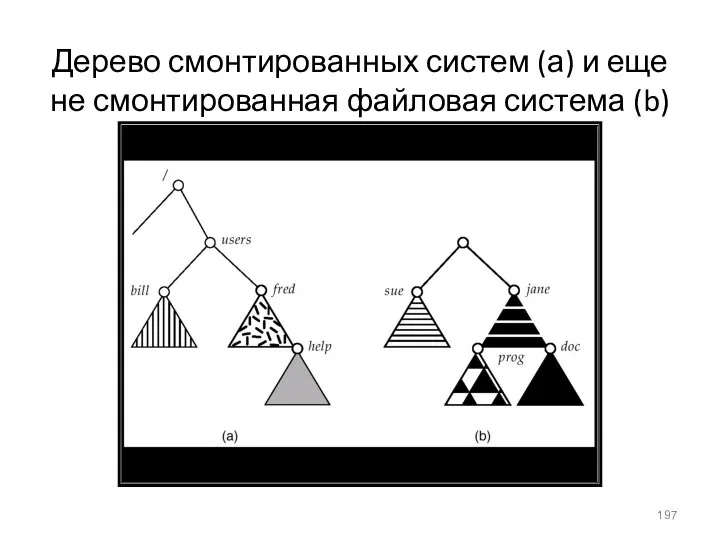
Дерево смонтированных систем (а) и еще не смонтированная файловая система (b)
Дерево смонтированных систем (а) и еще не смонтированная файловая система (b)
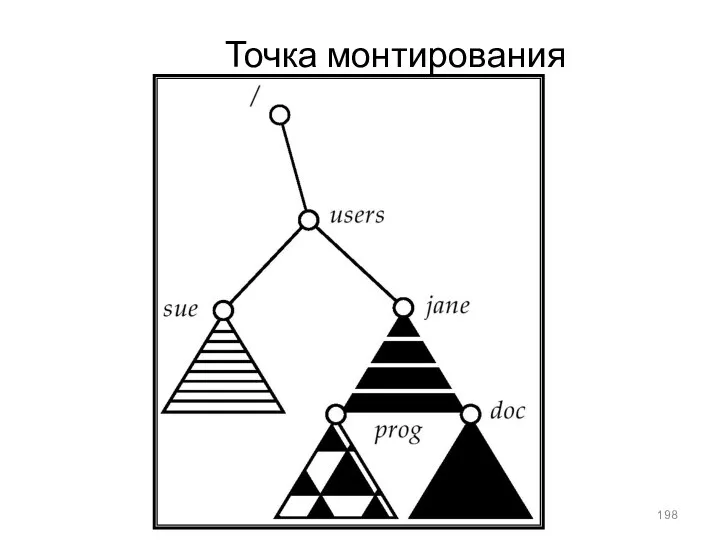
Точка монтирования
Точка монтирования

Защита (protection)
Создатель файла должен иметь возможность управлять:
Списком допустимых операций над файлом
Списком
Защита (protection)
Создатель файла должен иметь возможность управлять:
Списком допустимых операций над файлом
Списком

Списки доступа и группы (UNIX)
Режимы доступа: read, write, execute
Три класса пользователей:
RWX
a)
Списки доступа и группы (UNIX)
Режимы доступа: read, write, execute
Три класса пользователей:
RWX
a)
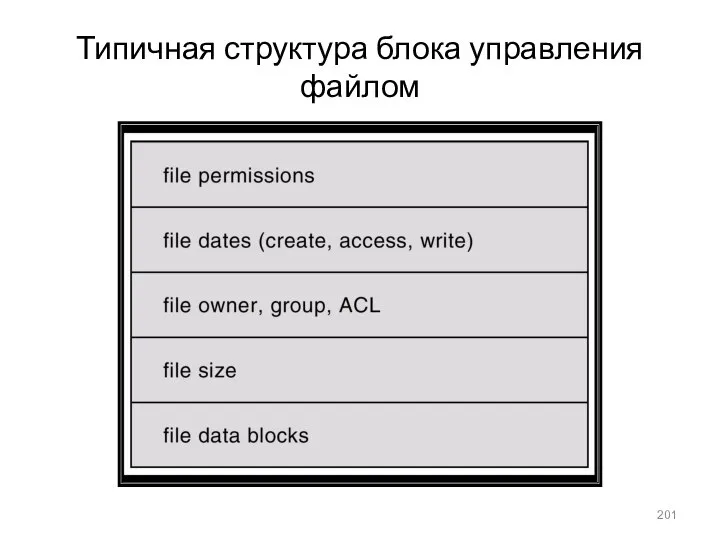
Типичная структура блока управления файлом
Типичная структура блока управления файлом
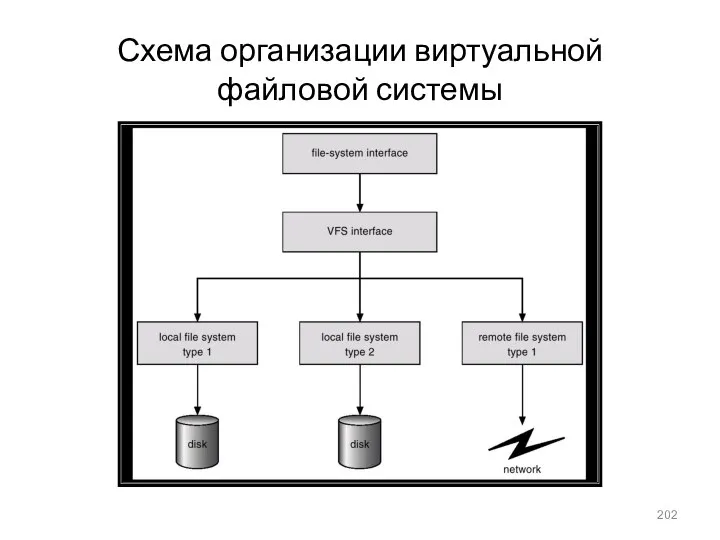
Схема организации виртуальной файловой системы
Схема организации виртуальной файловой системы
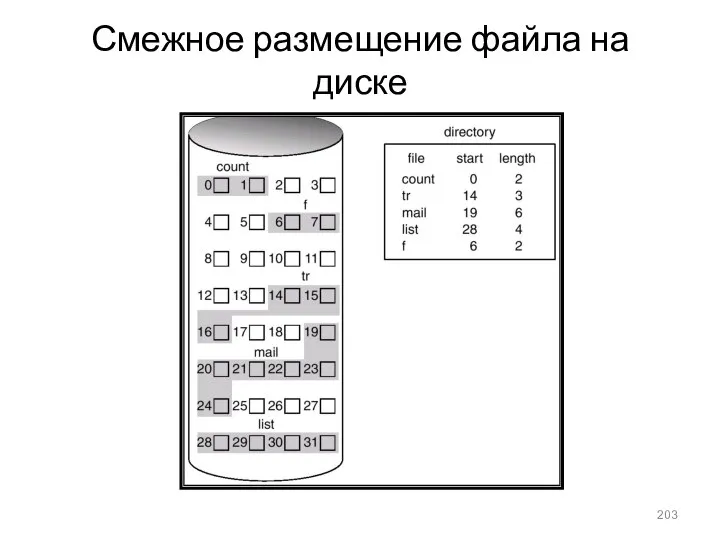
Смежное размещение файла на диске
Смежное размещение файла на диске
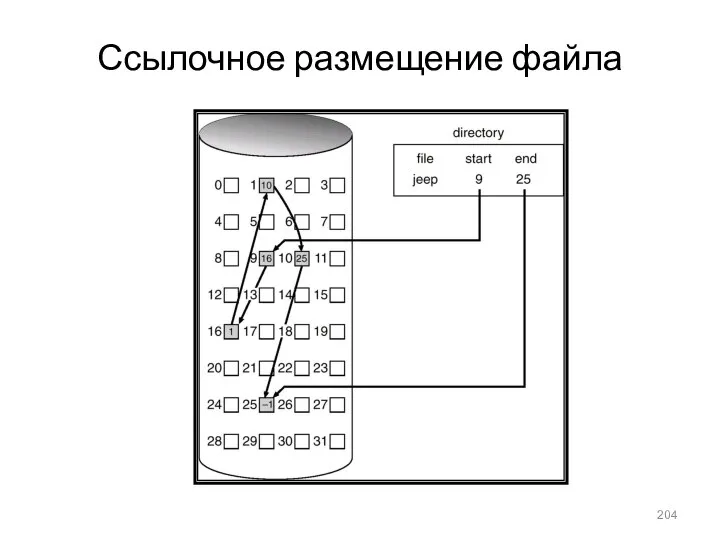
Ссылочное размещение файла
Ссылочное размещение файла
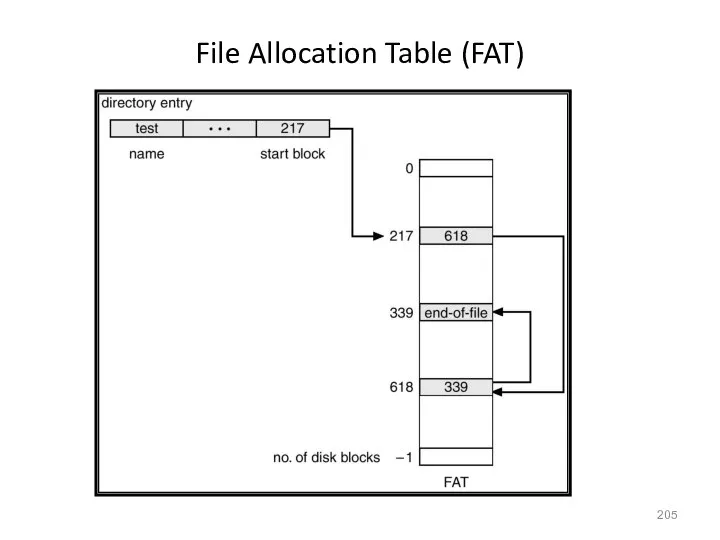
File Allocation Table (FAT)
File Allocation Table (FAT)
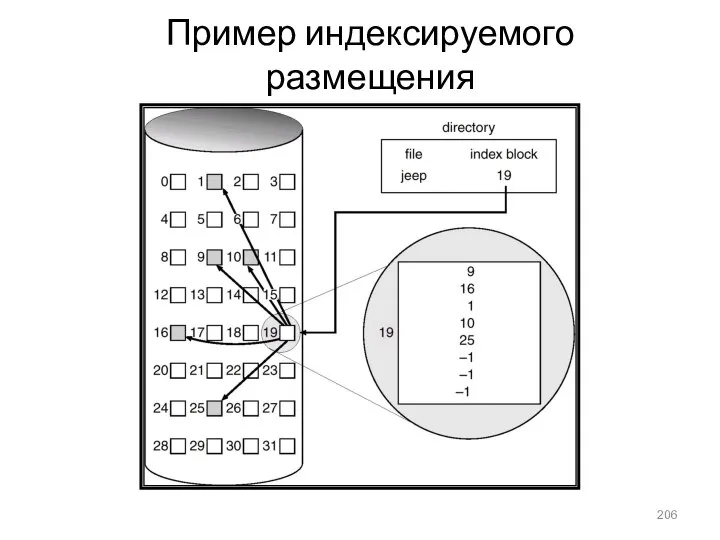
Пример индексируемого размещения
Пример индексируемого размещения

Управление свободной памятью
Битовый вектор (n блоков)
…
0
1
2
n-1
bit[i] =
0 ⇒ block[i] свободен
1 ⇒
Управление свободной памятью
Битовый вектор (n блоков)
…
0
1
2
n-1
bit[i] =
0 ⇒ block[i] свободен
1 ⇒

Управление свободной памятью (прод.)
Битовые шкалы требуют дополнительной памяти. Пример:
размер блока =
Управление свободной памятью (прод.)
Битовые шкалы требуют дополнительной памяти. Пример:
размер блока =
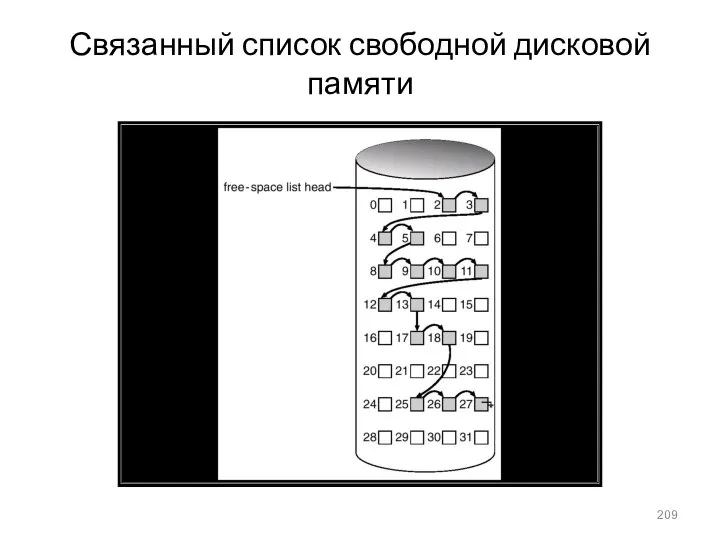
Связанный список свободной дисковой памяти
Связанный список свободной дисковой памяти
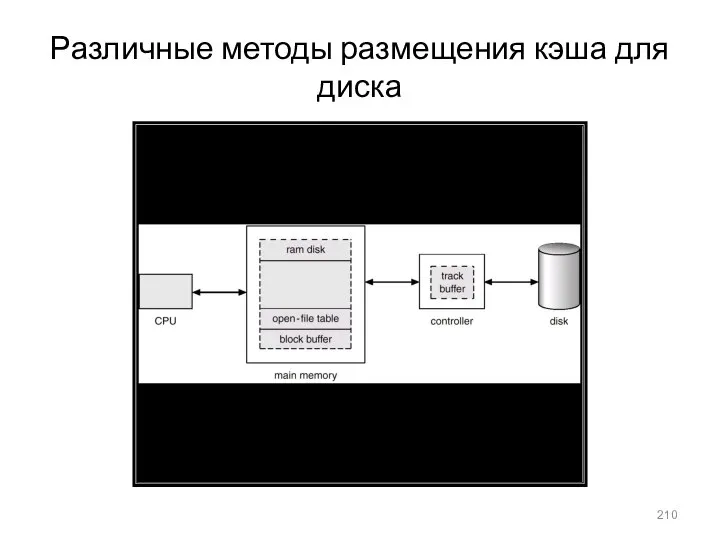
Различные методы размещения кэша для диска
Различные методы размещения кэша для диска
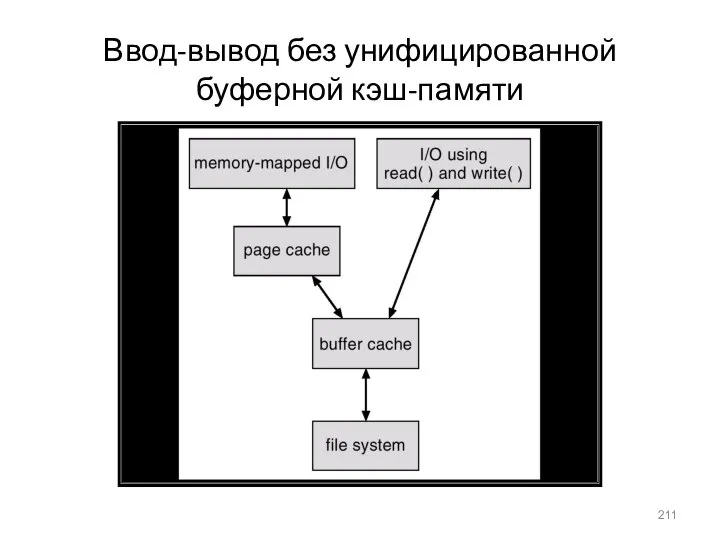
Ввод-вывод без унифицированной буферной кэш-памяти
Ввод-вывод без унифицированной буферной кэш-памяти
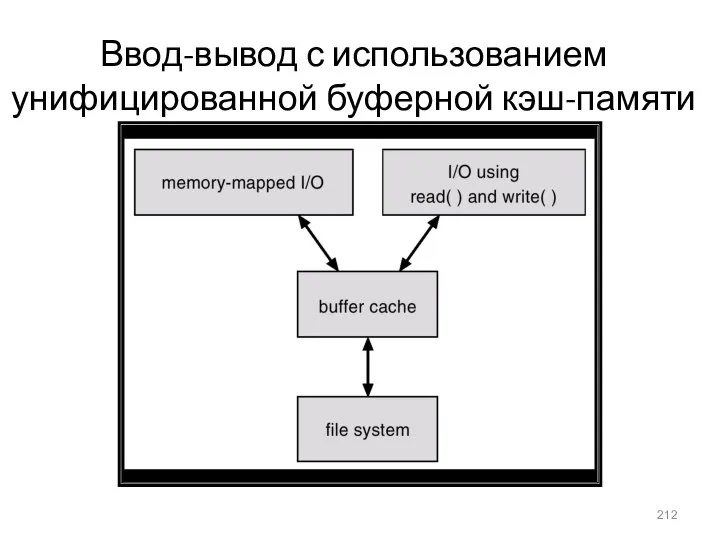
Ввод-вывод с использованием унифицированной буферной кэш-памяти
Ввод-вывод с использованием унифицированной буферной кэш-памяти
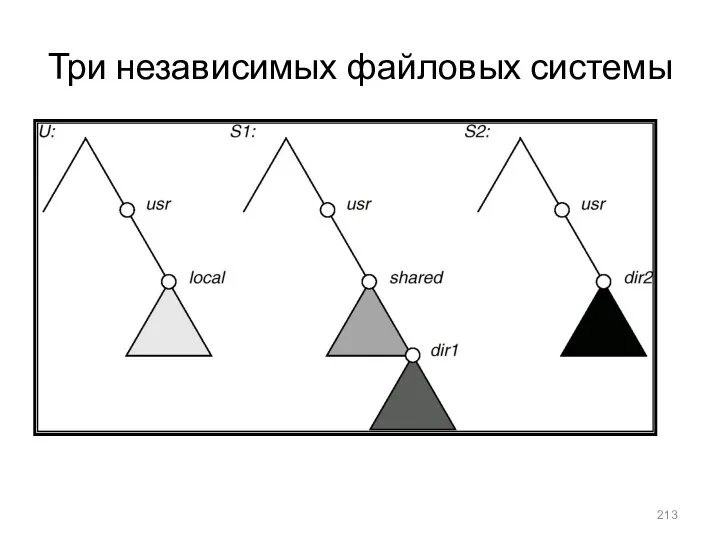
Три независимых файловых системы
Три независимых файловых системы
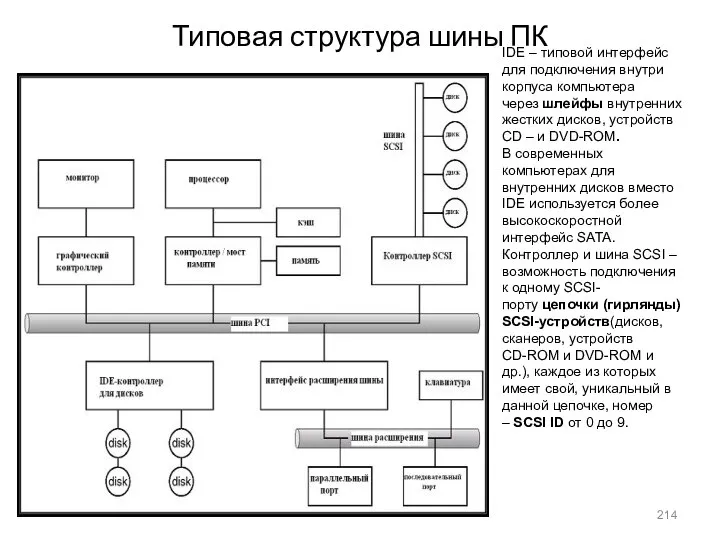
Типовая структура шины ПК
IDE – типовой интерфейс для подключения внутри корпуса
Типовая структура шины ПК
IDE – типовой интерфейс для подключения внутри корпуса

Расположение портов для устройств на ПК (частично)
Расположение портов для устройств на ПК (частично)

Опрос устройств (polling)
Определяет состояние устройства
command-ready – готово к выполнению команд;
busy – занято;
error –
Опрос устройств (polling)
Определяет состояние устройства
command-ready – готово к выполнению команд;
busy – занято;
error –
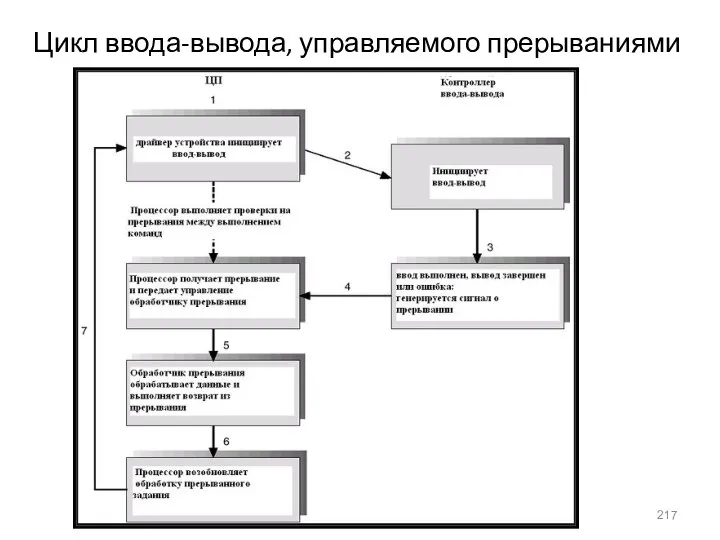
Цикл ввода-вывода, управляемого прерываниями
Цикл ввода-вывода, управляемого прерываниями

Вектор прерываний (событий) в процессоре Intel Pentium
Вектор прерываний – резидентный массив, содержащий
Вектор прерываний (событий) в процессоре Intel Pentium
Вектор прерываний – резидентный массив, содержащий
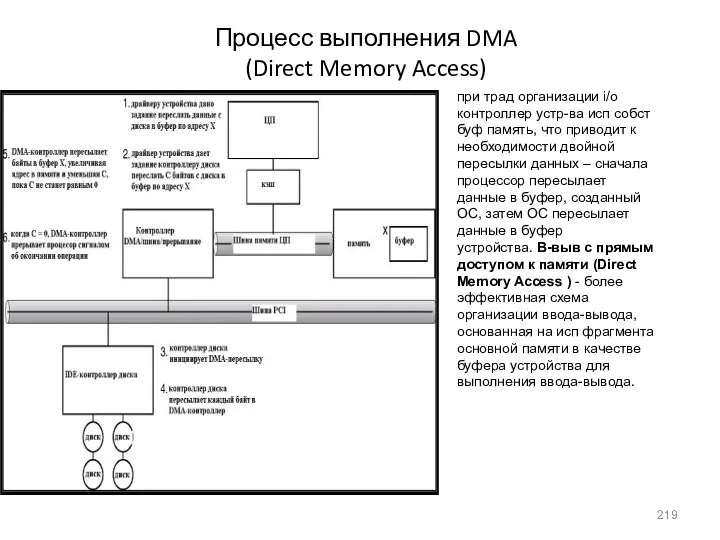
Процесс выполнения DMA
(Direct Memory Access)
при трад организации i/o контроллер устр-ва
Процесс выполнения DMA
(Direct Memory Access)
при трад организации i/o контроллер устр-ва
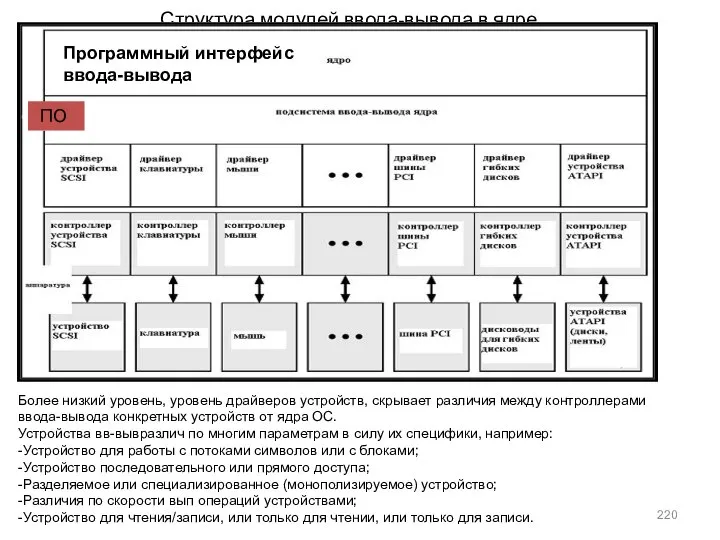
Структура модулей ввода-вывода в ядре
Более низкий уровень, уровень драйверов устройств, скрывает
Структура модулей ввода-вывода в ядре
Более низкий уровень, уровень драйверов устройств, скрывает
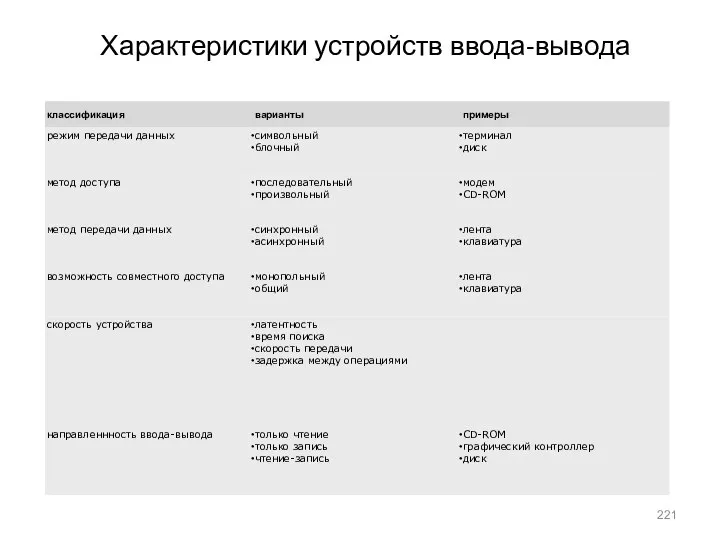
Характеристики устройств ввода-вывода
Характеристики устройств ввода-вывода
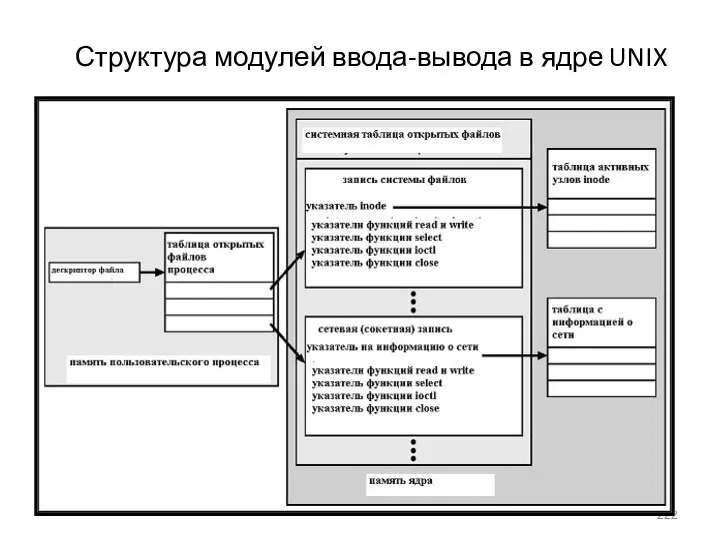
Структура модулей ввода-вывода в ядре UNIX
Структура модулей ввода-вывода в ядре UNIX
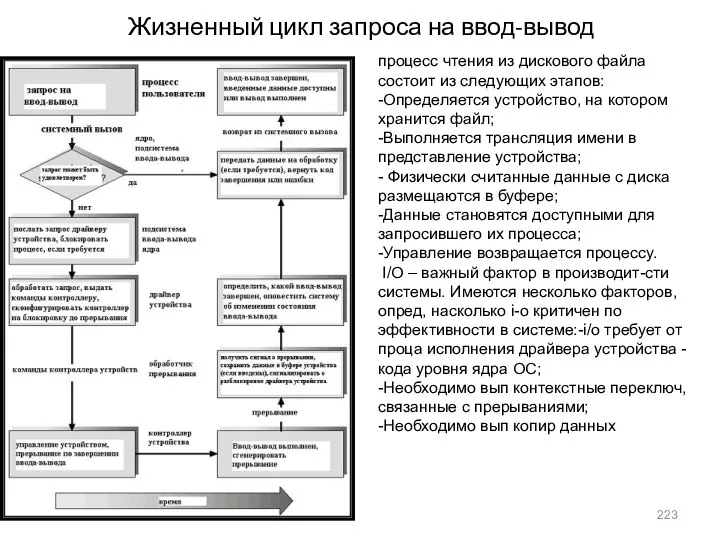
Жизненный цикл запроса на ввод-вывод
процесс чтения из дискового файла состоит из
Жизненный цикл запроса на ввод-вывод
процесс чтения из дискового файла состоит из
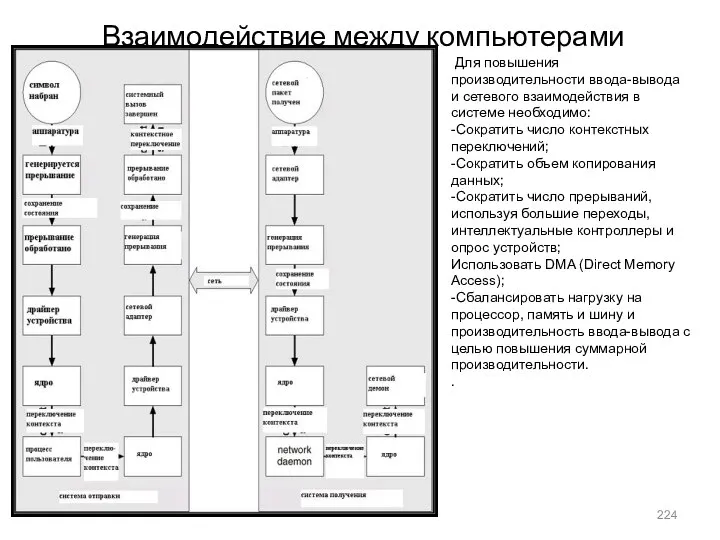
Взаимодействие между компьютерами
Для повышения производительности ввода-вывода и сетевого взаимодействия в системе
Взаимодействие между компьютерами
Для повышения производительности ввода-вывода и сетевого взаимодействия в системе
 Политические кризисы
Политические кризисы Пересечение прямой и плоскости, двух плоскостей
Пересечение прямой и плоскости, двух плоскостей Разделы гражданско-правовой статистики
Разделы гражданско-правовой статистики Финансовое право. Общая и Особенная части
Финансовое право. Общая и Особенная части Политико-правовое учение Полибия Выполнила студентка группы Ю-104 Чуева Яна
Политико-правовое учение Полибия Выполнила студентка группы Ю-104 Чуева Яна Основы проектирования. Детали машин и основы конструирования. Основные понятия деталей машин
Основы проектирования. Детали машин и основы конструирования. Основные понятия деталей машин Всемирный День Борьбы со СПИДом проходит под девизом «Остановим СПИД. Сдержим обещание» 1 декабря
Всемирный День Борьбы со СПИДом проходит под девизом «Остановим СПИД. Сдержим обещание» 1 декабря ОБРАЗОВАТЕЛЬНАЯ СИСТЕМА КАК ОБЪЕКТ УПРАВЛЕНИЯ
ОБРАЗОВАТЕЛЬНАЯ СИСТЕМА КАК ОБЪЕКТ УПРАВЛЕНИЯ рибні тюфтельки, рулет, зрази
рибні тюфтельки, рулет, зрази Правила рукопашного боя
Правила рукопашного боя Основные команды и директивы ATmega16 (продолжение)
Основные команды и директивы ATmega16 (продолжение) «Задачи – это интересно!»
«Задачи – это интересно!» Основатель научной школы проводной связи П. А. Азбукин (1882-1970)
Основатель научной школы проводной связи П. А. Азбукин (1882-1970) Принципы управленческого общения
Принципы управленческого общения Презентация "Объединенные Арабские Эмираты" - скачать презентации по Экономике
Презентация "Объединенные Арабские Эмираты" - скачать презентации по Экономике Памятники культуры
Памятники культуры Графическая среда разработки
Графическая среда разработки Проблема поощрения и наказания младших школьников
Проблема поощрения и наказания младших школьников Пасхальная книжка-раскраска
Пасхальная книжка-раскраска Обработка сигналов при помощи быстрого преобразования Фурье
Обработка сигналов при помощи быстрого преобразования Фурье Введение в SEO
Введение в SEO Санитарно-эпидемиологическое нормирование
Санитарно-эпидемиологическое нормирование Mein Superstar
Mein Superstar УПОЛНОМОЧЕННЫЙ ПО ПРАВАМ человека
УПОЛНОМОЧЕННЫЙ ПО ПРАВАМ человека Исполнительная надпись нотариуса
Исполнительная надпись нотариуса Схема станции М
Схема станции М Родительское собрание на тему: «Трудный диалог с учёбой или как помочь своему ребёнку учиться».
Родительское собрание на тему: «Трудный диалог с учёбой или как помочь своему ребёнку учиться». Зачем Бог сошел на землю. Библия для самых маленьких
Зачем Бог сошел на землю. Библия для самых маленьких