- Ropes или веревочное дерево

Содержание
- 2. ROPE Rope — структура данных для хранения строки, представляющая из себя двоичное сбалансированное дерево и позволяющая
- 3. ROPE В таблице приведены трудоемкости операций очереди с приоритетом:
- 4. Представление ROPE Очевидно что наша структура — это двоичное дерево поиска, в листьях которого находятся элементарные
- 5. Представление ROPE Узлы дерева имеют характеристику — вес. Если в узле дерева хранится непосредственно часть символов
- 6. Представление ROPE Структура будет имет следующий вид: struct trie { char *string; int length; struct trie
- 7. Создание узла ROPE struct trie *trie_create(char *string) { struct trie *node; if ((node = (trie*)malloc(sizeof(*node))) ==
- 8. Операция Merge (Конкатенация строк) Когда приходит запрос на конкатенацию с другой строкой мы объединяем оба дерева,
- 9. Операция Merge (Конкатенация строк) struct trie *merge(struct trie *trie1, struct trie *trie2) { struct trie *node;
- 10. Получение символа по индексу Чтобы получить символ по некоторому индексу , будем спускаться по дереву из
- 11. Получение символа по индексу char get(int i, struct trie *node) { if (node->left != NULL) if
- 12. Split (Разбиение строки) Чтобы разбить строку на две по некоторому индексу необходимо спускаясь по дереву (аналогично
- 13. Split (Разбиение строки) Пускай дано дерево:
- 14. Получение символа по индексу Тогда результатом выполнения операции по индексу будет:
- 15. Возвращение функцией двух узлов Для того, чтобы возвращать сразу два узла, воспользуемся следующей структурой: struct d_trie
- 16. Получение символа по индексу struct d_trie *split(struct trie *node, int i) { struct d_trie *res; res
- 17. Получение символа по индексу if (node->left != NULL) if (node->left->length >= i) { res = split(node->left,
- 18. Операции удаления и вставки Нетрудно понять, что имея операции merge и split, можно легко через них
- 19. Операция удаления struct trie *_delete(struct trie *node, int beginIndex, int endIndex) { struct d_trie *res; res
- 21. Скачать презентацию

ROPE
Rope — структура данных для хранения строки, представляющая из себя двоичное
ROPE
Rope — структура данных для хранения строки, представляющая из себя двоичное
ROPE
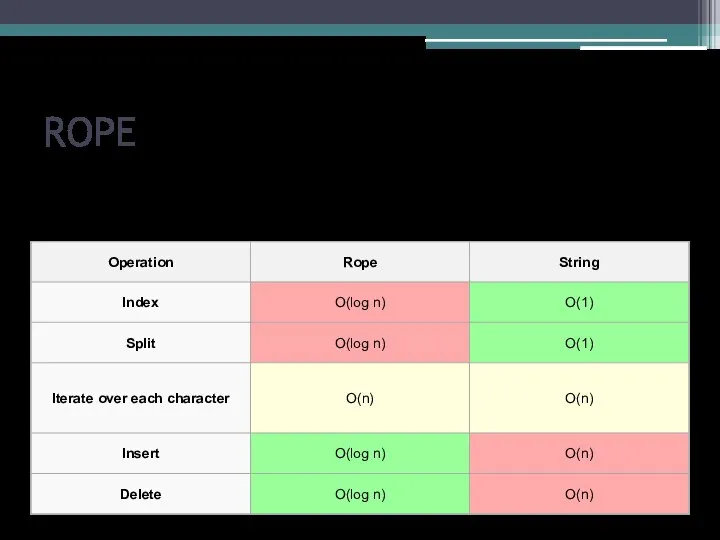
В таблице приведены трудоемкости операций очереди с приоритетом:
ROPE
В таблице приведены трудоемкости операций очереди с приоритетом:
Представление ROPE
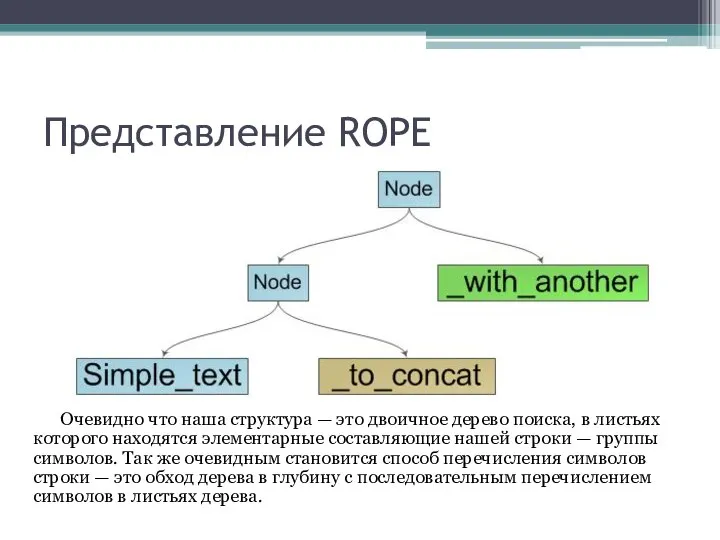
Очевидно что наша структура — это двоичное дерево поиска, в
Представление ROPE
Очевидно что наша структура — это двоичное дерево поиска, в

Представление ROPE
Узлы дерева имеют характеристику — вес. Если в узле дерева
Представление ROPE
Узлы дерева имеют характеристику — вес. Если в узле дерева

Представление ROPE
Структура будет имет следующий вид:
struct trie
{
char *string;
int length;
struct trie *left;
struct
Представление ROPE
Структура будет имет следующий вид:
struct trie
{
char *string;
int length;
struct trie *left;
struct

Создание узла ROPE
struct trie *trie_create(char *string)
{
struct trie *node;
if ((node =
Создание узла ROPE
struct trie *trie_create(char *string)
{
struct trie *node;
if ((node =
Операция Merge (Конкатенация строк)
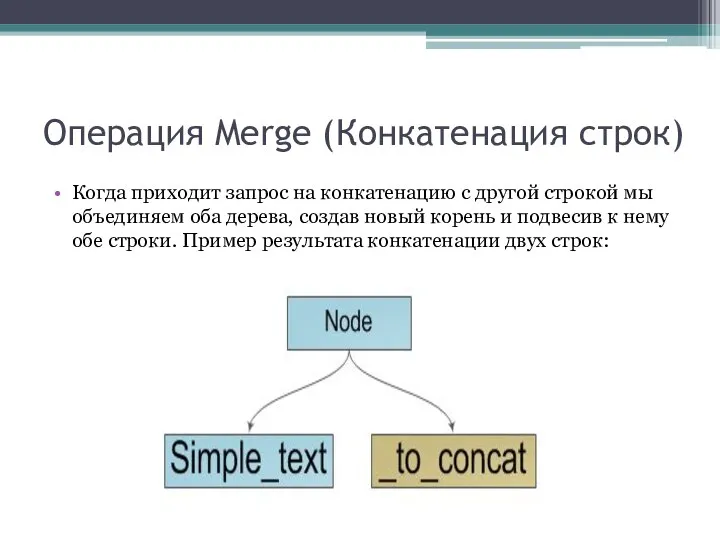
Когда приходит запрос на конкатенацию с другой строкой
Операция Merge (Конкатенация строк)
Когда приходит запрос на конкатенацию с другой строкой

Операция Merge (Конкатенация строк)
struct trie *merge(struct trie *trie1, struct trie *trie2)
{
struct
Операция Merge (Конкатенация строк)
struct trie *merge(struct trie *trie1, struct trie *trie2)
{
struct

Получение символа по индексу
Чтобы получить символ по некоторому индексу , будем спускаться
Получение символа по индексу
Чтобы получить символ по некоторому индексу , будем спускаться

Получение символа по индексу
char get(int i, struct trie *node)
{
if (node->left !=
Получение символа по индексу
char get(int i, struct trie *node)
{
if (node->left !=

Split (Разбиение строки)
Чтобы разбить строку на две по некоторому индексу необходимо спускаясь
Split (Разбиение строки)
Чтобы разбить строку на две по некоторому индексу необходимо спускаясь
Split (Разбиение строки)
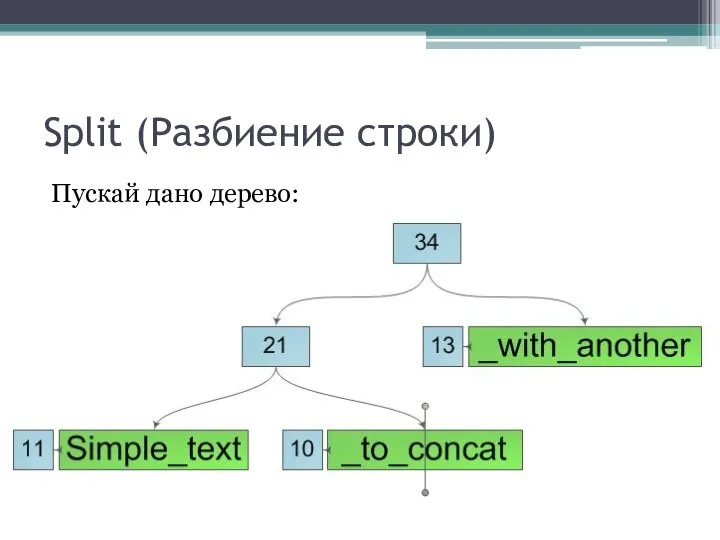
Пускай дано дерево:
Split (Разбиение строки)
Пускай дано дерево:
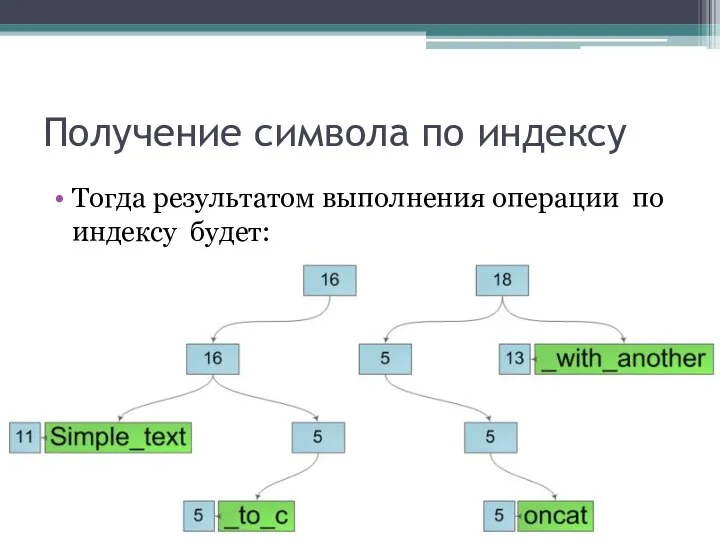
Получение символа по индексу
Тогда результатом выполнения операции по индексу будет:
Получение символа по индексу
Тогда результатом выполнения операции по индексу будет:

Возвращение функцией двух узлов
Для того, чтобы возвращать сразу два узла, воспользуемся
Возвращение функцией двух узлов
Для того, чтобы возвращать сразу два узла, воспользуемся

Получение символа по индексу
struct d_trie *split(struct trie *node, int i)
{
struct d_trie
Получение символа по индексу
struct d_trie *split(struct trie *node, int i)
{
struct d_trie

Получение символа по индексу
if (node->left != NULL)
if (node->left->length >= i)
{
res =
Получение символа по индексу
if (node->left != NULL)
if (node->left->length >= i)
{
res =

Операции удаления и вставки
Нетрудно понять, что имея операции merge и split, можно легко через
Операции удаления и вставки
Нетрудно понять, что имея операции merge и split, можно легко через

Операция удаления
struct trie *_delete(struct trie *node, int beginIndex, int endIndex)
{
struct d_trie
Операция удаления
struct trie *_delete(struct trie *node, int beginIndex, int endIndex)
{
struct d_trie
 Датчик положения дроссельной заслонки в автомобиле
Датчик положения дроссельной заслонки в автомобиле Державні принципи правової організації та функціонування Верховної Ради України в системі органів державної влади
Державні принципи правової організації та функціонування Верховної Ради України в системі органів державної влади Η ελληνική γλώσσα
Η ελληνική γλώσσα Введение в CSS. Селекторы. (Лекция 2)
Введение в CSS. Селекторы. (Лекция 2) Новая Стартовая программа
Новая Стартовая программа Ведущие принципы, функции и методы адаптивной двигательной рекреации
Ведущие принципы, функции и методы адаптивной двигательной рекреации Мы, выпускники 2000 года, благодарим наших любимых учителей за то, что они ввели нас в большой и интересный мир знаний! Мы, выпускники
Мы, выпускники 2000 года, благодарим наших любимых учителей за то, что они ввели нас в большой и интересный мир знаний! Мы, выпускники  Innovative metallurgical technology
Innovative metallurgical technology Олимпийский комитет РФ
Олимпийский комитет РФ Игнац Земмельвайс
Игнац Земмельвайс УЭР промежуточной станции
УЭР промежуточной станции  Национальный проект новая школа
Национальный проект новая школа  Дружба народов РФ
Дружба народов РФ C++ Network Programming Systematic Reuse with ACE & Frameworks
C++ Network Programming Systematic Reuse with ACE & Frameworks Спасо-Прилуцкий монастырь
Спасо-Прилуцкий монастырь Муниципальное бюджетное общеобразовательное учреждение гимназия N 18 г.Нижний Тагил 2011-2012 Автор проекта ученик 1 «Г» класса Абуша
Муниципальное бюджетное общеобразовательное учреждение гимназия N 18 г.Нижний Тагил 2011-2012 Автор проекта ученик 1 «Г» класса Абуша Проектная деятельность и социальное проектирование
Проектная деятельность и социальное проектирование МХК Приготовила ученица 10 «А» класса Дубовая Виктория Учитель: Лукьяненко Н.Н.
МХК Приготовила ученица 10 «А» класса Дубовая Виктория Учитель: Лукьяненко Н.Н.  Ирландские иллюминированные Евангелия
Ирландские иллюминированные Евангелия Массовые формы культурно-досуговой деятельности
Массовые формы культурно-досуговой деятельности ГНОЙНЫЕ ЗАБОЛЕВАНИЯ КОЖИ И ПОДКОЖНОЙ КЛЕЧАТКИ
ГНОЙНЫЕ ЗАБОЛЕВАНИЯ КОЖИ И ПОДКОЖНОЙ КЛЕЧАТКИ Сервисы Google
Сервисы Google Состав административного правонарушения
Состав административного правонарушения  Объемные насосы технических средств службы горючего
Объемные насосы технических средств службы горючего Христиан мәдениеті “Крещение Господне” мерекесі
Христиан мәдениеті “Крещение Господне” мерекесі ЭКОНОМИКА ДЛЯ МЕНЕДЖЕРОВ
ЭКОНОМИКА ДЛЯ МЕНЕДЖЕРОВ  Юзабилити-тестирование в DIRECTUM, или как удивить разработчика
Юзабилити-тестирование в DIRECTUM, или как удивить разработчика Презентация на тему "Что ценного дает коучинг?" - скачать презентации по Педагогике
Презентация на тему "Что ценного дает коучинг?" - скачать презентации по Педагогике