- Строковые потоки и буферы

Содержание
- 2. Функции позиционирования в потоках данных С++ Позиционирование чтения и записи выполняется отдельными функциями (суффикс «g» означает
- 3. Что такое позиция? Что есть тип pos_type? Стандартная библиотека С++ определяет глобальный класс шаблона fpos для
- 4. Что такое относительная позиция? В версиях с относительным позиционированием смещение задается по отношению к трем позициям,
- 5. Пример позиционирования // Заголовочные файлы для ввода-вывода #include #include void printFileTwice (const char* filename) { std::ifstream
- 6. Перенаправление потоков данных Перенаправление потока данных осуществляется назначением потокового буфера. В механизме назначения потоковых буферов перенаправление
- 7. Перенаправление потоков данных - пример #include #include using namespace std; void redirect(ostream&); int main() { cout
- 8. Перенаправление потоков данных - пример void redirect (ostream& strm) { ofstream file("redirect.txt"); streambuf* strm_buffer = strm.rdbuf();
- 9. Потоки чтения и записи Обычно файл открывается для чтения/записи при помощи класса fstream: std::fstream file ("example.txt",
- 10. Потоки чтения и записи Еще вариант - создать буфер файлового потока данных и назначить его обоим
- 11. Потоки чтения и записи - пример #include #include using namespace std; void main() { // Открытие
- 12. Потоки чтения и записи - пример Хотя для чтения и записи используются два разных объекта потоков
- 13. Потоковые классы для работы со строками Механизм потоковых классов также может использоваться для чтения или записи
- 14. Классы строковых потоков данных Для строк определены следующие потоковые классы, которые явля-ются аналогами соответствующих классов файловых
- 15. . Иерархия классов cтроковых потоков данных ios_base basic_streambuf streambuf / wstreambuf basic_ios ios / wios basic_istream
- 16. Основные операции со строковыми потоками данных Основная операция реализуется функциями: str() - возвращает буфер в виде
- 17. Операции со строковыми потоками данных При создании строковых потоков данных могут задаваться флаги режима открытия файла
- 18. Правила построения пользовательских операторов ввода-вывода Правила, которые должны соблюдаться в пользовательских реализациях операторов ввода-вывода. Они продиктованы
- 19. Классы потоковых буферов – вывод символов Потоки данных не выполняют непосредственные операции чтения и записи, а
- 20. Классы потоковых буферов – ввод символов При вводе иногда требуется узнать символ без его извлечения из
- 21. Потоковые буфера – ввод символов Функция in_avail() проверяет минимальное количество доступных символов. Например, с ее помощью
- 22. Потоковые буфера – другие функции Отдельная группа функций используется для подключения объекта локального контекста, для смены
- 23. Потоковые буфера – другие функции - пояснения Функция pubsetbuf() позволяет в определенной степени управлять стратегией буферизации
- 24. Синхронизация со стандартными потоками данных С По умолчанию восемь стандартных потоков данных С++ (четыре символь-ных потока
- 25. Непосредcтвенная работа с потоковыми буферами Все функции классов basic_istream и basic_ostream, выполняющие чтение или запись символов,
- 26. Непосредcтвенная работа с потоковыми буферами ( Для этого можно определить для потоковых буферов операторы >. (1)
- 27. Непосредcтвенная работа с потоковыми буферами (>>) При получении указателя на потоковый буфер оператор >> выполняет прямое
- 28. Интернационализация С развитием глобального рынка интернaционализация стала играть более важную роль в разработке программного обеспечения. По
- 29. Поддержка разных кодировок символов Существуют два основных принципа определения кодировок, содержащих более 256 символов: много6айтовое и
- 30. Трактовки символов Различия в кодировках существенны для обработки строк и ввода-вывода. Строковые и потоковые классы специализируются
- 31. Классы трактовки символов - функции
- 32. Классы трактовки символов – функции (дальше)
- 33. Концепция локального контекста Распространенный подход к интернационализации основан на использовании специальных сред, называемых локальными контекстами (locale)
- 34. Фацеты На функциональном уровне локальный контекст делится на несколько специальных объектов. Объект, обеспечивающий работу некоторого аспекта
- 35. Категории фацетов стандартной библиотеки С++
- 36. Фацеты - использование Определение собственных версий фацетов позволяет создавать специализированные локальные контексты. В следующем примере показано,
- 37. Тесты … Вопрос: Какой вывод будет у этой программы? #include int main() { std::cout (*(new int(5)));
- 38. Тесты … Вопрос: Какой вывод будет у этой программы? #include int main() { std::cout (*(new int(5)));
- 39. Тесты … Вопрос: Что произойдет при попытке скомпилировать и исполнить нижеприведенный код? class CBase { public:
- 41. Скачать презентацию
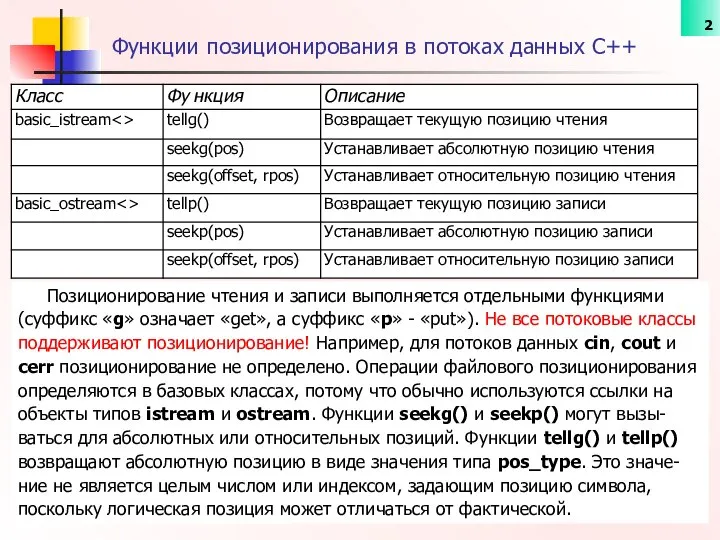
Функции позиционирования в потоках данных С++
Позиционирование чтения и записи выполняется отдельными
Функции позиционирования в потоках данных С++
Позиционирование чтения и записи выполняется отдельными

Что такое позиция?
Что есть тип pos_type? Стандартная библиотека С++ определяет глобальный
Что такое позиция?
Что есть тип pos_type? Стандартная библиотека С++ определяет глобальный

Что такое относительная позиция?
В версиях с относительным позиционированием смещение задается по
Что такое относительная позиция?
В версиях с относительным позиционированием смещение задается по

Пример позиционирования
// Заголовочные файлы для ввода-вывода
#include
#include
void printFileTwice (const char*
Пример позиционирования
// Заголовочные файлы для ввода-вывода
#include
#include
void printFileTwice (const char*

Перенаправление потоков данных
Перенаправление потока данных осуществляется назначением потокового буфера.
В механизме назначения
Перенаправление потоков данных
Перенаправление потока данных осуществляется назначением потокового буфера.
В механизме назначения

Перенаправление потоков данных - пример
#include
#include
using namespace std;
void redirect(ostream&);
int main()
{
Перенаправление потоков данных - пример
#include
#include
using namespace std;
void redirect(ostream&);
int main()
{

Перенаправление потоков данных - пример
void redirect (ostream& strm)
{
ofstream file("redirect.txt");
Перенаправление потоков данных - пример
void redirect (ostream& strm)
{
ofstream file("redirect.txt");

Потоки чтения и записи
Обычно файл открывается для чтения/записи при помощи класса
Потоки чтения и записи
Обычно файл открывается для чтения/записи при помощи класса

Потоки чтения и записи
Еще вариант - создать буфер файлового потока данных
Потоки чтения и записи
Еще вариант - создать буфер файлового потока данных

Потоки чтения и записи - пример
#include
#include
using namespace std;
void main()
{
Потоки чтения и записи - пример
#include
#include
using namespace std;
void main()
{

Потоки чтения и записи - пример
Хотя для чтения и записи используются
Потоки чтения и записи - пример
Хотя для чтения и записи используются

Потоковые классы для работы со строками
Механизм потоковых классов также может использоваться
Потоковые классы для работы со строками
Механизм потоковых классов также может использоваться

Классы строковых потоков данных
Для строк определены следующие потоковые классы, которые явля-ются
Классы строковых потоков данных
Для строк определены следующие потоковые классы, которые явля-ются
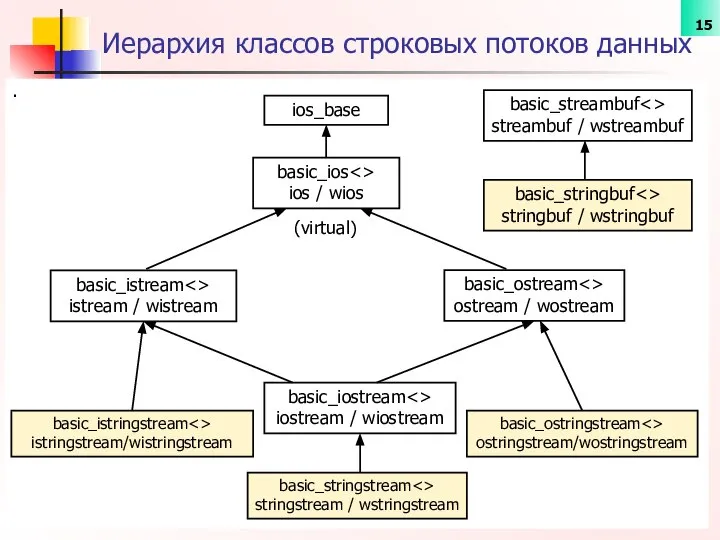
.
Иерархия классов cтроковых потоков данных
ios_base
basic_streambuf<>
streambuf / wstreambuf
basic_ios<>
ios / wios
basic_istream<> istrеаm /
.
Иерархия классов cтроковых потоков данных
ios_base
basic_streambuf<>
streambuf / wstreambuf
basic_ios<>
ios / wios
basic_istream<> istrеаm /

Основные операции со строковыми потоками данных
Основная операция реализуется функциями:
str() - возвращает
Основные операции со строковыми потоками данных
Основная операция реализуется функциями:
str() - возвращает

Операции со строковыми потоками данных
При создании строковых потоков данных могут задаваться
Операции со строковыми потоками данных
При создании строковых потоков данных могут задаваться

Правила построения пользовательских
операторов ввода-вывода
Правила, которые должны соблюдаться в пользовательских реализациях операторов
Правила построения пользовательских
операторов ввода-вывода
Правила, которые должны соблюдаться в пользовательских реализациях операторов

Классы потоковых буферов – вывод символов
Потоки данных не выполняют непосредственные операции
Классы потоковых буферов – вывод символов
Потоки данных не выполняют непосредственные операции

Классы потоковых буферов – ввод символов
При вводе иногда требуется узнать символ
Классы потоковых буферов – ввод символов
При вводе иногда требуется узнать символ

Потоковые буфера – ввод символов
Функция in_avail() проверяет минимальное количество доступных символов.
Потоковые буфера – ввод символов
Функция in_avail() проверяет минимальное количество доступных символов.
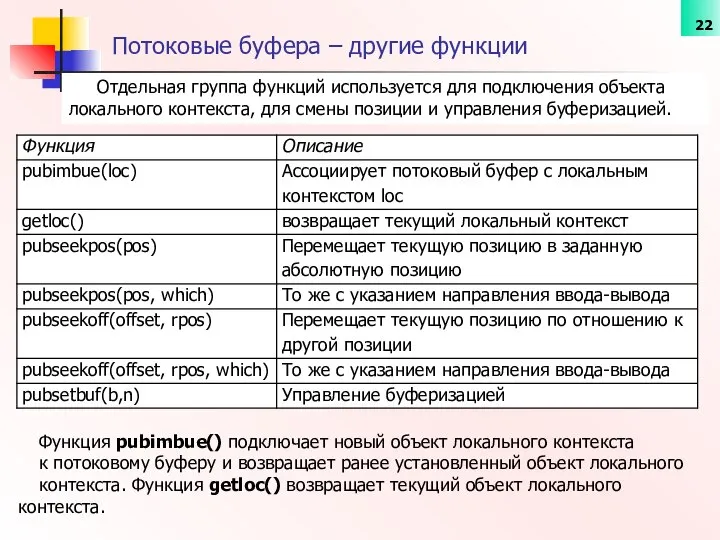
Потоковые буфера – другие функции
Отдельная группа функций используется для подключения объекта
Потоковые буфера – другие функции
Отдельная группа функций используется для подключения объекта

Потоковые буфера – другие функции - пояснения
Функция pubsetbuf() позволяет в определенной
Потоковые буфера – другие функции - пояснения
Функция pubsetbuf() позволяет в определенной

Синхронизация со стандартными потоками данных С
По умолчанию восемь стандартных потоков данных
Синхронизация со стандартными потоками данных С
По умолчанию восемь стандартных потоков данных

Непосредcтвенная работа с потоковыми буферами
Все функции классов basic_istream и basic_ostream, выполняющие
Непосредcтвенная работа с потоковыми буферами
Все функции классов basic_istream и basic_ostream, выполняющие

Непосредcтвенная работа с потоковыми буферами (<<)
Для этого можно определить для потоковых
Непосредcтвенная работа с потоковыми буферами (<<)
Для этого можно определить для потоковых

Непосредcтвенная работа с потоковыми буферами (>>)
При получении указателя на потоковый буфер
Непосредcтвенная работа с потоковыми буферами (>>)
При получении указателя на потоковый буфер

Интернационализация
С развитием глобального рынка интернaционализация стала играть более важную роль
Интернационализация
С развитием глобального рынка интернaционализация стала играть более важную роль

Поддержка разных кодировок символов
Существуют два основных принципа определения кодировок, содержащих более
Поддержка разных кодировок символов
Существуют два основных принципа определения кодировок, содержащих более

Трактовки символов
Различия в кодировках существенны для обработки строк и ввода-вывода.
Строковые
Трактовки символов
Различия в кодировках существенны для обработки строк и ввода-вывода.
Строковые
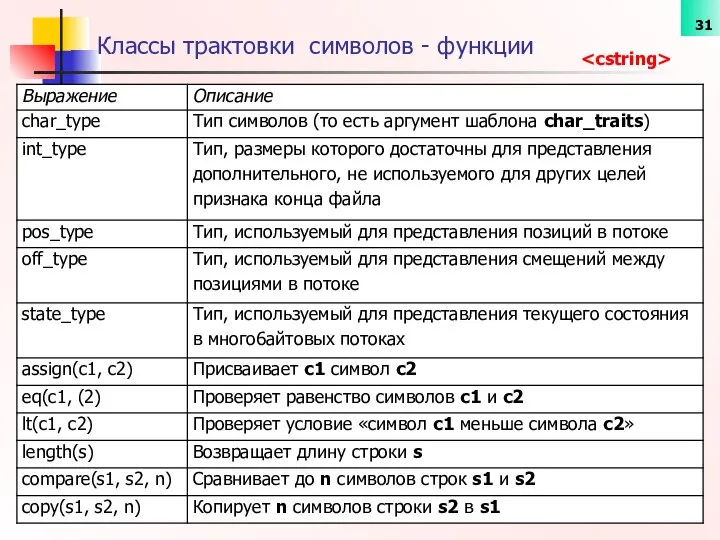
Классы трактовки символов - функции
Классы трактовки символов - функции
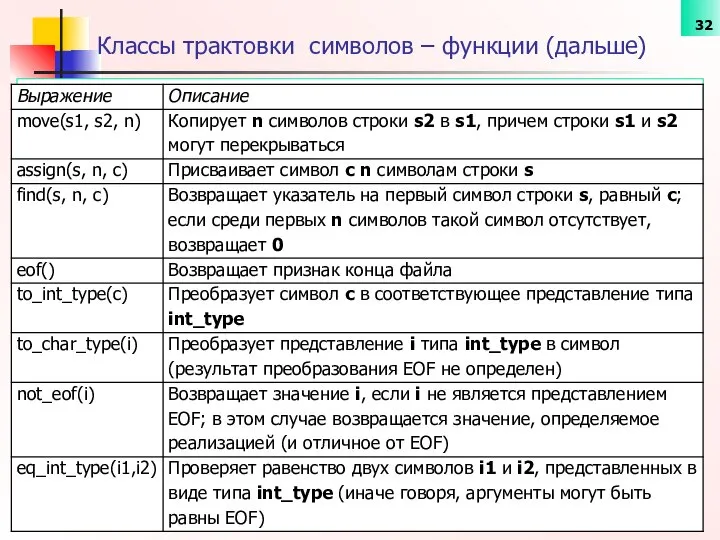
Классы трактовки символов – функции (дальше)
Классы трактовки символов – функции (дальше)

Концепция локального контекста
Распространенный подход к интернационализации основан на использовании специальных сред,
Концепция локального контекста
Распространенный подход к интернационализации основан на использовании специальных сред,

Фацеты
На функциональном уровне локальный контекст делится на несколько специальных объектов. Объект,
Фацеты
На функциональном уровне локальный контекст делится на несколько специальных объектов. Объект,
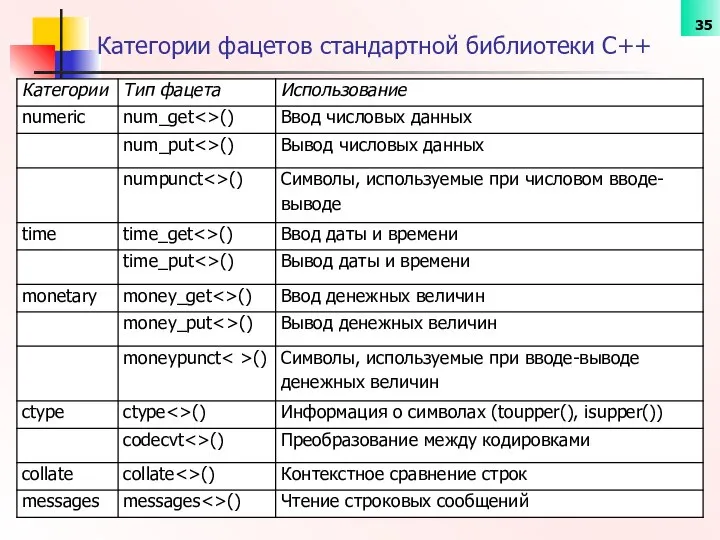
Категории фацетов стандартной библиотеки С++
Категории фацетов стандартной библиотеки С++

Фацеты - использование
Определение собственных версий фацетов позволяет создавать специализированные локальные контексты.
Фацеты - использование
Определение собственных версий фацетов позволяет создавать специализированные локальные контексты.

Тесты …
Вопрос: Какой вывод будет у этой программы?
#include
int main()
Тесты …
Вопрос: Какой вывод будет у этой программы?
#include
int main()
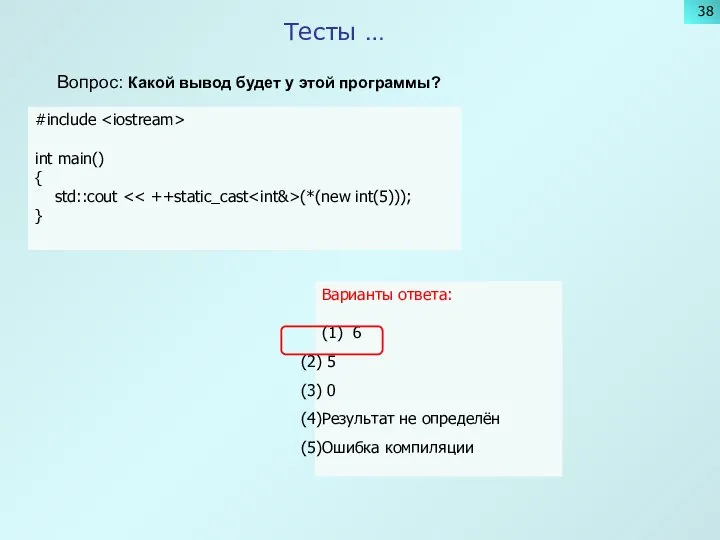
Тесты …
Вопрос: Какой вывод будет у этой программы?
#include
int main()
Тесты …
Вопрос: Какой вывод будет у этой программы?
#include
int main()

Тесты …
Вопрос: Что произойдет при попытке скомпилировать и исполнить нижеприведенный код?
class
Тесты …
Вопрос: Что произойдет при попытке скомпилировать и исполнить нижеприведенный код?
class
 Презентация "Булгаков Михаил" - скачать презентации по МХК
Презентация "Булгаков Михаил" - скачать презентации по МХК Причины коррупции в сфере государственной службы
Причины коррупции в сфере государственной службы Заболевания наружного уха, острый средний отит, мастоидит
Заболевания наружного уха, острый средний отит, мастоидит  Niedersachsen
Niedersachsen Искусство Древнего Китая
Искусство Древнего Китая Россия в XVII веке. Образование, наука и общественное мнение
Россия в XVII веке. Образование, наука и общественное мнение Презентация Структура денежно-кредитного рынка
Презентация Структура денежно-кредитного рынка Электронная почта
Электронная почта Повторение условного оператора
Повторение условного оператора Монументально-декоративное искусство Японии
Монументально-декоративное искусство Японии Беларусь і праблемы міжнароднай бяспекі ў 2000-х гг. Пагрозы
Беларусь і праблемы міжнароднай бяспекі ў 2000-х гг. Пагрозы Доклад на тему: «Педагогика и психология.» Выполнила: Студентка 1 курса 11 группы Сегень Екатерина Руководитель: Москалёва О
Доклад на тему: «Педагогика и психология.» Выполнила: Студентка 1 курса 11 группы Сегень Екатерина Руководитель: Москалёва О Дроссели и трансформаторы источников питания
Дроссели и трансформаторы источников питания Предложение. Эластичность предложения. Работа выполнена учителем экономики МОУ СОШ № 4 Г. Сосновый Бор Ефимовой Е.В.
Предложение. Эластичность предложения. Работа выполнена учителем экономики МОУ СОШ № 4 Г. Сосновый Бор Ефимовой Е.В.  Заполнители из природных плотных каменных пород
Заполнители из природных плотных каменных пород Физическая подготовка альпиниста
Физическая подготовка альпиниста Культура эпохи Возрождения Это,несомненно,золотой век, который вернул свет свободным искусствам.
Культура эпохи Возрождения Это,несомненно,золотой век, который вернул свет свободным искусствам. Основные направления социальной политики Вьетнама
Основные направления социальной политики Вьетнама  Бөлмелер экспликациясы
Бөлмелер экспликациясы Аттестационная работа. Методическая разработка “Датчик воды для Ардуино своими руками”
Аттестационная работа. Методическая разработка “Датчик воды для Ардуино своими руками” Внедрение игровой робототехники в образовательное пространство ОУ СПО
Внедрение игровой робототехники в образовательное пространство ОУ СПО Свадебная атрибутика славян
Свадебная атрибутика славян Обозначения условные приборов и средств автоматизации в схемах
Обозначения условные приборов и средств автоматизации в схемах Производная степенной функции
Производная степенной функции Предметные недели: нетрадиционный подход. И мы сохраним, тебя, русская речь, Великое русское слово. Анна Ахматова.
Предметные недели: нетрадиционный подход. И мы сохраним, тебя, русская речь, Великое русское слово. Анна Ахматова. Схемо- и системотехника электронных средств
Схемо- и системотехника электронных средств Легенда о Святом Валентине. День Святого Валентина в разных странах
Легенда о Святом Валентине. День Святого Валентина в разных странах Организационно-функциональная структура государственного управления в Республике Казахстан
Организационно-функциональная структура государственного управления в Республике Казахстан