- Суперкомпьютерные системы

Содержание
- 2. План История Типы суперкомпьютерных систем Векторно-конвейерные Массивно-параллельные NUMA – с неоднородным доступом к памяти Высокопроизводительные кластеры
- 3. Литература Суперкомпьютерные системы http://www.top500.org/ORSC/2004/ Транспьютеры http://maven.smith.edu/~thiebaut/transputer/descript.html Метакомпьютеры http://setiathome.ssl.berkeley.edu/ GRID системы http://www.grid.org
- 4. Исторические сведения Первые векторные, конвейерные и суперскалярные процессоры CDC 1960-года CRAY - CDC 1976 В СССР
- 5. Типы суперкомпьютерных систем Векторные (PVP, array, matrix, векторно-конвейерные vector-pipeline) компьютеры Массивно-параллельные суперкомпьютеры NUMA системы
- 6. Векторно-конвейерные суперкомпьютеры Сray Y-MP C90 Конец 1980-х До 16 процессоров с тактовой частотой до 250 МГц
- 7. Структура Векторно-конвейерные процессоры подключены к общей памяти как SMP Отсутствует кэш Каждый процессор может взаимодействовать с
- 8. Память До 1024 банков К разным банкам можно обращаться одновременно При обращении к одном банку задержка
- 9. Секция ввода-вывода Для связи с внешними устройствами и обмена информацией Low-speed (LOSP) channels - 6 Mbytes/s
- 10. Блок взаимодействия между процессорами Для быстрой передачи данных между процессорами (задержка 1 такт) Несколько коммуникационных кластеров
- 11. Векторно-конвейерный процессор Команды считываются блоками Все операции являются конвейерными Все функциональные устройства могут работать параллельно Векторные
- 12. Особенности использования PVP Эффективны для выполнения большого количества однотипных (векторных, матричных) вычислений Не эффективны, если операции
- 13. Транспьютеры Микропроцессоры, специально разработанные для параллельных вычислений 1980-е года компания INMOS Основная идея - возможность непосредственного
- 14. Особенности Транспьютер: Процессор Память Соединения До 4-х соединений с соседними процессорами
- 15. Массивно-параллельные компьютеры Набор блоков с общей памятью (UP, SMP, PVP) соединенных с помощью коммуникационной подсистемы Массивно-параллельные
- 16. Особенности систем Масштабируемость Легко расширяются установкой новых блоков Может быть большое количество процессоров (несколько тысяч в
- 17. Особенности использования Передача данных между блоками требует значительно большего времени, чем внутри блока Передача данных между
- 18. Реализации CRAY T3E IBM SP2 Классические большие суперкомпьютеры
- 19. IBM SP2 Процессоры Power 2 Узел Узлы IBM RS/6000 До 16 CPU До 16 узлов +
- 20. CRAY T3D топология 3D тор До 512 векторно-конвейерных процессорных блоков
- 21. NUMA системы NUMA – неоднородный доступ к памяти Набор SMP плат, связанных коммутатором Доступ процессоров к
- 22. Особенности Те же, что у SMP Когерентность кэшей ccNUMA –аппаратное обеспечение когерентности Программное обеспечение когерентности Обеспечение
- 23. SGI Altix 3000 Несколько блоков Связь NUMALink 3 – 3.2 Гбайт/с В сумме до 512 процессоров
- 24. Кластеры Кластер – набор вычислительных систем, которые могут работать независимо, связаны между собой и используются как
- 25. Особенности кластеров Все узлы кластера являются вычислительными системами, которые выполняют свою копию ядра операционной системы Кластер
- 26. Использование кластеров High Performance Clusters, HPC high availability cluster, HAC load balancing cluster, virtual server Storage
- 27. Вопросы стоимости Закон Гроша (Grosch) стоимость суперкомпьютера пропорциональна квадрату его производительности Для микропроцессорных систем перестал действовать,
- 28. Другие классификации кластеров Гомогенный Все машины кластера одинаковы (в определенном контексте) Гетерогенный Машины кластера – различны
- 29. Исторические сведения Мультикомпьютерные системы Конец 1970-х годов Первый промышленный кластер 1983 г VAX кластер, DEC Промышленные
- 30. Метакомпьютеры Метакомпьютеры – использование существующих (простаивающих) компьютерных ресурсов для решения задач Компьютерный класс Компьютеры в пределах
- 31. Использование мощности существующих компьютеров В ночное время компьютеры часто простаивают Потенциальная мощность простаивающих компьютеров может быть
- 32. Существующие проекты Обработка данных с радиотелескопов по поиску внеземных цивилизаций http://setiathome.ssl.berkeley.edu/ Взломы алгоритмов шифрования http://www.distributed.net/
- 33. GRID системы GRID – сеть Метакомпьютеры промышленного уровня Объединение компьютерных ресурсов в одну систему через Интернет
- 34. Lagre Hadron Colider - ускоритель Франция Швейцария 4.5 км LHC
- 35. Объемы вычислений Объём LHC данных соответствует примерно 20 миллионам CD ежегодно! требует компьютерной мощности эквивалентной ~
- 36. Структурная схема Информационная система (LDAP) Брокер ресурсов Вычислительный элемент Вычислительный элемент Элемент хранения Вычислительный элемент Элемент
- 37. Реализации Инструментарий Globus Condor Грид системы EDG ALIEN LCG
- 38. Средства коммуникации для кластерных систем Кластер в основном управляется программно Средства коммуникации – наиболее критичная аппаратная
- 39. Технологии коммуникации Ethernet Fast Ethernet Gigabit Ethernet 10Gigabit Ethernet Myrinet SCI Infiniband QSNet cLan GigaNet
- 40. Характеристики средств коммуникации Скорость передачи данных Сколько времени занимает передача единицы информации Латентность (начальная задержка) Сколько
- 41. Ethernet Среда Медь оптика Скорость передачи Fast 100 Mbit/c (125 Mбайт/с) Gigabit 1000 Мбит/с Латентность Fast
- 42. Myrinet (www.myri.com) Среда Медь Оптика Скорость передачи до 10 Gbit/c Латентность От 5 мкс Топология Звезда
- 43. SCI (dolphinics.com) Среда Медь (шлейф) Скорость передачи До 8008 Мбайт/с Задержка 1.2 мкс ! Топология Линейка
- 44. QSNet (quadrix.com) Среда Медь (параллельная шина) Скорость До 1064 MBytes/sec в одном направлении Латентность около 3
- 46. Скачать презентацию

План
История
Типы суперкомпьютерных систем
Векторно-конвейерные
Массивно-параллельные
NUMA – с неоднородным доступом к памяти
Высокопроизводительные кластеры
Метакомпьютеры
План
История
Типы суперкомпьютерных систем
Векторно-конвейерные
Массивно-параллельные
NUMA – с неоднородным доступом к памяти
Высокопроизводительные кластеры
Метакомпьютеры

Литература
Суперкомпьютерные системы http://www.top500.org/ORSC/2004/
Транспьютеры http://maven.smith.edu/~thiebaut/transputer/descript.html
Метакомпьютеры http://setiathome.ssl.berkeley.edu/
GRID системы
http://www.grid.org
Литература
Суперкомпьютерные системы http://www.top500.org/ORSC/2004/
Транспьютеры http://maven.smith.edu/~thiebaut/transputer/descript.html
Метакомпьютеры http://setiathome.ssl.berkeley.edu/
GRID системы
http://www.grid.org

Исторические сведения
Первые векторные, конвейерные и суперскалярные процессоры CDC 1960-года
CRAY - CDC
Исторические сведения
Первые векторные, конвейерные и суперскалярные процессоры CDC 1960-года
CRAY - CDC

Типы суперкомпьютерных систем
Векторные (PVP, array, matrix, векторно-конвейерные vector-pipeline) компьютеры
Массивно-параллельные суперкомпьютеры
NUMA системы
Типы суперкомпьютерных систем
Векторные (PVP, array, matrix, векторно-конвейерные vector-pipeline) компьютеры
Массивно-параллельные суперкомпьютеры
NUMA системы

Векторно-конвейерные суперкомпьютеры Сray Y-MP C90
Конец 1980-х
До 16 процессоров с тактовой частотой
Векторно-конвейерные суперкомпьютеры Сray Y-MP C90
Конец 1980-х
До 16 процессоров с тактовой частотой
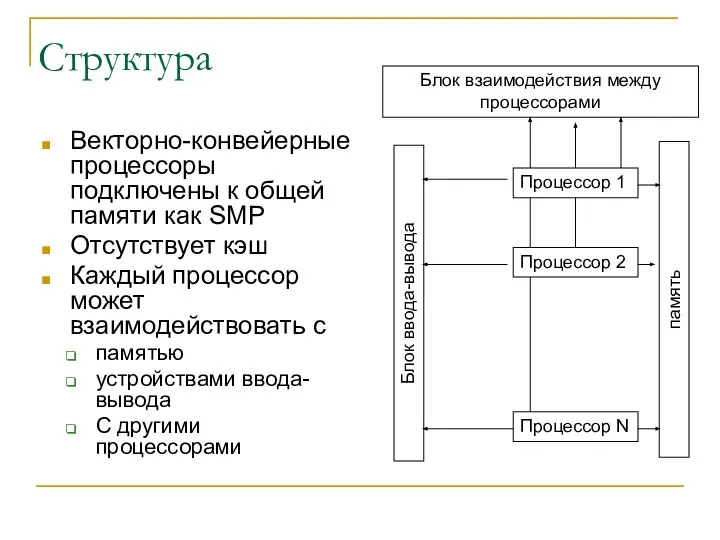
Структура
Векторно-конвейерные процессоры подключены к общей памяти как SMP
Отсутствует кэш
Каждый процессор может
Структура
Векторно-конвейерные процессоры подключены к общей памяти как SMP
Отсутствует кэш
Каждый процессор может

Память
До 1024 банков
К разным банкам можно обращаться одновременно
При обращении к одном
Память
До 1024 банков
К разным банкам можно обращаться одновременно
При обращении к одном

Секция ввода-вывода
Для связи с внешними устройствами и обмена информацией
Low-speed (LOSP) channels
Секция ввода-вывода
Для связи с внешними устройствами и обмена информацией
Low-speed (LOSP) channels
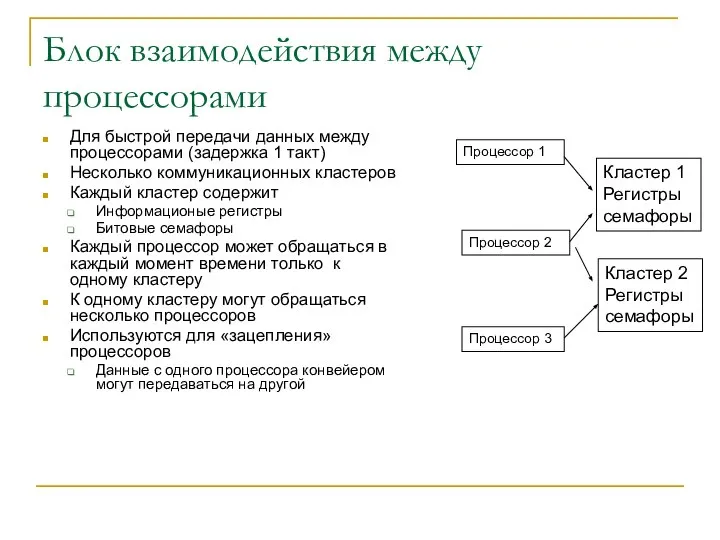
Блок взаимодействия между процессорами
Для быстрой передачи данных между процессорами (задержка 1
Блок взаимодействия между процессорами
Для быстрой передачи данных между процессорами (задержка 1
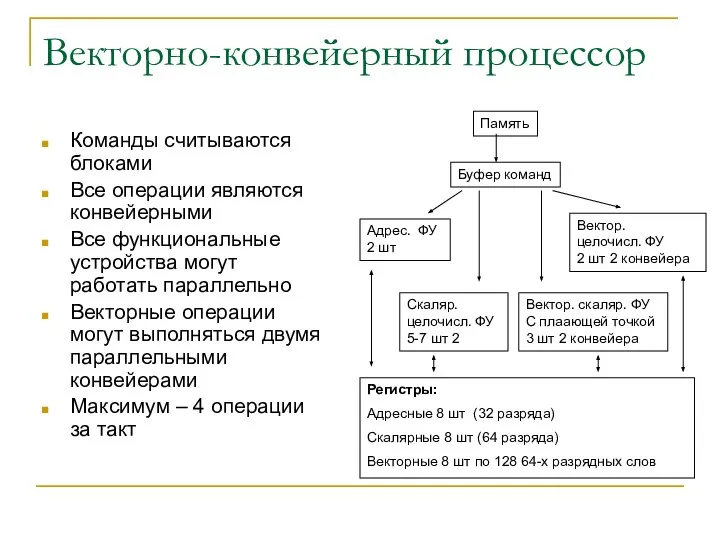
Векторно-конвейерный процессор
Команды считываются блоками
Все операции являются конвейерными
Все функциональные устройства могут работать
Векторно-конвейерный процессор
Команды считываются блоками
Все операции являются конвейерными
Все функциональные устройства могут работать

Особенности использования PVP
Эффективны для выполнения большого количества однотипных (векторных, матричных) вычислений
Не
Особенности использования PVP
Эффективны для выполнения большого количества однотипных (векторных, матричных) вычислений
Не

Транспьютеры
Микропроцессоры, специально разработанные для параллельных вычислений
1980-е года компания INMOS
Основная идея
Транспьютеры
Микропроцессоры, специально разработанные для параллельных вычислений
1980-е года компания INMOS
Основная идея
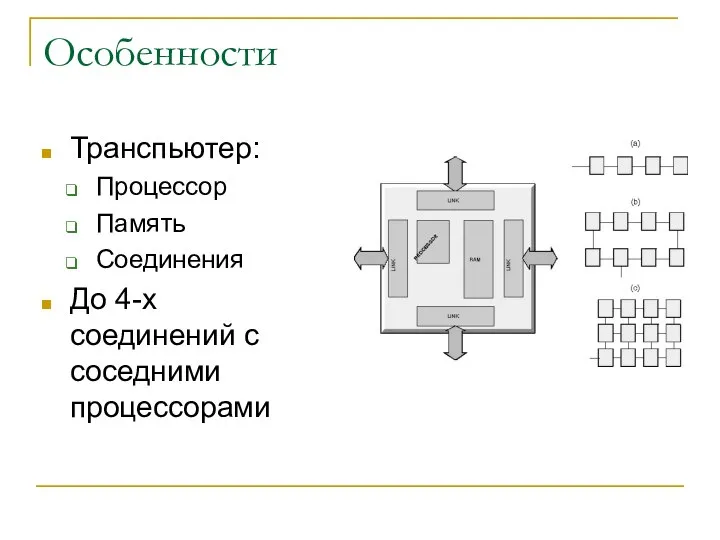
Особенности
Транспьютер:
Процессор
Память
Соединения
До 4-х соединений с соседними процессорами
Особенности
Транспьютер:
Процессор
Память
Соединения
До 4-х соединений с соседними процессорами

Массивно-параллельные компьютеры
Набор блоков с общей памятью (UP, SMP, PVP) соединенных с
Массивно-параллельные компьютеры
Набор блоков с общей памятью (UP, SMP, PVP) соединенных с

Особенности систем
Масштабируемость
Легко расширяются установкой новых блоков
Может быть большое количество процессоров
Особенности систем
Масштабируемость
Легко расширяются установкой новых блоков
Может быть большое количество процессоров

Особенности использования
Передача данных между блоками требует значительно большего времени, чем внутри
Особенности использования
Передача данных между блоками требует значительно большего времени, чем внутри

Реализации
CRAY T3E
IBM SP2
Классические большие суперкомпьютеры
Реализации
CRAY T3E
IBM SP2
Классические большие суперкомпьютеры

IBM SP2
Процессоры Power 2
Узел Узлы IBM RS/6000
До 16 CPU
До 16 узлов
IBM SP2
Процессоры Power 2
Узел Узлы IBM RS/6000
До 16 CPU
До 16 узлов
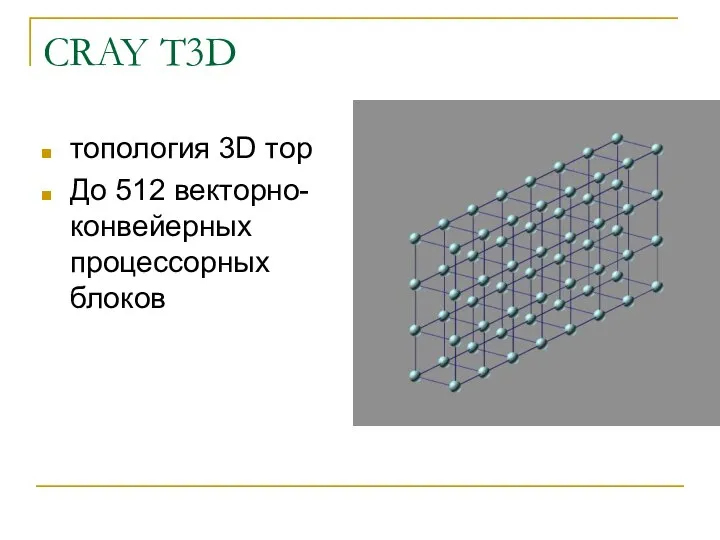
CRAY T3D
топология 3D тор
До 512 векторно-конвейерных процессорных блоков
CRAY T3D
топология 3D тор
До 512 векторно-конвейерных процессорных блоков

NUMA системы
NUMA – неоднородный доступ к памяти
Набор SMP плат, связанных коммутатором
Доступ
NUMA системы
NUMA – неоднородный доступ к памяти
Набор SMP плат, связанных коммутатором
Доступ

Особенности
Те же, что у SMP
Когерентность кэшей
ccNUMA –аппаратное обеспечение когерентности
Программное обеспечение
Особенности
Те же, что у SMP
Когерентность кэшей
ccNUMA –аппаратное обеспечение когерентности
Программное обеспечение

SGI Altix 3000
Несколько блоков
Связь NUMALink 3 – 3.2 Гбайт/с
В сумме до
SGI Altix 3000
Несколько блоков
Связь NUMALink 3 – 3.2 Гбайт/с
В сумме до

Кластеры
Кластер – набор вычислительных систем, которые могут работать независимо, связаны между
Кластеры
Кластер – набор вычислительных систем, которые могут работать независимо, связаны между

Особенности кластеров
Все узлы кластера являются вычислительными системами, которые выполняют свою копию
Особенности кластеров
Все узлы кластера являются вычислительными системами, которые выполняют свою копию

Использование кластеров
High Performance Clusters, HPC
high availability cluster, HAC
load balancing cluster, virtual server
Storage cluster, storage
Использование кластеров
High Performance Clusters, HPC
high availability cluster, HAC
load balancing cluster, virtual server
Storage cluster, storage

Вопросы стоимости
Закон Гроша (Grosch)
стоимость суперкомпьютера пропорциональна квадрату его производительности
Для микропроцессорных
Вопросы стоимости
Закон Гроша (Grosch)
стоимость суперкомпьютера пропорциональна квадрату его производительности
Для микропроцессорных

Другие классификации кластеров
Гомогенный
Все машины кластера одинаковы (в определенном контексте)
Гетерогенный
Машины кластера
Другие классификации кластеров
Гомогенный
Все машины кластера одинаковы (в определенном контексте)
Гетерогенный
Машины кластера

Исторические сведения
Мультикомпьютерные системы
Конец 1970-х годов
Первый промышленный кластер
1983 г VAX кластер,
Исторические сведения
Мультикомпьютерные системы
Конец 1970-х годов
Первый промышленный кластер
1983 г VAX кластер,

Метакомпьютеры
Метакомпьютеры – использование существующих (простаивающих) компьютерных ресурсов для решения задач
Компьютерный класс
Компьютеры
Метакомпьютеры
Метакомпьютеры – использование существующих (простаивающих) компьютерных ресурсов для решения задач
Компьютерный класс
Компьютеры

Использование мощности существующих компьютеров
В ночное время компьютеры часто простаивают
Потенциальная мощность простаивающих
Использование мощности существующих компьютеров
В ночное время компьютеры часто простаивают
Потенциальная мощность простаивающих

Существующие проекты
Обработка данных с радиотелескопов по поиску внеземных цивилизаций
http://setiathome.ssl.berkeley.edu/
Взломы алгоритмов шифрования
http://www.distributed.net/
Существующие проекты
Обработка данных с радиотелескопов по поиску внеземных цивилизаций
http://setiathome.ssl.berkeley.edu/
Взломы алгоритмов шифрования
http://www.distributed.net/

GRID системы
GRID – сеть
Метакомпьютеры промышленного уровня
Объединение компьютерных ресурсов в одну систему
GRID системы
GRID – сеть
Метакомпьютеры промышленного уровня
Объединение компьютерных ресурсов в одну систему

Lagre Hadron Colider - ускоритель
Франция
Швейцария
4.5 км
LHC
Lagre Hadron Colider - ускоритель
Франция
Швейцария
4.5 км
LHC

Объемы вычислений
Объём LHC данных соответствует
примерно 20 миллионам CD ежегодно!
требует компьютерной мощности
Объемы вычислений
Объём LHC данных соответствует
примерно 20 миллионам CD ежегодно!
требует компьютерной мощности
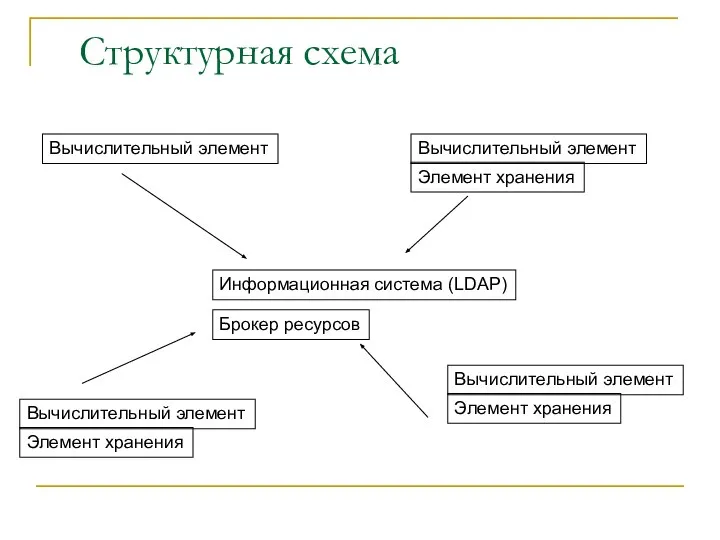
Структурная схема
Информационная система (LDAP)
Брокер ресурсов
Вычислительный элемент
Вычислительный элемент
Элемент хранения
Вычислительный элемент
Элемент хранения
Вычислительный элемент
Элемент
Структурная схема
Информационная система (LDAP)
Брокер ресурсов
Вычислительный элемент
Вычислительный элемент
Элемент хранения
Вычислительный элемент
Элемент хранения
Вычислительный элемент
Элемент

Реализации
Инструментарий
Globus
Condor
Грид системы
EDG
ALIEN
LCG
Реализации
Инструментарий
Globus
Condor
Грид системы
EDG
ALIEN
LCG

Средства коммуникации для кластерных систем
Кластер в основном управляется программно
Средства коммуникации –
Средства коммуникации для кластерных систем
Кластер в основном управляется программно
Средства коммуникации –

Технологии коммуникации
Ethernet
Fast Ethernet
Gigabit Ethernet
10Gigabit Ethernet
Myrinet
SCI
Infiniband
QSNet
cLan
GigaNet
Технологии коммуникации
Ethernet
Fast Ethernet
Gigabit Ethernet
10Gigabit Ethernet
Myrinet
SCI
Infiniband
QSNet
cLan
GigaNet

Характеристики средств коммуникации
Скорость передачи данных
Сколько времени занимает передача единицы информации
Латентность (начальная
Характеристики средств коммуникации
Скорость передачи данных
Сколько времени занимает передача единицы информации
Латентность (начальная

Ethernet
Среда
Медь
оптика
Скорость передачи
Fast 100 Mbit/c (125 Mбайт/с)
Gigabit 1000 Мбит/с
Латентность
Fast 125 мкс
Gigabit 33
Ethernet
Среда
Медь
оптика
Скорость передачи
Fast 100 Mbit/c (125 Mбайт/с)
Gigabit 1000 Мбит/с
Латентность
Fast 125 мкс
Gigabit 33

Myrinet (www.myri.com)
Среда
Медь
Оптика
Скорость передачи
до 10 Gbit/c
Латентность
От 5 мкс
Топология
Звезда
Гипердерево
Тип коммутации
Передача пакетов
Myrinet (www.myri.com)
Среда
Медь
Оптика
Скорость передачи
до 10 Gbit/c
Латентность
От 5 мкс
Топология
Звезда
Гипердерево
Тип коммутации
Передача пакетов

SCI (dolphinics.com)
Среда
Медь (шлейф)
Скорость передачи
До 8008 Мбайт/с
Задержка
1.2 мкс !
Топология
Линейка
Тор
Звезда
Тип коммутации
Передача пакетов
Общая
SCI (dolphinics.com)
Среда
Медь (шлейф)
Скорость передачи
До 8008 Мбайт/с
Задержка
1.2 мкс !
Топология
Линейка
Тор
Звезда
Тип коммутации
Передача пакетов
Общая

QSNet (quadrix.com)
Среда
Медь (параллельная шина)
Скорость
До 1064 MBytes/sec в одном направлении
Латентность
около 3 мкс
Топология
Гипердерево
Тип
QSNet (quadrix.com)
Среда
Медь (параллельная шина)
Скорость
До 1064 MBytes/sec в одном направлении
Латентность
около 3 мкс
Топология
Гипердерево
Тип
 Банки
Банки  Е1 біріншілік цифрлық ағынынның циклының құрылуы
Е1 біріншілік цифрлық ағынынның циклының құрылуы Проект "Подсолнух". Корпорация летнего экстрима
Проект "Подсолнух". Корпорация летнего экстрима Презентация "Архитектура Киевской Руси" - скачать презентации по МХК
Презентация "Архитектура Киевской Руси" - скачать презентации по МХК Презентация Национальная денежно-кредитная политика страны
Презентация Национальная денежно-кредитная политика страны Презентация на тему "Правовые основы организации школьного ученического самоуправления" - скачать презентации по Педагогике
Презентация на тему "Правовые основы организации школьного ученического самоуправления" - скачать презентации по Педагогике Страхование грузов при перевозке и ответственности наземного перевозчика
Страхование грузов при перевозке и ответственности наземного перевозчика Славянские языческие праздники (ноябрь)
Славянские языческие праздники (ноябрь) В помощь учителю по шахматам
В помощь учителю по шахматам Бизнес-план кафе «Какао-Мания»
Бизнес-план кафе «Какао-Мания» Презентация Жан Боден
Презентация Жан Боден Требования к участникам закупки
Требования к участникам закупки Миротворческая деятельность Вооруженных сил РФ
Миротворческая деятельность Вооруженных сил РФ facts Основные тиристорные устройства
facts Основные тиристорные устройства Основные буферные растворы крови
Основные буферные растворы крови Фундаменти. Зовнішні і внутрішні стіни
Фундаменти. Зовнішні і внутрішні стіни Язык программирования VB.NET
Язык программирования VB.NET В МИРЕ ИЗОБРАЗИТЕЛЬНОГО ИСКУССТВА Угадай Ка! (урок – соревнование) 7 класса. III триместр. Условия урока – соревнования : за пра
В МИРЕ ИЗОБРАЗИТЕЛЬНОГО ИСКУССТВА Угадай Ка! (урок – соревнование) 7 класса. III триместр. Условия урока – соревнования : за пра Знакомство с языком HTML
Знакомство с языком HTML Правила игры в футбол
Правила игры в футбол Расчет пружинно-шариковой предохранительной и фрикционной муфт
Расчет пружинно-шариковой предохранительной и фрикционной муфт Предмет начертательной геометрии. Метод проекций
Предмет начертательной геометрии. Метод проекций ЛЕГЕНДЫ О ВЕСЕННИХ ЦВЕТАХ
ЛЕГЕНДЫ О ВЕСЕННИХ ЦВЕТАХ Все о футболе
Все о футболе Особенности межкультурной коммуникации Италии и Испании
Особенности межкультурной коммуникации Италии и Испании Прорывы в области машинного обучения
Прорывы в области машинного обучения Отель MERCURE. Роза Хутор 4
Отель MERCURE. Роза Хутор 4 Imperativ. Повелительное наклонение
Imperativ. Повелительное наклонение