Презентация на тему "Прогностическая эффективность биомаркеров" - скачать бесплатно презентации по Биологии
- Презентация на тему "Прогностическая эффективность биомаркеров" - скачать бесплатно презентации по Биологии

Содержание
- 2. Прогностическая эффективность биомаркеров или как представить результаты так, чтобы они нравились не только нам, но и
- 3. ФЦП «Исследования и разработки по приоритетным направлениям развития научно-технологического комплекса России на 2007—2012 годы» О чем
- 4. Чувствительность – специфичность: старые добрые медицинские понятия Специфичность = 0.9 Чувствительность = 0.7
- 5. Выигрывая в чувствительности, обычно теряем специфичность (et converso) SE vs. SP: противоборство показателей Маркер у всех,
- 6. Так что важнее: чувствительность или специфичность? Area Under Curve?
- 7. AUC – это вероятность отличить больного от здорового, ориентируясь на маркер! Берем 1 здорового и 1
- 8. А зачем все это? Почему бы не обойтись привычным набором показателей ассоциирования – r, OR, p
- 9. 150 000 работ, претендующих на открытие биомаркеров Надежды 90-х не оправдались: эпоха GWAS буксует Капля в
- 10. Пример, когда сильный эффект не обеспечивает эффективность прогноза Сколько раз тест сработал? Вероятность того, что случайно
- 11. Здоровые Control Больные Case Носители маркера Свободны от маркера все начинается с таблицы сопряженности 2×2: >
- 12. Здоровые Control Больные Case Носители маркера Свободны от маркера Интерпретация в терминах ошибок I и II
- 13. Бинарный тест: вычисление показателей ассоциирования и риска Показатели ассоциирования: Показатели рисков: > RR Не все эти
- 14. Дизайн ассоциативных исследований Population study: случайная выборка без подбора групп Case-control study: подбор групп «больные-здоровые» Cohort
- 15. Возможность непосредственной оценки зависит от дизайна эксперимента! Однако в большинстве случаев в отношении pD и pM
- 16. Какими могут быть чувствительность, специфичность и риски для бинарного теста? .... Рассмотрим крайности: На что можно
- 17. Зависимость чувствительности от pD и pM при фиксированном OR (=5) SE - pM pM pD Чувствительность
- 18. SP – (1-pM) pM pD Зависимость специфичности от pD и pM при фиксированном OR(=5) Специфичность слегка
- 19. AUC pM pD OR=5 OR=10 OR=20 Зависимость AUC от pD и pM В этой точке SE=SP
- 20. При каких OR маркер является хорошим классификатором?
- 21. Почему высокое OR не всегда гарантирует эффективность прогнозов, и когда подобное происходит? Возьмем крайний случай: OR=∞
- 22. И еще одно обстоятельство OR=11, p=7⋅10-11 Популяционное обследование: Заболеваемость – 50% OR=11, но это не совсем
- 23. OR завышает оценку относительного риска pD=0.05 pM=0.1 - хорошая аппроксимация для RR
- 24. RR может быть существенно меньше OR в случае широко распространенного заболевания (pD>0.1) и редкого маркера (pM
- 25. Бинарные и количественные маркеры (тесты) Бинарный тест: маркер «есть-нет» Количественный тест: маркер является количественным показателем После
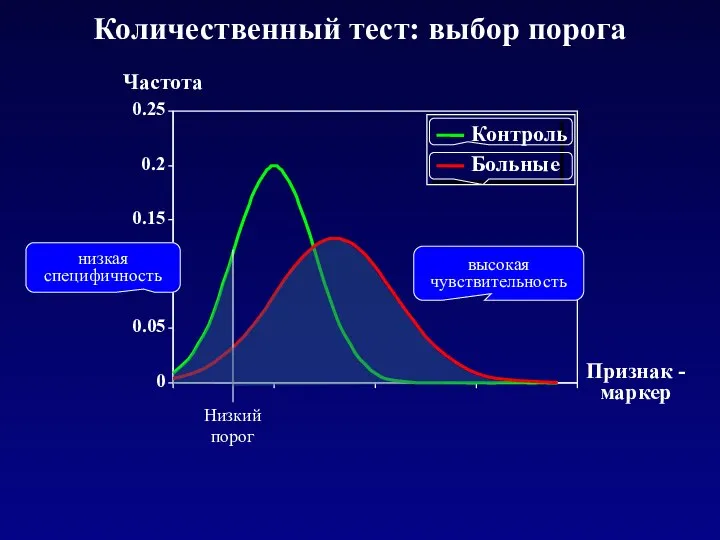
- 26. 0 0.05 0.1 0.15 0.2 0.25 Признак - маркер Частота Контроль Больные Количественный тест: выбор порога
- 27. 0 0.05 0.1 0.15 0.2 0.25 Признак - маркер Частота Контроль Больные Низкий порог Количественный тест:
- 28. ROC – анализ Receiver Operator Characteristics Термин времен 2-ой мировой войны, который придумали операторы первых радарных
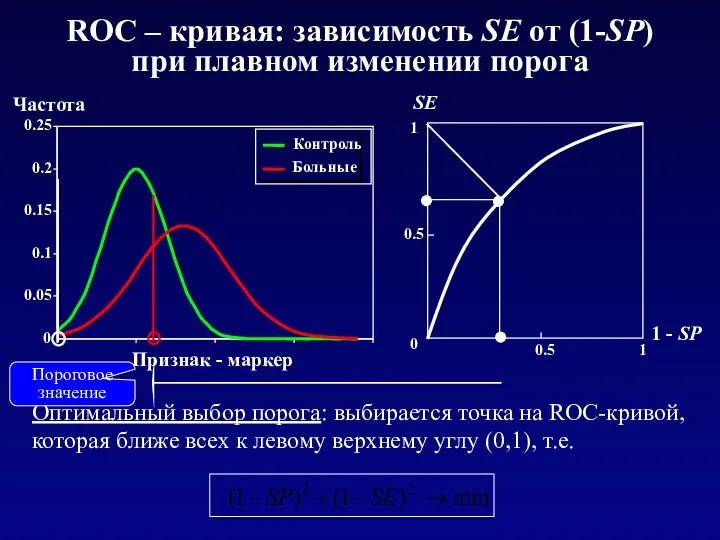
- 29. 0 0.05 0.1 0.15 0.2 0.25 Признак - маркер Частота Контроль Больные ROC – кривая: зависимость
- 30. Форма ROC-кривых
- 31. AUC - это площадь под ROC-кривой (Area Under Curve) AUC = Вероятность того, что значение признака-маркера
- 32. 0 1 2 3 Контроль Значения признака-маркера Больные Вычисления при ROC-анализе
- 33. Вычисления при ROC-анализе
- 34. 0.88 Все делается в Excel: 0.58
- 35. Все делается в Excel:
- 36. Все делается в Excel:
- 37. Все делается в Excel:
- 38. Наименьшее расстояние до точки (0,1) Все делается в Excel: Оптимальное пороговое значение При выборе этого этого
- 39. Все делается в Excel:
- 40. Пример из радиационной генетики:
- 41. Частоты хромосомных аберраций в зависимости от генотипов по кандидататным генам у ликвидаторов аварии на ЧАЭС и
- 42. Частоты хромосомных аберраций в зависимости от генотипов по кандидататным генам у ликвидаторов аварии на ЧАЭС и
- 43. Распределения частот аберраций хромосомного типа у ликвидаторов и в контрольной группе Что можно считать повышенным уровнем
- 44. Частота «рискового генотипа» среди лиц с повышенным уровнем аберраций хромосомного типа Хотя бы один минорный аллель
- 46. Скачать презентацию

Прогностическая эффективность биомаркеров
или
как представить результаты так,
чтобы они нравились не только
Прогностическая эффективность биомаркеров
или
как представить результаты так,
чтобы они нравились не только

ФЦП «Исследования и разработки по приоритетным направлениям развития научно-технологического комплекса России на 2007—2012
ФЦП «Исследования и разработки по приоритетным направлениям развития научно-технологического комплекса России на 2007—2012
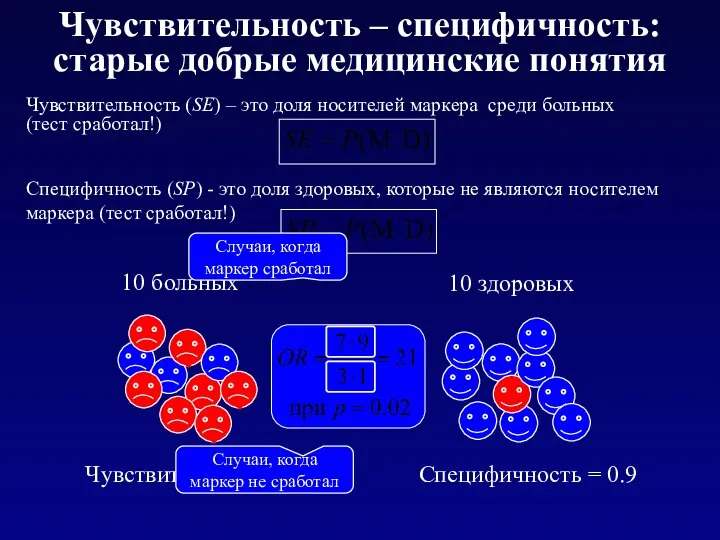
Чувствительность – специфичность: старые добрые медицинские понятия
Специфичность = 0.9
Чувствительность = 0.7
Чувствительность – специфичность: старые добрые медицинские понятия
Специфичность = 0.9
Чувствительность = 0.7

Выигрывая в чувствительности,
обычно теряем специфичность (et converso)
SE vs. SP:
противоборство
Выигрывая в чувствительности,
обычно теряем специфичность (et converso)
SE vs. SP:
противоборство

Так что важнее:
чувствительность или специфичность?
Area Under Curve?
Так что важнее:
чувствительность или специфичность?
Area Under Curve?

AUC – это вероятность отличить больного от здорового, ориентируясь на маркер!
Берем
AUC – это вероятность отличить больного от здорового, ориентируясь на маркер!
Берем

А зачем все это?
Почему бы не обойтись привычным набором
показателей ассоциирования
А зачем все это?
Почему бы не обойтись привычным набором
показателей ассоциирования

150 000
работ,
претендующих на
открытие биомаркеров
Надежды 90-х не оправдались: эпоха GWAS
150 000
работ,
претендующих на
открытие биомаркеров
Надежды 90-х не оправдались: эпоха GWAS

Пример, когда сильный эффект не обеспечивает эффективность прогноза
Сколько раз тест сработал?
Пример, когда сильный эффект не обеспечивает эффективность прогноза
Сколько раз тест сработал?

Здоровые
Control
Больные
Case
Носители
маркера
Свободны от
маркера
все начинается с таблицы сопряженности 2×2:
> pM
> 1-pM
Популяционная частота
Здоровые
Control
Больные
Case
Носители
маркера
Свободны от
маркера
все начинается с таблицы сопряженности 2×2:
> pM
> 1-pM
Популяционная частота

Здоровые
Control
Больные
Case
Носители
маркера
Свободны от
маркера
Интерпретация в терминах ошибок I и II рода
Плоховато запоминается
Здоровые
Control
Больные
Case
Носители
маркера
Свободны от
маркера
Интерпретация в терминах ошибок I и II рода
Плоховато запоминается

Бинарный тест: вычисление показателей ассоциирования и риска
Показатели ассоциирования:
Показатели рисков:
> RR
Не все
Бинарный тест: вычисление показателей ассоциирования и риска
Показатели ассоциирования:
Показатели рисков:
> RR
Не все
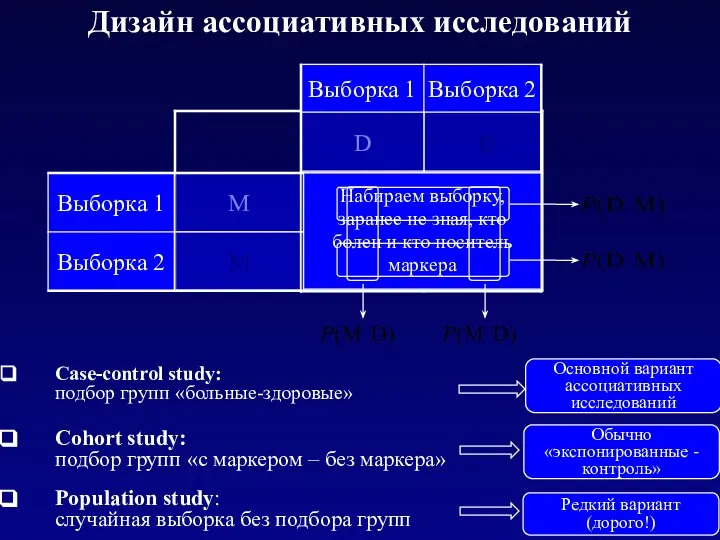
Дизайн ассоциативных исследований
Population study:
случайная выборка без подбора групп
Case-control study:
подбор
Дизайн ассоциативных исследований
Population study:
случайная выборка без подбора групп
Case-control study:
подбор

Возможность непосредственной оценки зависит от дизайна эксперимента!
Однако в большинстве случаев
Возможность непосредственной оценки зависит от дизайна эксперимента!
Однако в большинстве случаев

Какими могут быть чувствительность, специфичность и риски
для бинарного теста? .... Рассмотрим
Какими могут быть чувствительность, специфичность и риски
для бинарного теста? .... Рассмотрим

Зависимость чувствительности от pD и pM
при фиксированном OR (=5)
SE -
Зависимость чувствительности от pD и pM
при фиксированном OR (=5)
SE -

SP – (1-pM)
pM
pD
Зависимость специфичности от pD и pM
при фиксированном OR(=5)
SP – (1-pM)
pM
pD
Зависимость специфичности от pD и pM
при фиксированном OR(=5)

AUC
pM
pD
OR=5
OR=10
OR=20
Зависимость AUC от pD и pM
В этой точке SE=SP
AUC
pM
pD
OR=5
OR=10
OR=20
Зависимость AUC от pD и pM
В этой точке SE=SP
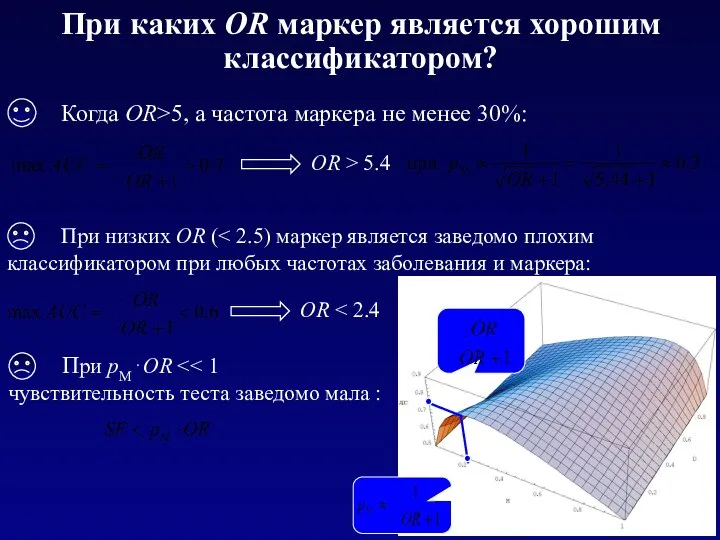
При каких OR маркер является хорошим классификатором?
При каких OR маркер является хорошим классификатором?

Почему высокое OR не всегда гарантирует эффективность прогнозов,
и когда подобное
Почему высокое OR не всегда гарантирует эффективность прогнозов,
и когда подобное

И еще одно обстоятельство
OR=11, p=7⋅10-11
Популяционное обследование:
Заболеваемость – 50%
OR=11, но это
И еще одно обстоятельство
OR=11, p=7⋅10-11
Популяционное обследование:
Заболеваемость – 50%
OR=11, но это
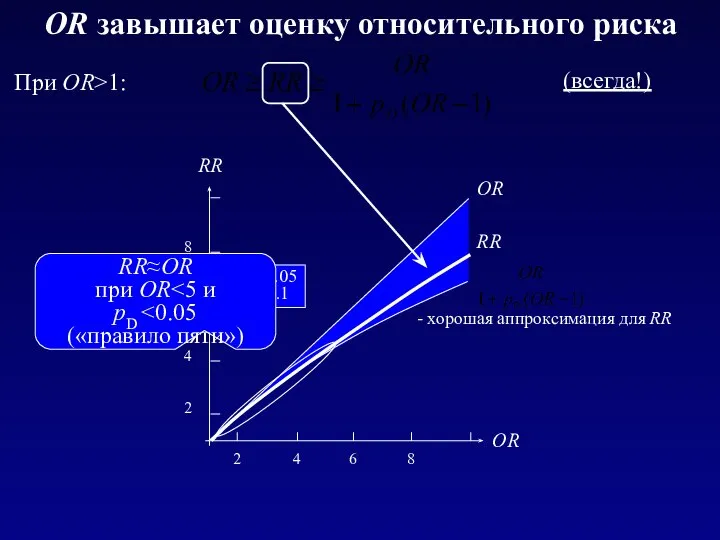
OR завышает оценку относительного риска
pD=0.05
pM=0.1
- хорошая аппроксимация для RR
OR завышает оценку относительного риска
pD=0.05
pM=0.1
- хорошая аппроксимация для RR

RR может быть существенно меньше OR
в случае широко распространенного заболевания (pD>0.1)
RR может быть существенно меньше OR
в случае широко распространенного заболевания (pD>0.1)

Бинарные и количественные маркеры (тесты)
Бинарный тест:
маркер «есть-нет»
Количественный тест:
маркер является
Бинарные и количественные маркеры (тесты)
Бинарный тест:
маркер «есть-нет»
Количественный тест:
маркер является
0
0.05
0.1
0.15
0.2
0.25
Признак - маркер
Частота
Контроль
Больные
Количественный тест: выбор порога
0
0.05
0.1
0.15
0.2
0.25
Признак - маркер
Частота
Контроль
Больные
Количественный тест: выбор порога

0
0.05
0.1
0.15
0.2
0.25
Признак - маркер
Частота
Контроль
Больные
Низкий порог
Количественный тест: выбор порога
Как выбрать порог, чтобы соотношение
чувствительность/специфичность
0
0.05
0.1
0.15
0.2
0.25
Признак - маркер
Частота
Контроль
Больные
Низкий порог
Количественный тест: выбор порога
Как выбрать порог, чтобы соотношение
чувствительность/специфичность

ROC – анализ
Receiver Operator Characteristics
Термин времен 2-ой мировой войны, который придумали
ROC – анализ
Receiver Operator Characteristics
Термин времен 2-ой мировой войны, который придумали
0
0.05
0.1
0.15
0.2
0.25
Признак - маркер
Частота
Контроль
Больные
ROC – кривая: зависимость SE от (1-SP)
при плавном
0
0.05
0.1
0.15
0.2
0.25
Признак - маркер
Частота
Контроль
Больные
ROC – кривая: зависимость SE от (1-SP)
при плавном

Форма ROC-кривых
Форма ROC-кривых

AUC - это площадь под ROC-кривой (Area Under Curve)
AUC = Вероятность
AUC - это площадь под ROC-кривой (Area Under Curve)
AUC = Вероятность

0
1
2
3
Контроль
Значения признака-маркера
Больные
Вычисления при ROC-анализе
0
1
2
3
Контроль
Значения признака-маркера
Больные
Вычисления при ROC-анализе

Вычисления при ROC-анализе
Вычисления при ROC-анализе

0.88
Все делается в Excel:
0.58
0.88
Все делается в Excel:
0.58

Все делается в Excel:
Все делается в Excel:

Все делается в Excel:
Все делается в Excel:

Все делается в Excel:
Все делается в Excel:

Наименьшее расстояние до точки (0,1)
Все делается в Excel:
Оптимальное пороговое значение
При выборе
Наименьшее расстояние до точки (0,1)
Все делается в Excel:
Оптимальное пороговое значение
При выборе

Все делается в Excel:
Все делается в Excel:

Пример из радиационной генетики:
Пример из радиационной генетики:

Частоты хромосомных аберраций в зависимости от генотипов по кандидататным генам у
Частоты хромосомных аберраций в зависимости от генотипов по кандидататным генам у
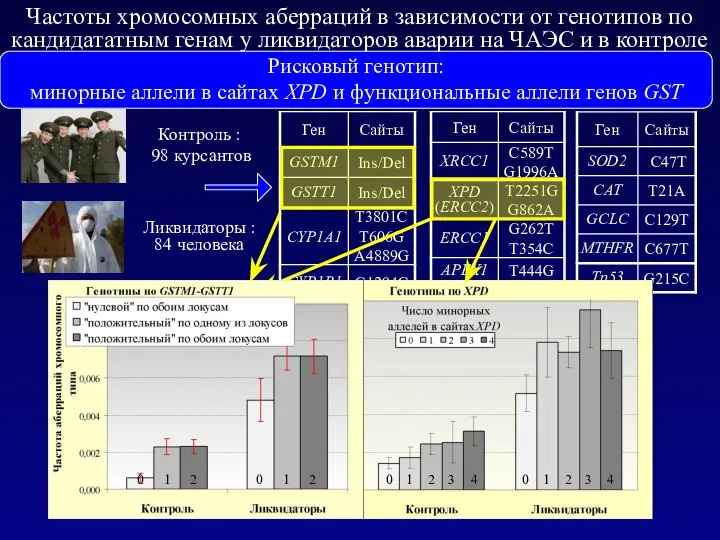
Частоты хромосомных аберраций в зависимости от генотипов по кандидататным генам у
Частоты хромосомных аберраций в зависимости от генотипов по кандидататным генам у

Распределения частот аберраций хромосомного типа у ликвидаторов и в контрольной группе
Что
Распределения частот аберраций хромосомного типа у ликвидаторов и в контрольной группе
Что

Частота «рискового генотипа» среди лиц с повышенным уровнем аберраций хромосомного типа
Хотя
Частота «рискового генотипа» среди лиц с повышенным уровнем аберраций хромосомного типа
Хотя
 Болезни аквариумных рыб Выполнил: ученик 9 а класса Волкотрубенко Михаил.
Болезни аквариумных рыб Выполнил: ученик 9 а класса Волкотрубенко Михаил. Развитие жизни на Земле. Эры
Развитие жизни на Земле. Эры Stages of the energy metabolism
Stages of the energy metabolism Пингвины. Семейство пингвиновых
Пингвины. Семейство пингвиновых Тіршіліктің пайда болуы
Тіршіліктің пайда болуы Этапы урока. Организация начала занятия. Проверка выполнения домашнего задания. Подготовка к усвоению новых знаний Изучение
Этапы урока. Организация начала занятия. Проверка выполнения домашнего задания. Подготовка к усвоению новых знаний Изучение  Головной мозг, его строение и функции
Головной мозг, его строение и функции Эмбриональная смертность и спонтанные аборты у собак
Эмбриональная смертность и спонтанные аборты у собак Внешнее строение птиц (мат.к лабор. работе)
Внешнее строение птиц (мат.к лабор. работе) Ю. Герман. К 110-летию со дня рождения писателя
Ю. Герман. К 110-летию со дня рождения писателя Презентация по биологии Строение клетки
Презентация по биологии Строение клетки  Перелётные птицы
Перелётные птицы Презентация на тему Семейство кошачьих Презентация к уроку
Презентация на тему Семейство кошачьих Презентация к уроку МУНИЦИПАЛЬНОЕ ОБЩЕОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ОДИНЦОВСКАЯ ГИМНАЗИЯ № 11 ВИРУСЫ – НЕКЛЕТОЧНАЯ ФОРМА ЖИЗНИ…
МУНИЦИПАЛЬНОЕ ОБЩЕОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ОДИНЦОВСКАЯ ГИМНАЗИЯ № 11 ВИРУСЫ – НЕКЛЕТОЧНАЯ ФОРМА ЖИЗНИ…  Общая характеристика некоторых представителей подкласса Розиды. Лекция 6-7. Часть 2
Общая характеристика некоторых представителей подкласса Розиды. Лекция 6-7. Часть 2 Игра Один-много
Игра Один-много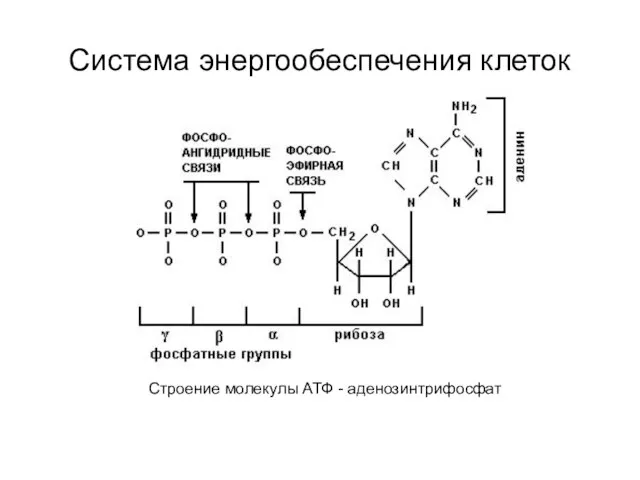 Система энергообеспечения клеток
Система энергообеспечения клеток Скелетная система
Скелетная система Экологическая токсикокинетика и биоаккумуляция ксенобиотиков. Токсическое действие СОЗ
Экологическая токсикокинетика и биоаккумуляция ксенобиотиков. Токсическое действие СОЗ Анатомия. Дыхательная система
Анатомия. Дыхательная система Аскомицеты. Характерные особенности аскомицетов
Аскомицеты. Характерные особенности аскомицетов Интродукция. Инвазивные виды
Интродукция. Инвазивные виды Будова прокаріотів
Будова прокаріотів  Разбор задания 31-32 ОГЭ-9 биология
Разбор задания 31-32 ОГЭ-9 биология Особенности организации многоклеточных животных
Особенности организации многоклеточных животных История болезни. Анамнез болезни животного
История болезни. Анамнез болезни животного Эмбриология. Периоды развития организма
Эмбриология. Периоды развития организма Человек и природа Урок 1. Биологическое и социальное в человеке.
Человек и природа Урок 1. Биологическое и социальное в человеке.