- Data Mining

Содержание
- 2. Докладчики Александра Симонова, Мат-Мех, 5 курс
- 3. История Data Mining 1960-е гг. – первая промышленная СУБД система IMS фирмы IBM. 1970-е гг. –
- 4. Возникновение Data Mining. Способствующие факторы совершенствование аппаратного и программного обеспечения; совершенствование технологий хранения и записи данных;
- 5. Понятие Data Mining Data Mining - это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных, практически
- 6. Мультидисциплинарность
- 7. Задачи Data Mining Классификация Кластеризация Прогнозирование Ассоциация Визуализация анализ и обнаружение отклонений Оценивание Анализ связей Подведение
- 8. Стадии Data Mining СВОБОДНЫЙ ПОИСК (в том числе ВАЛИДАЦИЯ) ПРОГНОСТИЧЕСКОЕ МОДЕЛИРОВАНИЕ АНАЛИЗ ИСКЛЮЧЕНИЙ
- 9. Методы Data Mining. Технологические методы. Непосредственное использование данных, или сохранение данных: кластерный анализ, метод ближайшего соседа,
- 10. Методы Data Mining. Статистические методы. Дескриптивный анализ и описание исходных данных. Анализ связей (корреляционный и регрессионный
- 11. Методы Data Mining. Кибернетические методы. Искусственные нейронные сети (распознавание, кластеризация, прогноз); Эволюционное программирование (в т.ч. алгоритмы
- 12. Визуализация инструментов Data Mining. Для деревьев решений - визуализатор дерева решений, список правил, таблица сопряженности. Для
- 13. Проблемы и вопросы Data Mining не может заменить аналитика! Сложность разработки и эксплуатации приложения Data Mining.
- 14. Области применения Data mining Database marketers - Рыночная сегментация, идентификация целевых групп, построение профиля клиента Банковское
- 15. Области применения Data mining. Продолжение. Телекоммуникация и энергетика - Привлечение клиентов, ценовая политика, анализ отказов, предсказание
- 16. Перспективы технологии Data Mining. выделение типов предметных областей с соответствующими им эвристиками создание формальных языков и
- 17. Литература по Data Mining "Wikipedia about Data Mining" (http://en.wikipedia.org/wiki/Data_mining) "Data Mining Tutorials" (http://www.eruditionhome.com/datamining/tut.html) "Thearling intro paper"
- 18. Деревья решений. История и основные понятия. Возникновение - 50-е годы (Ховиленд и Хант (Hoveland, Hunt) )
- 19. Деревья решений. Пример 1.
- 20. Деревья решений. Пример 2.
- 21. Деревья решений. Преимущества метода. Интуитивность деревьев решений Возможность извлекать правила из базы данных на естественном языке
- 22. Деревья решений. Процесс конструирования. Основные этапы алгоритмов конструирования деревьев: "построение" или "создание" дерева (tree building) "сокращение"
- 23. Деревья решений. Критерии расщепления. "мера информационного выигрыша" (information gain measure) индекс Gini, т.е. gini(T), определяется по
- 24. Деревья решений. Остановка построения дерева. Остановка - такой момент в процессе построения дерева, когда следует прекратить
- 25. Деревья решений. Сокращение дерева или отсечение ветвей. Критерии: Точность распознавания Ошибка
- 26. Деревья решений. Алгоритмы. CART . CART (Classification and Regression Tree) разработан в 1974-1984 годах четырьмя профессорами
- 27. Деревья решений. Алгоритмы. C4.5 . Строит дерево решений с неограниченным количеством ветвей у узла Дискретные значения
- 28. Деревья решений. Перспективы метода и выводы. Разработка новых масштабируемых алгоритмов (Sprint, предложенный Джоном Шафером) Метод деревьев
- 29. Метод "ближайшего соседа" или системы рассуждений на основе аналогичных случаев. Прецедент - это описание ситуации в
- 30. Метод "ближайшего соседа". Преимущества. Простота использования полученных результатов. Решения не уникальны для конкретной ситуации, возможно их
- 31. Метод "ближайшего соседа". Недостатки. Данный метод не создает каких-либо моделей или правил, обобщающих предыдущий опыт Cложность
- 32. Метод "ближайшего соседа". Решение задачи классификации новых объектов.
- 33. Метод "ближайшего соседа". Решение задачи прогнозирования.
- 34. Метод "ближайшего соседа". Оценка параметра k методом кросс-проверки. Кросс-проверка - известный метод получения оценок неизвестных параметров
- 35. Метод "ближайшего соседа". Примеры использования и реализации. Использование - программное обеспечение центра технической поддержки компании Dell,
- 37. Скачать презентацию

Докладчики
Александра Симонова, Мат-Мех, 5 курс
Докладчики
Александра Симонова, Мат-Мех, 5 курс

История Data Mining
1960-е гг. – первая промышленная СУБД система IMS фирмы
История Data Mining
1960-е гг. – первая промышленная СУБД система IMS фирмы

Возникновение Data Mining. Способствующие факторы
совершенствование аппаратного и программного обеспечения;
совершенствование технологий
Возникновение Data Mining. Способствующие факторы
совершенствование аппаратного и программного обеспечения;
совершенствование технологий

Понятие Data Mining
Data Mining - это процесс обнаружения в сырых данных
Понятие Data Mining
Data Mining - это процесс обнаружения в сырых данных
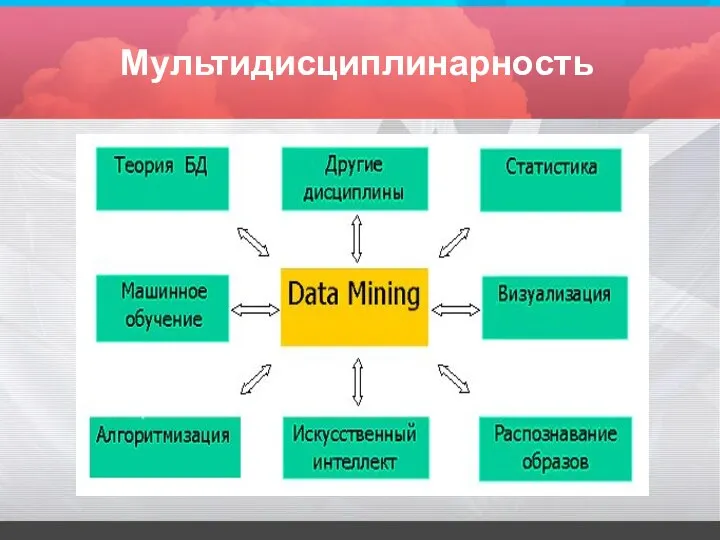
Мультидисциплинарность
Мультидисциплинарность

Задачи Data Mining
Классификация
Кластеризация
Прогнозирование
Ассоциация
Визуализация
анализ и обнаружение отклонений
Оценивание
Анализ связей
Подведение итогов
Задачи Data Mining
Классификация
Кластеризация
Прогнозирование
Ассоциация
Визуализация
анализ и обнаружение отклонений
Оценивание
Анализ связей
Подведение итогов
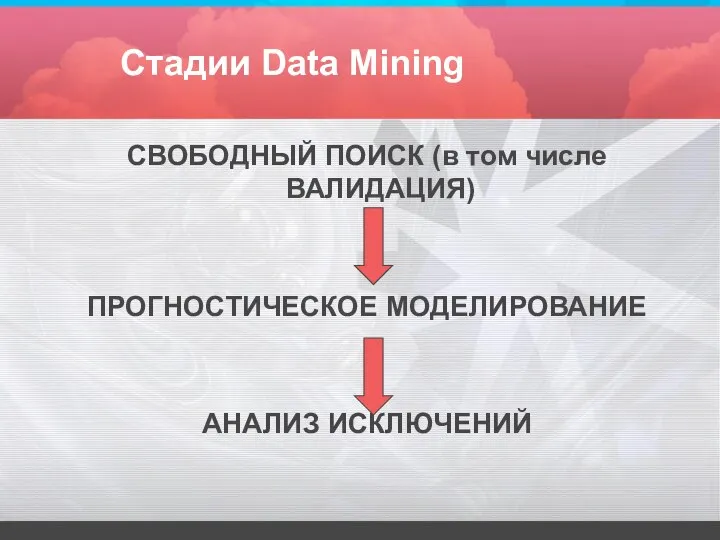
Стадии Data Mining
СВОБОДНЫЙ ПОИСК (в том числе ВАЛИДАЦИЯ)
ПРОГНОСТИЧЕСКОЕ МОДЕЛИРОВАНИЕ
АНАЛИЗ ИСКЛЮЧЕНИЙ
Стадии Data Mining
СВОБОДНЫЙ ПОИСК (в том числе ВАЛИДАЦИЯ)
ПРОГНОСТИЧЕСКОЕ МОДЕЛИРОВАНИЕ
АНАЛИЗ ИСКЛЮЧЕНИЙ

Методы Data Mining. Технологические методы.
Непосредственное использование данных, или сохранение данных:
кластерный анализ,
Методы Data Mining. Технологические методы.
Непосредственное использование данных, или сохранение данных: кластерный анализ,

Методы Data Mining. Статистические методы.
Дескриптивный анализ и описание исходных данных.
Анализ связей
Методы Data Mining. Статистические методы.
Дескриптивный анализ и описание исходных данных.
Анализ связей

Методы Data Mining. Кибернетические методы.
Искусственные нейронные сети (распознавание, кластеризация, прогноз);
Эволюционное программирование
Методы Data Mining. Кибернетические методы.
Искусственные нейронные сети (распознавание, кластеризация, прогноз);
Эволюционное программирование

Визуализация инструментов Data Mining.
Для деревьев решений - визуализатор дерева решений, список
Визуализация инструментов Data Mining.
Для деревьев решений - визуализатор дерева решений, список

Проблемы и вопросы
Data Mining не может заменить аналитика!
Сложность разработки и эксплуатации
Проблемы и вопросы
Data Mining не может заменить аналитика!
Сложность разработки и эксплуатации

Области применения Data mining
Database marketers - Рыночная сегментация, идентификация целевых групп,
Области применения Data mining
Database marketers - Рыночная сегментация, идентификация целевых групп,

Области применения Data mining. Продолжение.
Телекоммуникация и энергетика - Привлечение клиентов, ценовая
Области применения Data mining. Продолжение.
Телекоммуникация и энергетика - Привлечение клиентов, ценовая

Перспективы технологии Data Mining.
выделение типов предметных областей с соответствующими им эвристиками
создание
Перспективы технологии Data Mining.
выделение типов предметных областей с соответствующими им эвристиками
создание

Литература по Data Mining
"Wikipedia about Data Mining" (http://en.wikipedia.org/wiki/Data_mining)
"Data Mining Tutorials" (http://www.eruditionhome.com/datamining/tut.html)
"Thearling
Литература по Data Mining
"Wikipedia about Data Mining" (http://en.wikipedia.org/wiki/Data_mining)
"Data Mining Tutorials" (http://www.eruditionhome.com/datamining/tut.html)
"Thearling

Деревья решений. История и основные понятия.
Возникновение - 50-е годы (Ховиленд и
Деревья решений. История и основные понятия.
Возникновение - 50-е годы (Ховиленд и
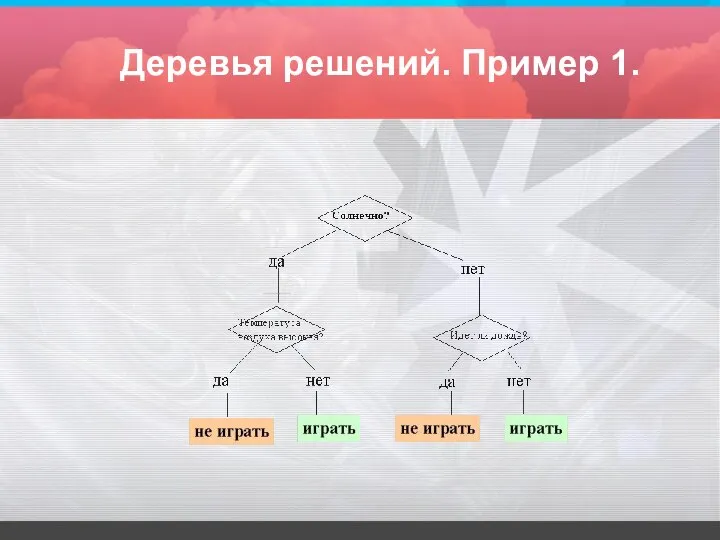
Деревья решений. Пример 1.
Деревья решений. Пример 1.
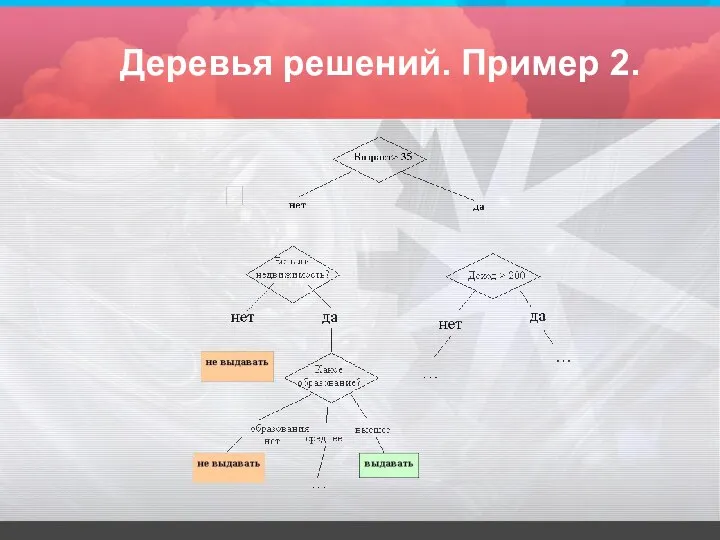
Деревья решений. Пример 2.
Деревья решений. Пример 2.

Деревья решений. Преимущества метода.
Интуитивность деревьев решений
Возможность извлекать правила из базы
Деревья решений. Преимущества метода.
Интуитивность деревьев решений
Возможность извлекать правила из базы

Деревья решений. Процесс конструирования.
Основные этапы алгоритмов конструирования деревьев:
"построение" или
Деревья решений. Процесс конструирования.
Основные этапы алгоритмов конструирования деревьев:
"построение" или

Деревья решений. Критерии расщепления.
"мера информационного выигрыша" (information gain measure)
индекс Gini,
Деревья решений. Критерии расщепления.
"мера информационного выигрыша" (information gain measure)
индекс Gini,

Деревья решений. Остановка построения дерева.
Остановка - такой момент в процессе построения
Деревья решений. Остановка построения дерева.
Остановка - такой момент в процессе построения

Деревья решений. Сокращение дерева или отсечение ветвей.
Критерии:
Точность распознавания
Ошибка
Деревья решений. Сокращение дерева или отсечение ветвей.
Критерии:
Точность распознавания
Ошибка

Деревья решений. Алгоритмы. CART .
CART (Classification and Regression Tree)
разработан в
Деревья решений. Алгоритмы. CART .
CART (Classification and Regression Tree)
разработан в

Деревья решений. Алгоритмы. C4.5 .
Строит дерево решений с неограниченным количеством ветвей
Деревья решений. Алгоритмы. C4.5 .
Строит дерево решений с неограниченным количеством ветвей

Деревья решений. Перспективы метода и выводы.
Разработка новых масштабируемых алгоритмов (Sprint, предложенный
Деревья решений. Перспективы метода и выводы.
Разработка новых масштабируемых алгоритмов (Sprint, предложенный

Метод "ближайшего соседа" или системы рассуждений на основе аналогичных случаев.
Прецедент -
Метод "ближайшего соседа" или системы рассуждений на основе аналогичных случаев.
Прецедент -

Метод "ближайшего соседа". Преимущества.
Простота использования полученных результатов.
Решения не уникальны для конкретной
Метод "ближайшего соседа". Преимущества.
Простота использования полученных результатов.
Решения не уникальны для конкретной

Метод "ближайшего соседа". Недостатки.
Данный метод не создает каких-либо моделей или правил,
Метод "ближайшего соседа". Недостатки.
Данный метод не создает каких-либо моделей или правил,

Метод "ближайшего соседа". Решение задачи классификации новых объектов.
Метод "ближайшего соседа". Решение задачи классификации новых объектов.
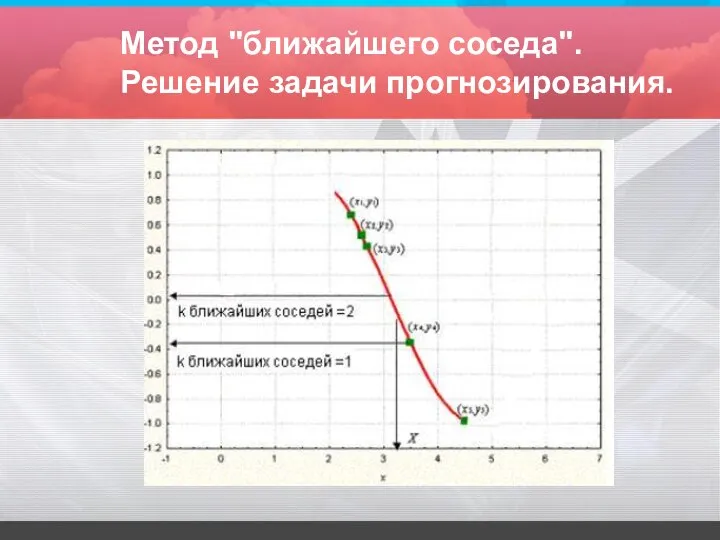
Метод "ближайшего соседа". Решение задачи прогнозирования.
Метод "ближайшего соседа". Решение задачи прогнозирования.

Метод "ближайшего соседа". Оценка параметра k методом кросс-проверки.
Кросс-проверка - известный метод
Метод "ближайшего соседа". Оценка параметра k методом кросс-проверки.
Кросс-проверка - известный метод

Метод "ближайшего соседа". Примеры использования и реализации.
Использование - программное обеспечение центра
Метод "ближайшего соседа". Примеры использования и реализации.
Использование - программное обеспечение центра
 Рогнеда
Рогнеда Ассемблер
Ассемблер Системы счисления
Системы счисления как добавить изображение
как добавить изображение CRM на базе Битрикс24. Решения для управления взаимоотношениями с клиентами
CRM на базе Битрикс24. Решения для управления взаимоотношениями с клиентами Комплекс упражнений для глаз Бородина Т. А., учитель информатики ОУ СОШ №3 «ОЦ» г. Сызрани
Комплекс упражнений для глаз Бородина Т. А., учитель информатики ОУ СОШ №3 «ОЦ» г. Сызрани Разработка АИС для автосалона ООО НАМИ
Разработка АИС для автосалона ООО НАМИ Вход в тестовую и «реальную» базу данных системы «АЦК-Госзаказ»
Вход в тестовую и «реальную» базу данных системы «АЦК-Госзаказ» On-line management tool for Applause Recognition Program. Автоматизация системы награждения сотрудников компании
On-line management tool for Applause Recognition Program. Автоматизация системы награждения сотрудников компании Информатика. Информатизация
Информатика. Информатизация Тема: «Настройка параметров страницы Word 2007» Пузакова Кристина Васильевна Учитель математики и информатики ГБОУ СОШ №918
Тема: «Настройка параметров страницы Word 2007» Пузакова Кристина Васильевна Учитель математики и информатики ГБОУ СОШ №918 Введение в нагрузочное тестирование ПО
Введение в нагрузочное тестирование ПО Создание сайта с помощью конструктора сайтов Google
Создание сайта с помощью конструктора сайтов Google Разработка и внедрение системы безопасности организации на базе серверной ОС Windows Server 2003
Разработка и внедрение системы безопасности организации на базе серверной ОС Windows Server 2003 Языки программирования
Языки программирования Оперативная память
Оперативная память  Ассоциативные правила в маркетинге и медицине
Ассоциативные правила в маркетинге и медицине Лингвистические особенности интернет-коммуникации как составляющей медиа-дискурса
Лингвистические особенности интернет-коммуникации как составляющей медиа-дискурса ОРГАНИЗАЦИЯ И СТРУКТУРА ТЕЛЕКОММУНИКАЦИОННЫХ КОМПЬЮТЕРНЫХ СЕТЕЙ
ОРГАНИЗАЦИЯ И СТРУКТУРА ТЕЛЕКОММУНИКАЦИОННЫХ КОМПЬЮТЕРНЫХ СЕТЕЙ Портфолио учителя. Учимся создавать электронное портфолио
Портфолио учителя. Учимся создавать электронное портфолио Микропроцессорные системы МИКРОРПОЦЕССОРЫ И МИКРОЭВМ
Микропроцессорные системы МИКРОРПОЦЕССОРЫ И МИКРОЭВМ  Компьютерная графика
Компьютерная графика С# тілінде деректер базасымен жұмыс істеу технологиялары
С# тілінде деректер базасымен жұмыс істеу технологиялары Как защититься от кибермошенничества
Как защититься от кибермошенничества Расчеты с использование электронных таблиц Обработка числовой информации Учитель информатики МОУ СОШ№ 8 г. Камышина Колпакова Л
Расчеты с использование электронных таблиц Обработка числовой информации Учитель информатики МОУ СОШ№ 8 г. Камышина Колпакова Л Процессоры фирмы Intel до Pentium III
Процессоры фирмы Intel до Pentium III  Презентация "Создание сайта" - скачать презентации по Информатике
Презентация "Создание сайта" - скачать презентации по Информатике D-PDI рекомендации по работе в системе
D-PDI рекомендации по работе в системе