- Абстрактные типы данных

Содержание
- 2. Абстрактный тип данных (АТД) это тип данных, который предоставляет для работы с элементами этого типа определенный
- 4. Суть абстракции Вся внутренняя структура спрятана от разработчика программного обеспечения. Абстрактный тип данных определяет набор функций,
- 5. Абстрактные структуры данных Конкретные реализации АТД называются абстрактными структурами данных.
- 6. Интерфейсы В программировании АТД обычно представляются в виде интерфейсов, которые скрывают соответствующие реализации типов. Программисты работают
- 7. Инкапсуляция Такой подход соответствует принципу инкапсуляции в объектно-ориентированном программировании. Пока структура данных поддерживает интерфейс, все программы,
- 8. Модульность АТД позволяют достичь модульности программных продуктов и иметь несколько альтернативных взаимозаменяемых реализаций отдельного модуля.
- 9. Примеры АТД Список Стек Очередь Очередь с приоритетом Ассоциативный массив
- 10. Список это абстрактный тип данных, представляющий собой упорядоченный набор значений, в котором некоторое значение может встречаться
- 11. Списки в функциональных языках являются фундаментальной структурой Большинство функциональных языков имеет встроенные средства для работы со
- 12. Стек структура данных, представляющая собой список элементов, организованных по принципу LIFO(англ. last in — first out,
- 13. Стек поместить элемент в стек push(…) извлечь элемент из стека pop(…) посмотреть не элемент на стеке
- 14. Стек на базе массива const int SIZE=50; struct stack { тип arr [SIZE]; тип * top;
- 15. тип top(stack s) { if (s.top == s.arr) { throw ("Stack Underflow"); } return *(s.top-1); }
- 16. Стек для рекурсивных алгоритмов Обход дерева в качестве тип используем t_ptr struct stack { t_ptr arr
- 17. init (st); p= tree; flag = 1; while ( flag ) { if (p) { push
- 18. Выражение, дерево трансляции, ПОЛИЗ (A+B)*(C+D)-E AB+CD+*E
- 19. ПОЛИЗ - форма записи математических выражений, в которой операнды расположены перед знаками операций. Вычисление выражения, записанного
- 21. Стек вычислений AB+CD+*E
- 22. Получение ПОЛИЗ из исходного выражения может выполняться с использованием стека на основе простого алгоритма, предложенного Дейкстpой.
- 23. Алгоритм Дейкстры Пpосматpивается исходная строка символов слева направо, операнды переписываются в выходную строку, а знаки операций
- 24. в) если очередной символ из исходной строки есть открывающая скобка, то он проталкивается в стек; г)
- 25. Трансляция в ПОЛИЗ (A+B)*(C+D)-E
- 26. struct stack { char arr [SIZE]; char * top; }; stack st; char v[ ] =―
- 27. while (*str) { if (is_letter(*str)) {*str1=*str; str1++;} else if (*str==‗(‗) push(st,*str); else { while (! empty(st)
- 28. while (!empty(st)) { c=pop(st); *str1=c; str1++; }
- 29. Очередь структура данных с дисциплиной доступа к элементам «первый пришел — первый вышел» (FIFO, First In
- 30. Дек (двусвязная очередь) (от англ. deque — double ended queue; двухсторонняя очередь, двусвязный список, очередь с
- 31. Очередь с приоритетом АТД, поддерживающий три операции: InsertWithPriority: добавить в очередь элемент с нaзначенным приоритетом. GetNext:
- 32. Реализация на базе массива const int N= . . .; //размер очереди struct Queue { int
- 33. Очередь на базе циклического массива const int N=. . .; //размер очереди struct Queue { int
- 34. Очередь на базе циклического массива void push ( Queue &Q, int value) { if ((Q.last%(N-1))+1==Q.first) throw("Overflow");
- 35. Множество тип данных, хранящий информацию о присутствии в множестве объектов любого счетного типа. Наиболее эффективная реализация
- 36. Ассоциативный массив (словарь) АТД, позволяющий хранить пары вида «(ключ, значение)» и поддерживающий операции добавления пары, а
- 37. Ассоциативный массив не может хранить две пары с одинаковыми ключами. Ассоциативный массив с точки зрения интерфейса
- 39. Скачать презентацию

Абстрактный тип данных (АТД)
это тип данных, который предоставляет для работы с
Абстрактный тип данных (АТД)
это тип данных, который предоставляет для работы с


Суть абстракции
Вся внутренняя структура спрятана от
разработчика программного обеспечения.
Абстрактный тип данных определяет
Суть абстракции
Вся внутренняя структура спрятана от
разработчика программного обеспечения.
Абстрактный тип данных определяет

Абстрактные структуры данных
Конкретные реализации АТД называются
абстрактными структурами данных.
Абстрактные структуры данных
Конкретные реализации АТД называются
абстрактными структурами данных.

Интерфейсы
В программировании АТД обычно представляются в виде интерфейсов, которые скрывают
соответствующие реализации
Интерфейсы
В программировании АТД обычно представляются в виде интерфейсов, которые скрывают
соответствующие реализации

Инкапсуляция
Такой подход соответствует принципу инкапсуляции
в объектно-ориентированном программировании.
Пока структура данных поддерживает интерфейс,
все
Инкапсуляция
Такой подход соответствует принципу инкапсуляции
в объектно-ориентированном программировании.
Пока структура данных поддерживает интерфейс,
все

Модульность
АТД позволяют достичь модульности программных
продуктов и иметь несколько альтернативных
взаимозаменяемых реализаций отдельного
Модульность
АТД позволяют достичь модульности программных
продуктов и иметь несколько альтернативных
взаимозаменяемых реализаций отдельного

Примеры АТД
Список
Стек
Очередь
Очередь с приоритетом
Ассоциативный массив
Примеры АТД
Список
Стек
Очередь
Очередь с приоритетом
Ассоциативный массив

Список
это абстрактный тип данных, представляющий собой
упорядоченный набор значений, в котором некоторое
значение
Список
это абстрактный тип данных, представляющий собой
упорядоченный набор значений, в котором некоторое
значение

Списки в функциональных языках
являются фундаментальной структурой
Большинство функциональных языков имеет
встроенные средства для
Списки в функциональных языках
являются фундаментальной структурой
Большинство функциональных языков имеет
встроенные средства для

Стек
структура данных, представляющая собой список элементов, организованных по принципу LIFO(англ. last
Стек
структура данных, представляющая собой список элементов, организованных по принципу LIFO(англ. last

Стек
поместить элемент в стек push(…)
извлечь элемент из стека pop(…)
посмотреть не элемент
Стек
поместить элемент в стек push(…)
извлечь элемент из стека pop(…)
посмотреть не элемент

Стек на базе массива
const int SIZE=50;
struct stack {
тип arr [SIZE];
тип *
Стек на базе массива
const int SIZE=50;
struct stack {
тип arr [SIZE];
тип *

тип top(stack s) {
if (s.top == s.arr) { throw ("Stack Underflow");
тип top(stack s) {
if (s.top == s.arr) { throw ("Stack Underflow");

Стек для рекурсивных алгоритмов
Обход дерева
в качестве тип используем t_ptr
struct stack
Стек для рекурсивных алгоритмов
Обход дерева
в качестве тип используем t_ptr
struct stack

init (st);
p= tree;
flag = 1;
while ( flag ) {
if (p) {
push
init (st);
p= tree;
flag = 1;
while ( flag ) {
if (p) {
push
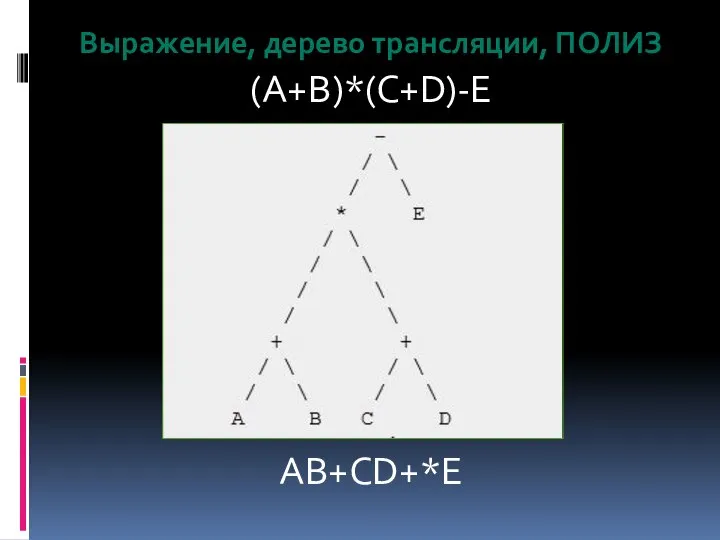
Выражение, дерево трансляции, ПОЛИЗ
(A+B)*(C+D)-E
AB+CD+*E
Выражение, дерево трансляции, ПОЛИЗ
(A+B)*(C+D)-E
AB+CD+*E

ПОЛИЗ - форма записи математических выражений, в которой операнды расположены перед
ПОЛИЗ - форма записи математических выражений, в которой операнды расположены перед


Стек вычислений
AB+CD+*E
Стек вычислений
AB+CD+*E

Получение ПОЛИЗ из исходного выражения может выполняться с использованием стека на
Получение ПОЛИЗ из исходного выражения может выполняться с использованием стека на

Алгоритм Дейкстры
Пpосматpивается исходная строка символов слева направо, операнды переписываются в выходную
Алгоритм Дейкстры
Пpосматpивается исходная строка символов слева направо, операнды переписываются в выходную

в) если очередной символ из исходной строки есть открывающая скобка, то
в) если очередной символ из исходной строки есть открывающая скобка, то

Трансляция в ПОЛИЗ
(A+B)*(C+D)-E
Трансляция в ПОЛИЗ
(A+B)*(C+D)-E
![struct stack { char arr [SIZE]; char * top; }; stack](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/719439/slide-25.jpg)
struct stack {
char arr [SIZE];
char * top;
};
stack st;
char v[ ] =―
struct stack {
char arr [SIZE];
char * top;
};
stack st;
char v[ ] =―
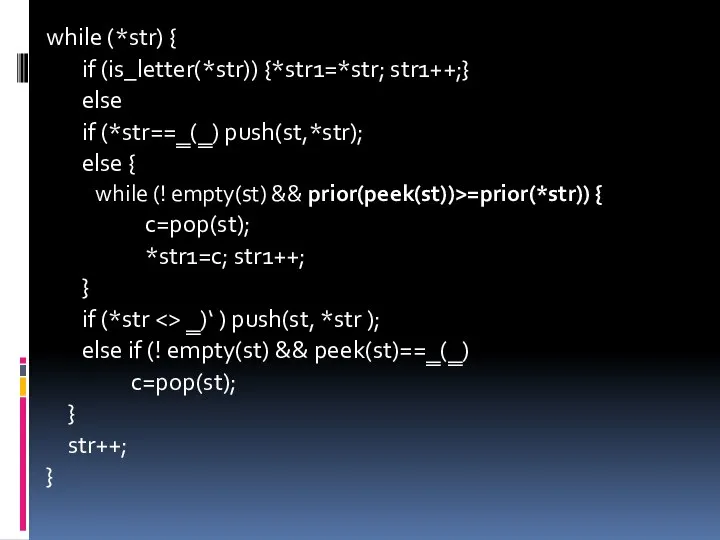
while (*str) {
if (is_letter(*str)) {*str1=*str; str1++;}
else
if (*str==‗(‗) push(st,*str);
else {
while (! empty(st)
while (*str) {
if (is_letter(*str)) {*str1=*str; str1++;}
else
if (*str==‗(‗) push(st,*str);
else {
while (! empty(st)

while (!empty(st)) {
c=pop(st);
*str1=c;
str1++;
}
while (!empty(st)) {
c=pop(st);
*str1=c;
str1++;
}

Очередь
структура данных с дисциплиной доступа к
элементам «первый пришел — первый вышел»
(FIFO,
Очередь
структура данных с дисциплиной доступа к
элементам «первый пришел — первый вышел»
(FIFO,

Дек (двусвязная очередь)
(от англ. deque — double ended queue; двухсторонняя очередь,
Дек (двусвязная очередь)
(от англ. deque — double ended queue; двухсторонняя очередь,

Очередь с приоритетом
АТД, поддерживающий три операции:
InsertWithPriority: добавить в очередь элемент с
нaзначенным
Очередь с приоритетом
АТД, поддерживающий три операции:
InsertWithPriority: добавить в очередь элемент с
нaзначенным

Реализация на базе массива
const int N= . . .; //размер очереди
struct
Реализация на базе массива
const int N= . . .; //размер очереди
struct

Очередь на базе циклического массива
const int N=. . .; //размер очереди
struct
Очередь на базе циклического массива
const int N=. . .; //размер очереди
struct

Очередь на базе циклического массива
void push ( Queue &Q, int value)
Очередь на базе циклического массива
void push ( Queue &Q, int value)

Множество
тип данных, хранящий информацию о присутствии в
множестве объектов любого счетного типа.
Множество
тип данных, хранящий информацию о присутствии в
множестве объектов любого счетного типа.

Ассоциативный массив (словарь)
АТД, позволяющий хранить пары вида «(ключ, значение)» и поддерживающий
Ассоциативный массив (словарь)
АТД, позволяющий хранить пары вида «(ключ, значение)» и поддерживающий

Ассоциативный массив не может хранить две пары с одинаковыми ключами.
Ассоциативный массив
Ассоциативный массив не может хранить две пары с одинаковыми ключами.
Ассоциативный массив
 Разработка робота на основе платформы Аrduino в качестве учебного пособия для МДК 02.03 Мехатроника и робототехника
Разработка робота на основе платформы Аrduino в качестве учебного пособия для МДК 02.03 Мехатроника и робототехника Действия с информацией. Хранение информации 5 класс Учитель информатики Елена Геннадьевна Лопатина
Действия с информацией. Хранение информации 5 класс Учитель информатики Елена Геннадьевна Лопатина Компьютер изнутри
Компьютер изнутри Безопасность детей в сети интернет. Родители и дети-вместе в интернете
Безопасность детей в сети интернет. Родители и дети-вместе в интернете Условная функция и логические выражения в табличном процессоре Excel
Условная функция и логические выражения в табличном процессоре Excel Әлеуметтік желілердің қазіргі жастардың дүниетанымына
Әлеуметтік желілердің қазіргі жастардың дүниетанымына Информационные системы и технологии в экономике. Тема 4. Структура ЭИС
Информационные системы и технологии в экономике. Тема 4. Структура ЭИС Интернет как средство связи. Влияние интернета на речь
Интернет как средство связи. Влияние интернета на речь С++ // язык программирования
С++ // язык программирования Относительная сложность. Колмогоровский подход
Относительная сложность. Колмогоровский подход Фундаментальная информатика и информационные технологии
Фундаментальная информатика и информационные технологии Двоичное представление информации в компьютере. Представление чисел в компьютере
Двоичное представление информации в компьютере. Представление чисел в компьютере Основные понятия и определения. Классификация архитектур информационных систем
Основные понятия и определения. Классификация архитектур информационных систем Программа для обучения. Наша команда Liga
Программа для обучения. Наша команда Liga Познавая Сурский край
Познавая Сурский край Что такое OpenGL?
Что такое OpenGL? Project report Активиа 14 дней
Project report Активиа 14 дней Базовые типы данных и ввод-вывод. Лабораторная работа №1
Базовые типы данных и ввод-вывод. Лабораторная работа №1 Принципы построения сетей документальной электросвязи
Принципы построения сетей документальной электросвязи Раздел 7 Линейный анализ устойчивости
Раздел 7 Линейный анализ устойчивости  Цифровые вычислительные устройства и микропроцессоры приборных комплексов
Цифровые вычислительные устройства и микропроцессоры приборных комплексов Кодирование чисел. Системы счисления
Кодирование чисел. Системы счисления Что такое современные медиа. И почему они гораздо больше, чем СМИ
Что такое современные медиа. И почему они гораздо больше, чем СМИ Обработка lightroom. Задание
Обработка lightroom. Задание К/р №4 ИНФО-9 по теме «Редакторы, таблицы, базы данных» 4
К/р №4 ИНФО-9 по теме «Редакторы, таблицы, базы данных» 4 Презентация "Поколения ЭВМ" - скачать презентации по Информатике
Презентация "Поколения ЭВМ" - скачать презентации по Информатике УИС «Моё дело»
УИС «Моё дело» Информация и информатика
Информация и информатика