- Data Mining – технология добычи данных

Содержание
- 2. Технология Data Mining Data Mining переводится как "добыча" или "раскопка данных". Нередко рядом с Data Mining
- 3. В связи с совершенствованием технологий записи и хранения данных на людей обрушились колоссальные потоки информационной руды
- 4. Традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа данных, откровенно спасовала перед лицом
- 5. Таблица - Примеры формулировок задач при использовании методов OLAP и Data Mining Важное положение Data Mining
- 6. Рисунок 1. Уровни знаний, извлекаемых из данных OLAP
- 7. Литература 1. А.А. Барсегян «Методы и модели анализа данных: OLAP и Data Mining», Санкт-Петербург, изд-во БХВ-Петрбург,
- 8. Определение Data Mining В целом технологию Data Mining достаточно точно определяет Григорий Пиатецкий-Шапиро — один из
- 9. Традиционные методы анализа данных (статистические методы) и OLAP в основном ориентированы на проверку заранее сформулированных гипотез
- 10. Двухмерная таблица "объект-атрибут" разведенный в браке
- 11. Основные понятия Данные - это необработанный материал, предоставляемый поставщиками данных и используемый потребителями для формирования информации
- 12. Измерение - процесс присвоения чисел характеристикам изучаемых объектов согласно определенному правилу. В процессе подготовки данных измеряется
- 13. Атрибуты Многие инструменты Data Mining при импорте данных из других источников предлагают выбрать тип шкалы для
- 14. Шкалы Шкала - правило, в соответствии с которым объектам присваиваются числа. Существует пять типов шкал измерений:
- 15. Порядковая шкала (ordinal scale) - шкала, в которой числа присваивают объектам для обозначения относительной позиции объектов,
- 16. Интервальная шкала (interval scale) - шкала, разности между значениями которой могут быть вычислены, однако их отношения
- 17. Относительная шкала (ratio scale) - шкала, в которой есть определенная точка отсчета и возможны отношения между
- 18. Дихотомическая шкала (dichotomous scale) - шкала, содержащая только две категории. Пример такой шкалы: пол (мужской и
- 19. Задачи анализа данных Классификация (Classification) Наиболее простая и распространенная задача Data Mining. В результате решения задачи
- 20. Ассоциация (Associations) В ходе решения задачи поиска ассоциативных правил отыскиваются закономерности между связанными событиями в наборе
- 21. Прогнозирование (Forecasting) В результате решения задачи прогнозирования на основе особенностей исторических данных оцениваются пропущенные или же
- 26. Сфера применения Data Mining Сфера применения Data Mining ничем не ограничена — она везде, где имеются
- 27. Розничная торговля Предприятия розничной торговли сегодня собирают подробную информацию о каждой отдельной покупке, используя кредитные карточки
- 28. Банковское дело Достижения технологии Data Mining используются в банковском деле для решения следующих распространенных задач: выявление
- 29. Телекоммуникации В области телекоммуникаций методы Data Mining помогают компаниям более энергично продвигать свои программы маркетинга и
- 30. Страхование Страховые компании в течение ряда лет накапливают большие объемы данных. Здесь обширное поле деятельности для
- 31. Типы закономерностей Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining: ассоциация, последовательность, классификация,
- 32. С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается
- 33. Классы систем Data Mining Data Mining является мультидисциплинарной областью, возникшей и развивающейся на базе достижений прикладной
- 34. Предметно-ориентированные аналитические системы Предметно-ориентированные аналитические системы очень разнообразны. Наиболее широкий подкласс таких систем, получивший распространение в
- 35. Статистические пакеты Последние версии почти всех известных статистических пакетов включают наряду с традиционными статистическими методами также
- 36. Нейронные сети Это большой класс систем, архитектура которых имеет аналогию с построением нервной ткани из нейронов.
- 37. Рисунок 5. Нейросеть, реализующая двух-слойный персептрон Структура биологического нейрона 1943 году Дж. Маккалоки и У. Питт
- 38. Основным недостатком нейросетевой парадигмы является необходимость иметь очень большой объем обучающей выборки. Другой существенный недостаток заключается
- 39. Системы рассуждений на основе аналогичных случаев Идея систем case based reasoning — CBR — на первый
- 40. Деревья решений (decision trees) Деревья решения являются одним из наиболее популярных подходов к решению задач Data
- 41. Для принятия решения, к какому классу отнести некоторый объект или ситуацию, требуется ответить на вопросы, стоящие
- 42. Генетические алгоритмы Data Mining не основная область применения генетических алгоритмов. Их нужно рассматривать скорее как мощное
- 43. Генетические алгоритмы удобны тем, что их легко распараллеливать. Например, можно разбить поколение на несколько групп и
- 44. Эволюционное программирование Проиллюстрируем современное состояние данного подхода на примере системы PolyAnalyst — российской разработке, получившей сегодня
- 45. Другое направление эволюционного программирования связано с поиском зависимости целевых переменных от остальных в форме функций какого-то
- 46. Алгоритмы ограниченного перебора Алгоритмы ограниченного перебора были предложены в середине 60-х годов М.М. Бонгардом для поиска
- 47. Системы для визуализации многомерных данных В той или иной мере средства для графического отображения данных поддерживаются
- 48. Рисунок 8. Визуализация данных системой DataMiner 3D Налог расходы рекомендации
- 49. Выводы 1. Рынок систем Data Mining экспоненциально развивается. В этом развитии принимают участие практически все крупнейшие
- 51. Скачать презентацию

Технология Data Mining
Data Mining переводится как "добыча" или "раскопка данных".
Технология Data Mining
Data Mining переводится как "добыча" или "раскопка данных".

В связи с совершенствованием технологий записи и хранения данных на людей
В связи с совершенствованием технологий записи и хранения данных на людей

Традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа
Традиционная математическая статистика, долгое время претендовавшая на роль основного инструмента анализа

Таблица - Примеры формулировок задач при использовании методов OLAP и Data
Таблица - Примеры формулировок задач при использовании методов OLAP и Data
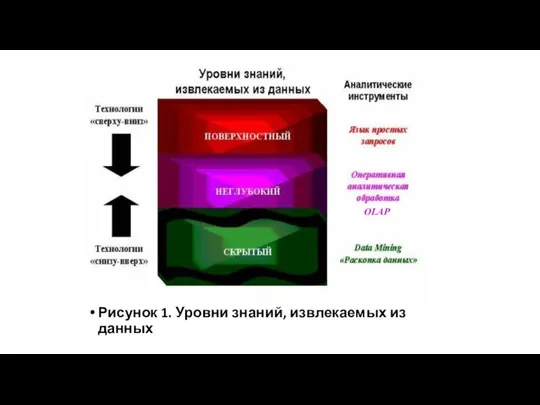
Рисунок 1. Уровни знаний, извлекаемых из данных
OLAP
Рисунок 1. Уровни знаний, извлекаемых из данных
OLAP

Литература
1. А.А. Барсегян «Методы и модели анализа данных: OLAP и Data
Литература
1. А.А. Барсегян «Методы и модели анализа данных: OLAP и Data

Определение Data Mining
В целом технологию Data Mining достаточно точно определяет Григорий
Определение Data Mining
В целом технологию Data Mining достаточно точно определяет Григорий

Традиционные методы анализа данных (статистические методы) и OLAP в основном ориентированы
Традиционные методы анализа данных (статистические методы) и OLAP в основном ориентированы
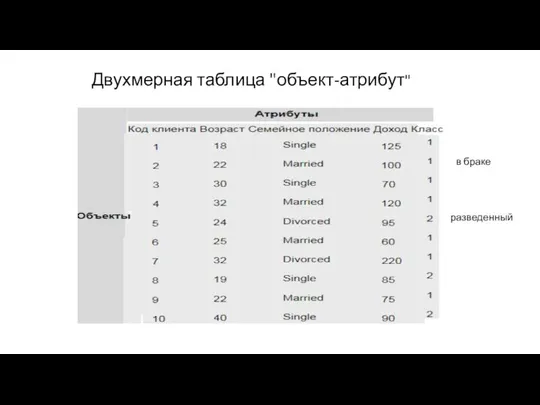
Двухмерная таблица "объект-атрибут"
разведенный
в браке
Двухмерная таблица "объект-атрибут"
разведенный
в браке

Основные понятия
Данные - это необработанный материал, предоставляемый поставщиками данных и используемый
Основные понятия
Данные - это необработанный материал, предоставляемый поставщиками данных и используемый

Измерение - процесс присвоения чисел характеристикам изучаемых объектов согласно определенному правилу.
Измерение - процесс присвоения чисел характеристикам изучаемых объектов согласно определенному правилу.

Атрибуты
Многие инструменты Data Mining при импорте данных из других источников предлагают
Атрибуты
Многие инструменты Data Mining при импорте данных из других источников предлагают

Шкалы
Шкала - правило, в соответствии с которым объектам присваиваются числа.
Существует пять
Шкалы
Шкала - правило, в соответствии с которым объектам присваиваются числа.
Существует пять

Порядковая шкала (ordinal scale) - шкала, в которой числа присваивают объектам
Порядковая шкала (ordinal scale) - шкала, в которой числа присваивают объектам

Интервальная шкала (interval scale) - шкала, разности между значениями которой могут
Интервальная шкала (interval scale) - шкала, разности между значениями которой могут

Относительная шкала (ratio scale) - шкала, в которой есть определенная точка
Относительная шкала (ratio scale) - шкала, в которой есть определенная точка

Дихотомическая шкала (dichotomous scale) - шкала, содержащая только две категории.
Пример такой
Дихотомическая шкала (dichotomous scale) - шкала, содержащая только две категории.
Пример такой

Задачи анализа данных
Классификация (Classification) Наиболее простая и распространенная задача Data Mining.
Задачи анализа данных
Классификация (Classification) Наиболее простая и распространенная задача Data Mining.

Ассоциация (Associations) В ходе решения задачи поиска ассоциативных правил отыскиваются закономерности
Ассоциация (Associations) В ходе решения задачи поиска ассоциативных правил отыскиваются закономерности

Прогнозирование (Forecasting) В результате решения задачи прогнозирования на основе особенностей исторических
Прогнозирование (Forecasting) В результате решения задачи прогнозирования на основе особенностей исторических




Сфера применения Data Mining
Сфера применения Data Mining ничем не ограничена
Сфера применения Data Mining
Сфера применения Data Mining ничем не ограничена

Розничная торговля
Предприятия розничной торговли сегодня собирают подробную информацию о каждой отдельной
Розничная торговля
Предприятия розничной торговли сегодня собирают подробную информацию о каждой отдельной

Банковское дело
Достижения технологии Data Mining используются в банковском деле для решения
Банковское дело
Достижения технологии Data Mining используются в банковском деле для решения

Телекоммуникации
В области телекоммуникаций методы Data Mining помогают компаниям более энергично продвигать
Телекоммуникации
В области телекоммуникаций методы Data Mining помогают компаниям более энергично продвигать

Страхование
Страховые компании в течение ряда лет накапливают большие объемы данных. Здесь
Страхование
Страховые компании в течение ряда лет накапливают большие объемы данных. Здесь

Типы закономерностей
Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data
Типы закономерностей
Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data

С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот
С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот

Классы систем Data Mining
Data Mining является мультидисциплинарной областью, возникшей и развивающейся
Классы систем Data Mining
Data Mining является мультидисциплинарной областью, возникшей и развивающейся

Предметно-ориентированные аналитические системы
Предметно-ориентированные аналитические системы очень разнообразны. Наиболее широкий подкласс таких
Предметно-ориентированные аналитические системы
Предметно-ориентированные аналитические системы очень разнообразны. Наиболее широкий подкласс таких

Статистические пакеты
Последние версии почти всех известных статистических пакетов включают наряду с
Статистические пакеты
Последние версии почти всех известных статистических пакетов включают наряду с

Нейронные сети
Это большой класс систем, архитектура которых имеет аналогию с построением
Нейронные сети
Это большой класс систем, архитектура которых имеет аналогию с построением
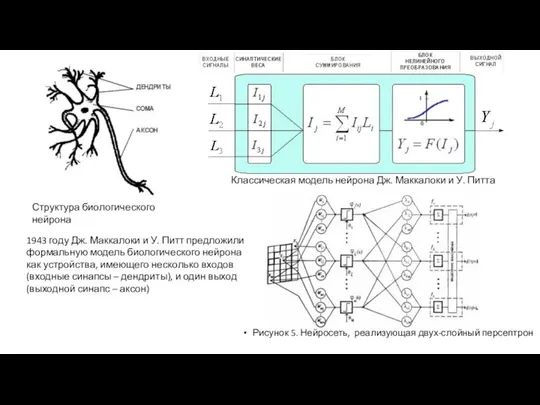
Рисунок 5. Нейросеть, реализующая двух-слойный персептрон
Структура биологического нейрона
1943 году Дж.
Рисунок 5. Нейросеть, реализующая двух-слойный персептрон
Структура биологического нейрона
1943 году Дж.

Основным недостатком нейросетевой парадигмы является необходимость иметь очень большой объем обучающей
Основным недостатком нейросетевой парадигмы является необходимость иметь очень большой объем обучающей

Системы рассуждений на основе аналогичных случаев
Идея систем case based reasoning —
Системы рассуждений на основе аналогичных случаев
Идея систем case based reasoning —
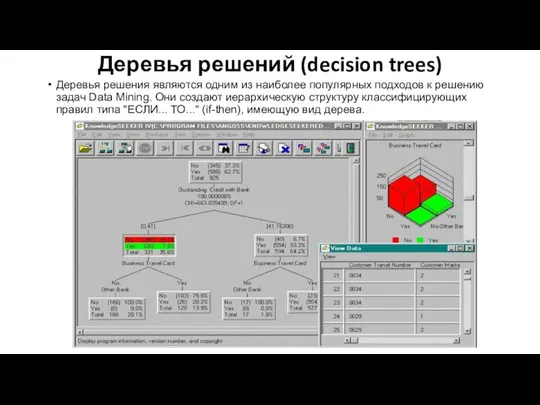
Деревья решений (decision trees)
Деревья решения являются одним из наиболее популярных подходов
Деревья решений (decision trees)
Деревья решения являются одним из наиболее популярных подходов

Для принятия решения, к какому классу отнести некоторый объект или ситуацию,
Для принятия решения, к какому классу отнести некоторый объект или ситуацию,

Генетические алгоритмы
Data Mining не основная область применения генетических алгоритмов. Их нужно
Генетические алгоритмы
Data Mining не основная область применения генетических алгоритмов. Их нужно

Генетические алгоритмы удобны тем, что их легко распараллеливать. Например, можно разбить
Генетические алгоритмы удобны тем, что их легко распараллеливать. Например, можно разбить

Эволюционное программирование
Проиллюстрируем современное состояние данного подхода на примере системы PolyAnalyst —
Эволюционное программирование
Проиллюстрируем современное состояние данного подхода на примере системы PolyAnalyst —

Другое направление эволюционного программирования связано с поиском зависимости целевых переменных от
Другое направление эволюционного программирования связано с поиском зависимости целевых переменных от

Алгоритмы ограниченного перебора
Алгоритмы ограниченного перебора были предложены в середине 60-х годов
Алгоритмы ограниченного перебора
Алгоритмы ограниченного перебора были предложены в середине 60-х годов

Системы для визуализации многомерных данных
В той или иной мере средства для
Системы для визуализации многомерных данных
В той или иной мере средства для

Рисунок 8. Визуализация данных системой DataMiner 3D
Налог
расходы
рекомендации
Рисунок 8. Визуализация данных системой DataMiner 3D
Налог
расходы
рекомендации

Выводы
1. Рынок систем Data Mining экспоненциально развивается. В этом развитии принимают участие
Выводы
1. Рынок систем Data Mining экспоненциально развивается. В этом развитии принимают участие
 Проектирование и разработка информационной системы Автомастерская
Проектирование и разработка информационной системы Автомастерская Устройства вывода информации (принтеры)
Устройства вывода информации (принтеры) Сеть социальных контактов
Сеть социальных контактов Информационные технологии. Профессиональная проба 7-8 классы
Информационные технологии. Профессиональная проба 7-8 классы Сетевые технологии и кодировки в компьютерных системах
Сетевые технологии и кодировки в компьютерных системах Поиск научной информации
Поиск научной информации Легедна о драконах
Легедна о драконах Лекция 5. Протоколы транспортного уровня
Лекция 5. Протоколы транспортного уровня 121176
121176 Введение в тестирование ПО. Программа курса
Введение в тестирование ПО. Программа курса AtmosphereSense симулятор атмос ферного давления
AtmosphereSense симулятор атмос ферного давления Презентация "Возможности операционной системы Linux" - скачать презентации по Информатике
Презентация "Возможности операционной системы Linux" - скачать презентации по Информатике Возможности графических редакторов
Возможности графических редакторов Антивирусные программы
Антивирусные программы  Методические особенности использования мобильных технологий при изучении математики
Методические особенности использования мобильных технологий при изучении математики Linux (Линукс)
Linux (Линукс) Полезная информация
Полезная информация Історія створення Windows
Історія створення Windows Визначення функцій в PHP
Визначення функцій в PHP Основы программирования в оболочке Free Pascal
Основы программирования в оболочке Free Pascal Розробка інтерфейсу мобільного додатку Rozcloud
Розробка інтерфейсу мобільного додатку Rozcloud Дистанционные курсы для ОЗО
Дистанционные курсы для ОЗО Логические основы компьютера
Логические основы компьютера Компьютерная графика
Компьютерная графика  Получение новой информации. Обработка информации. Способы кодирования
Получение новой информации. Обработка информации. Способы кодирования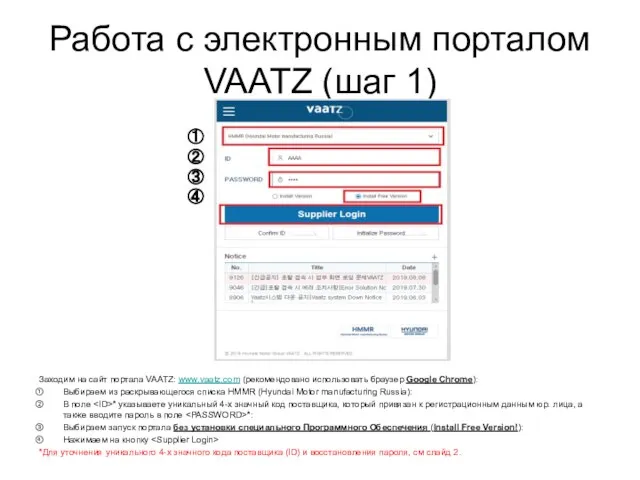 Работа с электронным порталом VAATZ (шаг 1)
Работа с электронным порталом VAATZ (шаг 1) Алфавит С#. Типы данных
Алфавит С#. Типы данных McDonalds administration tool
McDonalds administration tool