- Data Scientist. Рекомендательные системы

Содержание
- 2. План работы: 1. Постановка задачи, исходные данные и что с ними нужно сделать. 2. Подсчет топ
- 3. Постановка задачи: Нам нужно разработать рекомендательную систему подбора товаров, исходя из индивидуальных особенностей каждого пользователя. Представим
- 4. Roadmap экспериментов: Постановка задачи «Наивный» алгоритм Implicit ALS Implicit kNN LightFM Работают на основе разряженных матриц
- 5. Разбор алгоритмов:
- 6. Разбор алгоритмов: (СЛАЙД НА УДАЛЕНИЕ) 2. Implicit ALS (Alternating Least Squares) Хорошая удобная библиотека, главная фишка
- 7. Несколько слов о разряженных матрицах. Ключевым элементов в работе вышеописанных библиотек является т н разряженная матрица
- 8. Алгоритм на основе нейронной сети. В качестве вишенки на торте и чего-то по-настоящему рабочего было решено
- 9. Архитектура нейросети: 2 входа отдельно для продуктовых и пользовательских признаков Превращаем данные в одномерный тензор Объединение
- 10. Интересные наблюдения. Приведу две наиболее удачные конфигурации сетей: одна дала наилучшие финальные рекомендации, другая наивысшую точность
- 11. Некоторые технические моменты. Вид итогового датафрейма, отсортированного по величине выхода сигмоиды: Как дополнялись предсказания: Набор списка
- 13. Скачать презентацию

План работы:
1. Постановка задачи, исходные данные и что с ними нужно
План работы:
1. Постановка задачи, исходные данные и что с ними нужно
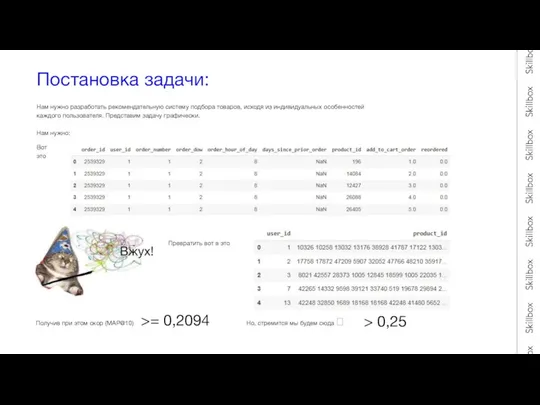
Постановка задачи:
Нам нужно разработать рекомендательную систему подбора товаров, исходя из индивидуальных
Постановка задачи:
Нам нужно разработать рекомендательную систему подбора товаров, исходя из индивидуальных
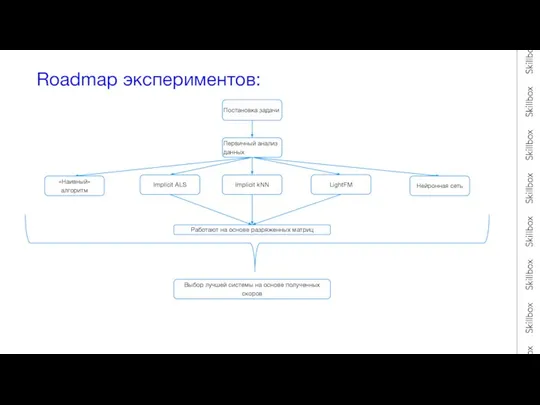
Roadmap экспериментов:
Постановка задачи
«Наивный» алгоритм
Implicit ALS
Implicit kNN
LightFM
Работают на основе разряженных матриц
Первичный анализ
Roadmap экспериментов:
Постановка задачи
«Наивный» алгоритм
Implicit ALS
Implicit kNN
LightFM
Работают на основе разряженных матриц
Первичный анализ

Разбор алгоритмов:
Разбор алгоритмов:

Разбор алгоритмов: (СЛАЙД НА УДАЛЕНИЕ)
2. Implicit ALS (Alternating Least Squares)
Хорошая удобная
Разбор алгоритмов: (СЛАЙД НА УДАЛЕНИЕ)
2. Implicit ALS (Alternating Least Squares)
Хорошая удобная
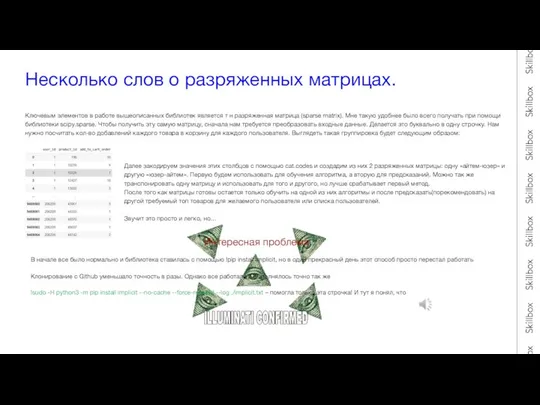
Несколько слов о разряженных матрицах.
Ключевым элементов в работе вышеописанных библиотек является
Несколько слов о разряженных матрицах.
Ключевым элементов в работе вышеописанных библиотек является

Алгоритм на основе нейронной сети.
В качестве вишенки на торте и чего-то
Алгоритм на основе нейронной сети.
В качестве вишенки на торте и чего-то

Архитектура нейросети:
2 входа отдельно для продуктовых и пользовательских признаков
Превращаем данные в
Архитектура нейросети:
2 входа отдельно для продуктовых и пользовательских признаков
Превращаем данные в
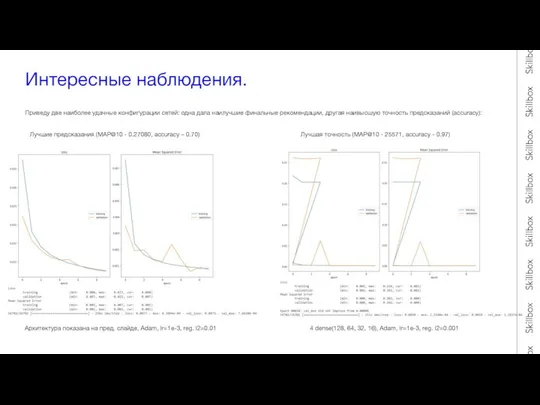
Интересные наблюдения.
Приведу две наиболее удачные конфигурации сетей: одна дала наилучшие финальные
Интересные наблюдения.
Приведу две наиболее удачные конфигурации сетей: одна дала наилучшие финальные

Некоторые технические моменты.
Вид итогового датафрейма, отсортированного по величине выхода сигмоиды:
Как дополнялись
Некоторые технические моменты.
Вид итогового датафрейма, отсортированного по величине выхода сигмоиды:
Как дополнялись
 Требования к конкурсным работам в номинации Лучший сайт
Требования к конкурсным работам в номинации Лучший сайт Модуль “Выписки и проверка контрагента”
Модуль “Выписки и проверка контрагента” Обработка информации. 5 класс
Обработка информации. 5 класс Цикл с предусловием
Цикл с предусловием Интерфейсы МатКапитал
Интерфейсы МатКапитал Предистория информатики
Предистория информатики Introduction to cloud computing
Introduction to cloud computing Презентация "Устройства ввода - вывода" - скачать презентации по Информатике
Презентация "Устройства ввода - вывода" - скачать презентации по Информатике Кодирование и декодирование информации (7 класс)
Кодирование и декодирование информации (7 класс) Блочная модель
Блочная модель Принципы организации сетей
Принципы организации сетей Рекламная сеть Яндекс
Рекламная сеть Яндекс Программа Sketch Up для MrDoors
Программа Sketch Up для MrDoors Социальная сеть как основа современной социальной структуры
Социальная сеть как основа современной социальной структуры Лагерь. Обучение в стиле Майнкрафт
Лагерь. Обучение в стиле Майнкрафт Оcнови роботи в пакеті Scilab
Оcнови роботи в пакеті Scilab Печать документов Борисов В.А. Красноармейский филиал ГОУ ВПО «Академия народного хозяйства при Правительстве РФ» Красноарме
Печать документов Борисов В.А. Красноармейский филиал ГОУ ВПО «Академия народного хозяйства при Правительстве РФ» Красноарме Техническое задание. Система голосования v3. Регистрация. Страница регистрации на сайте
Техническое задание. Система голосования v3. Регистрация. Страница регистрации на сайте Заголовок слайда. Вставьте Ваш текст
Заголовок слайда. Вставьте Ваш текст Информация и информационные процессы. Информационные технологии
Информация и информационные процессы. Информационные технологии Thieme - руководство пользователя на русском языке
Thieme - руководство пользователя на русском языке Creating MO Script with AMOS
Creating MO Script with AMOS Лабораторная работа №1 «Структура и влияние различных факторов на динамику ВВП РФ» Силантьев В.Б.<number><number> Профессор кафед
Лабораторная работа №1 «Структура и влияние различных факторов на динамику ВВП РФ» Силантьев В.Б.<number><number> Профессор кафед Домашняя работа по информатике 9 класс
Домашняя работа по информатике 9 класс Презентация "Информационная культура"
Презентация "Информационная культура" Книга Excel в библиотеке общих документов. Отчет
Книга Excel в библиотеке общих документов. Отчет Графики и диаграммы. Визуализация многорядных данных
Графики и диаграммы. Визуализация многорядных данных Internet технологии. Лекция 7.2
Internet технологии. Лекция 7.2