- Физические модели баз данных

Содержание
- 3. С точки зрения пользователя, файлом называется поименованная линейная последовательность записей, расположенных на внешних носителях, то есть
- 4. Модель хранения информации на устройстве последовательного доступа Файл как линейная последовательность записей
- 5. Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД), являются файлами прямого доступа. В
- 6. Иерархическая организация файловой структуры хранения Для файлов с постоянной длиной записи адрес размещения записи с номером
- 7. Файлы прямого доступа обеспечивают наиболее быстрый доступ к произвольным записям, и их использование считается наиболее перспективным
- 8. В некоторых очень редких случаях возможно построение функции, которая по значению ключа однозначно вычисляет адрес (номер
- 9. Суть методов хэширования состоит в том, что мы берем значения ключа ( или некоторые его характеристики)
- 10. Если вновь заносимая запись имеет значение функции хэширования такое же, которое использовала другая запись, уже имеющаяся
- 11. При поиске записи также сначала вычисляется значение ее хэш-функции и считывается первая запись в цепочке синонимов,
- 12. Организация стратегии свободного замещения При этой стратегии файловое пространство не разделяется на области, но для каждой
- 13. Индексные файлы Несмотря на высокую эффективность хэш-адресации, в файловых структурах далеко не всегда удается найти соответствующую
- 14. Файлы с плотным индексом, или индексно-прямые файлы В файлах с плотным индексом основная область содержит последовательность
- 15. Длина доступа к произвольной записи оценивается не в абсолютных значениях, а в количестве обращений к устройству
- 16. На диске записи файлов хранятся в блоках. Размер блока определяется физическими особенностями дискового контроллера и операционной
- 17. Мы имеем следующие исходные данные: Длина записи файла (LZ) — 128 байт. Длина первичного ключа (LK)
- 18. Количество блоков, которое необходимо для хранения всех 100 000 записей, мы определим по следующей формуле: КВО
- 19. Когда исчезает свободная область, возникает переполнение индексной области. В этом случае возможны два решения: либо перестроить
- 20. Файлы с неплотным индексом, или индексно-последовательные файлы Попробуем усовершенствовать способ хранения файла: будем хранить его в
- 21. В индексной области мы теперь ищем нужный блок по заданному значению первичного ключа. Так как все
- 22. Рассмотрим процедуры добавления и удаления новой записи при подобном индексе. Здесь новая запись должна заноситься сразу
- 23. Организация индексов в виде B-tree (В-деревьев) (balanced) Развитие предыдущего метода: если мы построим неплотный индекс, то
- 24. И над третьим уровнем строим новый, и на нем будет всего один блок, в котором будет
- 25. Построенное В-дерево
- 26. Для моделирования отношений 1:М (один-ко-многим) и М:М (многие-ко-мно-гим) на файловых структурах используется принцип организации цепочек записей
- 27. Алгоритм нахождения нужных записей «подчиненного» файла Шаг 1. Ищется запись в «основном» файле в соответствии с
- 28. Алгоритм удаления записи из цепочки «подчиненного» файла Шаг 1. Ищется удаляемая запись в соответствии с ранее
- 29. Добавление записи на первое место в цепочке. Добавление записи в конец цепочки. Добавление записи на заданное
- 30. Инвертированный список в общем случае — это двухуровневая индексная структура. Здесь на первом уровне находится файл
- 31. Построение инвертированного списка по номеру группы для списка студентов
- 32. При модификации основного файла происходит следующая последовательность действий: Изменяется запись основного файла. Исключается старая ссылка на
- 33. Модели физической организации данных при бесфайловой организации Файловая структура и система управления файлами являются прерогативой операционной
- 34. Физическая организация является в настоящий момент наиболее динамичной частью СУБД. Стремительно расширяются возможность устройств внешней памяти,
- 36. Чанк (chank) — представляет собой часть диска, физическое пространство на диске, которое ассоциировано одному процессу (on
- 37. Первый экстент задается при создании нового объекта типа таблица, его размер задается при создании. EXTENTSIZE —
- 38. Механизм удвоения размера экстента: если число выделяемых экстентов для процесса растет в пропорции, кратной 16, то
- 39. Слот — это 4-байтовое слово, 2 байта соответствуют смещению строки на странице и 2 байта —
- 40. При упорядочении строк на страницах не происходит физического перемещения строк, все манипуляции происходят со слотами. При
- 42. Скачать презентацию


С точки зрения пользователя, файлом называется поименованная линейная последовательность записей, расположенных
С точки зрения пользователя, файлом называется поименованная линейная последовательность записей, расположенных
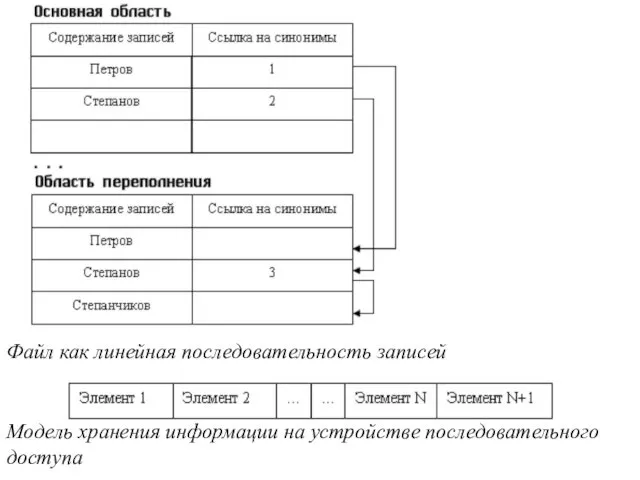
Модель хранения информации на устройстве последовательного доступа
Файл как линейная последовательность записей
Модель хранения информации на устройстве последовательного доступа
Файл как линейная последовательность записей

Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД),
Файлы с постоянной длиной записи, расположенные на устройствах прямого доступа (УПД),
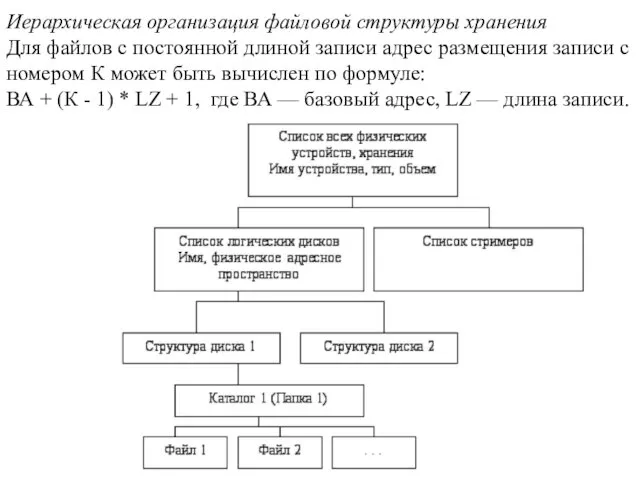
Иерархическая организация файловой структуры хранения
Для файлов с постоянной длиной записи адрес
Иерархическая организация файловой структуры хранения Для файлов с постоянной длиной записи адрес

Файлы прямого доступа обеспечивают наиболее быстрый доступ к произвольным записям, и
Файлы прямого доступа обеспечивают наиболее быстрый доступ к произвольным записям, и

В некоторых очень редких случаях возможно построение функции, которая по значению
В некоторых очень редких случаях возможно построение функции, которая по значению

Суть методов хэширования состоит в том, что мы берем значения ключа
Суть методов хэширования состоит в том, что мы берем значения ключа

Если вновь заносимая запись имеет значение функции хэширования такое же, которое
Если вновь заносимая запись имеет значение функции хэширования такое же, которое

При поиске записи также сначала вычисляется значение ее хэш-функции и считывается
При поиске записи также сначала вычисляется значение ее хэш-функции и считывается

Организация стратегии свободного замещения
При этой стратегии файловое пространство не разделяется на
Организация стратегии свободного замещения
При этой стратегии файловое пространство не разделяется на

Индексные файлы
Несмотря на высокую эффективность хэш-адресации, в файловых структурах далеко не
Индексные файлы
Несмотря на высокую эффективность хэш-адресации, в файловых структурах далеко не

Файлы с плотным индексом, или индексно-прямые файлы
В файлах с плотным индексом
Файлы с плотным индексом, или индексно-прямые файлы
В файлах с плотным индексом

Длина доступа к произвольной записи оценивается не в абсолютных значениях, а
Длина доступа к произвольной записи оценивается не в абсолютных значениях, а

На диске записи файлов хранятся в блоках. Размер блока определяется физическими
На диске записи файлов хранятся в блоках. Размер блока определяется физическими

Мы имеем следующие исходные данные:
Длина записи файла (LZ) — 128 байт.
Мы имеем следующие исходные данные:
Длина записи файла (LZ) — 128 байт.

Количество блоков, которое необходимо для хранения всех 100 000 записей, мы
Количество блоков, которое необходимо для хранения всех 100 000 записей, мы

Когда исчезает свободная область, возникает переполнение индексной области. В этом случае
Когда исчезает свободная область, возникает переполнение индексной области. В этом случае

Файлы с неплотным индексом, или индексно-последовательные файлы
Попробуем усовершенствовать способ хранения файла:
Файлы с неплотным индексом, или индексно-последовательные файлы
Попробуем усовершенствовать способ хранения файла:

В индексной области мы теперь ищем нужный блок по заданному значению
В индексной области мы теперь ищем нужный блок по заданному значению

Рассмотрим процедуры добавления и удаления новой записи при подобном индексе.
Здесь новая
Рассмотрим процедуры добавления и удаления новой записи при подобном индексе.
Здесь новая

Организация индексов в виде B-tree (В-деревьев) (balanced)
Развитие предыдущего метода: если
Организация индексов в виде B-tree (В-деревьев) (balanced)
Развитие предыдущего метода: если

И над третьим уровнем строим новый, и на нем будет всего
И над третьим уровнем строим новый, и на нем будет всего
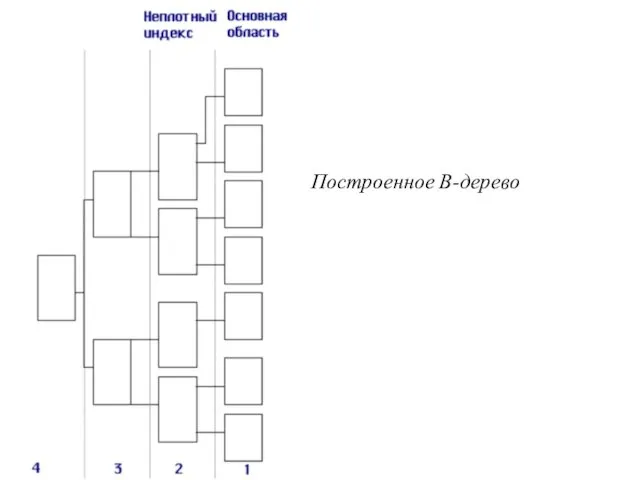
Построенное В-дерево
Построенное В-дерево

Для моделирования отношений 1:М (один-ко-многим) и М:М (многие-ко-мно-гим) на файловых структурах
Для моделирования отношений 1:М (один-ко-многим) и М:М (многие-ко-мно-гим) на файловых структурах

Алгоритм нахождения нужных записей «подчиненного» файла
Шаг 1. Ищется запись в «основном»
Алгоритм нахождения нужных записей «подчиненного» файла
Шаг 1. Ищется запись в «основном»

Алгоритм удаления записи из цепочки «подчиненного» файла
Шаг 1. Ищется удаляемая запись
Алгоритм удаления записи из цепочки «подчиненного» файла
Шаг 1. Ищется удаляемая запись

Добавление записи на первое место в цепочке.
Добавление записи в конец цепочки.
Добавление
Добавление записи на первое место в цепочке.
Добавление записи в конец цепочки.
Добавление

Инвертированный список в общем случае — это двухуровневая индексная структура.
Здесь
Инвертированный список в общем случае — это двухуровневая индексная структура.
Здесь

Построение инвертированного списка по номеру группы для списка студентов
Построение инвертированного списка по номеру группы для списка студентов

При модификации основного файла происходит следующая последовательность действий:
Изменяется запись основного файла.
Исключается
При модификации основного файла происходит следующая последовательность действий:
Изменяется запись основного файла.
Исключается

Модели физической организации данных при бесфайловой организации
Файловая структура и система управления
Модели физической организации данных при бесфайловой организации
Файловая структура и система управления

Физическая организация является в настоящий момент наиболее динамичной частью СУБД. Стремительно
Физическая организация является в настоящий момент наиболее динамичной частью СУБД. Стремительно


Чанк (chank) — представляет собой часть диска, физическое пространство на диске,
Чанк (chank) — представляет собой часть диска, физическое пространство на диске,

Первый экстент задается при создании нового объекта типа таблица, его размер
Первый экстент задается при создании нового объекта типа таблица, его размер

Механизм удвоения размера экстента: если число выделяемых экстентов для процесса растет
Механизм удвоения размера экстента: если число выделяемых экстентов для процесса растет

Слот — это 4-байтовое слово, 2 байта соответствуют смещению строки на
Слот — это 4-байтовое слово, 2 байта соответствуют смещению строки на

При упорядочении строк на страницах не происходит физического перемещения строк, все
При упорядочении строк на страницах не происходит физического перемещения строк, все
 Сравнение множеств (2 класс)
Сравнение множеств (2 класс) Компьютерные вирусы, типы вирусов, методы борьбы с вирусами (9 класс)
Компьютерные вирусы, типы вирусов, методы борьбы с вирусами (9 класс) Презентация "АРХИТЕКТУРА КОМПЬЮТЕРА" - скачать презентации по Информатике
Презентация "АРХИТЕКТУРА КОМПЬЮТЕРА" - скачать презентации по Информатике Кодирование и декодирование информации
Кодирование и декодирование информации Презентация "ИНТЕРНЕТ - ЗА И ПРОТИВ" - скачать презентации по Информатике
Презентация "ИНТЕРНЕТ - ЗА И ПРОТИВ" - скачать презентации по Информатике Элементы статистической обработки данных 7 класс
Элементы статистической обработки данных 7 класс  СМИ и соцсети
СМИ и соцсети Понятие Интернет
Понятие Интернет Автоматизация процессов разработки веб-приложения
Автоматизация процессов разработки веб-приложения Лабораторная работа №1 «Структура и влияние различных факторов на динамику ВВП РФ» Силантьев В.Б.<number><number> Профессор кафед
Лабораторная работа №1 «Структура и влияние различных факторов на динамику ВВП РФ» Силантьев В.Б.<number><number> Профессор кафед MS Projec
MS Projec Компьютерная графика, как вид изобразительного искусства Урок информатики и ИЗО в 5 классе
Компьютерная графика, как вид изобразительного искусства Урок информатики и ИЗО в 5 классе  Отработка навыков создания твёрдых тел сложной конфигурации в трёхмерном режиме Solidworks. Изделия медицинского назначения
Отработка навыков создания твёрдых тел сложной конфигурации в трёхмерном режиме Solidworks. Изделия медицинского назначения Единицы измерения информации
Единицы измерения информации Как работать сYouTube? Социальный сервис, предоставляющие услуги хостинга любительского видео.
Как работать сYouTube? Социальный сервис, предоставляющие услуги хостинга любительского видео. Сайты для родителей о детском чтении
Сайты для родителей о детском чтении Презентация по информатике Понятие алгоритма. Виды алгоритмов
Презентация по информатике Понятие алгоритма. Виды алгоритмов  Проект консольная игра поддавки
Проект консольная игра поддавки Алгоритм Из опыта работы Ермаковой В. В., учителя информатики МБОУ СОШ № 19 города Белово
Алгоритм Из опыта работы Ермаковой В. В., учителя информатики МБОУ СОШ № 19 города Белово  Аттестационная работа. Использование проектной и исследовательской деятельности на уроках информатики
Аттестационная работа. Использование проектной и исследовательской деятельности на уроках информатики Памятка по реагированию на информацию в сети Интернет
Памятка по реагированию на информацию в сети Интернет Общая характеристика специальности программная инженерия
Общая характеристика специальности программная инженерия Разработка Web-сайтов с использованием языка разметки гипертекста HTML
Разработка Web-сайтов с использованием языка разметки гипертекста HTML Sirius для ведения образовательных процессов
Sirius для ведения образовательных процессов Sketch Meme. На случай важных переговоров
Sketch Meme. На случай важных переговоров Основы логики и логические основы компьютера
Основы логики и логические основы компьютера Найти корни квадратного уравнения Ax2+Bx+C=0
Найти корни квадратного уравнения Ax2+Bx+C=0 Медиалог. Комплексная информационная система для поликлиники, стационара, сети медицинских учреждений
Медиалог. Комплексная информационная система для поликлиники, стационара, сети медицинских учреждений