- Информационный анализатор текстов и литературных произведений – программа Pen-Mastery

Содержание
- 2. В Интернет-пространстве при желании можно найти практически любую информацию и в любой форме. Но чаще всего
- 3. Но человеческое сознание меняется медленно. И при самых новейших технологиях остаются некоторые «старые» проблемы, среди которых
- 4. На данный момент существуют такие лингвистические системы:
- 5. Цель работы: Разработка авторской программы – универсального анализатора машиночитаемых текстов Объект исследования: Предмет исследования: Процесс анализа
- 6. Получение определенных объективных (математических или статистических) характеристик информации, которая содержится в текстовом файле; Организация модульной структуры
- 7. При составлении данной программы были сформулированы следующие рабочие гипотезы : Известно, что разнообразие (или богатство) речи
- 8. … рабочие гипотезы – 2 : Известно, что у сочинителя обязательно вырабатывается некоторый «авторский стиль», который
- 9. Не секрет, что субъективные факторы могут влиять на результаты какой-либо экспертизы. Математика способна удалить субъективизм из
- 10. Методика исследования анализируемого текста - 2 Среди этих величин было выбрано три основных : энтропия текста
- 11. Для подсчета названных величин программа «Pen-Mastery» проводит двухэтапную декомпозицию анализируемого текста: сначала весь текст раскладывается на
- 12. «Как оно работает ?» - 2 Теперь можно считать набор приведенных математических характеристик достаточно информативным и
- 13. Поскольку VBA уже много лет является отраслевым стандартом для управления приложениями MS Office под Windows, то,
- 14. Приступая к работе с программой, пользователь должен разместить анализируемый текст в «строго определенный Word-файл» (т.е. в
- 15. Сама регистрация подлежащего анализу текста происходит в два этапа. Сначала «записывается» автор текста: Анализ текста в
- 16. Затем – название текста: Анализ текста в «Pen-Mastery v.1» : шаг 2
- 17. Программа «следит» за ошибками человека: если не было внесено ни одной регистрационной записи – идентификатора автора
- 18. После успешного завершения процедуры регистрации анализируемого текста программа выдает сообщение об этом. Теперь наступает фаза математического
- 19. После выполнения инструкций базового модуля на форме появляется сообщение об окончании анализа текста. Теперь пользователю доступны
- 20. Полнота выводимых на дисплей статистических характеристик исследуемого текста регулируется переключателем режимов: либо «main Stat. data», либо
- 21. Вывод дополнительных данных: Анализ текста в «Pen-Mastery v.1» : шаг 6
- 22. Выводы Программа-анализатор «Pen-Mastery» задумана и сделана как модульный конструктор, который функционирует по принципу наращивания возможностей. Такая
- 23. Алгоритмы анализа машиночитаемых текстов программы «Pen-Mastery» позволяют ее успешно применять как для специалистов, так и для
- 24. Спасибо за внимание ! Настоящая работы выполнена в рамках Регионального образовательного проекта “IT docentes FUTURUM” (ITDF),
- 26. Скачать презентацию

В Интернет-пространстве при желании можно найти практически любую информацию и
В Интернет-пространстве при желании можно найти практически любую информацию и

Но человеческое сознание меняется медленно. И при самых новейших технологиях
Но человеческое сознание меняется медленно. И при самых новейших технологиях

На данный момент существуют такие лингвистические системы:
На данный момент существуют такие лингвистические системы:

Цель работы:
Разработка авторской программы – универсального анализатора машиночитаемых текстов
Объект исследования:
Предмет
исследования:
Процесс анализа
Цель работы:
Разработка авторской программы – универсального анализатора машиночитаемых текстов
Объект исследования:
Предмет
исследования:
Процесс анализа

Получение определенных объективных (математических или статистических) характеристик информации, которая содержится в
Получение определенных объективных (математических или статистических) характеристик информации, которая содержится в

При составлении данной программы были сформулированы следующие рабочие гипотезы :
Известно,
При составлении данной программы были сформулированы следующие рабочие гипотезы :
Известно,

… рабочие гипотезы – 2 :
Известно, что у сочинителя обязательно
… рабочие гипотезы – 2 :
Известно, что у сочинителя обязательно

Не секрет, что субъективные факторы могут влиять на результаты какой-либо
Не секрет, что субъективные факторы могут влиять на результаты какой-либо

Методика исследования анализируемого текста - 2
Среди этих величин было выбрано три
Методика исследования анализируемого текста - 2
Среди этих величин было выбрано три

Для подсчета названных величин программа «Pen-Mastery» проводит двухэтапную декомпозицию анализируемого текста:
Для подсчета названных величин программа «Pen-Mastery» проводит двухэтапную декомпозицию анализируемого текста:

«Как оно работает ?» - 2
Теперь можно считать набор приведенных
«Как оно работает ?» - 2
Теперь можно считать набор приведенных
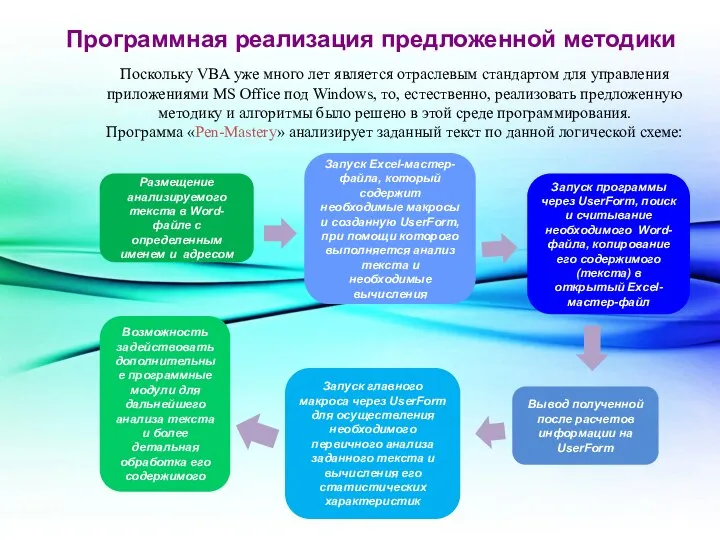
Поскольку VBA уже много лет является отраслевым стандартом для управления приложениями
Поскольку VBA уже много лет является отраслевым стандартом для управления приложениями

Приступая к работе с программой, пользователь должен разместить анализируемый текст в
Приступая к работе с программой, пользователь должен разместить анализируемый текст в
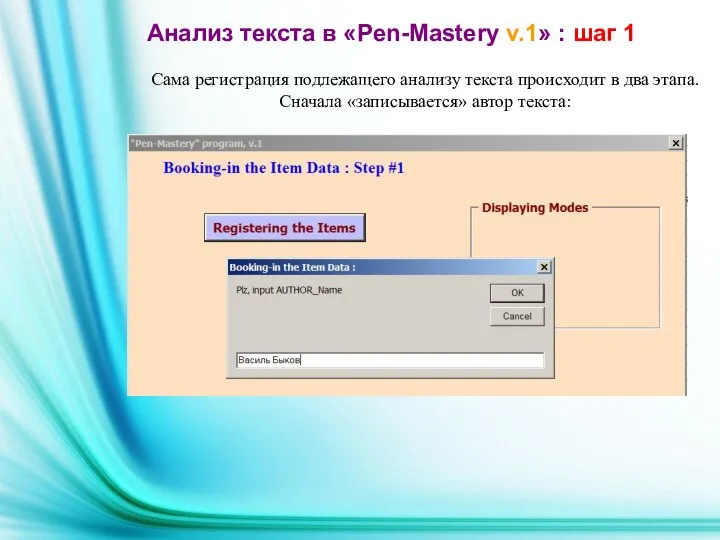
Сама регистрация подлежащего анализу текста происходит в два этапа.
Сначала «записывается» автор
Сама регистрация подлежащего анализу текста происходит в два этапа.
Сначала «записывается» автор

Затем – название текста:
Анализ текста в «Pen-Mastery v.1» : шаг 2
Затем – название текста:
Анализ текста в «Pen-Mastery v.1» : шаг 2
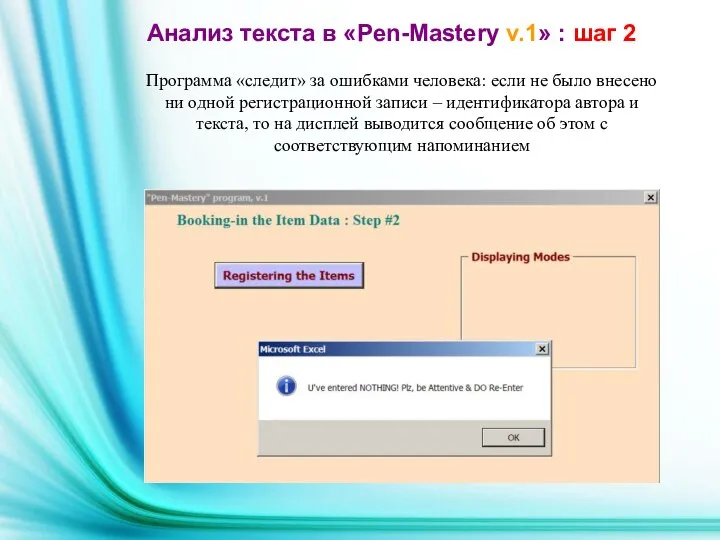
Программа «следит» за ошибками человека: если не было внесено ни одной
Программа «следит» за ошибками человека: если не было внесено ни одной

После успешного завершения процедуры регистрации анализируемого текста программа выдает сообщение об
После успешного завершения процедуры регистрации анализируемого текста программа выдает сообщение об
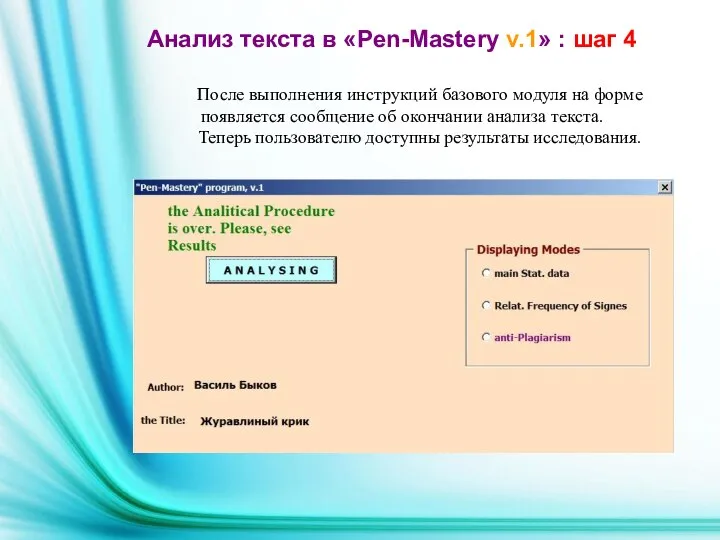
После выполнения инструкций базового модуля на форме появляется сообщение об окончании
После выполнения инструкций базового модуля на форме появляется сообщение об окончании

Полнота выводимых на дисплей статистических характеристик исследуемого текста регулируется переключателем режимов:
либо
Полнота выводимых на дисплей статистических характеристик исследуемого текста регулируется переключателем режимов:
либо

Вывод дополнительных данных:
Анализ текста в «Pen-Mastery v.1» : шаг 6
Вывод дополнительных данных:
Анализ текста в «Pen-Mastery v.1» : шаг 6

Выводы
Программа-анализатор «Pen-Mastery» задумана и сделана как модульный конструктор, который функционирует по
Выводы
Программа-анализатор «Pen-Mastery» задумана и сделана как модульный конструктор, который функционирует по

Алгоритмы анализа машиночитаемых текстов программы «Pen-Mastery» позволяют ее успешно применять как
Алгоритмы анализа машиночитаемых текстов программы «Pen-Mastery» позволяют ее успешно применять как

Спасибо за внимание !
Настоящая работы выполнена в рамках Регионального образовательного проекта
Спасибо за внимание !
Настоящая работы выполнена в рамках Регионального образовательного проекта
 Использование функций языка С++
Использование функций языка С++ Інтернет-технології в діяльності вищих навчальних закладів
Інтернет-технології в діяльності вищих навчальних закладів Состав персонального компьютера и периферийные устройства. (Часть 1)
Состав персонального компьютера и периферийные устройства. (Часть 1) Базы данных. Информационные системы
Базы данных. Информационные системы Презентация "Критерии и анализ благосостояния" - скачать презентации по Информатике
Презентация "Критерии и анализ благосостояния" - скачать презентации по Информатике Основные понятия баз данных
Основные понятия баз данных Киберспорт. Викторина
Киберспорт. Викторина SQL и NoSQL. Системы управления базами данных (СУБД)
SQL и NoSQL. Системы управления базами данных (СУБД) Методы разработки и выбора альтернатив
Методы разработки и выбора альтернатив Мои лучшие информационные интернет-ресурсы
Мои лучшие информационные интернет-ресурсы Экранизации игр
Экранизации игр Тема 1.2. Проектирование. 1. Нормализация БД (1)
Тема 1.2. Проектирование. 1. Нормализация БД (1) Дешифрация адреса
Дешифрация адреса 24 задание ЕГЭ по информатике
24 задание ЕГЭ по информатике Растровая графика
Растровая графика Основы защиты информации. Тема 7
Основы защиты информации. Тема 7 Вікіпедія на пальцях
Вікіпедія на пальцях Работа с аудио-редактором Audacity
Работа с аудио-редактором Audacity Классификация СУБД. Лекция 3
Классификация СУБД. Лекция 3 ИНФОРМАЦИОННЫЕ РЕВОЛЮЦИИ
ИНФОРМАЦИОННЫЕ РЕВОЛЮЦИИ  Карточная коллекционная игра
Карточная коллекционная игра Программное обеспечение Введение Прикладные программы Системные программы Системы программирования Правовая охрана прог
Программное обеспечение Введение Прикладные программы Системные программы Системы программирования Правовая охрана прог Вспомогательные алгоритмы и подпрограммы (9 класс.)
Вспомогательные алгоритмы и подпрограммы (9 класс.) Списки. Информатика для СПО
Списки. Информатика для СПО Подача заявки на программу дополнительного образования
Подача заявки на программу дополнительного образования Prolog – средство разработки экспертных систем. Назначение и структура экспертной системы
Prolog – средство разработки экспертных систем. Назначение и структура экспертной системы Информатика Учебник для 6 класса Л. Босова Выполнил: Фролов. А. 231группа
Информатика Учебник для 6 класса Л. Босова Выполнил: Фролов. А. 231группа  Экспертные системы. Принятие решений в системах ЗИ на основе нечеткой логики. Лекция 3
Экспертные системы. Принятие решений в системах ЗИ на основе нечеткой логики. Лекция 3