- Использование Ceph для организации файлового хранилища

Содержание
- 2. О продукте
- 4. Содержание доклада Предпосылки внедрения ФХ Варианты решений для ФХ Ceph: кратко о системе; варианты установки; принцип
- 5. Предпосылки внедрения ФХ в архитектуру
- 6. Инфраструктура до Ферма серверов приложений Отказоустойчивый кластер СУБД
- 7. 60% объема – тела документов БД сервиса
- 8. Инфраструктура после Ферма серверов приложений Отказоустойчивый кластер СУБД ...
- 9. Варианты решений для ФХ
- 10. Требования Распределенность Скорость Репликация данных Отказоустойчивость
- 11. Сравнение скоростей Физический сервер – источник файлов SSD диск vm – SMB-шара Анализируемый кластер Физический сервер
- 12. GlusterFS Последовательное копирование нескольких файлов по ~10 Гб: копирование в GlusterFS в 5-10 раз медленнее копирования
- 13. rsync Последовательное копирование нескольких небольших (мегабайты) и нескольких мелких (килобайты) файлов: rsync успевал реплицировать данные с
- 14. До окончания цикла из 10 повторений rsync ни разу не доживал rsync * . txt 1
- 15. Варианты доступа к данным в Ceph: Ceph Object Gateway (S3/Swift-совместимое API); CephFS – POSIX-совместимая файловая система;
- 16. Не было времени для реализации поддержки S3. Ceph + Object Gateway
- 17. Последовательное копирование нескольких файлов по ~10 Гб: копирование в CephFS в 2-3 раза медленнее копирования в
- 18. Скорость записи в кластер соизмерима со скоростью записи в SMB-шару. Ceph + RBD
- 19. Ceph + RBD
- 20. Что такое Ceph Ceph – сеть хранения данных. На каждом узле сети используются свои вычислительные ресурсы
- 21. MON – демон монитора, серверы с MON - мозги кластера. MON должно быть минимум 3 штуки.
- 22. Описание с картинками: https://habr.com/post/313644/ Все записываемые данные «складируются» в PG. Пулы данных состоят из PG. PG
- 23. Варианты установки
- 24. [global] mon_initial_members = admin-node, node01, node02 mon_host = 192.168.1.10:6789, 192.168.1.11:6789, 192.168.1.12:6789 auth_cluster_required = cephx auth_service_required =
- 25. ceph-deploy mon create-initial Инициализация кластера: ceph-deploy install admin-node node01 node02 node03 node04 Установка ПО Ceph на
- 26. ceph-deploy admin admin-node node01 node02 node03 node04 Добавление нод в кластер: ceph-deploy osd create --data /dev/vda
- 27. Репликация: другое здание/помещение; другая стойка; другая нода; OSD с наибольшим весом*; OSD с наибольшим свободным местом;
- 28. Советы по работе с OSD Иметь равное количество OSD на всех нодах. «Набор» размеров OSD на
- 29. Для настройки RBD в пуле данных используется сущность Image. Маппинг RBD происходит именно в Image. В
- 30. rbd map --pool documents --image data ceph-deploy install client ceph-deploy admin client Для подключения RBD лучше
- 31. Схема кластера admin-node node01 node02 osd.0 osd.1 osd.2 osd.3 client node03 node04 osd.4 osd.5 osd.6 osd.7
- 32. Размер RBD-образа не зависит от фактического суммарного объема OSD. Фактический суммарный объем всех OSD должен быть
- 33. При выходе из строя или недоступности OSD кластер автоматически начинает перебалансировку потерянных PG. Перед работами на
- 34. Указать новый максимальный размер образа (только вверх и надо учесть количество реплик): rbd resize --size 1390G
- 35. Цель – всегда иметь запас места на перебалансировку в случае смерти одной ноды. Легенда: 4 ноды
- 36. Плюсы: легко устанавливается и настраивается; быстрый; легко масштабируется; достаточное количество команд CLI для диагностики состояния кластера
- 37. Хранить бинарный контент в БД считается моветоном. Подавляющую часть нашего бинарного контента (тела документов) мы вынесли
- 38. https://docs.ceph.com/docs/master/ https://t.me/ceph_ru http://onreader.mdl.ru/MasteringCeph/content/Ch01.html Google + Яндекс Где искать помощь http://onreader.mdl.ru/MasteringCeph.2ed/content/Ch01.html
- 40. Скачать презентацию

О продукте
О продукте

Содержание доклада
Предпосылки внедрения ФХ
Варианты решений для ФХ
Ceph:
кратко о системе;
варианты установки;
принцип работы;
администрирование
Содержание доклада
Предпосылки внедрения ФХ
Варианты решений для ФХ
Ceph:
кратко о системе;
варианты установки;
принцип работы;
администрирование

Предпосылки внедрения ФХ
в архитектуру
Предпосылки внедрения ФХ
в архитектуру
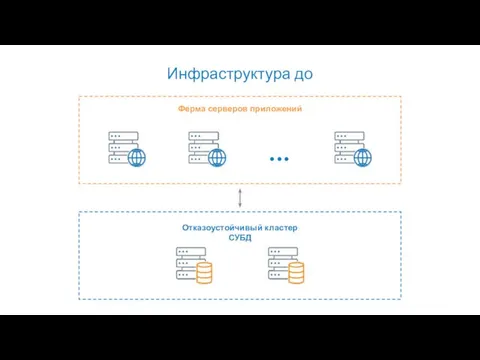
Инфраструктура до
Ферма серверов приложений
Отказоустойчивый кластер СУБД
Инфраструктура до
Ферма серверов приложений
Отказоустойчивый кластер СУБД

60% объема – тела документов
БД сервиса
60% объема – тела документов
БД сервиса
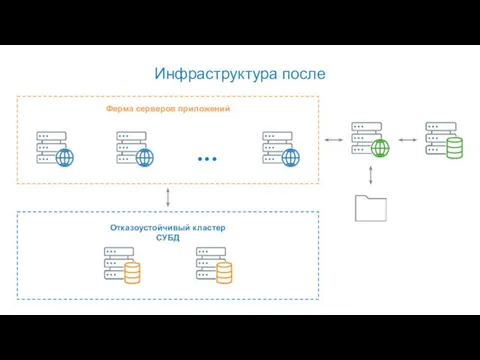
Инфраструктура после
Ферма серверов приложений
Отказоустойчивый кластер СУБД
...
Инфраструктура после
Ферма серверов приложений
Отказоустойчивый кластер СУБД
...

Варианты решений
для ФХ
Варианты решений
для ФХ

Требования
Распределенность
Скорость
Репликация данных
Отказоустойчивость
Требования
Распределенность
Скорость
Репликация данных
Отказоустойчивость
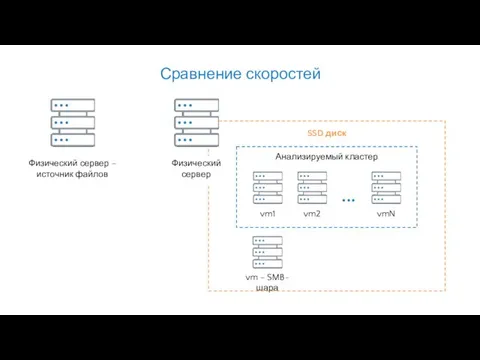
Сравнение скоростей
Физический сервер –
источник файлов
SSD диск
vm – SMB-шара
Анализируемый кластер
Физический
сервер
Сравнение скоростей
Физический сервер –
источник файлов
SSD диск
vm – SMB-шара
Анализируемый кластер
Физический
сервер

GlusterFS
Последовательное копирование нескольких файлов по ~10 Гб:
копирование в GlusterFS в
GlusterFS
Последовательное копирование нескольких файлов по ~10 Гб:
копирование в GlusterFS в

rsync
Последовательное копирование нескольких небольших (мегабайты)
и нескольких мелких (килобайты) файлов:
rsync успевал реплицировать
rsync
Последовательное копирование нескольких небольших (мегабайты)
и нескольких мелких (килобайты) файлов:
rsync успевал реплицировать

До окончания цикла
из 10 повторений rsync
ни разу не доживал
rsync
*
.
txt
1
Кб
5
Кб
10
До окончания цикла
из 10 повторений rsync
ни разу не доживал
rsync
*
.
txt
1
Кб
5
Кб
10

Варианты доступа к данным в Ceph:
Ceph Object Gateway (S3/Swift-совместимое API);
CephFS –
Варианты доступа к данным в Ceph:
Ceph Object Gateway (S3/Swift-совместимое API);
CephFS –

Не было времени для реализации поддержки S3.
Ceph + Object Gateway
Не было времени для реализации поддержки S3.
Ceph + Object Gateway

Последовательное копирование нескольких файлов по ~10 Гб:
копирование в CephFS в
Последовательное копирование нескольких файлов по ~10 Гб:
копирование в CephFS в

Скорость записи в кластер соизмерима со скоростью записи в SMB-шару.
Ceph +
Скорость записи в кластер соизмерима со скоростью записи в SMB-шару.
Ceph +

Ceph + RBD
Ceph + RBD

Что такое Ceph
Ceph – сеть хранения данных. На каждом узле сети
Что такое Ceph
Ceph – сеть хранения данных. На каждом узле сети

MON – демон монитора, серверы с MON - мозги кластера. MON
MON – демон монитора, серверы с MON - мозги кластера. MON

Описание с картинками: https://habr.com/post/313644/
Все записываемые данные «складируются» в PG.
Пулы данных состоят
Описание с картинками: https://habr.com/post/313644/
Все записываемые данные «складируются» в PG.
Пулы данных состоят

Варианты установки
Варианты установки
![[global] mon_initial_members = admin-node, node01, node02 mon_host = 192.168.1.10:6789, 192.168.1.11:6789, 192.168.1.12:6789](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/455050/slide-23.jpg)
[global]
mon_initial_members = admin-node, node01, node02
mon_host = 192.168.1.10:6789, 192.168.1.11:6789, 192.168.1.12:6789
auth_cluster_required = cephx
auth_service_required
[global]
mon_initial_members = admin-node, node01, node02
mon_host = 192.168.1.10:6789, 192.168.1.11:6789, 192.168.1.12:6789
auth_cluster_required = cephx
auth_service_required

ceph-deploy mon create-initial
Инициализация кластера:
ceph-deploy install admin-node node01 node02 node03 node04
Установка ПО
ceph-deploy mon create-initial
Инициализация кластера:
ceph-deploy install admin-node node01 node02 node03 node04
Установка ПО

ceph-deploy admin admin-node node01 node02 node03 node04
Добавление нод в кластер:
ceph-deploy osd
ceph-deploy admin admin-node node01 node02 node03 node04
Добавление нод в кластер:
ceph-deploy osd

Репликация:
другое здание/помещение;
другая стойка;
другая нода;
OSD с наибольшим весом*;
OSD с наибольшим свободным местом;
случайный
Репликация:
другое здание/помещение;
другая стойка;
другая нода;
OSD с наибольшим весом*;
OSD с наибольшим свободным местом;
случайный

Советы по работе с OSD
Иметь равное количество OSD на всех нодах.
«Набор»
Советы по работе с OSD
Иметь равное количество OSD на всех нодах.
«Набор»

Для настройки RBD в пуле данных используется сущность Image.
Маппинг RBD происходит
Для настройки RBD в пуле данных используется сущность Image.
Маппинг RBD происходит

rbd map --pool documents --image data
ceph-deploy install client
ceph-deploy admin client
Для подключения
rbd map --pool documents --image data
ceph-deploy install client
ceph-deploy admin client
Для подключения

Схема кластера
admin-node
node01
node02
osd.0
osd.1
osd.2
osd.3
client
node03
node04
osd.4
osd.5
osd.6
osd.7
/dev/rbd0
Схема кластера
admin-node
node01
node02
osd.0
osd.1
osd.2
osd.3
client
node03
node04
osd.4
osd.5
osd.6
osd.7
/dev/rbd0

Размер RBD-образа не зависит от фактического суммарного объема OSD.
Фактический суммарный объем
Размер RBD-образа не зависит от фактического суммарного объема OSD.
Фактический суммарный объем

При выходе из строя или недоступности OSD кластер автоматически начинает перебалансировку
При выходе из строя или недоступности OSD кластер автоматически начинает перебалансировку

Указать новый максимальный размер образа (только вверх и надо учесть количество
Указать новый максимальный размер образа (только вверх и надо учесть количество

Цель – всегда иметь запас места на перебалансировку в случае смерти
Цель – всегда иметь запас места на перебалансировку в случае смерти

Плюсы:
легко устанавливается и настраивается;
быстрый;
легко масштабируется;
достаточное количество команд CLI для диагностики состояния
Плюсы:
легко устанавливается и настраивается;
быстрый;
легко масштабируется;
достаточное количество команд CLI для диагностики состояния

Хранить бинарный контент в БД считается моветоном.
Подавляющую часть нашего бинарного контента
Хранить бинарный контент в БД считается моветоном.
Подавляющую часть нашего бинарного контента

https://docs.ceph.com/docs/master/
https://t.me/ceph_ru
http://onreader.mdl.ru/MasteringCeph/content/Ch01.html
Google + Яндекс
Где искать помощь
http://onreader.mdl.ru/MasteringCeph.2ed/content/Ch01.html
https://docs.ceph.com/docs/master/
https://t.me/ceph_ru
http://onreader.mdl.ru/MasteringCeph/content/Ch01.html
Google + Яндекс
Где искать помощь
http://onreader.mdl.ru/MasteringCeph.2ed/content/Ch01.html
 USB разъёмы
USB разъёмы Аттестационная работа. Проектная деятельность на уроках информатики. Электронные таблицы в жизни
Аттестационная работа. Проектная деятельность на уроках информатики. Электронные таблицы в жизни B-деревья
B-деревья Социальные сети. Влияние социальных сетей на нравственное формирование подростков
Социальные сети. Влияние социальных сетей на нравственное формирование подростков ЗАЩИТА ОТ НЕСАНКЦИОНИРОВАННОГО ДОСТУПА К ИНФОРМАЦИИ Информатика, 11 класс
ЗАЩИТА ОТ НЕСАНКЦИОНИРОВАННОГО ДОСТУПА К ИНФОРМАЦИИ Информатика, 11 класс Электронная цифровая подпись
Электронная цифровая подпись Операционная система Linux
Операционная система Linux Двоичное представление информации в компьютере. Представление чисел в компьютере
Двоичное представление информации в компьютере. Представление чисел в компьютере Как образуются понятия. Мысленное установление сходства
Как образуются понятия. Мысленное установление сходства ARTA_SMM_urok_0_2_chast_1
ARTA_SMM_urok_0_2_chast_1 Оценка количественных параметров текстовых документов
Оценка количественных параметров текстовых документов Аттестационная работа. Курс по выбору Дополнительные главы по информатике и ИКТ
Аттестационная работа. Курс по выбору Дополнительные главы по информатике и ИКТ Форматы графических файлов
Форматы графических файлов  Моделирование - презентация по Информатике_
Моделирование - презентация по Информатике_ The Frequency Domain
The Frequency Domain Процессор, системная плата 10 класс
Процессор, системная плата 10 класс Операционная система
Операционная система Алгоритм. Научное описание
Алгоритм. Научное описание Виды компьютерной графики
Виды компьютерной графики Структура компьютерных сетей
Структура компьютерных сетей Принципы построения распределенных баз данных
Принципы построения распределенных баз данных Какие лица отнесены к участникам дорожного движения?
Какие лица отнесены к участникам дорожного движения? Основы компьютерной графики и теории дизайна
Основы компьютерной графики и теории дизайна Дипломная работа на тему: Разработка интернет-портала салона «Версаль» Автор - студентка 5 курса специальности «Прикладная инф
Дипломная работа на тему: Разработка интернет-портала салона «Версаль» Автор - студентка 5 курса специальности «Прикладная инф Игра на нервах в играх жанра хоррор
Игра на нервах в играх жанра хоррор Руководство пользователя в Веб части системы
Руководство пользователя в Веб части системы Лексемы языка. Операторы языка. Программа на языке Си
Лексемы языка. Операторы языка. Программа на языке Си Дистанционные образовательные технологии
Дистанционные образовательные технологии