-
Коммуникационные операции «точка-точка» параллельное программирование

Содержание
- 2. кафедра ЮНЕСКО по НИТ Коммуникационные операции типа «точка-точка» К операциям этого типа относятся две представленные выше
- 3. кафедра ЮНЕСКО по НИТ Блокирующие функции Блокирующие функции подразумевают полное окончание операции после выхода из процедуры,
- 4. кафедра ЮНЕСКО по НИТ Неблокирующие функции Неблокирующие функции подразумевают совмещение операций обмена с другими операциями, поэтому
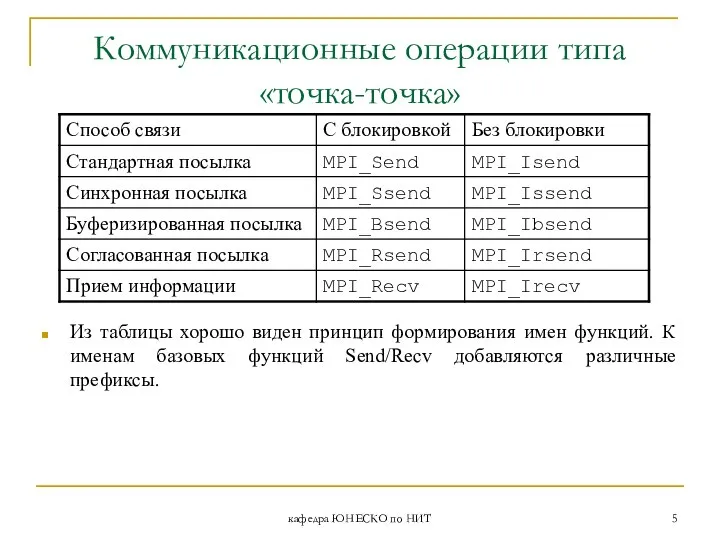
- 5. кафедра ЮНЕСКО по НИТ Коммуникационные операции типа «точка-точка» Из таблицы хорошо виден принцип формирования имен функций.
- 6. кафедра ЮНЕСКО по НИТ Коммуникационные операции типа «точка-точка»
- 7. кафедра ЮНЕСКО по НИТ MPI – Синхронная посылка Процессор-отправитель ожидает информацию о том, когда получатель примет
- 8. кафедра ЮНЕСКО по НИТ MPI – Буферизированная посылка или Несинхронная посылка Процессор-отправитель знает только когда сообщение
- 9. кафедра ЮНЕСКО по НИТ MPI–посылки без блокировки Неблокирующие операции немедленно возвращают управление программе. Программа выполняет следующие
- 10. кафедра ЮНЕСКО по НИТ Неблокирующие коммуникационные операции Использование неблокирующих коммуникационных операций более безопасно с точки зрения
- 11. кафедра ЮНЕСКО по НИТ Неблокирующие коммуникационные операции Неблокирующие операции используют специальный скрытый (opaque) объект "запрос обмена"
- 12. кафедра ЮНЕСКО по НИТ Функция передачи сообщений MPI_Isend Входные параметры: Выходные параметры:
- 13. кафедра ЮНЕСКО по НИТ Функция приема сообщений MPI_Irecv Входные параметры: Выходные параметры:
- 14. кафедра ЮНЕСКО по НИТ MPI – Non-Blocking Examples Выполнение других операций Выполнение других операций
- 15. кафедра ЮНЕСКО по НИТ Функция ожидания завершения неблокирующей операции MPI_Wait Входные параметры: Выходные параметры:
- 16. кафедра ЮНЕСКО по НИТ Функция проверки завершения неблокирующей операции MPI_Test Входные параметры: Выходные параметры:
- 17. MPI_Sendrecv – совмещение отправки и получения кафедра ЮНЕСКО по НИТ Выходные параметры: При использовании блокирующего режима
- 18. Нулевой процесс выполняет продолжительный цикл и после его выполнения посылает первому процессору значение вычислений цикла при
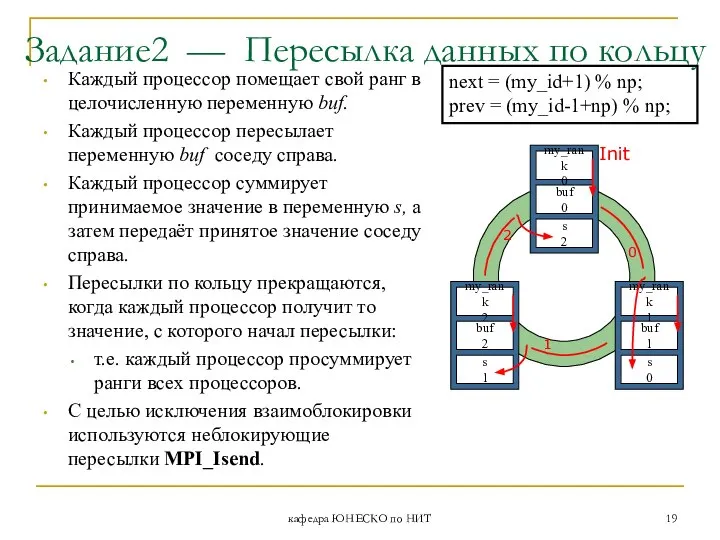
- 19. кафедра ЮНЕСКО по НИТ Задание2 — Пересылка данных по кольцу Init 0 1 2 Каждый процессор
- 21. Скачать презентацию

кафедра ЮНЕСКО по НИТ
Коммуникационные операции типа «точка-точка»
К операциям этого типа относятся
кафедра ЮНЕСКО по НИТ
Коммуникационные операции типа «точка-точка»
К операциям этого типа относятся

кафедра ЮНЕСКО по НИТ
Блокирующие функции
Блокирующие функции подразумевают полное окончание операции после
кафедра ЮНЕСКО по НИТ
Блокирующие функции
Блокирующие функции подразумевают полное окончание операции после

кафедра ЮНЕСКО по НИТ
Неблокирующие функции
Неблокирующие функции подразумевают совмещение операций обмена с
кафедра ЮНЕСКО по НИТ
Неблокирующие функции
Неблокирующие функции подразумевают совмещение операций обмена с
кафедра ЮНЕСКО по НИТ
Коммуникационные операции типа «точка-точка»
Из таблицы хорошо виден принцип
кафедра ЮНЕСКО по НИТ
Коммуникационные операции типа «точка-точка»
Из таблицы хорошо виден принцип

кафедра ЮНЕСКО по НИТ
Коммуникационные операции типа «точка-точка»
кафедра ЮНЕСКО по НИТ
Коммуникационные операции типа «точка-точка»
кафедра ЮНЕСКО по НИТ
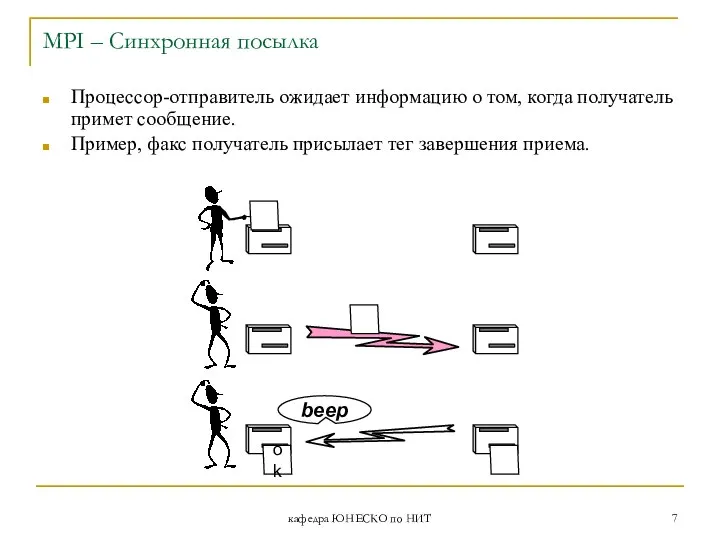
MPI – Синхронная посылка
Процессор-отправитель ожидает информацию о том,
кафедра ЮНЕСКО по НИТ
MPI – Синхронная посылка
Процессор-отправитель ожидает информацию о том,
кафедра ЮНЕСКО по НИТ
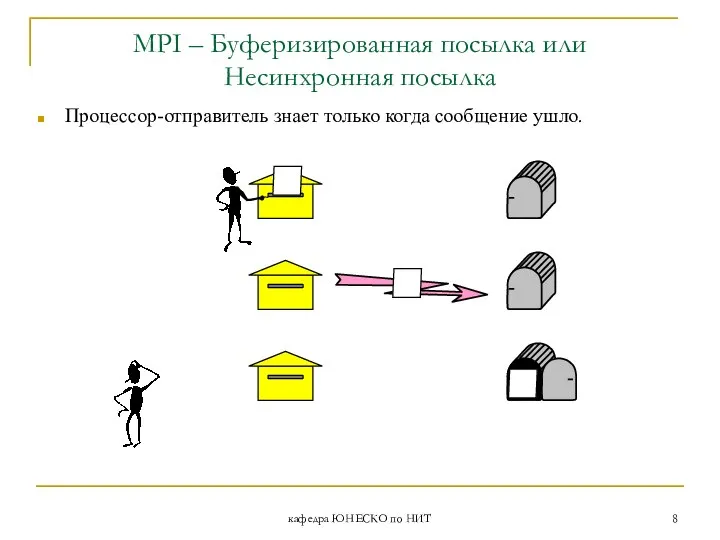
MPI – Буферизированная посылка или
Несинхронная посылка
Процессор-отправитель знает
кафедра ЮНЕСКО по НИТ
MPI – Буферизированная посылка или
Несинхронная посылка
Процессор-отправитель знает
кафедра ЮНЕСКО по НИТ
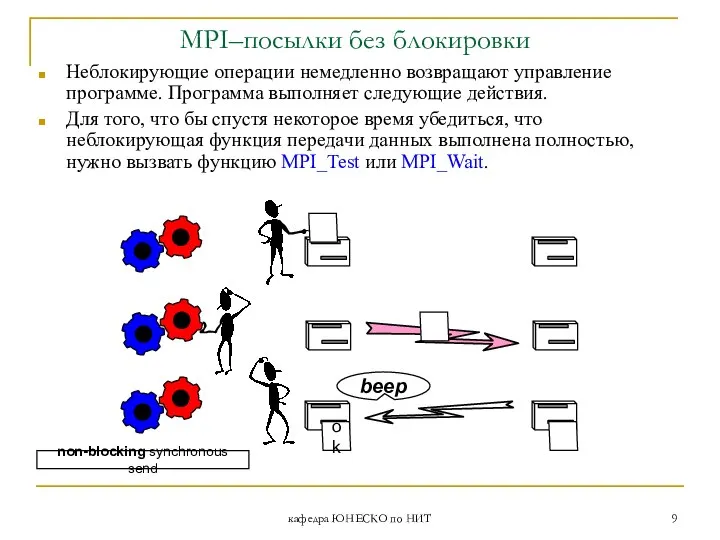
MPI–посылки без блокировки
Неблокирующие операции немедленно возвращают управление программе.
кафедра ЮНЕСКО по НИТ
MPI–посылки без блокировки
Неблокирующие операции немедленно возвращают управление программе.

кафедра ЮНЕСКО по НИТ
Неблокирующие коммуникационные операции
Использование неблокирующих коммуникационных операций более безопасно
кафедра ЮНЕСКО по НИТ
Неблокирующие коммуникационные операции
Использование неблокирующих коммуникационных операций более безопасно

кафедра ЮНЕСКО по НИТ
Неблокирующие коммуникационные операции
Неблокирующие операции используют специальный скрытый (opaque)
кафедра ЮНЕСКО по НИТ
Неблокирующие коммуникационные операции
Неблокирующие операции используют специальный скрытый (opaque)
кафедра ЮНЕСКО по НИТ
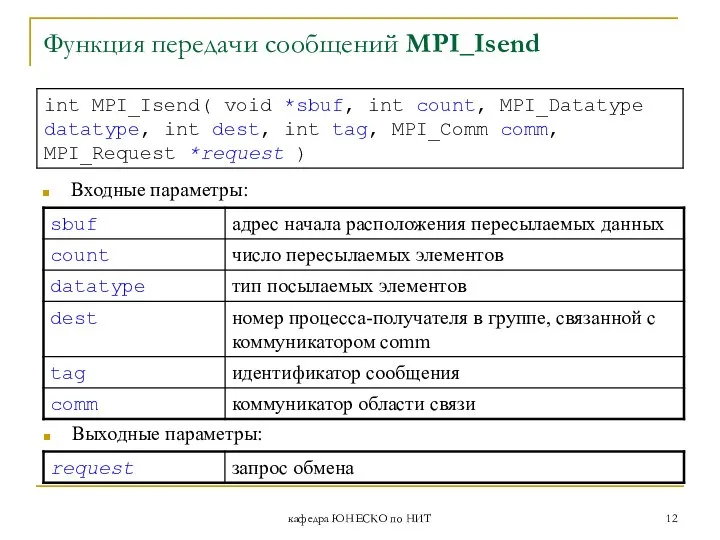
Функция передачи сообщений MPI_Isend
Входные параметры:
Выходные параметры:
кафедра ЮНЕСКО по НИТ
Функция передачи сообщений MPI_Isend
Входные параметры:
Выходные параметры:
кафедра ЮНЕСКО по НИТ
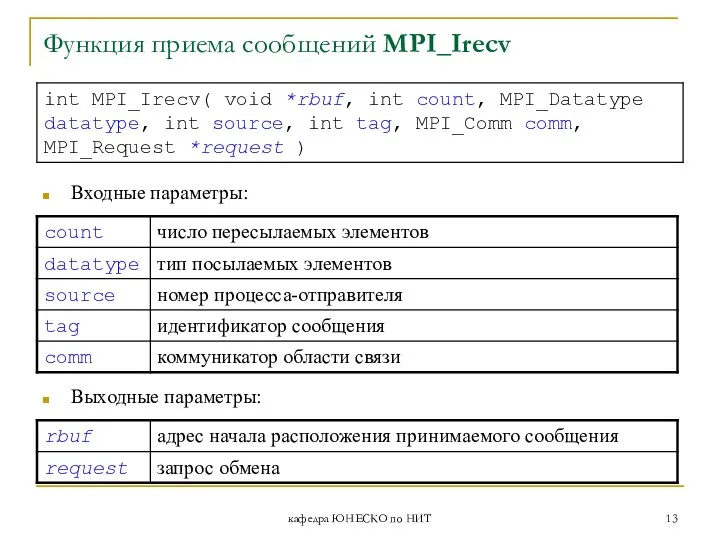
Функция приема сообщений MPI_Irecv
Входные параметры:
Выходные параметры:
кафедра ЮНЕСКО по НИТ
Функция приема сообщений MPI_Irecv
Входные параметры:
Выходные параметры:
кафедра ЮНЕСКО по НИТ
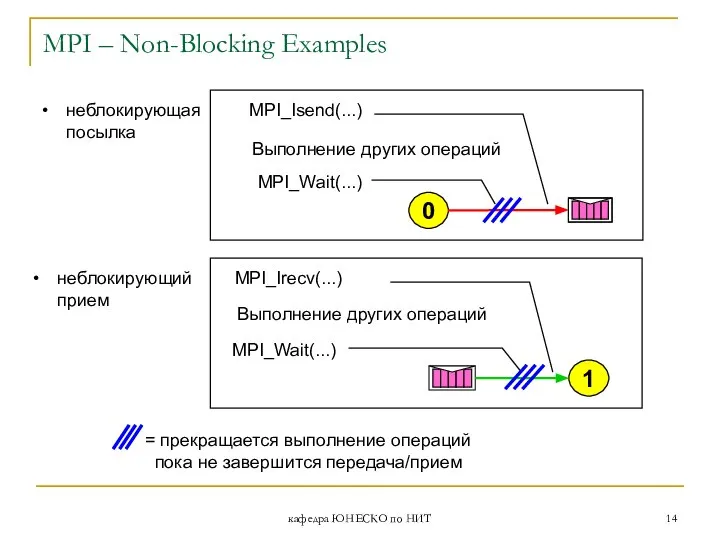
MPI – Non-Blocking Examples
Выполнение других операций
Выполнение других операций
кафедра ЮНЕСКО по НИТ
MPI – Non-Blocking Examples
Выполнение других операций
Выполнение других операций
кафедра ЮНЕСКО по НИТ
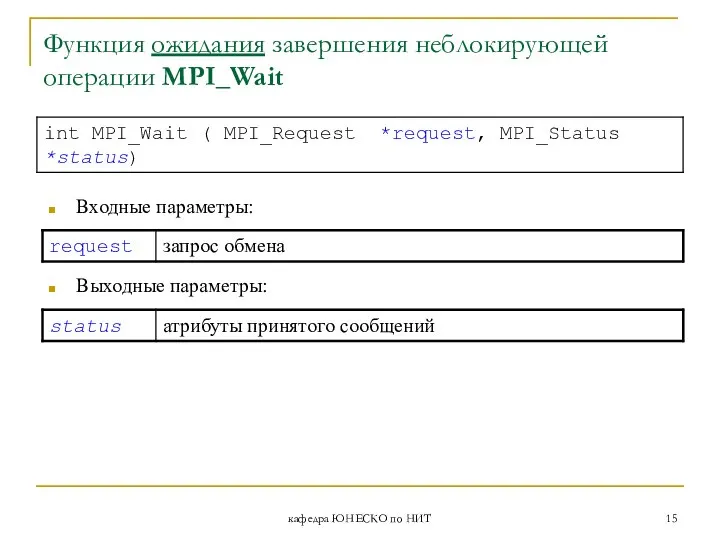
Функция ожидания завершения неблокирующей операции MPI_Wait
Входные параметры:
Выходные параметры:
кафедра ЮНЕСКО по НИТ
Функция ожидания завершения неблокирующей операции MPI_Wait
Входные параметры:
Выходные параметры:

кафедра ЮНЕСКО по НИТ
Функция проверки завершения неблокирующей операции MPI_Test
Входные параметры:
Выходные параметры:
кафедра ЮНЕСКО по НИТ
Функция проверки завершения неблокирующей операции MPI_Test
Входные параметры:
Выходные параметры:

MPI_Sendrecv – совмещение отправки и получения
кафедра ЮНЕСКО по НИТ
Выходные параметры:
При использовании
MPI_Sendrecv – совмещение отправки и получения
кафедра ЮНЕСКО по НИТ
Выходные параметры:
При использовании

Нулевой процесс выполняет продолжительный цикл и после его выполнения посылает первому
Нулевой процесс выполняет продолжительный цикл и после его выполнения посылает первому
кафедра ЮНЕСКО по НИТ
Задание2 — Пересылка данных по кольцу
Init
0
1
2
Каждый процессор помещает
кафедра ЮНЕСКО по НИТ
Задание2 — Пересылка данных по кольцу
Init
0
1
2
Каждый процессор помещает
 Презентация "Документы и делопроизводство" - скачать презентации по Информатике
Презентация "Документы и делопроизводство" - скачать презентации по Информатике Внешняя память
Внешняя память Библиографический поиск. Источники библиографического поиска
Библиографический поиск. Источники библиографического поиска Презентация "КОМПЬЮТЕРНЫЕ МОДЕЛИ" - скачать презентации по Информатике
Презентация "КОМПЬЮТЕРНЫЕ МОДЕЛИ" - скачать презентации по Информатике Минимальные требования компьютера для ОС Windows. Архитектура ОС Windows
Минимальные требования компьютера для ОС Windows. Архитектура ОС Windows Рекомендации по проведению ГИА по информатике и ИКТ Горбунова Татьяна Михайловна, методист ГОУ РК «ИПКРО»
Рекомендации по проведению ГИА по информатике и ИКТ Горбунова Татьяна Михайловна, методист ГОУ РК «ИПКРО»  Panda Cloud Antivirus
Panda Cloud Antivirus  Адресация. Режимы работы процессора. Управление памятью
Адресация. Режимы работы процессора. Управление памятью Компьютерные модели различных процессов
Компьютерные модели различных процессов Оператор Exists. Операторы сравнения с множеством значений. (Лекция 8)
Оператор Exists. Операторы сравнения с множеством значений. (Лекция 8) Процессный подход и современные системы управления организацией
Процессный подход и современные системы управления организацией Болашақтағы ГАЖ бағдарламасы
Болашақтағы ГАЖ бағдарламасы Основы построения ПК
Основы построения ПК Разработка проекта локальной сети для предприятий и организаций малого и среднего бизнеса
Разработка проекта локальной сети для предприятий и организаций малого и среднего бизнеса Влияние компьютера на организм человека
Влияние компьютера на организм человека Борьба с фейками 2.0
Борьба с фейками 2.0 Сетевые технологии
Сетевые технологии Функции вывода puts( ) и cputs()
Функции вывода puts( ) и cputs() Рекламный Wi-Fi New age-sky
Рекламный Wi-Fi New age-sky Ресурсы и управление ими в операционных системах. Тема 5
Ресурсы и управление ими в операционных системах. Тема 5 Администрирование баз данных
Администрирование баз данных Правила техники безопасности в компьютерном классе
Правила техники безопасности в компьютерном классе Комплексный подход к построению систем защиты информации на критически важных объектах инфраструктуры
Комплексный подход к построению систем защиты информации на критически важных объектах инфраструктуры Урок № 6 Создание презентаций в Microsoft Power Point
Урок № 6 Создание презентаций в Microsoft Power Point Как создавать посты?
Как создавать посты? Интернет. Электронная почта
Интернет. Электронная почта Restoration shaman in world of warcraft
Restoration shaman in world of warcraft Ввод информации в память компьютера. Урок 3
Ввод информации в память компьютера. Урок 3