- Линейные списки. Структура данных очередь

Содержание
- 2. Простой пример – очередь в кассу, если очереди нет, обслуживаешься сразу, иначе, становишься в ее конец.
- 3. Односвязный список (очередь) Шаблон структуры, информационная часть (ИЧ) которого – целое число: struct Spis1 { //
- 4. При создании очереди организуется структура следующего вида: Каждый элемент очереди имеет информацион-ную infо (ИЧ1, …, ИЧn)
- 5. Основные операции с очередью: – формирование очереди; – добавление нового элемента в конец очереди; – удаление
- 6. Формирование очереди состоит из двух этапов: создание первого элемента, добавление нового элемента в конец. Создание первого
- 7. 3. Формирование информационной части: t -> info = i; (обозначим i1 ) 4. В адресную часть
- 8. Добавление элемента в очередь Рассмотрим добавление только для второго элемента. 1. Ввод информации для текущего (второго)
- 9. 5. Элемент добавляется в конец, поэтому в адресную часть бывшего последнего элемента end заносим адрес созданного:
- 10. В результате получим Для добавления в очередь любого количества элементов организуется цикл, включающий пункты 1 –
- 11. Обобщив оба этапа, функция формирования оче-реди может иметь следующий вид (b – начало, e – конец,
- 12. // Иначе добавляем элемент в конец else { (*e) -> next = t; *e = t;
- 13. Эту функцию можно реализовать иначе: Spis1* Create (Spis1 **b, Spis1 *e, int in) { Spis1 *t
- 14. В функцию передаются: адрес указателя на начало списка, чтобы при его изменении обеспечить возврат в точку
- 15. Удаление первого элемента из очереди аналогично извлечению элемента из Стека… Пусть очередь создана (begin не равен
- 16. 4. Освобождаем память, занятую бывшим пер-вым: delete t; Алгоритмы просмотра и освобождения памя-ти аналогичны рассмотренным ранее
- 17. Очередь может быть организована и в виде двухсвязного (двунаправленного) списка, в каждом элементе которого два указателя:
- 18. Графически такой список выглядит следующим образом: Адреса begin -> prev (предыдущий у первого) и end ->
- 19. Формирование двунаправленного списка проводится в два этапа – формирование первого элемента и добавление нового, причем доба-вление
- 20. Создание первого элемента 1. Захват памяти: t = new Spis2; формируется конкретный адрес в ОП. 2.
- 21. Получили первый элемент списка:
- 22. Добавление элемента Захват памяти и формирование ИЧ аналогичны рассмотренным пунктам 1 – 2. Добавление в начало
- 23. Схема добавления элемента в начало
- 24. Добавление в конец списка 3.2. Формирование адресных частей: а) следующего нет: t -> next = NULL;
- 25. Схема добавления элемента в конец
- 26. Алгоритм просмотра списка
- 27. Алгоритм поиска по ключу Ключом может быть любое поле структуры, обычно это значение должно быть уникаль-ным
- 28. 4. Начало цикла (выполняем пока t != NULL). 5. Сравниваем ИЧ текущего элемента t с i_key.
- 29. Алгоритм удаления ОДНОГО элемента по ключу Удалить из списка элемент, ИЧ (ключ) которого совпадает с введенным
- 30. Удаление 1. Если удаляемый элемент находится в начале списка, т.е. key = begin, то первым элементом
- 31. Схема удаления элемента key из начала списка:
- 32. 2. Иначе, если удаляемый элемент в конце списка (key = end), то последним элементом в списке
- 33. Схема удаления элемента key из конца списка:
- 34. 3. Иначе, если элемент key находится в середине списка, нужно обеспечить связь предыдущего key -> prev
- 35. Схема удаления key из середины списка:
- 36. Алгоритм вставки элемента после элемента с указанным ключом Вставить в список элемент после элемента, значение ИЧ
- 37. Этап второй – вставка Найден адрес элемента key, после которого вставляем новый. 1. Захватываем память под
- 38. 5. Связываем предыдущий элемент с новым key -> next = t; 6. Если элемент добавляется не
- 39. Общая схема вставки элемента:
- 41. Скачать презентацию

Простой пример – очередь в кассу, если очереди нет, обслуживаешься сразу,
Простой пример – очередь в кассу, если очереди нет, обслуживаешься сразу,

Односвязный список (очередь)
Шаблон структуры, информационная часть (ИЧ) которого – целое число:
struct
Односвязный список (очередь)
Шаблон структуры, информационная часть (ИЧ) которого – целое число:
struct

При создании очереди организуется структура следующего вида:
Каждый элемент очереди имеет информацион-ную
При создании очереди организуется структура следующего вида:
Каждый элемент очереди имеет информацион-ную

Основные операции с очередью:
– формирование очереди;
– добавление нового элемента в конец
Основные операции с очередью:
– формирование очереди;
– добавление нового элемента в конец

Формирование очереди состоит из двух этапов: создание первого элемента, добавление нового
Формирование очереди состоит из двух этапов: создание первого элемента, добавление нового

3. Формирование информационной части:
t -> info = i; (обозначим i1 )
4. В
3. Формирование информационной части:
t -> info = i; (обозначим i1 )
4. В

Добавление элемента в очередь
Рассмотрим добавление только для второго элемента.
1. Ввод информации
Добавление элемента в очередь
Рассмотрим добавление только для второго элемента.
1. Ввод информации

5. Элемент добавляется в конец, поэтому в адресную часть бывшего последнего
5. Элемент добавляется в конец, поэтому в адресную часть бывшего последнего

В результате получим
Для добавления в очередь любого количества элементов организуется цикл,
В результате получим
Для добавления в очередь любого количества элементов организуется цикл,

Обобщив оба этапа, функция формирования оче-реди может иметь следующий вид (b
Обобщив оба этапа, функция формирования оче-реди может иметь следующий вид (b

// Иначе добавляем элемент в конец
else { (*e) -> next = t;
*e
// Иначе добавляем элемент в конец
else { (*e) -> next = t;
*e

Эту функцию можно реализовать иначе:
Spis1* Create (Spis1 **b, Spis1 *e, int
Эту функцию можно реализовать иначе:
Spis1* Create (Spis1 **b, Spis1 *e, int

В функцию передаются:
адрес указателя на начало списка, чтобы при его изменении
В функцию передаются:
адрес указателя на начало списка, чтобы при его изменении

Удаление первого элемента из очереди аналогично извлечению элемента из Стека…
Пусть
Удаление первого элемента из очереди аналогично извлечению элемента из Стека…
Пусть

4. Освобождаем память, занятую бывшим пер-вым:
delete t;
Алгоритмы просмотра и освобождения
4. Освобождаем память, занятую бывшим пер-вым:
delete t;
Алгоритмы просмотра и освобождения

Очередь может быть организована и в виде двухсвязного (двунаправленного) списка, в
Очередь может быть организована и в виде двухсвязного (двунаправленного) списка, в
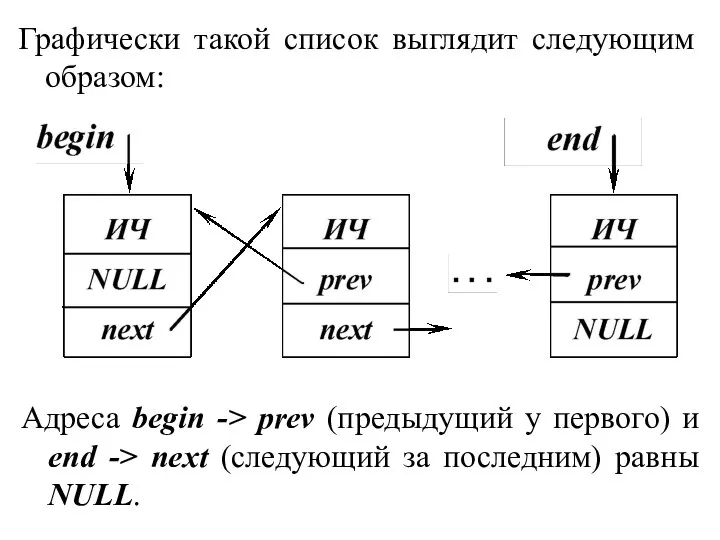
Графически такой список выглядит следующим образом:
Адреса begin -> prev (предыдущий
Графически такой список выглядит следующим образом:
Адреса begin -> prev (предыдущий

Формирование двунаправленного списка
проводится в два этапа – формирование первого элемента
Формирование двунаправленного списка
проводится в два этапа – формирование первого элемента

Создание первого элемента
1. Захват памяти: t = new Spis2;
формируется конкретный адрес
Создание первого элемента
1. Захват памяти: t = new Spis2;
формируется конкретный адрес
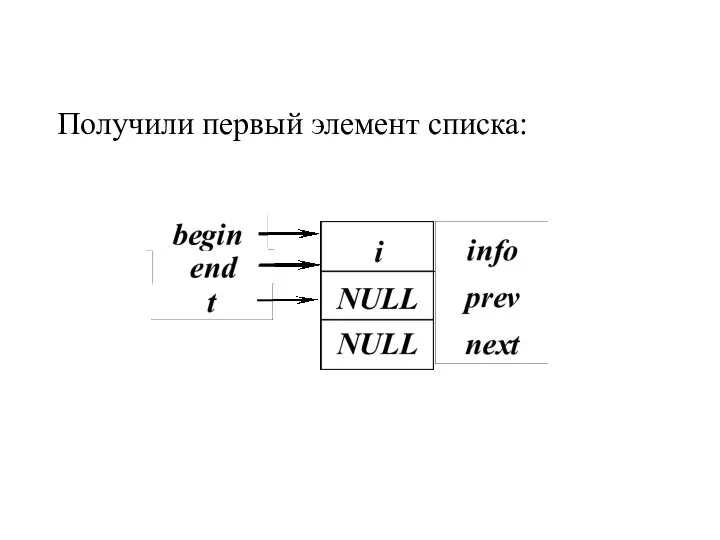
Получили первый элемент списка:
Получили первый элемент списка:

Добавление элемента
Захват памяти и формирование ИЧ аналогичны рассмотренным пунктам 1 –
Добавление элемента
Захват памяти и формирование ИЧ аналогичны рассмотренным пунктам 1 –
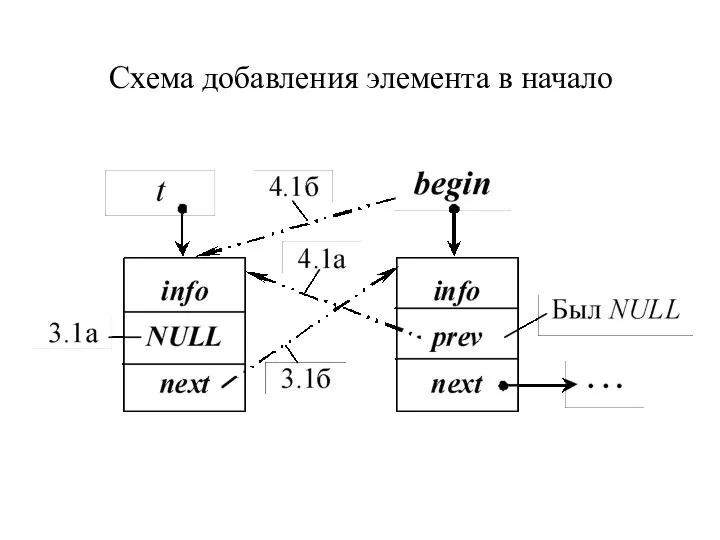
Схема добавления элемента в начало
Схема добавления элемента в начало

Добавление в конец списка
3.2. Формирование адресных частей:
а) следующего нет: t
Добавление в конец списка
3.2. Формирование адресных частей:
а) следующего нет: t
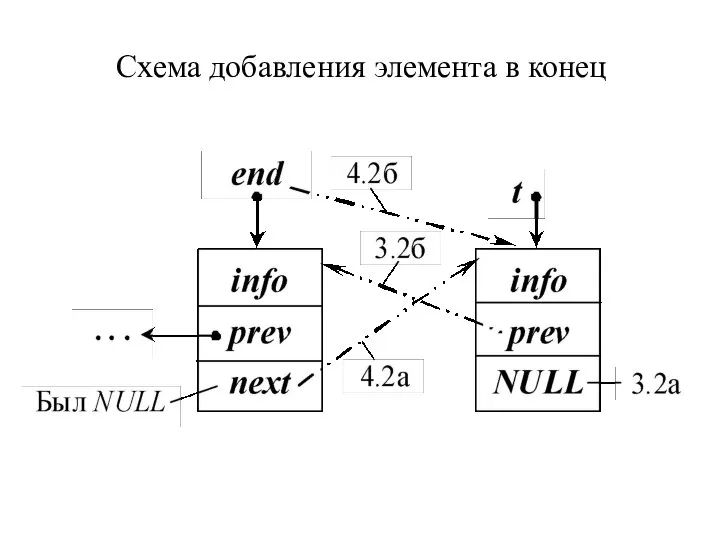
Схема добавления элемента в конец
Схема добавления элемента в конец

Алгоритм просмотра списка
Алгоритм просмотра списка

Алгоритм поиска по ключу
Ключом может быть любое поле структуры, обычно это
Алгоритм поиска по ключу
Ключом может быть любое поле структуры, обычно это

4. Начало цикла (выполняем пока t != NULL).
5. Сравниваем ИЧ текущего
4. Начало цикла (выполняем пока t != NULL).
5. Сравниваем ИЧ текущего

Алгоритм удаления ОДНОГО элемента по ключу
Удалить из списка элемент, ИЧ (ключ)
Алгоритм удаления ОДНОГО элемента по ключу
Удалить из списка элемент, ИЧ (ключ)

Удаление
1. Если удаляемый элемент находится в начале списка, т.е. key
Удаление
1. Если удаляемый элемент находится в начале списка, т.е. key
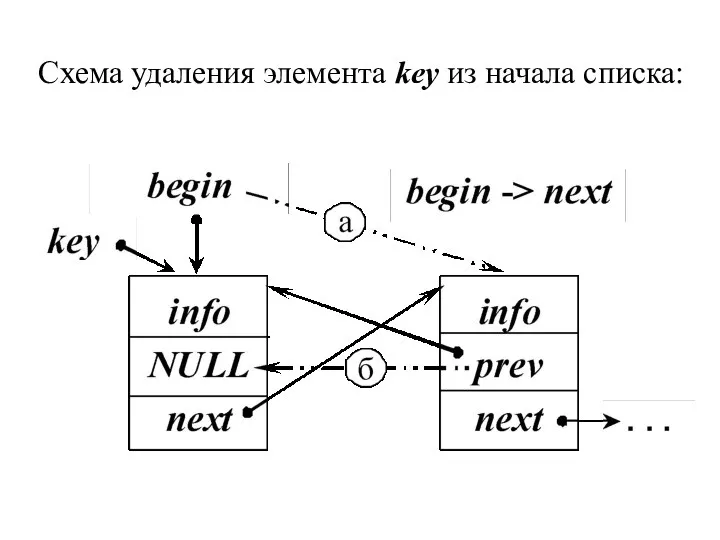
Схема удаления элемента key из начала списка:
Схема удаления элемента key из начала списка:

2. Иначе, если удаляемый элемент в конце списка (key = end),
2. Иначе, если удаляемый элемент в конце списка (key = end),
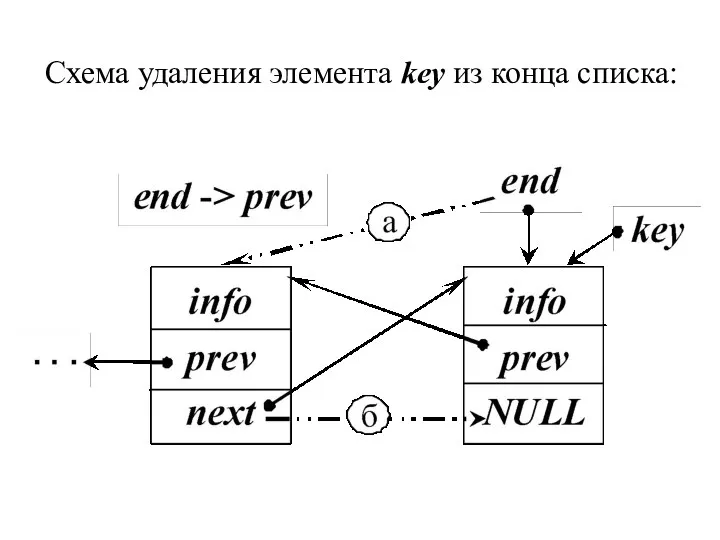
Схема удаления элемента key из конца списка:
Схема удаления элемента key из конца списка:

3. Иначе, если элемент key находится в середине списка, нужно обеспечить
3. Иначе, если элемент key находится в середине списка, нужно обеспечить
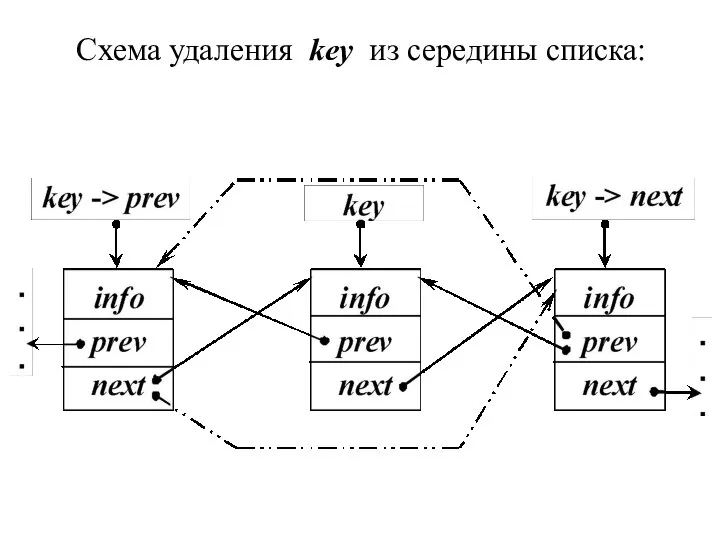
Схема удаления key из середины списка:
Схема удаления key из середины списка:

Алгоритм вставки элемента после элемента с указанным ключом
Вставить в список элемент
Алгоритм вставки элемента после элемента с указанным ключом
Вставить в список элемент

Этап второй – вставка
Найден адрес элемента key, после которого вставляем новый.
1.
Этап второй – вставка
Найден адрес элемента key, после которого вставляем новый.
1.

5. Связываем предыдущий элемент с новым
key -> next = t;
6. Если
5. Связываем предыдущий элемент с новым
key -> next = t;
6. Если
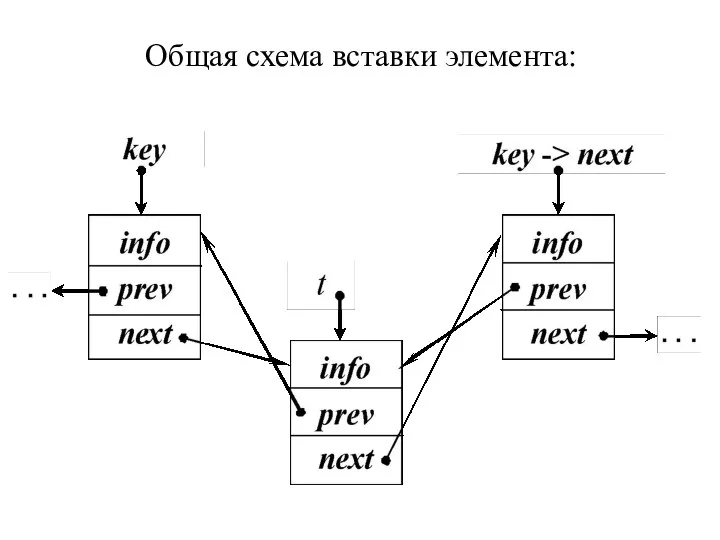
Общая схема вставки элемента:
Общая схема вставки элемента:
 Теория и практика информации и коммуникации. Журналистская деятельность
Теория и практика информации и коммуникации. Журналистская деятельность Цикл For
Цикл For Формы записи алгоритмов
Формы записи алгоритмов Файлы и файловая система
Файлы и файловая система Translation Practice
Translation Practice Архитектура ЭВМ
Архитектура ЭВМ  ТЕМА: Конструирование — разновидность моделирования
ТЕМА: Конструирование — разновидность моделирования Что делать с подписчиками. Идеи для зажигательных конкурсов
Что делать с подписчиками. Идеи для зажигательных конкурсов Решение расчетных задач с помощью электронных таблиц Microsoft Excel
Решение расчетных задач с помощью электронных таблиц Microsoft Excel Ур. 25
Ур. 25 Настройка службы DNS
Настройка службы DNS Формализованное описание и стилевое оформление телевизионного интернет-канала
Формализованное описание и стилевое оформление телевизионного интернет-канала Операции и выражения Операции и выражения Арифметические операции Для каждого типа данных определены действия, примен
Операции и выражения Операции и выражения Арифметические операции Для каждого типа данных определены действия, примен Теза́урус Безопасный интернет
Теза́урус Безопасный интернет 1C:Предприятие 8. Автосервис. Презентация отраслевого решения
1C:Предприятие 8. Автосервис. Презентация отраслевого решения ПРОЕКТ ПО ВНЕКЛАССНОЙ РАБОТЕ Какой вред наносят человеку сотовые телефоны и компьютеры?
ПРОЕКТ ПО ВНЕКЛАССНОЙ РАБОТЕ Какой вред наносят человеку сотовые телефоны и компьютеры? Презентация Природа и общество в Философии
Презентация Природа и общество в Философии Система управления базами данных. (Тема 1.3)
Система управления базами данных. (Тема 1.3) Использование интерактивных форм на веб - страницах
Использование интерактивных форм на веб - страницах МОНИТОРЫ
МОНИТОРЫ Жизненный цикл ПО и его этапы
Жизненный цикл ПО и его этапы Программная инженерия. Часть 1
Программная инженерия. Часть 1 Работа на цель. Проведение конкурсов в сети, обеспечивающих достижение конкретных целей
Работа на цель. Проведение конкурсов в сети, обеспечивающих достижение конкретных целей CSS-селекторы
CSS-селекторы Язык С++
Язык С++ Презентация Текстовая и графическая информация
Презентация Текстовая и графическая информация  Массив в программировании
Массив в программировании Процедуры. Назначение процедур
Процедуры. Назначение процедур