- Параллельное программирование Минакова Е.О. Студентка 6 курса ОНУ им.И.И.Мечникова

Содержание
- 2. Что же такое параллельное программирование Представьте себе такую картину: несколько автомобилей едут из пункта А в
- 3. Что же нужно, чтобы достичь параллелизма? Достижение параллелизма возможно только при выполнимости следующих требований к архитектурным
- 4. Примеры топологий многопроцессорных вычислительных систем полный граф (completely-connected graph or clique)- система, в которой между любой
- 5. Примеры топологий многопроцессорных вычислительных систем кольцо (ring) - данная топология получается из линейки процессоров соединением первого
- 6. Примеры топологий многопроцессорных вычислительных систем решетка (mesh) - система, в которой граф линий связи образует прямоугольную
- 7. КЛАССЫ ЗАДАЧ, КОТОРЫЕ МОЖНО ЭФФЕКТИВНО РАСПАРАЛЛЕЛИТЬ Одномерные массивы Двумерные массивы Клеточные автоматы Системы дифференциальных уравнений
- 8. Последовательный алгоритм суммирования Традиционный алгоритм для решения этой задачи состоит в последовательном суммировании элементов числового набора
- 9. Что все это значит Модифицированная каскадная схема Получение асимптотически ненулевой эффективности может быть обеспечено, например, при
- 10. МАТРИЧНОЕ УМНОЖЕНИЕ Вычислительная схема матричного умножения при использовании макроопераций умножения матрицы A на столбец матрицы B
- 11. МАТРИЧНОЕ УМНОЖЕНИЕ Состояние блоков на каждом процессоре в ходе выполнения итераций этапа вычислений
- 13. Скачать презентацию

Что же такое параллельное программирование
Представьте себе такую картину: несколько
Что же такое параллельное программирование
Представьте себе такую картину: несколько

Что же нужно, чтобы достичь параллелизма?
Достижение параллелизма возможно только при выполнимости
Что же нужно, чтобы достичь параллелизма?
Достижение параллелизма возможно только при выполнимости

Примеры топологий многопроцессорных
вычислительных систем
полный граф (completely-connected graph or clique)-
Примеры топологий многопроцессорных
вычислительных систем
полный граф (completely-connected graph or clique)-

Примеры топологий многопроцессорных
вычислительных систем
кольцо (ring) - данная топология получается из
Примеры топологий многопроцессорных
вычислительных систем
кольцо (ring) - данная топология получается из

Примеры топологий многопроцессорных
вычислительных систем
решетка (mesh) - система, в которой граф
Примеры топологий многопроцессорных
вычислительных систем
решетка (mesh) - система, в которой граф

КЛАССЫ ЗАДАЧ, КОТОРЫЕ МОЖНО ЭФФЕКТИВНО РАСПАРАЛЛЕЛИТЬ
Одномерные массивы
Двумерные массивы
Клеточные автоматы
Системы дифференциальных уравнений
КЛАССЫ ЗАДАЧ, КОТОРЫЕ МОЖНО ЭФФЕКТИВНО РАСПАРАЛЛЕЛИТЬ
Одномерные массивы
Двумерные массивы
Клеточные автоматы
Системы дифференциальных уравнений

Последовательный алгоритм суммирования
Традиционный алгоритм для решения этой задачи состоит в
последовательном суммировании
Последовательный алгоритм суммирования
Традиционный алгоритм для решения этой задачи состоит в
последовательном суммировании

Что все это значит
Модифицированная каскадная схема
Получение асимптотически ненулевой эффективности может быть
Что все это значит
Модифицированная каскадная схема
Получение асимптотически ненулевой эффективности может быть
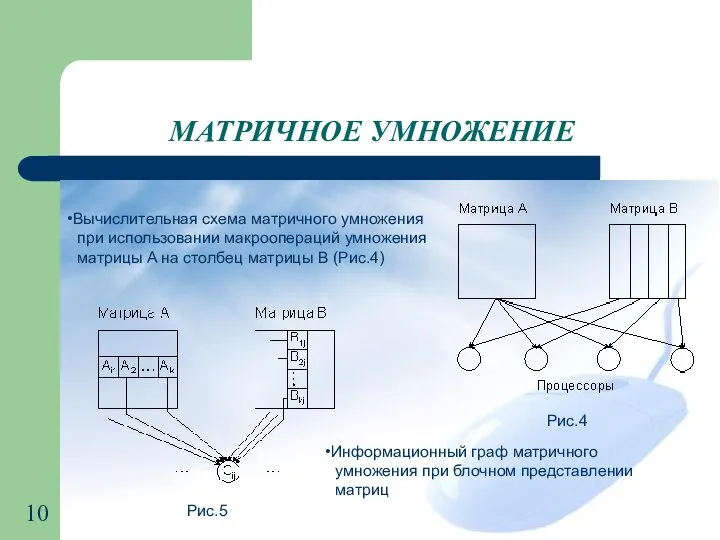
МАТРИЧНОЕ УМНОЖЕНИЕ
Вычислительная схема матричного умножения
при использовании макроопераций умножения
матрицы
МАТРИЧНОЕ УМНОЖЕНИЕ
Вычислительная схема матричного умножения
при использовании макроопераций умножения
матрицы

МАТРИЧНОЕ УМНОЖЕНИЕ
Состояние блоков на каждом процессоре в ходе выполнения итераций этапа
МАТРИЧНОЕ УМНОЖЕНИЕ Состояние блоков на каждом процессоре в ходе выполнения итераций этапа
 Годовой отчет по сайту www.space-team.com
Годовой отчет по сайту www.space-team.com КИС как составляющая современной инфраструктуры организации
КИС как составляющая современной инфраструктуры организации Муниципальное общеобразовательное учреждение «Гимназия №1 г. Рузы» Обзор интерактивных досок
Муниципальное общеобразовательное учреждение «Гимназия №1 г. Рузы» Обзор интерактивных досок Реляционные базы данных. Целостность данных. (Лекция 3)
Реляционные базы данных. Целостность данных. (Лекция 3) Связь. Система связи
Связь. Система связи Веб-сервисы на страже безопасности
Веб-сервисы на страже безопасности Коаксиальный кабель
Коаксиальный кабель Среда программирования Free Pascal
Среда программирования Free Pascal Эволюция минимализма
Эволюция минимализма Программирование на языке высокого уровня Ю-1
Программирование на языке высокого уровня Ю-1 Типы данных в программировании
Типы данных в программировании Поиск и представление информации
Поиск и представление информации Создание интерактивных тестов в программе MyTestX
Создание интерактивных тестов в программе MyTestX Переписывание. Задачи на листке
Переписывание. Задачи на листке Онлайн или не онлайн – вот в чем вопрос
Онлайн или не онлайн – вот в чем вопрос Цифровая fashion иллюстрация. Техника рисования по фотографии
Цифровая fashion иллюстрация. Техника рисования по фотографии Создание объектов в 3D max
Создание объектов в 3D max Требования к разработке приложения на платформе 1С: Предприятие 8.3
Требования к разработке приложения на платформе 1С: Предприятие 8.3 Обучающий курс Front-end
Обучающий курс Front-end Разработка приложений БД
Разработка приложений БД Кодирование информации в компьютерных сетях. Виды кодов
Кодирование информации в компьютерных сетях. Виды кодов Instagram в помощь формированию положительного имиджа библиотеки
Instagram в помощь формированию положительного имиджа библиотеки Система контроля и управления доступом
Система контроля и управления доступом Мультимедийные технологии - презентации по Информатике
Мультимедийные технологии - презентации по Информатике Стандарт TMN
Стандарт TMN Моя любимая семья. Онлайн-игра
Моя любимая семья. Онлайн-игра Блогосфера. Виды блогов. Имидж блоггера
Блогосфера. Виды блогов. Имидж блоггера Презентация "Беспроводные сети" - скачать презентации по Информатике
Презентация "Беспроводные сети" - скачать презентации по Информатике