- Поисковая система и машинное обучение

Содержание
- 2. Цели и вопросы Мои цели Переход из мира магии в мир науки Станет понятней как работает
- 3. Чего не будет Я не могу за 2 часа сделать вас Data Science спецами Четких рецептов
- 4. Как устроен поиск?
- 8. Ранжирование Ранжирование - процесс упорядочивания документов в соответствии со степенью их соответствия поисковому запросу.
- 9. Ранжирующие признаки Запросо-независимые или статические признаки — зависящие только от документа, но не от запроса. Например,
- 10. Как происходит поиск Запрос токенизируется, к словам запроса применяется морфологический анализ, ищутся синонимы Из документов индекса
- 11. Общая функция релевантности Функция релевантности документа d относительно запроса q fr(q,d)=a1h1(q,d)+a2h2(q,d)+...+anhn(q,d) количество функций hk(q,d) достаточно большое,
- 12. Качество поиска Ассесоры нужны не для ручного управления, а для оценки качества алгоритма Определяют фичи Постоянное
- 13. Выводы Среднее по топу не всегда покажет порог релевантности Никто не знает какие факторы как влияю
- 14. Ссылочный антиспам Вероятность что текст анкора коммерческий Вероятность что сайт продает ссылки Вероятность что сайт покупает
- 15. Текстовый антиспам ПФ на странице с текстом Вероятность встретить слово в тексте Тематический вектор текста документа
- 16. Поведенческие факторы и антиспам Поведение в топе Поведение на странице и хосте Ласт-клик.
- 17. Тематические фичи Количество и частота новыйх объявлений - для класифайдов Наличие интентов на странице(купить, скачать и
- 18. Про поиск и МО Антиспам построены на МО У яндекса алгоритм ранжированя работает на МО Все
- 19. Типы задач Классификация Кластеризация Регрессия Понижение размерности данных Восстановление плотности распределения вероятности по набору данных Одноклассовая
- 20. Класическая задача: Кредитный скоринг Объект - человек доход, есть квартира, есть жена у которой есть машина
- 21. Алгоритмы. Деревья решений
- 22. Random Forest
- 23. k-means
- 24. Коллаборативная фильтрация
- 25. МО для текстов Катеригоризация Кластеризация Таксономия Классификация
- 26. AlchemyLanguage API http://www.alchemyapi.com/products/demo/alchemylanguage
- 27. Классификация текстов http://docs.aylien.com/docs/addon-introduction
- 28. Пример. Как найти похожие документы Пацаны сказали что LSA - это круто. (на самом деле нет,
- 29. LSA? Как работает: удаление стоп-слов, стемминг или лемматизация слов в документах; исключение слов, встречающихся в единственном
- 30. LSA
- 31. Пример. Как найти похожие документы LSA: На выходе получаем координаты в тематическом пространстве LDA: На выходе
- 32. Как найти схожие документы. Обучение. LDA Пример обучения: http://pastebin.com/PMrCAQpz
- 33. Мера схожести Косинусная мера Коэффициент корреляции Пирсона Евклидово расстояние Коэффициент Танимото Манхэттенское расстояние и т.д.
- 34. Пример работы
- 35. Gensim
- 36. Сложность фраз. Задача и ограничения Ограничения: Нужно посчитать за вменяемое время "сложность" для ~ 100 млн
- 37. Сложность фразы. Параметры. SEO-score = вхождение фразы в разные участки снипета. Вспомагательные параметры: число главных страниц
- 38. Сложность фраз Поиск признаков Разметили обучающую выборку Отдельно обучили SEO-score Нормализовали другие параметры и обучили Проверили
- 39. Сложность фразы
- 40. Полином fr(q,d)=a1h1(q,d)+a2h2(q,d)+...+an
- 41. Нормировка линейная
- 42. Апроксимация
- 43. Виды апроксимации
- 44. Итоговая формула score=af(тиц)+bf(pr)+cf(ВС)+d
- 45. Как найти коэффициенты a,b,c
- 46. Таблица для поиска коэффициентов
- 47. Поиск решения
- 48. Поиск решения
- 49. Конец)
- 50. Усовершенствованный алгоритм Выбираем параметры Нормируем Находим корреляцию с правильными результатами Строим формулу Помним про эффект переобучения
- 51. Реальный пример https://docs.google.com/spreadsheets/d/1KSXignNr7SvNGhUU0W_uWCaxp5Ka3ea1jHRiWQKOFrM/edit#gid=573531330
- 52. Рекомендации kime, rapidminer - комбайны Gensim - библиотека python SciPy - библиотека python Национальный корпус русского
- 54. Скачать презентацию

Цели и вопросы
Мои цели
Переход из мира магии в мир науки
Станет понятней
Цели и вопросы
Мои цели
Переход из мира магии в мир науки
Станет понятней

Чего не будет
Я не могу за 2 часа сделать вас Data
Чего не будет
Я не могу за 2 часа сделать вас Data

Как устроен поиск?
Как устроен поиск?

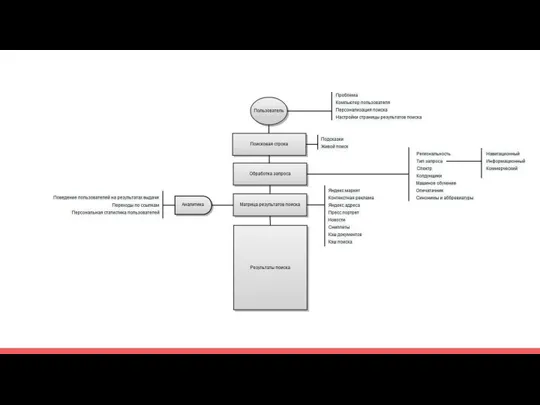

Ранжирование
Ранжирование - процесс упорядочивания документов в соответствии со степенью их
Ранжирование
Ранжирование - процесс упорядочивания документов в соответствии со степенью их

Ранжирующие признаки
Запросо-независимые или статические признаки — зависящие только от документа, но
Ранжирующие признаки
Запросо-независимые или статические признаки — зависящие только от документа, но

Как происходит поиск
Запрос токенизируется, к словам запроса применяется морфологический анализ, ищутся
Как происходит поиск
Запрос токенизируется, к словам запроса применяется морфологический анализ, ищутся

Общая функция релевантности
Функция релевантности документа d относительно запроса q
fr(q,d)=a1h1(q,d)+a2h2(q,d)+...+anhn(q,d)
количество функций hk(q,d)
Общая функция релевантности
Функция релевантности документа d относительно запроса q
fr(q,d)=a1h1(q,d)+a2h2(q,d)+...+anhn(q,d)
количество функций hk(q,d)

Качество поиска
Ассесоры нужны не для ручного управления, а для оценки качества
Качество поиска
Ассесоры нужны не для ручного управления, а для оценки качества

Выводы
Среднее по топу не всегда покажет порог релевантности
Никто не знает
Выводы
Среднее по топу не всегда покажет порог релевантности
Никто не знает

Ссылочный антиспам
Вероятность что текст анкора коммерческий
Вероятность что сайт продает ссылки
Вероятность что
Ссылочный антиспам
Вероятность что текст анкора коммерческий
Вероятность что сайт продает ссылки
Вероятность что

Текстовый антиспам
ПФ на странице с текстом
Вероятность встретить слово в тексте
Тематический вектор
Текстовый антиспам
ПФ на странице с текстом
Вероятность встретить слово в тексте
Тематический вектор

Поведенческие факторы и антиспам
Поведение в топе
Поведение на странице и хосте
Ласт-клик.
Поведенческие факторы и антиспам
Поведение в топе
Поведение на странице и хосте
Ласт-клик.

Тематические фичи
Количество и частота новыйх объявлений - для класифайдов
Наличие интентов на
Тематические фичи
Количество и частота новыйх объявлений - для класифайдов
Наличие интентов на

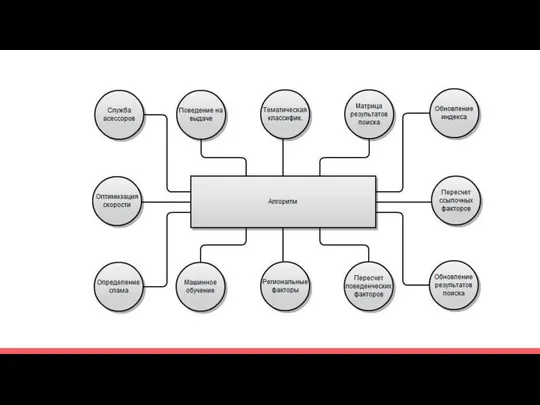
Про поиск и МО
Антиспам построены на МО
У яндекса алгоритм ранжированя работает
Про поиск и МО
Антиспам построены на МО
У яндекса алгоритм ранжированя работает

Типы задач
Классификация
Кластеризация
Регрессия
Понижение размерности данных
Восстановление плотности распределения вероятности по набору данных
Одноклассовая
Типы задач
Классификация Кластеризация Регрессия Понижение размерности данных Восстановление плотности распределения вероятности по набору данных Одноклассовая

Класическая задача: Кредитный скоринг
Объект - человек
доход, есть квартира, есть жена у
Класическая задача: Кредитный скоринг
Объект - человек
доход, есть квартира, есть жена у

Алгоритмы. Деревья решений
Алгоритмы. Деревья решений
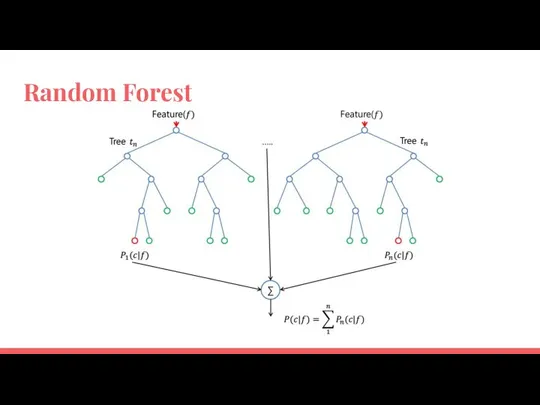
Random Forest
Random Forest
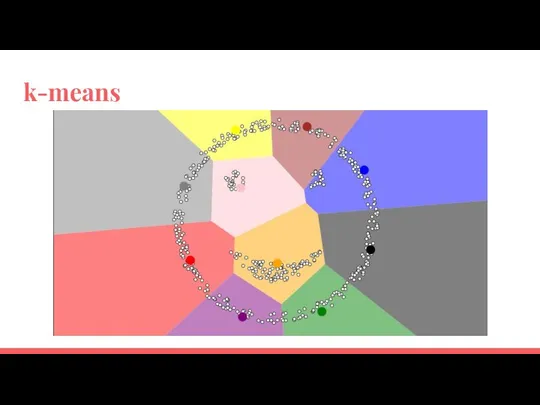
k-means
k-means

Коллаборативная фильтрация
Коллаборативная фильтрация

МО для текстов
Катеригоризация
Кластеризация
Таксономия
Классификация
МО для текстов
Катеригоризация
Кластеризация
Таксономия
Классификация

AlchemyLanguage API
http://www.alchemyapi.com/products/demo/alchemylanguage
AlchemyLanguage API
http://www.alchemyapi.com/products/demo/alchemylanguage
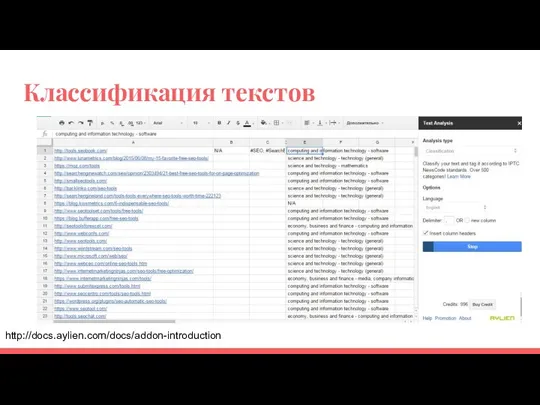
Классификация текстов
http://docs.aylien.com/docs/addon-introduction
Классификация текстов
http://docs.aylien.com/docs/addon-introduction

Пример. Как найти похожие документы
Пацаны сказали что LSA - это круто.
Пример. Как найти похожие документы
Пацаны сказали что LSA - это круто.

LSA?
Как работает:
удаление стоп-слов, стемминг или лемматизация слов в документах;
исключение слов, встречающихся
LSA?
Как работает:
удаление стоп-слов, стемминг или лемматизация слов в документах;
исключение слов, встречающихся
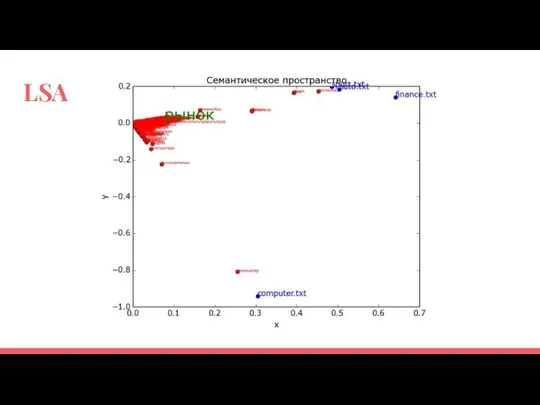
LSA
LSA

Пример. Как найти похожие документы
LSA:
На выходе получаем координаты в тематическом пространстве
LDA:
На
Пример. Как найти похожие документы
LSA:
На выходе получаем координаты в тематическом пространстве
LDA:
На

Как найти схожие документы. Обучение. LDA
Пример обучения:
http://pastebin.com/PMrCAQpz
Как найти схожие документы. Обучение. LDA
Пример обучения:
http://pastebin.com/PMrCAQpz

Мера схожести
Косинусная мера
Коэффициент корреляции Пирсона
Евклидово расстояние
Коэффициент Танимото
Манхэттенское расстояние и т.д.
Мера схожести
Косинусная мера
Коэффициент корреляции Пирсона
Евклидово расстояние
Коэффициент Танимото
Манхэттенское расстояние и т.д.
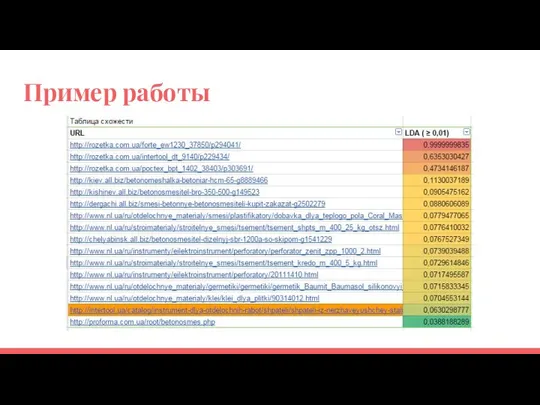
Пример работы
Пример работы
Gensim
Gensim

Сложность фраз. Задача и ограничения
Ограничения:
Нужно посчитать за вменяемое время "сложность" для
Сложность фраз. Задача и ограничения
Ограничения:
Нужно посчитать за вменяемое время "сложность" для

Сложность фразы. Параметры.
SEO-score = вхождение фразы в разные участки снипета.
Сложность фразы. Параметры.
SEO-score = вхождение фразы в разные участки снипета.

Сложность фраз
Поиск признаков
Разметили обучающую выборку
Отдельно обучили SEO-score
Нормализовали другие параметры и
Сложность фраз
Поиск признаков
Разметили обучающую выборку
Отдельно обучили SEO-score
Нормализовали другие параметры и
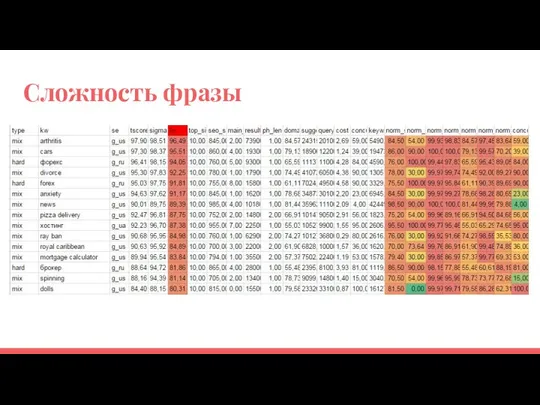
Сложность фразы
Сложность фразы

Полином
fr(q,d)=a1h1(q,d)+a2h2(q,d)+...+an
Полином
fr(q,d)=a1h1(q,d)+a2h2(q,d)+...+an

Нормировка линейная
Нормировка линейная
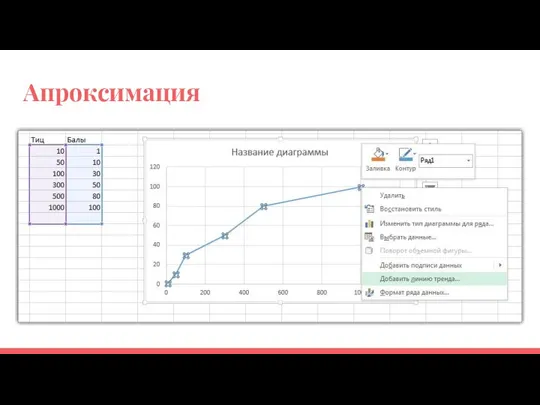
Апроксимация
Апроксимация
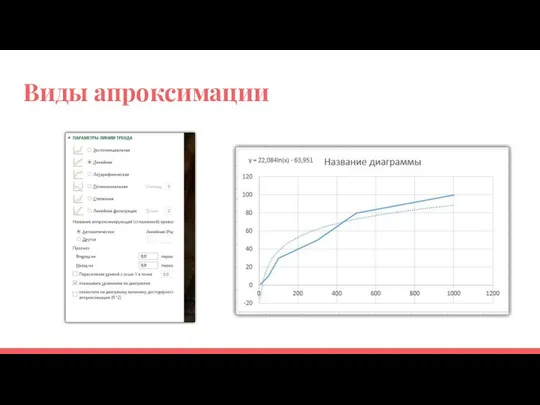
Виды апроксимации
Виды апроксимации

Итоговая формула
score=af(тиц)+bf(pr)+cf(ВС)+d
Итоговая формула
score=af(тиц)+bf(pr)+cf(ВС)+d

Как найти коэффициенты a,b,c
Как найти коэффициенты a,b,c
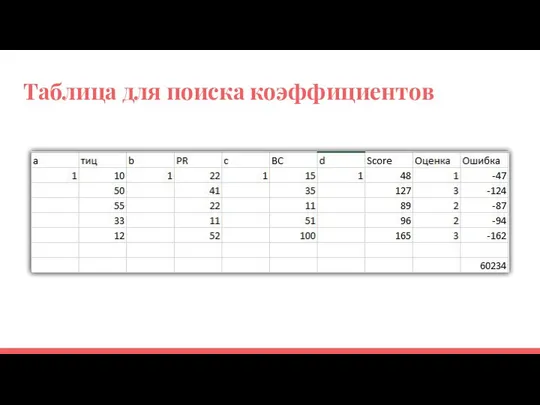
Таблица для поиска коэффициентов
Таблица для поиска коэффициентов
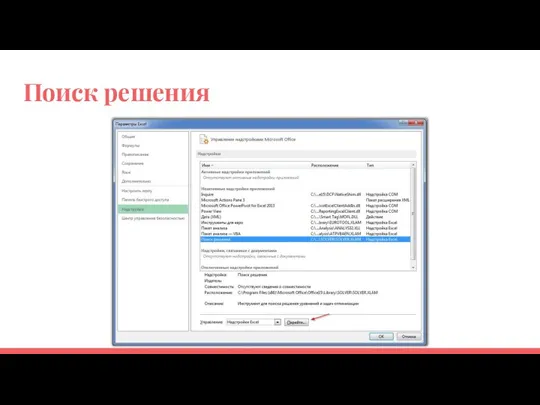
Поиск решения
Поиск решения
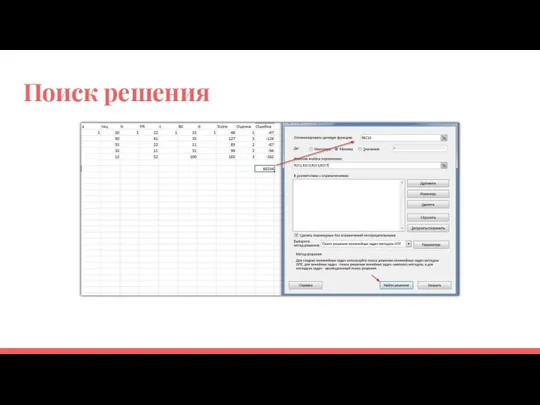
Поиск решения
Поиск решения
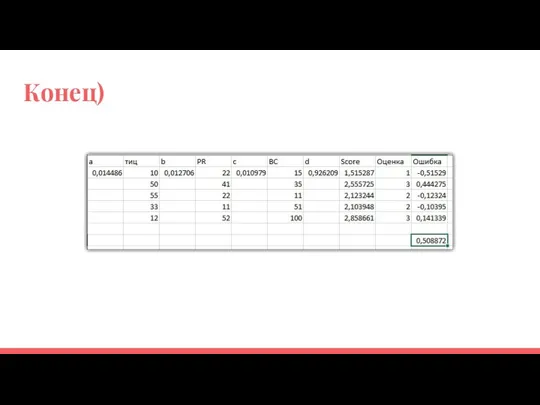
Конец)
Конец)

Усовершенствованный алгоритм
Выбираем параметры
Нормируем
Находим корреляцию с правильными результатами
Строим формулу
Помним про эффект переобучения
Усовершенствованный алгоритм
Выбираем параметры
Нормируем
Находим корреляцию с правильными результатами
Строим формулу
Помним про эффект переобучения

Реальный пример
https://docs.google.com/spreadsheets/d/1KSXignNr7SvNGhUU0W_uWCaxp5Ka3ea1jHRiWQKOFrM/edit#gid=573531330
Реальный пример
https://docs.google.com/spreadsheets/d/1KSXignNr7SvNGhUU0W_uWCaxp5Ka3ea1jHRiWQKOFrM/edit#gid=573531330

Рекомендации
kime, rapidminer - комбайны
Gensim - библиотека python
SciPy - библиотека python
Национальный корпус
Рекомендации
kime, rapidminer - комбайны
Gensim - библиотека python
SciPy - библиотека python
Национальный корпус
 Архитектуры систем ИИ и их эволюция
Архитектуры систем ИИ и их эволюция A mouse. A Microprocessor
A mouse. A Microprocessor Информационные технологии в Туризме
Информационные технологии в Туризме Внешние устройства, подключаемые к компьютеру. Программное обеспечение внешних устройств
Внешние устройства, подключаемые к компьютеру. Программное обеспечение внешних устройств Корейские игры
Корейские игры Презентация "BI Розничной сети" - скачать презентации по Информатике
Презентация "BI Розничной сети" - скачать презентации по Информатике Презентация на тему Компьютерные очки
Презентация на тему Компьютерные очки קורס מבוא למדעי המידע
קורס מבוא למדעי המידע Отношения тождества, подчинения, пересечения. Проект «Ученики Леонардо Эйлера» Подготовила учитель информатики МКОУ СОШ №7 Холо
Отношения тождества, подчинения, пересечения. Проект «Ученики Леонардо Эйлера» Подготовила учитель информатики МКОУ СОШ №7 Холо Защита информации, антивирусная защита
Защита информации, антивирусная защита Циклические алгоритмы
Циклические алгоритмы Безопасность в интернете
Безопасность в интернете Шифрование на основе таблицы с управляющими символами
Шифрование на основе таблицы с управляющими символами Работа с графическими примитивами
Работа с графическими примитивами Разработка программы планирование планово-предупредительных ремонтов ЗАО Боровичи-Мебель
Разработка программы планирование планово-предупредительных ремонтов ЗАО Боровичи-Мебель Компьютерная преступность и безопасность. Компьютерные преступления в Уголовном кодексе РФ.
Компьютерная преступность и безопасность. Компьютерные преступления в Уголовном кодексе РФ.  Архив файлов
Архив файлов Виды мошеничества в интернете
Виды мошеничества в интернете Возможности программы iTunes
Возможности программы iTunes ЭВМ и периферия
ЭВМ и периферия Вставка объектов в документ Технология обработки текстовой информации
Вставка объектов в документ Технология обработки текстовой информации Блочные системы шифрования. Криптографическая защита информации. (Лекция 2)
Блочные системы шифрования. Криптографическая защита информации. (Лекция 2) Путешествие по стране Информация. Измерение информации
Путешествие по стране Информация. Измерение информации AMS partner. Софты. Дмитрий Лаптев | PROFIT на ПП
AMS partner. Софты. Дмитрий Лаптев | PROFIT на ПП Сетевые аппаратные средства. (Лекция 4)
Сетевые аппаратные средства. (Лекция 4) Деление полиномов
Деление полиномов Мультимедийные технологии
Мультимедийные технологии Становление информационного общества
Становление информационного общества