- Строковый тип данных в языке С. Параметры запуска. Компиляция

Содержание
- 2. Под хранение строки выделяются последовательно идущие ячейки памяти. Таким образом, строка представляет собой массив символов. Для
- 3. этом случае имена m2 и m3 являются указателями на первые элементы массивов: m2 - эквивалентно &m2[0]
- 4. Здесь m3 является константой-указателем. Нельзя изменить m3, так как это означало бы изменение положения (адреса) массива
- 5. Инициализация выполняется по правилам, определенным для массивов. Тексты в кавычках эквивалентны инициализации каждой строки в массиве.
- 6. Операции со строками Большинство строковых операций языка С, работает с указателями. Для размещения в оперативной памяти
- 7. Вывод строк можно осуществлять через printf: Для вывода строк также может использоваться функция puts: int puts
- 8. Количество символов, считываемых gets(), не ограничивается. Поэтому программист должен сам следить за тем, чтобы не выйти
- 9. Основные функции стандартной библиотеки string.h
- 11. Следует иметь в виду, что все эти функции не производит проверки границ, поэтому программист должен сам
- 14. Параметры запуска При создании консольного приложения в языке С, автоматически создается функция main следующего вида: int
- 15. В среде Dev-C++ аргументы запуска можно задать в меню выполнить -> параметры…
- 17. Компиляция программ Исходный C файл — это всего лишь текстовый файл с С кодом, который невозможно
- 18. Процесс компиляции программ на языке C обычно состоит из следующих этапов: 1) Препроцессинг – подготовка исходного
- 19. 4) Компоновка - компоновщик (линкер) связывает все объектные файлы и статические библиотеки в единый исполняемый файл.
- 21. Скачать презентацию

Под хранение строки выделяются последовательно идущие ячейки памяти. Таким образом, строка
Под хранение строки выделяются последовательно идущие ячейки памяти. Таким образом, строка

этом случае имена m2 и m3 являются указателями на первые элементы массивов:
m2 - эквивалентно &m2[0]
m2[0] -
этом случае имена m2 и m3 являются указателями на первые элементы массивов:
m2 - эквивалентно &m2[0]
m2[0] -

Здесь m3 является константой-указателем. Нельзя изменить m3, так как это означало бы изменение положения
Здесь m3 является константой-указателем. Нельзя изменить m3, так как это означало бы изменение положения

Инициализация выполняется по правилам, определенным для массивов. Тексты в кавычках эквивалентны
Инициализация выполняется по правилам, определенным для массивов. Тексты в кавычках эквивалентны

Операции со строками
Большинство строковых операций языка С, работает с указателями. Для
Операции со строками
Большинство строковых операций языка С, работает с указателями. Для

Вывод строк можно осуществлять через printf:
Для вывода строк также может использоваться
Вывод строк можно осуществлять через printf:
Для вывода строк также может использоваться

Количество символов, считываемых gets(), не ограничивается. Поэтому программист должен сам следить
Количество символов, считываемых gets(), не ограничивается. Поэтому программист должен сам следить

Основные функции стандартной библиотеки string.h
Основные функции стандартной библиотеки string.h


Следует иметь в виду, что все эти функции не производит проверки
Следует иметь в виду, что все эти функции не производит проверки

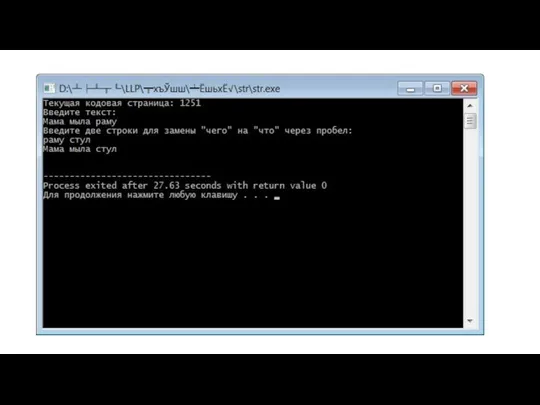

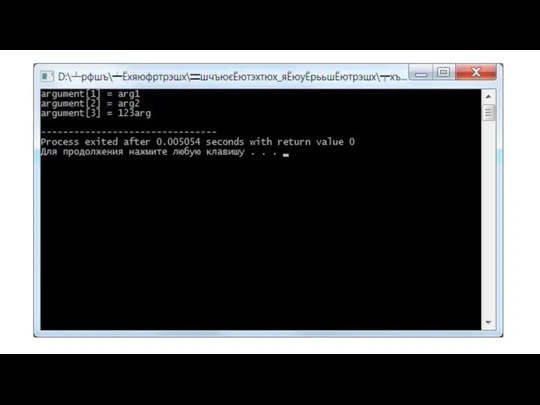
Параметры запуска
При создании консольного приложения в языке С, автоматически создается функция
Параметры запуска
При создании консольного приложения в языке С, автоматически создается функция
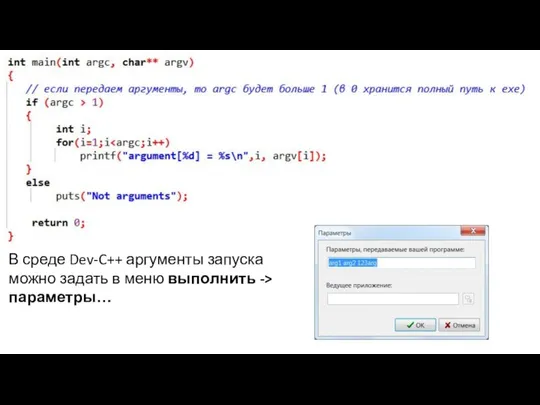
В среде Dev-C++ аргументы запуска можно задать в меню выполнить ->
В среде Dev-C++ аргументы запуска можно задать в меню выполнить ->

Компиляция программ
Исходный C файл — это всего лишь текстовый файл с С
Компиляция программ
Исходный C файл — это всего лишь текстовый файл с С

Процесс компиляции программ на языке C обычно состоит из следующих этапов:
1)
Процесс компиляции программ на языке C обычно состоит из следующих этапов:
1)

4) Компоновка - компоновщик (линкер) связывает все объектные файлы и статические библиотеки
4) Компоновка - компоновщик (линкер) связывает все объектные файлы и статические библиотеки
 Методические принципы создания электронных учебников
Методические принципы создания электронных учебников ООП на Delphi - 7: Программируем свою игрушку
ООП на Delphi - 7: Программируем свою игрушку Защита информации
Защита информации Исполнитель «Чертёжник». Система команд исполнителя «Чертёжник»
Исполнитель «Чертёжник». Система команд исполнителя «Чертёжник» Paint
Paint Разработка модели специалиста по защите информации
Разработка модели специалиста по защите информации Добавление видеофрагментов и их воспроизведение в ходе презентации PowerPoint 2007 Жакулина Ирина Валентиновна, учитель начальных к
Добавление видеофрагментов и их воспроизведение в ходе презентации PowerPoint 2007 Жакулина Ирина Валентиновна, учитель начальных к WinPhlash update SOP
WinPhlash update SOP Электронное заключение контрактов по результатам проведения электронных закупок в соответствии со статьей 83.2 44-ФЗ
Электронное заключение контрактов по результатам проведения электронных закупок в соответствии со статьей 83.2 44-ФЗ Пошаговая инструкция регистрации на портале Госуслуги
Пошаговая инструкция регистрации на портале Госуслуги Основные понятия PHP
Основные понятия PHP Графические возможности MS Word
Графические возможности MS Word IC7000 Advanced & basic HP-automation system for stationary installations
IC7000 Advanced & basic HP-automation system for stationary installations Общее понятие о компьютере. Своя игра
Общее понятие о компьютере. Своя игра Методологические основы принятия решений для сложных систем
Методологические основы принятия решений для сложных систем Бизнес-система Топ-24
Бизнес-система Топ-24 HTML
HTML Запросы на выборку данных
Запросы на выборку данных Основная идея
Основная идея HASH-функции, электронная подпись и цифровые сертификаты. Лекция 5
HASH-функции, электронная подпись и цифровые сертификаты. Лекция 5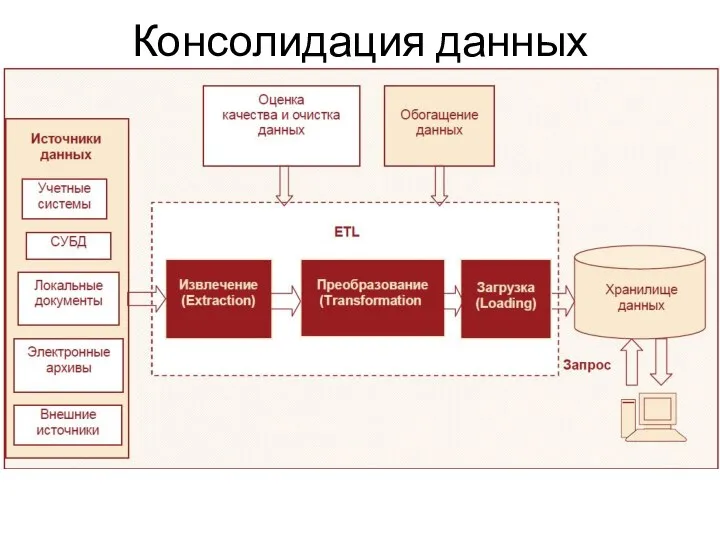 Консолидация данных
Консолидация данных Национальный стандарт по библиотечной статистике
Национальный стандарт по библиотечной статистике Цифровой прорыв - всероссийский конкурс для ИТ-специалистов, дизайнеров и управленцев в сфере цифровой экономики
Цифровой прорыв - всероссийский конкурс для ИТ-специалистов, дизайнеров и управленцев в сфере цифровой экономики RCS Service box
RCS Service box Основы программирования. Летающие Объекты. Лабораторная работа №10
Основы программирования. Летающие Объекты. Лабораторная работа №10 Космический бой
Космический бой Безопасный интернет Мы хотим, чтоб интернет был вам другом много лет! Будешь знать семь правил этих - смело плавай в&nb
Безопасный интернет Мы хотим, чтоб интернет был вам другом много лет! Будешь знать семь правил этих - смело плавай в&nb Виды ссылок в Excel
Виды ссылок в Excel