- TGS-Prüfungsfragen

Содержание
- 2. 1.
- 7. Berechnen Sie B+!B sowie B+!(B-1) und interpretieren Sie die Ergebnisse. B ist eine 8-Bit Binärzahl, die
- 8. Begründen Sie, wie viele Bit (mindestens) benötigt werden um 74 unterschiedliche Zustände darstellen zu können.
- 9. Erklären Sie den Unterschied zwischen Kilobyte und Kibibyte Kilobyte = 10^3 Byte (1000) Kibibyte = 2^10
- 12. 1.(I, II) Was ist ein Floating Gate? Wozu wird es verwendet? wird bei PROM, EPROM, EEPROM,
- 13. 2. (I, II)Erklären sie den Fetch - Decode - Execute Zyklus. Was passiert in jedem dieser
- 14. Erklären sie den Fetch – Decode – Execute Zyklus (FDE). Was passiert in jedem dieser Schritte?
- 15. 3.(I) Amdahl‘s Law Angenommen die Fraction Enhanced beträgt 1/4 der Gesamtausführzeit und der Speedup Enhanced (für
- 16. 4.(II) Amdahl‘s Law Variante2: Fraction Enhanced 2/3. Wie groß muss der Speedup Enhanced (für diese 2/3)
- 18. 5.(I) Erklären Sie den Zusammenhang zwischen Big – und Little Endian und sagen Sie welche Variante
- 19. 6.(II) Konvertieren Sie 1101 1011 01112 in das Hexadezimalsystem. Wie groß ist diese Zahl im Dezimalsystem
- 20. Was hat das Binäre-, Oktale- und Hexadezimale Zahlensystem gemeinsam? Wie geht die Formel dazu? Zu welchem
- 21. Wie wird im Dualsystem multipliziert/dividiert? Welche logische Operation steht dem zu? Multiplikation: Zahl wird um S
- 22. 7.(I) Wann werden Komplemente in der Zahlensdarstellung am Computer verwendet? Nenne Sie mindestens zwei Komplemente
- 23. 8.(I) Single Precision 32 Bits Einfache Genauigkeit - Exponent (8bit) , für Bereich entscheidend und Mantisse(23bit)
- 24. 9.(II) Nennen Sie zwei Stellenwertsysteme, die in der Informatik oft genutzt werden. Wodurch wird bei Stellenwertsystemen
- 25. 10.(I) Kann der rechnerisch wirkende Exponent einer Fließkommazahl (IEEE 754 Standard) kleiner als 0 sein? Wenn
- 26. Argumentieren Sie, warum folgende Aussagen korrekt bzw. falsch sind (ohne Begründung keine Punkte). Mit double Precision
- 27. 11.(I) Erklären Sie, warum bei der Verarbeitung von reellen Zahlen am Computer Rundungsfehler auftreten können. Welcher
- 28. 12.(II) Wie viele unterschiedliche Zustände können mit n Bit dargestellt werden? 2 auf n Zustände (s.18)
- 29. 13.(II) Erklären Sie die Bedetung von Exponent und Mantisse bei Fließkommazahl-Darstellung (IEEE 754 Standard) Siehe Frage
- 30. Weitere Prüfungsfragen (Thema2 – Boolesche Algebra)
- 31. 15.(I) Welche der folgenden 3 Booleschen Ausdrücke sind identisch? Hinweis: Versuchen Sie alle Terme auf eine
- 32. Warum werden Normalformen verwendet? um Ausdrücke zu vereinfachen und leserlicher zu machen, da viele verschiedene Formen
- 33. Welche beiden wichtigen Normalformen (für Boole´sche Funktionen) gibt es (vollständige Bezeichnung)? KNF = Konjunktive Normalform Volldisjunktionen
- 34. Geben Sie jeweils ein typisches Beispiel pro Normalform mit drei booleschen Variablen a, b und c
- 35. Sie kennen Distributiv- und Kommutativgesetz sowohl vom Rechnen mit reellen Zahlen, als auch der booleschen Algebra.
- 36. 16.(I) Beweisen Sie mittels KV-Diagramm die De Morgansche Regel. !(a oder b) = !a und !b
- 37. 16.(I) Beweisen Sie mittels KV-Diagramm die De Morgansche Regel. !(a und b) = !a oder !b
- 38. 17.(II) Wozu wird ein KV-Diagramm verwendet? Wie viele Felder hat ein KV-Diagramm mit n Eingangsvariablen und
- 39. 18.(II) Gegeben ist folgender Term in minimaler DNF: a ˅ (b ˄ c). Tragen Sie diesen
- 40. 19.(II) Handelt es sich beim folgenden Satz um eine Tautologie, eine Antilogie (kontradiktion), oder keines von
- 41. Weitere Prüfungsfragen (Thema 3 – Digitale Logik)
- 42. Welche Anschlüsse hat ein n-Kanal-MOSFET, und wozu dienen diese Anschlüsse? Gate (Tor, Gatter): wenn nicht geladen,
- 43. 20. (I) Skizieren Sie den Aufbau eine n-Kanal-MOSFET (NMOS) einschließlich der verschiedenen Dotierungen, und beschriften Sie
- 44. Metal Oxide Semiconductor Field Effect Transistor (MOSFET): Vier Anschlüsse: Source – Drain – Gate – Bulk
- 45. 21.(I) Wann bezeichnet man ein Gatter als „logisch vollständig“? Nennen Sie zwei Beispiele für logisch vollständige
- 46. 22.(II) Multiplexer: Wozu dienen die Steuerleitungen? Wie viele Steuerleitungen werden bei einem Multiplexer mit 8 Eingangsleitungen
- 47. 23.(II) Latches und Flip-Flops: Erklären Sie den Unterschied zwischen taktzustand-gesteurt und taktflanken-gesteurt. Latch ist taktzustands-(taktpegel-)gesteuert. kann
- 48. 23.(II) Latches und Flip-Flops: Erklären Sie den Unterschied zwischen taktzustand-gesteurt und taktflanken-gesteurt. FlipFlop ist taktflankengesteuert. übernimmt
- 49. 24.(I) Beschreiben Sie den Unterschied zwischen einem Decoder und einem Multiplexer? Welche Ein- und Ausgänge und
- 50. 24.(I) Beschreiben Sie den Unterschied zwischen einem Decoder und einem Multiplexer? Welche Ein- und Ausgänge und
- 51. 25.(I) Welche zwei wichtigen Vertreter von flüchtigen RAM Speichern kennen Sie (vollständige Bezeichnung!) Erläutern Sie kurz
- 52. 25.(I) Welche zwei wichtigen Vertreter von flüchtigen RAM Speichern kennen Sie (vollständige Bezeichnung!) Erläutern Sie kurz
- 53. Erklären Sie die grundlegenden Unterschiede zwischen den Speichertypen RAM und ROM! Wofür stehen die Abkürzungen? RAM
- 54. Prozessor: Was versteht man unter Register bzw. Registersatz? Erklären Sie die grundlegenden Eigenschaften von Registern Registersatz:
- 55. Prozessor: Wofür steht die Abkürzung ALU und welche Aufgaben hat die ALU? ALU = Arithmetical Logical
- 56. 26.(I) Carry-Ripple-Addierer: Erklären Sie das Prinzip des Carry-Ripple-Addierers! Wie viele Binärzahlen kann er addieren? Wie viele
- 57. 26.(I) Carry-Ripple-Addierer: Erklären Sie das Prinzip des Carry-Ripple-Addierers! Wie viele Binärzahlen kann er addieren? Wie viele
- 58. 26.(I) Carry-Ripple-Addierer: Erklären Sie das Prinzip des Carry-Ripple-Addierers! Wie viele Binärzahlen kann er addieren? Wie viele
- 59. Skizzieren Sie den typischen Aufbau eines 32 Bit Speicherbausteines mit Wortleitungen und 8 Bitleitungen. Erklären Sie,
- 60. 27.(II) Wie viele Binärzahlen kann ein Volladdierer addieren und wie viele Stellen können diese Binärzahlen haben?
- 61. 28.(II)Geben Sie die grundlegenden Eigenschaften von Flash-Speichern an! Zu welcher Familie (RAM/ROM) von Halbaleiterspeichern (engl. Semiconductor)
- 62. 29.(II) Aus wie vielen Transistoren besteht eine SRAM-Speicherzelle typischerweise? Skizieren Sie den grundsätzlichen Aufbau einer SRAM-Zelle!
- 63. Prozessor: Welche Aufgabe haben Busse? Über welche Busse ist die CPU an den Rest des Systems
- 64. Paging: Erklären Sie den Unterschied zwischen physikalischem und virtuellem Adressraum. physikalischer Adressraum: befindet sich vollständig am
- 65. Caches: Warum wird zwischen MR und MPI (nicht MP!) unterschieden? MR = Miss Rate = Misses/Speicherzugriff
- 67. Ein Prozess kann nur von einem anderen Prozess beendet werden. Falsch – in kann auch durch
- 68. Beim CPU Scheduling kann die durchschnittliche Wartezeit dadurch minimiert werden, dass Prozesse mit langer Ausführungszeit zuerst
- 70. 30.(I) Erklären Sie in wenigen Worten das Prinzip des virtuellen Speichers wird bei Speichermangel im Hauptspeicher
- 71. 31.(I) Erklären Sie, warum man in CPUs schon seit langer Zeit Caches verwendet. CPU wurde in
- 72. 32.(II) Aus welchen grundlegenden Komponenten besteht eine CPU? Beschreiben Sie jede dieser Komponenten mit einem Satz.
- 73. 33.(II) Beschreiben Sie kurz (aufzählen reicht nicht) mindestens zwei Probleme die beim Pipelining auftreten können und
- 74. 33.(II) Beschreiben Sie kurz (aufzählen reicht nicht) mindestens zwei Probleme die beim Pipelining auftreten können und
- 75. 33.(II) Beschreiben Sie kurz (aufzählen reicht nicht) mindestens zwei Probleme die beim Pipelining auftreten können und
- 76. 34.(I) Warum ist Pipelining für die Performance einer CPU wichtig? Diskutieren Sie mindestens zwei Problem beim
- 77. 35.(I) Erklären Sie die beiden Begriffe CISC und RISC. Worin liegen die Unterschiede zwischen diesen beiden
- 78. 35.(I) Erklären Sie die beiden Begriffe CISC und RISC. Worin liegen die Unterschiede zwischen diesen beiden
- 79. 36.(I) Erklären sie, warum bei mehrstufigen Caches die Miss Penalty (MP) des Level 1 (L1) Caches
- 80. 37.(I) (Magnetische) Festplatte: Warum können defragmentierte Daten schneller gelesen werden als stark fragmentierte Daten? Welche(r) Teil(e)
- 81. 38.(II) Caches: Was besagt das Lokalitätsprinzip? Erklären Sie kurz die zwei Arten von Lokalität? auf (Haupt-)Speicher
- 82. 39.(II) Caches: Erklären Sie die Begriffe: Hit Time, Miss Rate, Miss Penalty
- 83. Weitere Prüfungsfragen (Thema 5 –Betriebsysteme)
- 84. 40.(II) Erklären Sie das Konzept des Multiprogramming und warum es vorteilhaft für die Auslastung einer CPU
- 85. 41.(II) Erklären Sie die wichtigsten Unterschiede zwischen Prozessen und Threads bezüglich Ressourcenverwaltung, Ausführungsverwaltung, Speicherschutz, und Effizienz
- 86. 41.(II) Erklären Sie die wichtigsten Unterschiede zwischen Prozessen und Threads bezüglich Ressourcenverwaltung, Ausführungsverwaltung, Speicherschutz, und Effizienz
- 87. 42.(II) Wann spricht man von einem Context Switch? Warum können viele Context Switches in kurzer Zeit
- 88. 43.(II) Diskutieren Sie mindestens drei mögliche Gründe wann eine CPU-Scheduling Entscheidung getroffen werden kann/muss? Neuer (Kind-)Prozess
- 89. 44.(II) Erklären Sie präzise die preemptive Priority Scheduling Strategie mit Aging. Warum ist das Prinzip des
- 90. Thema 5 - Betriebsysteme JA/NEIN Fragen + Begründung
- 91. Betriebsysteme JA/NEIN Fragen 1. Betriebssysteme verwalten zwar den Zugriff auf die CPU; Betriebssysteme verwalten jedoch ansonsten
- 92. 6. Jeder Thread hat seinen eigenen Befehlszähler und einen eigenen Zuständ. Richtig- Da jeder Thread für
- 93. 11. Beim CPU Scheduling kann die durchschnittliche Wartezeit dadurch minimiert werden, dass Prozesse mit kurzer Ausführungszeit
- 94. 14. In interaktiven Betriebssystemen gibt es üblicherweise mehr context switches als in Stapelverarbeitungssystemen. Richtig – bei
- 96. Скачать презентацию

1.
1.





Berechnen Sie B+!B sowie B+!(B-1) und interpretieren Sie die Ergebnisse.
B
Berechnen Sie B+!B sowie B+!(B-1) und interpretieren Sie die Ergebnisse. B

Begründen Sie, wie viele Bit (mindestens) benötigt werden um 74 unterschiedliche
Begründen Sie, wie viele Bit (mindestens) benötigt werden um 74 unterschiedliche

Erklären Sie den Unterschied zwischen Kilobyte und Kibibyte
Kilobyte = 10^3 Byte
Erklären Sie den Unterschied zwischen Kilobyte und Kibibyte
Kilobyte = 10^3 Byte



1.(I, II) Was ist ein Floating Gate?
Wozu wird es verwendet?
wird bei
1.(I, II) Was ist ein Floating Gate?
Wozu wird es verwendet?
wird bei

2. (I, II)Erklären sie den
Fetch - Decode - Execute Zyklus.
2. (I, II)Erklären sie den Fetch - Decode - Execute Zyklus.
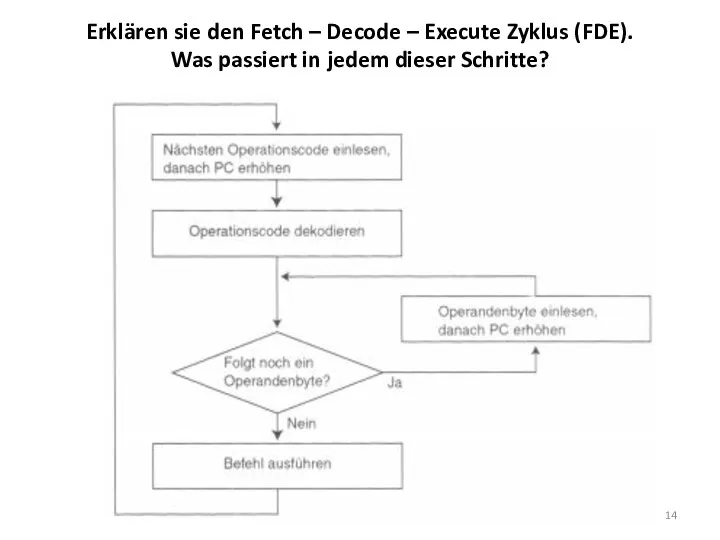
Erklären sie den Fetch – Decode – Execute Zyklus (FDE).
Was
Erklären sie den Fetch – Decode – Execute Zyklus (FDE). Was

3.(I) Amdahl‘s Law
Angenommen die Fraction Enhanced beträgt 1/4 der Gesamtausführzeit und
3.(I) Amdahl‘s Law
Angenommen die Fraction Enhanced beträgt 1/4 der Gesamtausführzeit und

4.(II) Amdahl‘s Law
Variante2:
Fraction Enhanced 2/3. Wie groß muss der Speedup Enhanced
4.(II) Amdahl‘s Law
Variante2:
Fraction Enhanced 2/3. Wie groß muss der Speedup Enhanced


5.(I) Erklären Sie den Zusammenhang zwischen Big – und Little Endian
5.(I) Erklären Sie den Zusammenhang zwischen Big – und Little Endian

6.(II) Konvertieren Sie 1101 1011 01112 in das Hexadezimalsystem. Wie groß
6.(II) Konvertieren Sie 1101 1011 01112 in das Hexadezimalsystem. Wie groß

Was hat das Binäre-, Oktale- und Hexadezimale Zahlensystem gemeinsam? Wie geht
Was hat das Binäre-, Oktale- und Hexadezimale Zahlensystem gemeinsam? Wie geht

Wie wird im Dualsystem multipliziert/dividiert? Welche logische Operation steht dem zu?
Multiplikation:
Zahl
Wie wird im Dualsystem multipliziert/dividiert? Welche logische Operation steht dem zu?
Multiplikation:
Zahl

7.(I) Wann werden Komplemente in der Zahlensdarstellung
am Computer verwendet?
Nenne
7.(I) Wann werden Komplemente in der Zahlensdarstellung am Computer verwendet? Nenne
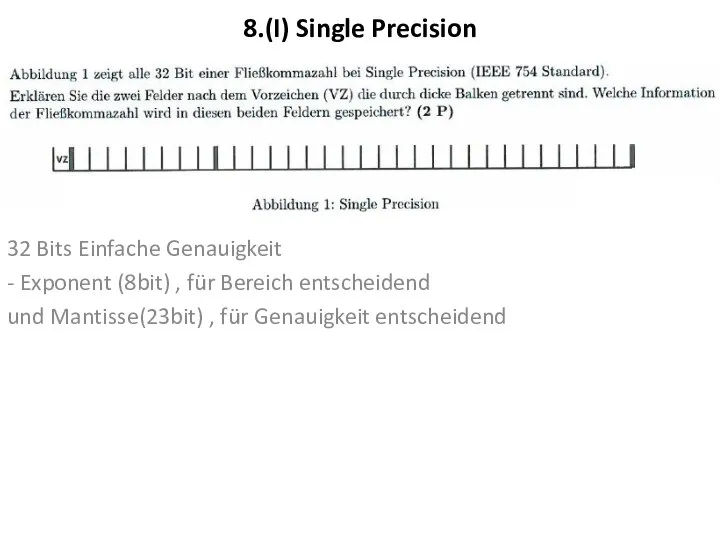
8.(I) Single Precision
32 Bits Einfache Genauigkeit
- Exponent (8bit) , für Bereich
8.(I) Single Precision
32 Bits Einfache Genauigkeit
- Exponent (8bit) , für Bereich

9.(II) Nennen Sie zwei Stellenwertsysteme, die in der Informatik oft genutzt
9.(II) Nennen Sie zwei Stellenwertsysteme, die in der Informatik oft genutzt

10.(I) Kann der rechnerisch wirkende Exponent einer Fließkommazahl (IEEE 754 Standard)
10.(I) Kann der rechnerisch wirkende Exponent einer Fließkommazahl (IEEE 754 Standard)

Argumentieren Sie, warum folgende Aussagen korrekt
bzw. falsch sind (ohne Begründung
Argumentieren Sie, warum folgende Aussagen korrekt bzw. falsch sind (ohne Begründung

11.(I) Erklären Sie, warum bei der Verarbeitung von reellen Zahlen am
11.(I) Erklären Sie, warum bei der Verarbeitung von reellen Zahlen am

12.(II) Wie viele unterschiedliche Zustände können mit n Bit dargestellt werden?
2
12.(II) Wie viele unterschiedliche Zustände können mit n Bit dargestellt werden?
2

13.(II) Erklären Sie die Bedetung von Exponent und Mantisse bei Fließkommazahl-Darstellung
13.(II) Erklären Sie die Bedetung von Exponent und Mantisse bei Fließkommazahl-Darstellung

Weitere Prüfungsfragen
(Thema2 – Boolesche Algebra)
Weitere Prüfungsfragen
(Thema2 – Boolesche Algebra)

15.(I) Welche der folgenden 3 Booleschen Ausdrücke
sind identisch?
Hinweis: Versuchen Sie
15.(I) Welche der folgenden 3 Booleschen Ausdrücke sind identisch? Hinweis: Versuchen Sie

Warum werden Normalformen verwendet?
um Ausdrücke zu vereinfachen und leserlicher zu machen,
Warum werden Normalformen verwendet?
um Ausdrücke zu vereinfachen und leserlicher zu machen,

Welche beiden wichtigen Normalformen (für Boole´sche Funktionen) gibt es (vollständige Bezeichnung)?
KNF
Welche beiden wichtigen Normalformen (für Boole´sche Funktionen) gibt es (vollständige Bezeichnung)?
KNF

Geben Sie jeweils ein typisches Beispiel pro Normalform mit drei booleschen
Geben Sie jeweils ein typisches Beispiel pro Normalform mit drei booleschen

Sie kennen Distributiv- und Kommutativgesetz sowohl vom Rechnen mit reellen Zahlen,
Sie kennen Distributiv- und Kommutativgesetz sowohl vom Rechnen mit reellen Zahlen,

16.(I) Beweisen Sie mittels KV-Diagramm
die De Morgansche Regel.
!(a oder b)
16.(I) Beweisen Sie mittels KV-Diagramm
die De Morgansche Regel.
!(a oder b)

16.(I) Beweisen Sie mittels KV-Diagramm
die De Morgansche Regel.
!(a und b)
16.(I) Beweisen Sie mittels KV-Diagramm
die De Morgansche Regel.
!(a und b)

17.(II) Wozu wird ein KV-Diagramm verwendet?
Wie viele Felder hat ein
17.(II) Wozu wird ein KV-Diagramm verwendet? Wie viele Felder hat ein
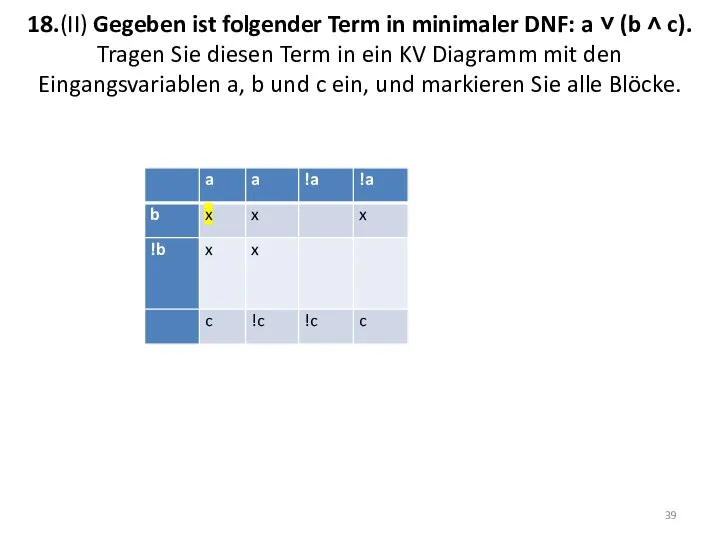
18.(II) Gegeben ist folgender Term in minimaler DNF: a ˅ (b
18.(II) Gegeben ist folgender Term in minimaler DNF: a ˅ (b
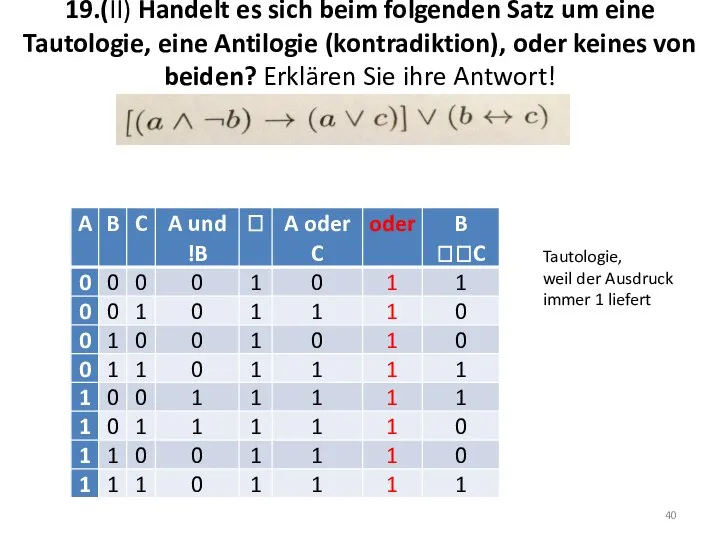
19.(II) Handelt es sich beim folgenden Satz um eine Tautologie, eine
19.(II) Handelt es sich beim folgenden Satz um eine Tautologie, eine

Weitere Prüfungsfragen
(Thema 3 – Digitale Logik)
Weitere Prüfungsfragen
(Thema 3 – Digitale Logik)

Welche Anschlüsse hat ein n-Kanal-MOSFET,
und wozu dienen diese Anschlüsse?
Gate (Tor,
Welche Anschlüsse hat ein n-Kanal-MOSFET,
und wozu dienen diese Anschlüsse?
Gate (Tor,
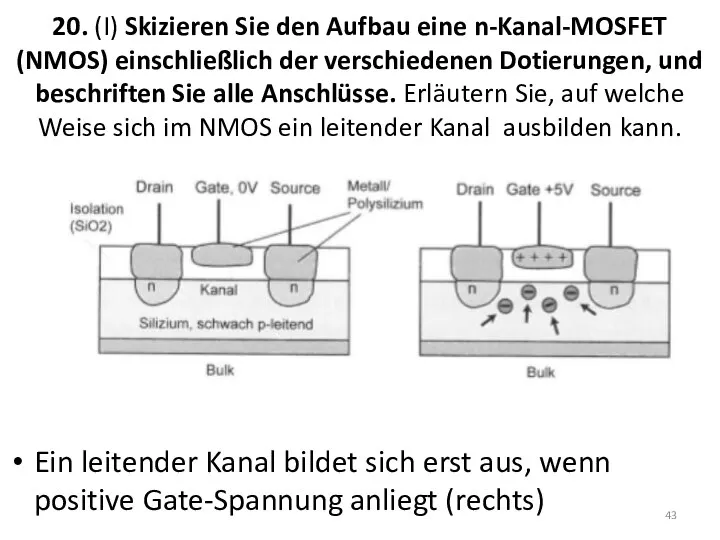
20. (I) Skizieren Sie den Aufbau eine n-Kanal-MOSFET (NMOS) einschließlich der
20. (I) Skizieren Sie den Aufbau eine n-Kanal-MOSFET (NMOS) einschließlich der

Metal Oxide Semiconductor Field Effect Transistor (MOSFET):
Vier Anschlüsse: Source – Drain
Metal Oxide Semiconductor Field Effect Transistor (MOSFET):
Vier Anschlüsse: Source – Drain

21.(I) Wann bezeichnet man ein Gatter
als „logisch vollständig“?
Nennen Sie
21.(I) Wann bezeichnet man ein Gatter als „logisch vollständig“? Nennen Sie

22.(II) Multiplexer: Wozu dienen die Steuerleitungen?
Wie viele Steuerleitungen werden bei
22.(II) Multiplexer: Wozu dienen die Steuerleitungen? Wie viele Steuerleitungen werden bei
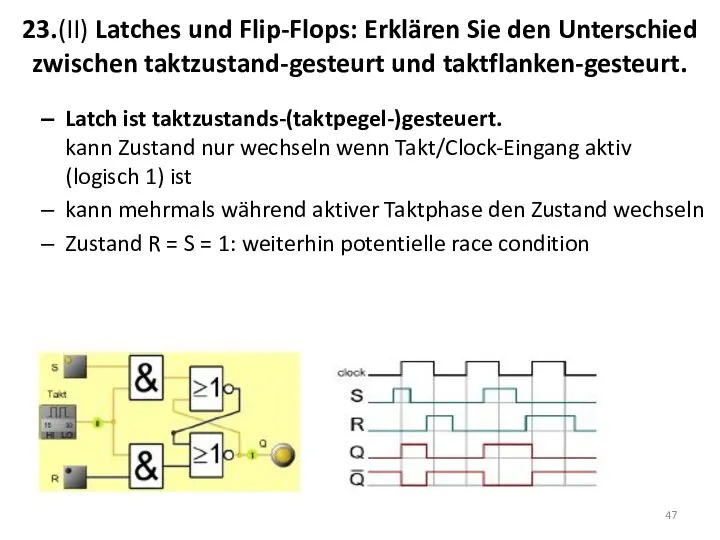
23.(II) Latches und Flip-Flops: Erklären Sie den Unterschied zwischen taktzustand-gesteurt und
23.(II) Latches und Flip-Flops: Erklären Sie den Unterschied zwischen taktzustand-gesteurt und
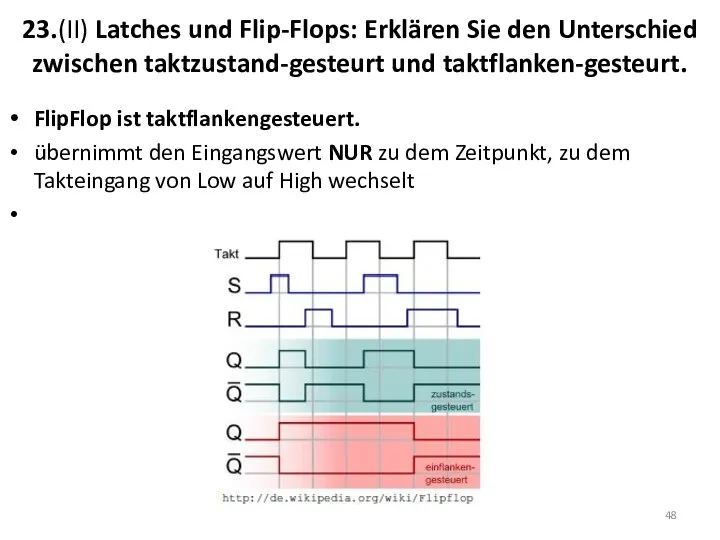
23.(II) Latches und Flip-Flops: Erklären Sie den Unterschied zwischen taktzustand-gesteurt und
23.(II) Latches und Flip-Flops: Erklären Sie den Unterschied zwischen taktzustand-gesteurt und

24.(I) Beschreiben Sie den Unterschied zwischen einem Decoder und einem Multiplexer?
24.(I) Beschreiben Sie den Unterschied zwischen einem Decoder und einem Multiplexer?

24.(I) Beschreiben Sie den Unterschied zwischen einem Decoder und einem Multiplexer?
24.(I) Beschreiben Sie den Unterschied zwischen einem Decoder und einem Multiplexer?
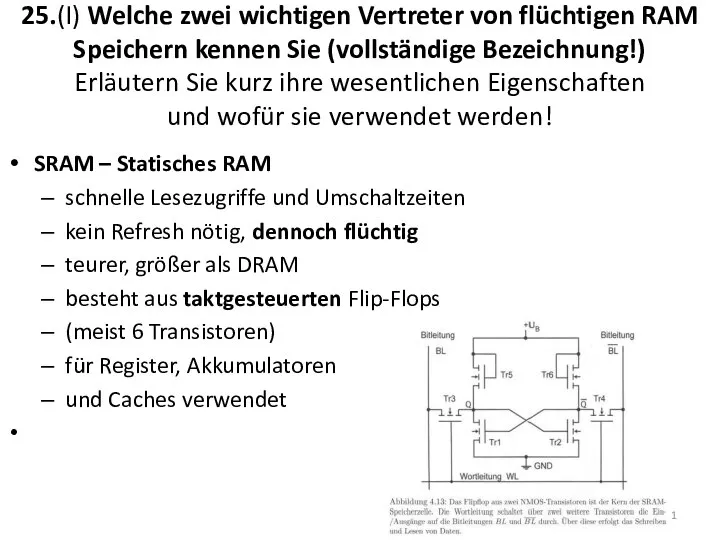
25.(I) Welche zwei wichtigen Vertreter von flüchtigen RAM Speichern kennen Sie
25.(I) Welche zwei wichtigen Vertreter von flüchtigen RAM Speichern kennen Sie
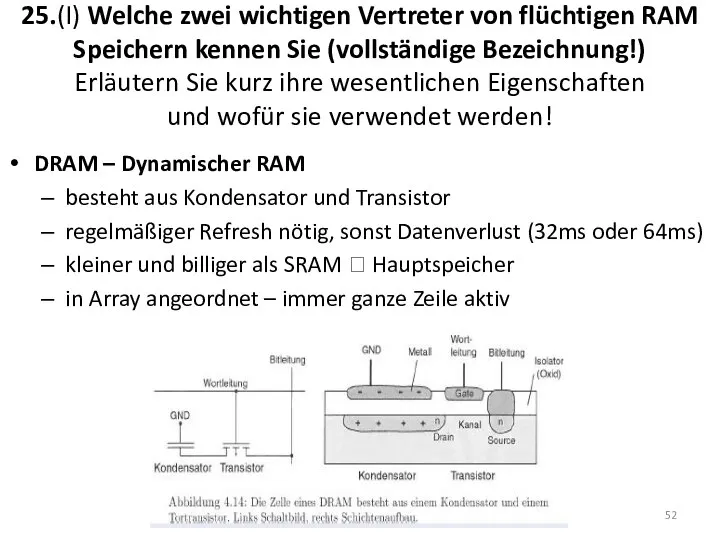
25.(I) Welche zwei wichtigen Vertreter von flüchtigen RAM Speichern kennen Sie
25.(I) Welche zwei wichtigen Vertreter von flüchtigen RAM Speichern kennen Sie

Erklären Sie die grundlegenden Unterschiede zwischen den Speichertypen RAM und ROM!
Erklären Sie die grundlegenden Unterschiede zwischen den Speichertypen RAM und ROM!

Prozessor: Was versteht man unter Register bzw. Registersatz? Erklären Sie die
Prozessor: Was versteht man unter Register bzw. Registersatz? Erklären Sie die
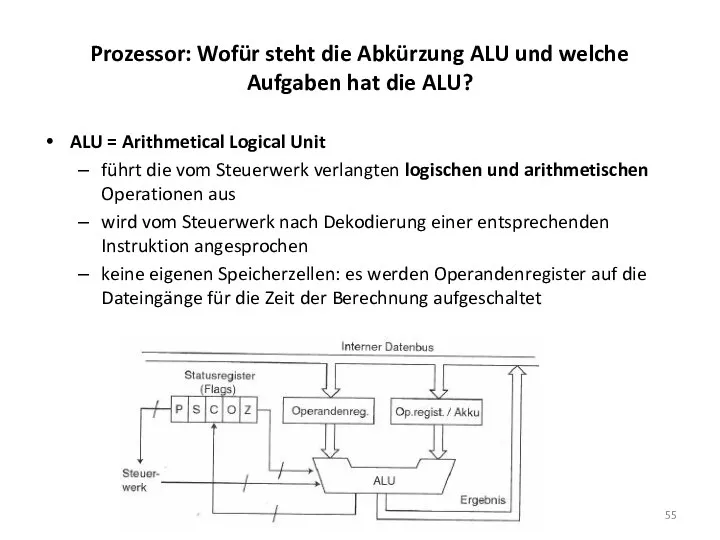
Prozessor: Wofür steht die Abkürzung ALU und welche Aufgaben hat die
Prozessor: Wofür steht die Abkürzung ALU und welche Aufgaben hat die
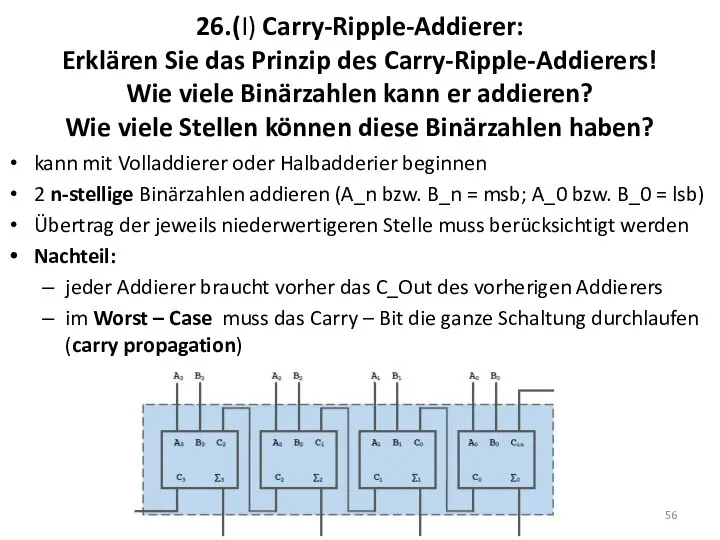
26.(I) Carry-Ripple-Addierer:
Erklären Sie das Prinzip des Carry-Ripple-Addierers!
Wie viele Binärzahlen
26.(I) Carry-Ripple-Addierer: Erklären Sie das Prinzip des Carry-Ripple-Addierers! Wie viele Binärzahlen
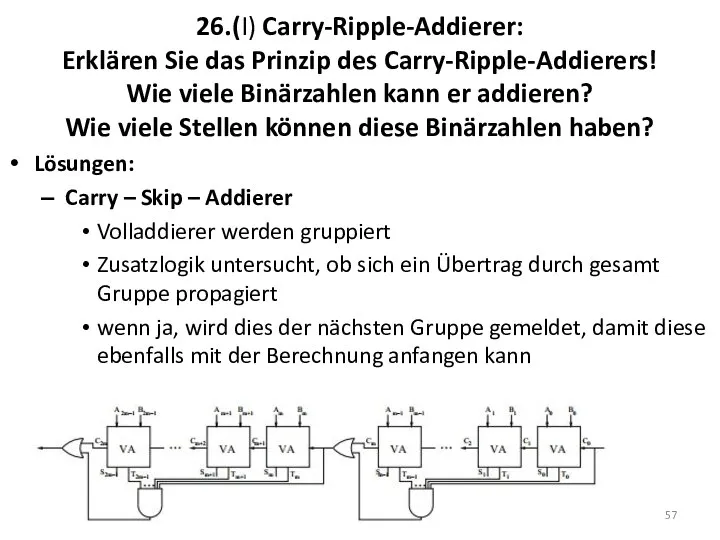
26.(I) Carry-Ripple-Addierer:
Erklären Sie das Prinzip des Carry-Ripple-Addierers!
Wie viele Binärzahlen
26.(I) Carry-Ripple-Addierer: Erklären Sie das Prinzip des Carry-Ripple-Addierers! Wie viele Binärzahlen
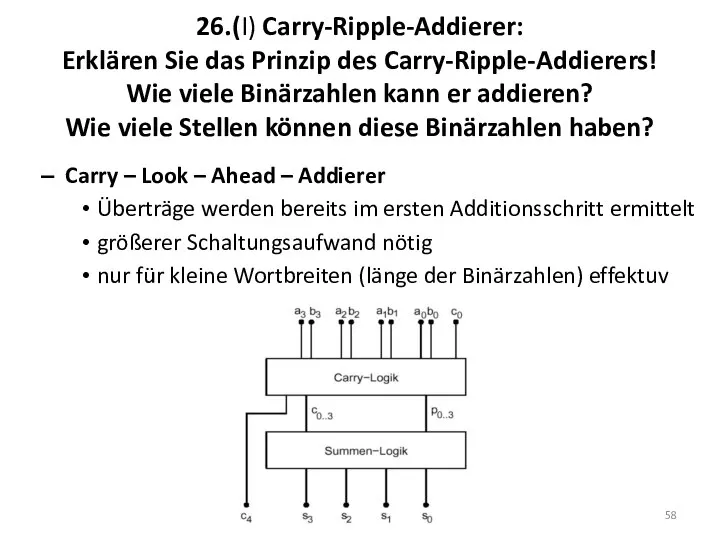
26.(I) Carry-Ripple-Addierer:
Erklären Sie das Prinzip des Carry-Ripple-Addierers!
Wie viele Binärzahlen
26.(I) Carry-Ripple-Addierer: Erklären Sie das Prinzip des Carry-Ripple-Addierers! Wie viele Binärzahlen
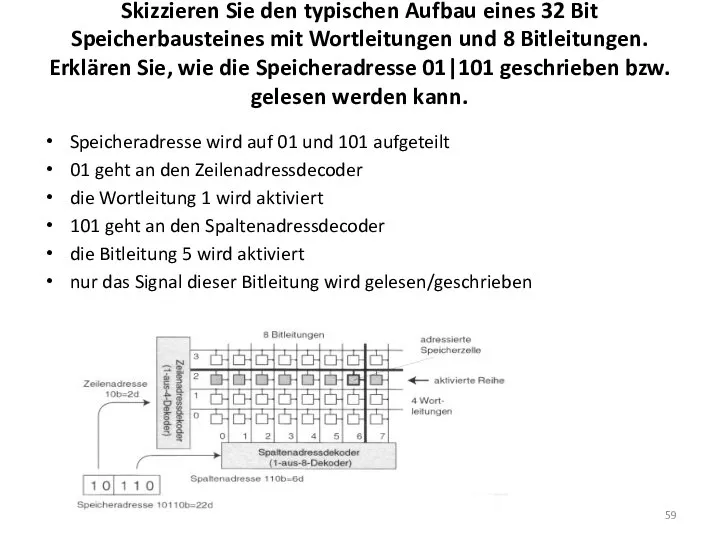
Skizzieren Sie den typischen Aufbau eines 32 Bit Speicherbausteines mit Wortleitungen
Skizzieren Sie den typischen Aufbau eines 32 Bit Speicherbausteines mit Wortleitungen

27.(II) Wie viele Binärzahlen kann ein Volladdierer addieren und wie viele
27.(II) Wie viele Binärzahlen kann ein Volladdierer addieren und wie viele

28.(II)Geben Sie die grundlegenden Eigenschaften
von Flash-Speichern an!
Zu welcher Familie
28.(II)Geben Sie die grundlegenden Eigenschaften von Flash-Speichern an! Zu welcher Familie
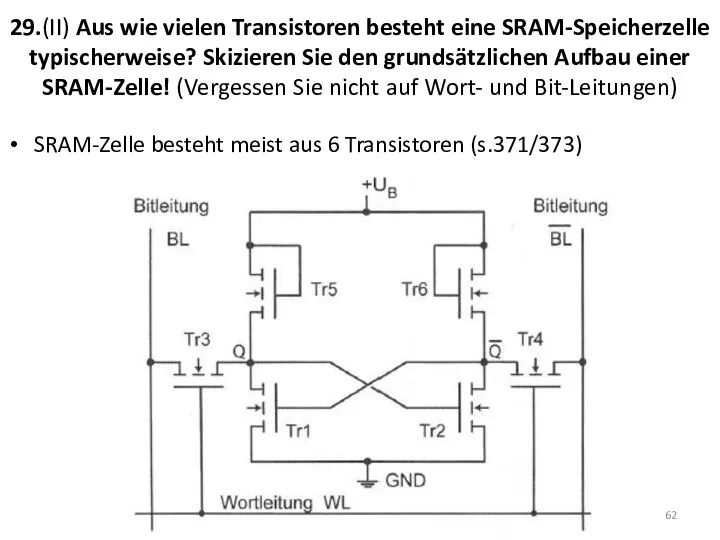
29.(II) Aus wie vielen Transistoren besteht eine SRAM-Speicherzelle typischerweise? Skizieren Sie
29.(II) Aus wie vielen Transistoren besteht eine SRAM-Speicherzelle typischerweise? Skizieren Sie
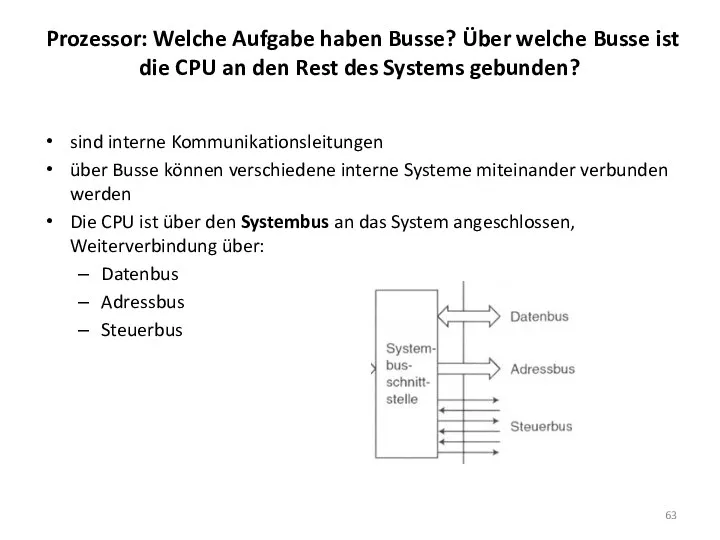
Prozessor: Welche Aufgabe haben Busse? Über welche Busse ist die CPU
Prozessor: Welche Aufgabe haben Busse? Über welche Busse ist die CPU

Paging: Erklären Sie den Unterschied zwischen physikalischem und virtuellem Adressraum.
physikalischer Adressraum:
befindet
Paging: Erklären Sie den Unterschied zwischen physikalischem und virtuellem Adressraum.
physikalischer Adressraum:
befindet

Caches: Warum wird zwischen MR und MPI (nicht MP!) unterschieden?
MR =
Caches: Warum wird zwischen MR und MPI (nicht MP!) unterschieden?
MR =


Ein Prozess kann nur von einem anderen Prozess beendet werden.
Falsch –
Ein Prozess kann nur von einem anderen Prozess beendet werden.
Falsch –

Beim CPU Scheduling kann die durchschnittliche Wartezeit dadurch minimiert werden, dass
Beim CPU Scheduling kann die durchschnittliche Wartezeit dadurch minimiert werden, dass

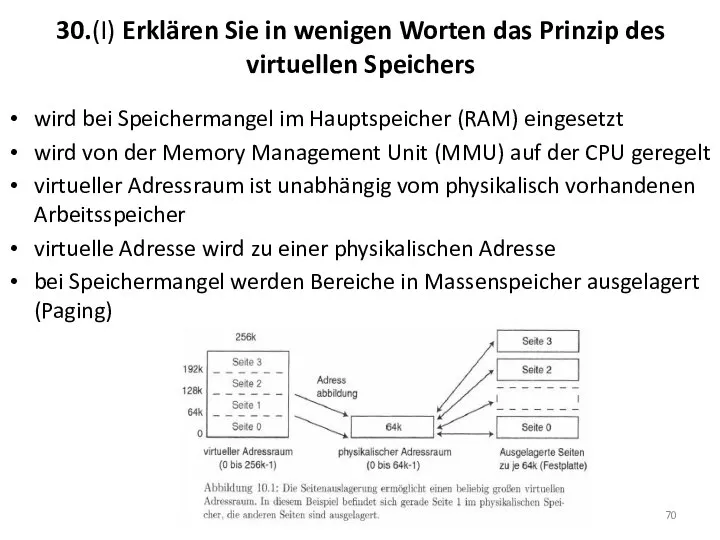
30.(I) Erklären Sie in wenigen Worten das Prinzip des virtuellen Speichers
wird
30.(I) Erklären Sie in wenigen Worten das Prinzip des virtuellen Speichers
wird

31.(I) Erklären Sie, warum man in CPUs schon seit langer Zeit
31.(I) Erklären Sie, warum man in CPUs schon seit langer Zeit
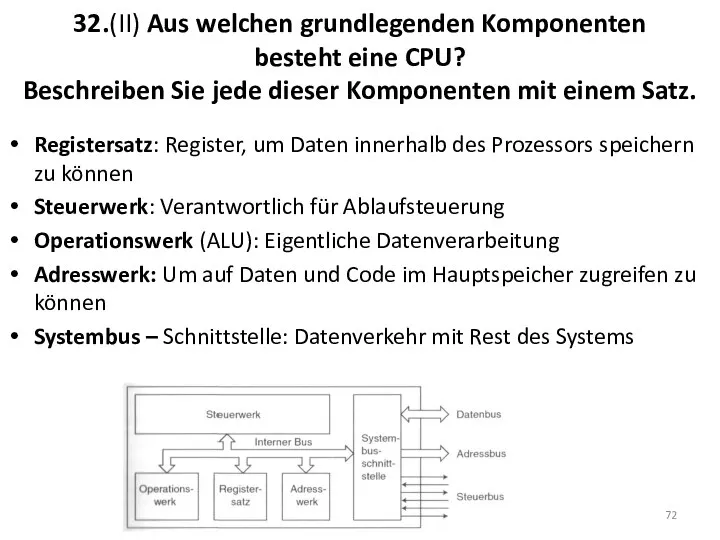
32.(II) Aus welchen grundlegenden Komponenten
besteht eine CPU?
Beschreiben Sie jede
32.(II) Aus welchen grundlegenden Komponenten besteht eine CPU? Beschreiben Sie jede

33.(II) Beschreiben Sie kurz (aufzählen reicht nicht) mindestens zwei Probleme die
33.(II) Beschreiben Sie kurz (aufzählen reicht nicht) mindestens zwei Probleme die

33.(II) Beschreiben Sie kurz (aufzählen reicht nicht) mindestens zwei Probleme die
33.(II) Beschreiben Sie kurz (aufzählen reicht nicht) mindestens zwei Probleme die

33.(II) Beschreiben Sie kurz (aufzählen reicht nicht) mindestens zwei Probleme die
33.(II) Beschreiben Sie kurz (aufzählen reicht nicht) mindestens zwei Probleme die

34.(I) Warum ist Pipelining für die Performance einer CPU wichtig? Diskutieren
34.(I) Warum ist Pipelining für die Performance einer CPU wichtig? Diskutieren

35.(I) Erklären Sie die beiden Begriffe CISC und RISC. Worin liegen
35.(I) Erklären Sie die beiden Begriffe CISC und RISC. Worin liegen

35.(I) Erklären Sie die beiden Begriffe CISC und RISC. Worin liegen
35.(I) Erklären Sie die beiden Begriffe CISC und RISC. Worin liegen

36.(I) Erklären sie, warum bei mehrstufigen Caches die Miss Penalty (MP)
36.(I) Erklären sie, warum bei mehrstufigen Caches die Miss Penalty (MP)
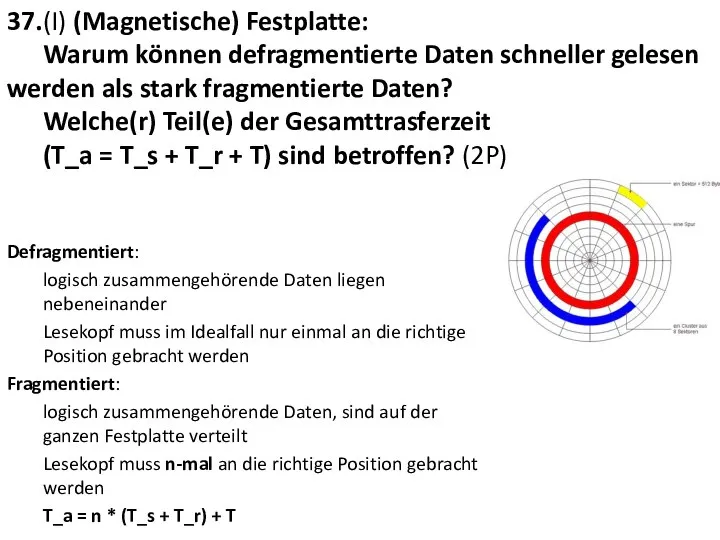
37.(I) (Magnetische) Festplatte:
Warum können defragmentierte Daten schneller gelesen werden als
37.(I) (Magnetische) Festplatte: Warum können defragmentierte Daten schneller gelesen werden als

38.(II) Caches: Was besagt das Lokalitätsprinzip? Erklären Sie kurz die zwei
38.(II) Caches: Was besagt das Lokalitätsprinzip? Erklären Sie kurz die zwei

39.(II) Caches: Erklären Sie die Begriffe:
Hit Time, Miss Rate, Miss
39.(II) Caches: Erklären Sie die Begriffe: Hit Time, Miss Rate, Miss

Weitere Prüfungsfragen
(Thema 5 –Betriebsysteme)
Weitere Prüfungsfragen
(Thema 5 –Betriebsysteme)

40.(II) Erklären Sie das Konzept des Multiprogramming und warum es vorteilhaft
40.(II) Erklären Sie das Konzept des Multiprogramming und warum es vorteilhaft

41.(II) Erklären Sie die wichtigsten Unterschiede zwischen Prozessen und Threads bezüglich
41.(II) Erklären Sie die wichtigsten Unterschiede zwischen Prozessen und Threads bezüglich

41.(II) Erklären Sie die wichtigsten Unterschiede zwischen Prozessen und Threads bezüglich
41.(II) Erklären Sie die wichtigsten Unterschiede zwischen Prozessen und Threads bezüglich

42.(II) Wann spricht man von einem Context Switch? Warum können viele
42.(II) Wann spricht man von einem Context Switch? Warum können viele

43.(II) Diskutieren Sie mindestens drei mögliche Gründe wann eine CPU-Scheduling Entscheidung
43.(II) Diskutieren Sie mindestens drei mögliche Gründe wann eine CPU-Scheduling Entscheidung

44.(II) Erklären Sie präzise die preemptive Priority Scheduling Strategie mit Aging.
44.(II) Erklären Sie präzise die preemptive Priority Scheduling Strategie mit Aging.

Thema 5 - Betriebsysteme
JA/NEIN Fragen + Begründung
Thema 5 - Betriebsysteme
JA/NEIN Fragen + Begründung

Betriebsysteme JA/NEIN Fragen
1. Betriebssysteme verwalten zwar den Zugriff auf die CPU;
Betriebsysteme JA/NEIN Fragen
1. Betriebssysteme verwalten zwar den Zugriff auf die CPU;

6. Jeder Thread hat seinen eigenen Befehlszähler und einen eigenen Zuständ.
Richtig-
6. Jeder Thread hat seinen eigenen Befehlszähler und einen eigenen Zuständ.
Richtig-

11. Beim CPU Scheduling kann die durchschnittliche Wartezeit dadurch minimiert werden,
11. Beim CPU Scheduling kann die durchschnittliche Wartezeit dadurch minimiert werden,

14. In interaktiven Betriebssystemen gibt es üblicherweise mehr context switches als
14. In interaktiven Betriebssystemen gibt es üblicherweise mehr context switches als
 «Компьютерные сети. Виды компьютерных сетей» Кривенцов Л.А.
«Компьютерные сети. Виды компьютерных сетей» Кривенцов Л.А.  Определение конфигурации компьютера программными средствами
Определение конфигурации компьютера программными средствами Stealth и Стелс шутеров
Stealth и Стелс шутеров Технология программирования задач с циклами
Технология программирования задач с циклами Выявление и отбор документов для публикации
Выявление и отбор документов для публикации Информатика. Основные понятия информатики (часть 2)
Информатика. Основные понятия информатики (часть 2) Программирование на языке высокого уровня. Битовые операции
Программирование на языке высокого уровня. Битовые операции Tuesday, November 4, 2014
Tuesday, November 4, 2014 Класична задача криптографії
Класична задача криптографії Защитный экран/ Классическая касса
Защитный экран/ Классическая касса Проектирование специального программного обеспечения АСУ ТП типовых дожимных насосных станций транспортировки сырой нефти
Проектирование специального программного обеспечения АСУ ТП типовых дожимных насосных станций транспортировки сырой нефти 社交媒体. Социальные сети
社交媒体. Социальные сети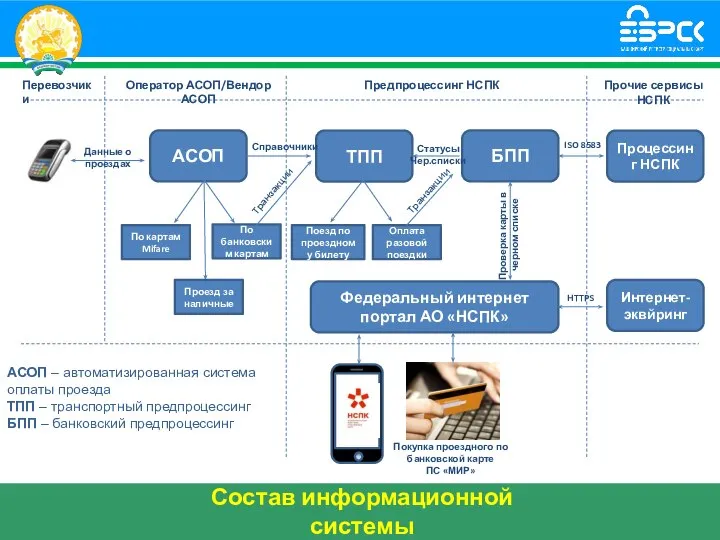 Схема транспортного предпроцессинга для НСПК
Схема транспортного предпроцессинга для НСПК Учитель информатики Трифонова Татьяна Викторовна г.Октябрьск ТЕКСТОВЫЕ РЕДАКТОРЫ И ПРОЦЕССОРЫ 10-11 кл
Учитель информатики Трифонова Татьяна Викторовна г.Октябрьск ТЕКСТОВЫЕ РЕДАКТОРЫ И ПРОЦЕССОРЫ 10-11 кл Оформление отчетов по практическим занятиям с помощью текстового редактора
Оформление отчетов по практическим занятиям с помощью текстового редактора Электронные таблицы
Электронные таблицы Разрешение имен с помощью DNS Лаштанов И.Г.
Разрешение имен с помощью DNS Лаштанов И.Г.  Логические элементы ПК. Построение функциональных схем
Логические элементы ПК. Построение функциональных схем Безопасный интернет
Безопасный интернет Програмування С++. Нелінійна обробка одновимірних масивів
Програмування С++. Нелінійна обробка одновимірних масивів Распознавание типа контента по фотографии
Распознавание типа контента по фотографии Kinder-Inter.net. Обзор образовательных сайтов для детей и их родителей
Kinder-Inter.net. Обзор образовательных сайтов для детей и их родителей Guidance for Video/Audio in PowerPoints
Guidance for Video/Audio in PowerPoints Презентация по информатике Алгоритм и его формальное исполнение
Презентация по информатике Алгоритм и его формальное исполнение  Traditional Security Issues
Traditional Security Issues Тенденции в СМИ России в 2017-2018 годах
Тенденции в СМИ России в 2017-2018 годах Устройства вывода информации
Устройства вывода информации Traffic Engineering. (Лекция 3)
Traffic Engineering. (Лекция 3)