- Введение в специальность. Введение в технологии параллельного программирования

Содержание
- 2. Введение 2 https://regnum.ru/pictures/2255436/1.html
- 3. 11 Введение в технологии параллельного программирования Понятие «Технологии параллельного программирования», история Примеры и основные области применения
- 4. Технологии параллельного программирования 12 Параллельное программирование - это техника программирования, которая использует преимущества многоядерных или многопроцессорных
- 5. История развития параллелизма 13 1941 г. - Конрад Цузе, вычислительная машина Z3, Германия
- 6. История развития параллелизма 14 1945 г. - Джон Мокли, ЭВМ ЭНИАК, США
- 7. История развития параллелизма 14 1959 г. - Анатолий Иванович Китов, ЭВМ «М-100», СССР
- 8. История развития параллелизма 15 1961 г. - IBM 7030, США
- 9. История развития параллелизма 15 1962 г. – Atlas, Манчестерский университет, Великобритания
- 10. История развития параллелизма 15 1964 г., компания Control Data Corporation, Сеймур Крэй, CDC-6600, США
- 11. История развития параллелизма 15 1976 г., компания Cray Recearch, Сеймур Крэй, CRAY 1, США
- 12. История развития параллелизма 15 1982 г., компания Cray Recearch, Сеймур Крэй, CRAY X-MP, США
- 13. История развития параллелизма 15 1996 г., компания Intel, Sandia NL, ASCI Red, США
- 14. История развития параллелизма 15 2002 г., компания NEC, Earth Simulator, Япония
- 15. История развития параллелизма 15 2009 г., IBM, Roadrunner, США
- 16. История развития параллелизма 15 2020 г., Fujitsu Limited, Fugaku, Япония
- 17. 15 https://www.top500.org/
- 18. 15 Рейтинг суперкомпьютеров СНГ http://top50.supercomputers.ru/list
- 19. Примеры и основные области применения технологий параллельного программирования
- 20. Научные исследования в области естественных наук Физика плазмы Квантовая химия Астрофизика Атомная физика Физика конденсированных сред
- 21. Примеры приложений: Науки о Земле Анализ изменений климата Прогнозирование погоды Состояние атмосферы
- 22. Примеры приложений: Науки о жизни Новые лекарства и методы лечения Геномика Поиск в базах данных
- 23. Инженерные расчёты Виртуальное проектирование Оптимизация
- 24. ВПК Обработка снимков Проектирование экзосклетов Роботов Расшифровка информации Модернизация и разработка техники
- 25. Финансовый сектор Автоматизированное принятие решений Сервисы на основе ИИ Оценка и управление рисками Предиктивная аналитика
- 26. Проблемы технологий параллельного программирования
- 27. 16
- 28. 16 http://www.invertedalchemy.com/2017/05/
- 29. TSMC – техпроцессор - 5-нм
- 30. Основные архитектурные особенности построения параллельной вычислительной среды
- 31. Общие проблемы https://musicseasons.org/wp-content/uploads/MG_6427.jpg
- 32. Архитектура многопроцессорных систем с общей памятью Мультипроцессоры
- 33. Архитектура многопроцессорных систем с распределенной памятью Мультикомпьютеры https://parallel.ru/computers/taxonomy/
- 34. ПЛЮСЫ И МИНУСЫ РАЗЛИЧНЫХ АРХИТЕКТУР Привычная модель программирования за счет единого адресного пространства Высокая скорость и
- 35. Классификация М. Флинна, 1966 г.
- 36. Классификация М. Флинна, 1966 г.
- 37. Основные подклассы - Векторно-конвейерные - Массово-параллельные - Симметричные мультипроцессоры (SMP) - Кластеры
- 38. Основные классы современных параллельных ЭВМ Параллельные векторные системы
- 39. Основные классы современных параллельных ЭВМ Массивно-параллельные системы (MPP)
- 40. Основные классы современных параллельных ЭВМ Симметричные мультипроцессорные системы (SMP)
- 41. Основные классы современных параллельных ЭВМ Кластерные системы
- 42. Основные классы современных параллельных ЭВМ Grid (вычислительная сеть)
- 43. Основные классы современных параллельных ЭВМ Графические процессоры (GPU)
- 44. Основные классы современных параллельных ЭВМ Системы с неоднородным доступом к памяти (NUMA)
- 45. Основные классы современных параллельных ЭВМ Набор персональных компьютеров
- 46. Основные классы современных параллельных ЭВМ - Компьютеры с распределенной памятью с двухуровневой архитектурой; - Гибридные метакластерные
- 47. Систематизация MIMD-компьютеров по Р. Хокни
- 48. Топологии соединения вычислительных узлов в высокопроизводительных вычислительных системах* *Параллельное программирование с использованием OpenMP: учебное пособие /
- 49. классификация Т. Фенга Основана на двух характеристиках: число n бит в машинном слове, обрабатываемых параллельно; число
- 50. классификация Т. Фенга - разрядно-последовательные, пословно-последовательные (n=1, m=1); - разрядно-параллельные, пословно-последовательные (n>1, m=1); - разрядно-последовательные, пословно-параллельные
- 51. классификация В. Хендлера Три уровня обработки данных: - уровень выполнения программы; - уровень выполнения команд; -
- 52. классификация В. Хендлера k - число процессоров; k’ - глубина макроконвейера; d - число АЛУ в
- 53. классификации Д. Скилликорна - процессор команд (IP – Instruction Procesor) – интерпретатор команд; - процессор данных
- 54. классификации Д. Скилликорна четыре типа переключателей: - 1–1 – связывает пару функциональных устройств; - n–n –
- 55. Анализ производительности и эффективности параллельных вычислений
- 56. Способы параллельной обработки данных: параллелизм конвейерность
- 57. Свойства параллельных вычислений Ускорение T1 ‑ время выполнения программы одним процессором Tp ‑ время выполнения программы
- 58. Закон Амдала q – доля последовательных вычислений в применяемом алгоритме обработки данных, p – число процессоров
- 59. ПОКАЗАТЕЛИ ЭФФЕКТИВНОСТИ ПАРАЛЛЕЛЬНЫХ АЛГОРИТМОВ
- 60. Закон Густафсона-Барсиса где α - доля последовательных расчётов в программе, n- количество процессоров.
- 61. Параллельный алгоритм называют масштабируемым (scalable), если при росте числа процессоров он обеспечивает увеличение ускорения при сохранении
- 62. Принципы разработки параллельных алгоритмов (parallel computing) 1
- 63. Классификация алгоритмов по типу параллелизма Алгоритмы, использующие параллелизм данных (Data Parallelism). Алгоритмы с распределением данных (Data
- 64. РАЗРАБОТКА ПАРАЛЛЕЛЬНОГО АЛГОРИТМА Ключевые шаги разработки параллельного алгоритма: Поиск параллелизма в известном последовательном алгоритме, его модификация
- 65. Общая схема взаимосвязи этапов разработки параллельных алгоритмов
- 66. Специфические задачи реализации параллельного алгоритма в виде параллельной программы: Распределение подзадач между процессорами (task mapping, load
- 67. ПОДХОДЫ К ДЕКОМПОЗИЦИИ НА ПОДЗАДАЧИ Есть два основных подхода к декомпозиции задач на параллелизуемые подзадачи: Функциональная
- 68. СПОСОБЫ ДЕКОМПОЗИЦИИ Конвейерная обработка данных
- 69. СПОСОБЫ ДЕКОМПОЗИЦИИ Рекурсивный параллелизм (разделяй и властвуй)
- 70. СПОСОБЫ ДЕКОМПОЗИЦИИ Геометрическая декомпозиция
- 71. МОДЕЛИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ Разделяемая память (shared memory): Аналогия - доска объявлений Подзадачи используют общее адресное пространство
- 72. МОДЕЛИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ Передача сообщений (message passing): Аналогия – отправка писем с явным указанием отправителя и
- 73. МОДЕЛИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ Параллельная обработка данных (data parallelization): Строго описанные глобальные операции над данными (может обозначаеться
- 74. ПРОЦЕССЫ И ПОТОКИ
- 75. МНОГОПОТОЧНЫЕ ПРИЛОЖЕНИЯ Сценарий работы многопоточного приложения: Сначала инициализируется стартовый поток процесса, выполняет загрузку необходимых ресурсов Стартовый
- 76. ПОДЗАДАЧИ И ПОТОКИ Задача (подзадача) состоит из данных и процедуры их обработки Планировщик задач назначает задачу
- 77. ПРОБЛЕМЫ СИНХРОНИЗАЦИИ Взаимная блокировка (deadlock) – ситуация в многозадачной среде при которой несколько потоков находятся в
- 78. МОДЕЛЬ П/П НА ОСНОВЕ ПЕРЕДАЧИ СООБЩЕНИЙ Основные характеристики модели на основе передачи сообщений: Набор задач, имеющих
- 79. МОДЕЛЬ П/П НА ОСНОВЕ ПЕРЕДАЧИ СООБЩЕНИЙ Программирование для модели на основе передачи сообщений: С точки зрения
- 80. ПРИМЕР ПЕРЕДАЧИ СООБЩЕНИЯ
- 81. МОДЕЛЬ П/П – ПАРАЛЛЕЛЬНАЯ ОБРАБОТКА ДАННЫХ Programming with the data parallel model is usually accomplished by
- 82. МОДЕЛЬ П/П – ПАРАЛЛЕЛЬНАЯ ОБРАБОТКА ДАННЫХ Programming with the data parallel model is usually accomplished by
- 83. ИСТОЧНИКИ И РЕСУРСЫ Ресурсы для самоподготовки: 1. Малявко, А. А. Параллельное программирование на основе технологий openmp,
- 85. Скачать презентацию

Введение
2
https://regnum.ru/pictures/2255436/1.html
Введение
2
https://regnum.ru/pictures/2255436/1.html

11
Введение в технологии параллельного программирования
Понятие «Технологии параллельного программирования», история
Примеры
11
Введение в технологии параллельного программирования
Понятие «Технологии параллельного программирования», история
Примеры

Технологии параллельного программирования
12
Параллельное программирование - это техника программирования, которая использует преимущества многоядерных
Технологии параллельного программирования
12
Параллельное программирование - это техника программирования, которая использует преимущества многоядерных

История развития параллелизма
13
1941 г. - Конрад Цузе, вычислительная машина Z3, Германия
История развития параллелизма
13
1941 г. - Конрад Цузе, вычислительная машина Z3, Германия

История развития параллелизма
14
1945 г. - Джон Мокли, ЭВМ ЭНИАК, США
История развития параллелизма
14
1945 г. - Джон Мокли, ЭВМ ЭНИАК, США

История развития параллелизма
14
1959 г. - Анатолий Иванович Китов, ЭВМ «М-100», СССР
История развития параллелизма
14
1959 г. - Анатолий Иванович Китов, ЭВМ «М-100», СССР

История развития параллелизма
15
1961 г. - IBM 7030, США
История развития параллелизма
15
1961 г. - IBM 7030, США

История развития параллелизма
15
1962 г. – Atlas, Манчестерский университет, Великобритания
История развития параллелизма
15
1962 г. – Atlas, Манчестерский университет, Великобритания

История развития параллелизма
15
1964 г., компания Control Data Corporation, Сеймур Крэй, CDC-6600,
История развития параллелизма
15
1964 г., компания Control Data Corporation, Сеймур Крэй, CDC-6600,

История развития параллелизма
15
1976 г., компания Cray Recearch, Сеймур Крэй, CRAY 1,
История развития параллелизма
15
1976 г., компания Cray Recearch, Сеймур Крэй, CRAY 1,

История развития параллелизма
15
1982 г., компания Cray Recearch, Сеймур Крэй, CRAY X-MP,
История развития параллелизма
15
1982 г., компания Cray Recearch, Сеймур Крэй, CRAY X-MP,
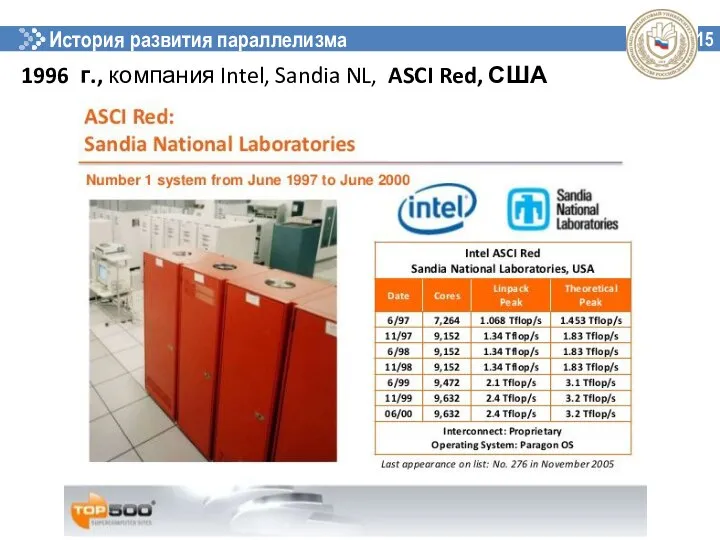
История развития параллелизма
15
1996 г., компания Intel, Sandia NL, ASCI Red, США
История развития параллелизма
15
1996 г., компания Intel, Sandia NL, ASCI Red, США

История развития параллелизма
15
2002 г., компания NEC, Earth Simulator, Япония
История развития параллелизма
15
2002 г., компания NEC, Earth Simulator, Япония

История развития параллелизма
15
2009 г., IBM, Roadrunner, США
История развития параллелизма
15
2009 г., IBM, Roadrunner, США

История развития параллелизма
15
2020 г., Fujitsu Limited, Fugaku, Япония
История развития параллелизма
15
2020 г., Fujitsu Limited, Fugaku, Япония
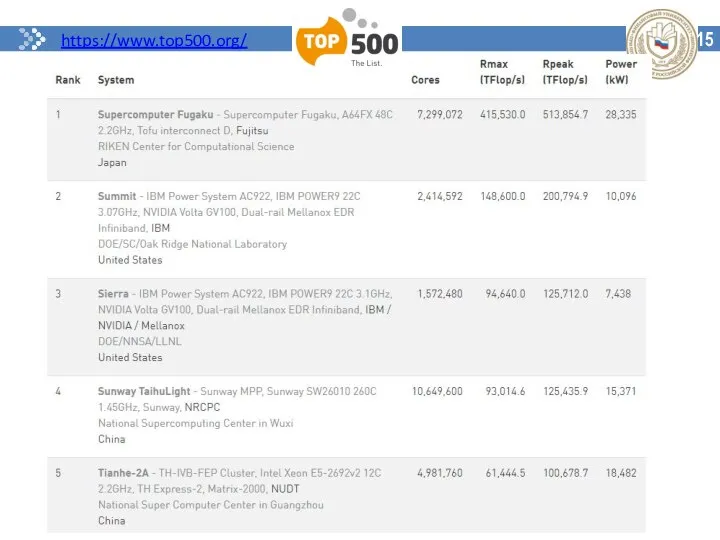
15
https://www.top500.org/
15
https://www.top500.org/
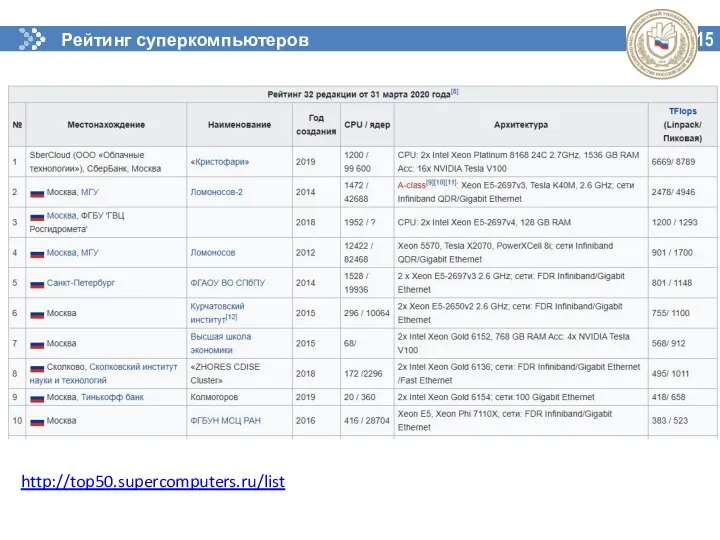
15
Рейтинг суперкомпьютеров СНГ
http://top50.supercomputers.ru/list
15
Рейтинг суперкомпьютеров СНГ
http://top50.supercomputers.ru/list

Примеры и основные области применения технологий параллельного программирования
Примеры и основные области применения технологий параллельного программирования

Научные исследования в области естественных наук
Физика плазмы
Квантовая химия
Астрофизика
Атомная физика
Физика конденсированных сред
Молекулярная
Научные исследования в области естественных наук
Физика плазмы
Квантовая химия
Астрофизика
Атомная физика
Физика конденсированных сред
Молекулярная

Примеры приложений: Науки о Земле
Анализ изменений климата
Прогнозирование погоды
Состояние
атмосферы
Примеры приложений: Науки о Земле
Анализ изменений климата
Прогнозирование погоды
Состояние
атмосферы
Примеры приложений: Науки о жизни
Новые лекарства и методы лечения
Геномика
Поиск в базах
Примеры приложений: Науки о жизни
Новые лекарства и методы лечения
Геномика
Поиск в базах
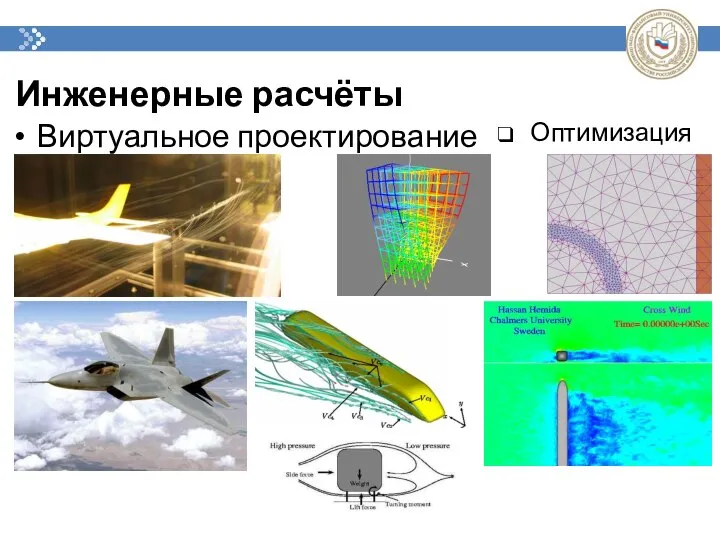
Инженерные расчёты
Виртуальное проектирование
Оптимизация
Инженерные расчёты
Виртуальное проектирование
Оптимизация

ВПК
Обработка снимков
Проектирование экзосклетов
Роботов
Расшифровка информации
Модернизация и разработка техники
ВПК
Обработка снимков
Проектирование экзосклетов
Роботов
Расшифровка информации
Модернизация и разработка техники

Финансовый сектор
Автоматизированное принятие решений
Сервисы на основе ИИ
Оценка и управление
Финансовый сектор
Автоматизированное принятие решений
Сервисы на основе ИИ
Оценка и управление

Проблемы технологий параллельного программирования
Проблемы технологий параллельного программирования
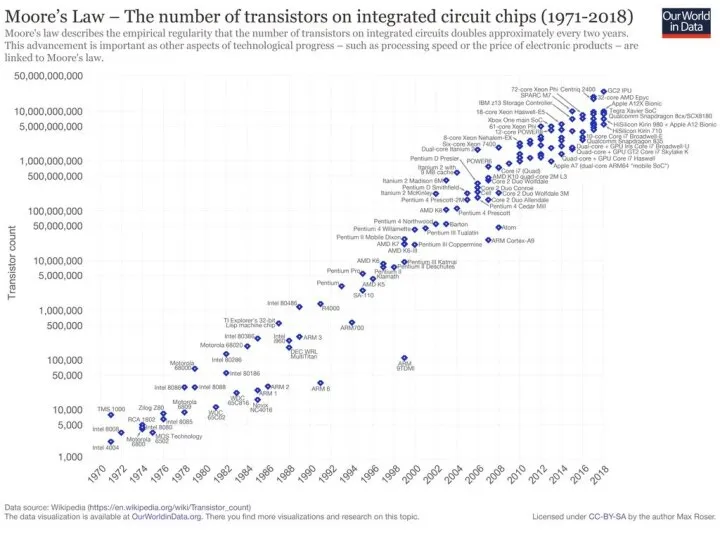
16
16

16
http://www.invertedalchemy.com/2017/05/
16
http://www.invertedalchemy.com/2017/05/

TSMC – техпроцессор - 5-нм
TSMC – техпроцессор - 5-нм

Основные архитектурные особенности построения параллельной вычислительной среды
Основные архитектурные особенности построения параллельной вычислительной среды

Общие проблемы
https://musicseasons.org/wp-content/uploads/MG_6427.jpg
Общие проблемы
https://musicseasons.org/wp-content/uploads/MG_6427.jpg
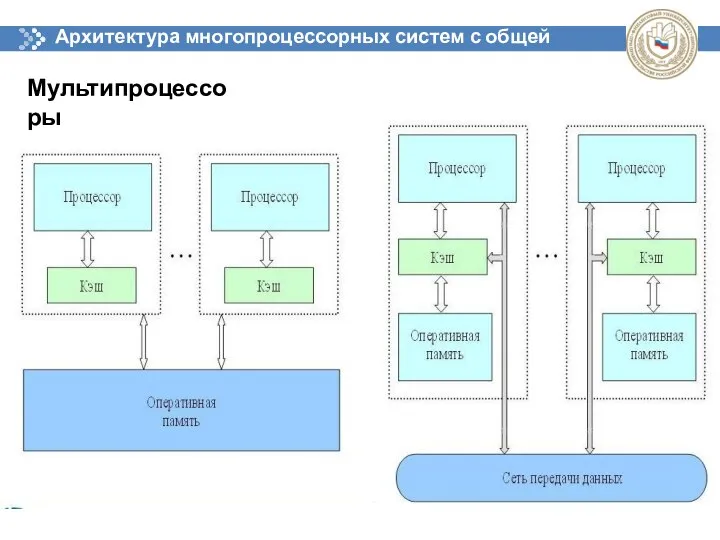
Архитектура многопроцессорных систем с общей памятью
Мультипроцессоры
Архитектура многопроцессорных систем с общей памятью
Мультипроцессоры
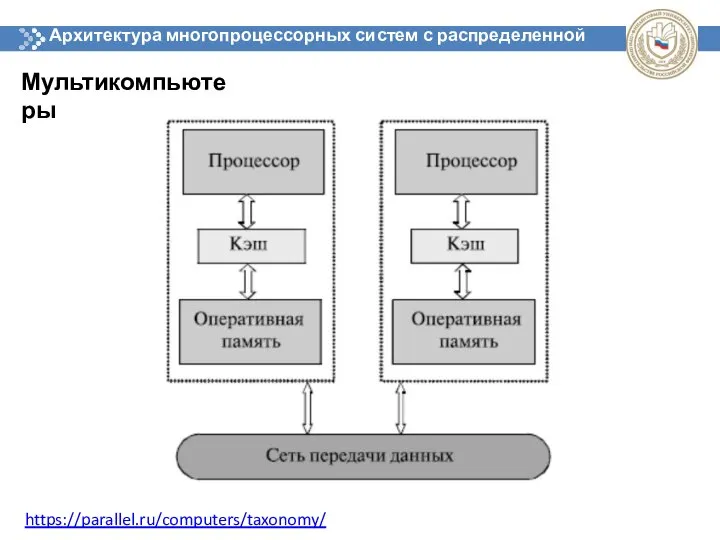
Архитектура многопроцессорных систем с распределенной памятью
Мультикомпьютеры
https://parallel.ru/computers/taxonomy/
Архитектура многопроцессорных систем с распределенной памятью
Мультикомпьютеры
https://parallel.ru/computers/taxonomy/

ПЛЮСЫ И МИНУСЫ РАЗЛИЧНЫХ АРХИТЕКТУР
Привычная модель программирования за счет единого адресного
ПЛЮСЫ И МИНУСЫ РАЗЛИЧНЫХ АРХИТЕКТУР
Привычная модель программирования за счет единого адресного
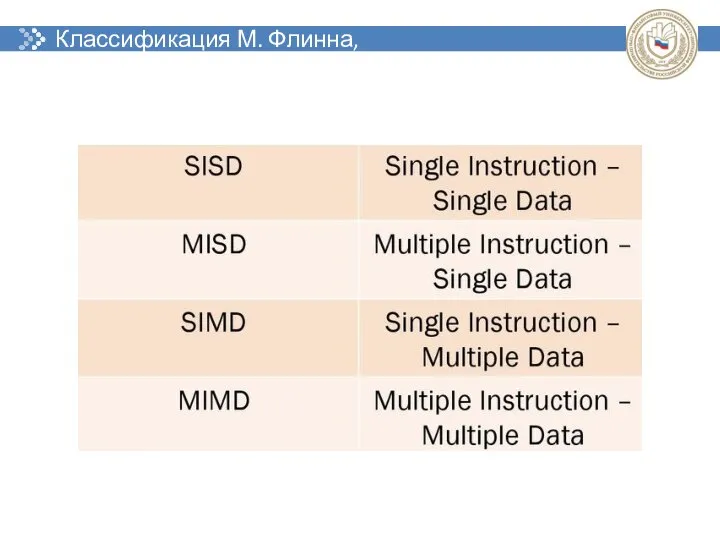
Классификация М. Флинна, 1966 г.
Классификация М. Флинна, 1966 г.
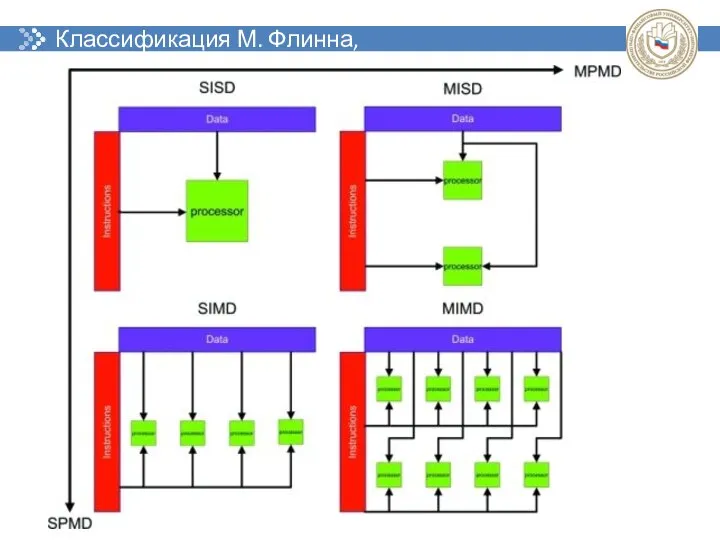
Классификация М. Флинна, 1966 г.
Классификация М. Флинна, 1966 г.

Основные подклассы
- Векторно-конвейерные
- Массово-параллельные
- Симметричные мультипроцессоры (SMP)
- Кластеры
Основные подклассы
- Векторно-конвейерные
- Массово-параллельные
- Симметричные мультипроцессоры (SMP)
- Кластеры

Основные классы современных параллельных ЭВМ
Параллельные векторные системы
Основные классы современных параллельных ЭВМ
Параллельные векторные системы

Основные классы современных параллельных ЭВМ
Массивно-параллельные системы (MPP)
Основные классы современных параллельных ЭВМ
Массивно-параллельные системы (MPP)

Основные классы современных параллельных ЭВМ
Симметричные мультипроцессорные системы (SMP)
Основные классы современных параллельных ЭВМ
Симметричные мультипроцессорные системы (SMP)

Основные классы современных параллельных ЭВМ
Кластерные системы
Основные классы современных параллельных ЭВМ
Кластерные системы

Основные классы современных параллельных ЭВМ
Grid (вычислительная сеть)
Основные классы современных параллельных ЭВМ
Grid (вычислительная сеть)

Основные классы современных параллельных ЭВМ
Графические процессоры (GPU)
Основные классы современных параллельных ЭВМ
Графические процессоры (GPU)
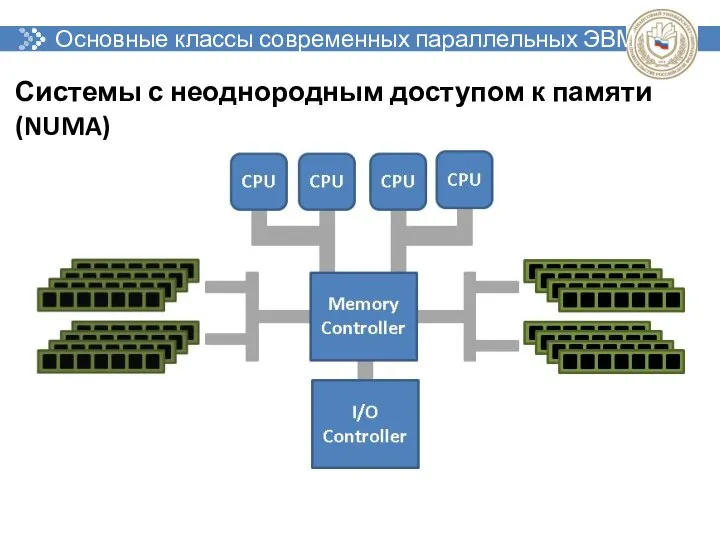
Основные классы современных параллельных ЭВМ
Системы с неоднородным доступом к памяти (NUMA)
Основные классы современных параллельных ЭВМ
Системы с неоднородным доступом к памяти (NUMA)

Основные классы современных параллельных ЭВМ
Набор персональных компьютеров
Основные классы современных параллельных ЭВМ
Набор персональных компьютеров

Основные классы современных параллельных ЭВМ
- Компьютеры с распределенной памятью с двухуровневой
Основные классы современных параллельных ЭВМ
- Компьютеры с распределенной памятью с двухуровневой
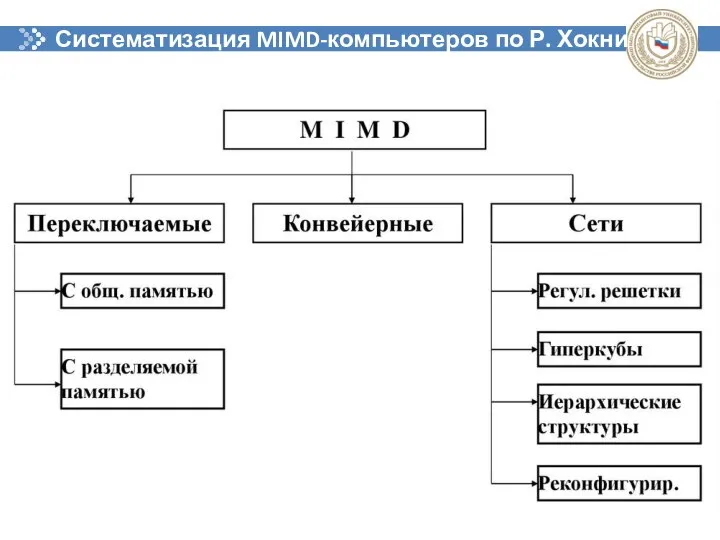
Систематизация MIMD-компьютеров по Р. Хокни
Систематизация MIMD-компьютеров по Р. Хокни
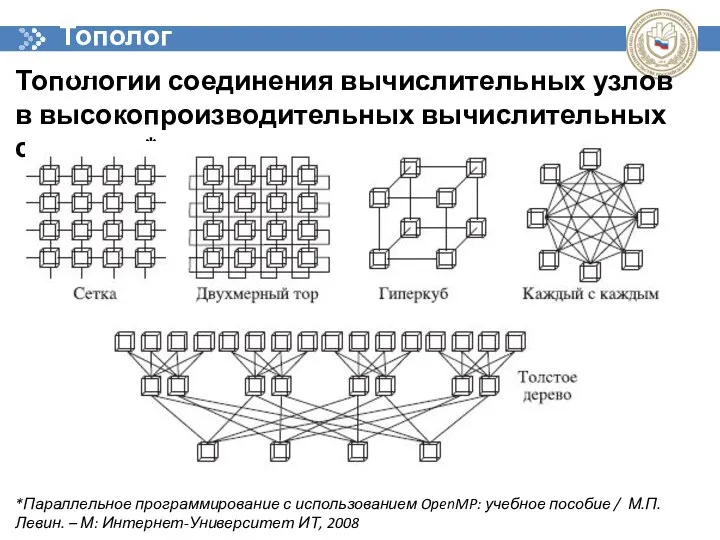
Топологии соединения вычислительных узлов в высокопроизводительных вычислительных системах*
*Параллельное программирование с использованием
Топологии соединения вычислительных узлов в высокопроизводительных вычислительных системах*
*Параллельное программирование с использованием

классификация Т. Фенга
Основана на двух характеристиках:
число n бит в машинном
классификация Т. Фенга
Основана на двух характеристиках:
число n бит в машинном

классификация Т. Фенга
- разрядно-последовательные, пословно-последовательные (n=1, m=1);
- разрядно-параллельные, пословно-последовательные (n>1, m=1);
-
классификация Т. Фенга
- разрядно-последовательные, пословно-последовательные (n=1, m=1);
- разрядно-параллельные, пословно-последовательные (n>1, m=1);
-

классификация В. Хендлера
Три уровня обработки данных:
- уровень выполнения
классификация В. Хендлера
Три уровня обработки данных:
- уровень выполнения

классификация В. Хендлера
k - число процессоров;
k’ - глубина макроконвейера;
d -
классификация В. Хендлера
k - число процессоров;
k’ - глубина макроконвейера;
d -

классификации Д. Скилликорна
- процессор команд (IP – Instruction Procesor) – интерпретатор
классификации Д. Скилликорна
- процессор команд (IP – Instruction Procesor) – интерпретатор

классификации Д. Скилликорна
четыре типа переключателей:
- 1–1 – связывает пару функциональных устройств;
-
классификации Д. Скилликорна
четыре типа переключателей:
- 1–1 – связывает пару функциональных устройств;
-

Анализ производительности и эффективности параллельных вычислений
Анализ производительности и эффективности параллельных вычислений

Способы параллельной обработки данных:
параллелизм
конвейерность
Способы параллельной обработки данных:
параллелизм
конвейерность

Свойства параллельных вычислений
Ускорение
T1 ‑ время выполнения программы одним процессором
Tp ‑ время
Свойства параллельных вычислений
Ускорение
T1 ‑ время выполнения программы одним процессором
Tp ‑ время

Закон Амдала
q – доля последовательных вычислений в применяемом алгоритме обработки данных,
Закон Амдала
q – доля последовательных вычислений в применяемом алгоритме обработки данных,
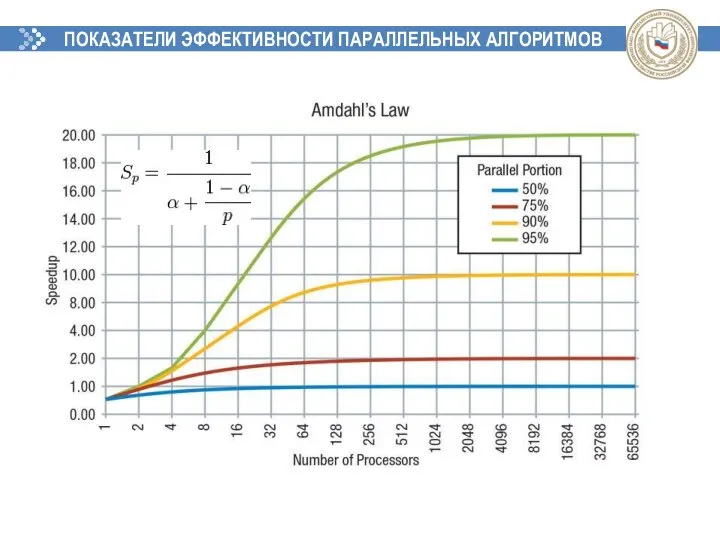
ПОКАЗАТЕЛИ ЭФФЕКТИВНОСТИ ПАРАЛЛЕЛЬНЫХ АЛГОРИТМОВ
ПОКАЗАТЕЛИ ЭФФЕКТИВНОСТИ ПАРАЛЛЕЛЬНЫХ АЛГОРИТМОВ

Закон Густафсона-Барсиса
где α - доля последовательных расчётов в программе, n- количество
Закон Густафсона-Барсиса
где α - доля последовательных расчётов в программе, n- количество

Параллельный алгоритм называют масштабируемым (scalable), если при росте числа процессоров он обеспечивает увеличение
Параллельный алгоритм называют масштабируемым (scalable), если при росте числа процессоров он обеспечивает увеличение

Принципы разработки параллельных алгоритмов
(parallel computing)
1
Принципы разработки параллельных алгоритмов
(parallel computing)
1

Классификация алгоритмов по типу параллелизма
Алгоритмы, использующие параллелизм данных (Data Parallelism).
Алгоритмы
Классификация алгоритмов по типу параллелизма
Алгоритмы, использующие параллелизм данных (Data Parallelism).
Алгоритмы

РАЗРАБОТКА ПАРАЛЛЕЛЬНОГО АЛГОРИТМА
Ключевые шаги разработки параллельного алгоритма:
Поиск параллелизма в известном последовательном
РАЗРАБОТКА ПАРАЛЛЕЛЬНОГО АЛГОРИТМА
Ключевые шаги разработки параллельного алгоритма:
Поиск параллелизма в известном последовательном
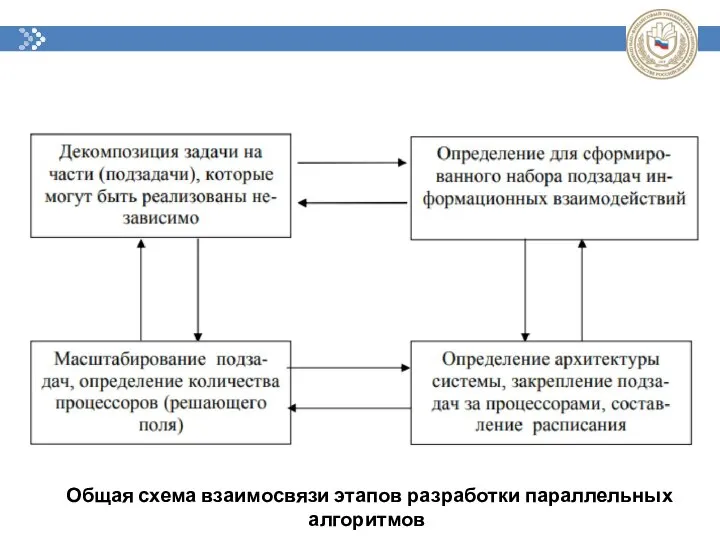
Общая схема взаимосвязи этапов разработки параллельных алгоритмов
Общая схема взаимосвязи этапов разработки параллельных алгоритмов

Специфические задачи реализации параллельного алгоритма в виде параллельной программы:
Распределение подзадач между
Распределение подзадач между
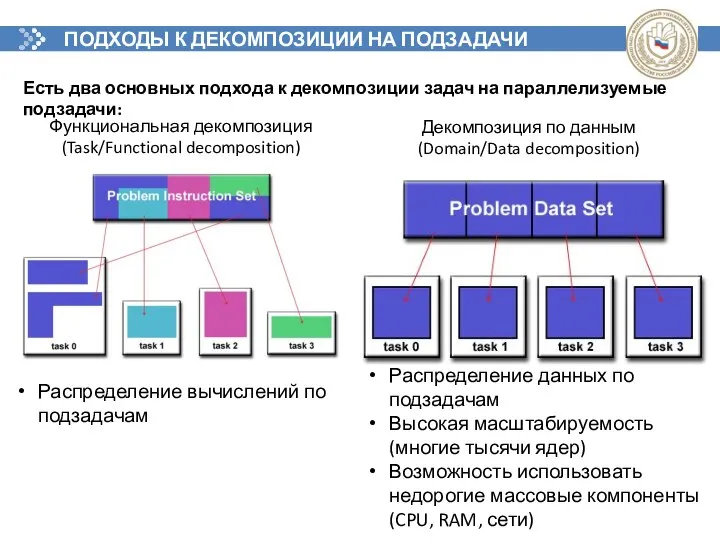
ПОДХОДЫ К ДЕКОМПОЗИЦИИ НА ПОДЗАДАЧИ
Есть два основных подхода к декомпозиции задач
ПОДХОДЫ К ДЕКОМПОЗИЦИИ НА ПОДЗАДАЧИ
Есть два основных подхода к декомпозиции задач
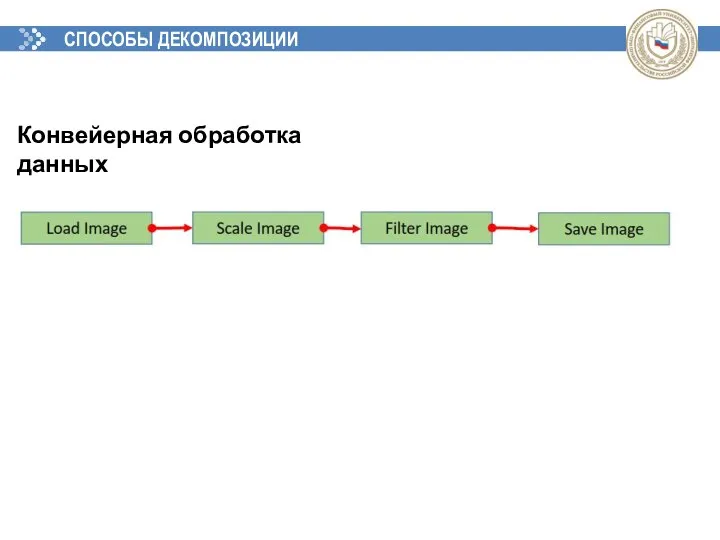
СПОСОБЫ ДЕКОМПОЗИЦИИ
Конвейерная обработка данных
СПОСОБЫ ДЕКОМПОЗИЦИИ
Конвейерная обработка данных
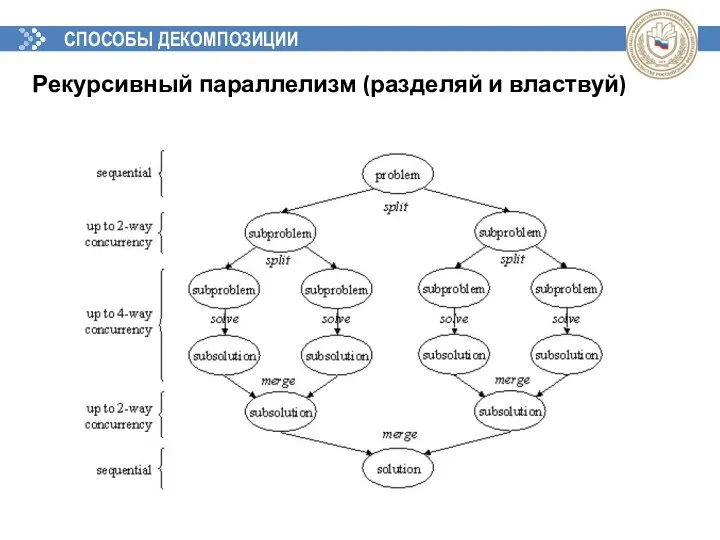
СПОСОБЫ ДЕКОМПОЗИЦИИ
Рекурсивный параллелизм (разделяй и властвуй)
СПОСОБЫ ДЕКОМПОЗИЦИИ
Рекурсивный параллелизм (разделяй и властвуй)
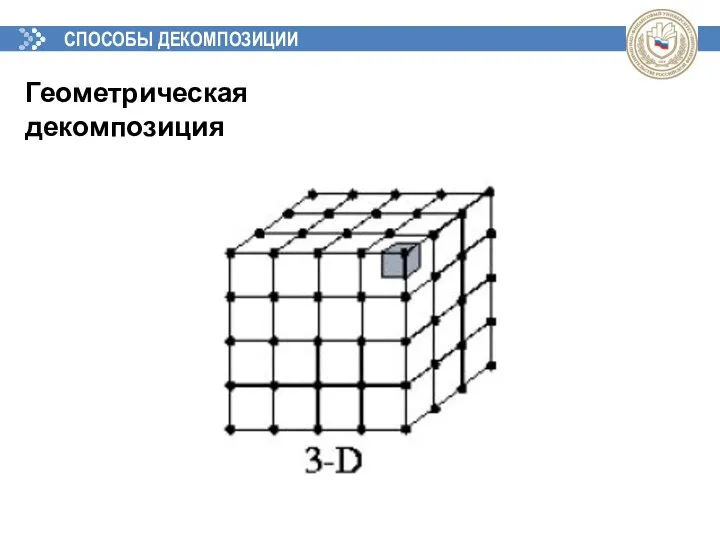
СПОСОБЫ ДЕКОМПОЗИЦИИ
Геометрическая декомпозиция
СПОСОБЫ ДЕКОМПОЗИЦИИ
Геометрическая декомпозиция

МОДЕЛИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
Разделяемая память (shared memory):
Аналогия - доска объявлений
Подзадачи используют
МОДЕЛИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
Разделяемая память (shared memory):
Аналогия - доска объявлений
Подзадачи используют

МОДЕЛИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
Передача сообщений (message passing):
Аналогия – отправка писем с
МОДЕЛИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
Передача сообщений (message passing):
Аналогия – отправка писем с

МОДЕЛИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
Параллельная обработка данных (data parallelization):
Строго описанные глобальные операции над
МОДЕЛИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
Параллельная обработка данных (data parallelization):
Строго описанные глобальные операции над
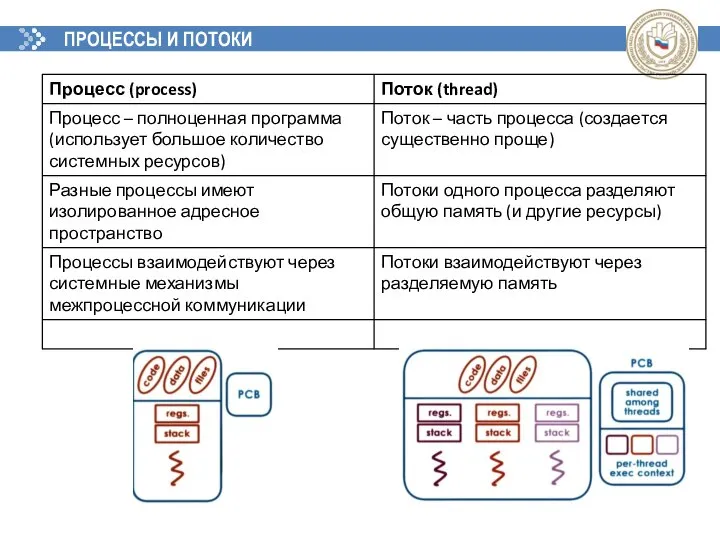
ПРОЦЕССЫ И ПОТОКИ
ПРОЦЕССЫ И ПОТОКИ
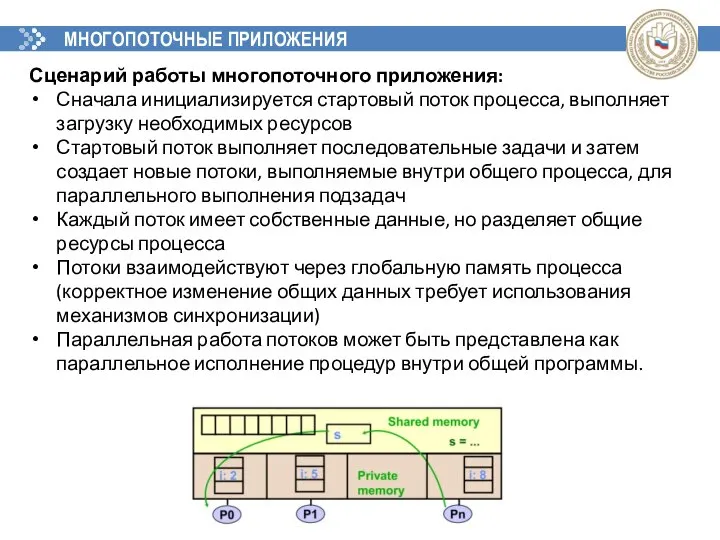
МНОГОПОТОЧНЫЕ ПРИЛОЖЕНИЯ
Сценарий работы многопоточного приложения:
Сначала инициализируется стартовый поток процесса, выполняет
МНОГОПОТОЧНЫЕ ПРИЛОЖЕНИЯ
Сценарий работы многопоточного приложения:
Сначала инициализируется стартовый поток процесса, выполняет
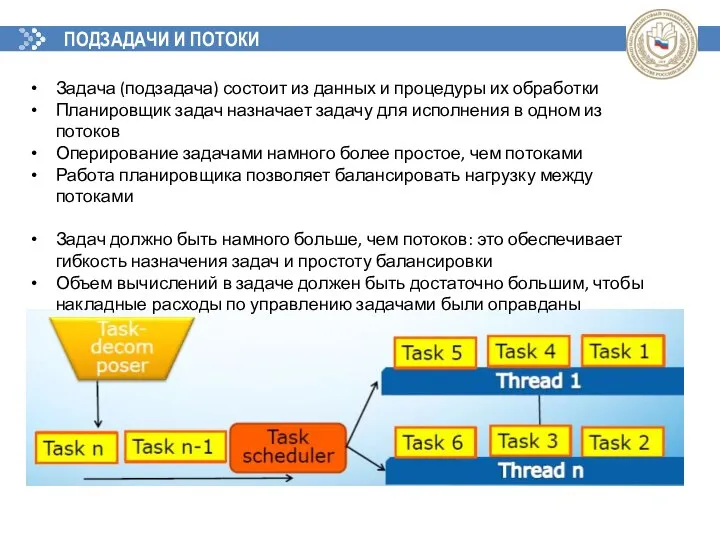
ПОДЗАДАЧИ И ПОТОКИ
Задача (подзадача) состоит из данных и процедуры их обработки
Планировщик
ПОДЗАДАЧИ И ПОТОКИ
Задача (подзадача) состоит из данных и процедуры их обработки
Планировщик

ПРОБЛЕМЫ СИНХРОНИЗАЦИИ
Взаимная блокировка (deadlock) – ситуация в многозадачной среде при которой
ПРОБЛЕМЫ СИНХРОНИЗАЦИИ
Взаимная блокировка (deadlock) – ситуация в многозадачной среде при которой

МОДЕЛЬ П/П НА ОСНОВЕ ПЕРЕДАЧИ СООБЩЕНИЙ
Основные характеристики модели на основе передачи
МОДЕЛЬ П/П НА ОСНОВЕ ПЕРЕДАЧИ СООБЩЕНИЙ
Основные характеристики модели на основе передачи

МОДЕЛЬ П/П НА ОСНОВЕ ПЕРЕДАЧИ СООБЩЕНИЙ
Программирование для модели на основе передачи
МОДЕЛЬ П/П НА ОСНОВЕ ПЕРЕДАЧИ СООБЩЕНИЙ
Программирование для модели на основе передачи
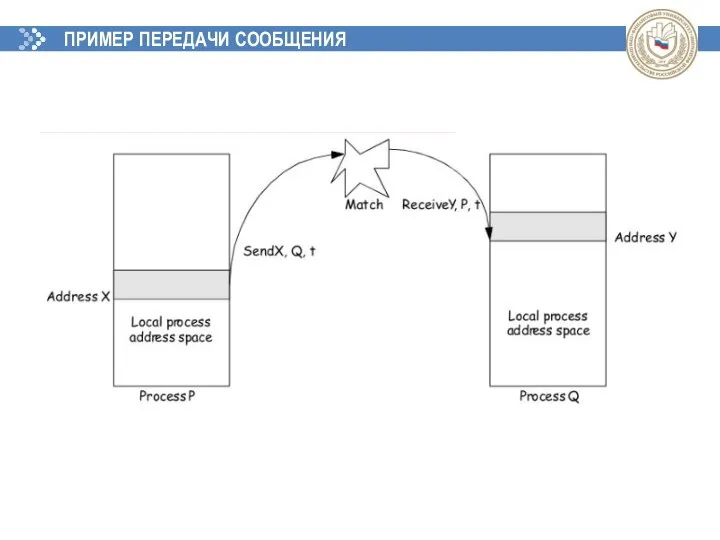
ПРИМЕР ПЕРЕДАЧИ СООБЩЕНИЯ
ПРИМЕР ПЕРЕДАЧИ СООБЩЕНИЯ

МОДЕЛЬ П/П – ПАРАЛЛЕЛЬНАЯ ОБРАБОТКА ДАННЫХ
Programming with the data parallel model
МОДЕЛЬ П/П – ПАРАЛЛЕЛЬНАЯ ОБРАБОТКА ДАННЫХ
Programming with the data parallel model

МОДЕЛЬ П/П – ПАРАЛЛЕЛЬНАЯ ОБРАБОТКА ДАННЫХ
Programming with the data parallel model
МОДЕЛЬ П/П – ПАРАЛЛЕЛЬНАЯ ОБРАБОТКА ДАННЫХ
Programming with the data parallel model

ИСТОЧНИКИ И РЕСУРСЫ
Ресурсы для самоподготовки:
1. Малявко, А. А. Параллельное программирование на
ИСТОЧНИКИ И РЕСУРСЫ
Ресурсы для самоподготовки:
1. Малявко, А. А. Параллельное программирование на
 Разработка линейных алгоритмов
Разработка линейных алгоритмов Виды искусственного интеллекта
Виды искусственного интеллекта Электронная книжная выставка о спорте
Электронная книжная выставка о спорте Алгоритм Информатика 2 класс Учитель МОУ «СОШ №56» г. Новокузнецк Муравьева Марина Игоревна
Алгоритм Информатика 2 класс Учитель МОУ «СОШ №56» г. Новокузнецк Муравьева Марина Игоревна Отчет по итогам мониторинга сайтов общественных палат субъектов Российской Федерации
Отчет по итогам мониторинга сайтов общественных палат субъектов Российской Федерации Mask R-CNN: извлечение данных из паспортов
Mask R-CNN: извлечение данных из паспортов Типы алгоритмов
Типы алгоритмов Новый элемент цифровой экономики. ЭР-телеком холдинг
Новый элемент цифровой экономики. ЭР-телеком холдинг В поисках сокровищ
В поисках сокровищ Обзорная программа на Ассемблере
Обзорная программа на Ассемблере Моделирование и формализация баз данных
Моделирование и формализация баз данных мультимедиа Microsoft PowerPoint
мультимедиа Microsoft PowerPoint  Структура книги
Структура книги Сегменты электронной коммерции и их особенности
Сегменты электронной коммерции и их особенности Текстовые и табличные документы. Работа с базами данных. Компьютерная графика
Текстовые и табличные документы. Работа с базами данных. Компьютерная графика Содержательный подход к измерению информации
Содержательный подход к измерению информации Новые архитектуры высокопроизводительной и отказоустойчивой обработки распределенных данных
Новые архитектуры высокопроизводительной и отказоустойчивой обработки распределенных данных Решение задания В15 (системы логических уравнений)
Решение задания В15 (системы логических уравнений) Монетизация. Вводный каст. РСЯ-Марафон. (Занятие 9)
Монетизация. Вводный каст. РСЯ-Марафон. (Занятие 9) Средства массовой информации (СМИ)
Средства массовой информации (СМИ) Информатизация образования
Информатизация образования Подготовка данных. Цифровая 3D-медицина
Подготовка данных. Цифровая 3D-медицина Форматирование многостраничного документа
Форматирование многостраничного документа Основные возможности, характеристики и особенности системы
Основные возможности, характеристики и особенности системы Як ми виграли комп‘ютер. Гра-тест
Як ми виграли комп‘ютер. Гра-тест Презентация "Инструкция по созданию Поля чудес" - скачать презентации по Информатике
Презентация "Инструкция по созданию Поля чудес" - скачать презентации по Информатике Использование Python для работы с JSON
Использование Python для работы с JSON ТЕКСТОВЫЙ РЕДАКТОР. Тест.
ТЕКСТОВЫЙ РЕДАКТОР. Тест.