- Основные понятия математической статистики

Содержание
- 2. Основные понятия математической статистики. Математическая статистика – это раздел математики о методах регистрации, систематизации и анализа
- 3. Генеральная совокупность – это совокупность всех объектов, которые имеют типичную характеристику или признак. Это все возможные
- 4. Основные задачи, которые стоят перед математической статистикой: 1. Определение закона распределения случайной величины по имеющимся статистическим
- 5. Схема предварительной обработки экспериментальных данных. 1) Сбор экспериментальных данных. Чтобы определить закон распределения случайной величины, нужно
- 6. Пример: При измерении частоты пульса у 10 пациентов получены следующие результаты: 90, 110, 65, 80, 90,
- 7. Схема предварительной обработки экспериментальных данных. 2) Составление вариационного ряда. вариационный ряд (статистическое распределение) -- набор пар
- 8. Графическое представление дискретного вариационного ряда - это полигон частот: х
- 9. Если признак изменяется непрерывно, то составляется интервальный вариационный ряд: набор пар вид интервал – частота. Для
- 10. Пример. Анализ веса 60-ти новорожденных дал следующие результаты: min вес 1,5 кг, max вес 5 кг.
- 11. Графическая характеристика непрерывного вариационного ряда - Гистограмма:
- 12. Закономерности распределения генеральной совокупности оцениваются по выборочной совокупности. При увеличении объёма выборки (n→∞), относительные частоты стремятся
- 13. Характеристики генеральной совокупности Математическое ожидание M[X] дисперсия D[X] среднее квадратическое отклонение σ[X] Характеристики выборки (статистики) -
- 14. Генеральная совокупность (n→∞) Выборка (n- конечно) ν=n-1 число степеней свободы Sn-стандартное отклонение
- 15. Извлечём из генеральной совокупности N выборок, тогда их средние арифметические сами будут являться значениями случайной величины
- 16. показывает насколько выборочное среднее арифметическое близко к матожиданию М[X] генеральной совокупности. Чем больше объём выборки n,
- 17. Истинные значения М[X] и D[X] можно найти по генеральной совокупности, что практически невозможно. По выборке из
- 18. Если известна функция распределения, то этот интервал можно найти из соотношения: зная границы интервала, можно найти
- 19. Доверительным интервалом какого либо параметра, называют такой интервал, о котором можно сказать, что с вероятностью РД
- 20. Основная масса случайных величин в биологии и медицине распределена по нормальному закону распределения, следовательно, задав доверительную
- 21. Где стандартное отклонение для случайной величины Но для малых выборок (n В 1908 г английский математик
- 22. Нормированная случайная величина вычисляется по формуле: Плотность вероятности случайной величины: Где Вn -- параметр , зависит
- 23. Практическим следствием этого открытия явилась возможность определять границы доверительного интервала для М[X] с заданной доверительной вероятностью
- 25. Пример: При определении концентрации белка в растворе были получены следующие результаты (в мг/л):110, 112, 115, 113,
- 26. Для =0,95
- 27. 1.Провести серию измерений, не менее трех 2.Найти среднее арифметическое 3.Вычислить доверительный интервал (случайную ошибку). для заданной
- 28. б). если класс точности не указан ( например линейка или термометр) 5. Вычислить общую ошибку: Эту
- 30. Скачать презентацию

Основные понятия математической статистики.
Математическая статистика – это раздел математики о методах
Основные понятия математической статистики.
Математическая статистика – это раздел математики о методах

Генеральная совокупность – это совокупность всех объектов, которые имеют типичную характеристику
Генеральная совокупность – это совокупность всех объектов, которые имеют типичную характеристику

Основные задачи, которые стоят перед математической статистикой:
1. Определение закона распределения случайной
Основные задачи, которые стоят перед математической статистикой:
1. Определение закона распределения случайной

Схема предварительной обработки экспериментальных данных.
1) Сбор экспериментальных данных.
Чтобы определить закон распределения
Схема предварительной обработки экспериментальных данных.
1) Сбор экспериментальных данных.
Чтобы определить закон распределения

Пример:
При измерении частоты пульса у 10 пациентов получены следующие результаты: 90,
Пример:
При измерении частоты пульса у 10 пациентов получены следующие результаты: 90,

Схема предварительной обработки экспериментальных данных.
2) Составление вариационного ряда.
вариационный ряд (статистическое распределение)
Схема предварительной обработки экспериментальных данных.
2) Составление вариационного ряда.
вариационный ряд (статистическое распределение)
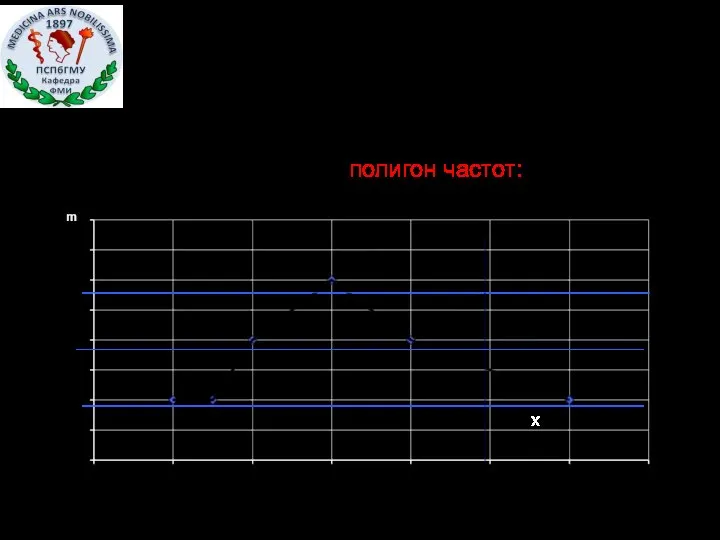
Графическое представление дискретного вариационного ряда - это полигон частот:
х
Графическое представление дискретного вариационного ряда - это полигон частот:
х

Если признак изменяется непрерывно, то составляется интервальный вариационный ряд: набор пар
Если признак изменяется непрерывно, то составляется интервальный вариационный ряд: набор пар

Пример. Анализ веса 60-ти новорожденных дал следующие результаты: min вес 1,5
Пример. Анализ веса 60-ти новорожденных дал следующие результаты: min вес 1,5
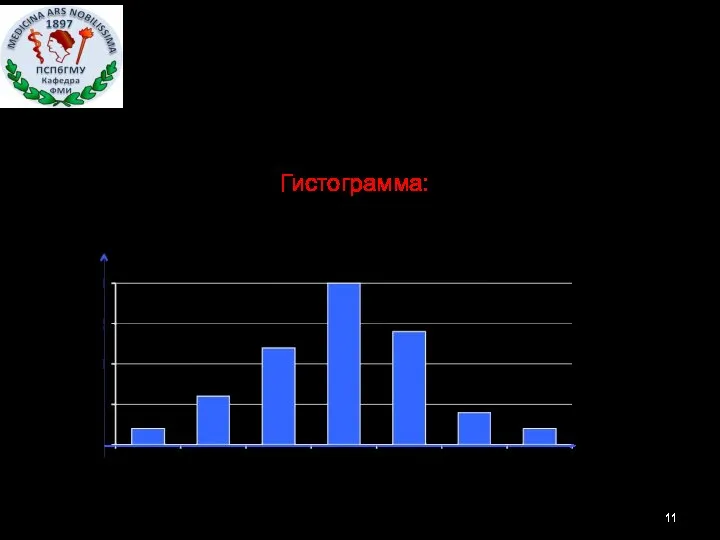
Графическая характеристика непрерывного вариационного ряда - Гистограмма:
Графическая характеристика непрерывного вариационного ряда - Гистограмма:

Закономерности распределения генеральной совокупности оцениваются по выборочной совокупности.
При увеличении объёма
Закономерности распределения генеральной совокупности оцениваются по выборочной совокупности.
При увеличении объёма
![Характеристики генеральной совокупности Математическое ожидание M[X] дисперсия D[X] среднее квадратическое отклонение](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1465727/slide-12.jpg)
Характеристики генеральной совокупности
Математическое ожидание M[X]
дисперсия D[X]
среднее квадратическое отклонение σ[X]
Характеристики выборки (статистики)
Математическое ожидание M[X]
дисперсия D[X]
среднее квадратическое отклонение σ[X]
Характеристики выборки (статистики)

Генеральная совокупность (n→∞) Выборка (n- конечно)
ν=n-1 число степеней свободы
Sn-стандартное отклонение
Генеральная совокупность (n→∞) Выборка (n- конечно)
ν=n-1 число степеней свободы
Sn-стандартное отклонение

Извлечём из генеральной совокупности N выборок, тогда их средние арифметические сами
Извлечём из генеральной совокупности N выборок, тогда их средние арифметические сами
![показывает насколько выборочное среднее арифметическое близко к матожиданию М[X] генеральной совокупности.](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1465727/slide-15.jpg)
показывает насколько выборочное среднее арифметическое близко к матожиданию М[X] генеральной
показывает насколько выборочное среднее арифметическое близко к матожиданию М[X] генеральной
![Истинные значения М[X] и D[X] можно найти по генеральной совокупности, что](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1465727/slide-16.jpg)
Истинные значения М[X] и D[X] можно найти по генеральной совокупности, что
Истинные значения М[X] и D[X] можно найти по генеральной совокупности, что

Если известна функция распределения, то этот интервал можно найти из соотношения:
Если известна функция распределения, то этот интервал можно найти из соотношения:

Доверительным интервалом какого либо параметра, называют такой интервал, о котором можно
Доверительным интервалом какого либо параметра, называют такой интервал, о котором можно

Основная масса случайных величин в биологии и медицине распределена по нормальному
Основная масса случайных величин в биологии и медицине распределена по нормальному

Где стандартное отклонение для случайной величины
Но для малых выборок (n<30)
Где стандартное отклонение для случайной величины
Но для малых выборок (n<30)

Нормированная случайная величина вычисляется по формуле:
Плотность вероятности случайной величины:
Где Вn
Плотность вероятности случайной величины:
Где Вn

Практическим следствием этого открытия явилась возможность определять границы доверительного интервала для
Практическим следствием этого открытия явилась возможность определять границы доверительного интервала для
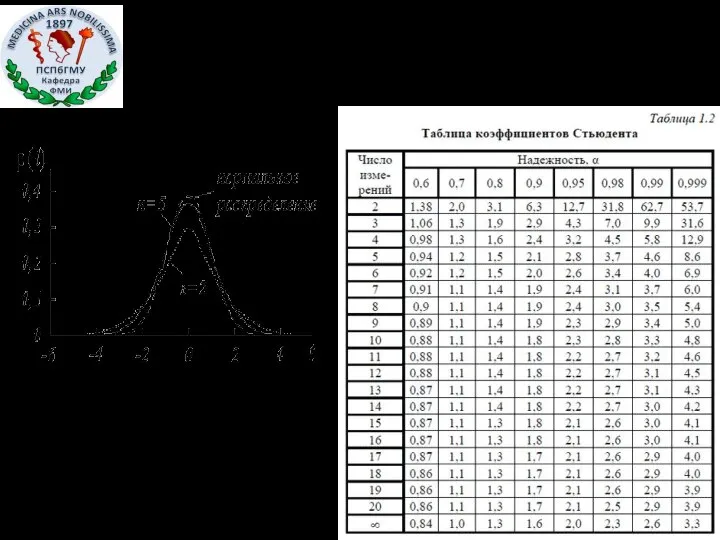

Пример:
При определении концентрации белка в растворе были получены следующие результаты
Пример:
При определении концентрации белка в растворе были получены следующие результаты

Для =0,95
Для =0,95

1.Провести серию измерений, не менее трех
2.Найти среднее арифметическое
3.Вычислить доверительный интервал
1.Провести серию измерений, не менее трех
2.Найти среднее арифметическое
3.Вычислить доверительный интервал

б). если класс точности не указан ( например линейка или
б). если класс точности не указан ( например линейка или
 y=sin x функциясе
y=sin x функциясе Сравнение чисел. 6 класс
Сравнение чисел. 6 класс Системы линейных алгебраических уравнений
Системы линейных алгебраических уравнений Признаки параллельных прямых
Признаки параллельных прямых Единицы измерений
Единицы измерений Аттестационная работа. Методическая разработка по выполнению проекта по математике «Некоторые замечательные кривые»
Аттестационная работа. Методическая разработка по выполнению проекта по математике «Некоторые замечательные кривые» Аналитическая геометрия в пространстве
Аналитическая геометрия в пространстве Приёмы вычитания с переходом через 10
Приёмы вычитания с переходом через 10 Двугранный угол. Перпендикулярность плоскостей. (10 класс)
Двугранный угол. Перпендикулярность плоскостей. (10 класс) Компьютерная грамотность и основы работы с Интернет
Компьютерная грамотность и основы работы с Интернет Арифметический квадратный корень. Задания для устного счета. 8 класс
Арифметический квадратный корень. Задания для устного счета. 8 класс Тренажёр - раскраска по таблице умножения
Тренажёр - раскраска по таблице умножения Аттестационная работа. Технология преподавания элективного курса «Комплексные числа»
Аттестационная работа. Технология преподавания элективного курса «Комплексные числа» Лобачевский Николай Иванович и его творческий путь
Лобачевский Николай Иванович и его творческий путь Задачи на движение
Задачи на движение  Сложение и вычитание смешанных дробей
Сложение и вычитание смешанных дробей Как показать ученикам, что не всякая формула задает функцию и не всякую функцию можно задать формулой?
Как показать ученикам, что не всякая формула задает функцию и не всякую функцию можно задать формулой? Численные меоды. Вычислительная математика
Численные меоды. Вычислительная математика Презентация по математике "Нестандартные задачи" - скачать
Презентация по математике "Нестандартные задачи" - скачать  Аттестационная работа. Учебно-исследовательская деятельность на уроках математики
Аттестационная работа. Учебно-исследовательская деятельность на уроках математики Передача значения переменной из одной формы в другую
Передача значения переменной из одной формы в другую Классификация многоугольников по числу углов
Классификация многоугольников по числу углов Интерактивный тренажер «Тригонометрические уравнения»
Интерактивный тренажер «Тригонометрические уравнения» Доли. Обыкновенные дроби
Доли. Обыкновенные дроби  Аrcsin
Аrcsin Случаи сложения и вычитания, основанные на знании нумерации чиселм
Случаи сложения и вычитания, основанные на знании нумерации чиселм Теорема Пифагора
Теорема Пифагора Параллельность прямых в пространстве
Параллельность прямых в пространстве