- XML Native Database Sedna 3.0 Климов Евгений (Slach) Александр Календарев (Alexandre)

Содержание
- 2. Сразу после phpConf2007, работаю в Start-Up'e ;) Есть приложение, в котором необходимо получать из внешних БД
- 3. Существующие XML- native DB: Apache XIndice (XML:DB XUpdate, JDCB, XML_RPC Работает под с Apache Tomcat )
- 4. Основные черты XML- native DB: Определена логическая модель XML документа XML документ – представлен, как фундаментальная
- 5. возможное применение XML- native DB : использование в Web-службах генерация суммарных отчетов данных из XML поиск
- 6. Полноценная СУБД (а не надстройка над SQL), специально спроектированная для XML представления данных и работы с
- 7. транзакционные операции с данными (ACID модель); резервирование данных; авторизация и разделение доступа; оптимизация запросов; управление внешней
- 8. SednaXMLDB - Поддерживаемые платформы: Linux x86 kernel version 2.4 or higher; Windows 2000/XP/2003/Vista; Mac OS X
- 9. SednaXML – общая архитектура (1/3) Governer - регулятор, центральный компонент все остальные компоненты регистрируются у него,
- 10. Компоненты, инкапсулированные в Transaction Parser – парсинг текстовых XQuery запросов в логическое представление, которое является деревом
- 11. Рисунок (1) Структура Node Descriptor внутреннее представление узла Рисунок (2) Хранение дексрипторов узла в блоках «памяти»
- 12. Где скачать - http://modis.ispras.ru/sedna/sedna_download_register.htmlГде скачать - http://modis.ispras.ru/sedna/sedna_download_register.html и http://modis.ispras.ru/FTPContent/ (тут много вкусного ;) Как ставить –
- 13. Утилиты: se_gov \ se_stop – запуск\остановка самого сервера (Governer) se_rc – просмотр списка запущенных компонентов se_cdb
- 14. Где скачать - http://modis.ispras.ru/FTPContent/api/ Как поставить Win32: добавить в php.ini extension=php_sedna.5.2.2.dll (работает под 5.2.3), Linux \
- 15. XQuery - язык, который полезен для работы со структурированной и мало структурированной информацией независим от платформы
- 16. W3C Спецификации XQuery XML Path Language (XPath) 2.0 XQuery and XPath Data Model XQuery and XPath
- 17. SednaXML возможности XQuery Выборка элементов или атрибутов из документов, коллекций и последовательностей узлов; Объединение данных из
- 18. Язык XQuery рекомендован W3C Консорциумом, как язык запросов для доступа к XML данным в XML ориентированных
- 19. Основные конструкции – FLWOR (for, let, where, order, return) (: комментарий, записывается так :) for $n1
- 20. Условное выражение IF Требуется наличие всех трех условий (if, then и else), а выражение в условии
- 21. Вставка узлов в заданное место UPDATE insert Expr1 (into|preceding|following) Expr2 Пример Добавляем ROW в WT_GOODS перед
- 22. Замена узлов UPDATE replace $var [as type] in Expr1 with Expr2($var) Удвоение остатка для списка товаров
- 23. Создание VALUED индекса CREATE INDEX “goods_by_code” ON collection(“westtorg”)/WT_DOCUMENT/WT_BODY/WT_GOODS/ROW BY CODE AS xs:integer Удаление DROP INDEX “goods_by_code”
- 24. Создание FULL-TEXT Indexes используется с dtSearch CREATE FULL-TEXT INDEX “goods_name_fulltext” ON collection(“westtorg”)/WT_DOCUMENT/WT_BODY/WT_GOODS/ROW/NAME AS “string-value” Полнотекстовое сканирование
- 25. Модули представляют собой текстовые файлы с набором ф-ций под определенным namespace например - wt.xqlib module namespace
- 26. Общий вид выражения для создания триггера CREATE TRIGGERtrigger-name (BEFORE|AFTER)(INSERT|DELETE|REPLACE) ON XpathExpression (FOR EACH NODE|FOR EACH STATEMENT)
- 27. Таблица условий при которых стартует триггер SednaXML – триггеры (2/2)
- 28. Как сейчас: SQL схема для поиска и импорта данных 18 таблиц, по 8-9 столбцов в каждой
- 29. Как сейчас: Типичный SQL запрос для поиска SELECT SQL_CALC_FOUND_ROWS o.company_id,o.guid, o.name, MIN(p.price) AS min_price, COUNT(DISTINCT go.guid)
- 30. Как могло бы быть: Переделка запроса под XQuery { let $goods := (ftindex-scan("goods_fullname_fulltext", "пиво туборг")/parent::ROW union
- 31. Как сейчас: схема импорта данных SednaXML – практическое использование (4/7) Как есть: схема импорта данных в
- 32. Как можно сделать: схема импорта данных в Sedna с использованием BULK LOAD При BULK LOAD не
- 33. Хочется: схема кластерного поиска в MySQL с использованием MySQL Proxy SednaXML – практическое использование (6/7)
- 34. Хочется: схема кластерного поиска в Sedna с использованием Hadoop SednaXML – практическое использование (7/7)
- 35. Шаблоны проектирования XML -данных Базовые соглашения Отношение иерархии Отношение один ко многим Отношение многие ко многим
- 36. Шаблоны проектирования XML –данных Базовые соглашения Каждая таблица – это отдельный документ Имя таблицы – имя
- 37. Шаблоны проектирования XML –данных Базовые соглашения - пример Пример:
- 38. Шаблоны проектирования XML -данных Отношение иерархии
- 39. Шаблоны проектирования XML -данных Отношение один ко многим
- 40. Шаблоны проектирования XML -данных Отношение многие ко многим
- 41. Нет нормальных инструментов написания, отладки и профилирования XQuery запросов, необходимо существенно перестраивать сознание разработчика для того
- 42. ~ 1,5 млн – предложений 600 магазинов 700 категорий товаров Коротко о проекте
- 43. Проект – изнутри (1/3)
- 44. Проект – изнутри (2/3)
- 45. Проект – изнутри (3/3)
- 46. как могло бы быть:
- 47. где использовать SednaXML в проекте Прием и хранение XML Документов Обобщение и обработка XML Документов Публикация
- 48. Поиск информации Выбор шаблона поиска Выбор информации по шаблону
- 49. Шаблоны поиска Категория Брэнд Модель Свойства
- 50. Шаблоны поиска
- 51. Структура данных
- 52. Запросы XPath для шаблона : Brand[@name=“Canon”]/model[@name=“Povershort S80” and @category=“ ”]/offer XQuery: let $model := doc(“good”)/Brand[@name=“Canon”]/model; for
- 53. Запросы (продолжение) XQuery: let $сat_id := doc(“catalog”)/ Category[ @name=“фотоаппарат”]/@id; let $model := doc(“good”)/ Brand[@name=“Canon”]/model; for $m
- 54. Проблемы Составные имена модели Морфология Ошибки ввода
- 56. Скачать презентацию

Сразу после phpConf2007, работаю в Start-Up'e ;)
Есть приложение, в котором необходимо
Сразу после phpConf2007, работаю в Start-Up'e ;)
Есть приложение, в котором необходимо

Существующие XML- native DB:
Apache XIndice (XML:DB XUpdate, JDCB, XML_RPC Работает под
Существующие XML- native DB:
Apache XIndice (XML:DB XUpdate, JDCB, XML_RPC Работает под

Основные черты XML- native DB:
Определена логическая модель XML документа
XML документ
Основные черты XML- native DB:
Определена логическая модель XML документа
XML документ

возможное применение XML- native DB :
использование в Web-службах
генерация суммарных отчетов данных
возможное применение XML- native DB :
использование в Web-службах
генерация суммарных отчетов данных

Полноценная СУБД (а не надстройка над SQL), специально спроектированная для XML
Полноценная СУБД (а не надстройка над SQL), специально спроектированная для XML

транзакционные операции с данными (ACID модель);
резервирование данных;
авторизация и
транзакционные операции с данными (ACID модель);
резервирование данных;
авторизация и

SednaXMLDB - Поддерживаемые платформы:
Linux x86 kernel version 2.4 or higher;
Windows 2000/XP/2003/Vista;
Mac
SednaXMLDB - Поддерживаемые платформы:
Linux x86 kernel version 2.4 or higher;
Windows 2000/XP/2003/Vista;
Mac

SednaXML – общая архитектура (1/3)
Governer - регулятор, центральный компонент все остальные
SednaXML – общая архитектура (1/3)
Governer - регулятор, центральный компонент все остальные

Компоненты, инкапсулированные в Transaction
Parser – парсинг текстовых XQuery запросов в
Компоненты, инкапсулированные в Transaction
Parser – парсинг текстовых XQuery запросов в
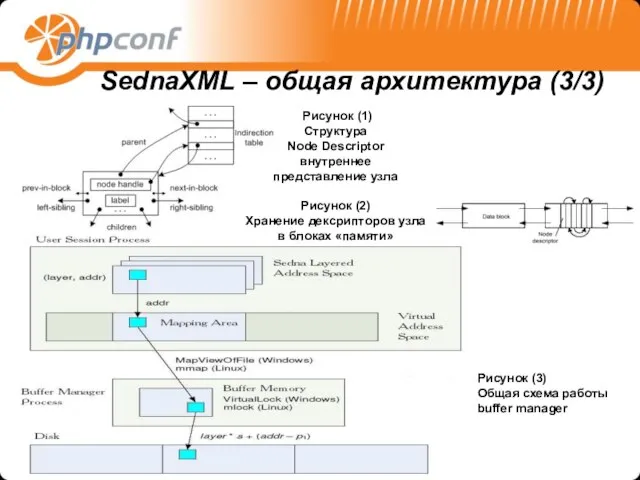
Рисунок (1)
Структура
Node Descriptor
внутреннее
представление узла
Рисунок (2)
Хранение дексрипторов
Рисунок (1)
Структура
Node Descriptor
внутреннее
представление узла
Рисунок (2)
Хранение дексрипторов
Где скачать - http://modis.ispras.ru/sedna/sedna_download_register.htmlГде скачать - http://modis.ispras.ru/sedna/sedna_download_register.html и http://modis.ispras.ru/FTPContent/ (тут много
Где скачать - http://modis.ispras.ru/sedna/sedna_download_register.htmlГде скачать - http://modis.ispras.ru/sedna/sedna_download_register.html и http://modis.ispras.ru/FTPContent/ (тут много

Утилиты:
se_gov \ se_stop – запуск\остановка самого сервера (Governer)
se_rc – просмотр списка
Утилиты:
se_gov \ se_stop – запуск\остановка самого сервера (Governer)
se_rc – просмотр списка

Где скачать - http://modis.ispras.ru/FTPContent/api/
Как поставить
Win32: добавить в php.ini extension=php_sedna.5.2.2.dll (работает
Где скачать - http://modis.ispras.ru/FTPContent/api/
Как поставить
Win32: добавить в php.ini extension=php_sedna.5.2.2.dll (работает

XQuery - язык, который
полезен для работы со структурированной и мало
XQuery - язык, который
полезен для работы со структурированной и мало

W3C Спецификации XQuery
XML Path Language (XPath) 2.0
XQuery and XPath Data
W3C Спецификации XQuery
XML Path Language (XPath) 2.0
XQuery and XPath Data

SednaXML возможности XQuery
Выборка элементов или атрибутов из документов, коллекций и последовательностей
SednaXML возможности XQuery
Выборка элементов или атрибутов из документов, коллекций и последовательностей

Язык XQuery рекомендован W3C Консорциумом, как язык запросов для доступа к
Язык XQuery рекомендован W3C Консорциумом, как язык запросов для доступа к

Основные конструкции – FLWOR (for, let, where, order, return)
(: комментарий, записывается
Основные конструкции – FLWOR (for, let, where, order, return)
(: комментарий, записывается

Условное выражение IF
Требуется наличие всех трех условий (if, then и else),
Условное выражение IF
Требуется наличие всех трех условий (if, then и else),

Вставка узлов в заданное место
UPDATE insert Expr1 (into|preceding|following) Expr2
Пример
Добавляем ROW
Вставка узлов в заданное место
UPDATE insert Expr1 (into|preceding|following) Expr2
Пример
Добавляем ROW
![Замена узлов UPDATE replace $var [as type] in Expr1 with Expr2($var)](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1231404/slide-21.jpg)
Замена узлов
UPDATE replace $var [as type] in Expr1 with Expr2($var)
Удвоение
Замена узлов
UPDATE replace $var [as type] in Expr1 with Expr2($var)
Удвоение

Создание VALUED индекса
CREATE INDEX “goods_by_code”
ON collection(“westtorg”)/WT_DOCUMENT/WT_BODY/WT_GOODS/ROW
BY CODE AS xs:integer
Удаление
DROP INDEX
Создание VALUED индекса
CREATE INDEX “goods_by_code”
ON collection(“westtorg”)/WT_DOCUMENT/WT_BODY/WT_GOODS/ROW
BY CODE AS xs:integer
Удаление
DROP INDEX

Создание FULL-TEXT Indexes используется с dtSearch
CREATE FULL-TEXT INDEX “goods_name_fulltext”
ON collection(“westtorg”)/WT_DOCUMENT/WT_BODY/WT_GOODS/ROW/NAME
AS
Создание FULL-TEXT Indexes используется с dtSearch
CREATE FULL-TEXT INDEX “goods_name_fulltext”
ON collection(“westtorg”)/WT_DOCUMENT/WT_BODY/WT_GOODS/ROW/NAME
AS

Модули представляют собой текстовые файлы с набором ф-ций под определенным namespace
Модули представляют собой текстовые файлы с набором ф-ций под определенным namespace

Общий вид выражения для создания триггера
CREATE TRIGGERtrigger-name
(BEFORE|AFTER)(INSERT|DELETE|REPLACE)
ON XpathExpression
(FOR EACH
Общий вид выражения для создания триггера
CREATE TRIGGERtrigger-name
(BEFORE|AFTER)(INSERT|DELETE|REPLACE)
ON XpathExpression
(FOR EACH
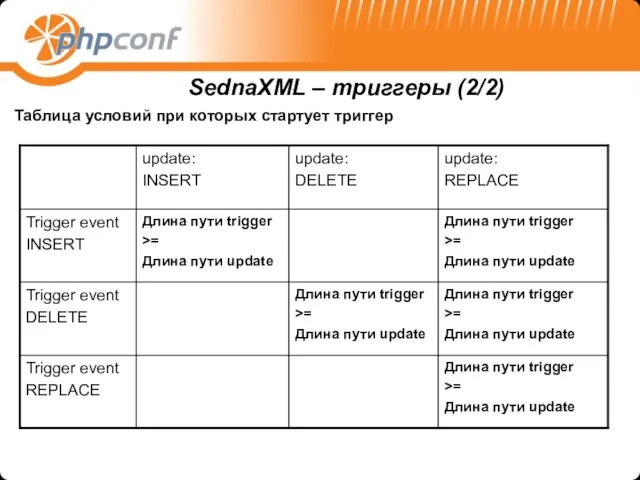
Таблица условий при которых стартует триггер
SednaXML – триггеры (2/2)
Таблица условий при которых стартует триггер
SednaXML – триггеры (2/2)

Как сейчас: SQL схема для поиска и импорта данных
18 таблиц, по
Как сейчас: SQL схема для поиска и импорта данных
18 таблиц, по

Как сейчас: Типичный SQL запрос для поиска
SELECT SQL_CALC_FOUND_ROWS
o.company_id,o.guid, o.name, MIN(p.price)
Как сейчас: Типичный SQL запрос для поиска
SELECT SQL_CALC_FOUND_ROWS
o.company_id,o.guid, o.name, MIN(p.price)

Как могло бы быть: Переделка запроса под XQuery
{
let $goods
Как могло бы быть: Переделка запроса под XQuery
let $goods
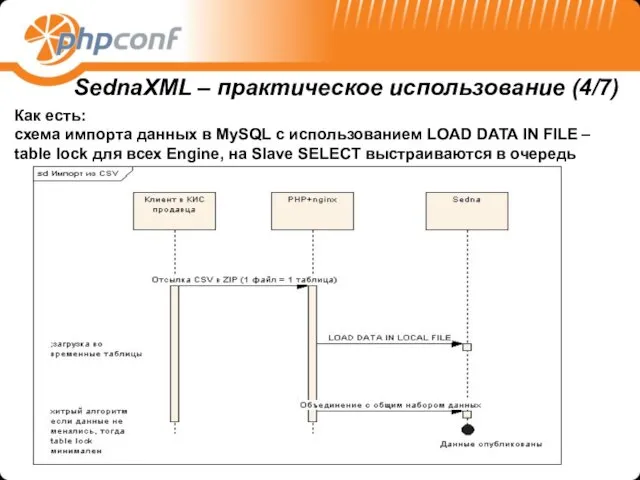
Как сейчас: схема импорта данных
SednaXML – практическое использование (4/7)
Как есть:
схема
Как сейчас: схема импорта данных
SednaXML – практическое использование (4/7)
Как есть: схема

Как можно сделать:
схема импорта данных в Sedna с использованием BULK
Как можно сделать: схема импорта данных в Sedna с использованием BULK
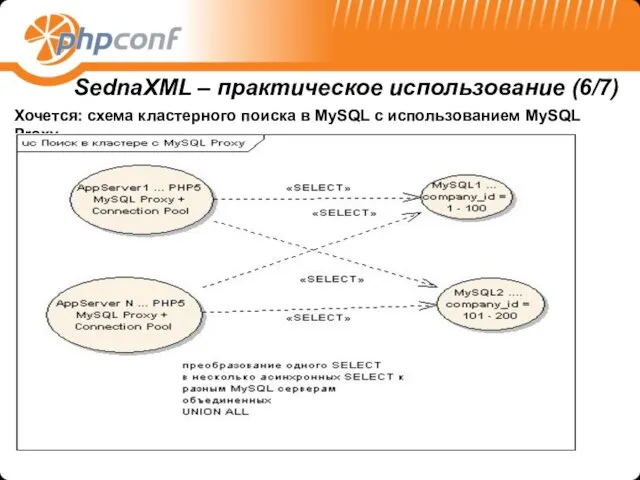
Хочется: схема кластерного поиска в MySQL с использованием MySQL Proxy
SednaXML –
Хочется: схема кластерного поиска в MySQL с использованием MySQL Proxy
SednaXML –
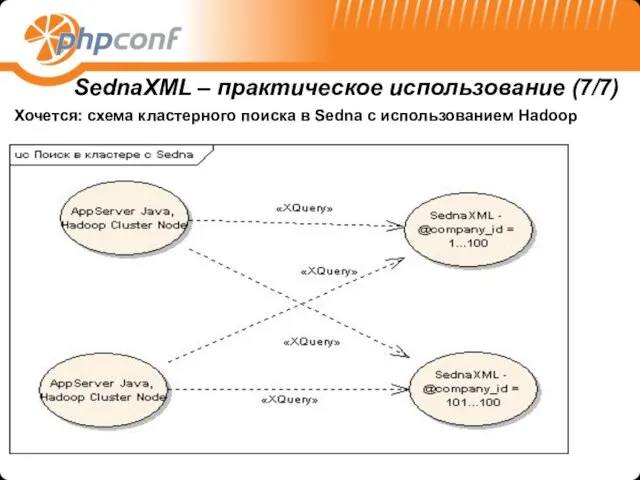
Хочется: схема кластерного поиска в Sedna с использованием Hadoop
SednaXML – практическое
Хочется: схема кластерного поиска в Sedna с использованием Hadoop
SednaXML – практическое

Шаблоны проектирования XML -данных
Базовые соглашения
Отношение иерархии
Отношение один ко
Шаблоны проектирования XML -данных
Базовые соглашения
Отношение иерархии
Отношение один ко

Шаблоны проектирования XML –данных
Базовые соглашения
Каждая таблица – это отдельный документ
Имя таблицы
Шаблоны проектирования XML –данных
Базовые соглашения
Каждая таблица – это отдельный документ
Имя таблицы

Шаблоны проектирования XML –данных
Базовые соглашения - пример
Пример:
Шаблоны проектирования XML –данных
Базовые соглашения - пример
Пример:
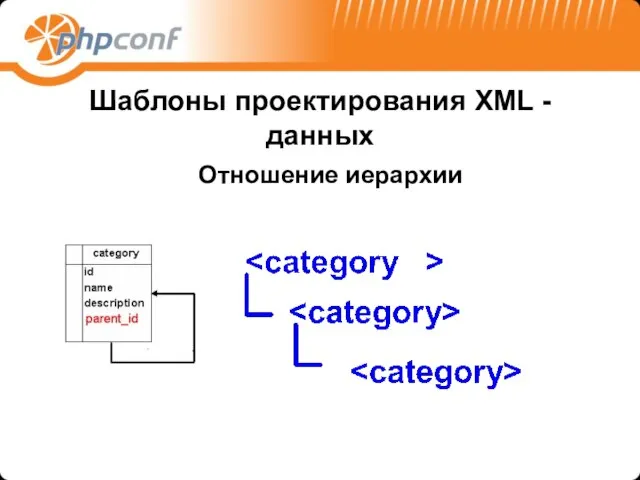
Шаблоны проектирования XML -данных
Отношение иерархии
Шаблоны проектирования XML -данных
Отношение иерархии
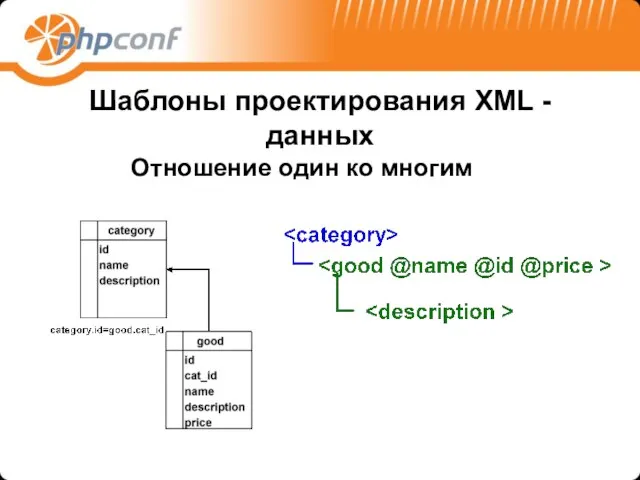
Шаблоны проектирования XML -данных
Отношение один ко многим
Шаблоны проектирования XML -данных
Отношение один ко многим
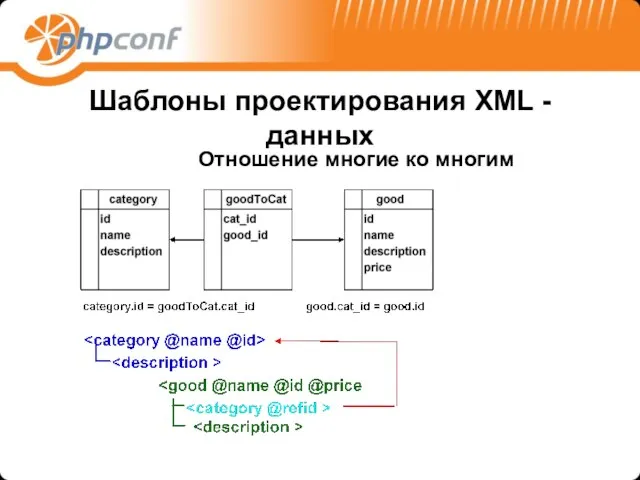
Шаблоны проектирования XML -данных
Отношение многие ко многим
Шаблоны проектирования XML -данных
Отношение многие ко многим

Нет нормальных инструментов написания, отладки и профилирования XQuery запросов, необходимо
Нет нормальных инструментов написания, отладки и профилирования XQuery запросов, необходимо

~ 1,5 млн – предложений
600 магазинов
700 категорий товаров
Коротко
~ 1,5 млн – предложений
600 магазинов
700 категорий товаров
Коротко

Проект – изнутри (1/3)
Проект – изнутри (1/3)
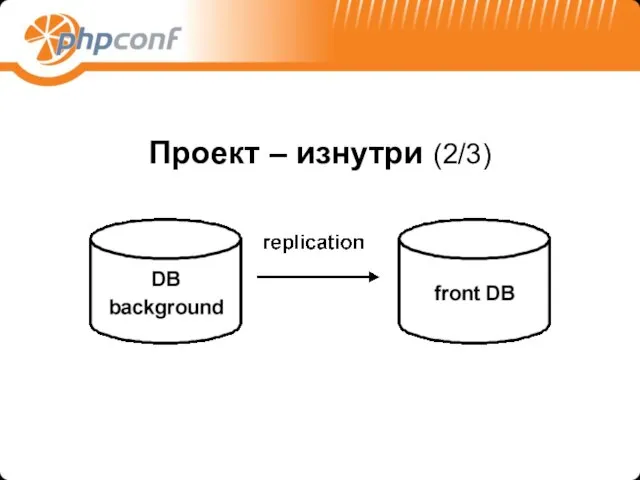
Проект – изнутри (2/3)
Проект – изнутри (2/3)
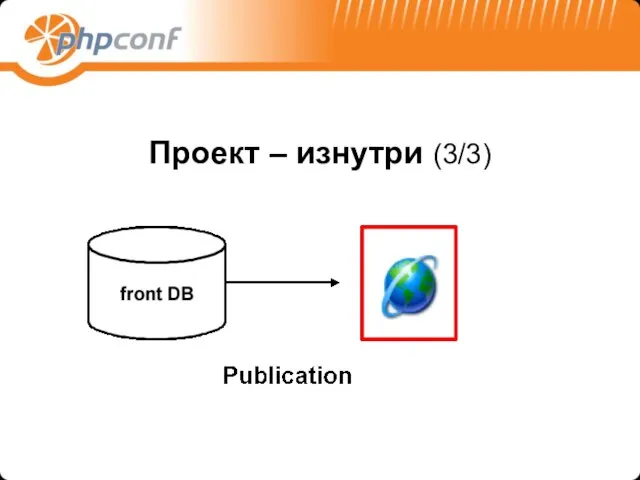
Проект – изнутри (3/3)
Проект – изнутри (3/3)

как могло бы быть:
как могло бы быть:

где использовать SednaXML в проекте
Прием и хранение XML Документов
Обобщение и
где использовать SednaXML в проекте
Прием и хранение XML Документов
Обобщение и

Поиск информации
Выбор шаблона поиска
Выбор информации по шаблону
Поиск информации
Выбор шаблона поиска
Выбор информации по шаблону
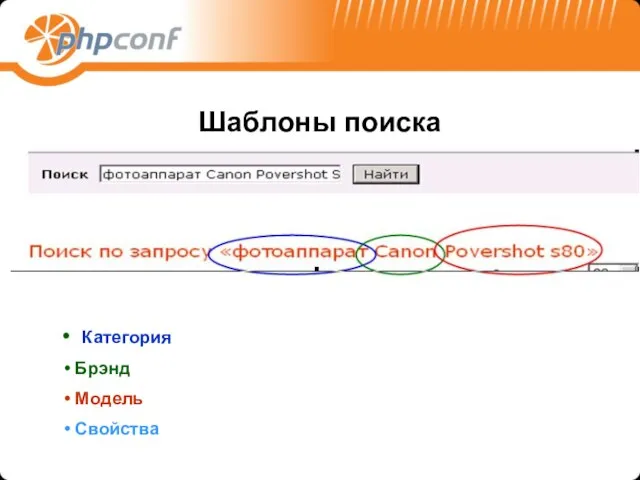
Шаблоны поиска
Категория
Брэнд
Модель
Свойства
Шаблоны поиска
Категория
Брэнд
Модель
Свойства

Шаблоны поиска
<Категория> <Брэнд> <Модель>
<Категория>
<Категория> <Брэнд>
<Категория> <Модель>
<Брэнд>
Шаблоны поиска
<Категория> <Брэнд> <Модель>
<Категория>
<Категория> <Брэнд>
<Категория> <Модель>
<Брэнд>

Структура данных
Структура данных
![Запросы XPath для шаблона : Brand[@name=“Canon”]/model[@name=“Povershort S80” and @category=“ ”]/offer XQuery:](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1231404/slide-51.jpg)
Запросы
XPath для шаблона <Категория> <Брэнд> <Модель>:
Brand[@name=“Canon”]/model[@name=“Povershort S80” and @category=“”]/offer
XQuery:
let $model :=
Запросы
XPath для шаблона <Категория> <Брэнд> <Модель>:
Brand[@name=“Canon”]/model[@name=“Povershort S80” and @category=“
XQuery:
let $model :=
![Запросы (продолжение) XQuery: let $сat_id := doc(“catalog”)/ Category[ @name=“фотоаппарат”]/@id; let $model](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1231404/slide-52.jpg)
Запросы (продолжение)
XQuery:
let $сat_id := doc(“catalog”)/ Category[ @name=“фотоаппарат”]/@id;
let $model := doc(“good”)/ Brand[@name=“Canon”]/model;
for
Запросы (продолжение)
XQuery:
let $сat_id := doc(“catalog”)/ Category[ @name=“фотоаппарат”]/@id;
let $model := doc(“good”)/ Brand[@name=“Canon”]/model;
for

Проблемы
Составные имена модели
Морфология
Ошибки ввода
Проблемы
Составные имена модели
Морфология
Ошибки ввода
 Урок: « Карвинг: Оформление яблок».
Урок: « Карвинг: Оформление яблок». Переводчик в сфере профессиональной коммуникации в Омском Юридическом Институте. - презентация
Переводчик в сфере профессиональной коммуникации в Омском Юридическом Институте. - презентация Лоскутное шитье Автор: Гехт О.А.
Лоскутное шитье Автор: Гехт О.А. Анимационный фильм - презентация к уроку Технологии_
Анимационный фильм - презентация к уроку Технологии_ 4 глава
4 глава Муниципальное образовательное учреждение дополнительного образования детей - Дом Детского творчества село Большая Глушица Заба
Муниципальное образовательное учреждение дополнительного образования детей - Дом Детского творчества село Большая Глушица Заба Тема урока: «Машинные швы»
Тема урока: «Машинные швы» Мастер-класс по технологии по теме «Квилинг. Цыплята» для 7 класса. Автор: Зорина Галина Алексеевна, учитель технологии высшей ква
Мастер-класс по технологии по теме «Квилинг. Цыплята» для 7 класса. Автор: Зорина Галина Алексеевна, учитель технологии высшей ква Урок технологии во 2 классе
Урок технологии во 2 классе  Обзор решений ГК VDEL для России и СНГ
Обзор решений ГК VDEL для России и СНГ блюда Блюда из круп Блюда из бобовых Блюда из макаронных изделий Блюда из яиц
блюда Блюда из круп Блюда из бобовых Блюда из макаронных изделий Блюда из яиц Leica DISTO™ D8 Для внутренних и внешних работ
Leica DISTO™ D8 Для внутренних и внешних работ Калейдоскоп самоделок - презентация к уроку Технологии_
Калейдоскоп самоделок - презентация к уроку Технологии_ Гайдар Магдануров Веб-евангелист Microsoft DT 201Веб-стандарты Участие Microsoft в комитетах W3C Поддержка стандартов в IE9 HTML 5 CSS 3. - презентация
Гайдар Магдануров Веб-евангелист Microsoft DT 201Веб-стандарты Участие Microsoft в комитетах W3C Поддержка стандартов в IE9 HTML 5 CSS 3. - презентация Тот, кто не смотрит вперед оказывается позади Д. Герберт
Тот, кто не смотрит вперед оказывается позади Д. Герберт  Сотовый поликарбонат – актуальное предложение сезона!
Сотовый поликарбонат – актуальное предложение сезона! Кот в сапогах. (в технике пэчворк)
Кот в сапогах. (в технике пэчворк) ИСПОЛЬЗОВАНИЕ NTFS REPARSE POINTS НА ПРИМЕРЕ WINDOWS HSM Кирилл Колотыгин. IBA
ИСПОЛЬЗОВАНИЕ NTFS REPARSE POINTS НА ПРИМЕРЕ WINDOWS HSM Кирилл Колотыгин. IBA Элементы резьбы. Резьбонарезной инструмент Материал к уроку в 7 классе Учитель технологии Галахов А.Г. МОУ «Степанщинская СОШ»
Элементы резьбы. Резьбонарезной инструмент Материал к уроку в 7 классе Учитель технологии Галахов А.Г. МОУ «Степанщинская СОШ» ДОМАШНЕЕ ПЕЧЕНЬЕ Алиса Дагаева Класс 3б Гимназия №11
ДОМАШНЕЕ ПЕЧЕНЬЕ Алиса Дагаева Класс 3б Гимназия №11 URG, корпоратив 2007
URG, корпоратив 2007 ТЕХНОЛОГІЯ ПРИГОТУВАННЯ СТРАВ З ЗАПЕЧЕНОЇ ПТИЦІ
ТЕХНОЛОГІЯ ПРИГОТУВАННЯ СТРАВ З ЗАПЕЧЕНОЇ ПТИЦІ  Тряпичная кукла. Курская Столбушка - презентация к уроку Технологии_
Тряпичная кукла. Курская Столбушка - презентация к уроку Технологии_ Филимоновская игрушка - презентация к уроку Технологии
Филимоновская игрушка - презентация к уроку Технологии Твердая рука - презентация к уроку Технологии
Твердая рука - презентация к уроку Технологии Волшебный квиллинг - презентация к уроку Технологии
Волшебный квиллинг - презентация к уроку Технологии Технология кейсов Селицкая Виктория Валерьевна, учитель русского языка и литературы ГБОУ Гимназии № 196, методист ГБОУ ДППО ЦПКС
Технология кейсов Селицкая Виктория Валерьевна, учитель русского языка и литературы ГБОУ Гимназии № 196, методист ГБОУ ДППО ЦПКС  Тюльпаны к 8 марта - презентация к уроку Технологии
Тюльпаны к 8 марта - презентация к уроку Технологии