- Jenkins Jobs

Содержание
- 2. CONTINUOUS INTEGRATION (CI) Непрерывная интеграция Практика включает в себя: Хранение кода в системе контроля версий (VCS)
- 3. CONTINUOUS DELIVERY (CD) Непрерывная поставка Практика включает в себя: Хранение инсталляционного пакета(дистрибутива) в централизованном хранилище. Гарантирование
- 4. PART I BUILD
- 5. BUILD WITH JENKINS: PIPELINE SCRIPT Pipeline plugin — решение, реализованное в виде плагина к Jenkins, позволяющее
- 6. BUILD WITH JENKINS: MAIN STAGES SCM – Source Control Management Проверка наличия GIT-репозитория Проверка наличия указанной
- 7. BUILD WITH JENKINS: DOCKER Docker – платформа, позволяющая упаковывать приложение вместе со всей его средой. Три
- 8. BUILD WITH JENKINS: DOCKER-TAG В pipeline dockerTag формируется на этапе «Set Env» Имя ветки и коммит
- 9. BUILD WITH JENKINS: CREATE IMAGES Образы, которые должны быть собраны в рамках текущей задачи в Jenkins,
- 10. BUILD WITH JENKINS: PUSH IMAGES На этапе «Push images» образы отправляются в централизованное хранилище Harbor В
- 11. ERROR ANALYSIS USING JENKINS Характерным признаком того, что сборка закончилась неудачно, является покраснение любого из этапов
- 12. ERROR ANALYSIS USING JENKINS Для анализа ошибок можно использовать два инструмента: Console Output: выводит логи сборки
- 13. PART II DEPLOY
- 14. KUBERNETES CLUSTER ARCHITECTURE Kubernetes – это программная система, которая позволяет легко развертывать контейнеризированные приложения и управлять
- 15. KUBERNETES CLUSTERS IN DEV-ZONE В контуре DEV существует два рабочих кластера Kubernetes - dev1 и dev2
- 16. DEV-STANDS Необходимо разделять сервисы, которые могут связываться с внешним миром и создают определенные риски безопасности, и
- 17. DEV-STANDS Таким образом, стенды – это namespace в кластере Kubernetes. Наименование этих namespace: devX-YY-dmz и devX-YY-inside,
- 18. DEPLOY WITH JENKINS: PIPELINE SCRIPT Обычное расположение в GIT-репозитории: distribution/Jenkins-ci/deploy.groovy Основные параметры: STAND_NAME – номер стенда,
- 19. DEPLOY WITH JENKINS: MAIN STAGES Основные этапы и шаги развертывания, без привязки к наименованию, заключаются в
- 20. DEPLOY WITH JENKINS: MAIN JOBS Наиболее часто используемые задачи по развертыванию в Jenkins следующие:
- 21. DEPLOY WITH JENKINS: FULLDEPLOY Перечисленные на предыдущем слайде задачи входят в состав FullDeploy FullDeploy позволяет развернуть
- 22. DEPLOY WITH JENKINS: FULLDEPLOY В edupower_deploy_versions.yaml включены последовательности и словари. У каждого сервиса есть набор свойств
- 23. DEPLOY WITH JENKINS: FULLDEPLOY FullDeploy не перегружен той логикой, которая прописана в Pipeline задач по деплою
- 24. STAND DIAGNOSTICS Kibana https://kibana-dev.pcbltools.ru/ Инструмент визуализации и изучения данных, который применяется для таких задач, как анализ
- 26. Скачать презентацию

CONTINUOUS INTEGRATION (CI)
Непрерывная интеграция
Практика включает в себя:
Хранение кода в системе
CONTINUOUS INTEGRATION (CI)
Непрерывная интеграция
Практика включает в себя:
Хранение кода в системе

CONTINUOUS DELIVERY (CD)
Непрерывная поставка
Практика включает в себя:
Хранение инсталляционного пакета(дистрибутива) в централизованном
CONTINUOUS DELIVERY (CD)
Непрерывная поставка
Практика включает в себя:
Хранение инсталляционного пакета(дистрибутива) в централизованном

PART I
BUILD
PART I
BUILD

BUILD WITH JENKINS:
PIPELINE SCRIPT
Pipeline plugin — решение, реализованное в виде плагина к Jenkins,
BUILD WITH JENKINS:
PIPELINE SCRIPT
Pipeline plugin — решение, реализованное в виде плагина к Jenkins,

BUILD WITH JENKINS:
MAIN STAGES
SCM – Source Control Management
Проверка наличия GIT-репозитория
Проверка наличия
BUILD WITH JENKINS:
MAIN STAGES
SCM – Source Control Management
Проверка наличия GIT-репозитория
Проверка наличия

BUILD WITH JENKINS:
DOCKER
Docker – платформа, позволяющая упаковывать приложение вместе со всей его
BUILD WITH JENKINS:
DOCKER
Docker – платформа, позволяющая упаковывать приложение вместе со всей его

BUILD WITH JENKINS:
DOCKER-TAG
В pipeline dockerTag формируется на этапе «Set Env»
Имя ветки
BUILD WITH JENKINS:
DOCKER-TAG
В pipeline dockerTag формируется на этапе «Set Env»
Имя ветки

BUILD WITH JENKINS:
CREATE IMAGES
Образы, которые должны быть собраны в рамках текущей
BUILD WITH JENKINS:
CREATE IMAGES
Образы, которые должны быть собраны в рамках текущей
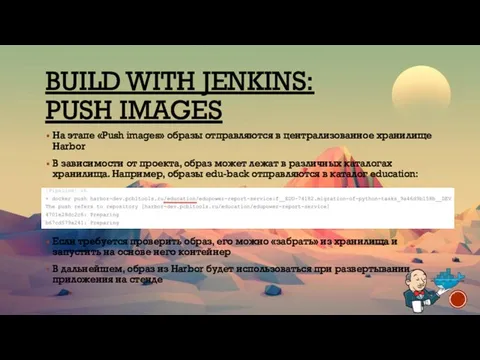
BUILD WITH JENKINS:
PUSH IMAGES
На этапе «Push images» образы отправляются в централизованное
BUILD WITH JENKINS:
PUSH IMAGES
На этапе «Push images» образы отправляются в централизованное

ERROR ANALYSIS USING JENKINS
Характерным признаком того, что сборка закончилась неудачно, является
ERROR ANALYSIS USING JENKINS
Характерным признаком того, что сборка закончилась неудачно, является

ERROR ANALYSIS USING JENKINS
Для анализа ошибок можно использовать два инструмента:
Console Output:
ERROR ANALYSIS USING JENKINS
Для анализа ошибок можно использовать два инструмента:
Console Output:

PART II
DEPLOY
PART II
DEPLOY

KUBERNETES CLUSTER ARCHITECTURE
Kubernetes – это программная система, которая позволяет легко развертывать
KUBERNETES CLUSTER ARCHITECTURE
Kubernetes – это программная система, которая позволяет легко развертывать

KUBERNETES CLUSTERS IN DEV-ZONE
В контуре DEV существует два рабочих кластера Kubernetes
KUBERNETES CLUSTERS IN DEV-ZONE
В контуре DEV существует два рабочих кластера Kubernetes

DEV-STANDS
Необходимо разделять сервисы, которые могут связываться с внешним миром и создают
DEV-STANDS
Необходимо разделять сервисы, которые могут связываться с внешним миром и создают

DEV-STANDS
Таким образом, стенды – это namespace в кластере Kubernetes. Наименование этих
DEV-STANDS
Таким образом, стенды – это namespace в кластере Kubernetes. Наименование этих

DEPLOY WITH JENKINS:
PIPELINE SCRIPT
Обычное расположение в GIT-репозитории: distribution/Jenkins-ci/deploy.groovy
Основные параметры:
STAND_NAME – номер
DEPLOY WITH JENKINS:
PIPELINE SCRIPT
Обычное расположение в GIT-репозитории: distribution/Jenkins-ci/deploy.groovy
Основные параметры:
STAND_NAME – номер

DEPLOY WITH JENKINS:
MAIN STAGES
Основные этапы и шаги развертывания, без привязки к
DEPLOY WITH JENKINS:
MAIN STAGES
Основные этапы и шаги развертывания, без привязки к

DEPLOY WITH JENKINS:
MAIN JOBS
Наиболее часто используемые задачи по развертыванию в Jenkins
DEPLOY WITH JENKINS:
MAIN JOBS
Наиболее часто используемые задачи по развертыванию в Jenkins

DEPLOY WITH JENKINS:
FULLDEPLOY
Перечисленные на предыдущем слайде задачи входят в состав FullDeploy
FullDeploy
DEPLOY WITH JENKINS:
FULLDEPLOY
Перечисленные на предыдущем слайде задачи входят в состав FullDeploy
FullDeploy
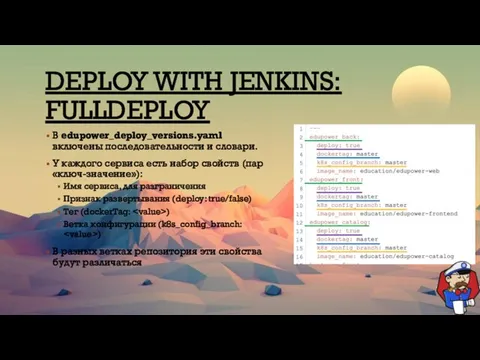
DEPLOY WITH JENKINS:
FULLDEPLOY
В edupower_deploy_versions.yaml включены последовательности и словари.
У каждого сервиса
DEPLOY WITH JENKINS:
FULLDEPLOY
В edupower_deploy_versions.yaml включены последовательности и словари.
У каждого сервиса

DEPLOY WITH JENKINS:
FULLDEPLOY
FullDeploy не перегружен той логикой, которая прописана в Pipeline
DEPLOY WITH JENKINS:
FULLDEPLOY
FullDeploy не перегружен той логикой, которая прописана в Pipeline

STAND DIAGNOSTICS
Kibana
https://kibana-dev.pcbltools.ru/
Инструмент визуализации и изучения данных, который применяется для таких
STAND DIAGNOSTICS
Kibana https://kibana-dev.pcbltools.ru/ Инструмент визуализации и изучения данных, который применяется для таких
 класс карантин №1
класс карантин №1 Презентация
Презентация Святые Земли Русской
Святые Земли Русской Лентообмотка кабельных сборок и жгутов. Обмотка по длине жгута
Лентообмотка кабельных сборок и жгутов. Обмотка по длине жгута Православные религиозные учреждения Москвы
Православные религиозные учреждения Москвы Церковь Невеста Христа
Церковь Невеста Христа 20180424_prezentatsiya_o_pizanskoy_bashne1
20180424_prezentatsiya_o_pizanskoy_bashne1 Повышение выработки на установке 37/1-5 ОЗСМ, ПАО Газпром нефть
Повышение выработки на установке 37/1-5 ОЗСМ, ПАО Газпром нефть 20130809_grig
20130809_grig Лучший друг
Лучший друг Современные требования работодателя
Современные требования работодателя Современные технологии сельского хозяйства
Современные технологии сельского хозяйства 20151206_prezentatsiya_mal._prints
20151206_prezentatsiya_mal._prints Разработка модели женского летнего платья в системе автоматизированного проектирования швейных изделий
Разработка модели женского летнего платья в системе автоматизированного проектирования швейных изделий Моделирование фартука
Моделирование фартука Групп-фолап
Групп-фолап Деревья (средняя группа)
Деревья (средняя группа) Исследования реакций адаптаций организма к высоким температурам
Исследования реакций адаптаций организма к высоким температурам 12 июня - День России
12 июня - День России Проблемы проектирования теплозащиты наружных стен
Проблемы проектирования теплозащиты наружных стен Стретчинг
Стретчинг 90411-4-grishechkina-ie-gotovaya-dlya-pechati-1
90411-4-grishechkina-ie-gotovaya-dlya-pechati-1 Габарит на железнодорожном транспорте
Габарит на железнодорожном транспорте Сдача электроподвижного состава на линии
Сдача электроподвижного состава на линии Опасные насекомые Крыма
Опасные насекомые Крыма Ислам как мировая религия
Ислам как мировая религия На поставку плоскошлифовального с прямоугольным столом и горизонтальным шпинделем модели 3Л722А(В)Ф2 -70
На поставку плоскошлифовального с прямоугольным столом и горизонтальным шпинделем модели 3Л722А(В)Ф2 -70 Рецензия. Что это такое и как написать рецензию
Рецензия. Что это такое и как написать рецензию