- Современные суперкомпьютерные технологии решения больших задач

Содержание
- 3. Характеристики суперкомпьютеров ∙ IBM RoadRunner, 6562 AMD Opteron DC + 12240 IBM Cell, 1105 Tflop/s, ОП
- 4. Суперкомпьютер СКИФ МГУ - Чебышев Создан МГУ, ИПС РАН и компанией “Т-Платформы” при поддержке компании Интел
- 5. Суперкомпьютер СКИФ МГУ - Чебышев 60 Tflop/s, 1250 процессоров Intel Xeon (*4 ядра)
- 6. Суперкомпьютер СКИФ МГУ - Чебышев
- 7. Суперкомпьютер СКИФ МГУ - Чебышев
- 8. Суперкомпьютер СКИФ МГУ - Чебышев
- 9. Суперкомпьютер СКИФ МГУ - Чебышев
- 10. Суперкомпьютер СКИФ МГУ - Чебышев
- 11. Суперкомпьютер СКИФ МГУ - Чебышев
- 12. Суперкомпьютер СКИФ МГУ - Чебышев
- 13. Суперкомпьютер СКИФ МГУ - Чебышев
- 14. Суперкомпьютер СКИФ МГУ - Чебышев
- 15. 60 Tflop/s, Linpack = 47,17 Tflop/s (750.000×750.000) 625 узлов, 1250 × Intel Xeon E5472 3.0 GHz
- 16. Высокопроизводительные компьютерные системы (основные классы)
- 17. Высокопроизводительные компьютерные системы (степень параллелизма) 1 102 104 106 Степень параллелизма
- 18. Высокопроизводительные компьютерные системы (степень параллелизма) 1 102 104 106 Степень параллелизма Многоядерность
- 19. Высокопроизводительные компьютерные системы (степень параллелизма) 2 – 4 – 8 – 12 … 102 104 106
- 20. Многоядерные процессоры: это навсегда 80-ядерный процессор Intel
- 21. Высокопроизводительные компьютерные системы (основные классы) Компьютеры с общей памятью Компьютеры с распределенной памятью Распределенные вычислительные среды
- 22. Компьютеры с реконфигурируемой архитектурой (http://fpga.parallel.ru)
- 23. FPGA Компьютеры с реконфигурируемой архитектурой (http://fpga.parallel.ru)
- 24. FPGA Компьютеры с реконфигурируемой архитектурой (http://fpga.parallel.ru)
- 25. Компьютеры с реконфигурируемой архитектурой (http://fpga.parallel.ru)
- 26. Компьютеры с реконфигурируемой архитектурой (http://fpga.parallel.ru) РВС-5: установка в НИВЦ МГУ в середине 2009 года Разработчик –
- 27. Графические процессоры и HPC (http://gpu.parallel.ru)
- 28. Графические процессоры и HPC (http://gpu.parallel.ru)
- 29. Графические процессоры и HPC (http://gpu.parallel.ru)
- 30. Свойства распределенных вычислительных сред Масштабность. Распределенность. Динамичность. Неоднородность. Различная административная принадлежность.
- 31. СВОЙСТВА ВЫЧИСЛИТЕЛЬНЫХ СРЕД Класс и свойства задач Структура процесса вычислений Программирование вычислительных сред Выполнение распределенных программ
- 32. Система метакомпьютинга X-COM (http://x-com.parallel.ru)
- 33. Решение больших задач в распределенных вычислительных средах Центр “Биоинженерия” РАН. Определение скрытой периодичности в генетических последовательностях.
- 34. Система метакомпьютинга X-COM (http://x-com.parallel.ru)
- 35. Куда мы планируем двигаться дальше? Следующий компьютер Московского университета будет установлен к концу 2009 года, производительность:
- 36. Скорости растут, КПД падает…
- 37. Компьютерный дизайн лекарств (Intel -fast, исследование эффективности, Clovertown 2.66GHz) КПД процессора на задаче: 4% !!! Реальная
- 38. АНАЛИЗ АЛГОРИТМИЧЕСКОГО ПОДХОДА ↓ АНАЛИЗ СТРУКТУРЫ ПРИКЛАДНОЙ ПРОГРАММЫ ↓ АНАЛИЗ ЭФФЕКТИВНОСТИ СИСТЕМ РАЗРАБОТКИ ПО ↓ АНАЛИЗ
- 39. Реальная производительность, Mflops Анализ эффективности программ
- 40. АНАЛИЗ АЛГОРИТМИЧЕСКОГО ПОДХОДА ↓ АНАЛИЗ СТРУКТУРЫ ПРИКЛАДНОЙ ПРОГРАММЫ ↓ АНАЛИЗ ЭФФЕКТИВНОСТИ СИСТЕМ РАЗРАБОТКИ ПО ↓ АНАЛИЗ
- 41. Что снижает производительность современных кластеров? Закон Амдала Латентность передачи по сети Пропускная способность каналов передачи данных
- 42. Топология FatTree: СКИФ МГУ “Чебышев”
- 43. Что снижает производительность современных кластеров? Закон Амдала Латентность передачи по сети Пропускная способность каналов передачи данных
- 44. Что влияет на производительность узлов кластеров? использование суперскалярности, неполная загрузка конвейерных функциональных устройств, пропускная способность кэшей,
- 45. Производительность на базовых операциях Производительность, Mflops
- 46. Масштабирование по частоте CPU? Производительность, Mflops
- 47. Реальное масштабирование на практике… Производительность, Mflops
- 48. Реальное масштабирование на практике… Clowertown – 1,6 GHz 1,066 GHz Clowertown – 2,66 GHz 1,333 GHz
- 49. Теория и практика масштабирования Производительность, Mflops
- 50. Эффективность, % КПД работы процессоров …
- 51. КПД работы процессоров …
- 52. Процессоры и массивы…
- 53. Простой пример. Исходный текст for ( i = 1; i
- 54. Простой пример. Эффект от преобразований (перестановка циклов, раскрутка, Intel -fast)
- 55. Простой пример. Эффект от преобразований (перестановка циклов, раскрутка, PGI)
- 56. Сравнение компиляторов: Intel и PGI (простой пример, PGI/Intel)
- 57. Характеристики работы программно-аппаратной среды Количество задач в состоянии счёта на узле Число переключений контекста Процент использования
- 58. Исследование динамических свойств программ
- 59. Исследование динамических свойств программ
- 60. Исследование динамических свойств программ
- 61. Исследование динамических свойств программ
- 62. Сертификация эффективности параллельных программ • Эффективность последовательная • Эффективность параллельная Объекты исследования: Задача – Алгоритм –
- 63. Параллелизм – новый этап развития компьютерного мира ОБРАЗОВАНИЕ! ОБРАЗОВАНИЕ! ОБРАЗОВАНИЕ!
- 64. Учебный процесс и образование
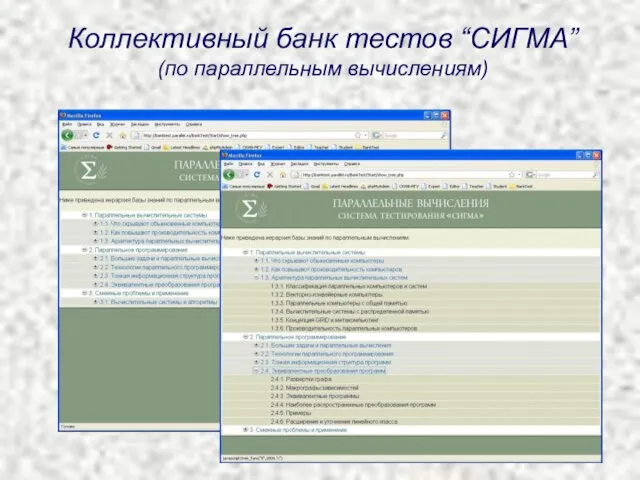
- 65. Коллективный банк тестов “СИГМА” (по параллельным вычислениям)
- 66. Коллективный банк тестов “СИГМА” (по параллельным вычислениям)
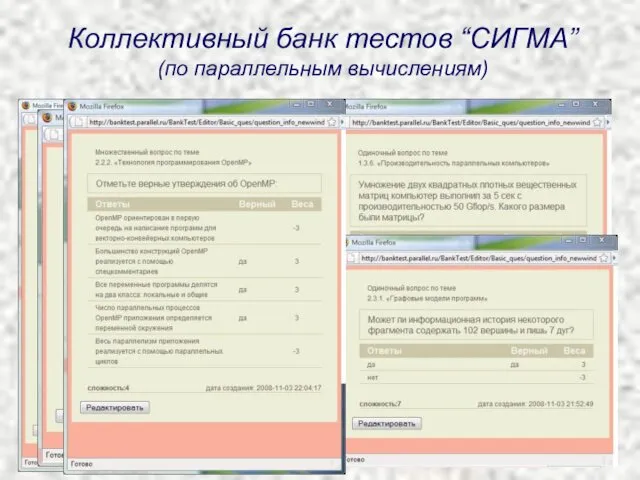
- 67. Коллективный банк тестов “СИГМА” (по параллельным вычислениям)
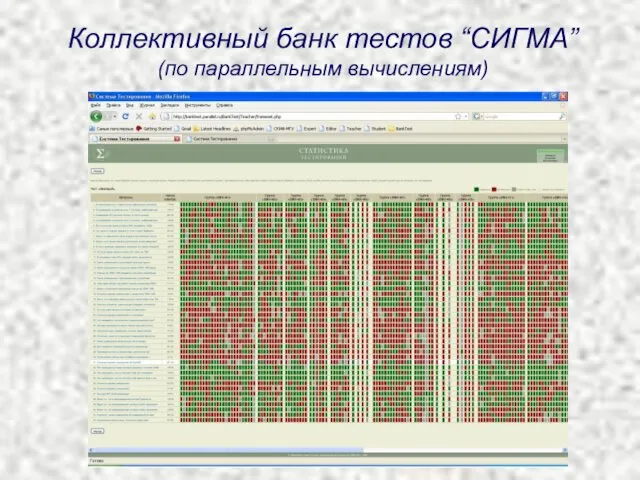
- 68. Коллективный банк тестов “СИГМА” (по параллельным вычислениям)
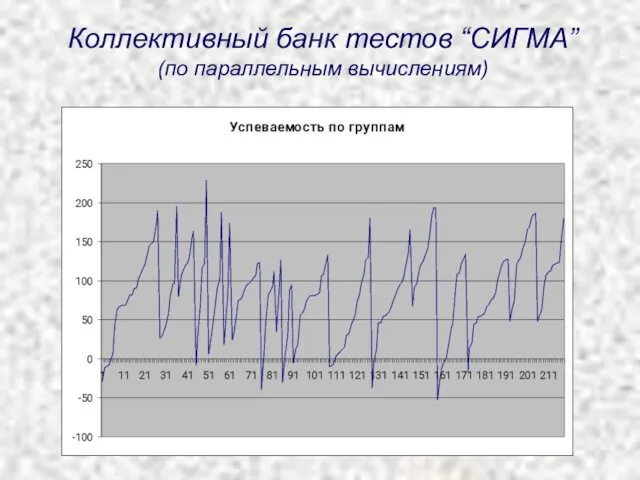
- 69. Коллективный банк тестов “СИГМА” (по параллельным вычислениям)
- 70. Учебный процесс и образование
- 72. Скачать презентацию


Характеристики суперкомпьютеров
∙ IBM RoadRunner, 6562 AMD Opteron DC + 12240 IBM Cell,
1105
Характеристики суперкомпьютеров
∙ IBM RoadRunner, 6562 AMD Opteron DC + 12240 IBM Cell,
1105

Суперкомпьютер СКИФ МГУ - Чебышев
Создан МГУ, ИПС РАН и компанией “Т-Платформы”
Суперкомпьютер СКИФ МГУ - Чебышев
Создан МГУ, ИПС РАН и компанией “Т-Платформы”

Суперкомпьютер СКИФ МГУ - Чебышев
60 Tflop/s, 1250 процессоров Intel Xeon (*4
Суперкомпьютер СКИФ МГУ - Чебышев
60 Tflop/s, 1250 процессоров Intel Xeon (*4

Суперкомпьютер СКИФ МГУ - Чебышев
Суперкомпьютер СКИФ МГУ - Чебышев

Суперкомпьютер СКИФ МГУ - Чебышев
Суперкомпьютер СКИФ МГУ - Чебышев

Суперкомпьютер СКИФ МГУ - Чебышев
Суперкомпьютер СКИФ МГУ - Чебышев

Суперкомпьютер СКИФ МГУ - Чебышев
Суперкомпьютер СКИФ МГУ - Чебышев

Суперкомпьютер СКИФ МГУ - Чебышев
Суперкомпьютер СКИФ МГУ - Чебышев

Суперкомпьютер СКИФ МГУ - Чебышев
Суперкомпьютер СКИФ МГУ - Чебышев

Суперкомпьютер СКИФ МГУ - Чебышев
Суперкомпьютер СКИФ МГУ - Чебышев

Суперкомпьютер СКИФ МГУ - Чебышев
Суперкомпьютер СКИФ МГУ - Чебышев

Суперкомпьютер СКИФ МГУ - Чебышев
Суперкомпьютер СКИФ МГУ - Чебышев

60 Tflop/s, Linpack = 47,17 Tflop/s (750.000×750.000)
625 узлов, 1250 × Intel
60 Tflop/s, Linpack = 47,17 Tflop/s (750.000×750.000)
625 узлов, 1250 × Intel
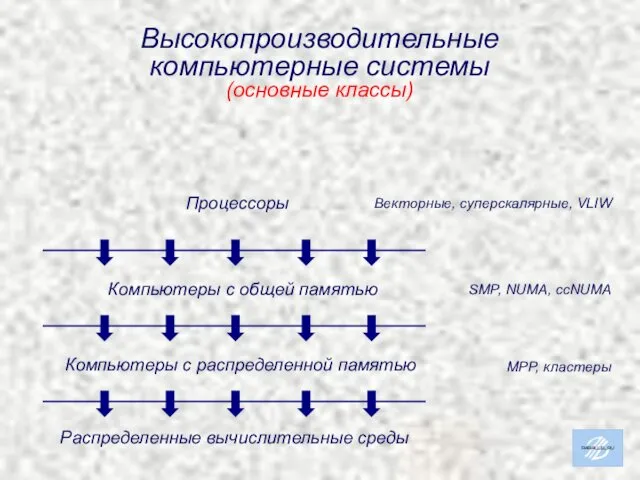
Высокопроизводительные
компьютерные системы
(основные классы)
Высокопроизводительные
компьютерные системы
(основные классы)
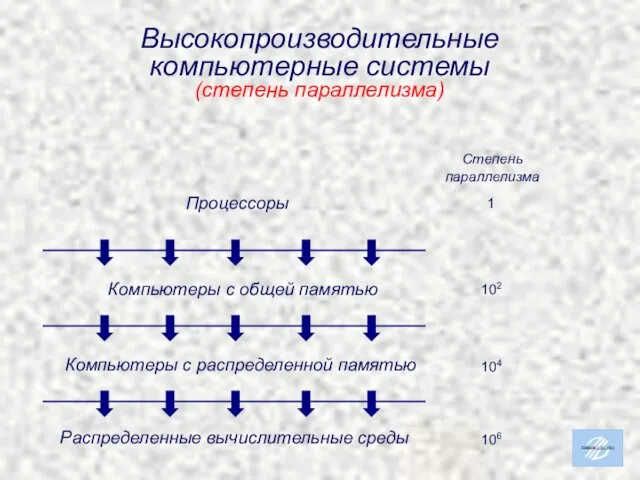
Высокопроизводительные
компьютерные системы
(степень параллелизма)
1
102
104
106
Степень
параллелизма
Высокопроизводительные
компьютерные системы
(степень параллелизма)
1
102
104
106
Степень
параллелизма
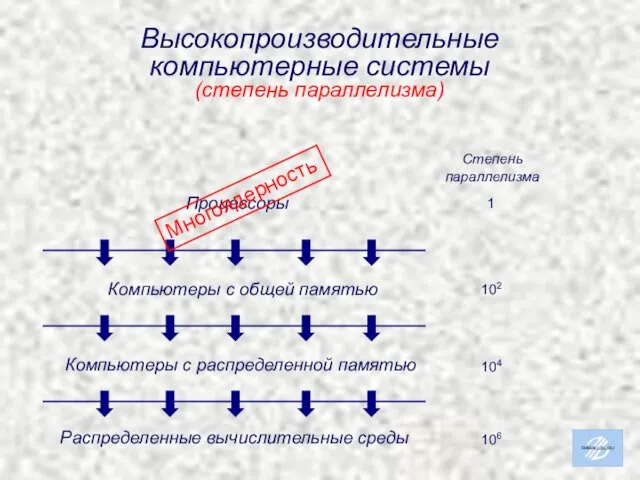
Высокопроизводительные
компьютерные системы
(степень параллелизма)
1
102
104
106
Степень
параллелизма
Многоядерность
Высокопроизводительные
компьютерные системы
(степень параллелизма)
1
102
104
106
Степень
параллелизма
Многоядерность
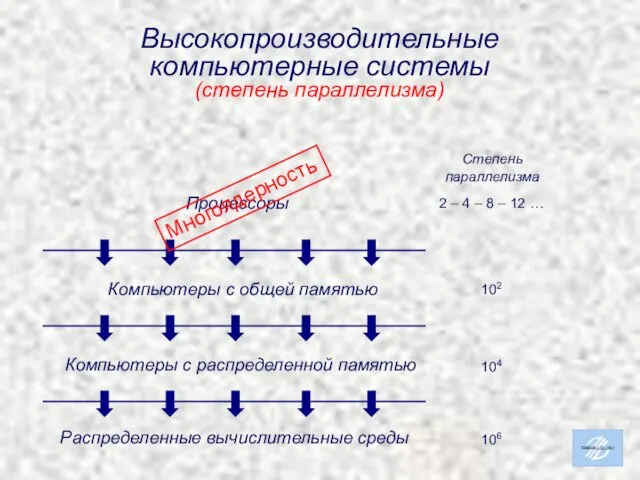
Высокопроизводительные
компьютерные системы
(степень параллелизма)
2 – 4 – 8 – 12 …
102
104
106
Степень
Высокопроизводительные
компьютерные системы
(степень параллелизма)
2 – 4 – 8 – 12 …
102
104
106
Степень

Многоядерные процессоры: это навсегда
80-ядерный процессор Intel
Многоядерные процессоры: это навсегда
80-ядерный процессор Intel
Высокопроизводительные
компьютерные системы
(основные классы)
Компьютеры с общей памятью
Компьютеры с распределенной памятью
Распределенные вычислительные
Высокопроизводительные
компьютерные системы
(основные классы)
Компьютеры с общей памятью
Компьютеры с распределенной памятью
Распределенные вычислительные
Компьютеры с реконфигурируемой архитектурой
(http://fpga.parallel.ru)
Компьютеры с реконфигурируемой архитектурой
(http://fpga.parallel.ru)
FPGA
Компьютеры с реконфигурируемой архитектурой
(http://fpga.parallel.ru)
FPGA
Компьютеры с реконфигурируемой архитектурой
(http://fpga.parallel.ru)
FPGA
Компьютеры с реконфигурируемой архитектурой
(http://fpga.parallel.ru)
FPGA
Компьютеры с реконфигурируемой архитектурой
(http://fpga.parallel.ru)

Компьютеры с реконфигурируемой архитектурой
(http://fpga.parallel.ru)
Компьютеры с реконфигурируемой архитектурой
(http://fpga.parallel.ru)
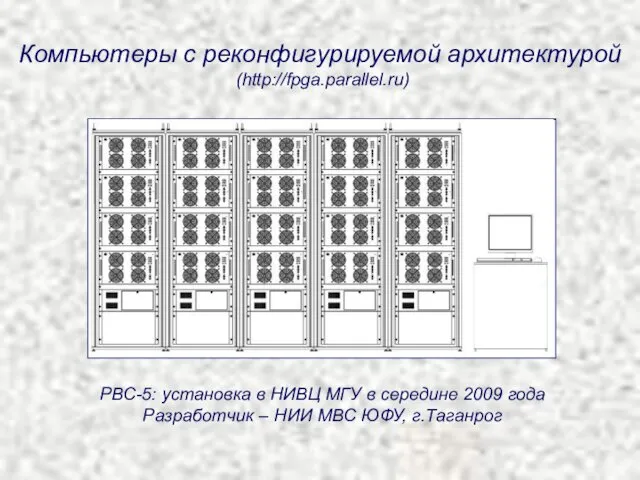
Компьютеры с реконфигурируемой архитектурой
(http://fpga.parallel.ru)
РВС-5: установка в НИВЦ МГУ в середине
Компьютеры с реконфигурируемой архитектурой
(http://fpga.parallel.ru)
РВС-5: установка в НИВЦ МГУ в середине
Графические процессоры и HPC
(http://gpu.parallel.ru)
Графические процессоры и HPC
(http://gpu.parallel.ru)

Графические процессоры и HPC
(http://gpu.parallel.ru)
Графические процессоры и HPC
(http://gpu.parallel.ru)
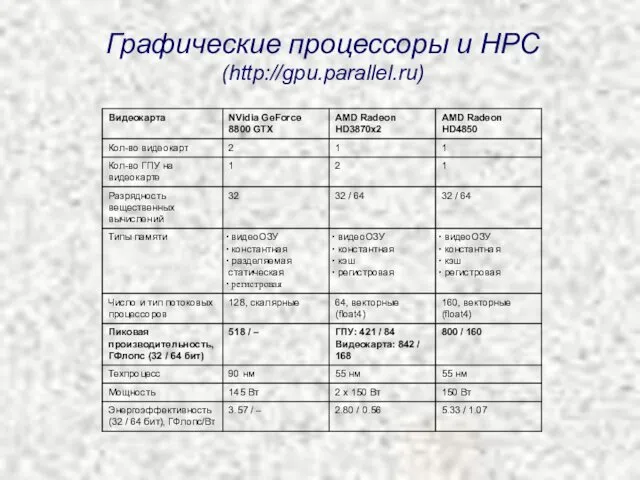
Графические процессоры и HPC
(http://gpu.parallel.ru)
Графические процессоры и HPC
(http://gpu.parallel.ru)

Свойства распределенных вычислительных сред
Масштабность.
Распределенность.
Динамичность.
Неоднородность.
Различная административная принадлежность.
Масштабность.
Распределенность.
Динамичность.
Неоднородность.
Различная административная принадлежность.
СВОЙСТВА ВЫЧИСЛИТЕЛЬНЫХ СРЕД
Класс и
свойства
задач
Структура
процесса
вычислений
Программирование
вычислительных
сред
Выполнение
распределенных
программ
Использование вычислительных сред
СВОЙСТВА ВЫЧИСЛИТЕЛЬНЫХ СРЕД
Класс и
свойства
задач
Структура
процесса
вычислений
Программирование
вычислительных
сред
Выполнение
распределенных
программ
Использование вычислительных сред
Система метакомпьютинга X-COM
(http://x-com.parallel.ru)
Система метакомпьютинга X-COM
(http://x-com.parallel.ru)

Решение больших задач в распределенных вычислительных средах
Центр “Биоинженерия” РАН. Определение скрытой
Решение больших задач в распределенных вычислительных средах
Центр “Биоинженерия” РАН. Определение скрытой
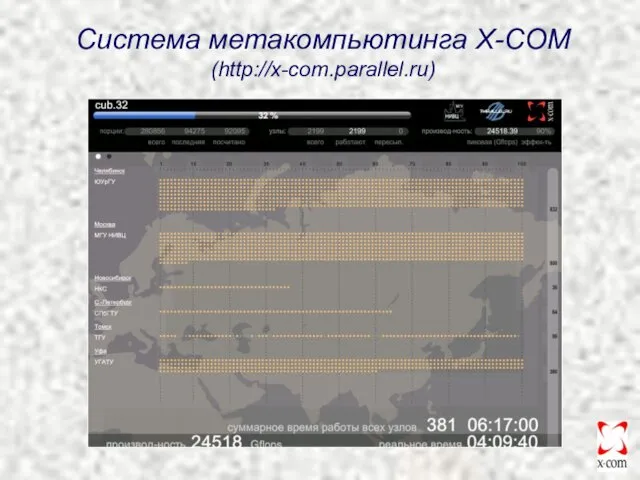
Система метакомпьютинга X-COM
(http://x-com.parallel.ru)
Система метакомпьютинга X-COM
(http://x-com.parallel.ru)

Куда мы планируем двигаться
дальше?
Следующий компьютер
Московского университета будет
установлен к концу 2009
Куда мы планируем двигаться
дальше?
Следующий компьютер
Московского университета будет
установлен к концу 2009

Скорости растут, КПД падает…
Скорости растут, КПД падает…
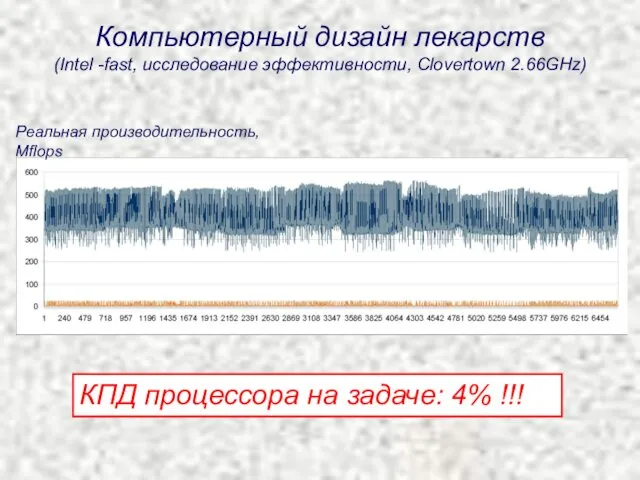
Компьютерный дизайн лекарств
(Intel -fast, исследование эффективности, Clovertown 2.66GHz)
КПД процессора на задаче:
Компьютерный дизайн лекарств
(Intel -fast, исследование эффективности, Clovertown 2.66GHz)
КПД процессора на задаче:

АНАЛИЗ АЛГОРИТМИЧЕСКОГО ПОДХОДА
↓
АНАЛИЗ СТРУКТУРЫ ПРИКЛАДНОЙ ПРОГРАММЫ
↓
АНАЛИЗ ЭФФЕКТИВНОСТИ СИСТЕМ РАЗРАБОТКИ
АНАЛИЗ АЛГОРИТМИЧЕСКОГО ПОДХОДА
↓
АНАЛИЗ СТРУКТУРЫ ПРИКЛАДНОЙ ПРОГРАММЫ
↓
АНАЛИЗ ЭФФЕКТИВНОСТИ СИСТЕМ РАЗРАБОТКИ
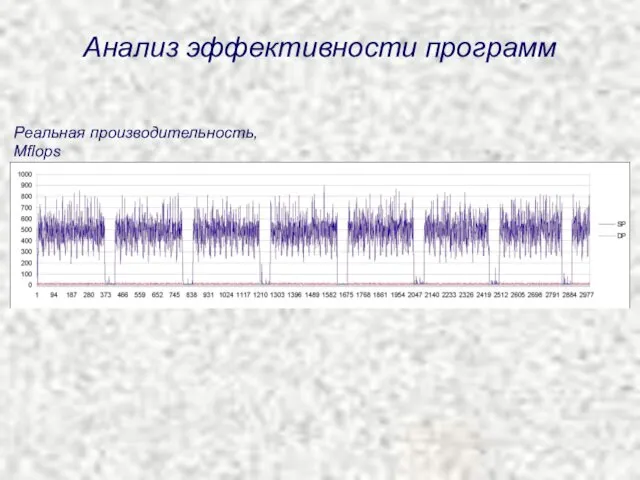
Реальная производительность,
Mflops
Анализ эффективности программ
Реальная производительность,
Mflops
Анализ эффективности программ

АНАЛИЗ АЛГОРИТМИЧЕСКОГО ПОДХОДА
↓
АНАЛИЗ СТРУКТУРЫ ПРИКЛАДНОЙ ПРОГРАММЫ
↓
АНАЛИЗ ЭФФЕКТИВНОСТИ СИСТЕМ РАЗРАБОТКИ
АНАЛИЗ АЛГОРИТМИЧЕСКОГО ПОДХОДА
↓
АНАЛИЗ СТРУКТУРЫ ПРИКЛАДНОЙ ПРОГРАММЫ
↓
АНАЛИЗ ЭФФЕКТИВНОСТИ СИСТЕМ РАЗРАБОТКИ

Что снижает производительность современных кластеров?
Закон Амдала
Латентность передачи по сети
Что снижает производительность современных кластеров?
Закон Амдала
Латентность передачи по сети
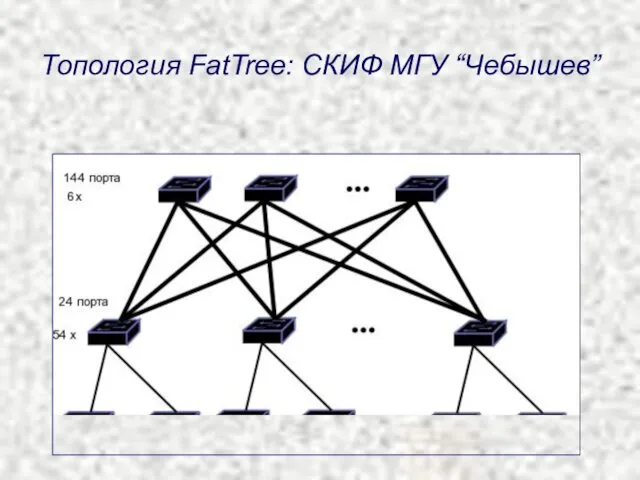
Топология FatTree: СКИФ МГУ “Чебышев”
Топология FatTree: СКИФ МГУ “Чебышев”

Что снижает производительность современных кластеров?
Закон Амдала
Латентность передачи по сети
Что снижает производительность современных кластеров?
Закон Амдала
Латентность передачи по сети

Что влияет на производительность узлов кластеров?
использование суперскалярности,
неполная загрузка конвейерных
Что влияет на производительность узлов кластеров?
использование суперскалярности,
неполная загрузка конвейерных
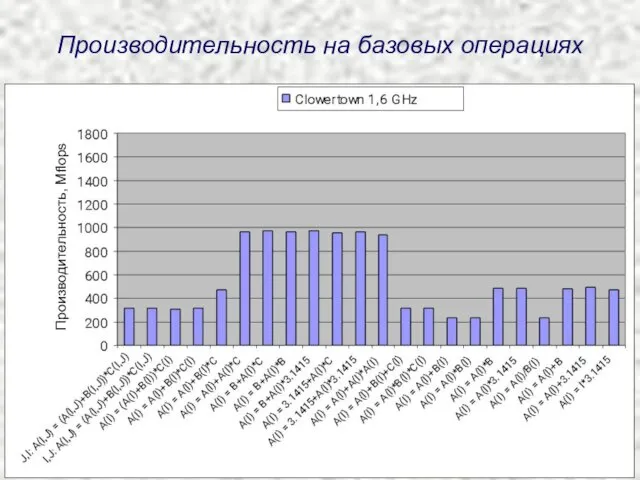
Производительность на базовых операциях
Производительность, Mflops
Производительность на базовых операциях
Производительность, Mflops
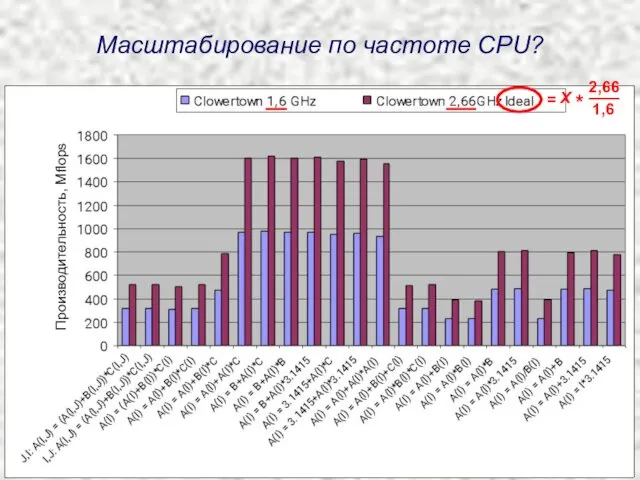
Масштабирование по частоте CPU?
Производительность, Mflops
Масштабирование по частоте CPU?
Производительность, Mflops
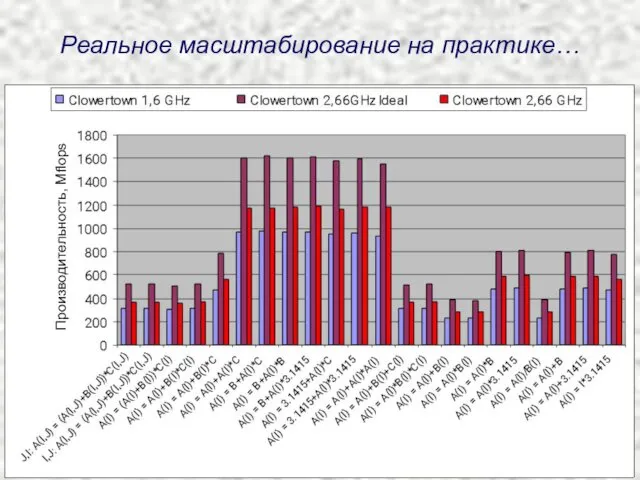
Реальное масштабирование на практике…
Производительность, Mflops
Реальное масштабирование на практике…
Производительность, Mflops

Реальное масштабирование на практике…
Clowertown – 1,6 GHz 1,066 GHz
Clowertown – 2,66 GHz 1,333
Реальное масштабирование на практике…
Clowertown – 1,6 GHz 1,066 GHz Clowertown – 2,66 GHz 1,333
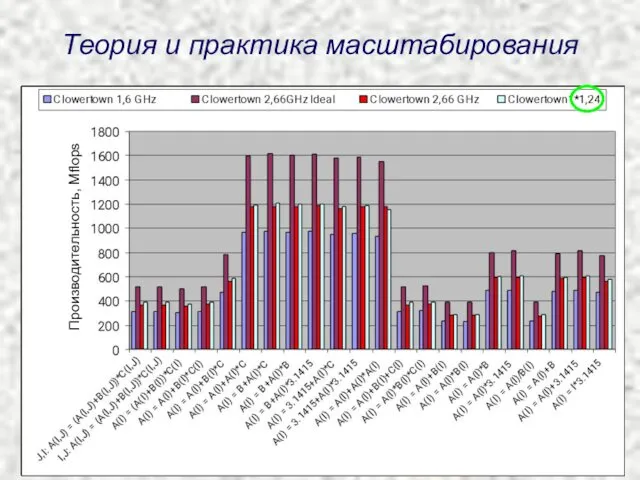
Теория и практика масштабирования
Производительность, Mflops
Теория и практика масштабирования
Производительность, Mflops
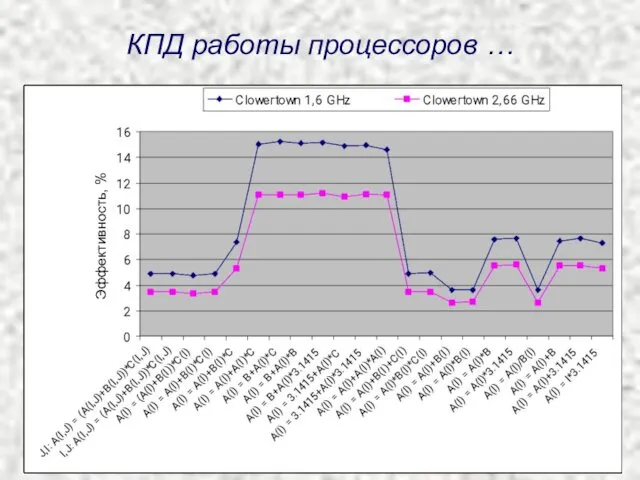
Эффективность, %
КПД работы процессоров …
Эффективность, %
КПД работы процессоров …
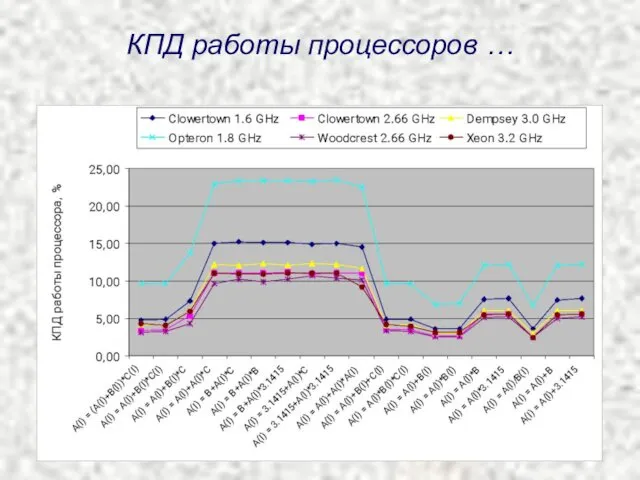
КПД работы процессоров …
КПД работы процессоров …
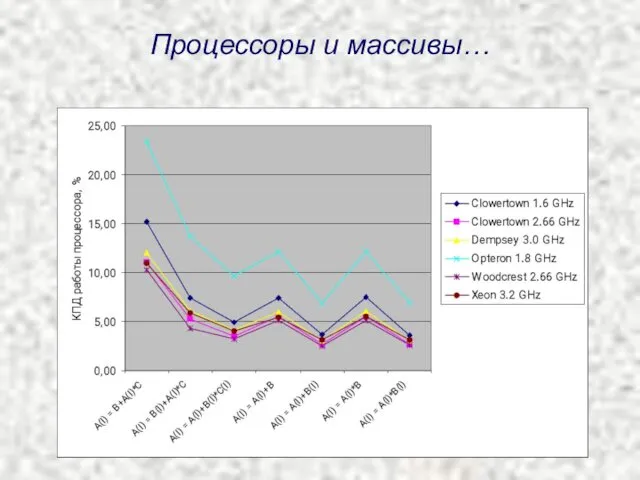
Процессоры и массивы…
Процессоры и массивы…

Простой пример. Исходный текст
for ( i = 1; i < N;
Простой пример. Исходный текст
for ( i = 1; i < N;
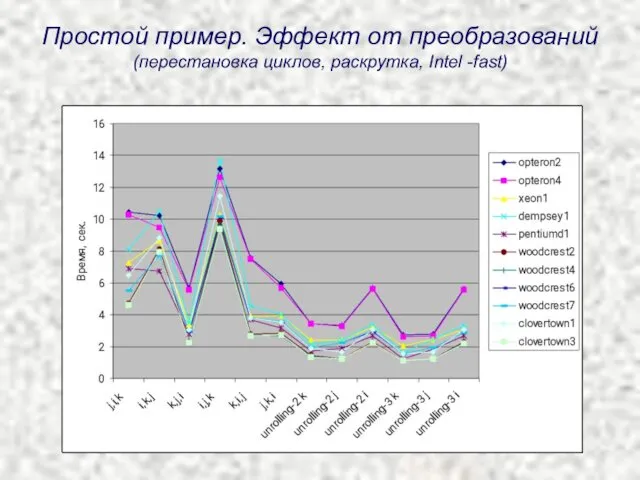
Простой пример. Эффект от преобразований
(перестановка циклов, раскрутка, Intel -fast)
Простой пример. Эффект от преобразований
(перестановка циклов, раскрутка, Intel -fast)
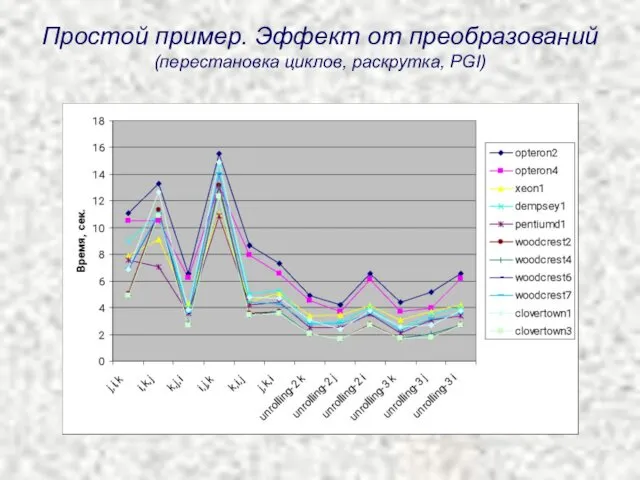
Простой пример. Эффект от преобразований
(перестановка циклов, раскрутка, PGI)
Простой пример. Эффект от преобразований
(перестановка циклов, раскрутка, PGI)
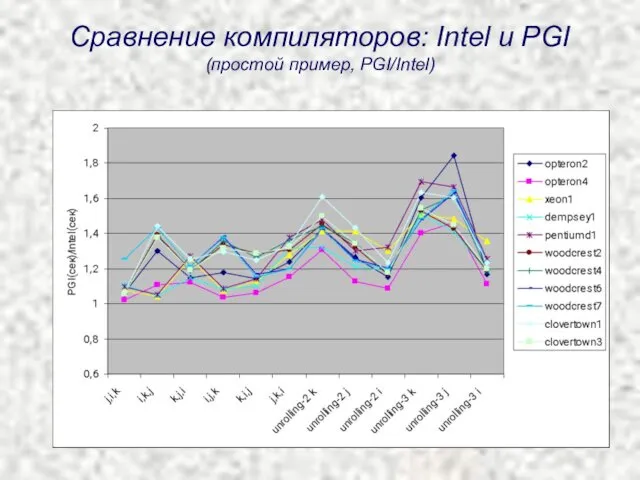
Сравнение компиляторов: Intel и PGI
(простой пример, PGI/Intel)
Сравнение компиляторов: Intel и PGI
(простой пример, PGI/Intel)

Характеристики работы
программно-аппаратной среды
Количество задач в состоянии счёта на узле
Число
Характеристики работы
программно-аппаратной среды
Количество задач в состоянии счёта на узле
Число
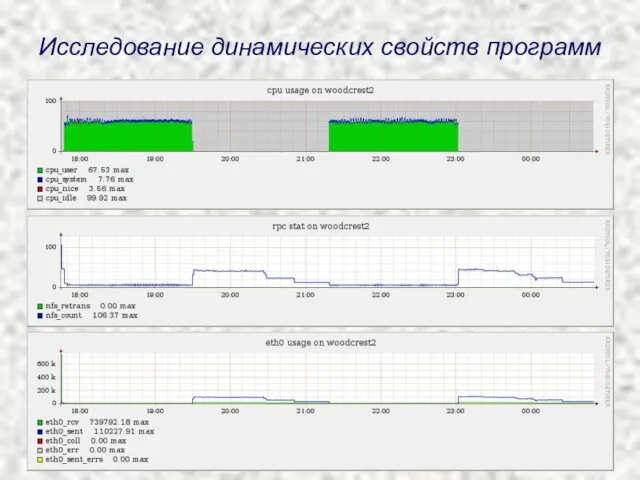
Исследование динамических свойств программ
Исследование динамических свойств программ

Исследование динамических свойств программ
Исследование динамических свойств программ
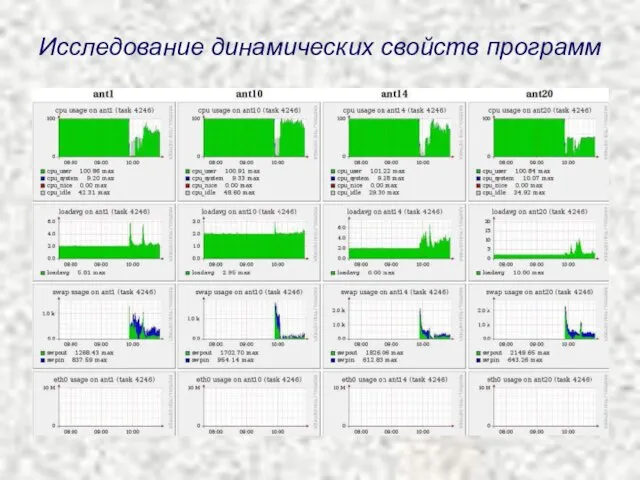
Исследование динамических свойств программ
Исследование динамических свойств программ
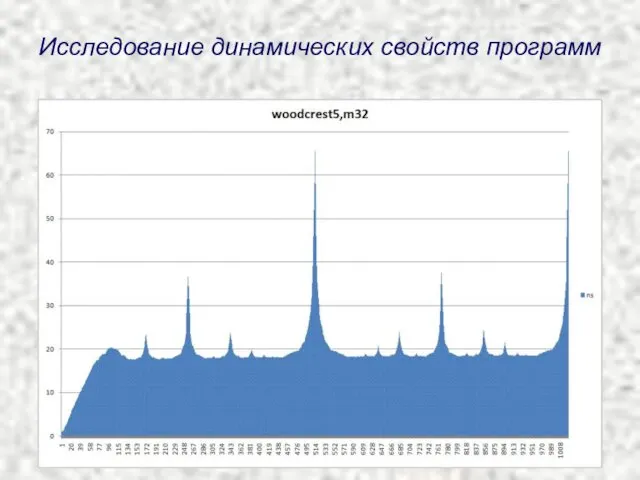
Исследование динамических свойств программ
Исследование динамических свойств программ

Сертификация эффективности
параллельных программ
• Эффективность последовательная
• Эффективность параллельная
Объекты исследования:
Задача – Алгоритм
Сертификация эффективности
параллельных программ
• Эффективность последовательная • Эффективность параллельная Объекты исследования: Задача – Алгоритм

Параллелизм – новый этап развития компьютерного мира
ОБРАЗОВАНИЕ!
ОБРАЗОВАНИЕ!
ОБРАЗОВАНИЕ!
Параллелизм – новый этап развития компьютерного мира
ОБРАЗОВАНИЕ!
ОБРАЗОВАНИЕ!
ОБРАЗОВАНИЕ!
Учебный процесс и образование
Учебный процесс и образование
Коллективный банк тестов “СИГМА”
(по параллельным вычислениям)
Коллективный банк тестов “СИГМА”
(по параллельным вычислениям)
Коллективный банк тестов “СИГМА”
(по параллельным вычислениям)
Коллективный банк тестов “СИГМА”
(по параллельным вычислениям)
Коллективный банк тестов “СИГМА”
(по параллельным вычислениям)
Коллективный банк тестов “СИГМА”
(по параллельным вычислениям)
Коллективный банк тестов “СИГМА”
(по параллельным вычислениям)
Коллективный банк тестов “СИГМА”
(по параллельным вычислениям)
Коллективный банк тестов “СИГМА”
(по параллельным вычислениям)
Коллективный банк тестов “СИГМА”
(по параллельным вычислениям)

Учебный процесс и образование
Учебный процесс и образование
 Эдом. Происхождение идумеев
Эдом. Происхождение идумеев Организация движения поездов
Организация движения поездов Иконы и фрески
Иконы и фрески С новым годом
С новым годом Правила оформления заявления на участие в конкурсе по предоставлению помещений
Правила оформления заявления на участие в конкурсе по предоставлению помещений Автопарк ГФ
Автопарк ГФ Растительные волокна
Растительные волокна Адаптации организмов
Адаптации организмов 20160324_zhenskie_obrazy_v_iskusstve
20160324_zhenskie_obrazy_v_iskusstve Березник – моя малая родина
Березник – моя малая родина Онлайн-курсы (1)
Онлайн-курсы (1) 20180304_urok_6_kl
20180304_urok_6_kl Салахова Саида
Салахова Саида День милосердия и благотворительности
День милосердия и благотворительности Предложения разные по цели высказывания
Предложения разные по цели высказывания Табиғат ресурстары
Табиғат ресурстары O Holy Night. Зимние пейзажи
O Holy Night. Зимние пейзажи Особенности транспорта
Особенности транспорта 20110802_Vzaimosvyaz_iskusstv
20110802_Vzaimosvyaz_iskusstv Сепараторы для гравитационного обогащения угля
Сепараторы для гравитационного обогащения угля Сетевая акция
Сетевая акция Оценка количественных параметров текстового документа
Оценка количественных параметров текстового документа Вакуумные уборочные машины
Вакуумные уборочные машины Don sanoati bo'yicha kadrlar buyurtmachilari va ishlab chiqarish korxonalari
Don sanoati bo'yicha kadrlar buyurtmachilari va ishlab chiqarish korxonalari Архангельская область
Архангельская область Экран состояния охраны труда в хозяйстве электрификации и электроснабжени
Экран состояния охраны труда в хозяйстве электрификации и электроснабжени Основные сведения о системах электроснабжения объектов
Основные сведения о системах электроснабжения объектов Машины для посева и посадки
Машины для посева и посадки