- Двоичный поиск в упорядоченном массиве

Содержание
- 3. Идея двоичного поиска: Возьмем средний элемент упорядоченного массива и сравним с ключом поиска «Х». Возможны варианты:
- 4. Алгоритм на псевдокоде (первая версия) Обозначим L, R – правая и левая границы рабочей части массива,
- 5. 1 2 3 4 5 6 7 8 9 10 11 12 а б б б
- 6. Рассмотрим вторую версию алгоритма, в которой уменьшим количество сравнений путем исключения из алгоритма проверки на равенство.
- 7. L: = 1, R: = n DO ( L m: = ⌊(L+R)/2⌋ IF (am ELSE R:
- 8. 1 2 3 4 5 6 7 8 9 10 11 12 а б б б
- 9. Трудоемкость двоичного поиска Сначала определим максимальное количество итераций (k). Рассмотрим худший случай, когда 1) часть массива
- 10. Трудоемкость двоичного поиска
- 12. Графики трудоемкости двоичного поиска
- 13. Сортировка данных со сложной структурой Дан массив абонентов А: Иванов Петров Абрамов 223322 345767 667891 Struct
- 14. Сортировка данных со сложной структурой Пример. Struct abonent { char name[10]; long phone; } A[n]; Попытка
- 16. Логическая функция Less (меньше) При сортировке по имени абонента: int less ( struct abonent X, struct
- 17. Наполовину пуст? Наполовину полон? Программист считает, что стакан в два раза больше, чем нужно
- 18. При сортировке по сложному ключу так же легко определить функцию less. Для сортировки по фамилии абонента
- 19. Тогда в алгоритмах сортировок вместо оператора сравнения используем вызов функции less. Например, в пузырьковой сортировке: DO
- 20. Вывод: Если структура сортируемых данных не соответствует простым (встроенным) типам языка, то операции отношения необходимо переопределить
- 21. Преимущества: 1) Операции отношения могут быть определены различными способами в зависимости от ключа сортировки и условия
- 23. Сортировка по множеству ключей Пусть рассмотренный телефонный справочник хранится в виде базы данных в памяти компьютера
- 24. Индексация данных Рассмотрим суть индексации на массиве целых чисел: 1 2 3 4 5 6 7
- 25. Чтобы упорядочить массив А (по возрастанию), мы построили индексный массив В, в него записали номера элементов
- 26. Пример. Вывод элементов массива (по возрастанию): DO ( i = 1, …, n) вывод ( А
- 27. Построение индексного массива Построение индексного массива выполняется на базе любого алгоритма сортировки. *Вначале в массив В
- 28. Построение индексного массива Алгоритм на псевдокоде (на примере пузырьковой сортировки) B := (1, 2, …, n)
- 29. Преимущества индексации 1) Появляется возможность построения нескольких различных индексов, которые можно использовать по мере необходимости. 2)
- 31. Скачать презентацию


Идея двоичного поиска: Возьмем средний элемент упорядоченного массива и сравним с
Идея двоичного поиска: Возьмем средний элемент упорядоченного массива и сравним с

Алгоритм на псевдокоде
(первая версия)
Обозначим
L, R – правая и левая
Алгоритм на псевдокоде
(первая версия)
Обозначим
L, R – правая и левая

1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10

Рассмотрим вторую версию алгоритма,
в которой
уменьшим количество сравнений
путем
Рассмотрим вторую версию алгоритма,
в которой
уменьшим количество сравнений
путем

L: = 1, R: = n
DO ( L m: = ⌊(L+R)/2⌋
IF
L: = 1, R: = n
DO ( L
IF

1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10

Трудоемкость двоичного поиска
Сначала определим
максимальное количество итераций (k).
Рассмотрим худший случай,
Трудоемкость двоичного поиска
Сначала определим
максимальное количество итераций (k).
Рассмотрим худший случай,

Трудоемкость двоичного поиска
Трудоемкость двоичного поиска

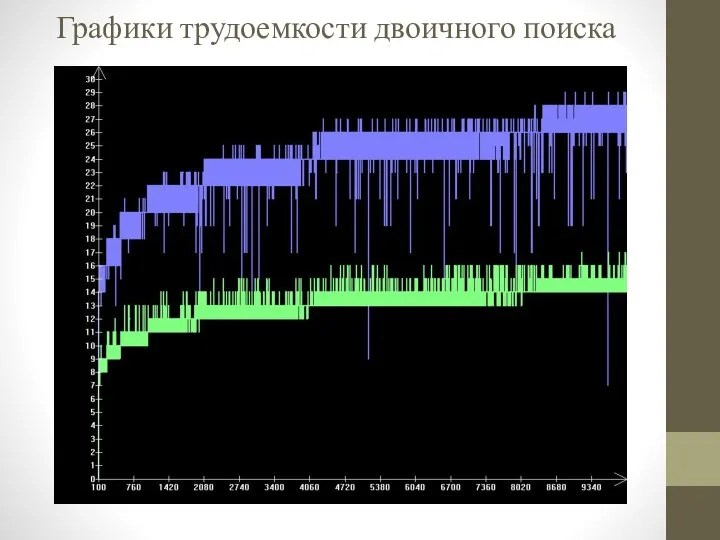
Графики трудоемкости двоичного поиска
Графики трудоемкости двоичного поиска

Сортировка данных
со сложной структурой
Дан массив абонентов
А: Иванов Петров Абрамов
Сортировка данных
со сложной структурой
Дан массив абонентов
А: Иванов Петров Абрамов
![Сортировка данных со сложной структурой Пример. Struct abonent { char name[10];](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1335596/slide-13.jpg)
Сортировка данных
со сложной структурой
Пример. Struct abonent { char name[10];
Сортировка данных
со сложной структурой
Пример. Struct abonent { char name[10];


Логическая функция Less (меньше)
При сортировке по имени абонента:
int less (
Логическая функция Less (меньше)
При сортировке по имени абонента:
int less (

Наполовину пуст?
Наполовину полон?
Программист считает, что
стакан в два раза больше, чем
Наполовину пуст?
Наполовину полон?
Программист считает, что
стакан в два раза больше, чем

При сортировке по сложному ключу так же легко определить функцию less.
Для
При сортировке по сложному ключу так же легко определить функцию less.
Для

Тогда в алгоритмах сортировок вместо оператора сравнения используем вызов функции less.
Например,
Тогда в алгоритмах сортировок вместо оператора сравнения используем вызов функции less.
Например,

Вывод:
Если структура сортируемых данных
не соответствует
простым (встроенным) типам языка, то
Вывод:
Если структура сортируемых данных
не соответствует
простым (встроенным) типам языка, то

Преимущества:
1) Операции отношения могут быть определены различными способами в зависимости от
Преимущества:
1) Операции отношения могут быть определены различными способами в зависимости от


Сортировка по множеству ключей
Пусть рассмотренный телефонный справочник хранится в виде базы
Сортировка по множеству ключей
Пусть рассмотренный телефонный справочник хранится в виде базы

Индексация данных
Рассмотрим суть индексации на массиве целых чисел:
1 2 3
Индексация данных
Рассмотрим суть индексации на массиве целых чисел:
1 2 3

Чтобы упорядочить массив А (по возрастанию),
мы построили индексный массив
Чтобы упорядочить массив А (по возрастанию),
мы построили индексный массив

Пример. Вывод элементов массива (по возрастанию):
DO ( i = 1, …,
Пример. Вывод элементов массива (по возрастанию):
DO ( i = 1, …,

Построение индексного массива
Построение индексного массива выполняется
на базе любого алгоритма сортировки.
*Вначале
Построение индексного массива
Построение индексного массива выполняется
на базе любого алгоритма сортировки.
*Вначале

Построение индексного массива
Алгоритм на псевдокоде
(на примере пузырьковой сортировки)
B
Построение индексного массива
Алгоритм на псевдокоде
(на примере пузырьковой сортировки)
B

Преимущества индексации
1) Появляется возможность построения нескольких различных индексов, которые можно
Преимущества индексации
1) Появляется возможность построения нескольких различных индексов, которые можно
 Коммуникационная кампания «Стань волонтером». Футбольный урок
Коммуникационная кампания «Стань волонтером». Футбольный урок Классный час Учителя Суздальцевой Е.В. МОУ Яхромской СОШ №2
Классный час Учителя Суздальцевой Е.В. МОУ Яхромской СОШ №2 Лекция5.ppt
Лекция5.ppt Презентация "Колесо фортуны" - скачать презентации по МХК
Презентация "Колесо фортуны" - скачать презентации по МХК Ненаркотические анальгетики
Ненаркотические анальгетики Твердотельная электроника
Твердотельная электроника Модуль числа 8 класс
Модуль числа 8 класс  Лекция 05 - Грыжи. Осложнения грыж (слайды).ppt
Лекция 05 - Грыжи. Осложнения грыж (слайды).ppt Склонение имен существительных. Несклоняемые имена существительные. урок русского языка в 4 классе
Склонение имен существительных. Несклоняемые имена существительные. урок русского языка в 4 классе  Пищевые отравления
Пищевые отравления  Зимові народні свята січня
Зимові народні свята січня Web-службы SOAP, WSDL, UDDI, GXA
Web-службы SOAP, WSDL, UDDI, GXA Нормы права: понятие, структура, виды. Тема 9
Нормы права: понятие, структура, виды. Тема 9 Кесарево сечение в современном акушерстве
Кесарево сечение в современном акушерстве  Архетипы. Коллаж
Архетипы. Коллаж В.В.Маяковский: жизнь и творчество
В.В.Маяковский: жизнь и творчество Презентация по МХК Храмы Древней Греции
Презентация по МХК Храмы Древней Греции Здоровьесберегающие технологии на логопедических занятиях
Здоровьесберегающие технологии на логопедических занятиях Программа «Беги за мной. Богучанский район»
Программа «Беги за мной. Богучанский район»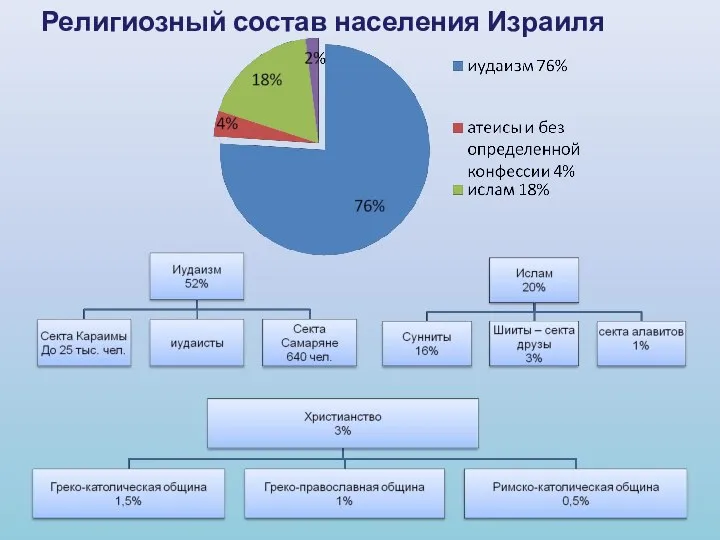 Религиозный состав населения Израиля. Иудаизм
Религиозный состав населения Израиля. Иудаизм Политическое развитие и модернизация
Политическое развитие и модернизация .Системное управление развитием ОУ
.Системное управление развитием ОУ Государственная (итоговая) аттестация выпускников 9 и 11 классов в 2012 году Светлана Юрьевна Бакулина, главный консультант управ
Государственная (итоговая) аттестация выпускников 9 и 11 классов в 2012 году Светлана Юрьевна Бакулина, главный консультант управ Проект поселения будущего
Проект поселения будущего Частные производные второго порядка
Частные производные второго порядка Схема климат. установки ПАНАСОНИК
Схема климат. установки ПАНАСОНИК Динамическое программирование Оптимальные деревья поиска
Динамическое программирование Оптимальные деревья поиска Специфика персонала, как объекта защиты
Специфика персонала, как объекта защиты