- Информационные технологии поддержки принятия решений

Содержание
- 2. Знания как основной ресурс менеджмента Управление знаниями (Knowledge Management, KM) – новая и быстро развивающаяся область
- 3. Если раньше стоимость компаний составляли финансовый капитал, здания, оборудование и другие материальные ценности, то в новой,
- 4. Управление знаниями предполагает широкое использование следующих информационных технологий: баз данных и хранилищ данных (Data Warehousing –
- 5. Системы поддержки принятия решений В 1980-е годы американские и японские компании начали развивать новые информационные системы.
- 6. Современная компания с разветвленным бизнесом, как правило, имеет: системы поддержки деятельности руководителя (Executive Support Systems -
- 7. Задачи СППР Анализ обстановки (ситуаций). Генерация возможных управленческих решений (сценарий действия). Оценка сгенерированных сценариев (действий, решений)
- 8. Основные компоненты системы поддержки принятия решения
- 9. Примеры социальных и экономических проблем, требующих анализа данных
- 10. 1. Опросы населения Мониторинг общественного мнения и анализ социально-экономической ситуации. Анализ данных нужен для выяснения ситуации
- 11. 2. Общественная безопасность Анализ преступности. Анализ данных необходим для того, чтобы понять, какие типы преступлений совершаются,
- 12. 3. Образование Планирование школьных округов. Нахождение оптимального месторасположения новых школ, в зависимости от условий района, демографической
- 13. 4. Трудоустройство Анализ рынка труда - состав и структура рабочей силы. Анализ предложений работодателей. Анализ заявлений
- 14. 5. Анализ прибыли Оценка соответствия размеров уплаченных налогов и размеров собственности. Анализ мошенничеств - выявление характеристик
- 15. 6. Здравоохранение Анализ заболеваемости населения (по самым различным факторам). Эпидемиология - выявление причин заболеваний и территорий
- 16. 7. Стратегическое планирование Анализ удовлетворенности клиентов и изучение изменений потребностей общественности. Профилирование населения. Создание более эффективных
- 17. 8. Контроль качества продукции Одна из наиболее важных прикладных областей принятия решений, приносящих наибольший доход в
- 18. 9. Бизнес Без современных методов анализа невозможно осуществить обработку огромного количества данных и принятие решений, которые
- 19. 9. Бизнес (продолжение) Предсказание рыночных временных рядов. В этой области предсказания наиболее тесно связаны с доходностью,
- 20. Современные методы добычи знаний: «Оперативная аналитическая обработка данных» (On-Line Analytical Processing или (OLAP)) и «Обнаружение знаний
- 21. Хранилища данных Основой для принятия решений является анализ данных, выявление скрытых закономерностей и знаний, содержащихся в
- 22. Зачем строить хранилища данных - ведь они содержат заведомо избыточную информацию, которая и так есть в
- 23. Технология OLAP – это инструмент оперативного анализа данных, содержащихся в хранилище. Главной особенностью является то, что
- 24. Обнаружение знаний в базах данных (Knowledge discovery in databases (KDD) или Data Mining – «раскопка» данных)
- 25. Основные направления углубленного анализа данных (KDD) Можно выделить пять основных типов задач анализа данных, для решения
- 26. Интеллектуальные системы компьютерного анализа данных могут основываться на двух подходах: Первый заключается в том, что в
- 27. Экспертные системы Экспертная система — это программа для компьютера, которая оперирует со знаниями в определенной предметной
- 28. Проблемы ставятся перед системой в виде совокупности фактов, описывающих некоторую ситуацию, и система с помощью базы
- 29. Более перспективен второй подход, который основан на анализе данных с помощью статистических пакетов или нейронных сетей.
- 30. Поиск ассоциативных правил Ассоциативные правила позволяют находить закономерности между связанными событиями. Примером такого правила, служит утверждение,
- 31. Ассоциативным правилом называется правило «если X, то Y» Другими словами, целью анализа является установление следующих зависимостей:
- 32. Транзакцией называется некоторая последовательность действий, представляющих единое целое, например покупка человеком товаров в магазине. Поддержкой ассоциативного
- 33. Задача нахождения ассоциативных правил разбивается на две подзадачи: Нахождение всех наборов элементов, которые удовлетворяют некоторому заданному
- 36. Классификация данных и извлечение правил из данных. «Дерево решений» как пример экспертной системы «Дерево решений» (Decision
- 37. У каждого клиента 6 параметров (переменных) Зависимая (целевая) переменная – кредитный рейтинг. Два возможных значения: 0
- 38. Эти данные – результат исследований, направленных на выяснение характеристик клиентов, позволяющих выяснить, какие из них позволяют
- 39. Пояснения после решения примера Что получено: Набор правил, позволяющий на основе знания объясняющих переменных предсказать результативную
- 40. Можно сохранить обученное дерево решений и применять сохранённый алгоритм для предсказания кредитного рейтинга клиента. Очевидно, что
- 41. Дискриминантный анализ Дискриминантный анализ включает в себя методы классификации наблюдений в ситуации, когда исследователь обладает достаточно
- 42. Метод может применяться во всех случаях, когда на основании уже имеющейся информации, требуется отнести новый случай
- 43. Графическая интерпретация Принципы дискриминантного анализа можно пояснить графически для простого случая, когда объекты надо распределить на
- 44. Далее вычисляются координаты центров этих множеств (координаты центроидов групп – по терминологии дискриминантного анализа). На рисунке
- 45. Через центроиды проводится прямая (синяя), а через точку, находящуюся на равном расстоянии от центроидов, проводится линия
- 46. Таким образом, обучающая выборка позволяет построить новую систему координат (синяя и фиолетовая линии), которая и позволяет
- 47. У каждого клиента 6 параметров (переменных) Зависимая (целевая) переменная – кредитный рейтинг. Два возможных значения: 0
- 48. Снова все данные разобьём на обучающую выборку (70%) и тестовую (30%) с помощью введения дополнительной переменной,
- 50. Пояснения после решения примера Основные результаты – в таблице Результаты классификации Алгоритм дискриминантного анализа может исключать
- 51. SPSS и PASW PASW (Predictive Analytics Software) это «бывшая» SPSS (Statistical Package for Social Science) (после
- 52. Манипуляция данными, импорт, экспорт файлов с сохранением в различных форматах. Получение описательной статистики (среднее, дисперсия и
- 53. Как представлять данные для анализа? (типы статистических шкал в PASW) Практически все известные пакеты анализа данных
- 54. Номинативная (категориальная) шкала является самым «низким» уровнем измерения. В этом случае числовое значение приписывается переменным произвольно.
- 55. Ясно, что переменные, измеренные в этой шкале, нельзя подвергать никаким арифметическим, алгебраическим или логическим операциям. Для
- 56. Порядковая шкала применяется, если переменная выражает степень проявления какого либо свойства, и ее значения могут быть
- 57. Интервальная шкала предполагает, что можно определить не только порядок значений, но и расстояние между значениями. Эта
- 58. Шкала отношений. Для переменных, измеренных в этой шкале, определены все арифметические и логические операции, которые можно
- 59. Кластерный анализ
- 60. Кластерный анализ ставит перед собой задачу классификации объектов. Синонимами термина «кластерный анализ» являются «автоматическая классификация объектов
- 61. Кластерный анализ рационально использовать на ранних стадиях исследования, когда о данных мало что известно. Методы автоматического
- 62. Виды кластерного анализа (реализованы в PASW) Метод К- средних (или итерационный метод). Метод используется при достаточно
- 63. Пусть, например, необходимо выделить К кластеров. На первом шаге вычисляются (или задаются пользователем) координаты К центров
- 65. Анализ результатов примера Оказалось, что около 80% «плохих» заемщиков попали в один кластер, что позволяет для
- 66. Иерархический кластерный анализ. Метод используется при сравнительно небольшом числе объектов (до нескольких сотен). Сущность метода состоит
- 67. Простой пример для иллюстрации алгоритма иерархического кластерного анализа Пусть имеется четыре объекта, для которых рассчитана матрица
- 68. На последнем шаге в кластер будет включен четвертый объект, имеющий наименьшее расстояние до первого объекта, включенного
- 69. Алгоритм иерархического кластерного анализа, реализованный в PASW, очень похож на описанный выше. Шкала расстояний при построении
- 70. Факторный анализ
- 71. Факторный анализ это процедура, с помощью которой большое число переменных, характеризующих имеющиеся наблюдения, сводится к меньшему
- 72. Алгоритм факторного анализа несложен, но описывается громоздкими математическими выражениями, поэтому ограничимся простейшим примером, допускающим графическую интерпретацию.
- 73. Видно, что есть определённая закономерность в расположении точек (между ценой автомобиля и ресурсом его двигателя есть
- 74. Отыскание такой новой системы координат и нахождение взаимосвязи «новых» координат f1 f2 (называемых факторами) и «старых»
- 75. Простой пример (не следует рассматривать всерьез в содержательном аспекте) Пятью респондентами, желающими приобрести путёвки на курорт,
- 76. Вопрос: нельзя ли передать смысл ответов респондентов меньшим числом переменных? (Не четырьмя, а тремя, двумя или,
- 77. Регрессионный анализ и прогнозирование
- 78. Задачей регрессионного анализа является построение математической модели взаимосвязи явлений на основе имеющихся данных об этих явлениях.
- 79. Регрессионные модели – это модели взаимосвязи, сформулированные в виде функциональной зависимости результативной (зависимой) переменной от одной
- 81. Будем считать вес – результативной переменной, а рост – факторной Если данные о росте и весе
- 82. На первом шаге регрессионного анализа исследователь должен выбрать вид зависимости между факторным и результативным признаками. Вид
- 83. После выбора вида зависимости можно начать регрессионный анализ. Первое, что должен сделать регрессионный анализ – это
- 84. Математически критерий «максимальной близости» прямой к наблюдаемым значениям yi , - это минимальность значения суммы квадратов
- 85. Основные результаты регрессионного анализа рассмотренного примера:
- 86. Расчеты статистической значимости в регрессионном анализе базируются на обычных статистических процедурах «проверки гипотез». Выдвигается «нулевая гипотеза»
- 87. Добавим в рассматриваемый пример еще одну переменную предиктор – возраст. Это соответствует предположению, что на вес
- 88. Можно сделать вывод о том, что по наблюдаемым данным вес не зависит от возраста (константа b2
- 89. Логистическая регрессия Эта разновидность регрессионного анализа применяется не для изучения взаимосвязи явлений, а для решения задач
- 90. Рассмотрим наиболее простой случай – случай бинарной логистической регрессии. В этом случае зависимая переменная y может
- 92. Выявление взаимосвязи явлений Корреляционный анализ
- 93. В задачах корреляционного анализа требуется установить наличие взаимосвязи между изучаемыми явлениями (вычислить коэффициент корреляции и оценить
- 94. Пример вычисления коэффициента корреляции по Пирсону Данные о «параметрах» футболистов сборной России по футболу «образца» 2008
- 95. Таблицы сопряжённости и критерий χ2 Таблицы сопряженности (или «перекрестные распределения») служат для выявления зависимости между двумя
- 96. Всего 2008 человек опрошено в Украине и 1600 в России. Вопрос: есть ли взаимосвязь между мнением
- 97. В «переводе» на язык статистики задача выглядит так: есть две переменные: первая переменная – это «страна»
- 98. Если бы числа ответов респондентов были бы равны ожидаемым частотам – это означало бы, что мнения
- 99. Построение экспертных систем на основе нейронных сетей
- 100. Задачи анализа данных, решаемые с помощью нейронных сетей Выявление взаимосвязей и прогнозирование Классификация Кластеризация Классификация и
- 101. Нейронные сети как средство анализа данных Под нейронными сетями понимаются вычислительные структуры, которые моделируют процессы хранения
- 102. Элементарным преобразователем данных в нейронных сетях является нейрон, названный так по аналогии с биологическим прототипом, который,
- 103. Схема «биологического» нейрона
- 104. Схема формального нейрона
- 105. Если на входе сигналы: x1, x2… xn, то на выходе из ядра возникает итоговый сигнал S
- 106. Классификация нейронных сетей В многослойных или слоистых нейронных сетях нейроны объединяются в слои. Слой содержит совокупность
- 107. Слои в нейронных сетях
- 108. «Обучение» нейронной сети. Алгоритм обратного распространения ошибок В классическом алгоритме обучения (алгоритм обратного распространения ошибки) в
- 109. В классическом алгоритме подстройка весов синапсов происходит после предъявления нейронной сети каждого примера Более быстрые алгоритмы
- 110. Для того чтобы сеть могла анализировать данные, она должна иметь достаточный уровень сложности. Для приближенной оценки
- 111. Такое приближенное определение числа нейронов еще не гарантирует хорошие прогностические качества нейронной сети. Решением проблемы служит
- 112. Пример задачи прогнозирования Есть данные о средних за текущую неделю характеристиках фондового рынка: х1 – доходность
- 114. Скачать презентацию

Знания как основной ресурс менеджмента
Управление знаниями (Knowledge Management, KM) –
Знания как основной ресурс менеджмента
Управление знаниями (Knowledge Management, KM) –

Если раньше стоимость компаний составляли финансовый капитал, здания, оборудование и другие
Если раньше стоимость компаний составляли финансовый капитал, здания, оборудование и другие

Управление знаниями предполагает широкое использование следующих информационных технологий:
баз данных и хранилищ
Управление знаниями предполагает широкое использование следующих информационных технологий:
баз данных и хранилищ

Системы поддержки принятия решений
В 1980-е годы американские и японские компании начали
Системы поддержки принятия решений
В 1980-е годы американские и японские компании начали

Современная компания с разветвленным бизнесом, как правило, имеет:
системы поддержки деятельности
Современная компания с разветвленным бизнесом, как правило, имеет:
системы поддержки деятельности

Задачи СППР
Анализ обстановки (ситуаций).
Генерация возможных управленческих решений (сценарий действия).
Задачи СППР
Анализ обстановки (ситуаций).
Генерация возможных управленческих решений (сценарий действия).
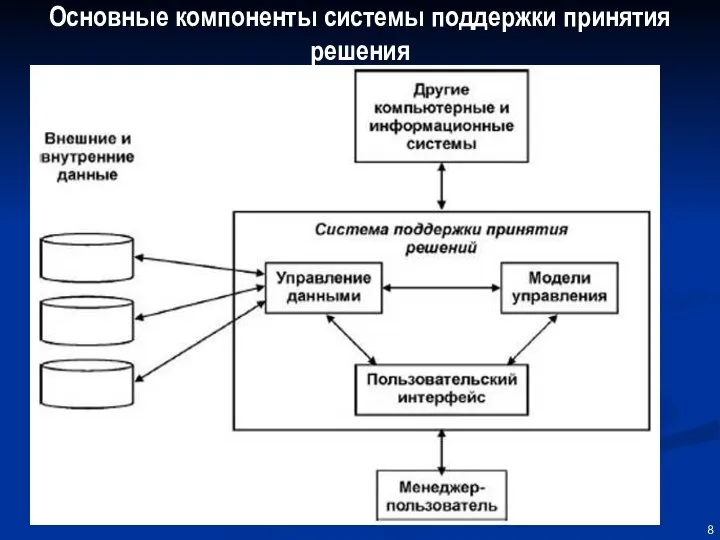
Основные компоненты системы поддержки принятия решения
Основные компоненты системы поддержки принятия решения

Примеры социальных и экономических проблем, требующих анализа данных
Примеры социальных и экономических проблем, требующих анализа данных

1. Опросы населения
Мониторинг общественного мнения и анализ социально-экономической ситуации. Анализ данных
1. Опросы населения
Мониторинг общественного мнения и анализ социально-экономической ситуации. Анализ данных

2. Общественная безопасность
Анализ преступности. Анализ данных необходим для того, чтобы понять,
2. Общественная безопасность
Анализ преступности. Анализ данных необходим для того, чтобы понять,

3. Образование
Планирование школьных округов. Нахождение оптимального месторасположения новых школ, в зависимости
3. Образование
Планирование школьных округов. Нахождение оптимального месторасположения новых школ, в зависимости

4. Трудоустройство
Анализ рынка труда - состав и структура рабочей силы. Анализ
4. Трудоустройство
Анализ рынка труда - состав и структура рабочей силы. Анализ

5. Анализ прибыли
Оценка соответствия размеров уплаченных налогов и размеров собственности.
Анализ мошенничеств
5. Анализ прибыли
Оценка соответствия размеров уплаченных налогов и размеров собственности.
Анализ мошенничеств

6. Здравоохранение
Анализ заболеваемости населения (по самым различным факторам).
Эпидемиология - выявление причин
6. Здравоохранение
Анализ заболеваемости населения (по самым различным факторам).
Эпидемиология - выявление причин

7. Стратегическое планирование
Анализ удовлетворенности клиентов и изучение изменений потребностей общественности.
Профилирование населения.
7. Стратегическое планирование
Анализ удовлетворенности клиентов и изучение изменений потребностей общественности.
Профилирование населения.

8. Контроль качества продукции
Одна из наиболее важных прикладных областей принятия решений,
8. Контроль качества продукции
Одна из наиболее важных прикладных областей принятия решений,

9. Бизнес
Без современных методов анализа невозможно осуществить обработку огромного количества данных
9. Бизнес
Без современных методов анализа невозможно осуществить обработку огромного количества данных

9. Бизнес (продолжение)
Предсказание рыночных временных рядов. В этой области предсказания наиболее
9. Бизнес (продолжение)
Предсказание рыночных временных рядов. В этой области предсказания наиболее

Современные методы добычи знаний:
«Оперативная аналитическая обработка данных»
(On-Line Analytical Processing или
Современные методы добычи знаний: «Оперативная аналитическая обработка данных» (On-Line Analytical Processing или

Хранилища данных
Основой для принятия решений является анализ данных, выявление скрытых закономерностей
Хранилища данных
Основой для принятия решений является анализ данных, выявление скрытых закономерностей

Зачем строить хранилища данных - ведь они содержат заведомо избыточную информацию,
Зачем строить хранилища данных - ведь они содержат заведомо избыточную информацию,

Технология OLAP – это инструмент оперативного анализа данных, содержащихся в хранилище.
Главной
Технология OLAP – это инструмент оперативного анализа данных, содержащихся в хранилище.
Главной

Обнаружение знаний в базах данных
(Knowledge discovery in databases (KDD)
или
Обнаружение знаний в базах данных (Knowledge discovery in databases (KDD) или

Основные направления углубленного анализа данных (KDD)
Можно выделить пять основных типов задач
Основные направления углубленного анализа данных (KDD)
Можно выделить пять основных типов задач

Интеллектуальные системы компьютерного анализа данных могут основываться на двух подходах:
Первый заключается
Интеллектуальные системы компьютерного анализа данных могут основываться на двух подходах:
Первый заключается

Экспертные системы
Экспертная система — это программа для компьютера, которая оперирует со
Экспертные системы
Экспертная система — это программа для компьютера, которая оперирует со

Проблемы ставятся перед системой в виде совокупности фактов, описывающих некоторую ситуацию,
Проблемы ставятся перед системой в виде совокупности фактов, описывающих некоторую ситуацию,

Более перспективен второй подход, который основан на анализе данных с помощью
Более перспективен второй подход, который основан на анализе данных с помощью

Поиск ассоциативных правил
Ассоциативные правила позволяют находить закономерности между связанными событиями.
Поиск ассоциативных правил
Ассоциативные правила позволяют находить закономерности между связанными событиями.

Ассоциативным правилом называется правило «если X, то Y»
Другими словами, целью анализа
Ассоциативным правилом называется правило «если X, то Y»
Другими словами, целью анализа

Транзакцией называется некоторая последовательность действий, представляющих единое целое, например покупка человеком
Транзакцией называется некоторая последовательность действий, представляющих единое целое, например покупка человеком

Задача нахождения ассоциативных правил разбивается на две подзадачи:
Нахождение всех наборов
Задача нахождения ассоциативных правил разбивается на две подзадачи:
Нахождение всех наборов
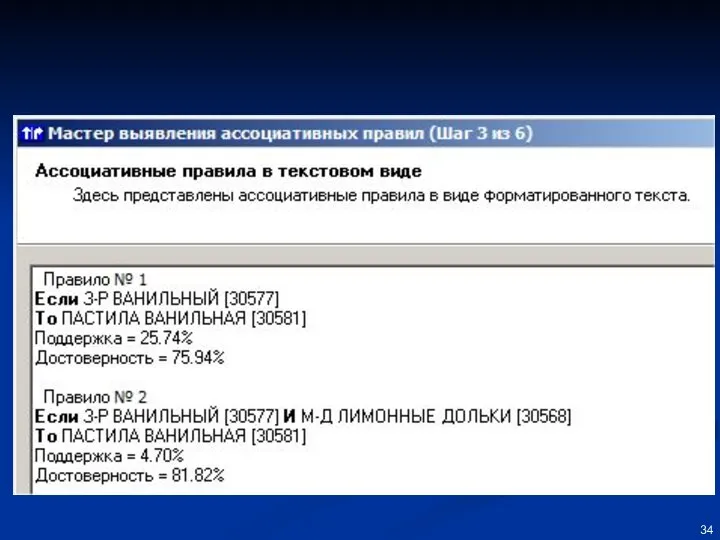
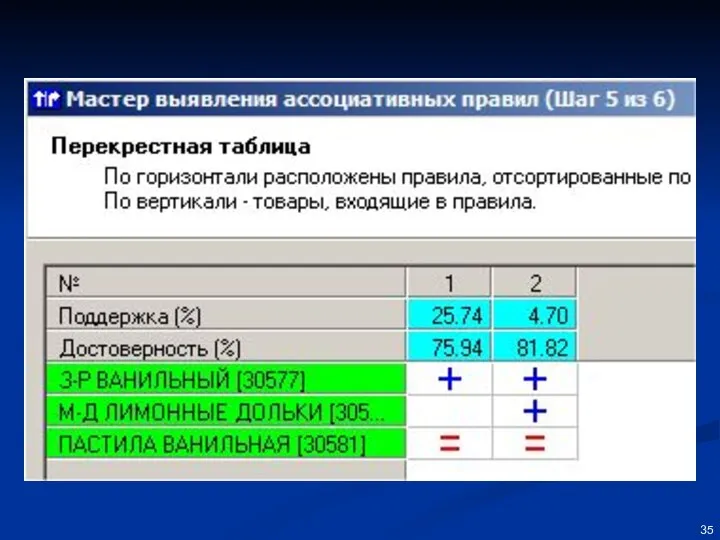

Классификация данных и извлечение правил из данных.
«Дерево решений» как пример экспертной
Классификация данных и извлечение правил из данных. «Дерево решений» как пример экспертной

У каждого клиента 6 параметров (переменных)
Зависимая (целевая) переменная – кредитный рейтинг.
У каждого клиента 6 параметров (переменных)
Зависимая (целевая) переменная – кредитный рейтинг.

Эти данные – результат исследований, направленных на выяснение характеристик клиентов, позволяющих
Эти данные – результат исследований, направленных на выяснение характеристик клиентов, позволяющих

Пояснения после решения примера
Что получено:
Набор правил, позволяющий на основе знания
Пояснения после решения примера
Что получено:
Набор правил, позволяющий на основе знания

Можно сохранить обученное дерево решений и применять сохранённый алгоритм для предсказания
Можно сохранить обученное дерево решений и применять сохранённый алгоритм для предсказания

Дискриминантный анализ
Дискриминантный анализ включает в себя методы классификации наблюдений в ситуации,
Дискриминантный анализ
Дискриминантный анализ включает в себя методы классификации наблюдений в ситуации,

Метод может применяться во всех случаях, когда на основании уже имеющейся
Метод может применяться во всех случаях, когда на основании уже имеющейся

Графическая интерпретация
Принципы дискриминантного анализа можно пояснить графически для простого случая, когда
Графическая интерпретация
Принципы дискриминантного анализа можно пояснить графически для простого случая, когда
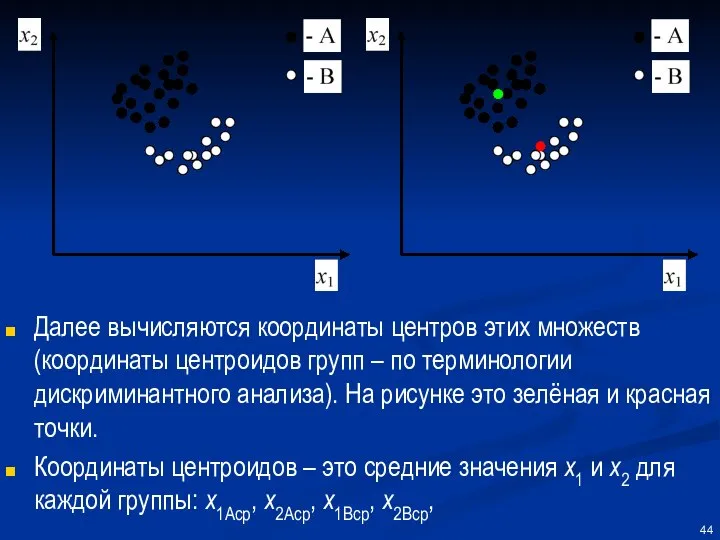
Далее вычисляются координаты центров этих множеств (координаты центроидов групп – по
Далее вычисляются координаты центров этих множеств (координаты центроидов групп – по
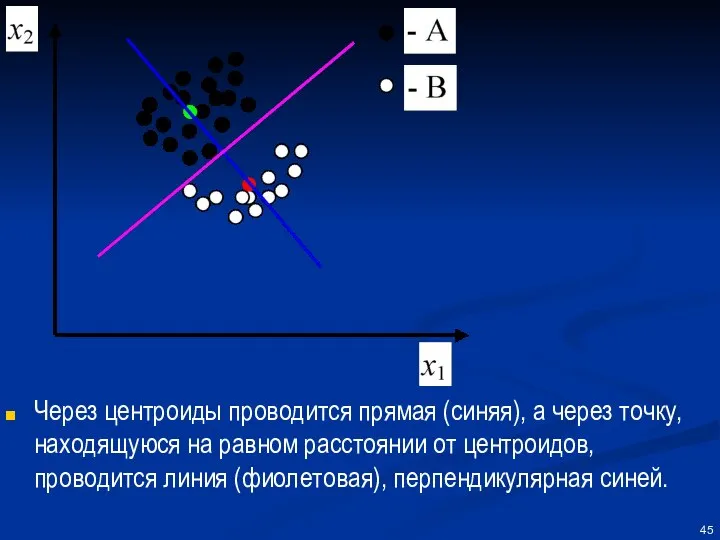
Через центроиды проводится прямая (синяя), а через точку, находящуюся на равном
Через центроиды проводится прямая (синяя), а через точку, находящуюся на равном

Таким образом, обучающая выборка позволяет построить новую систему координат (синяя и
Таким образом, обучающая выборка позволяет построить новую систему координат (синяя и

У каждого клиента 6 параметров (переменных)
Зависимая (целевая) переменная – кредитный рейтинг.
У каждого клиента 6 параметров (переменных)
Зависимая (целевая) переменная – кредитный рейтинг.
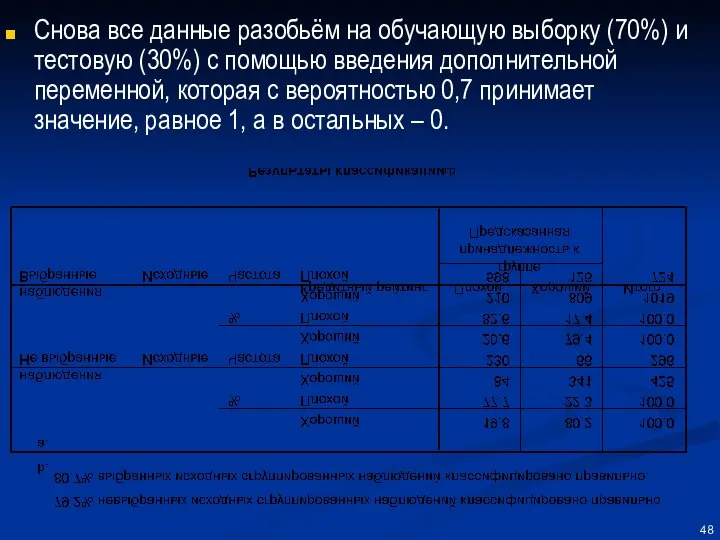
Снова все данные разобьём на обучающую выборку (70%) и тестовую (30%)
Снова все данные разобьём на обучающую выборку (70%) и тестовую (30%)


Пояснения после решения примера
Основные результаты – в таблице Результаты классификации
Алгоритм дискриминантного
Пояснения после решения примера
Основные результаты – в таблице Результаты классификации
Алгоритм дискриминантного

SPSS и PASW
PASW (Predictive Analytics Software) это «бывшая» SPSS (Statistical Package
SPSS и PASW
PASW (Predictive Analytics Software) это «бывшая» SPSS (Statistical Package

Манипуляция данными, импорт, экспорт файлов с сохранением в различных форматах.
Получение описательной
Манипуляция данными, импорт, экспорт файлов с сохранением в различных форматах.
Получение описательной

Как представлять данные для анализа?
(типы статистических шкал в PASW)
Практически все известные
Как представлять данные для анализа?
(типы статистических шкал в PASW)
Практически все известные

Номинативная (категориальная) шкала является самым «низким» уровнем измерения. В этом случае
Номинативная (категориальная) шкала является самым «низким» уровнем измерения. В этом случае

Ясно, что переменные, измеренные в этой шкале, нельзя подвергать никаким арифметическим,
Ясно, что переменные, измеренные в этой шкале, нельзя подвергать никаким арифметическим,

Порядковая шкала применяется, если переменная выражает степень проявления какого либо свойства,
Порядковая шкала применяется, если переменная выражает степень проявления какого либо свойства,

Интервальная шкала предполагает, что можно определить не только порядок значений, но
Интервальная шкала предполагает, что можно определить не только порядок значений, но

Шкала отношений.
Для переменных, измеренных в этой шкале, определены все арифметические
Шкала отношений. Для переменных, измеренных в этой шкале, определены все арифметические

Кластерный анализ
Кластерный анализ

Кластерный анализ ставит перед собой задачу классификации объектов.
Синонимами термина
Кластерный анализ ставит перед собой задачу классификации объектов. Синонимами термина

Кластерный анализ рационально использовать на ранних стадиях исследования, когда о данных
Кластерный анализ рационально использовать на ранних стадиях исследования, когда о данных

Виды кластерного анализа (реализованы в PASW)
Метод К- средних (или итерационный метод).
Метод
Виды кластерного анализа (реализованы в PASW)
Метод К- средних (или итерационный метод). Метод

Пусть, например, необходимо выделить К кластеров.
На первом шаге вычисляются (или задаются
Пусть, например, необходимо выделить К кластеров. На первом шаге вычисляются (или задаются

Анализ результатов примера
Оказалось, что около 80% «плохих» заемщиков попали в один
Анализ результатов примера
Оказалось, что около 80% «плохих» заемщиков попали в один

Иерархический кластерный анализ.
Метод используется при сравнительно небольшом числе объектов (до нескольких
Иерархический кластерный анализ. Метод используется при сравнительно небольшом числе объектов (до нескольких
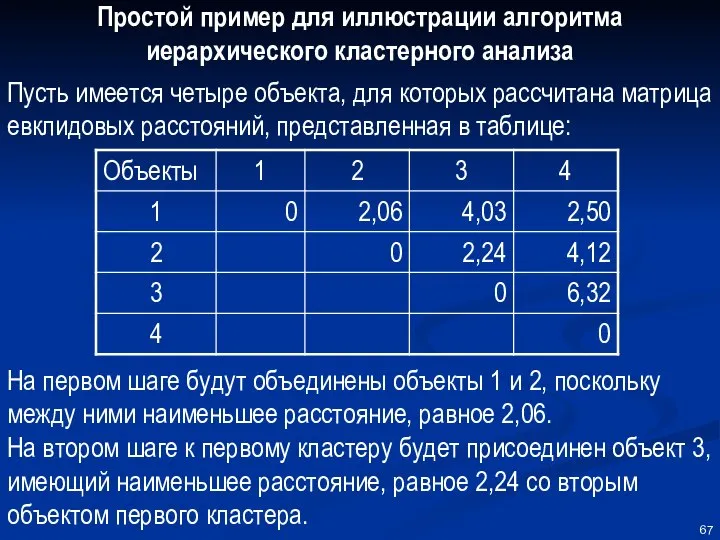
Простой пример для иллюстрации алгоритма иерархического кластерного анализа
Пусть имеется четыре объекта,
Простой пример для иллюстрации алгоритма иерархического кластерного анализа
Пусть имеется четыре объекта,

На последнем шаге в кластер будет включен четвертый объект, имеющий наименьшее
На последнем шаге в кластер будет включен четвертый объект, имеющий наименьшее

Алгоритм иерархического кластерного анализа, реализованный в PASW, очень похож на описанный
Алгоритм иерархического кластерного анализа, реализованный в PASW, очень похож на описанный

Факторный анализ
Факторный анализ

Факторный анализ это процедура, с помощью которой большое число переменных, характеризующих
Факторный анализ это процедура, с помощью которой большое число переменных, характеризующих
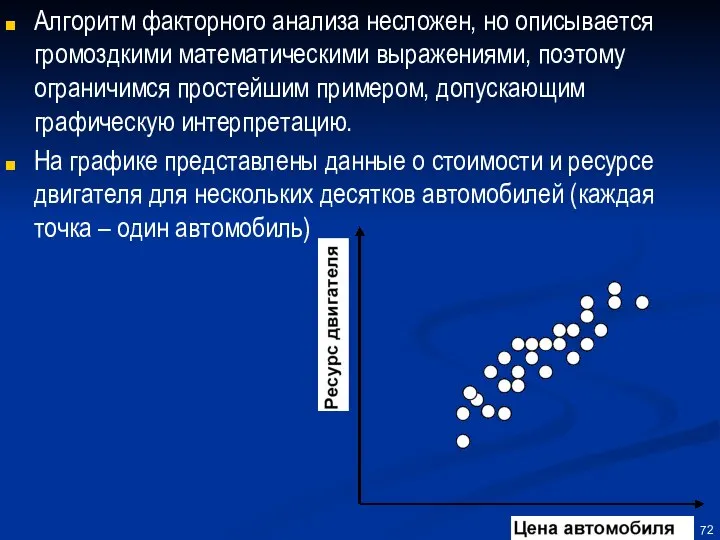
Алгоритм факторного анализа несложен, но описывается громоздкими математическими выражениями, поэтому ограничимся
Алгоритм факторного анализа несложен, но описывается громоздкими математическими выражениями, поэтому ограничимся
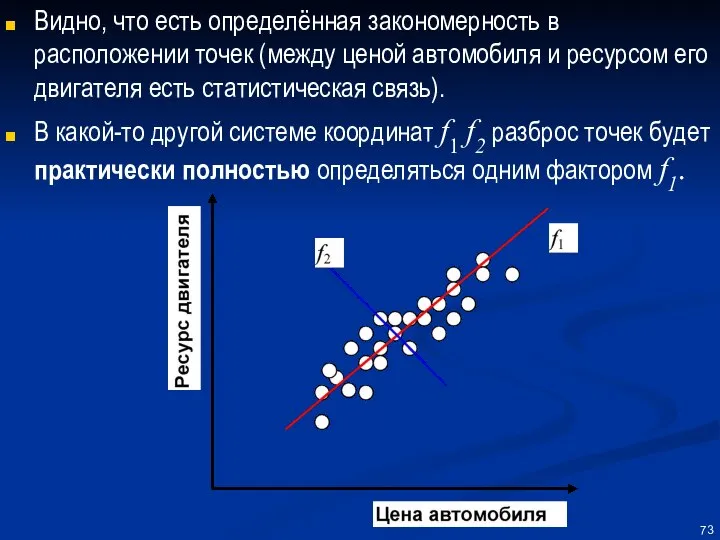
Видно, что есть определённая закономерность в расположении точек (между ценой автомобиля
Видно, что есть определённая закономерность в расположении точек (между ценой автомобиля

Отыскание такой новой системы координат и нахождение взаимосвязи «новых» координат f1
Отыскание такой новой системы координат и нахождение взаимосвязи «новых» координат f1
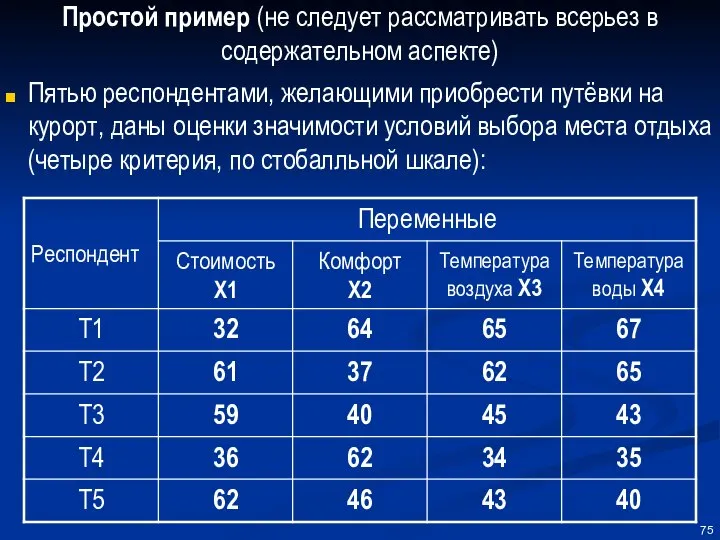
Простой пример (не следует рассматривать всерьез в содержательном аспекте)
Пятью респондентами, желающими
Простой пример (не следует рассматривать всерьез в содержательном аспекте)
Пятью респондентами, желающими
Вопрос: нельзя ли передать смысл ответов респондентов меньшим числом переменных?
(Не четырьмя,
Вопрос: нельзя ли передать смысл ответов респондентов меньшим числом переменных? (Не четырьмя,

Регрессионный анализ и прогнозирование
Регрессионный анализ и прогнозирование

Задачей регрессионного анализа является построение математической модели взаимосвязи явлений на основе
Задачей регрессионного анализа является построение математической модели взаимосвязи явлений на основе

Регрессионные модели – это модели взаимосвязи, сформулированные в виде функциональной зависимости
Регрессионные модели – это модели взаимосвязи, сформулированные в виде функциональной зависимости
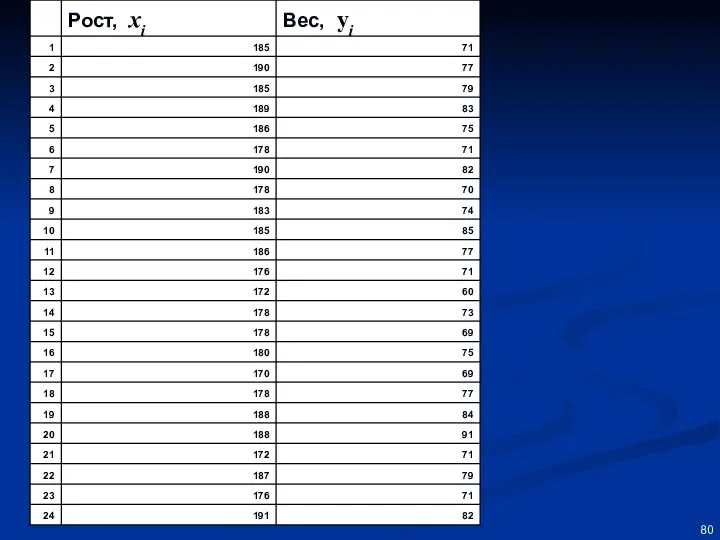
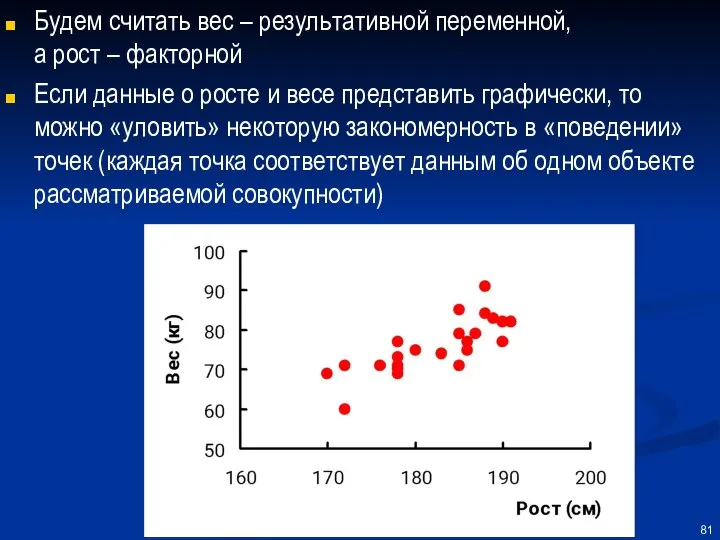
Будем считать вес – результативной переменной,
а рост – факторной
Если данные
Будем считать вес – результативной переменной,
а рост – факторной
Если данные

На первом шаге регрессионного анализа исследователь должен выбрать вид зависимости между
На первом шаге регрессионного анализа исследователь должен выбрать вид зависимости между
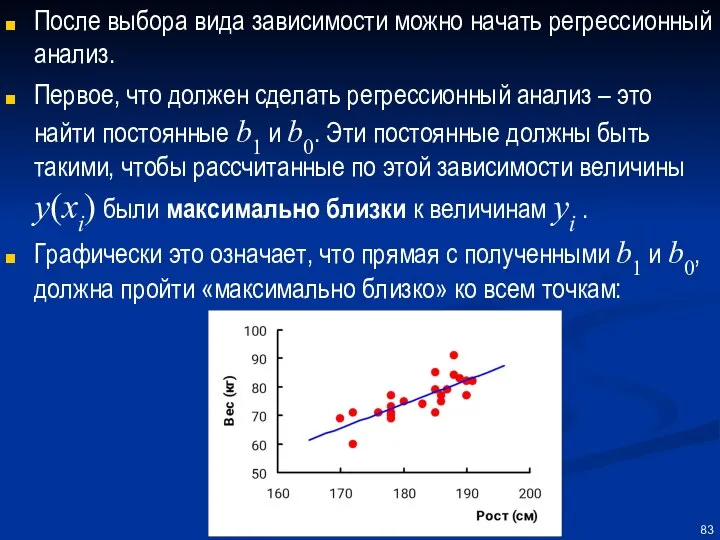
После выбора вида зависимости можно начать регрессионный анализ.
Первое, что должен сделать
После выбора вида зависимости можно начать регрессионный анализ.
Первое, что должен сделать

Математически критерий «максимальной близости» прямой к наблюдаемым значениям yi , -
Математически критерий «максимальной близости» прямой к наблюдаемым значениям yi , -
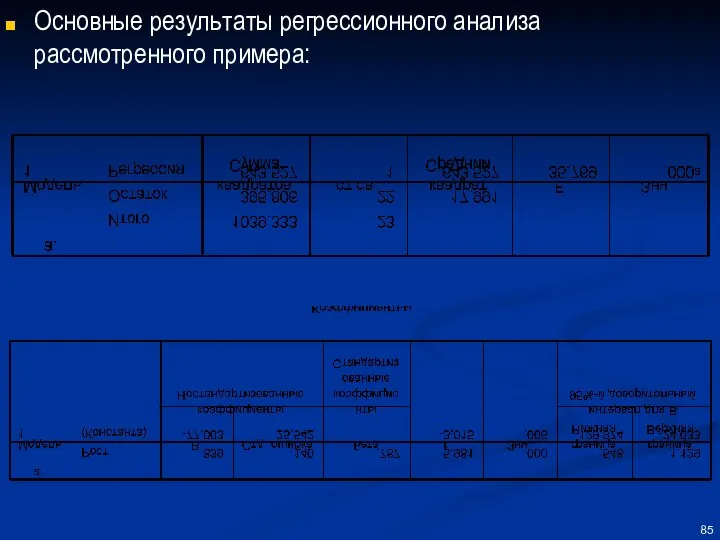
Основные результаты регрессионного анализа рассмотренного примера:
Основные результаты регрессионного анализа рассмотренного примера:

Расчеты статистической значимости в регрессионном анализе базируются на обычных статистических процедурах
Расчеты статистической значимости в регрессионном анализе базируются на обычных статистических процедурах

Добавим в рассматриваемый пример еще одну переменную предиктор – возраст. Это
Добавим в рассматриваемый пример еще одну переменную предиктор – возраст. Это
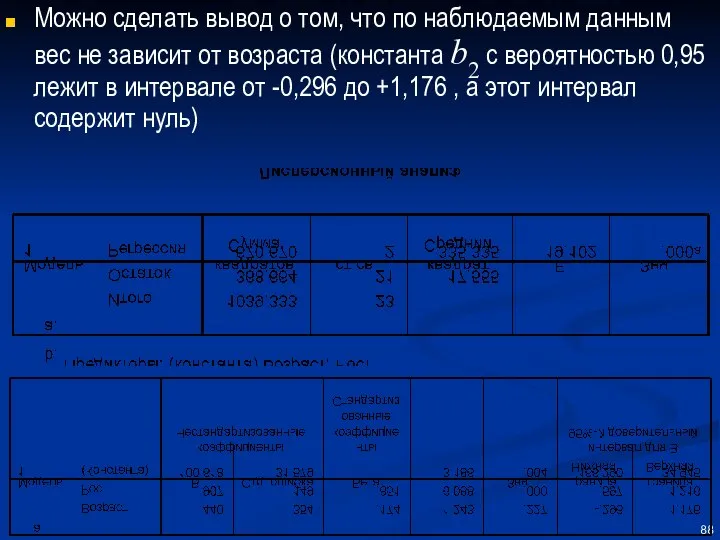
Можно сделать вывод о том, что по наблюдаемым данным вес не
Можно сделать вывод о том, что по наблюдаемым данным вес не

Логистическая регрессия
Эта разновидность регрессионного анализа применяется не для изучения взаимосвязи явлений,
Логистическая регрессия
Эта разновидность регрессионного анализа применяется не для изучения взаимосвязи явлений,

Рассмотрим наиболее простой случай – случай бинарной логистической регрессии.
В этом случае
Рассмотрим наиболее простой случай – случай бинарной логистической регрессии. В этом случае

Выявление взаимосвязи явлений
Корреляционный анализ
Выявление взаимосвязи явлений
Корреляционный анализ

В задачах корреляционного анализа требуется установить наличие взаимосвязи между изучаемыми явлениями
В задачах корреляционного анализа требуется установить наличие взаимосвязи между изучаемыми явлениями
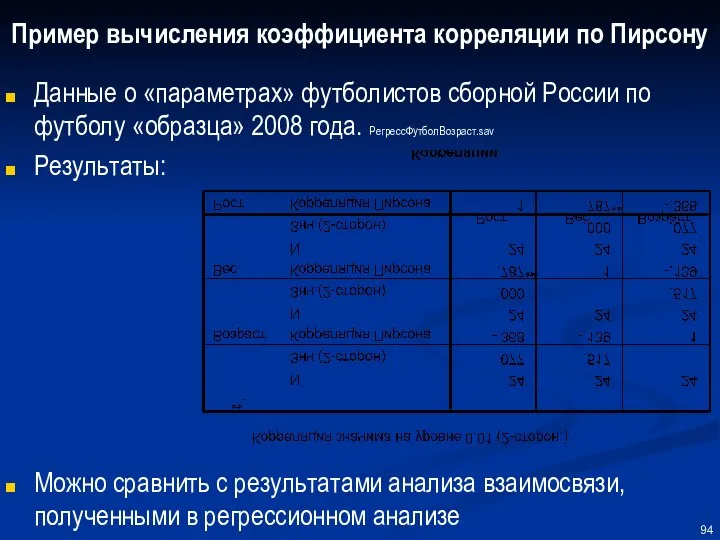
Пример вычисления коэффициента корреляции по Пирсону
Данные о «параметрах» футболистов сборной России
Пример вычисления коэффициента корреляции по Пирсону
Данные о «параметрах» футболистов сборной России

Таблицы сопряжённости и критерий χ2
Таблицы сопряженности (или «перекрестные распределения») служат для
Таблицы сопряжённости и критерий χ2
Таблицы сопряженности (или «перекрестные распределения») служат для
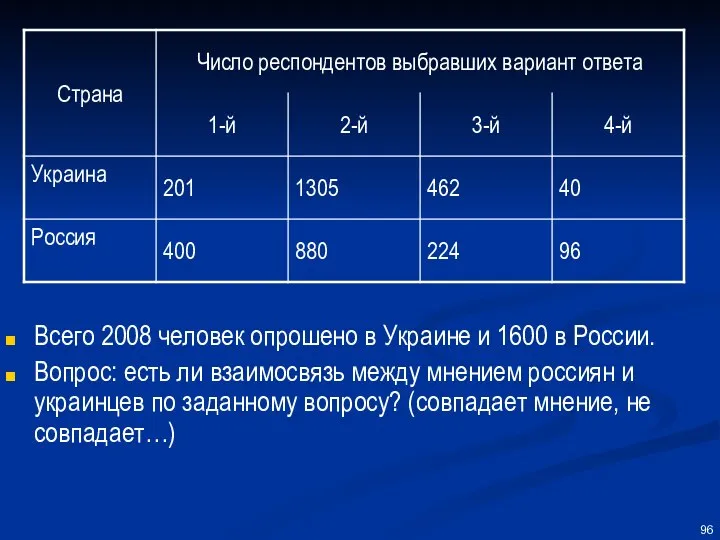
Всего 2008 человек опрошено в Украине и 1600 в России.
Вопрос: есть
Всего 2008 человек опрошено в Украине и 1600 в России.
Вопрос: есть

В «переводе» на язык статистики задача выглядит так:
есть две переменные:
В «переводе» на язык статистики задача выглядит так: есть две переменные:
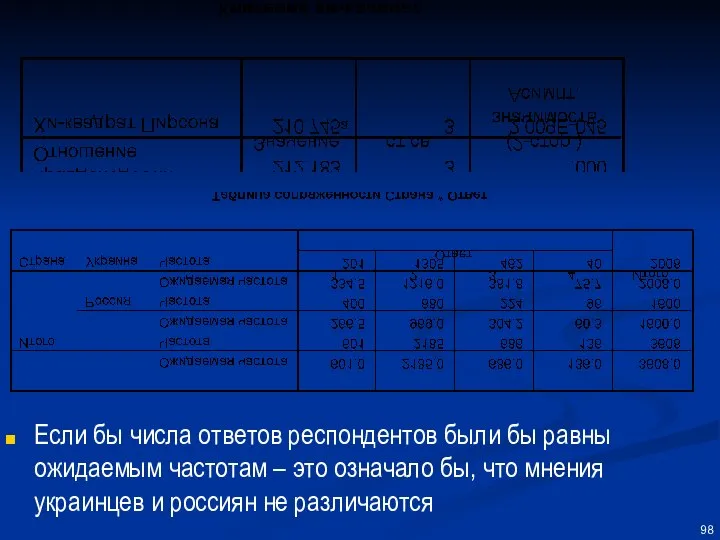
Если бы числа ответов респондентов были бы равны ожидаемым частотам –
Если бы числа ответов респондентов были бы равны ожидаемым частотам –

Построение экспертных систем на основе нейронных сетей
Построение экспертных систем на основе нейронных сетей

Задачи анализа данных, решаемые с помощью нейронных сетей
Выявление взаимосвязей и прогнозирование
Классификация
Кластеризация
Задачи анализа данных, решаемые с помощью нейронных сетей
Выявление взаимосвязей и прогнозирование
Классификация
Кластеризация

Нейронные сети как средство анализа данных
Под нейронными сетями понимаются вычислительные структуры,
Нейронные сети как средство анализа данных
Под нейронными сетями понимаются вычислительные структуры,

Элементарным преобразователем данных в нейронных сетях является нейрон, названный так по
Элементарным преобразователем данных в нейронных сетях является нейрон, названный так по
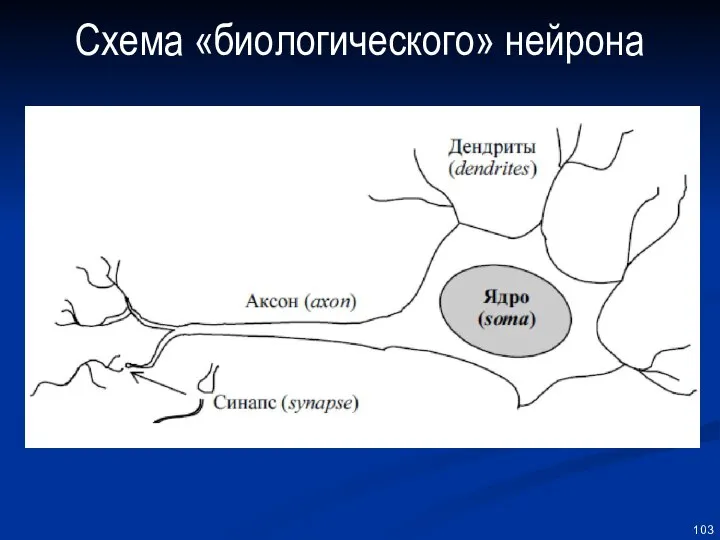
Схема «биологического» нейрона
Схема «биологического» нейрона
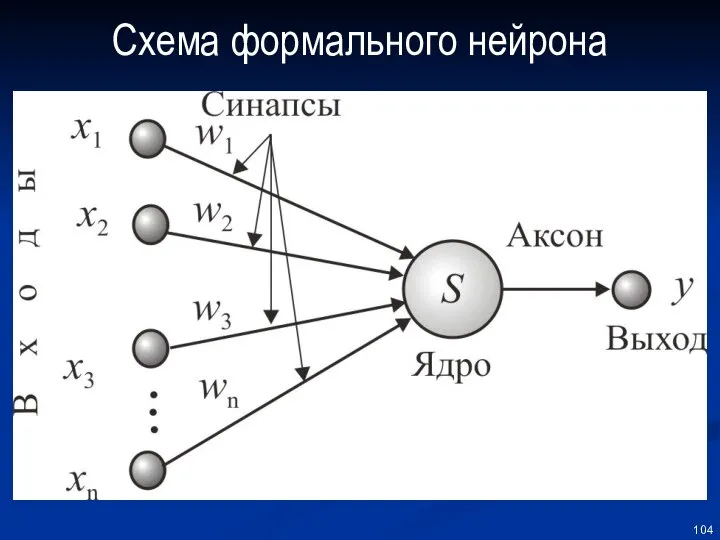
Схема формального нейрона
Схема формального нейрона

Если на входе сигналы: x1, x2… xn, то
на выходе из ядра
Если на входе сигналы: x1, x2… xn, то
на выходе из ядра

Классификация нейронных сетей
В многослойных или слоистых нейронных сетях нейроны объединяются в
Классификация нейронных сетей
В многослойных или слоистых нейронных сетях нейроны объединяются в
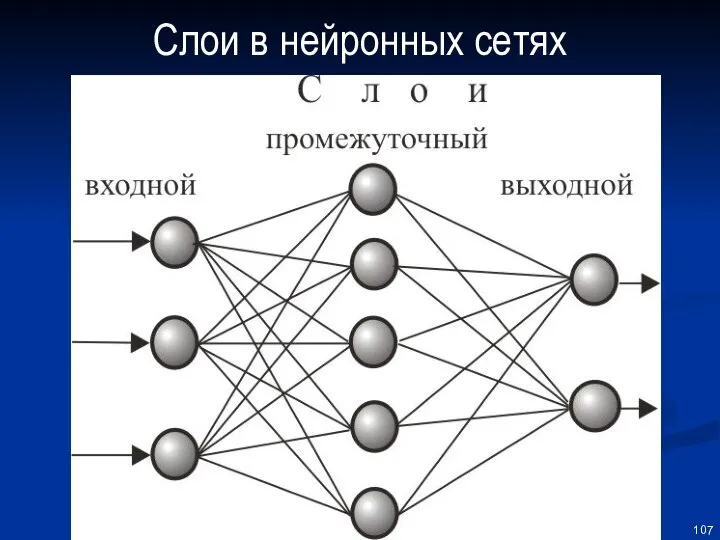
Слои в нейронных сетях
Слои в нейронных сетях

«Обучение» нейронной сети.
Алгоритм обратного распространения ошибок
В классическом алгоритме обучения (алгоритм
«Обучение» нейронной сети.
Алгоритм обратного распространения ошибок
В классическом алгоритме обучения (алгоритм

В классическом алгоритме подстройка весов синапсов происходит после предъявления нейронной сети
В классическом алгоритме подстройка весов синапсов происходит после предъявления нейронной сети

Для того чтобы сеть могла анализировать данные, она должна иметь достаточный
Для того чтобы сеть могла анализировать данные, она должна иметь достаточный

Такое приближенное определение числа нейронов еще не гарантирует хорошие прогностические качества
Такое приближенное определение числа нейронов еще не гарантирует хорошие прогностические качества

Пример задачи прогнозирования
Есть данные о средних за текущую неделю характеристиках фондового
Пример задачи прогнозирования
Есть данные о средних за текущую неделю характеристиках фондового
 Arrays Loops. Java Core
Arrays Loops. Java Core Қазақстанның тәуелсіз дамуы кезеңіндегі ар-ождан. Қазақстан Республикасының ар-ождан туралы заңнамасы. Дәріс 13
Қазақстанның тәуелсіз дамуы кезеңіндегі ар-ождан. Қазақстан Республикасының ар-ождан туралы заңнамасы. Дәріс 13 Презентация Правило интерпретации № 5
Презентация Правило интерпретации № 5 Пчеловодство. Рамки на трёх уровнях. Проект
Пчеловодство. Рамки на трёх уровнях. Проект Русская живопись в I половине XIX века Ширшакова Алла Васильевна МБОУ Епифанская СОШ
Русская живопись в I половине XIX века Ширшакова Алла Васильевна МБОУ Епифанская СОШ Основоположники натюрморта «Малые голландцы»
Основоположники натюрморта «Малые голландцы» Презентация "Психология цвета" - скачать презентации по МХК
Презентация "Психология цвета" - скачать презентации по МХК Презентация по МХК Наука и культура в 1917-1945 гг.
Презентация по МХК Наука и культура в 1917-1945 гг.  ВКР: Разработка системы на основе микроконтроллеров
ВКР: Разработка системы на основе микроконтроллеров Как оценить результаты формирования компетенций? Молокова Анна Викторовна, зав. кафедрой начального образования, Д-р. пед. наук
Как оценить результаты формирования компетенций? Молокова Анна Викторовна, зав. кафедрой начального образования, Д-р. пед. наук Анализ тональности сообщений Лидия Михайловна Пивоварова Системы понимания текста
Анализ тональности сообщений Лидия Михайловна Пивоварова Системы понимания текста Multipleksor multiplexer
Multipleksor multiplexer Старинная русская одежда. (4 класс)
Старинная русская одежда. (4 класс) Инвестиционная деятельность предприятия Лекция 10
Инвестиционная деятельность предприятия Лекция 10 Православная духовная традиция. Основы православной культуры
Православная духовная традиция. Основы православной культуры Można tak. Ale można też tak
Można tak. Ale można też tak Характерные частоты среды
Характерные частоты среды Роль классного руководителя в выпускном классе Классный руководитель 9 Б класса Никуленко Татьяна Николаевна
Роль классного руководителя в выпускном классе Классный руководитель 9 Б класса Никуленко Татьяна Николаевна  Культурология. Введение в культурологию
Культурология. Введение в культурологию Police of the United States
Police of the United States Etrusskie_khramy
Etrusskie_khramy Производство в суде апелляционной инстанции. Исполнение приговора
Производство в суде апелляционной инстанции. Исполнение приговора  Соединения элементов деревянных конструкций (ДК)
Соединения элементов деревянных конструкций (ДК) Параметрические методы ценообразования Выполнили: Мишина Даша Новиков Игорь группа э093
Параметрические методы ценообразования Выполнили: Мишина Даша Новиков Игорь группа э093 Алгоритмы поиска. Лекция 12
Алгоритмы поиска. Лекция 12 авд (мдк 02.01)
авд (мдк 02.01) Комплексные проверки состояния законности в местах лишения свободы
Комплексные проверки состояния законности в местах лишения свободы Доклад По дисциплине «Культурология» На тему «Основные направления в искусстве 20 века»
Доклад По дисциплине «Культурология» На тему «Основные направления в искусстве 20 века»