- Извлечение фактов из текста. Математическая лингвистика

Содержание
- 2. Что такое компьютерная лингвистика? Компьютерная лингвистика изучает язык с позиции его использования в компьютерных системах.
- 3. Задачи компьютерной лингвистики: автоматическое составление словарей и грамматик; анализ естественно-языковых текстов; создание и использование текстовых корпусов;
- 4. Извлечение фактов (структурированной информации) из неструктурированного текста - Text Mining. С помощью этой технологии можно представлять
- 5. Где применяются технологии извлечения фактов? Яндекс – Почта, Новости, Карты и др. сервисы.
- 6. Где применяются технологии извлечения фактов?
- 7. Где применяются технологии извлечения фактов? В поисковых системах, например Google и Yandex, для сбора информации о
- 8. Пример извлечения фактов
- 9. Задача проекта: извлечение фактов из текстов для структурирования информации. Под «фактом» понимается набор извлеченных сущностей, связанных
- 10. Примеры неструктурированного текста: В 1771 году Карл Шееле получил плавиковую кислоту. В природе значимые скопления фтора
- 11. Получаем на выходе:
- 12. Инструменты для работы Томита-парсер — это инструмент для извлечения структурированных данных (фактов) из текста на естественном
- 13. Грамматика томита-парсера Так выглядит часть грамматики для томита-парсера (для извлечения места рождения человека): Born -> Verb
- 14. Грамматика томита-парсера Язык описания грамматик для томита-парсера построен на основе порождающих грамматик.
- 15. Источники: Блог Яндекса на Хабре http://habrahabr.ru/company/yandex/blog/219311/ http://habrahabr.ru/company/yandex/blog/205198/ Скриншоты с Яндекс Почты
- 17. Скачать презентацию

Что такое компьютерная лингвистика?
Компьютерная лингвистика изучает язык с позиции его использования
Что такое компьютерная лингвистика?
Компьютерная лингвистика изучает язык с позиции его использования

Задачи компьютерной лингвистики:
автоматическое составление словарей и грамматик;
анализ естественно-языковых текстов;
создание и использование
Задачи компьютерной лингвистики:
автоматическое составление словарей и грамматик;
анализ естественно-языковых текстов;
создание и использование

Извлечение фактов (структурированной информации) из неструктурированного текста - Text Mining.
С
Извлечение фактов (структурированной информации) из неструктурированного текста - Text Mining.
С
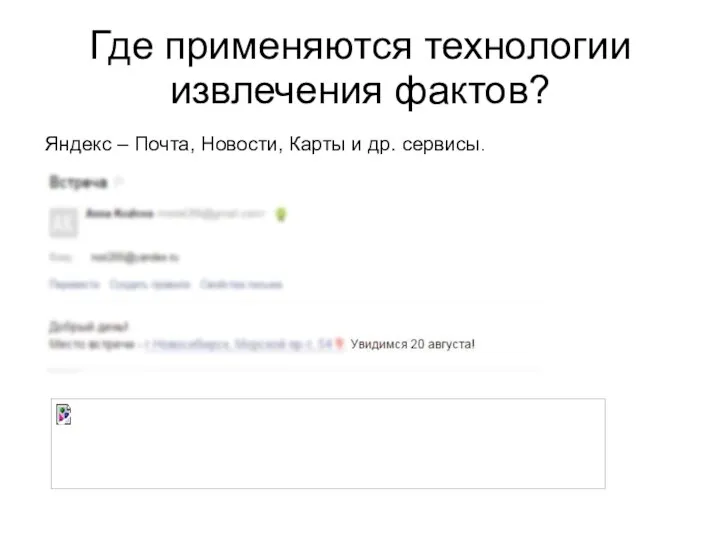
Где применяются технологии извлечения фактов?
Яндекс – Почта, Новости, Карты и др.
Где применяются технологии извлечения фактов?
Яндекс – Почта, Новости, Карты и др.
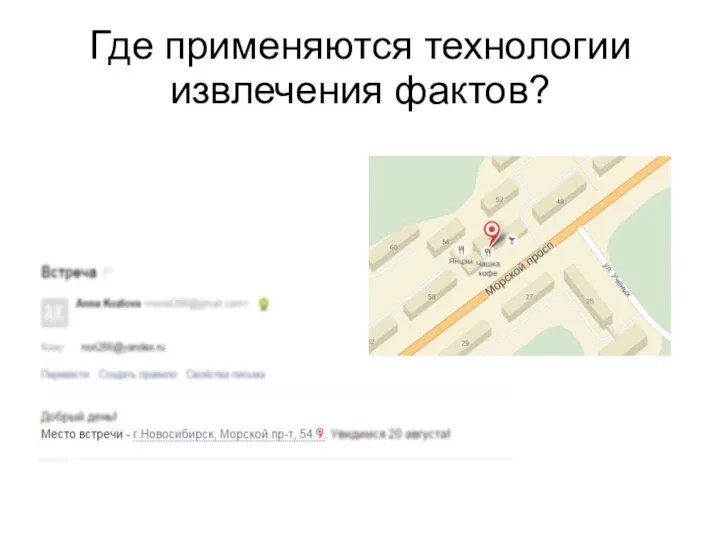
Где применяются технологии извлечения фактов?
Где применяются технологии извлечения фактов?

Где применяются технологии извлечения фактов?
В поисковых системах, например Google и Yandex,
Где применяются технологии извлечения фактов?
В поисковых системах, например Google и Yandex,

Пример извлечения фактов
Пример извлечения фактов

Задача проекта:
извлечение фактов из текстов для структурирования информации.
Под «фактом» понимается набор
Задача проекта:
извлечение фактов из текстов для структурирования информации.
Под «фактом» понимается набор

Примеры неструктурированного текста:
В 1771 году Карл Шееле получил плавиковую кислоту.
В природе
Примеры неструктурированного текста:
В 1771 году Карл Шееле получил плавиковую кислоту.
В природе
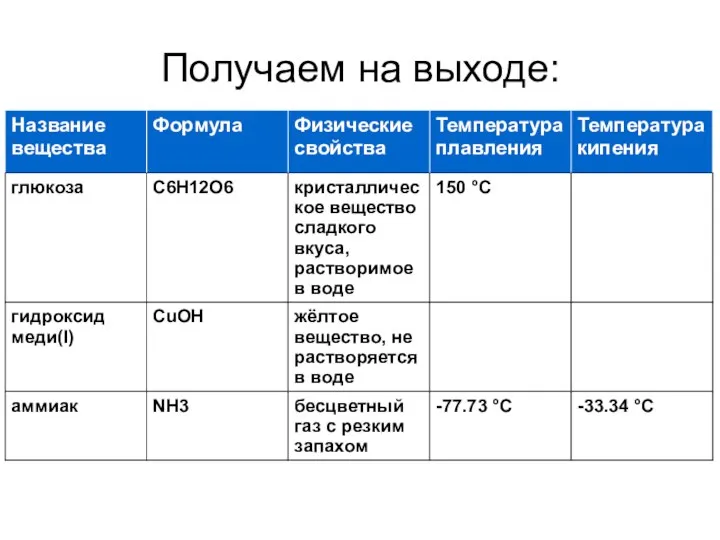
Получаем на выходе:
Получаем на выходе:

Инструменты для работы
Томита-парсер — это инструмент для извлечения структурированных данных (фактов)
Инструменты для работы
Томита-парсер — это инструмент для извлечения структурированных данных (фактов)

Грамматика томита-парсера
Так выглядит часть грамматики для томита-парсера (для извлечения места рождения
Грамматика томита-парсера
Так выглядит часть грамматики для томита-парсера (для извлечения места рождения
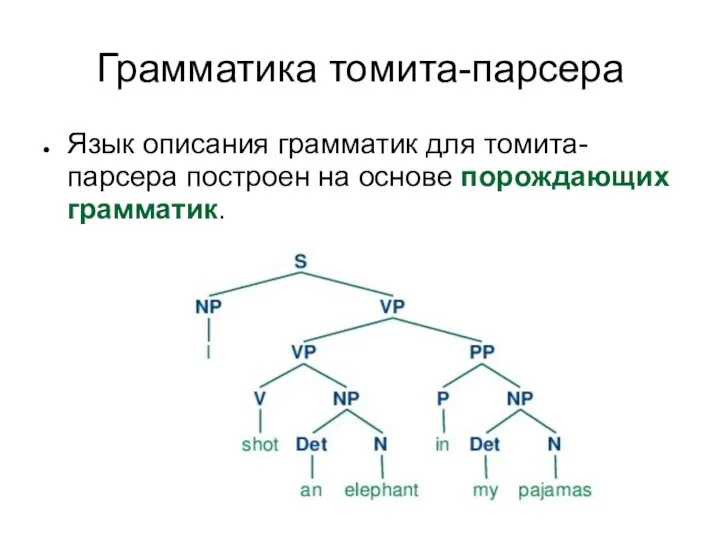
Грамматика томита-парсера
Язык описания грамматик для томита-парсера построен на основе порождающих грамматик.
Грамматика томита-парсера
Язык описания грамматик для томита-парсера построен на основе порождающих грамматик.

Источники:
Блог Яндекса на Хабре http://habrahabr.ru/company/yandex/blog/219311/
http://habrahabr.ru/company/yandex/blog/205198/
Скриншоты с Яндекс Почты
Источники:
Блог Яндекса на Хабре http://habrahabr.ru/company/yandex/blog/219311/
http://habrahabr.ru/company/yandex/blog/205198/
Скриншоты с Яндекс Почты
 Презентация на тему "Отчёт педагога-организатора и Президента школы об инновационных формах работы 2014/2015г" - скачать презента
Презентация на тему "Отчёт педагога-организатора и Президента школы об инновационных формах работы 2014/2015г" - скачать презента Пространственная дисперсия диэлектрической проницаемости
Пространственная дисперсия диэлектрической проницаемости Воспитательные системы в социуме
Воспитательные системы в социуме Православная церковь в годы Великой Отечественной войны
Православная церковь в годы Великой Отечественной войны Презентация Коммуникативные шумы (барьеры) и способы их преодоления
Презентация Коммуникативные шумы (барьеры) и способы их преодоления Точка безубыточности Точка безубыточности определяет, каким должен быть объем продаж для того, чтобы предприятие могло покры
Точка безубыточности Точка безубыточности определяет, каким должен быть объем продаж для того, чтобы предприятие могло покры Математический бой с мультяшными героями
Математический бой с мультяшными героями Интерактивные формы обучения как средство творческого развития учащихся на уроках ИЗО и технологии
Интерактивные формы обучения как средство творческого развития учащихся на уроках ИЗО и технологии Презентация на тему "Пищевые добавки в воде" - скачать презентации по Медицине
Презентация на тему "Пищевые добавки в воде" - скачать презентации по Медицине Требования к машинам и деталям
Требования к машинам и деталям Ф.А.Искандер - советский и российский прозаик и абхазский поэт
Ф.А.Искандер - советский и российский прозаик и абхазский поэт Телевидение и передача видеосигналов в ТКС
Телевидение и передача видеосигналов в ТКС Product placement в фильмографии Тима Бертона
Product placement в фильмографии Тима Бертона برامج وفعاليات جمعية مراكز األحياء إشراف :محافظة الطائف تنفيذ :جمعية مراكز األحياء
برامج وفعاليات جمعية مراكز األحياء إشراف :محافظة الطائف تنفيذ :جمعية مراكز األحياء Анализ воспитательной работы за 2014 -2015 учебный год
Анализ воспитательной работы за 2014 -2015 учебный год  Политический Public Relations. (Тема 9)
Политический Public Relations. (Тема 9) Троянская война
Троянская война Полёт на Луну - презентация для начальной школы_
Полёт на Луну - презентация для начальной школы_ Версии Linux
Версии Linux Электроэнергетическое оборудование
Электроэнергетическое оборудование Подшипники скольжения
Подшипники скольжения  Святитель Иоанн Златоуст (347- 407 годы)
Святитель Иоанн Златоуст (347- 407 годы) Спортивная викторина
Спортивная викторина Министерства Образования и науки Российской Федерации Татарский государственный гуманитарно-педагогический университет Факул
Министерства Образования и науки Российской Федерации Татарский государственный гуманитарно-педагогический университет Факул Как сделать храм доступным для всех: технические нормы и архитектурные решения
Как сделать храм доступным для всех: технические нормы и архитектурные решения Информатика понятие
Информатика понятие Памяти наших отцов. Макаров Борис Николаевич
Памяти наших отцов. Макаров Борис Николаевич Разработка отдельных фаз компиляции для заданного входного языка
Разработка отдельных фаз компиляции для заданного входного языка