- Направления развития искусственного интеллекта

Содержание
- 2. Эволюционное моделирование Одной из главных характеристик искусственного интеллекта как науки является его междисциплинарность, позволяющая привлекать интересные
- 4. Основной тезис эволюционного моделирования - заменить процесс моделирования сложного объекта моделированием его эволюции. Он направлен на
- 5. наследственность (потомки сохраняют свойства родителей); изменчивость (потомки почти всегда не идентичны); естественный отбор (выживают наиболее приспособленные).
- 6. Понятие «эволюционное моделирование» сформировалось в работах Л. Фогеля, А. Оуэне, М. Уолша. В 1966 году вышла
- 7. Пусть перед нами стоит задача оптимизации, например: Задача наилучшего приближения Если рассматривать систему n линейных уравнений
- 8. Задача о рационе. Пусть имеется n различных пищевых продуктов, содержащих m различных питательных веществ. Обозначим через
- 9. Транспортная задача. Эта задача — классическая задача линейного программирования. К ней сводятся многие оптимизационные задачи. Формулируется
- 10. Задачи о распределении ресурсов. Общий смысл таких задач — распределить ограниченный ресурс между потребителями оптимальным образом.
- 11. Переформулируем задачу оптимизации как задачу нахождения максимума некоторой функции f(x1, x2, …, xn), называемой функцией приспособленности
- 12. Особью будет называться строка, являющаяся конкатенацией строк упорядоченного набора параметров: 1010 10110 101 … 10101 |
- 13. Генетические алгоритмы оперируют совокупностью особей (популяцией), которые представляют собой строки, кодирующие одно из решений задачи. Этим
- 14. В классическом ГА: начальная популяция формируется случайным образом размер популяции (количество особей N) фиксируется и не
- 17. Промежуточная популяция — это набор особей, получивших право размножаться. Наиболее приспособленные особи могут быть записаны туда
- 18. Скрещивание Как известно, в теории эволюции важную роль играет то, каким образом признаки родителей передаются потомкам.
- 19. Существует большое количество разновидностей оператора скрещивания. Простейший одноточечный кроссовер работает следующим образом. Сначала случайным образом выбирается
- 20. Родитель 1 1 0 0 1 0 1 1 | 0 1 0 0 1 Родитель
- 21. Мутация Следующий генетический оператор предназначен для того, чтобы поддерживать разнообразие особей с популяции, - это оператор
- 22. ^ Особь до мутации: 1 0 0 1 0 1 1 0 0 1 1 1
- 23. Более сложной разновидностью мутации являются операторы инверсии и транслокации. Инверсия – это перестановка генов в обратном
- 24. Транслокация - это перенос какого-либо участка хромосомы в другой сегмент этой же хромосомы. ^ Особь до
- 25. Формирование нового поколения После скрещивания и мутации особей необходимо решить проблему: какие из новых особей войдут
- 26. Такой процесс эволюции, вообще говоря, может продолжаться до бесконечности. Критерием останова может служить заданное количество поколений
- 28. CHC-алгоритм CHC (Cross generational elitist selection, Heterogenous recombination, Cataclysmic mutation) был предложен Эсхелманом и характеризуется следующими
- 29. Genitor Этот алгоритм был создан Д. Уитли. Genitor-подобные алгоритмы отличаются от классического ГА следующими тремя свойствами:
- 30. Параллельные генетические алгоритмы Генетические алгоритмы можно организовать как несколько параллельно выполняющихся процессов, это увеличит их производительность.
- 31. Островная модель (island model, рис. 17) – это тоже модель параллельного генетического алгоритма. Она заключается в
- 33. Когнитивное моделирование Одно из наиболее продуктивных решений проблем, возникающих в области управления и организации, состоит в
- 34. Этапы когнитивного анализа Формулировка цели и задач исследования. Изучение сложной ситуации с позиций поставленной цели: сбор,
- 35. Определение взаимосвязи между факторами путем рассмотрения причинно-следственных цепочек (построение когнитивной карты в виде ориентированного графа). Изучение
- 36. (В результате прохождения этапов 3 – 5 строится, в конечном итоге, когнитивная модель ситуации (системы), которая
- 37. 7. Сценарное моделирование: Определение с помощью когнитивной модели возможных вариантов развития ситуации (системы), обнаружение путей, механизмов
- 38. Этапы когнитивного моделирования Выявление факторов, характеризующих проблемную ситуацию, развитие системы (среды). Например, суть проблемы неплатежей налогов
- 39. Определение характера влияния (положительное, отрицательное, +\-) Например, увеличение (уменьшение) фактора «Уровень налогового бремени» увеличивает (уменьшает) «Неплатежи
- 40. Для того чтобы понять и проанализировать поведение сложной системы, строят структурную схему причинно-следственных связей элементов системы
- 42. Когнитивная карта отображает лишь факт наличия влияний факторов друг на друга. В ней не отражается ни
- 44. Обучение и самообучение. Включает модели, методы и алгоритмы, ориентированные на автоматическое накопление и формирование знаний с
- 45. Понятие Data Mining Data Mining – это процесс поддержки принятия решений, основанный на поиске в данных
- 46. Неочевидных – это значит, что найденные закономерности не обнаруживаются стандартными методами обработки информации или экспертным путем.
- 47. Традиционные методы анализа данных (статистические методы) и OLAP в основном ориентированы на проверку заранее сформулированных гипотез
- 48. Мультидисциплинарность
- 49. Задачи Data Mining Классификация Кластеризация Прогнозирование Ассоциация Визуализация анализ и обнаружение отклонений Оценивание Анализ связей Подведение
- 50. Методы Data Mining. Технологические методы. Непосредственное использование данных, или сохранение данных: кластерный анализ, метод ближайшего соседа,
- 51. Методы Data Mining. Статистические методы. Дескриптивный анализ и описание исходных данных. Анализ связей (корреляционный и регрессионный
- 52. Методы Data Mining. Кибернетические методы. Искусственные нейронные сети (распознавание, кластеризация, прогноз); Эволюционное программирование (в т.ч. алгоритмы
- 53. Визуализация инструментов Data Mining. Для деревьев решений - визуализатор дерева решений, список правил, таблица сопряженности. Для
- 54. Проблемы и вопросы Data Mining не может заменить аналитика! Сложность разработки и эксплуатации приложения Data Mining.
- 55. Области применения Data mining Database marketers - Рыночная сегментация, идентификация целевых групп, построение профиля клиента Банковское
- 56. Области применения Data mining. Продолжение. Телекоммуникация и энергетика - Привлечение клиентов, ценовая политика, анализ отказов, предсказание
- 57. Перспективы технологии Data Mining. выделение типов предметных областей с соответствующими им эвристиками создание формальных языков и
- 58. Деревья решений. История и основные понятия. Возникновение - 50-е годы (Ховиленд и Хант (Hoveland, Hunt) )
- 59. Деревья решений. Пример 1.
- 60. Деревья решений. Пример 2.
- 61. Деревья решений. Преимущества метода. Интуитивность деревьев решений Возможность извлекать правила из базы данных на естественном языке
- 62. Data mining
- 63. Игры и машинное творчество. Охватывает создание компьютерной музыки, стихов, интеллектуальные системы для изобретения новых объектов, cоздание
- 64. В середине 50-х годов в США (Л.Хиллер и Л.Айзексон), а несколько позже в СССР (Р.Х.Зарипов) были
- 65. Технологии ИИ Машинное творчество и ИИ Начальный период развития ИИ: машинное творчество – одно из основных
- 66. Технологии ИИ Общая структура творческого процесса Моделирование творческих процессов и лабиринтная модель мышления: Гипотеза: решение любой
- 67. Технологии ИИ Музыка Моцарт. «Инструкция по сочинению вальсов с помощью двух игральных костей без малейшего знания
- 68. Технологии ИИ Музыка Моцарт. «Инструкция по сочинению вальсов с помощью двух игральных костей без малейшего знания
- 69. Компьютерные игры История компьютерных игр началась в далеком 1947 году, когда Томас Т. Голдсмит-младший и Эстл
- 71. В 1948 году Алан Тьюринг и Д.Г. Чемпернаут написали алгоритм шахматной игры. Для запуска алгоритма, было
- 72. В отрезке времени с 1951 по 1960 гг. изобретения в направлении компьютерных игр приписывают тройке лиц,
- 74. Апрель 1962, одна из первых известных цифровых компьютерных игр Spacewar! Была очень популярной игрой в 1960-е
- 76. В 1970 году Дуглас Энгельбарт запатентовал «систему X-Y индикации на мониторе»( Компьютерная мышь) С 1971 года
- 78. 1972 год Грегори Йоб написал (Охота на Вампуса) «Hunt The Wumpus» — первую текстовую игру в
- 80. 1973 год Atari выпускает Gotcha! — игру в жанре лабиринт для аркадных автоматов. Mazewar разработана для
- 82. Mattel выпускает Missile Attack, первую портативную игру на ЖК-дисплее. Cinematronics выпускает Space Wars — первый игровой
- 84. Всё что происходит далее, похоже на гонку кампаний, их перепродажу и появление более крупных и мощных
- 85. История шахматных машин старше, чем история компьютеров. Идея создать машину, играющую в шахматы, датируется ещё восемнадцатым
- 87. Создание механических шахматных автоматов прекратилось с появлением цифровых компьютеров в середине XX века. В 1951 году
- 88. Примерно в это же время, в 1951 году, математик Клод Шеннон написал свою первую статью о
- 89. Следующим шагом в развитии шахматного программирования стала разработка в ядерной лаборатории Лос-Аламоса в 1952 году на
- 90. Важное событие для компьютерных шахмат произошло в 1958 году, когда Аллен Ньюэлл, Клифф Шоу и Герберт
- 91. В 1994 Гарри Каспаров проиграл программе Fritz 3 турнирную блиц-партию в Мюнхене. Программа также выиграла у
- 92. В феврале 1996 года Гарри Каспаров победил шахматный суперкомпьютер Deep Blue со счетом 4-2. Этот матч
- 94. Компьютерные шахматные программы рассматривают шахматные ходы как игровое дерево. Теоретически, они должны оценивать все позиции, которые
- 95. Вторым распространенным методом является итерационное заглубление. Сначала перебирается дерево игры до определенной глубины, после чего выделяется
- 96. Системы когнитивной графики. Ориентированы на общение с пользователем ИИС посредством графических образов, которые генерируются в соответствии
- 97. Системы когнитивной графики. Когнитивная графика позволяет в наглядном и выразительном виде представить множество параметров, характеризующих изучаемое
- 98. Системы когнитивной графики.
- 99. Системы когнитивной графики.
- 100. Системы контекстной помощи. В них пользователь описывает проблему, а система на основе дополнительного диалога конкретизирует ее
- 101. Программное обеспечение систем ИИ Языки программирования, ориентированные на обработку символьной информации языки логического программирования (PROLOG), языки
- 102. Программное обеспечение систем ИИ интегрированные- программные среды, содержащие арсенал инструментальных средств для создания систем ИИ (КБ,
- 103. Признаки ИИС коммуникативные способности — способ взаимодействия конечного пользователя с системой; решение сложных плохо формализуемых задач,
- 104. Признаки ИИС способность к самообучению — умение системы автоматически извлекать знания из накопленного опыта и применять
- 105. Модели представления знаний Знания о некоторой ПрО представляют собой совокупность сведений об объектах этой ПрО, их
- 106. Трактовки знаний психологическая: психические образы, мысленные модели; интеллектуальная: совокупность сведений о некоторой ПрО, включающих факты об
- 107. Трактовки знаний формально-логическая: формализованная информация о некоторой ПрО, используемая для получения (вывода) новых знаний об этой
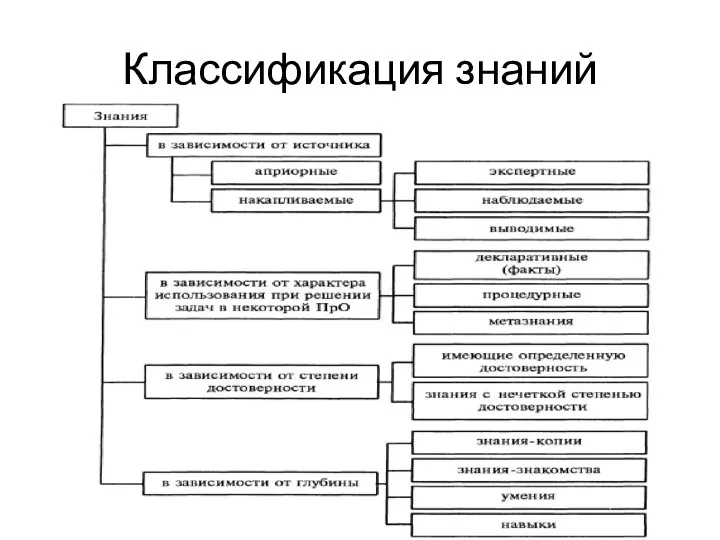
- 108. Классификация знаний
- 109. Классификация знаний декларативные знания- факты, сведения описательного характера; процедурные знания - информация о способах решения типовых
- 110. Классификация знаний Знания, имеющих определенную степень достоверности: «Следующим днем календаря после 31 мая является 1 июня»
- 111. Концептуальные свойства знаний 1) внутренняя интерпретация; 2) наличие внутренней структуры связей; 3) наличие внешней структуры связей;
- 112. Внутренняя интерпретация знаний Позволяет соотнести данные, хранящиеся в памяти ЭВМ, с их смысловым содержанием. Например, пусть
- 113. Внутренняя интерпретация знаний По иному обстоят дела, если информация представлена выражением: «Оценка студента Иванова на экзамене
- 114. Наличие внутренней и внешней структур связей Основываются на структурном подходе к представлению ПрО, согласно которому в
- 115. Шкалирование знаний Позволяет сопоставлять и упорядочивать качественно одинаковые, но различающиеся в количественном плане свойства и отношения
- 117. Скачать презентацию

Эволюционное моделирование
Одной из главных характеристик искусственного интеллекта как науки является его
Эволюционное моделирование
Одной из главных характеристик искусственного интеллекта как науки является его

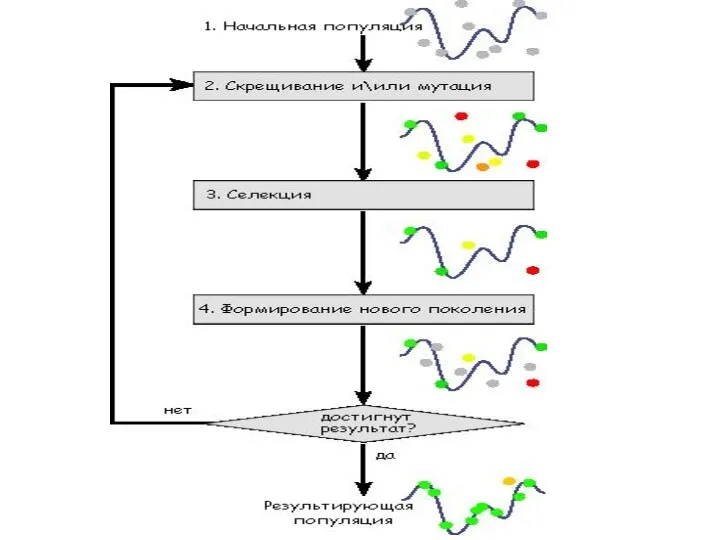
Основной тезис эволюционного моделирования - заменить процесс моделирования сложного объекта моделированием
Основной тезис эволюционного моделирования - заменить процесс моделирования сложного объекта моделированием

наследственность (потомки сохраняют свойства родителей);
изменчивость (потомки почти всегда не идентичны);
наследственность (потомки сохраняют свойства родителей);
изменчивость (потомки почти всегда не идентичны);

Понятие «эволюционное моделирование» сформировалось в работах Л. Фогеля, А. Оуэне, М.
Понятие «эволюционное моделирование» сформировалось в работах Л. Фогеля, А. Оуэне, М.

Пусть перед нами стоит задача оптимизации, например:
Задача наилучшего приближения
Если рассматривать систему
Пусть перед нами стоит задача оптимизации, например:
Задача наилучшего приближения
Если рассматривать систему

Задача о рационе.
Пусть имеется n различных пищевых продуктов, содержащих m
Задача о рационе.
Пусть имеется n различных пищевых продуктов, содержащих m

Транспортная задача.
Эта задача — классическая задача линейного программирования. К ней
Транспортная задача.
Эта задача — классическая задача линейного программирования. К ней

Задачи о распределении ресурсов.
Общий смысл таких задач — распределить ограниченный
Задачи о распределении ресурсов.
Общий смысл таких задач — распределить ограниченный

Переформулируем задачу оптимизации как задачу нахождения максимума некоторой функции f(x1, x2,
Переформулируем задачу оптимизации как задачу нахождения максимума некоторой функции f(x1, x2,

Особью будет называться строка, являющаяся конкатенацией строк упорядоченного набора параметров:
1010
Особью будет называться строка, являющаяся конкатенацией строк упорядоченного набора параметров:
1010

Генетические алгоритмы оперируют совокупностью особей (популяцией), которые представляют собой строки, кодирующие
Генетические алгоритмы оперируют совокупностью особей (популяцией), которые представляют собой строки, кодирующие

В классическом ГА:
начальная популяция формируется случайным образом
размер популяции (количество особей N)
В классическом ГА:
начальная популяция формируется случайным образом
размер популяции (количество особей N)
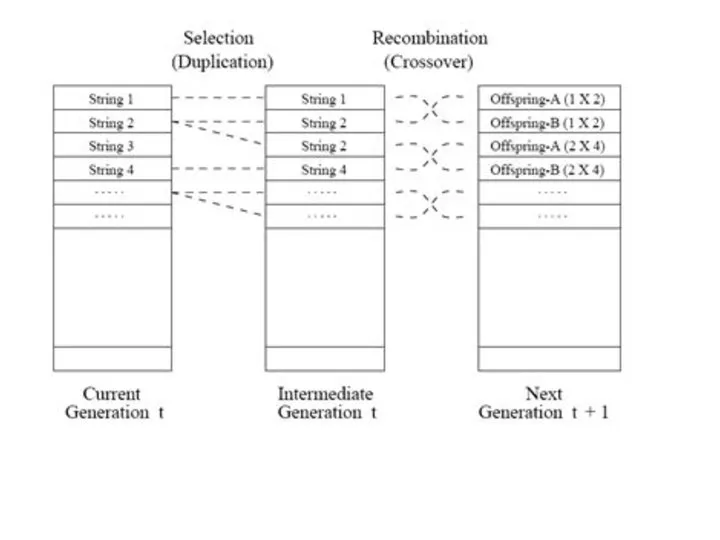

Промежуточная популяция — это набор особей, получивших право размножаться. Наиболее приспособленные
Промежуточная популяция — это набор особей, получивших право размножаться. Наиболее приспособленные

Скрещивание
Как известно, в теории эволюции важную роль играет то, каким образом
Скрещивание
Как известно, в теории эволюции важную роль играет то, каким образом

Существует большое количество разновидностей оператора скрещивания. Простейший одноточечный кроссовер работает следующим
Существует большое количество разновидностей оператора скрещивания. Простейший одноточечный кроссовер работает следующим

Родитель 1 1 0 0 1 0 1 1 | 0
Родитель 1 1 0 0 1 0 1 1 | 0

Мутация
Следующий генетический оператор предназначен для того, чтобы поддерживать разнообразие особей
Мутация
Следующий генетический оператор предназначен для того, чтобы поддерживать разнообразие особей

^ Особь до мутации: 1 0 0 1 0 1 1
^ Особь до мутации: 1 0 0 1 0 1 1

Более сложной разновидностью мутации являются операторы инверсии и транслокации. Инверсия –
Более сложной разновидностью мутации являются операторы инверсии и транслокации. Инверсия –

Транслокация - это перенос какого-либо участка хромосомы в другой сегмент этой
Транслокация - это перенос какого-либо участка хромосомы в другой сегмент этой

Формирование нового поколения
После скрещивания и мутации особей необходимо решить проблему:
Формирование нового поколения
После скрещивания и мутации особей необходимо решить проблему:

Такой процесс эволюции, вообще говоря, может продолжаться до бесконечности. Критерием останова
Такой процесс эволюции, вообще говоря, может продолжаться до бесконечности. Критерием останова
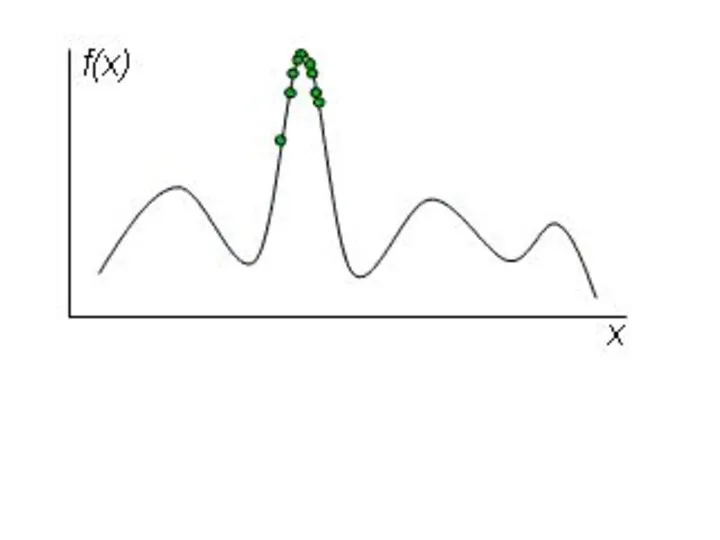

CHC-алгоритм
CHC (Cross generational elitist selection, Heterogenous recombination, Cataclysmic mutation) был предложен
CHC-алгоритм
CHC (Cross generational elitist selection, Heterogenous recombination, Cataclysmic mutation) был предложен

Genitor
Этот алгоритм был создан Д. Уитли. Genitor-подобные алгоритмы отличаются от классического
Genitor
Этот алгоритм был создан Д. Уитли. Genitor-подобные алгоритмы отличаются от классического

Параллельные генетические алгоритмы
Генетические алгоритмы можно организовать как несколько параллельно выполняющихся процессов,
Параллельные генетические алгоритмы
Генетические алгоритмы можно организовать как несколько параллельно выполняющихся процессов,

Островная модель (island model, рис. 17) – это тоже модель параллельного
Островная модель (island model, рис. 17) – это тоже модель параллельного

Когнитивное моделирование
Одно из наиболее продуктивных решений проблем, возникающих в области управления
Когнитивное моделирование
Одно из наиболее продуктивных решений проблем, возникающих в области управления

Этапы когнитивного анализа
Формулировка цели и задач исследования.
Изучение сложной ситуации с
Этапы когнитивного анализа
Формулировка цели и задач исследования.
Изучение сложной ситуации с

Определение взаимосвязи между факторами путем рассмотрения причинно-следственных цепочек (построение когнитивной карты
Определение взаимосвязи между факторами путем рассмотрения причинно-следственных цепочек (построение когнитивной карты

(В результате прохождения этапов 3 – 5 строится, в конечном итоге,
(В результате прохождения этапов 3 – 5 строится, в конечном итоге,

7. Сценарное моделирование: Определение с помощью когнитивной модели возможных вариантов развития
7. Сценарное моделирование: Определение с помощью когнитивной модели возможных вариантов развития

Этапы когнитивного моделирования
Выявление факторов, характеризующих проблемную ситуацию, развитие системы (среды). Например,
Этапы когнитивного моделирования
Выявление факторов, характеризующих проблемную ситуацию, развитие системы (среды). Например,

Определение характера влияния (положительное, отрицательное, +\-) Например, увеличение (уменьшение) фактора «Уровень
Определение характера влияния (положительное, отрицательное, +\-) Например, увеличение (уменьшение) фактора «Уровень

Для того чтобы понять и проанализировать поведение сложной системы, строят структурную
Для того чтобы понять и проанализировать поведение сложной системы, строят структурную
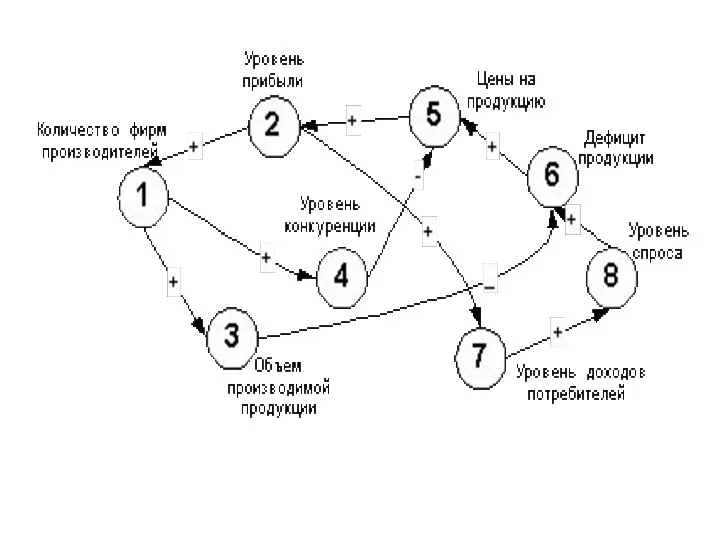

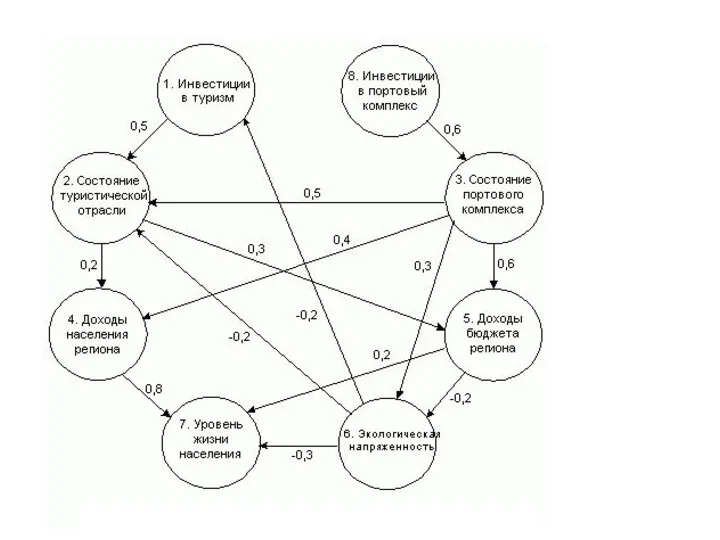
Когнитивная карта отображает лишь факт наличия влияний факторов друг на друга.
Когнитивная карта отображает лишь факт наличия влияний факторов друг на друга.

Обучение и самообучение.
Включает модели, методы и алгоритмы, ориентированные на
Обучение и самообучение.
Включает модели, методы и алгоритмы, ориентированные на

Понятие Data Mining
Data Mining – это процесс поддержки принятия решений, основанный
Понятие Data Mining
Data Mining – это процесс поддержки принятия решений, основанный

Неочевидных – это значит, что найденные закономерности не обнаруживаются стандартными методами
Неочевидных – это значит, что найденные закономерности не обнаруживаются стандартными методами

Традиционные методы анализа данных (статистические методы) и OLAP в основном ориентированы
Традиционные методы анализа данных (статистические методы) и OLAP в основном ориентированы
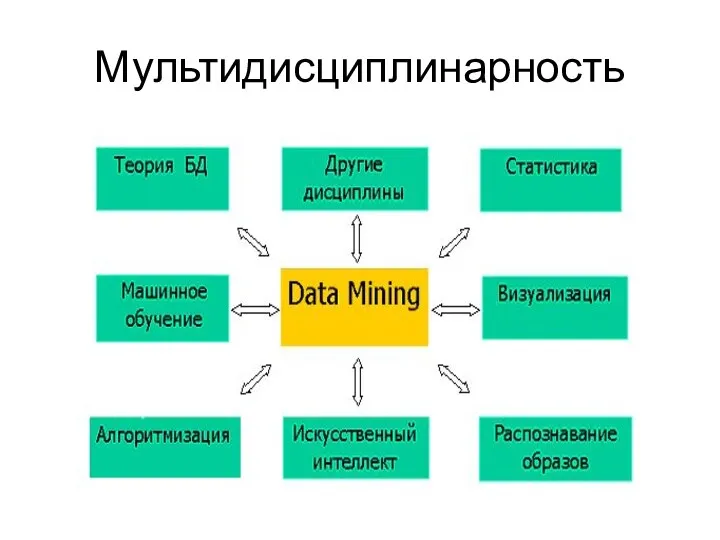
Мультидисциплинарность
Мультидисциплинарность

Задачи Data Mining
Классификация
Кластеризация
Прогнозирование
Ассоциация
Визуализация
анализ и обнаружение отклонений
Оценивание
Анализ связей
Подведение итогов
Задачи Data Mining
Классификация
Кластеризация
Прогнозирование
Ассоциация
Визуализация
анализ и обнаружение отклонений
Оценивание
Анализ связей
Подведение итогов

Методы Data Mining. Технологические методы.
Непосредственное использование данных, или сохранение данных:
кластерный анализ,
Методы Data Mining. Технологические методы.
Непосредственное использование данных, или сохранение данных: кластерный анализ,

Методы Data Mining. Статистические методы.
Дескриптивный анализ и описание исходных данных.
Анализ связей
Методы Data Mining. Статистические методы.
Дескриптивный анализ и описание исходных данных.
Анализ связей

Методы Data Mining. Кибернетические методы.
Искусственные нейронные сети (распознавание, кластеризация, прогноз);
Эволюционное программирование
Методы Data Mining. Кибернетические методы.
Искусственные нейронные сети (распознавание, кластеризация, прогноз);
Эволюционное программирование

Визуализация инструментов Data Mining.
Для деревьев решений - визуализатор дерева решений, список
Визуализация инструментов Data Mining.
Для деревьев решений - визуализатор дерева решений, список

Проблемы и вопросы
Data Mining не может заменить аналитика!
Сложность разработки и эксплуатации
Проблемы и вопросы
Data Mining не может заменить аналитика!
Сложность разработки и эксплуатации

Области применения Data mining
Database marketers - Рыночная сегментация, идентификация целевых групп,
Области применения Data mining
Database marketers - Рыночная сегментация, идентификация целевых групп,

Области применения Data mining. Продолжение.
Телекоммуникация и энергетика - Привлечение клиентов, ценовая
Области применения Data mining. Продолжение.
Телекоммуникация и энергетика - Привлечение клиентов, ценовая

Перспективы технологии Data Mining.
выделение типов предметных областей с соответствующими им эвристиками
создание
Перспективы технологии Data Mining.
выделение типов предметных областей с соответствующими им эвристиками
создание

Деревья решений. История и основные понятия.
Возникновение - 50-е годы (Ховиленд и
Деревья решений. История и основные понятия.
Возникновение - 50-е годы (Ховиленд и
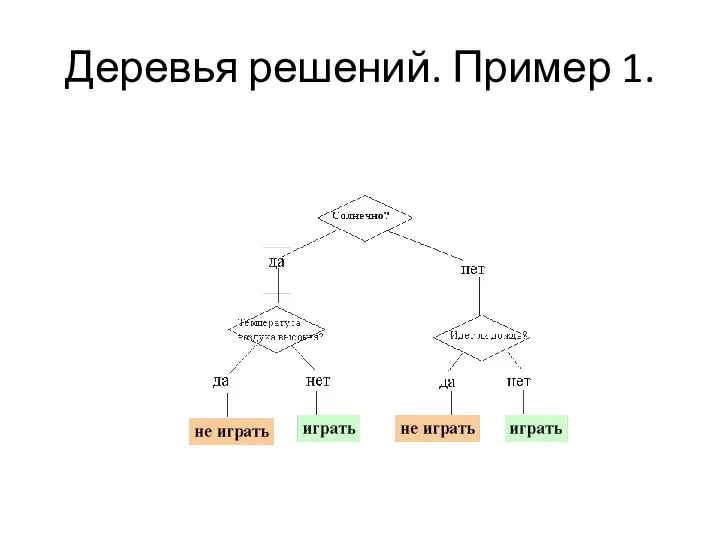
Деревья решений. Пример 1.
Деревья решений. Пример 1.
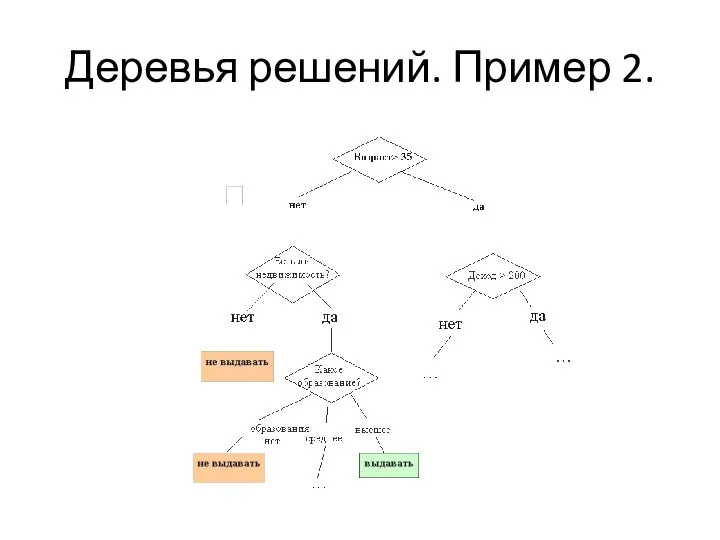
Деревья решений. Пример 2.
Деревья решений. Пример 2.

Деревья решений. Преимущества метода.
Интуитивность деревьев решений
Возможность извлекать правила из базы
Деревья решений. Преимущества метода.
Интуитивность деревьев решений
Возможность извлекать правила из базы

Data mining
Data mining

Игры и машинное творчество.
Охватывает создание компьютерной музыки, стихов, интеллектуальные
Игры и машинное творчество.
Охватывает создание компьютерной музыки, стихов, интеллектуальные

В середине 50-х годов в США (Л.Хиллер и Л.Айзексон), а несколько
В середине 50-х годов в США (Л.Хиллер и Л.Айзексон), а несколько
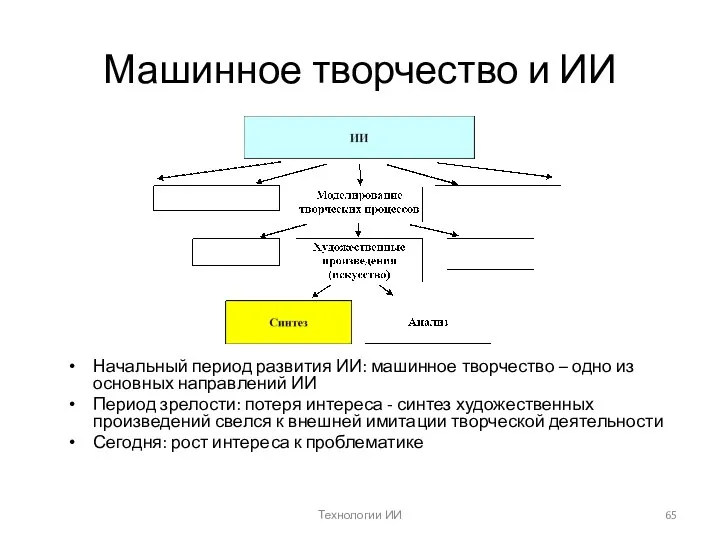
Технологии ИИ
Машинное творчество и ИИ
Начальный период развития ИИ: машинное творчество
Технологии ИИ
Машинное творчество и ИИ
Начальный период развития ИИ: машинное творчество
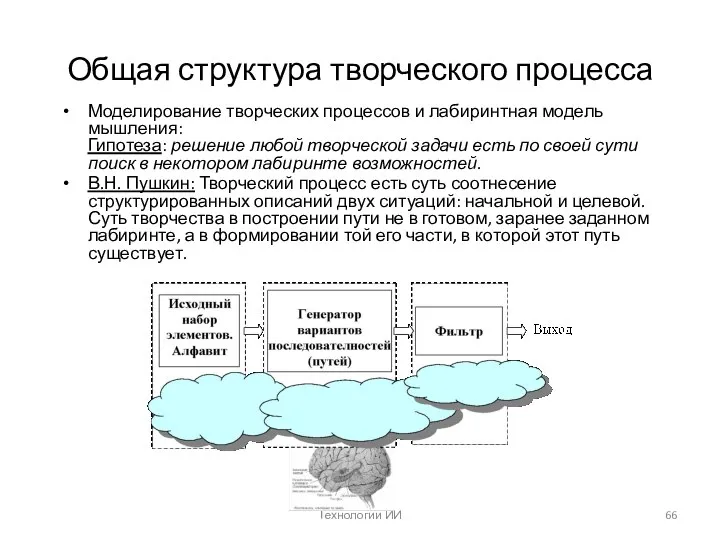
Технологии ИИ
Общая структура творческого процесса
Моделирование творческих процессов и лабиринтная модель
Технологии ИИ
Общая структура творческого процесса
Моделирование творческих процессов и лабиринтная модель

Технологии ИИ
Музыка
Моцарт. «Инструкция по сочинению вальсов с помощью двух игральных
Технологии ИИ
Музыка
Моцарт. «Инструкция по сочинению вальсов с помощью двух игральных

Технологии ИИ
Музыка
Моцарт. «Инструкция по сочинению вальсов с помощью двух игральных
Технологии ИИ
Музыка
Моцарт. «Инструкция по сочинению вальсов с помощью двух игральных

Компьютерные игры
История компьютерных игр началась в далеком 1947 году, когда Томас
Компьютерные игры
История компьютерных игр началась в далеком 1947 году, когда Томас
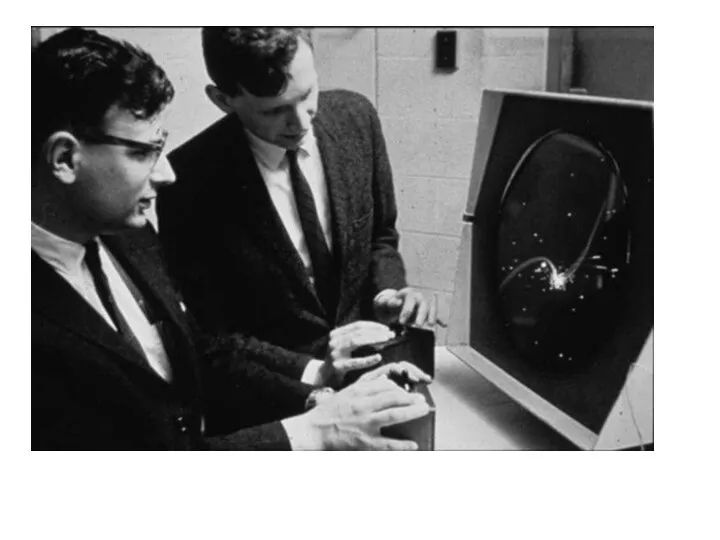

В 1948 году Алан Тьюринг и Д.Г. Чемпернаут написали алгоритм шахматной
В 1948 году Алан Тьюринг и Д.Г. Чемпернаут написали алгоритм шахматной

В отрезке времени с 1951 по 1960 гг. изобретения в направлении
В отрезке времени с 1951 по 1960 гг. изобретения в направлении


Апрель 1962, одна из первых известных цифровых компьютерных игр Spacewar! Была
Апрель 1962, одна из первых известных цифровых компьютерных игр Spacewar! Была


В 1970 году Дуглас Энгельбарт запатентовал «систему X-Y индикации на мониторе»(
В 1970 году Дуглас Энгельбарт запатентовал «систему X-Y индикации на мониторе»(


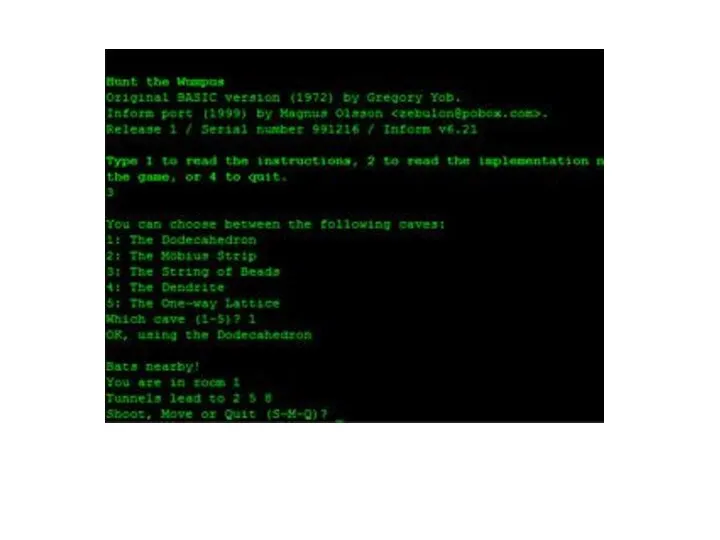
1972 год
Грегори Йоб написал (Охота на Вампуса) «Hunt The Wumpus» —
1972 год
Грегори Йоб написал (Охота на Вампуса) «Hunt The Wumpus» —

1973 год
Atari выпускает Gotcha! — игру в жанре лабиринт для
1973 год
Atari выпускает Gotcha! — игру в жанре лабиринт для


Mattel выпускает Missile Attack, первую портативную игру на ЖК-дисплее.
Cinematronics выпускает
Mattel выпускает Missile Attack, первую портативную игру на ЖК-дисплее.
Cinematronics выпускает


Всё что происходит далее, похоже на гонку кампаний, их перепродажу и
Всё что происходит далее, похоже на гонку кампаний, их перепродажу и

История шахматных машин старше, чем история компьютеров. Идея создать машину, играющую
История шахматных машин старше, чем история компьютеров. Идея создать машину, играющую


Создание механических шахматных автоматов прекратилось с появлением цифровых компьютеров в середине
Создание механических шахматных автоматов прекратилось с появлением цифровых компьютеров в середине

Примерно в это же время, в 1951 году, математик Клод Шеннон
Примерно в это же время, в 1951 году, математик Клод Шеннон

Следующим шагом в развитии шахматного программирования стала разработка в ядерной лаборатории
Следующим шагом в развитии шахматного программирования стала разработка в ядерной лаборатории

Важное событие для компьютерных шахмат произошло в 1958 году, когда Аллен
Важное событие для компьютерных шахмат произошло в 1958 году, когда Аллен

В 1994 Гарри Каспаров проиграл программе Fritz 3 турнирную блиц-партию в
В 1994 Гарри Каспаров проиграл программе Fritz 3 турнирную блиц-партию в

В феврале 1996 года Гарри Каспаров победил шахматный суперкомпьютер Deep Blue
В феврале 1996 года Гарри Каспаров победил шахматный суперкомпьютер Deep Blue


Компьютерные шахматные программы рассматривают шахматные ходы как игровое дерево. Теоретически, они
Компьютерные шахматные программы рассматривают шахматные ходы как игровое дерево. Теоретически, они

Вторым распространенным методом является итерационное заглубление. Сначала перебирается дерево игры до
Вторым распространенным методом является итерационное заглубление. Сначала перебирается дерево игры до

Системы когнитивной графики.
Ориентированы на общение с пользователем ИИС посредством графических образов,
Системы когнитивной графики.
Ориентированы на общение с пользователем ИИС посредством графических образов,

Системы когнитивной графики.
Когнитивная графика
позволяет в наглядном и выразительном виде представить множество
Системы когнитивной графики.
Когнитивная графика
позволяет в наглядном и выразительном виде представить множество
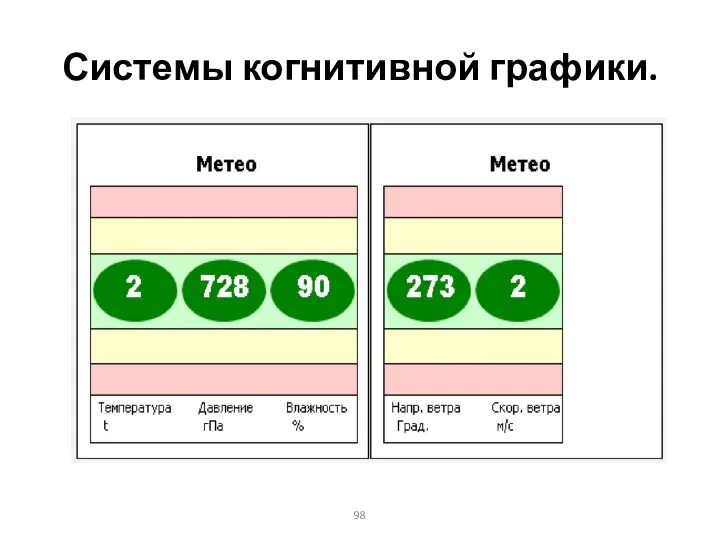
Системы когнитивной графики.
Системы когнитивной графики.
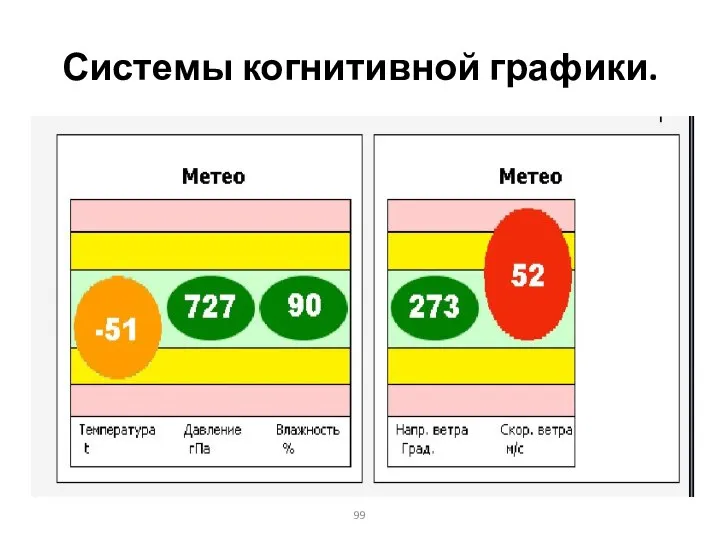
Системы когнитивной графики.
Системы когнитивной графики.

Системы контекстной помощи.
В них пользователь описывает проблему, а система
Системы контекстной помощи.
В них пользователь описывает проблему, а система

Программное обеспечение систем ИИ
Языки программирования, ориентированные на обработку символьной информации
Программное обеспечение систем ИИ
Языки программирования, ориентированные на обработку символьной информации

Программное обеспечение систем ИИ
интегрированные- программные среды, содержащие арсенал инструментальных
Программное обеспечение систем ИИ
интегрированные- программные среды, содержащие арсенал инструментальных

Признаки ИИС
коммуникативные способности — способ взаимодействия конечного пользователя с системой;
решение
Признаки ИИС
коммуникативные способности — способ взаимодействия конечного пользователя с системой;
решение

Признаки ИИС
способность к самообучению — умение системы автоматически извлекать знания
Признаки ИИС
способность к самообучению — умение системы автоматически извлекать знания

Модели представления знаний
Знания о некоторой ПрО представляют собой совокупность сведений
Модели представления знаний
Знания о некоторой ПрО представляют собой совокупность сведений

Трактовки знаний
психологическая: психические образы, мысленные модели;
интеллектуальная: совокупность сведений о некоторой
Трактовки знаний
психологическая: психические образы, мысленные модели;
интеллектуальная: совокупность сведений о некоторой

Трактовки знаний
формально-логическая: формализованная информация о некоторой ПрО, используемая для получения (вывода)
Трактовки знаний
формально-логическая: формализованная информация о некоторой ПрО, используемая для получения (вывода)
Классификация знаний
Классификация знаний

Классификация знаний
декларативные знания- факты, сведения описательного характера;
процедурные знания - информация о
Классификация знаний
декларативные знания- факты, сведения описательного характера;
процедурные знания - информация о

Классификация знаний
Знания, имеющих определенную степень достоверности: «Следующим днем календаря после 31
Классификация знаний
Знания, имеющих определенную степень достоверности: «Следующим днем календаря после 31

Концептуальные свойства знаний
1) внутренняя интерпретация;
2) наличие внутренней структуры связей;
3) наличие внешней
Концептуальные свойства знаний
1) внутренняя интерпретация;
2) наличие внутренней структуры связей;
3) наличие внешней

Внутренняя интерпретация знаний
Позволяет соотнести данные, хранящиеся в памяти ЭВМ, с их
Внутренняя интерпретация знаний
Позволяет соотнести данные, хранящиеся в памяти ЭВМ, с их

Внутренняя интерпретация знаний
По иному обстоят дела, если информация представлена выражением: «Оценка
Внутренняя интерпретация знаний
По иному обстоят дела, если информация представлена выражением: «Оценка

Наличие внутренней и внешней структур связей
Основываются на структурном подходе к представлению
Наличие внутренней и внешней структур связей
Основываются на структурном подходе к представлению

Шкалирование знаний
Позволяет сопоставлять и упорядочивать качественно одинаковые, но различающиеся в количественном
Шкалирование знаний
Позволяет сопоставлять и упорядочивать качественно одинаковые, но различающиеся в количественном
 Качество образования как толкование объекта. Теоретические и практические подходы к определению качества образования.
Качество образования как толкование объекта. Теоретические и практические подходы к определению качества образования. Система автоматизированного проектирования
Система автоматизированного проектирования смк
смк Медицина эпохи феодализма Ближний и Средний Восток
Медицина эпохи феодализма Ближний и Средний Восток Словарные коды класса LZ
Словарные коды класса LZ Критерии оценивания @Попова Снежанна Владиславовна учитель высшей квалификационной категории МОУ «СОШ №2» г.Краснотурьинск
Критерии оценивания @Попова Снежанна Владиславовна учитель высшей квалификационной категории МОУ «СОШ №2» г.Краснотурьинск Структуры данных
Структуры данных Анализ данных ежедневных атмосферных осадков г. Нур-Султан (Астана)
Анализ данных ежедневных атмосферных осадков г. Нур-Султан (Астана) Дети и деньги
Дети и деньги  7 «С»
7 «С» Что делать в трудную минуту? Молодёжь Смоленской Центральной Церкви
Что делать в трудную минуту? Молодёжь Смоленской Центральной Церкви Выпрямительные диоды
Выпрямительные диоды ЧПУ-УЧПУ-СЧПУ
ЧПУ-УЧПУ-СЧПУ Навыки эффективной мотивации
Навыки эффективной мотивации Возбудители вирусных гепатитов
Возбудители вирусных гепатитов  Понятие алгоритма и способы записи алгоритмов. (урок 1)
Понятие алгоритма и способы записи алгоритмов. (урок 1) Медико-тактическая характеристика очагов поражения ядерным оружием и при авариях на АЭС
Медико-тактическая характеристика очагов поражения ядерным оружием и при авариях на АЭС Флексии и агглютинация, аналитизм, изоляция
Флексии и агглютинация, аналитизм, изоляция  ИСТОРИЯ ПУТЕШЕСТВИЙ И ТУРИЗМА КАК НАУКА. ПЕРИОДИЗАЦИЯ ИСТОРИИ ТУРИЗМА
ИСТОРИЯ ПУТЕШЕСТВИЙ И ТУРИЗМА КАК НАУКА. ПЕРИОДИЗАЦИЯ ИСТОРИИ ТУРИЗМА Работа железнодорожных билетных касс и багажного отделения
Работа железнодорожных билетных касс и багажного отделения Разложение на простые множители 6 класс Математика презентация
Разложение на простые множители 6 класс Математика презентация Строительство универсальной спортивной площадки
Строительство универсальной спортивной площадки Нормативно-правовое и нормативно-техническое регулирование в строительстве
Нормативно-правовое и нормативно-техническое регулирование в строительстве Технология каменной кладки. (Лекция 10)
Технология каменной кладки. (Лекция 10) Пневмония
Пневмония  Презентация ФУНКЦИИ ДЕНЕГ
Презентация ФУНКЦИИ ДЕНЕГ „W obcym łóżku?”. Rzecz o szóstym przykazaniu
„W obcym łóżku?”. Rzecz o szóstym przykazaniu Тема урока: Основы технологии оклейки стен обоями.
Тема урока: Основы технологии оклейки стен обоями.