- Технологии параллельного программирования

Содержание
- 2. ТЕХНОЛОГИИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ OpenMP TBB MPI CUDA OpenCL OpenACC Chapel 13.03.2018
- 3. https://en.wikipedia.org/wiki/OpenMP OpenMP 13.03.2018
- 4. Разработку спецификации OpenMP ведут несколько крупных производителей ВТ и ПО AMD, IBM, Intel, Cray, HP, Fujitsu,
- 5. OpenMP uses a portable, scalable model with a simple interface for developing parallel applications for platforms
- 6. 13.03.2018 По умолчанию в компиляторах поддержка OpenMP выключена. Для её включения следует использовать дополнительную опцию gcc,
- 7. 13.03.2018 http://www.cyberforum.ru/blogs/18334/blog2965.html
- 8. 13.03.2018 http://www.cyberforum.ru/blogs/18334/blog2965.html
- 9. 13.03.2018 ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ OPEN MP НА С++ СМОТРИ ТУТ http://www.cyberforum.ru/blogs/18334/blog2965.html
- 10. Message Passing Interface (MPI, интерфейс передачи сообщений) — программный интерфейс (API) для передачи информации, который позволяет
- 11. 13.03.2018
- 12. В первую очередь MPI ориентирован на системы с распределенной памятью, то есть когда затраты на передачу
- 13. Intel Threading Building Blocks (также известная как TBB) — кроссплатформенная библиотека шаблонов С++, разработанная компанией Intel
- 14. 13.03.2018
- 15. The open standard for parallel programming of heterogeneous systems OpenCL ™ (Open Computing Language) - это
- 16. https://habrahabr.ru/post/261323/ OpenCL – как и с чего начать можно найти примеры тут (С++): 13.03.2018
- 17. CUDA vs OpenCL 13.03.2018 CUDA это архитектура параллельных вычислений от NVIDIA, позволяющая существенно увеличить вычислительную производительность
- 18. 13.03.2018 То есть если Вы захотите чтобы ваш движок рендеринга или программа расчета нагрузок на крыло
- 19. 13.03.2018 было решено создать некий единый стандарт для программ, исполняющихся в гетерогенной среде. Это означает, что
- 20. 13.03.2018 Решение проблемы Для разработки открытого стандарта решили привлечь людей, у которых уже есть опыт в
- 21. 13.03.2018
- 22. Попробуем решить одну простую задачу с помощью актуальных технологий параллельного программирования (OpenMP, TBB, MPI, CUDA, OpenCL,
- 23. Вычислим число Пи путем численного интегрирования, будем использовать метод прямоугольников 13.03.2018
- 24. Объявим количество шагов, на которые разобьем интеграл a – левый предел интеграла b – правый предел
- 25. 13.03.2018
- 26. Вычислим площадь криволинейной трапеции, посчитав значение функции в каждом прямоугольнике и домножив на основание //определение значения
- 27. Попробуем решить задачу сначала последовательным алгоритмом, а затем с использованием технологий параллельного программирования. И сравним время
- 28. Последовательное программирование package parallelprog; public class ParallelProg { static double x=0; static double a=0;//левый предел static
- 29. public static void main(String[] args) { start = System.nanoTime();//Отметим время начала step=Math.abs(a-b)/n; System.out.println("Начинаем вычислять интеграл"); //определение
- 30. Результат последовательного программирования Результат №1 Результат №2 13.03.2018
- 31. ТЕПЕРЬ ПОПРОБУЕМ РЕШИТЬ ЗАДАЧУ С ПОМОЩЬЮ ПАРАЛЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ 13.03.2018
- 32. Самая доступная простым пользователям параллельная архитектура — это обычный многоядерный процессор или несколько процессоров на одной
- 33. Одно ядро также способно исполнять параллельно несколько потоков — такой режим называется псевдо-параллельным или конкурентным. Ядро
- 34. Латентность (задержка) - это время, которое затрачивается на чтение из памяти одного слова данных (восьми байт)
- 35. Самый «исторический» способ использовать сразу несколько ядер на процессоре — это механизм потоков операционной системы, который
- 36. С точки зрения программиста важно то, что параллельные потоки, исполняемые на разных ядрах или процессорах видят
- 37. ВЕРНЕМСЯ К НАШЕЙ ЗАДАЧЕ: ВЫЧИСЛЕНИЕ ИНТЕГРАЛА 13.03.2018
- 38. РАЗОБЬЕМ ИНТЕГРАЛ НА ЛЕВУЮ И ПРАВУЮ ЧАСТИ. ПЕРВЫЙ ПОТОК БУДЕТ ВЫЧИСЛЯТЬ ИНТЕГРАЛ СЛЕВА НАПРАВО, НАЧИНАЯ ОТ
- 39. ВОПРОС: Почему будет неэффективным решением разбить интервал АВ на равные доли и отдать параллельным потокам на
- 40. ОТВЕТ: Если один из потоков посчитает свою часть раньше — то соответствующее ядро будет простаивать, т.е.
- 41. Поэтому оба потока будут вычислять интеграл с разной скоростью, пока не встретятся лицом к лицу 13.03.2018
- 42. Что касаемо программы Многопоточность в Java 13.03.2018
- 43. Процесс — это совокупность кода и данных, разделяющих общее виртуальное адресное пространство (VAS). Чаще всего одна
- 44. Браузер Chrome создает отдельный процесс для каждой вкладки, что дает ему некоторые преимущества, вроде независимости вкладок
- 45. ОС оперирует так называемыми страницами памяти, которые представляют собой просто область определенного фиксированного размера. Если процессу
- 46. Один поток – это одна единица исполнения кода. Каждый поток последовательно выполняет инструкции процесса, которому он
- 47. Псевдо-параллелизм. Система запоминает состояние (контекст) каждого потока, перед тем как переключиться на другой поток, и восстанавливает
- 48. УКРЕПИМ ЗНАНИЯ: Процессы изолированы друг от друга, поэтому прямой доступ к памяти чужого процесса невозможен. параллельные
- 49. JAVA Каждый процесс имеет хотя бы один выполняющийся поток. Тот поток, с которого начинается выполнение программы,
- 50. КАК СОЗДАТЬ ПОТОКИ В JAVA https://habrahabr.ru/post/164487/ 13.03.2018
- 51. СПОСОБ №1 СОЗДАТЬ ПОТОК В JAVA С ПОМОЩЬЮ ИНТЕРФЕЙСА RUNNABLE 13.03.2018
- 52. public class MyThread implements Runnable{ @Override public void run() { /*Код который должен выполнить поток*/ }
- 53. СПОСОБ №2: НАСЛЕДОВАНИЕ ОТ КЛАССА THREAD 13.03.2018
- 54. public class MyThread extends Thread{ @Override public void run() { /*Код который должен выполнить поток*/ }
- 55. В ЧЕМ РАЗНИЦА МЕЖДУ РЕАЛИЗАЦИЕЙ ИНТЕРФЕЙСА RUNNABLE И НАСЛЕДОВАНИЕМ ОТ КЛАССА THREAD? http://qaru.site/questions/57/implements-runnable-vs-extends-thread 13.03.2018
- 56. ДАВАЙТЕ ИЗУЧИМ КОД: 13.03.2018
- 57. 13.03.2018
- 58. 13.03.2018
- 59. В интерфейсе Runnable создается только один экземпляр класса, и он разделяется различными потоками. Таким образом, значение
- 60. Когда использовать Runnable? Используйте интерфейс Runnable, если вы хотите получить доступ к одному и тому же
- 61. Когда вы реализуете интерфейс Runnable, вы можете сохранить пространство для своего класса для расширения любого другого
- 62. В задачи нашего курса не входит освоение ЯВУ, давайте все же вернемся к нашей задаче, которую
- 63. Мы создали 2 потока, которые вычисляют интеграл. Программа ParallelProg 13.03.2018
- 64. Давайте посмотрим как эти два потока борются за один и тот же ресурс – ядро. Пример
- 65. Давайте посмотрим как эти два потока борются за один и тот же ресурс – ядро. Пример
- 66. Вот что происходит с процессором, когда оба потока запущены. 13.03.2018
- 67. Вот что происходит с процессором, когда оба потока прекратили вычисления. 13.03.2018
- 68. РЕЗУЛЬТАТЫ ТЕСТИРОВАНИЯ Мы видим, что при параллельном выполнении задачи мы улучшили показатели времени на 19,53% в
- 69. ВОПРОС: ПОЧЕМУ ВРЕМЯ ВЫЧИСЛЕНИЯ ИНТЕГРАЛА НЕ УЛУЧШИЛОСЬ ПРИ ПАРАЛЛЕЛЬНОМ ПОДХОДЕ НА 50% , ВЕДЬ ПО ИДЕИ
- 70. ОТВЕТ: В данном примере обе задачи были однотипные, а значит им требовались одни и те же
- 71. ПРОВЕДЕМ НОВЫЕ ИССЛЕДОВАНИЯ! Создадим два параллельных потока: Первый поток будет вычислять интеграл для числа Pi (как
- 72. КОГДА ОБА ПОТОКА РАБОТАЮТ Программа JOGLParallelProgram 13.03.2018
- 73. ПОТОК 1 ЗАВЕРШИЛ ВЫЧИСЛЕНИЯ Программа JOGLParallelProgram 13.03.2018
- 74. ОБРАТИМСЯ К ФИЛОСОФИИ☺ Ответит ли нам программа на вечный вопрос: Что появилось раньше: Яйцо или Курица?
- 75. РЕЗУЛЬТАТЫ СПОРА: 13.03.2018
- 76. НАГРУЗКА НА ЦП МИНИМАЛЬНА (ВЫЧИСЛЕНИЙ НЕТ) Программа PrallelProgramming 13.03.2018
- 77. ПРОВЕДЕМ 100 АНАЛОГИЧНЫХ ТЕСТОВ, ЧТОБЫ УЗНАТЬ ВЕРОЯТНОСТЬ ВЫДАЧИ ОТВЕТА 13.03.2018
- 78. РЕЗУЛЬТАТЫ ТЕСТИРОАНИЯ: ЯЙЦО vs КУРИЦА ПОБЕЖДАЕТ ЯЙЦО СО СЧЕТОМ 88:12 13.03.2018
- 80. Скачать презентацию

ТЕХНОЛОГИИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
OpenMP
TBB
MPI
CUDA
OpenCL
OpenACC
Chapel
13.03.2018
ТЕХНОЛОГИИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
OpenMP
TBB
MPI
CUDA
OpenCL
OpenACC
Chapel
13.03.2018

https://en.wikipedia.org/wiki/OpenMP
OpenMP
13.03.2018
https://en.wikipedia.org/wiki/OpenMP
OpenMP
13.03.2018

Разработку спецификации OpenMP ведут несколько крупных производителей ВТ и ПО
AMD, IBM,
Разработку спецификации OpenMP ведут несколько крупных производителей ВТ и ПО
AMD, IBM,
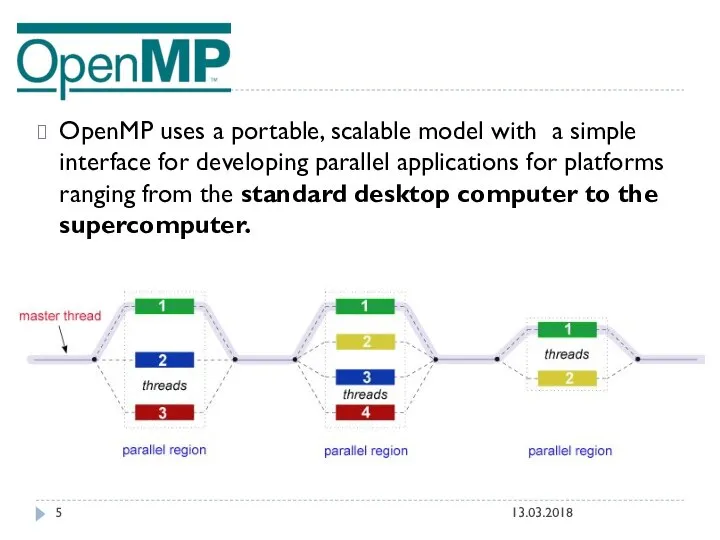
OpenMP uses a portable, scalable model with a simple interface for
OpenMP uses a portable, scalable model with a simple interface for

13.03.2018
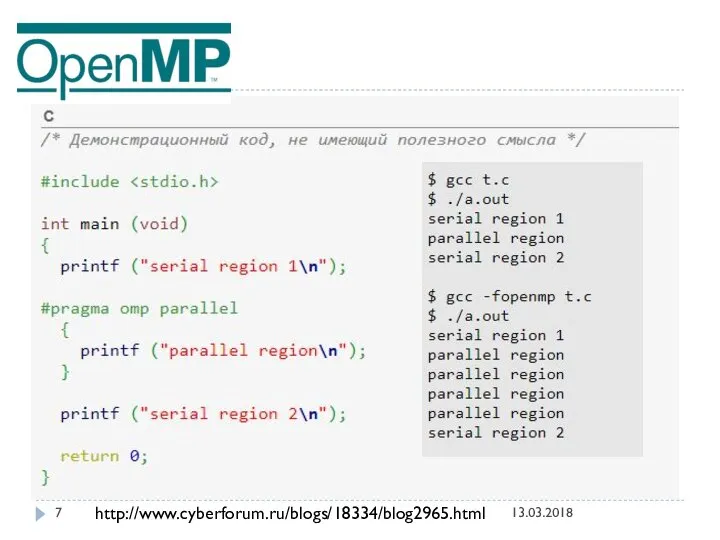
По умолчанию в компиляторах поддержка OpenMP выключена. Для её включения следует
13.03.2018
По умолчанию в компиляторах поддержка OpenMP выключена. Для её включения следует
13.03.2018
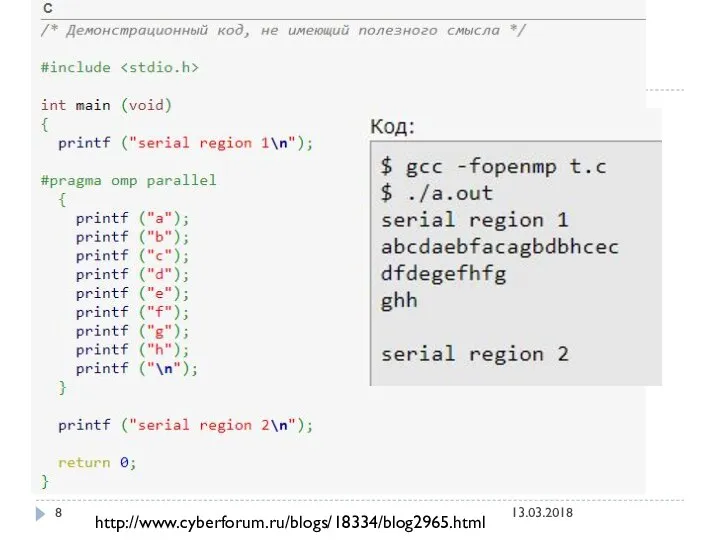
http://www.cyberforum.ru/blogs/18334/blog2965.html
13.03.2018
http://www.cyberforum.ru/blogs/18334/blog2965.html
13.03.2018
http://www.cyberforum.ru/blogs/18334/blog2965.html
13.03.2018
http://www.cyberforum.ru/blogs/18334/blog2965.html

13.03.2018
ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ OPEN MP НА С++ СМОТРИ ТУТ
http://www.cyberforum.ru/blogs/18334/blog2965.html
13.03.2018
ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ OPEN MP НА С++ СМОТРИ ТУТ
http://www.cyberforum.ru/blogs/18334/blog2965.html

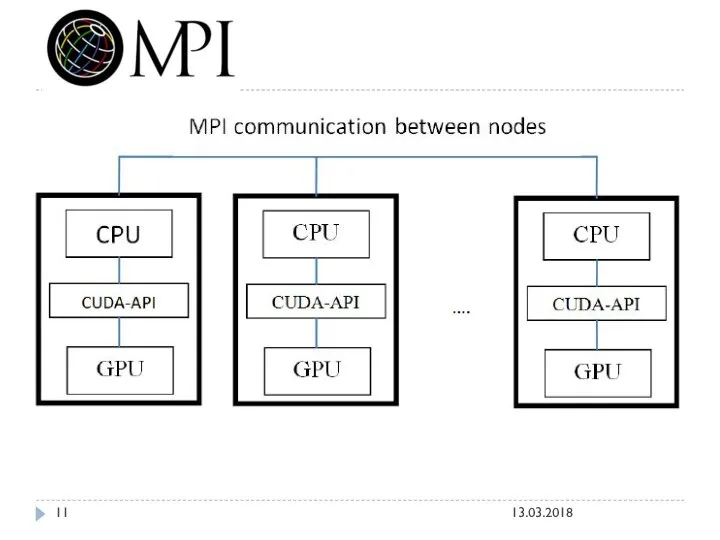
Message Passing Interface (MPI, интерфейс передачи сообщений) — программный интерфейс (API) для передачи информации,
Message Passing Interface (MPI, интерфейс передачи сообщений) — программный интерфейс (API) для передачи информации,
13.03.2018
13.03.2018

В первую очередь MPI ориентирован на системы с распределенной памятью, то есть
В первую очередь MPI ориентирован на системы с распределенной памятью, то есть

Intel Threading Building Blocks (также известная как TBB) — кроссплатформенная библиотека шаблонов С++, разработанная
Intel Threading Building Blocks (также известная как TBB) — кроссплатформенная библиотека шаблонов С++, разработанная
13.03.2018
13.03.2018

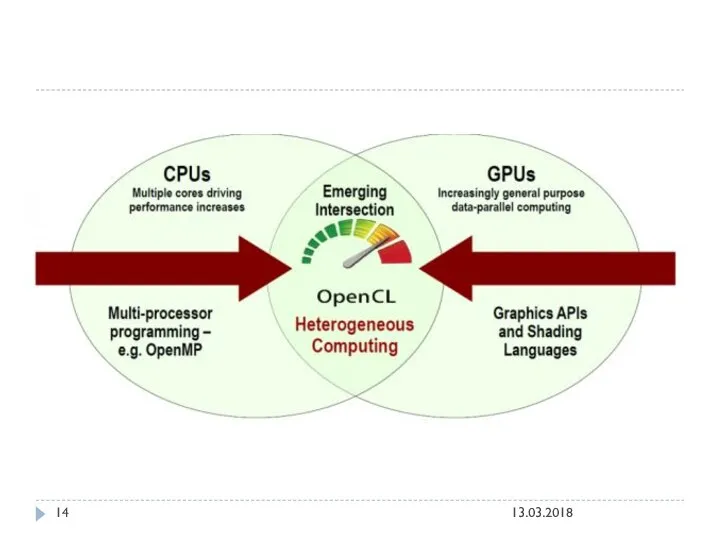
The open standard for parallel programming of heterogeneous systems
OpenCL ™ (Open
The open standard for parallel programming of heterogeneous systems
OpenCL ™ (Open

https://habrahabr.ru/post/261323/
OpenCL – как и с чего начать можно найти примеры тут
https://habrahabr.ru/post/261323/
OpenCL – как и с чего начать можно найти примеры тут

CUDA vs OpenCL
13.03.2018
CUDA
это архитектура параллельных вычислений от NVIDIA, позволяющая существенно
CUDA vs OpenCL
13.03.2018
CUDA
это архитектура параллельных вычислений от NVIDIA, позволяющая существенно

13.03.2018
То есть если Вы захотите чтобы ваш движок рендеринга или программа
13.03.2018
То есть если Вы захотите чтобы ваш движок рендеринга или программа

13.03.2018
было решено создать некий единый стандарт для программ, исполняющихся в гетерогенной
13.03.2018
было решено создать некий единый стандарт для программ, исполняющихся в гетерогенной

13.03.2018
Решение проблемы
Для разработки открытого стандарта решили привлечь людей, у которых уже
13.03.2018
Решение проблемы
Для разработки открытого стандарта решили привлечь людей, у которых уже
13.03.2018
13.03.2018

Попробуем решить одну простую задачу с помощью актуальных технологий параллельного программирования
Попробуем решить одну простую задачу с помощью актуальных технологий параллельного программирования

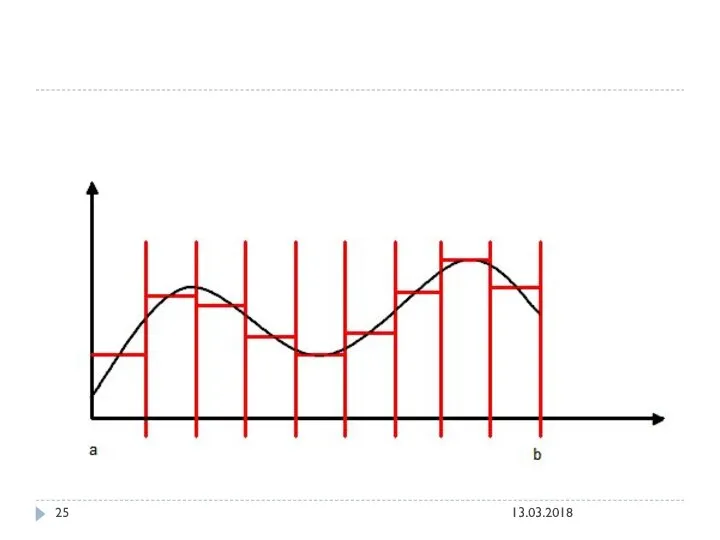
Вычислим число Пи путем численного интегрирования, будем использовать метод прямоугольников
13.03.2018
Вычислим число Пи путем численного интегрирования, будем использовать метод прямоугольников
13.03.2018

Объявим количество шагов, на которые разобьем интеграл
a – левый предел интеграла
b
Объявим количество шагов, на которые разобьем интеграл
a – левый предел интеграла
b
13.03.2018
13.03.2018

Вычислим площадь криволинейной трапеции, посчитав значение функции в каждом прямоугольнике и
Вычислим площадь криволинейной трапеции, посчитав значение функции в каждом прямоугольнике и

Попробуем решить задачу сначала последовательным алгоритмом, а затем с использованием технологий
Попробуем решить задачу сначала последовательным алгоритмом, а затем с использованием технологий

Последовательное программирование
package parallelprog;
public class ParallelProg {
static double x=0;
static double
Последовательное программирование
package parallelprog;
public class ParallelProg {
static double x=0;
static double
![public static void main(String[] args) { start = System.nanoTime();//Отметим время начала](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/1363954/slide-28.jpg)
public static void main(String[] args) {
start = System.nanoTime();//Отметим время начала
public static void main(String[] args) {
start = System.nanoTime();//Отметим время начала

Результат последовательного программирования
Результат №1
Результат №2
13.03.2018
Результат последовательного программирования
Результат №1
Результат №2
13.03.2018

ТЕПЕРЬ ПОПРОБУЕМ РЕШИТЬ ЗАДАЧУ С ПОМОЩЬЮ ПАРАЛЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
13.03.2018
ТЕПЕРЬ ПОПРОБУЕМ РЕШИТЬ ЗАДАЧУ С ПОМОЩЬЮ ПАРАЛЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
13.03.2018

Самая доступная простым пользователям параллельная архитектура — это обычный многоядерный процессор
Самая доступная простым пользователям параллельная архитектура — это обычный многоядерный процессор

Одно ядро также способно исполнять параллельно несколько потоков — такой режим
Одно ядро также способно исполнять параллельно несколько потоков — такой режим

Латентность (задержка) - это время, которое затрачивается на чтение из памяти
Латентность (задержка) - это время, которое затрачивается на чтение из памяти

Самый «исторический» способ использовать сразу несколько ядер на процессоре — это
Самый «исторический» способ использовать сразу несколько ядер на процессоре — это

С точки зрения программиста важно то, что параллельные потоки, исполняемые на
С точки зрения программиста важно то, что параллельные потоки, исполняемые на

ВЕРНЕМСЯ К НАШЕЙ ЗАДАЧЕ: ВЫЧИСЛЕНИЕ ИНТЕГРАЛА
13.03.2018
ВЕРНЕМСЯ К НАШЕЙ ЗАДАЧЕ: ВЫЧИСЛЕНИЕ ИНТЕГРАЛА
13.03.2018
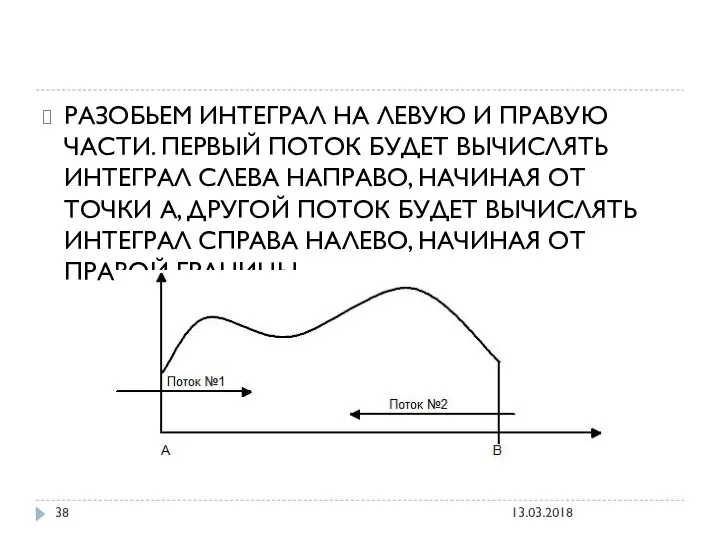
РАЗОБЬЕМ ИНТЕГРАЛ НА ЛЕВУЮ И ПРАВУЮ ЧАСТИ. ПЕРВЫЙ ПОТОК БУДЕТ ВЫЧИСЛЯТЬ
РАЗОБЬЕМ ИНТЕГРАЛ НА ЛЕВУЮ И ПРАВУЮ ЧАСТИ. ПЕРВЫЙ ПОТОК БУДЕТ ВЫЧИСЛЯТЬ
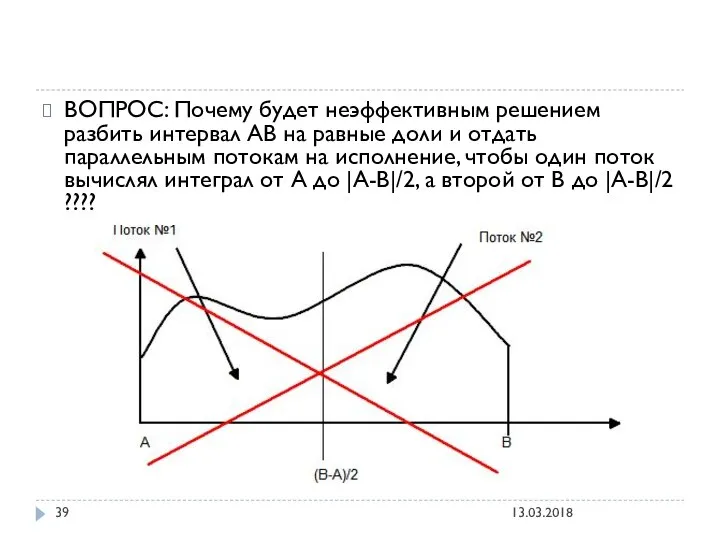
ВОПРОС: Почему будет неэффективным решением разбить интервал АВ на равные доли
ВОПРОС: Почему будет неэффективным решением разбить интервал АВ на равные доли

ОТВЕТ: Если один из потоков посчитает свою часть раньше — то
ОТВЕТ: Если один из потоков посчитает свою часть раньше — то
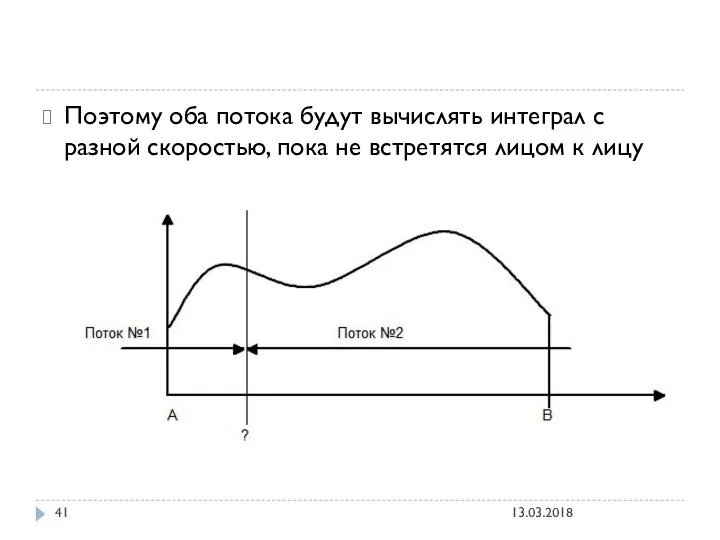
Поэтому оба потока будут вычислять интеграл с разной скоростью, пока не
Поэтому оба потока будут вычислять интеграл с разной скоростью, пока не

Что касаемо программы
Многопоточность в Java
13.03.2018
Что касаемо программы
Многопоточность в Java
13.03.2018

Процесс — это совокупность кода и данных, разделяющих общее виртуальное адресное
Процесс — это совокупность кода и данных, разделяющих общее виртуальное адресное
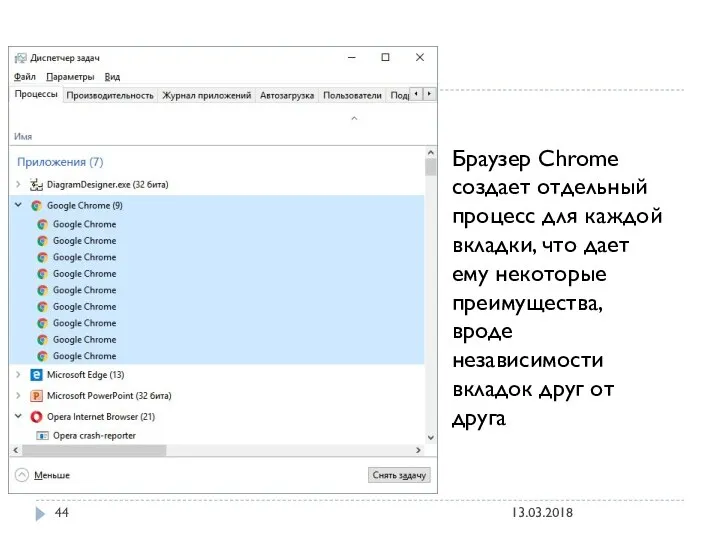
Браузер Chrome создает отдельный процесс для каждой вкладки, что дает ему
Браузер Chrome создает отдельный процесс для каждой вкладки, что дает ему

ОС оперирует так называемыми страницами памяти, которые представляют собой просто область
ОС оперирует так называемыми страницами памяти, которые представляют собой просто область

Один поток – это одна единица исполнения кода. Каждый поток последовательно
Один поток – это одна единица исполнения кода. Каждый поток последовательно

Псевдо-параллелизм.
Система запоминает состояние (контекст) каждого потока, перед тем как переключиться на
Псевдо-параллелизм.
Система запоминает состояние (контекст) каждого потока, перед тем как переключиться на

УКРЕПИМ ЗНАНИЯ:
Процессы изолированы друг от друга, поэтому прямой доступ к памяти
УКРЕПИМ ЗНАНИЯ:
Процессы изолированы друг от друга, поэтому прямой доступ к памяти

JAVA
Каждый процесс имеет хотя бы один выполняющийся поток. Тот поток, с
JAVA
Каждый процесс имеет хотя бы один выполняющийся поток. Тот поток, с
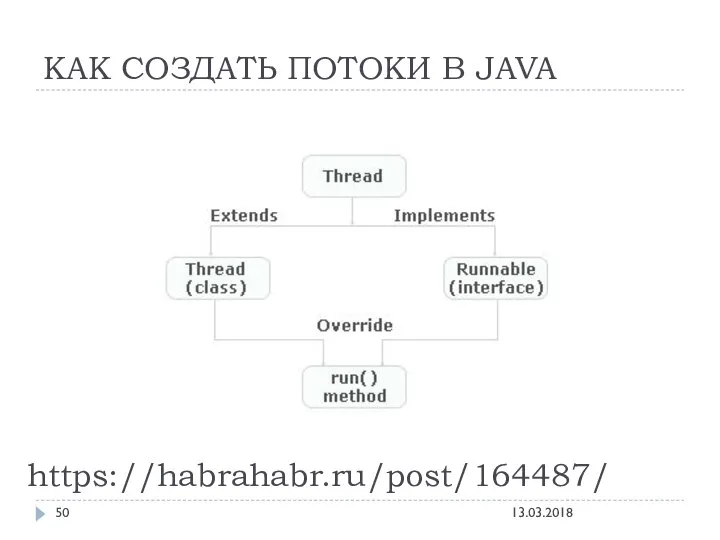
КАК СОЗДАТЬ ПОТОКИ В JAVA
https://habrahabr.ru/post/164487/
13.03.2018
КАК СОЗДАТЬ ПОТОКИ В JAVA
https://habrahabr.ru/post/164487/
13.03.2018

СПОСОБ №1 СОЗДАТЬ ПОТОК В JAVA С ПОМОЩЬЮ ИНТЕРФЕЙСА RUNNABLE
13.03.2018
СПОСОБ №1 СОЗДАТЬ ПОТОК В JAVA С ПОМОЩЬЮ ИНТЕРФЕЙСА RUNNABLE
13.03.2018
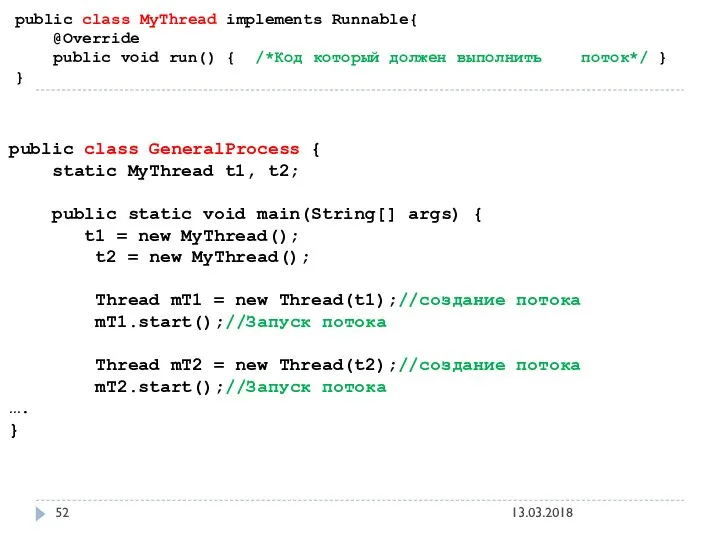
public class MyThread implements Runnable{
@Override
public void run() {
public class MyThread implements Runnable{
@Override
public void run() {

СПОСОБ №2: НАСЛЕДОВАНИЕ ОТ КЛАССА THREAD
13.03.2018
СПОСОБ №2: НАСЛЕДОВАНИЕ ОТ КЛАССА THREAD
13.03.2018

public class MyThread extends Thread{
@Override
public void run() {
public class MyThread extends Thread{
@Override
public void run() {

В ЧЕМ РАЗНИЦА МЕЖДУ РЕАЛИЗАЦИЕЙ ИНТЕРФЕЙСА RUNNABLE И НАСЛЕДОВАНИЕМ ОТ КЛАССА
В ЧЕМ РАЗНИЦА МЕЖДУ РЕАЛИЗАЦИЕЙ ИНТЕРФЕЙСА RUNNABLE И НАСЛЕДОВАНИЕМ ОТ КЛАССА

ДАВАЙТЕ ИЗУЧИМ КОД:
13.03.2018
ДАВАЙТЕ ИЗУЧИМ КОД:
13.03.2018

13.03.2018
13.03.2018

13.03.2018
13.03.2018

В интерфейсе Runnable создается только один экземпляр класса, и он разделяется
В интерфейсе Runnable создается только один экземпляр класса, и он разделяется

Когда использовать Runnable?
Используйте интерфейс Runnable, если вы хотите получить доступ к
Когда использовать Runnable? Используйте интерфейс Runnable, если вы хотите получить доступ к

Когда вы реализуете интерфейс Runnable, вы можете сохранить пространство для своего класса
Когда вы реализуете интерфейс Runnable, вы можете сохранить пространство для своего класса

В задачи нашего курса не входит освоение ЯВУ, давайте все же
В задачи нашего курса не входит освоение ЯВУ, давайте все же
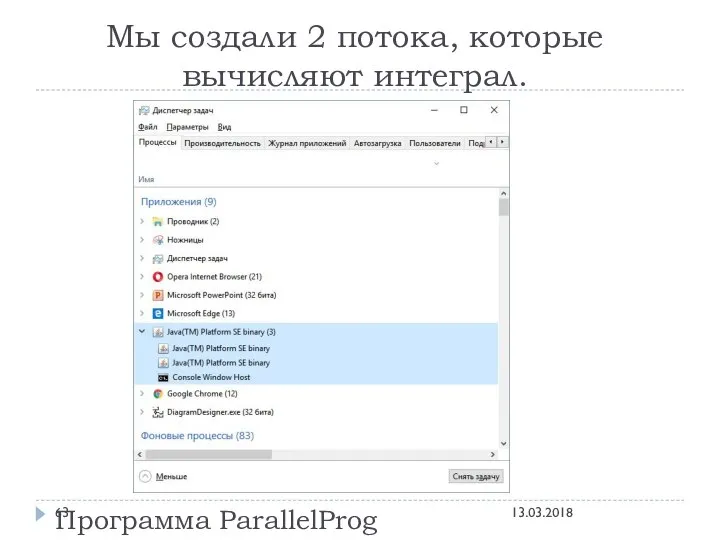
Мы создали 2 потока, которые вычисляют интеграл.
Программа ParallelProg
13.03.2018
Мы создали 2 потока, которые вычисляют интеграл.
Программа ParallelProg
13.03.2018
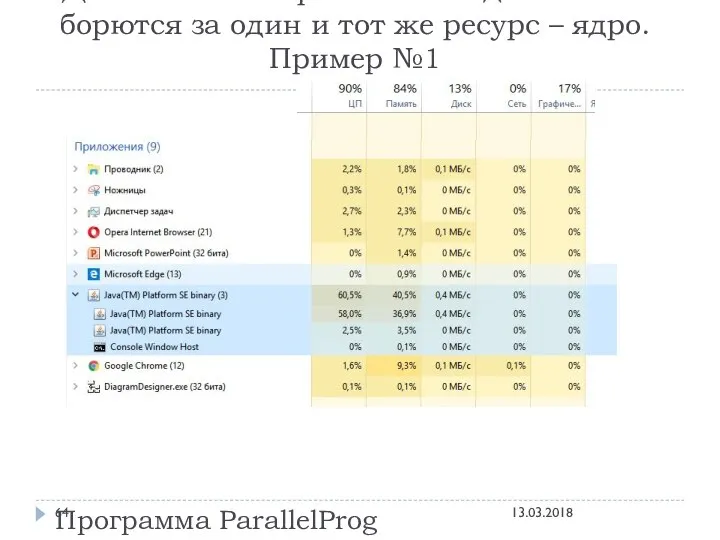
Давайте посмотрим как эти два потока борются за один и тот
Давайте посмотрим как эти два потока борются за один и тот
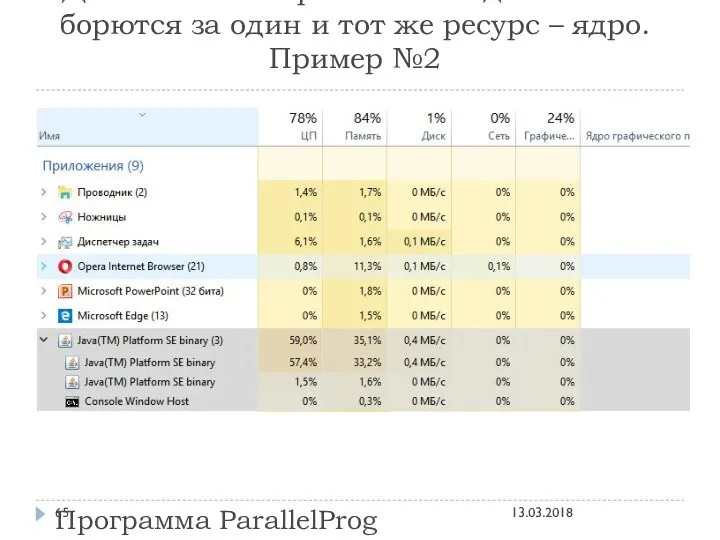
Давайте посмотрим как эти два потока борются за один и тот
Давайте посмотрим как эти два потока борются за один и тот
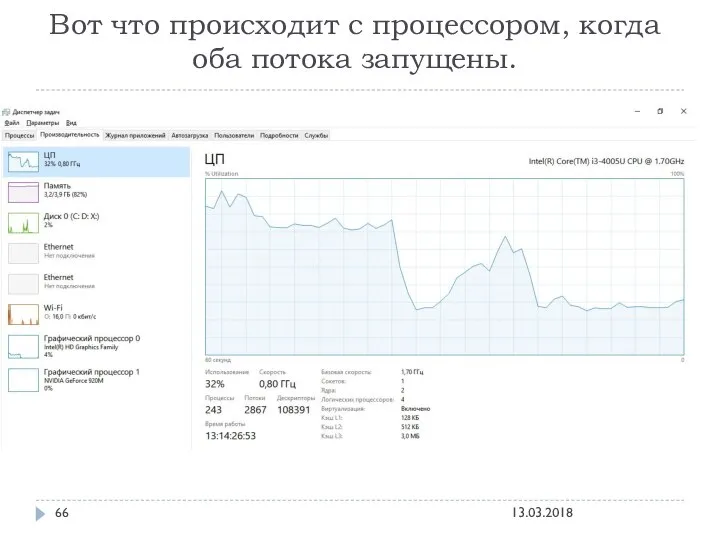
Вот что происходит с процессором, когда оба потока запущены.
13.03.2018
Вот что происходит с процессором, когда оба потока запущены.
13.03.2018
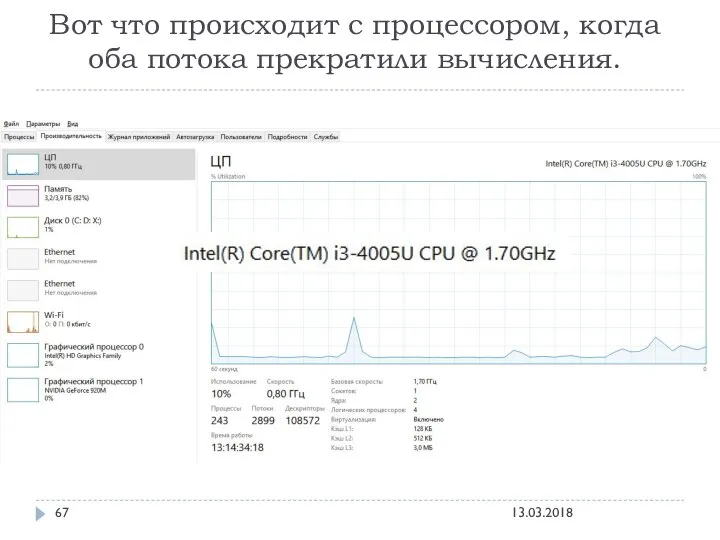
Вот что происходит с процессором, когда оба потока прекратили вычисления.
13.03.2018
Вот что происходит с процессором, когда оба потока прекратили вычисления.
13.03.2018

РЕЗУЛЬТАТЫ ТЕСТИРОВАНИЯ
Мы видим, что при параллельном выполнении задачи мы улучшили показатели
РЕЗУЛЬТАТЫ ТЕСТИРОВАНИЯ
Мы видим, что при параллельном выполнении задачи мы улучшили показатели

ВОПРОС: ПОЧЕМУ ВРЕМЯ ВЫЧИСЛЕНИЯ ИНТЕГРАЛА НЕ УЛУЧШИЛОСЬ ПРИ ПАРАЛЛЕЛЬНОМ ПОДХОДЕ НА
ВОПРОС: ПОЧЕМУ ВРЕМЯ ВЫЧИСЛЕНИЯ ИНТЕГРАЛА НЕ УЛУЧШИЛОСЬ ПРИ ПАРАЛЛЕЛЬНОМ ПОДХОДЕ НА

ОТВЕТ:
В данном примере обе задачи были однотипные, а значит им требовались
ОТВЕТ:
В данном примере обе задачи были однотипные, а значит им требовались

ПРОВЕДЕМ НОВЫЕ ИССЛЕДОВАНИЯ!
Создадим два параллельных потока:
Первый поток будет вычислять интеграл для
ПРОВЕДЕМ НОВЫЕ ИССЛЕДОВАНИЯ!
Создадим два параллельных потока:
Первый поток будет вычислять интеграл для
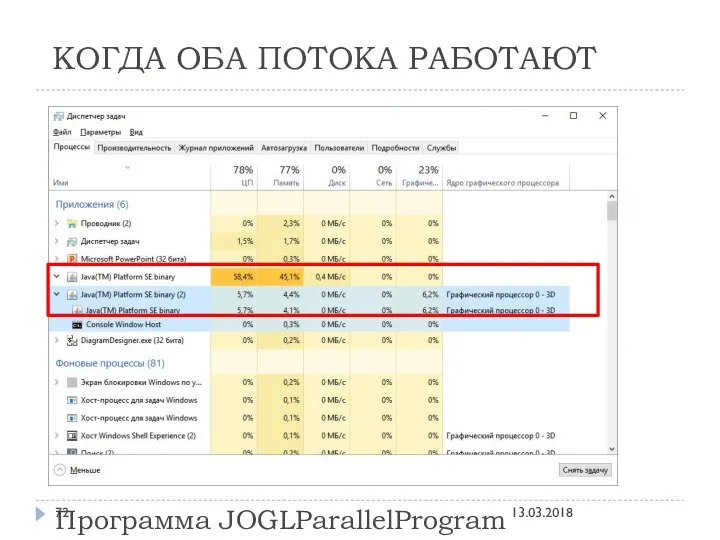
КОГДА ОБА ПОТОКА РАБОТАЮТ
Программа JOGLParallelProgram
13.03.2018
КОГДА ОБА ПОТОКА РАБОТАЮТ
Программа JOGLParallelProgram
13.03.2018
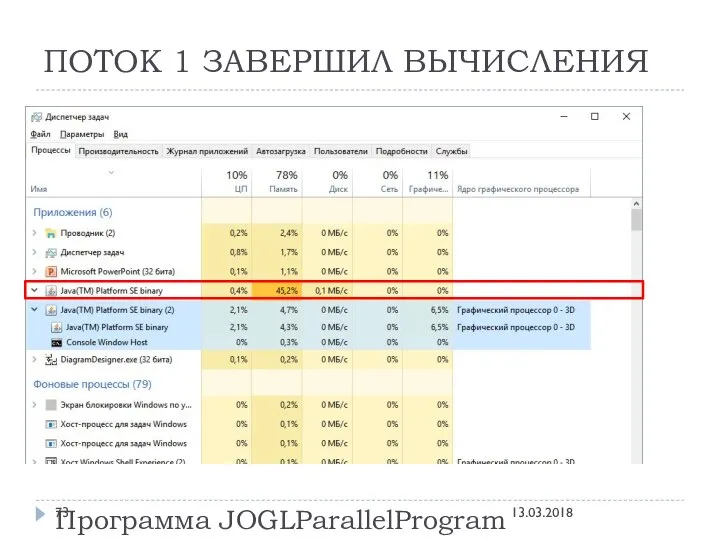
ПОТОК 1 ЗАВЕРШИЛ ВЫЧИСЛЕНИЯ
Программа JOGLParallelProgram
13.03.2018
ПОТОК 1 ЗАВЕРШИЛ ВЫЧИСЛЕНИЯ
Программа JOGLParallelProgram
13.03.2018

ОБРАТИМСЯ К ФИЛОСОФИИ☺
Ответит ли нам программа на вечный вопрос: Что появилось
ОБРАТИМСЯ К ФИЛОСОФИИ☺
Ответит ли нам программа на вечный вопрос: Что появилось

РЕЗУЛЬТАТЫ СПОРА:
13.03.2018
РЕЗУЛЬТАТЫ СПОРА:
13.03.2018
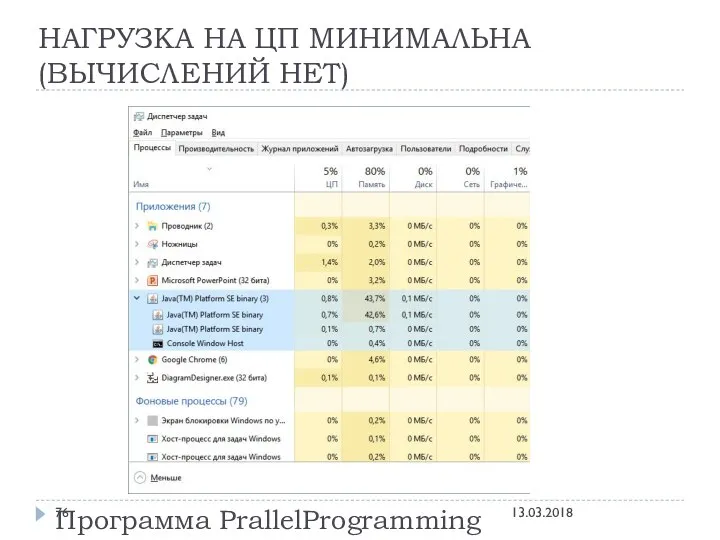
НАГРУЗКА НА ЦП МИНИМАЛЬНА (ВЫЧИСЛЕНИЙ НЕТ)
Программа PrallelProgramming
13.03.2018
НАГРУЗКА НА ЦП МИНИМАЛЬНА (ВЫЧИСЛЕНИЙ НЕТ)
Программа PrallelProgramming
13.03.2018

ПРОВЕДЕМ 100 АНАЛОГИЧНЫХ ТЕСТОВ, ЧТОБЫ УЗНАТЬ ВЕРОЯТНОСТЬ ВЫДАЧИ ОТВЕТА
13.03.2018
ПРОВЕДЕМ 100 АНАЛОГИЧНЫХ ТЕСТОВ, ЧТОБЫ УЗНАТЬ ВЕРОЯТНОСТЬ ВЫДАЧИ ОТВЕТА
13.03.2018

РЕЗУЛЬТАТЫ ТЕСТИРОАНИЯ:
ЯЙЦО vs КУРИЦА
ПОБЕЖДАЕТ ЯЙЦО СО СЧЕТОМ
88:12
13.03.2018
РЕЗУЛЬТАТЫ ТЕСТИРОАНИЯ:
ЯЙЦО vs КУРИЦА
ПОБЕЖДАЕТ ЯЙЦО СО СЧЕТОМ
88:12
13.03.2018
 Ультразвуковая размерная обработка материалов
Ультразвуковая размерная обработка материалов Проектирование и конструирование второстепенной балки
Проектирование и конструирование второстепенной балки Презентация территориально-структурное деление таможенных органов
Презентация территориально-структурное деление таможенных органов  Корпускулярно- волновая природа света
Корпускулярно- волновая природа света Кубизм в архитектуре. Оригами
Кубизм в архитектуре. Оригами Комбинированный алгоритм. Программирование черепашки для постройки дома. Использование инвентаряв одной программе
Комбинированный алгоритм. Программирование черепашки для постройки дома. Использование инвентаряв одной программе Разработка беспилотников для условий Севера
Разработка беспилотников для условий Севера Правовое государство
Правовое государство Муниципальное дошкольное образовательное учреждение Центр развития ребенка- детский сад №36 Педагогический совет №2 «Здоровье
Муниципальное дошкольное образовательное учреждение Центр развития ребенка- детский сад №36 Педагогический совет №2 «Здоровье Тема: Использование метода проекта в специальной (коррекционной) школе VIII вида Учитель: Шульгина Татьяна Николаевна
Тема: Использование метода проекта в специальной (коррекционной) школе VIII вида Учитель: Шульгина Татьяна Николаевна Word переход и поиск
Word переход и поиск История развития телевидения как средства массовой информации
История развития телевидения как средства массовой информации Raspberry Pi India
Raspberry Pi India Война СССР в Афганистане
Война СССР в Афганистане  Словарные слова 3 класс
Словарные слова 3 класс  Вопросы к рейтинг-контролю
Вопросы к рейтинг-контролю Presentation Template Creative, Ideas
Presentation Template Creative, Ideas Ҡаҙ өмәһе
Ҡаҙ өмәһе Использование материалов инвентаризации в оперативно-следственной практике
Использование материалов инвентаризации в оперативно-следственной практике Профессия дорожники. Строительство дорог
Профессия дорожники. Строительство дорог Презентация Россия в 18 веке
Презентация Россия в 18 веке Почему в лесу нужно соблюдать тишину? Автор: Кульчицкая И.Н. Учитель начальных классов.
Почему в лесу нужно соблюдать тишину? Автор: Кульчицкая И.Н. Учитель начальных классов. БИОФИЗИКА АНАЛИЗАТОРОВ
БИОФИЗИКА АНАЛИЗАТОРОВ Dekooder
Dekooder Операционные системы. Введение (часть 1)
Операционные системы. Введение (часть 1) Специфические методы и этапы статистического исследования
Специфические методы и этапы статистического исследования Сделка: понятие, формы, виды. Условия действительности сделок. Обязательства: понятие, виды, способы обеспечения исполнения
Сделка: понятие, формы, виды. Условия действительности сделок. Обязательства: понятие, виды, способы обеспечения исполнения Нормальная физиология
Нормальная физиология