- Технология CUDA

Содержание
- 2. Что такое CUDA? CUDA – это архитектура параллельных вычислений от NVIDIA, позволяющая существенно увеличить вычислительную производительность
- 3. Немного о GPU Первый вопрос, который должен задать каждый перед применением GPU для решения своих задач
- 4. Базовые понятия и термины Устройство (device) — GPU. Выполняет роль «подчиненного» — делает только то, что
- 5. Базовые понятия и термины Ядра Рассмотрим более детально процесс написания кода для ядер и их запуска.
- 6. Базовые понятия и термины Каким же образом мы задаем количество потоков, в которых будет запущено ядро?
- 7. Основные этапы CUDA-программы Хост выделяет нужное количество памяти на устройстве. Хост копирует данные из своей памяти
- 8. Аппаратное обеспечение GPU CUDA-совместимый GPU состоит из нескольких (обычно десятков) streaming multiprocessors (потоковых мультипроцессоров), далее SM.
- 9. Аппаратное обеспечение GPU Согласно модели CUDA, программист разбивает задачу на блоки, а блоки на потоки. Каким
- 10. Синхронизация в CUDA Барьер — точка в коде ядра, по достижению которой поток может «пройти» дальше,
- 12. Скачать презентацию

Что такое CUDA?
CUDA – это архитектура параллельных вычислений от NVIDIA, позволяющая
Что такое CUDA?
CUDA – это архитектура параллельных вычислений от NVIDIA, позволяющая

Немного о GPU
Первый вопрос, который должен задать каждый перед применением GPU
Немного о GPU
Первый вопрос, который должен задать каждый перед применением GPU

Базовые понятия и термины
Устройство (device) — GPU. Выполняет роль «подчиненного» — делает
Базовые понятия и термины
Устройство (device) — GPU. Выполняет роль «подчиненного» — делает

Базовые понятия и термины
Ядра
Рассмотрим более детально процесс написания кода для
Базовые понятия и термины
Ядра
Рассмотрим более детально процесс написания кода для

Базовые понятия и термины
Каким же образом мы задаем количество потоков, в
Базовые понятия и термины
Каким же образом мы задаем количество потоков, в

Основные этапы CUDA-программы
Хост выделяет нужное количество памяти на устройстве.
Хост копирует данные
Основные этапы CUDA-программы
Хост выделяет нужное количество памяти на устройстве.
Хост копирует данные

Аппаратное обеспечение GPU
CUDA-совместимый GPU состоит из нескольких (обычно десятков) streaming multiprocessors (потоковых мультипроцессоров),
Аппаратное обеспечение GPU
CUDA-совместимый GPU состоит из нескольких (обычно десятков) streaming multiprocessors (потоковых мультипроцессоров),

Аппаратное обеспечение GPU
Согласно модели CUDA, программист разбивает задачу на блоки, а
Аппаратное обеспечение GPU
Согласно модели CUDA, программист разбивает задачу на блоки, а

Синхронизация в CUDA
Барьер — точка в коде ядра, по достижению которой поток
Синхронизация в CUDA
Барьер — точка в коде ядра, по достижению которой поток
 Преступления против семьи и несовершеннолетних
Преступления против семьи и несовершеннолетних химия [Автосохраненный]
химия [Автосохраненный] Презентация Систематизация законодательства
Презентация Систематизация законодательства Здравствуйте, это мы! Визитная карточка ДОО, функционирующих в МОУ «СОШ» с.п. Совхозное
Здравствуйте, это мы! Визитная карточка ДОО, функционирующих в МОУ «СОШ» с.п. Совхозное Основні схеми та будова електричних мереж
Основні схеми та будова електричних мереж Алгоритм стереозрения
Алгоритм стереозрения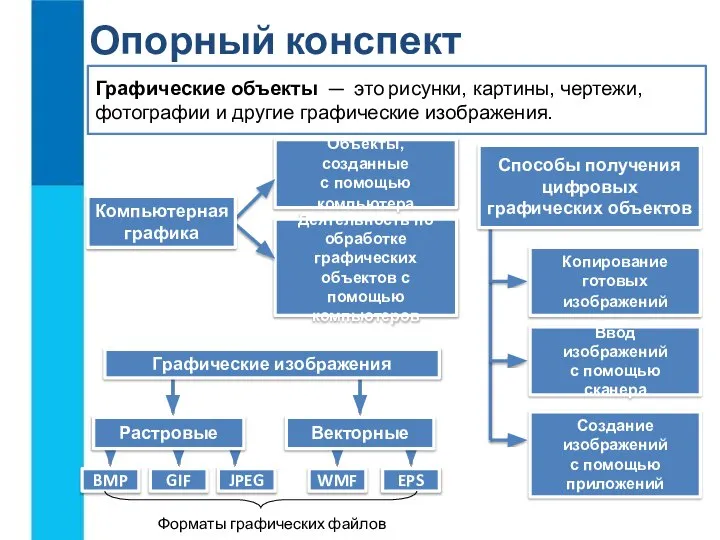 Графические объекты. Опорный конспект
Графические объекты. Опорный конспект Страна Япония
Страна Япония Прибыль и рентабельность. 1. Классификация затрат для определения прибыли. 2. Виды себестоимости. 3. &nbs
Прибыль и рентабельность. 1. Классификация затрат для определения прибыли. 2. Виды себестоимости. 3. &nbs Инстументальная коммуникационная деятельность
Инстументальная коммуникационная деятельность Совещание первосвященников об убиении Христа. Предательство Иуды
Совещание первосвященников об убиении Христа. Предательство Иуды Автоматизированная информационно-измерительная система коммерческого учета электроэнергии АИИС КУЭ БП «Нейрон»
Автоматизированная информационно-измерительная система коммерческого учета электроэнергии АИИС КУЭ БП «Нейрон» Законодательные и нормативно-правовые акты, регулирующие проведение ресурсосбережения на объектах коммунального хозяйства
Законодательные и нормативно-правовые акты, регулирующие проведение ресурсосбережения на объектах коммунального хозяйства 02.01 Плоские геометрические фигуры 2
02.01 Плоские геометрические фигуры 2 ПРАВОВОЕ РЕГУЛИРОВАНИЕ АДМИНИСТРАТИВНОЙ ОТВЕТСТВЕННОСТИ. Выполнила :Панасенко А.С. Группа Э091
ПРАВОВОЕ РЕГУЛИРОВАНИЕ АДМИНИСТРАТИВНОЙ ОТВЕТСТВЕННОСТИ. Выполнила :Панасенко А.С. Группа Э091 Behalten sie ruhe und deutsch lernen
Behalten sie ruhe und deutsch lernen МЕНЕДЖМЕНТ И ОРГАНИЗАЦИОННАЯ ДЕМОКРАТИЯ
МЕНЕДЖМЕНТ И ОРГАНИЗАЦИОННАЯ ДЕМОКРАТИЯ Программы, которые используются в строительстве: AutoCAD, ArchiCAD, Revit, SketchUp, Blender
Программы, которые используются в строительстве: AutoCAD, ArchiCAD, Revit, SketchUp, Blender Организация зоны технического обслуживания и ремонта АТП «ИП Дедов» по восстановлению коленчатого вала автомобилей ЗИЛ 130
Организация зоны технического обслуживания и ремонта АТП «ИП Дедов» по восстановлению коленчатого вала автомобилей ЗИЛ 130 О введении обязательной маркировки
О введении обязательной маркировки Талдау-табыс кілті
Талдау-табыс кілті Дизайн и архитектура. Итоговое тестирование. ИЗО. 7 класс
Дизайн и архитектура. Итоговое тестирование. ИЗО. 7 класс Программные средства эконометрического анализа и прогнозирования
Программные средства эконометрического анализа и прогнозирования Чистый четверг. День 4. Для малышей. Возраст 2 года – 5 лет
Чистый четверг. День 4. Для малышей. Возраст 2 года – 5 лет تررین پرترا جامع ترین و پرر ینننر ت اجتماعی کشور
تررین پرترا جامع ترین و پرر ینننر ت اجتماعی کشور Особые приемы психологического воздействия на людей Выполнила студентка группы Ю-104 Чуева Яна
Особые приемы психологического воздействия на людей Выполнила студентка группы Ю-104 Чуева Яна  «Музеи в орбите учебно-воспитательного процесса в начальной школе: эффекты и феномены»
«Музеи в орбите учебно-воспитательного процесса в начальной школе: эффекты и феномены» Архитектура: от модерна до конструктивизма
Архитектура: от модерна до конструктивизма