- Молекулярные базы данных. Принцип действия и характеристики основных компьютерных программ

Содержание
- 2. Новейшим методом изучения природных молекул является применение информационных систем. Работая с информационными моделями молекул, исследователь обычно
- 3. Компьютерным моделированием молекулярно-генетических и смежных процессов занимаются такие науки как биоинформатика, системная биология, геномика, эволюционная генетика,
- 4. Биоинформатика Биоинформатика — это область науки, разрабатывающая и применяющая вычислительные алгоритмы для систематизации и анализа генетической
- 5. Биоинформатика включает в себя: базы данных, в которых хранится биологическая информация набор инструментов для анализа тех
- 6. Задачи, решаемые биоинформатикой
- 7. Биолог в биоинформатике обычно имеет дело с базами данных и инструментами их анализа. Теперь разберемся, какие
- 8. Второй тип – курируемые базы данных, за достоверность которых отвечает хозяин базы данных. Туда информацию никто
- 9. Поддержание базы требует работы кураторов или аннотаторов. Тем не менее, даже в курируемых базах данных могут
- 10. Третий тип – производные базы данных. Такие базы получаются в результате обработки данных из архивных и
- 11. И интегрированные базы данных, в которых вся информация (курируемая, не курируемая) свалена в кучу, и введя
- 12. Теперь перейдем к рассмотрению инструментов биоинформатики. Инструменты определяются задачами, которые мы хотим решать. Основу биоинформатики составляют
- 13. Как сравнивают последовательности? Запишем одну последовательность под другой: attgtACcTCgTgG-AA---- -----AC-TCaTaGcAAccag Нам надо при сравнении найти наилучший
- 14. Таким образом, первым делом после секвенирования последовательности ищут в базах данных похожие последовательности, чтобы после сравнения
- 15. Молекулярно-генетические данные хранятся в специализированных банках данных (все на английском языке): крупнейшая база генетических данных –
- 16. удобная в навигации база генетических последовательностей – Ensembl
- 17. удобный доступ к полным геномам через сайт Европейского института биоинформатики - http://www.ebi.ac.uk/genomes/
- 18. крупнейший банк белковых данных – UniProt.org
- 19. крупнейший банк данных о структуре биологических макромолекул http://www.pdb.org/
- 20. Информационные системы, касающиеся моделей макромолекул и надмолекулярных структур: GeneBank & EMBL – здесь хранятся первичные последовательности
- 21. Окно программы Discovery Studio Видны вторичные и третичные структуры, поверхность белка кальмодулина. Доступные инструменты расположены слева
- 22. CAZy: Carbohydrate-Active Enzymes Database. На сайте представлена современная классификация ферментов синтеза и утилизации углеводов, а также
- 23. http://molbiol.edu.ru/review/01_01.html
- 29. Форматы файлов, используемых в биоинформатике FASTA >roa1_drome Rea guano receptor type III >> 0.1 MVNSNQNQNGNSNGHDDDFPQDSITEPEHMRKLFIGGLDYRTTDENLKAHEKWGNIVDVVVMKDPRTKRSRGFGFITYSHSSMIDEAQKSRPHKIDGRVEPKRAVPRQDIDSPNAGATVKKLFVGALKDDHDEQSIRDYFQHFGNIVDNIVIDKETGKKRGFAFVEFDDYDPVDKVVLQKQHQLNGKMVDVKKALPKNDQQGGGGGRGGPGGRAGGNRGNMGGGNYGNQNGGGNWNNGGNNWGNNRGNDNWGNNSFGGGGGGGGGYGGGNNSWGNNNPWDNGNGGGNFGGGGNNWNGGNDFGGYQQNYGGGPQRGGGNFNNNRMQPYQGGGGFKAGGGNQGNYGNNQGFNNGGNNRRY >roa2_drome
- 30. GenBank LOCUS SCU49845 5028 bp DNA PLN 21-JUN-1999 DEFINITION Saccharomyces cerevisiae TCP1-beta gene, partial cds, and
- 31. GenBank. Запись sequence
- 32. GenBank. Запись mRNA
- 33. Сплайсинг и восстановление последовательности mRNA mRNA seq=(AF018429.1:282-561)+(AF018429.1:1034-1172)+(AF018430.1:560-651)+(AF018430.1:1-45)+………
- 34. GenBank. Запись genomic DNA
- 35. GenBank. Аннотация
- 36. Как добавить данные в GB? http://www.ncbi.nlm.nih.gov/ Genbank/submit.html Зачем? информация в community; Журналы требуют это ДО публикации
- 37. Форматы описания белков PDB PDB-XML MMDB-Cn3D
- 38. PDB – Protein Data Bank HEADER LUMINESCENT PROTEIN 09-DEC-03 1RRX TITLE CRYSTALLOGRAPHIC EVIDENCE FOR ISOMERIC CHROMOPHORES
- 39. HELIX 1 1 GLU A 5 THR A 9 5 5 HELIX 2 2 ALA A
- 40. PDB-XML PDBML: the representation of archival macromolecular structure data in XML. John Wesbrook, Nobutoshi Ito, Haruki
- 42. Скачать презентацию

Новейшим методом изучения природных молекул является применение информационных систем.
Работая с
Новейшим методом изучения природных молекул является применение информационных систем.
Работая с

Компьютерным моделированием молекулярно-генетических и смежных процессов занимаются такие науки как биоинформатика,
Компьютерным моделированием молекулярно-генетических и смежных процессов занимаются такие науки как биоинформатика,

Биоинформатика
Биоинформатика — это область науки, разрабатывающая и применяющая вычислительные алгоритмы для
Биоинформатика
Биоинформатика — это область науки, разрабатывающая и применяющая вычислительные алгоритмы для

Биоинформатика включает в себя:
базы данных, в которых хранится биологическая информация
набор инструментов
Биоинформатика включает в себя:
базы данных, в которых хранится биологическая информация
набор инструментов

Задачи, решаемые биоинформатикой
Задачи, решаемые биоинформатикой

Биолог в биоинформатике обычно имеет дело с базами данных и инструментами
Биолог в биоинформатике обычно имеет дело с базами данных и инструментами

Второй тип – курируемые базы данных, за достоверность которых отвечает хозяин
Второй тип – курируемые базы данных, за достоверность которых отвечает хозяин

Поддержание базы требует работы кураторов или аннотаторов. Тем не менее, даже в
Поддержание базы требует работы кураторов или аннотаторов. Тем не менее, даже в

Третий тип – производные базы данных. Такие базы получаются в результате
Третий тип – производные базы данных. Такие базы получаются в результате

И интегрированные базы данных, в которых вся информация (курируемая, не курируемая)
И интегрированные базы данных, в которых вся информация (курируемая, не курируемая)

Теперь перейдем к рассмотрению инструментов биоинформатики. Инструменты определяются задачами, которые мы
Теперь перейдем к рассмотрению инструментов биоинформатики. Инструменты определяются задачами, которые мы

Как сравнивают последовательности? Запишем одну последовательность под другой:
attgtACcTCgTgG-AA----
-----AC-TCaTaGcAAccag
Нам надо при сравнении
Как сравнивают последовательности? Запишем одну последовательность под другой:
attgtACcTCgTgG-AA----
-----AC-TCaTaGcAAccag
Нам надо при сравнении

Таким образом, первым делом после секвенирования последовательности ищут в базах данных
Таким образом, первым делом после секвенирования последовательности ищут в базах данных
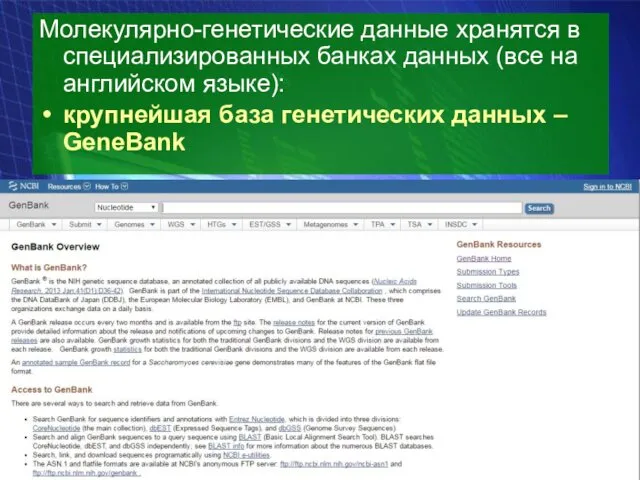
Молекулярно-генетические данные хранятся в специализированных банках данных (все на английском языке):
Молекулярно-генетические данные хранятся в специализированных банках данных (все на английском языке):
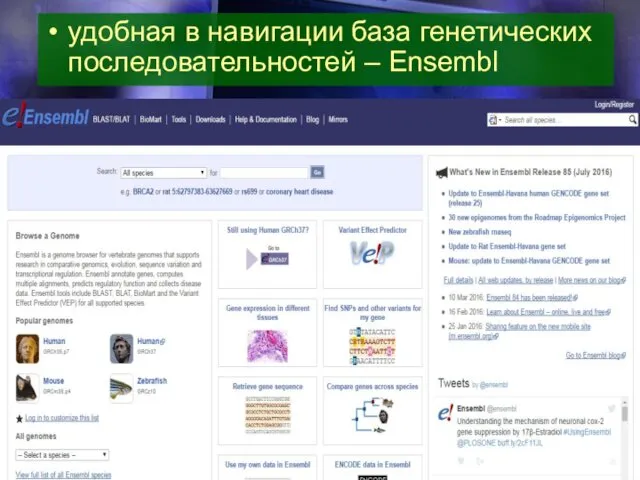
удобная в навигации база генетических последовательностей – Ensembl
удобная в навигации база генетических последовательностей – Ensembl
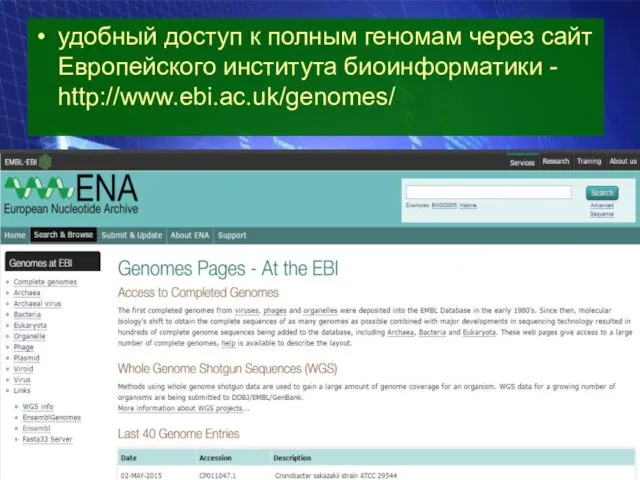
удобный доступ к полным геномам через сайт Европейского института биоинформатики -
удобный доступ к полным геномам через сайт Европейского института биоинформатики -
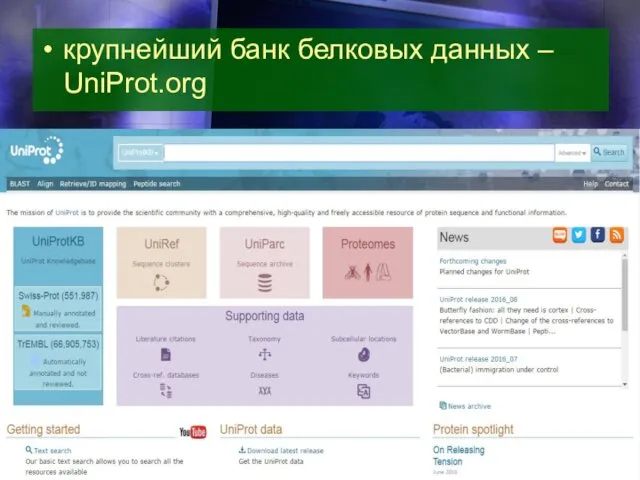
крупнейший банк белковых данных – UniProt.org
крупнейший банк белковых данных – UniProt.org
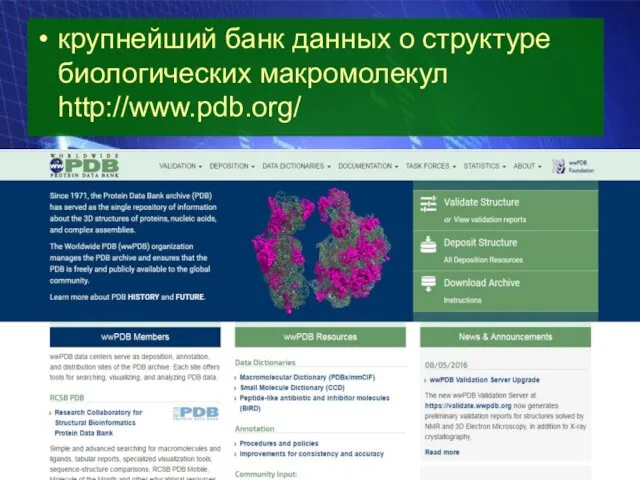
крупнейший банк данных о структуре биологических макромолекул http://www.pdb.org/
крупнейший банк данных о структуре биологических макромолекул http://www.pdb.org/

Информационные системы, касающиеся моделей макромолекул и надмолекулярных структур:
GeneBank & EMBL
Информационные системы, касающиеся моделей макромолекул и надмолекулярных структур:
GeneBank & EMBL
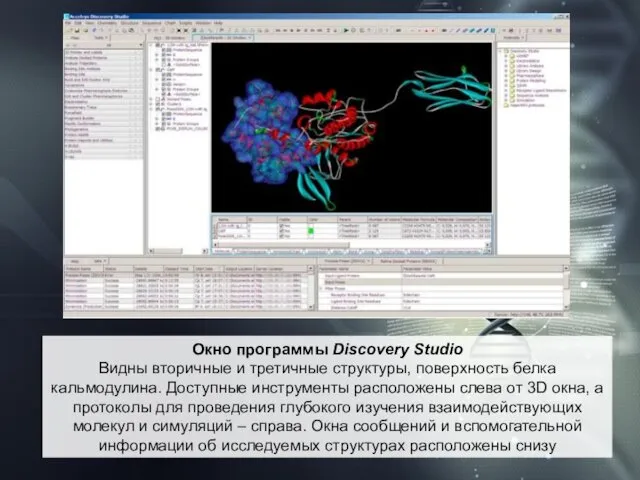
Окно программы Discovery Studio
Видны вторичные и третичные структуры, поверхность белка
Окно программы Discovery Studio
Видны вторичные и третичные структуры, поверхность белка

CAZy: Carbohydrate-Active Enzymes Database.
На сайте представлена современная классификация ферментов синтеза и
CAZy: Carbohydrate-Active Enzymes Database. На сайте представлена современная классификация ферментов синтеза и

http://molbiol.edu.ru/review/01_01.html
http://molbiol.edu.ru/review/01_01.html





Форматы файлов, используемых в биоинформатике
FASTA
>roa1_drome Rea guano receptor type III >>
Форматы файлов, используемых в биоинформатике
FASTA
>roa1_drome Rea guano receptor type III >>

GenBank
LOCUS SCU49845 5028 bp DNA PLN 21-JUN-1999
DEFINITION Saccharomyces cerevisiae TCP1-beta gene,
GenBank
LOCUS SCU49845 5028 bp DNA PLN 21-JUN-1999
DEFINITION Saccharomyces cerevisiae TCP1-beta gene,

GenBank. Запись sequence
GenBank. Запись sequence
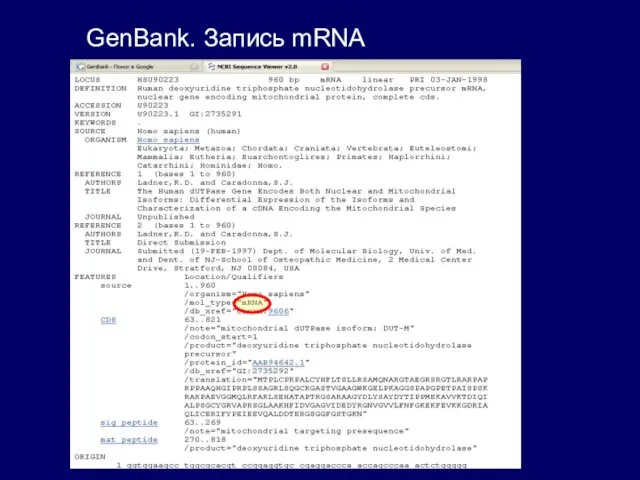
GenBank. Запись mRNA
GenBank. Запись mRNA
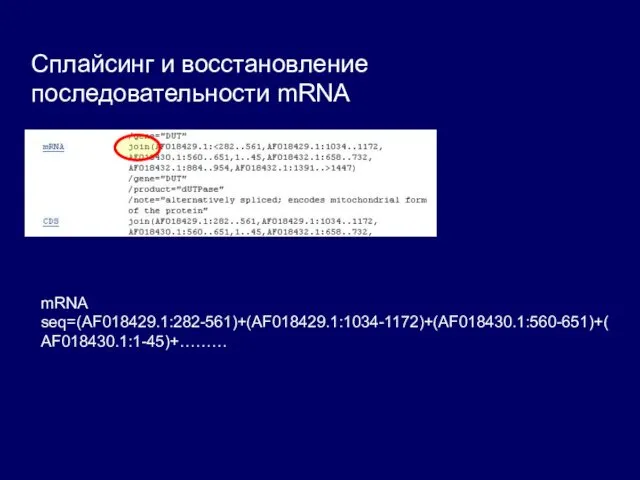
Сплайсинг и восстановление последовательности mRNA
mRNA seq=(AF018429.1:282-561)+(AF018429.1:1034-1172)+(AF018430.1:560-651)+(AF018430.1:1-45)+………
Сплайсинг и восстановление последовательности mRNA
mRNA seq=(AF018429.1:282-561)+(AF018429.1:1034-1172)+(AF018430.1:560-651)+(AF018430.1:1-45)+………
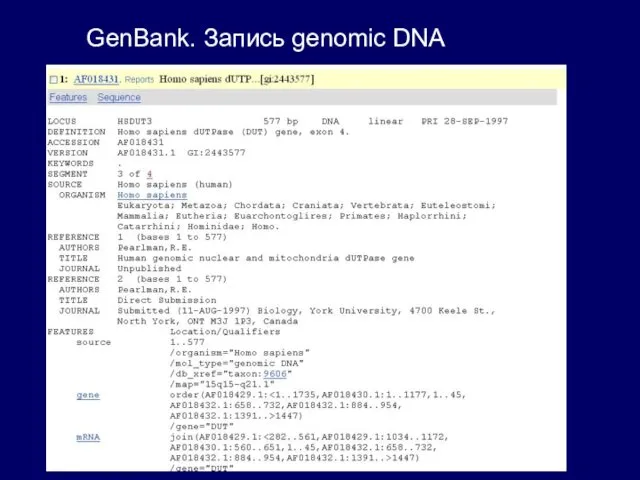
GenBank. Запись genomic DNA
GenBank. Запись genomic DNA

GenBank. Аннотация
GenBank. Аннотация
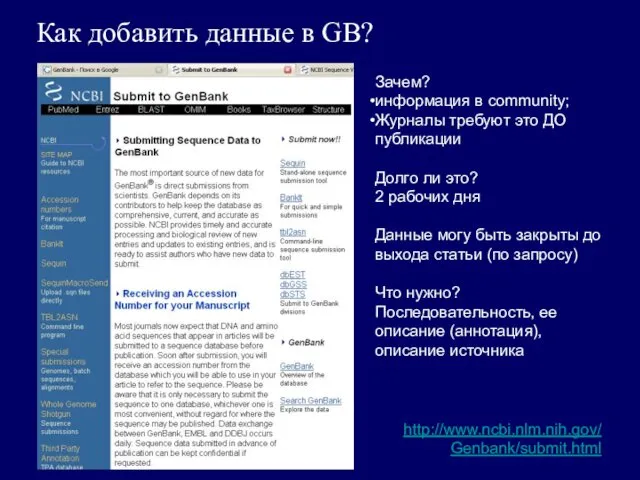
Как добавить данные в GB?
http://www.ncbi.nlm.nih.gov/
Genbank/submit.html
Зачем?
информация в community;
Журналы требуют это ДО публикации
Долго
Как добавить данные в GB?
http://www.ncbi.nlm.nih.gov/
Genbank/submit.html
Зачем?
информация в community;
Журналы требуют это ДО публикации
Долго

Форматы описания белков
PDB
PDB-XML
MMDB-Cn3D
Форматы описания белков
PDB
PDB-XML
MMDB-Cn3D

PDB – Protein Data Bank
HEADER LUMINESCENT PROTEIN 09-DEC-03 1RRX
TITLE CRYSTALLOGRAPHIC
PDB – Protein Data Bank
HEADER LUMINESCENT PROTEIN 09-DEC-03 1RRX
TITLE CRYSTALLOGRAPHIC
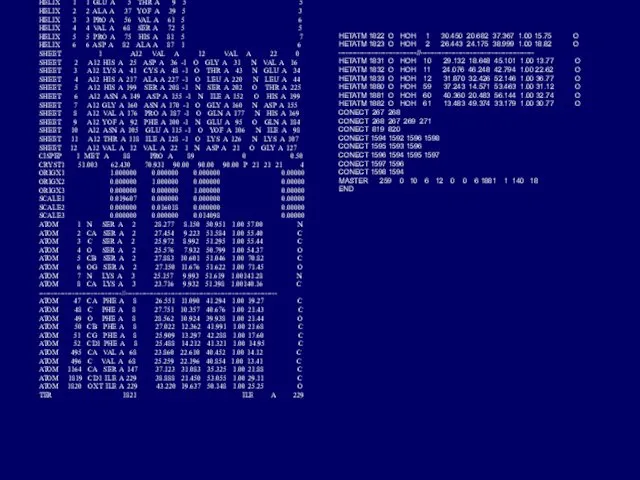
HELIX 1 1 GLU A 5 THR A 9 5 5
HELIX 1 1 GLU A 5 THR A 9 5 5

PDB-XML
PDBML: the representation of archival macromolecular structure data in XML. John
PDB-XML
PDBML: the representation of archival macromolecular structure data in XML. John
 Биопластики: область применения
Биопластики: область применения Эмульсиялардың тұрақтылығына полиэтиленгликоль-баз композицияларының әсері
Эмульсиялардың тұрақтылығына полиэтиленгликоль-баз композицияларының әсері Кристаллография. История развития
Кристаллография. История развития Производство фенолформальдегидной смолы
Производство фенолформальдегидной смолы Обмен липидов. Классификация липидов
Обмен липидов. Классификация липидов Хімічний склад синтетичних миючих засобів та їх основні нормативно-технічні показники
Хімічний склад синтетичних миючих засобів та їх основні нормативно-технічні показники Химия элементов VA группы
Химия элементов VA группы Органические производные титана со связями Ti-O-C. Получение и свойства. Полимеры на их основе
Органические производные титана со связями Ti-O-C. Получение и свойства. Полимеры на их основе Алкины. Ацетилен – представитель алкинов.
Алкины. Ацетилен – представитель алкинов. Презентация по Химии "Основные сведения о строении атома" - скачать смотреть
Презентация по Химии "Основные сведения о строении атома" - скачать смотреть  Кислотность органических соединений. Типы химических реакций
Кислотность органических соединений. Типы химических реакций Эмульсии как лиофобные дисперсные системы
Эмульсии как лиофобные дисперсные системы Альдегиды. Раствор формальдегида. Гексаметилентетрамин (метенамин)
Альдегиды. Раствор формальдегида. Гексаметилентетрамин (метенамин) Нефть. Состав и свойства
Нефть. Состав и свойства «Знаки химических элементов. Относительная атомная масса химических элементов»
«Знаки химических элементов. Относительная атомная масса химических элементов»  Поверхностные явления
Поверхностные явления Фазовые равновесия в системе ограниченно смешивающихся жидкостей
Фазовые равновесия в системе ограниченно смешивающихся жидкостей Способы разделения смесей
Способы разделения смесей Химические предприятия Саратовской области
Химические предприятия Саратовской области 1oe_zanyatie (1)
1oe_zanyatie (1) Напій кока-кола. Активні інгредієнти кока-коли
Напій кока-кола. Активні інгредієнти кока-коли Адсорбция. Адсорбциондық тепе-теңдік
Адсорбция. Адсорбциондық тепе-теңдік Аминокислоты
Аминокислоты Роль нафти у сучасному світі Підготував учень 11 класу Войтюк Дмитро
Роль нафти у сучасному світі Підготував учень 11 класу Войтюк Дмитро  Новітні досягнення в хімії (9 клас)
Новітні досягнення в хімії (9 клас) Рідкі кристали Використання
Рідкі кристали Використання  Що ховається за цифрами? Харчові домішки
Що ховається за цифрами? Харчові домішки Алканы. Гомологический ряд предельных углеводородов
Алканы. Гомологический ряд предельных углеводородов