- Абстрактные типы данных. Структура данных

Содержание
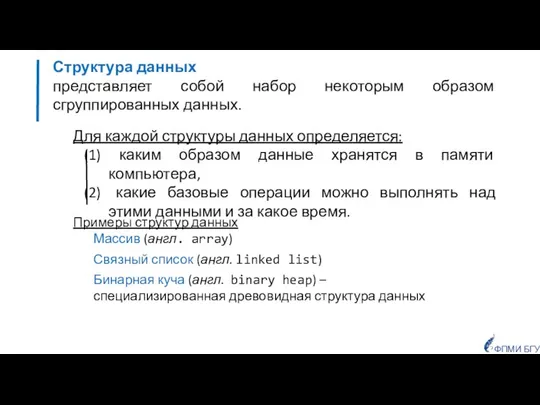
- 2. Структура данных представляет собой набор некоторым образом сгруппированных данных. Примеры структур данных Массив (англ. array) Связный
- 3. Абстрактный тип данных (англ. abstract data type) Для абстрактного типа определяется интерфейс — набор операций, которые
- 4. Список (list) Стек (stack) Очередь (queue) Двухстороняя очередь (deque) Множество (set) Ассоциативный массив/отображение/ словарь (associative array/map/dictiona)
- 5. Структуры данных
- 6. Массив фиксированного размера (англ. array) Массив— это структура данных с произвольным доступом к элементу (англ. random
- 7. Поиск элемента по ключу x Добавление элемента Удаление элемента произвольный массив упорядоченный массив ФПМИ БГУ Время
- 8. Динамический массив (англ. dynamic array) ФПМИ БГУ
- 9. Как можно организовать динамический массив на базе статического? ФПМИ БГУ Пусть изначально массив пуст, затем в
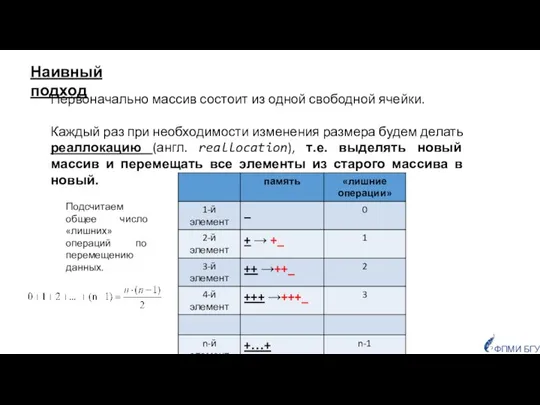
- 10. Наивный подход Первоначально массив состоит из одной свободной ячейки. Каждый раз при необходимости изменения размера будем
- 11. Для уменьшения числа реаллокаций будем расширять массив «с запасом», оставляя пустые ячейки, которые можно будет использовать
- 12. ФПМИ БГУ Расширение с запасом: на сколько или во сколько раз? Ёмкость Размер
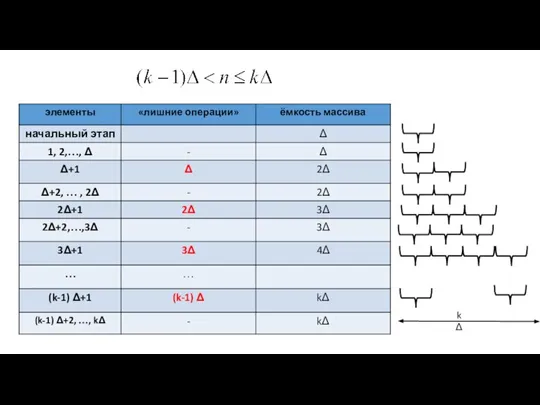
- 13. При поступлении (∆+1) элемента потребуется создать новый массив ёмкости =[∆+ ∆]и перенести все данные в него,
- 14. kΔ
- 15. «Лишние» операции ФПМИ БГУ оценка снизу оценка сверху
- 16. Таким образом, можно сделать вывод, что при фиксированной константе α > 1 общее число операций по
- 17. Конкретная операция вставки каждого элемента осуществляется: или за константное время, когда в массиве есть свободная ёмкость;
- 18. Пример реализации динамического массива на базе статического с использованием стратегии удвоения
- 19. Применение динамических массивов на практике Динамические массивы очень удобны и широко используются на практике в прикладных
- 21. Связный список— некоторая последовательность элементов, которые связаны друг с другом логически. Логический порядок прохождения элементов определяется
- 22. В односвязном, или однонаправленном связном, списке (англ. singly linked list) каждый узел содержит ссылку на следующий
- 23. Чаще всего узлы списка размещают в динамической памяти, при этом в качестве значений ссылок используются адреса
- 24. Добавление элемента задана ссылка на элемент, после которого выполняется добавление Удаление элемента задана ссылка на элемент,
- 25. 1. Поиск элемента по ключу x: 2. Добавление элемента задана ссылка на элемент, после которого выполняется
- 26. Быстрая вставка и удаление Операции вставки в конкретное место списка и удаления определённого элемента списка выполняются
- 27. Нет произвольного доступа Динамические массивы обеспечивают произвольный доступ к любому элементу по индексу за константное время,
- 28. В реальной практике прикладного программирования связные списки в чистом виде используются крайне редко. Применение на практике
- 29. В современных языках программирования двусвязный список представлен: ФПМИ БГУ
- 30. Абстрактные типы данных
- 31. Для абстрактного типа определяется интерфейс — набор операций, которые могут быть выполнены. Пользователь абстрактного типа, используя
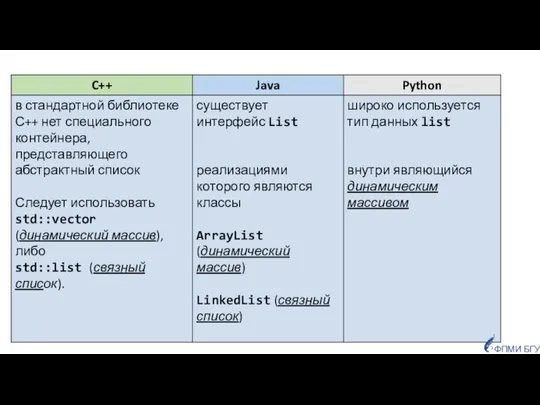
- 32. Список (англ. list) Список - абстрактный тип данных, представляющий собой набор элементов, которые следуют в определённом
- 33. 1. создание пустого списка; Список (англ. list) Базовые операции: Абстрактный тип данных «cписок» обычно реализуется на
- 34. ФПМИ БГУ
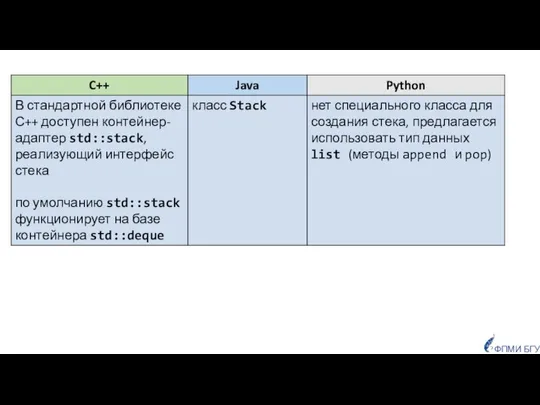
- 35. 1. Init() — создание пустого стека; Стек (англ. stack) Базовые операции: Моделирование стека выполняется на динамическом
- 36. ФПМИ БГУ
- 37. 1. Init() — создание пустой очереди; Очередь (англ. queue) Базовые операции: Наиболее простые способы моделирования очереди:
- 38. ФПМИ БГУ
- 39. Двухсторонняя очередь (англ. double-ended queue, или deque) Двухсторонняя очередь— обобщение очереди, где добавление и удаление элементов
- 40. https://coderoad.ru/6292332/Что-же-такое-на-самом-деле-дек-В-STL все блоки имеют одинаковый размер, который зафиксирован
- 41. ФПМИ БГУ
- 42. Множество (англ. set) Множество —абстрактная структура данных, которая хранит набор попарно различных объектов без определённого порядка.
- 43. ФПМИ БГУ
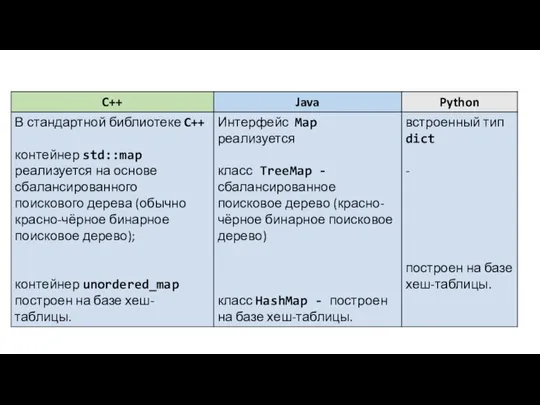
- 44. Ассоциативный массив /отображение/словарь (англ. associative array/ map/ dictionary) Ассоциативный массив или отображение, или словарь, — абстрактная
- 47. Скачать презентацию
Структура данных
представляет собой набор некоторым образом сгруппированных данных.
Примеры структур
Структура данных
представляет собой набор некоторым образом сгруппированных данных.
Примеры структур

Абстрактный тип данных (англ. abstract data type)
Для абстрактного типа определяется
Абстрактный тип данных (англ. abstract data type)
Для абстрактного типа определяется

Список (list)
Стек (stack)
Очередь (queue)
Двухстороняя очередь (deque)
Множество (set)
Ассоциативный массив/отображение/
Список (list)
Стек (stack)
Очередь (queue)
Двухстороняя очередь (deque)
Множество (set)
Ассоциативный массив/отображение/

Структуры данных
Структуры данных

Массив фиксированного размера (англ. array)
Массив— это структура данных с произвольным
Массив фиксированного размера (англ. array)
Массив— это структура данных с произвольным

Поиск элемента по ключу x
Добавление элемента
Удаление элемента
произвольный массив
упорядоченный массив
ФПМИ БГУ
Время выполнения
Поиск элемента по ключу x
Добавление элемента
Удаление элемента
произвольный массив
упорядоченный массив
ФПМИ БГУ
Время выполнения

Динамический массив (англ. dynamic array)
ФПМИ БГУ
Динамический массив (англ. dynamic array)
ФПМИ БГУ

Как можно организовать динамический массив
на базе статического?
ФПМИ БГУ
Пусть изначально массив
Как можно организовать динамический массив
на базе статического?
ФПМИ БГУ
Пусть изначально массив
Наивный подход
Первоначально массив состоит из одной свободной ячейки.
Каждый раз при
Наивный подход
Первоначально массив состоит из одной свободной ячейки.
Каждый раз при

Для уменьшения числа реаллокаций будем расширять массив «с запасом», оставляя пустые
Для уменьшения числа реаллокаций будем расширять массив «с запасом», оставляя пустые

ФПМИ БГУ
Расширение с запасом: на сколько или во сколько раз?
Ёмкость
Размер
ФПМИ БГУ
Расширение с запасом: на сколько или во сколько раз?
Ёмкость
Размер
![При поступлении (∆+1) элемента потребуется создать новый массив ёмкости =[∆+ ∆]и](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/634361/slide-12.jpg)
При поступлении (∆+1) элемента потребуется создать новый массив ёмкости =[∆+ ∆]и
При поступлении (∆+1) элемента потребуется создать новый массив ёмкости =[∆+ ∆]и
kΔ
kΔ

«Лишние» операции
ФПМИ БГУ
оценка снизу
оценка сверху
«Лишние» операции
ФПМИ БГУ
оценка снизу
оценка сверху

Таким образом, можно сделать вывод, что при фиксированной константе α >
Таким образом, можно сделать вывод, что при фиксированной константе α >

Конкретная операция вставки каждого элемента осуществляется:
или за константное время, когда
Конкретная операция вставки каждого элемента осуществляется:
или за константное время, когда

Пример реализации динамического массива
на базе статического с использованием стратегии удвоения
Пример реализации динамического массива
на базе статического с использованием стратегии удвоения

Применение динамических массивов на практике
Динамические массивы очень удобны и широко используются
Применение динамических массивов на практике
Динамические массивы очень удобны и широко используются
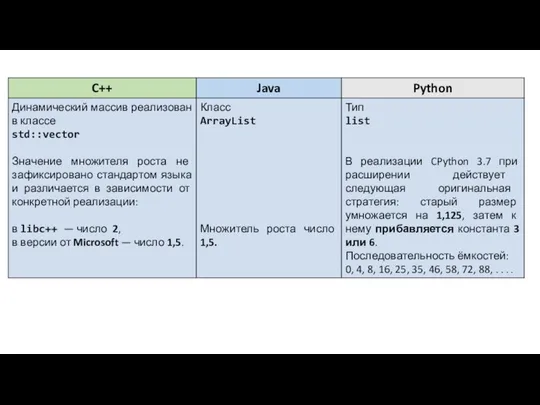

Связный список— некоторая последовательность элементов, которые связаны друг с другом логически.
Связный список— некоторая последовательность элементов, которые связаны друг с другом логически.

В односвязном, или однонаправленном связном, списке (англ. singly linked list) каждый
В односвязном, или однонаправленном связном, списке (англ. singly linked list) каждый

Чаще всего узлы списка размещают в динамической памяти, при этом в
Чаще всего узлы списка размещают в динамической памяти, при этом в

Добавление элемента
задана ссылка на элемент, после которого выполняется добавление
Удаление элемента
Добавление элемента
задана ссылка на элемент, после которого выполняется добавление
Удаление элемента

1. Поиск элемента по ключу x:
2. Добавление элемента
задана ссылка на
1. Поиск элемента по ключу x:
2. Добавление элемента
задана ссылка на

Быстрая вставка и удаление
Операции вставки в конкретное место списка и
Быстрая вставка и удаление
Операции вставки в конкретное место списка и

Нет произвольного доступа
Динамические массивы обеспечивают произвольный доступ к любому элементу по
Нет произвольного доступа
Динамические массивы обеспечивают произвольный доступ к любому элементу по

В реальной практике прикладного программирования связные списки в чистом виде используются
В реальной практике прикладного программирования связные списки в чистом виде используются

В современных языках программирования двусвязный список представлен:
ФПМИ БГУ
В современных языках программирования двусвязный список представлен:
ФПМИ БГУ

Абстрактные типы данных
Абстрактные типы данных

Для абстрактного типа определяется интерфейс — набор операций, которые могут быть
Для абстрактного типа определяется интерфейс — набор операций, которые могут быть

Список (англ. list)
Список - абстрактный тип данных, представляющий собой набор элементов,
Список (англ. list)
Список - абстрактный тип данных, представляющий собой набор элементов,

1. создание пустого списка;
Список (англ. list)
Базовые операции:
Абстрактный тип данных «cписок»
1. создание пустого списка;
Список (англ. list)
Базовые операции:
Абстрактный тип данных «cписок»
ФПМИ БГУ
ФПМИ БГУ

1. Init() — создание пустого стека;
Стек (англ. stack)
Базовые операции:
Моделирование стека выполняется
1. Init() — создание пустого стека;
Стек (англ. stack)
Базовые операции:
Моделирование стека выполняется
ФПМИ БГУ
ФПМИ БГУ

1. Init() — создание пустой очереди;
Очередь (англ. queue)
Базовые операции:
Наиболее простые способы
1. Init() — создание пустой очереди;
Очередь (англ. queue)
Базовые операции:
Наиболее простые способы

ФПМИ БГУ
ФПМИ БГУ

Двухсторонняя очередь (англ. double-ended queue, или deque)
Двухсторонняя очередь— обобщение очереди,
Двухсторонняя очередь (англ. double-ended queue, или deque)
Двухсторонняя очередь— обобщение очереди,

https://coderoad.ru/6292332/Что-же-такое-на-самом-деле-дек-В-STL
все блоки имеют одинаковый размер, который зафиксирован
https://coderoad.ru/6292332/Что-же-такое-на-самом-деле-дек-В-STL
все блоки имеют одинаковый размер, который зафиксирован

ФПМИ БГУ
ФПМИ БГУ

Множество (англ. set)
Множество —абстрактная структура данных, которая хранит набор попарно различных
Множество (англ. set)
Множество —абстрактная структура данных, которая хранит набор попарно различных

ФПМИ БГУ
ФПМИ БГУ

Ассоциативный массив /отображение/словарь
(англ. associative array/ map/ dictionary)
Ассоциативный массив или отображение, или
Ассоциативный массив /отображение/словарь
(англ. associative array/ map/ dictionary)
Ассоциативный массив или отображение, или
 Стоимость реализованной продукции
Стоимость реализованной продукции Проблемы безопасности детей в интернете
Проблемы безопасности детей в интернете Этапы подготовки и решения задач на ЭВМ
Этапы подготовки и решения задач на ЭВМ Работа с личным кабинетом (ЛК)
Работа с личным кабинетом (ЛК) Презентация "Объектно – ориентированное программирование на DELPHI - 11" - скачать презентации по Информатике
Презентация "Объектно – ориентированное программирование на DELPHI - 11" - скачать презентации по Информатике Презентация "Динамическое программирование в математике" - скачать презентации по Информатике
Презентация "Динамическое программирование в математике" - скачать презентации по Информатике Правила составления отчета в Excel. Учет автомобилей на парковке
Правила составления отчета в Excel. Учет автомобилей на парковке Создание презентаций: возможности, основные виды
Создание презентаций: возможности, основные виды Вопросы программирования и оптимизации приложений на CUDA. Лекторы: Обухов А.Н. (Nvidia) Боресков А.В. (ВМиК МГУ) Харламов А.А. (Nvidia)
Вопросы программирования и оптимизации приложений на CUDA. Лекторы: Обухов А.Н. (Nvidia) Боресков А.В. (ВМиК МГУ) Харламов А.А. (Nvidia)  Информация и информационные процессы в живой и неживой природе
Информация и информационные процессы в живой и неживой природе Презентация "Компьютерные вирусы 11 класс" - скачать презентации по Информатике
Презентация "Компьютерные вирусы 11 класс" - скачать презентации по Информатике Адресация в инфокоммуникационных сетях. Модель межсетевого взаимодействия – модель OSI. Промышленные сетевые
Адресация в инфокоммуникационных сетях. Модель межсетевого взаимодействия – модель OSI. Промышленные сетевые Веб-сайт Интернет магазин Дуб-Дубом
Веб-сайт Интернет магазин Дуб-Дубом Задача классификации. Метод деревьев решений
Задача классификации. Метод деревьев решений Введение в электронные таблицы. Запись формул в таблицу
Введение в электронные таблицы. Запись формул в таблицу Компьютерные презентации
Компьютерные презентации Тест. Программное обеспечение компьютера
Тест. Программное обеспечение компьютера Новые информационные технологии
Новые информационные технологии Adobe Photoshop
Adobe Photoshop Способы записи алгоритмов. 9 класс
Способы записи алгоритмов. 9 класс Информатика. Основные понятия и определения
Информатика. Основные понятия и определения Основные характеристики компьютера
Основные характеристики компьютера Основные понятия типографики: единицы измерения, шрифты, гарнитура
Основные понятия типографики: единицы измерения, шрифты, гарнитура Количественная характеристика информации
Количественная характеристика информации ГОУ ВПО « Поморский государственный университет имени М.В. Ломоносова» Реферат на тему: Ребенок и компьютерные игры
ГОУ ВПО « Поморский государственный университет имени М.В. Ломоносова» Реферат на тему: Ребенок и компьютерные игры Адрес ячейки электронной таблицы. Лекция 3
Адрес ячейки электронной таблицы. Лекция 3 Презентация "Лабораторная 3" - скачать презентации по Информатике
Презентация "Лабораторная 3" - скачать презентации по Информатике Анализ программы с циклами и условными операторами
Анализ программы с циклами и условными операторами