- Задача классификации. Метод деревьев решений

Содержание
- 2. Основные положения метода Метод деревьев решений (decision tree) для задачи классификации состоит в том, чтобы осуществлять
- 3. Дерево решений – это модель, представляющая собой совокупность правил для принятия решений. Графически её можно представить
- 4. Метод деревьев решений реализует принцип так называемого «рекурсивного деления» (recursive partitioning). Эта стратегия также называется «Разделяй
- 5. Пример В кинокомпании стол редактора завален сценариями кинофильмов, нужно разложить их по трём ящикам: Популярные («mainstream
- 6. 1) Количество снимавшихся в фильме звёзд как первый из признаков, по которому производится разбиение данных Пример
- 7. Продолжать процесс разделения данных можно и дальше, пока не получим очень «мелкое» разделение (может оказаться, что
- 8. Пример Дерево решений для классификации киносценариев Классификация сценариев лишь по 2-м факторам (количество занятых звёзд и
- 9. Численные алгоритмы метода деревьев решений, допускающие компьютерную реализацию Существуют различные численные алгоритмы построения деревьев решений: CART,
- 10. Функция оценки качества разбиения, которая используется для выбора оптимального правила, - индекс Gini . Данная оценочная
- 11. Механизм отсечения - minimal cost-complexity tree pruning, алгоритм CART принципиально отличается от других алгоритмов конструирования деревьев
- 12. Алгоритм C4.5 Алгоритм C4.5 строит дерево решений с неограниченным количеством ветвей у узла. Данный алгоритм может
- 13. Алгоритм (С5.0) автоматизированного построения дерева решений Фактически алгоритм C5.0 представляет собой стандарт процедуры построения деревьев решений.
- 14. Энтропия как мера чистоты групп Если у системы всего 2 возможных состояния, то её энтропия –
- 15. Алгоритм может выбрать тот признак, разбиение по которому даст самую чистую группу (т.е. группу, имеющую наименьшую
- 16. Может возникнуть ситуация, когда группы окажутся слишком мелкими, а точек ветвления будет слишком много – в
- 18. ЗАДАЧА КЛАССИФИКАЦИИ. ДИСКРИМИНАНТНЫЙ АНАЛИЗ Анализ данных
- 19. Дискриминантный анализ Дискриминантный анализ является разделом многомерного статистического анализа, который включает в себя методы классификации многомерных
- 20. Дискриминантный анализ – это общий термин, относящийся к нескольким тесно связанным статистическим процедурам. Эти процедуры можно
- 21. Дискриминация Основной целью дискриминации является нахождение такой линейной комбинации переменных (в дальнейшем эти переменные будем называть
- 23. Скачать презентацию

Основные положения метода
Метод деревьев решений (decision tree) для задачи классификации
Основные положения метода
Метод деревьев решений (decision tree) для задачи классификации

Дерево решений – это модель, представляющая собой совокупность правил для
Дерево решений – это модель, представляющая собой совокупность правил для

Метод деревьев решений реализует принцип так называемого «рекурсивного деления» (recursive
Метод деревьев решений реализует принцип так называемого «рекурсивного деления» (recursive
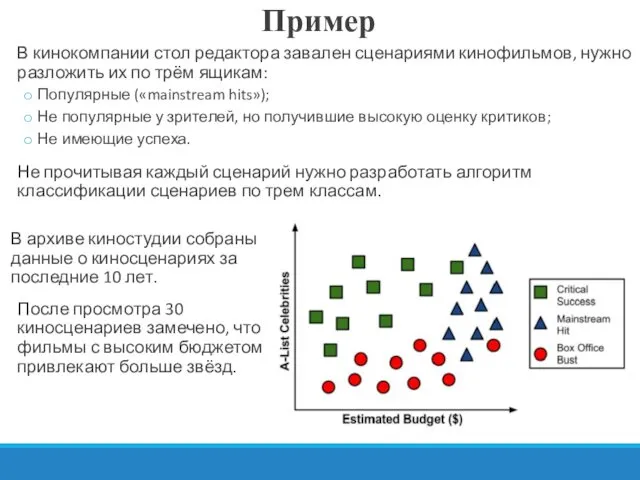
Пример
В кинокомпании стол редактора завален сценариями кинофильмов, нужно разложить их по
Пример
В кинокомпании стол редактора завален сценариями кинофильмов, нужно разложить их по
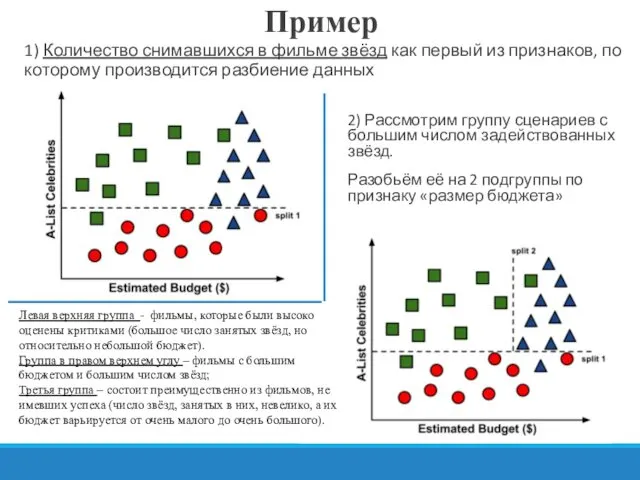
1) Количество снимавшихся в фильме звёзд как первый из признаков, по
1) Количество снимавшихся в фильме звёзд как первый из признаков, по

Продолжать процесс разделения данных можно и дальше, пока не получим очень
Продолжать процесс разделения данных можно и дальше, пока не получим очень
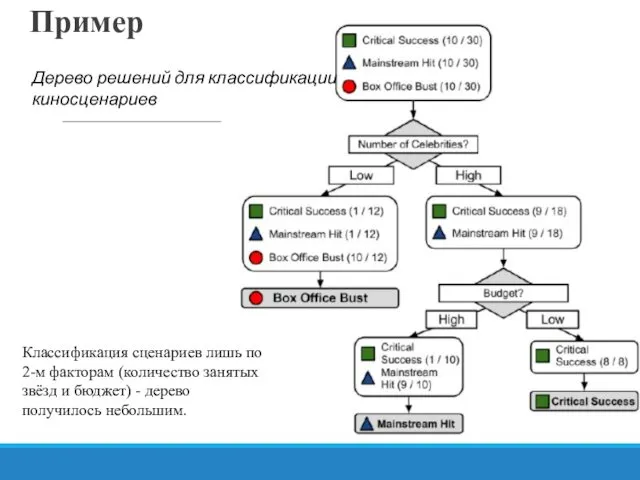
Пример
Дерево решений для классификации киносценариев
Классификация сценариев лишь по 2-м факторам
Пример
Дерево решений для классификации киносценариев
Классификация сценариев лишь по 2-м факторам

Численные алгоритмы метода деревьев решений, допускающие компьютерную реализацию
Существуют различные численные алгоритмы
Численные алгоритмы метода деревьев решений, допускающие компьютерную реализацию
Существуют различные численные алгоритмы

Функция оценки качества разбиения, которая используется для выбора оптимального правила, - индекс
Функция оценки качества разбиения, которая используется для выбора оптимального правила, - индекс

Механизм отсечения - minimal cost-complexity tree pruning, алгоритм CART принципиально отличается от других алгоритмов конструирования
Механизм отсечения - minimal cost-complexity tree pruning, алгоритм CART принципиально отличается от других алгоритмов конструирования

Алгоритм C4.5
Алгоритм C4.5 строит дерево решений с неограниченным количеством ветвей у узла. Данный
Алгоритм C4.5
Алгоритм C4.5 строит дерево решений с неограниченным количеством ветвей у узла. Данный

Алгоритм (С5.0) автоматизированного построения дерева решений
Фактически алгоритм C5.0 представляет собой
Алгоритм (С5.0) автоматизированного построения дерева решений
Фактически алгоритм C5.0 представляет собой
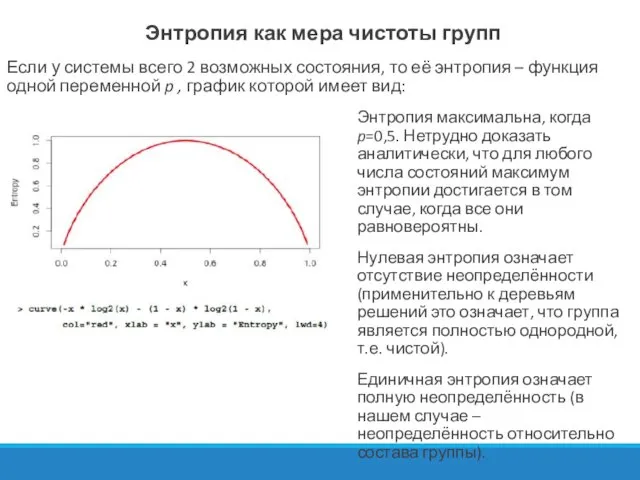
Энтропия как мера чистоты групп
Если у системы всего 2 возможных состояния,
Энтропия как мера чистоты групп
Если у системы всего 2 возможных состояния,

Алгоритм может выбрать тот признак, разбиение по которому даст самую чистую
Алгоритм может выбрать тот признак, разбиение по которому даст самую чистую

Может возникнуть ситуация, когда группы окажутся слишком мелкими, а точек ветвления
Может возникнуть ситуация, когда группы окажутся слишком мелкими, а точек ветвления

ЗАДАЧА КЛАССИФИКАЦИИ.
ДИСКРИМИНАНТНЫЙ АНАЛИЗ
Анализ данных
ЗАДАЧА КЛАССИФИКАЦИИ.
ДИСКРИМИНАНТНЫЙ АНАЛИЗ
Анализ данных

Дискриминантный анализ
Дискриминантный анализ является разделом многомерного статистического анализа, который включает в себя
Дискриминантный анализ
Дискриминантный анализ является разделом многомерного статистического анализа, который включает в себя

Дискриминантный анализ – это общий термин, относящийся к нескольким тесно связанным
Дискриминантный анализ – это общий термин, относящийся к нескольким тесно связанным

Дискриминация
Основной целью дискриминации является нахождение такой линейной комбинации переменных (в дальнейшем
Дискриминация
Основной целью дискриминации является нахождение такой линейной комбинации переменных (в дальнейшем
 Истинные и ложные суждения
Истинные и ложные суждения Тест. Комп'ютерні віруси
Тест. Комп'ютерні віруси Библиографический поиск. Источники библиографического поиска
Библиографический поиск. Источники библиографического поиска Система управления базами данных. 9 класс
Система управления базами данных. 9 класс Информационные объекты различных видов. Язык как способ представления информации. Лекция 8
Информационные объекты различных видов. Язык как способ представления информации. Лекция 8 Презентация по информатике Системы Счисления
Презентация по информатике Системы Счисления  Школа глазами домашнего животного. Фотокросс
Школа глазами домашнего животного. Фотокросс WORD простейшие операции с текстом
WORD простейшие операции с текстом Проблемы безопасности детей в интернете
Проблемы безопасности детей в интернете Народная программистская мудрость
Народная программистская мудрость Защита файлов и управление доступом к ним. Борисов В.А. Красноармейский филиал ГОУ ВПО «Академия народного хозяйства при Пр
Защита файлов и управление доступом к ним. Борисов В.А. Красноармейский филиал ГОУ ВПО «Академия народного хозяйства при Пр Идут часы, и мы идем, И в этом наша суть, И каждый с временем вдвоем: Проходит весь свой путь. А. Дольский
Идут часы, и мы идем, И в этом наша суть, И каждый с временем вдвоем: Проходит весь свой путь. А. Дольский Работа в Еxcel
Работа в Еxcel Цикл for
Цикл for Браузеры
Браузеры Регистрация. ИСТИНА. Интеллектуальная система тематического исследования научно-технической информации
Регистрация. ИСТИНА. Интеллектуальная система тематического исследования научно-технической информации Информационные хранилища
Информационные хранилища Педагогические программные средства
Педагогические программные средства CATIA Generative Shape Design Update/ Обновление Модуля Расширенного Проектирования Поверхностей
CATIA Generative Shape Design Update/ Обновление Модуля Расширенного Проектирования Поверхностей Тестирование. Какое бывает тестирование
Тестирование. Какое бывает тестирование Binary Tree. Проблема поиска значений
Binary Tree. Проблема поиска значений Типология БД. Модели представления данных
Типология БД. Модели представления данных Паттерны проектирования: Шаблонный метод
Паттерны проектирования: Шаблонный метод Верстка web-страниц
Верстка web-страниц Шаги подключения к ЕСИА для упрощённой идентификации клиентов
Шаги подключения к ЕСИА для упрощённой идентификации клиентов Какие роботы присутствуют в повседневности
Какие роботы присутствуют в повседневности Инструмент заливка
Инструмент заливка ИНФОРМАТИКА И ИКТ
ИНФОРМАТИКА И ИКТ