- Архитектуры распределенных информационных систем

Содержание
- 2. ПОНЯТИЕ АРХИТЕКТУРЫ РАСПРЕДЕЛЕННОЙ СИСТЕМЫ Организация РС определяется тем каким образом программное обеспечение РС распределяется между вычислительными
- 3. ПРОГРАММНАЯ АРХИТЕКТУРА Организация РС определяется составом программных компонент входящих в состав системы. Программная архитектура показывает помимо
- 4. ПРОЗHАЧНОСТЬ РС И ЕЕ АРХИТЕКТУРА Исходя из требования обеспечения прозрачности в распределенных системах требуется четко разделять
- 5. ВЫБОР ВАРИАНТА ПРОГРАММНОЙ АРХИТЕКТУРЫ Важнейшим решением при разработке архитектуры системы является: выбор варианта размещения ПО промежуточного
- 6. СИСТЕМНАЯ АРХИТЕКТУРА Фактическая (реально разворачиваемая) реализация РС, требует однозначного определения размещения программных компонент системы на реальных
- 7. ВИДЫ СИСТЕМНОЙ АРХИТЕКТУРЫ Различают три вида системной архитектуры: централизованная; децентрализованная (peer-to-peer); гибридная – комбинация элементов централизованной
- 8. ПОНЯТИЕ АРХИТЕКТУРНОГО СТИЛЯ В настоящее время исследования в области программного обеспечения достигли достаточной зрелости, что позволило
- 9. ПОНЯТИЕ ПРОГРАММНОГО КОМПОНЕНТА Компонент – модульная единица ПО снабженная полностью определенным и предоставляемым по запросу интерфейсом.
- 10. ОСНОВНЫЕ ВИДЫ АРХИТЕКТУР РИС В настоящее время общепризнанными архитектурными стилями считаются: многоуровневые архитектукры (layered); объектные архитектуры
- 11. МНОГОУРОВНЕВАЯ АРХИТЕКТУРА Базовая идея проста: компоненты распределяются по уровням, при этом компонент уровня j Lj может
- 12. ДРУГИЕ ВИДЫ МНОГОУРОВНЕВЫХ АРХИТЕКТУР Смешанная многоуровневая архитектура – допускает вызов не только смежных нижележащих уровней, но
- 13. МНОГОУРОВНЕВАЯ ОРГАНИЗАЦИЯ СТЕКА СЕТЕВЫХ ПРОТОКОЛОВ Примером такой организации может служить стек сетевых протоколов, например : TCP/IP
- 14. АРХИТЕКТУРА ПРИЛОЖЕНИЯ (РАССЛОЕНИЕ ПРИЛОЖЕНИЯ)
- 15. МНОГОУРОВНЕВАЯ ОРГАНИЗАЦИЯ ПРИЛОЖЕНИЙ
- 16. АРХИТЕКТУРА ОСНОВАННАЯ НА ОБЪЕКТАХ (OBJECT-BASED ARCHITECTURE) В этой архитектуре понятие объект однозначно соответствует понятию компонент. Объекты
- 17. РАСПРЕДЕЛЕННЫЕ ОБЪЕКТЫ Когда клиент связывается с распределенным объектом, реализация интерфейса этого объекта, называемая proxy, загружается в
- 18. СЕРВИС Архитектура распределенных объектов ее основе сформировать сервис как независимую программную единицу. Сервис реализуется как самодостаточная
- 19. ОСНОВНЫЕ ПОНЯТИЯ СОА (1) СOA – это способ описания требований и методология предоставления сервисов, независимых от
- 20. ОСНОВНЫЕ ПОНЯТИЯ СОА (2) SOA описывается как совокупность сервисов, реализуемых в виде компонентных объектов, систематизированных на
- 21. ВЗАИМОДЕЙСТВИЕ МЕЖДУ ПОСТАВЩИКОМ И ПОТРЕБИТЕЛЕМ СЕРВИСА Клиент обращается к поставщику посылая ему сообщение стандартного формата, содержащее
- 22. АРХИТЕКТУРА ИС ПРЕДПРИЯТИЯ НА ОСНОВЕ SOA Уровень бизнес-логики предприятия Уровень логики приложения Уровень приложения
- 23. ВЕБ СЕРВИС Веб-служба, веб-сервис (англ. web service) — идентифицируемая программная система со стандартизированными интерфейсами.
- 24. МОДЕЛЬ РАБОТЫ WEB-СЕРВИСА
- 25. СТЕК ПРОТОКОЛОВ WEB-СЕРВИСА
- 26. АРХИТЕКТУРА ОСНОВАННАЯ НА РЕСУРСАХ Рост числа сервисов доступных через Web и создание распределенных систем на основе
- 27. РЕСУРСО-ЦЕНТРИЧЕСКАЯ АРХИТЕКТУРА Ресурсы могут добавляться либо удаляться с помощь приложения (удаленного). Такой подход привел формированию понятия
- 28. ПРИНЦИПЫ АРХИТЕКТУРЫ RESTFUL Архитектура REST (Representational State Transfer) основана на четырех принципах [Fielding, 2000]: Использование единой
- 29. СРАВНЕНИЕ REST И SOAP/XML WEB-СЕРВИСОВ RESTful архитектура стала популярна благодаря своей простоте. SOAP поддерживает 16 операций,
- 30. АРХИТЕКТУРЫ ОСНОВАННЫЕ НА ПУБЛИКАЦИИ И ПОДПИСКЕ По мере роста размеров РС стало важным иметь архитектуру в
- 31. СПОСОБЫ КООРДИНАЦИИ В зависимости то вида координации используемой в системе можно определить несколько моделей архитектуры подписка/публикация.
- 32. ВАРИАНТЫ АРХИТЕКТУР ПУБЛИКАЦИЯ/ПОДПИСКА В зависимости от комбинации двух факторов координации различают следующие модели архитектуры публикация/подписка: архитектура
- 33. АРХИТЕКТУРА П/П С ПРЯМОЙ КООРДИНАЦИЕЙ В этой модели одновременно используются оба вида координации: Координация по времени
- 34. АРХИТЕКТУРА П/П С КООРДИНАЦИЕЙ ЧЕРЕЗ ПОЧТОВЫЙ ЯЩИК В этой модели: Отсутствует координация по времени, оба процесса
- 35. АРХИТЕКТУРА НА ОСНОВЕ ОБЩЕГО ПРОСТРАНСТВА ДАННЫХ Пример: Linda - программная модель, разработанная в 1980 году. Разделяемое
- 36. АРХИТЕКТУРА П/П НА ОСНОВЕ СОБЫТИЙ Для получения уведомления процесс подписчик должен всегда находиться в рабочем состоянии.
- 37. ВАРИАНТЫ АРХИТЕКТУРЫ П/П НА ОСНОВЕ СОБЫТИЙ В зависимости от способа описания события различают два варианта систем
- 38. СИСТЕМА ПУБЛИКАЦИИ/ПОДПИСКИ ОСНОВАННАЯ НА ТЕМЕ Событие описывается набором атрибутов – списком пар (атрибут, значение). Подписка должна
- 39. СИСТЕМЫ ПУБЛИКАЦИИ/ПОДПИСКИ ОСНОВАННЫЕ НА СОДЕРЖИМОМ (КОНТЕНТЕ) В этом случае событие также описывается набором атрибутов, которые представляются
- 40. ПРИНЦИП ОБМЕНА ДАННЫМИ МЕЖДУ ИЗДАТЕЛЕМ И ПОДПИСЧИКОМ В СИСТЕМАХ С ШИНОЙ СОБЫТИЙ Условием обмена данными является
- 41. ОСНОВНАЯ ПРОБЛЕМА СИСТЕМ ПУБЛИКАЦИИ/ПОДПИСКИ События могут легко запутать работу подписчиков. В качестве примера рассмотрим такую подписку:
- 42. ОРГАНИЗАЦИЯ ПРОМЕЖУТОЧНОГО ПО (MIDLEWARE) При организации ПО промежуточного уровня в системах основанных на объектных компонентах, часто
- 43. WRAPPERS ИЛИ ADAPTERS При создании распределенных проблем на основе уже существующих компонент мы сразу же сталкиваемся
- 44. БРОКЕР СООБЩЕНИЙ Уменьшить число адаптеров можно создав промежуточное ПО, которое обеспечит централизованное управление доступом между различными
- 45. ПЕРЕХВАТЧИКИ ОБРАЩЕНИЙ (INTERCEPTORS) Концептуально перехватчик обращений, прерывает нормальный процесс вызова компонент и позволят исполнить другой фрагмент
- 46. ОБРАЩЕНИЕ К РЕПЛИКАМ ОБЪЕКТА В Представим, что объект В имеет несколько реплик. В этом случае мы
- 47. АДАПТИРУЕМОЕ ПО ПРОМЕЖУТОЧНОГО СЛОЯ Необходимость в адаптируемом промежуточном ПО возникает из-за того, что в окружении РС
- 48. ЗАМЕНА КОМПОНЕНТ ВО ВРЕМЯ ИСПОЛНЕНИЯ Примером такого подхода является замена программных компонент в момент их исполнения.
- 49. СИСТЕМНАЯ АРХИТЕКТУРА
- 50. ЦЕНТРАЛИЗОВАННАЯ ОРГАНИЗАЦИЯ РС
- 51. ВАРИАНТЫ АРХИТЕКТУРЫ КЛИЕНТ-СЕРВЕР Простейшая организация предполагает наличие всего двух типов машин. Клиентские машины, на которых имеются
- 52. ФИЗИЧЕСКИ ДВУХЗВЕННЫЕ АРХИТЕКТУРЫ Один из подходов к организации клиентов и серверов — это распределение программ, находящихся
- 53. РАЗНОВИДНОСТИ МОДЕЛИ КЛИЕНТ-СЕРВЕР Обычно ПО хранения данных располагается на сервере (например, сервер базы данных), интерфейс с
- 54. ТОЛСТЫЙ КЛИЕНТ Основным недостатком толстого клиента является сложность администрирования и трудности с обновлением ПО, поскольку его
- 55. ТОНКИЙ КЛИЕНТ В тонком клиенте этот недостаток устраняется, однако появляются большие сложности в создании ПО серверной
- 56. ВЗАИМОДЕЙСТВИЕ МЕЖДУ КЛИЕНТОМ И СЕРВЕРОМ Взаимодействие между клиентом и сервером расположенными на разных машинах часто называют
- 57. МНОГОУРОВНЕВЫЕ СИСТЕМЫ КЛИЕНТ-СЕРВЕР Многоуровневая архитектура клиент-сервер позволяет более разумно распределить модули обработки данных, которые в этом
- 58. ПОВЕДЕНИЕ СЕРВЕРА КАК КЛИЕНТА В СЛОЖНЫХ ПРИЛОЖЕНИЯХ В классической модели клиент-сервер не предполагается поведение машины сервера,
- 59. ПРИМЕР РАБОТЫ СЕРВЕРА В КАЧЕСТВЕ КЛИЕНТА В WEB ПРИЛОЖЕНИИ Другой пример работа серверов приложений в среде
- 60. HTTP Request CFML HTML HTML Database Messaging Directory Services File Server Distributed Objects ТРЕХЗВЕННАЯ АРХИТЕКТУРА СЕРВЕРА
- 61. ДЕЦЕНТРАЛИЗОВАННАЯ ОРГАНИЗАЦИЯ РС: СИСТЕМЫ PEER-TO-PEER (ОДНОРАНГОВЫЕ СИСТЕМЫ)
- 62. СРАВНЕНИЕ СИСТЕМ P2P И КЛИЕНТ-СЕРВЕР В отличие от классической клиент серверной архитектуры в архитектуре Р2Р каждый
- 63. СРАВНЕНИЕ ПРИНЦИПОВ ПОСТРОЕНИЯ СИСТЕМ P2P И КЛИЕНТ-СЕРВЕР Сравниваемые принципы организации систем: управление; доступность ресурсов; структура; мобильность
- 64. СПОСОБЫ РЕАЛИЗАЦИИ РАСПРЕДЕЛЕННОСТИ В СИСТЕМЕ Различают два способа реализации распределенности: Вертикальная распределенность. Горизонтальная распределенность.
- 65. ВЕРТИКАЛЬНАЯ РАСПРЕДЕЛЕННОСТЬ Реализуется путем разбиения приложения на логические уровни связанные иерархически. Такая организация характерна для клиент
- 66. ГОРИЗОНТАЛЬНАЯ РАСПРЕДЕЛЕННОСТЬ В этом случае клиент или сервер могут одновременно исполняться на одном и том же
- 67. ЗАДАЧИ РЕШАЕМЫЕ С ПОМОЩЬЮ Р2Р СИСТЕМ (1) Уменьшение/распределение затрат. Серверы централизованных систем, которые обслуживают большое количество
- 68. ЗАДАЧИ РЕШАЕМЫЕ С ПОМОЩЬЮ Р2Р СИСТЕМ (2) Надежность сети определяется такими параметрами как количество сбоев в
- 69. ПРИНЦИПЫ ПОСТРОЕНИЯ РС Р2Р В распределенной системе Р2Р каждый узел участник знает некоторое число логических соседей
- 70. КЛАССИФИКАЦИЯ СИСТЕМ Р2Р Системы Р2Р можно классифицировать по двум признакам: По степени централизации. По наличию или
- 71. КЛАССИФИКАЦИЯ Р2Р СИСТЕМ ПО СТЕПЕНИ ИХ ЦЕНТРАЛИЗАЦИИ
- 72. ЦЕНТРАЛИЗОВАННЫЕ Р2Р СИСТЕМЫ В этом случае некоторая группа узлов отвечает за выполнение критически важных для всей
- 73. НЕДОСТАТКИ ЦЕНТРАЛИЗОВАННЫХ P2P СИСТЕМ Управляющие сервера являются потенциальными точками отказа. Такое решение является плохо масштабируемым. Эти
- 74. ДЕЦЕНТРАЛИЗОВАННЫЕ АРХИТЕКТУРЫ Р2Р СИСТЕМ При очень большом числе пиров гибридные системы не способны обеспечить корректную обработку
- 75. ПРИМЕР ДЕЦЕНТРАЛИЗОВАННОЙ P2P GNUTELLA В системе Gnutella поиск и предоставление сервисов производится путем процедуры пошагового поиска,
- 76. КЛАССИФИКАЦИЯ Р2Р СИСТЕМ ПО ИХ СТРУКТУРЕ
- 77. СТРУКТУРИРОВАННЫЕ Р2Р СИСТЕМЫ Структура Р2р системы определяется структурой наложенной сети, которая может иметь одну из известных
- 78. ИНДЕКС РЕСУРСА СТРУКТУРИРОВАННОЙ P2P СИСТЕМЫ Характеристикой структурированной Р2Р системы является так называемый индекс, который однозначно определяет
- 79. РАСПРЕДЕЛЕННАЯ ХЭШ ТАБЛИЦА (DISTRIBUTED HASH TABLE) Каждому узлу структурированной P2P системы назначается идентификатор из одного того
- 80. ПОИСК УЗЛА СТРУКТУРИРОВАННОЙ P2P СИСТЕМЫ Для того чтобы найти узел, ассоциируемый с ключом, необходимо выполнить операцию
- 81. ПРИМЕР СТРУКТУРИРОВАННОЙ P2P СИСТЕМЫ - ГИПЕРКУБ Примером простой P2P системы с ограниченным числом узлов может служить
- 82. ПОИСК ПО ГИПЕРКУБУ Предположим, узел 0111(7) ищет данные, имеющие идентификатор 1110(14).
- 83. ПОИСК В СИСТЕМЕ С ТОПОЛОГИЕЙ КОЛЬЦО (СИСТЕМА ХОРД) Узлы образуют наложенную сеть логическое кольцо. В которой
- 84. ПОИСК УЗЛА В СИСТЕМЕ ХОРД Предположим, узел 9 ищет узел отвечающий за экземпляр данных с ключем
- 85. ПОИСК С ПОМОЩЬЮ МАРШРУТИЗАЦИИ ДОКУМЕНТОВ (1) Данный метод обеспечивает поиск документов без участия центрального индекса, средствами
- 86. ПОИСК С ПОМОЩЬЮ МАРШРУТИЗАЦИИ ДОКУМЕНТОВ (2) Поиск ресурса производится по аналогичному алгоритму, но вместо копирования документа
- 87. НЕСТРУКТУРИРОВАННЫЕ P2P СИСТЕМЫ Они не имеют определенной топологии. Каждый узел в такой системе поддерживает список соседних
- 88. МЕТОД ЗАТОПЛЕНИЯ Узел u посылает запросы ко всем известным ему соседям. Если узел v имеет требуемые
- 89. МЕТОД СЛУЧАЙНОГО БЛУЖДАНИЯ Узел u просто опрашивает соседей выбирая их случайным образом. Например, пусть u выберет
- 90. МЕТОД ПОИСКА ОСНОВАННЫЙ НА ПОЛИТИКЕ Этот метод занимает промежуточное положение между методами затопления и случайного блуждания.
- 91. ИЕРАРХИЧЕСКИ ОРГАНИЗОВАННЫЕ Р2Р СИСТЕМЫ В не структурированных системах по мере их роста поиск данных может стать
- 92. ИЕРАРХИЧЕСКАЯ ОРГАНИЗАЦИЯ СЕТИ Р2Р Узлы играющие роль брокеров, а также узлы поддерживающие индекс ресурсов называются супер-узлами.
- 93. ИЕРАРХИЧЕСКАЯ Р2Р СИСТЕМА. ПРИМЕР: SKYPE Самой популярной на сегодняшний день службой Интернет-телефонии является Skype, созданная в
- 94. ГИБРИДНЫЕ АРХИТЕКТУРЫ Р2Р СИСТЕМ
- 95. ГИБРИДНЫЕ АРХИТЕКТУРЫ Р2Р Существует множество архитектур РС в которых успешно сочетаются архитектуры клиент сервер и децентрализованные
- 96. ЧАСТИЧНО ЦЕНТРАЛИЗОВАННЫЕ (ГИБРИДНЫЕ) СИСТЕМЫ Р2Р В этих системах все узлы делятся на несколько типов в зависимости
- 97. СИСТЕМЫ С ГРАНИЧНЫМИ СЕРВЕРАМИ Эти системы разворачиваются в Интернет, при этом на границах сетей сервис провайдеров
- 98. СИСТЕМЫ НА ОСНОВЕ ВЗАИМНОГО СОТРУДНИЧЕСТВА (COLLABORATIVE SYSTEMS) Гибридная архитектура особенно широко используется в системах на основе
- 99. BITTORRENT Если узел хочет опубликовать файл или набор файлов, то программа- клиент BitTorrent сети разделяет передаваемые
- 100. ПРИМЕНЕНИЕ СИСТЕМ P2P Наибольшее распространение пиринговые системы получили при реализации сиситем предназначенных для обработки больших объемов
- 101. ДОСТОИНСТВА P2P СИСТЕМ Можно выделить следующие основные преимущества пиринговых систем: высокая масштабируемость, связанная с равномерным распределением
- 103. Скачать презентацию

ПОНЯТИЕ АРХИТЕКТУРЫ РАСПРЕДЕЛЕННОЙ СИСТЕМЫ
Организация РС определяется тем каким образом программное обеспечение
ПОНЯТИЕ АРХИТЕКТУРЫ РАСПРЕДЕЛЕННОЙ СИСТЕМЫ
Организация РС определяется тем каким образом программное обеспечение

ПРОГРАММНАЯ АРХИТЕКТУРА
Организация РС определяется составом программных компонент входящих в состав системы.
Программная
ПРОГРАММНАЯ АРХИТЕКТУРА
Организация РС определяется составом программных компонент входящих в состав системы.
Программная

ПРОЗHАЧНОСТЬ РС И ЕЕ АРХИТЕКТУРА
Исходя из требования обеспечения прозрачности в распределенных
ПРОЗHАЧНОСТЬ РС И ЕЕ АРХИТЕКТУРА
Исходя из требования обеспечения прозрачности в распределенных

ВЫБОР ВАРИАНТА ПРОГРАММНОЙ АРХИТЕКТУРЫ
Важнейшим решением при разработке архитектуры системы является:
выбор варианта
ВЫБОР ВАРИАНТА ПРОГРАММНОЙ АРХИТЕКТУРЫ
Важнейшим решением при разработке архитектуры системы является:
выбор варианта

СИСТЕМНАЯ АРХИТЕКТУРА
Фактическая (реально разворачиваемая) реализация РС, требует однозначного определения размещения программных
СИСТЕМНАЯ АРХИТЕКТУРА
Фактическая (реально разворачиваемая) реализация РС, требует однозначного определения размещения программных

ВИДЫ СИСТЕМНОЙ АРХИТЕКТУРЫ
Различают три вида системной архитектуры:
централизованная;
децентрализованная (peer-to-peer);
гибридная – комбинация элементов
ВИДЫ СИСТЕМНОЙ АРХИТЕКТУРЫ
Различают три вида системной архитектуры:
централизованная;
децентрализованная (peer-to-peer);
гибридная – комбинация элементов

ПОНЯТИЕ АРХИТЕКТУРНОГО СТИЛЯ
В настоящее время исследования в области программного обеспечения достигли
ПОНЯТИЕ АРХИТЕКТУРНОГО СТИЛЯ
В настоящее время исследования в области программного обеспечения достигли

ПОНЯТИЕ ПРОГРАММНОГО КОМПОНЕНТА
Компонент – модульная единица ПО снабженная полностью определенным и
ПОНЯТИЕ ПРОГРАММНОГО КОМПОНЕНТА
Компонент – модульная единица ПО снабженная полностью определенным и

ОСНОВНЫЕ ВИДЫ АРХИТЕКТУР РИС
В настоящее время общепризнанными архитектурными стилями считаются:
многоуровневые архитектукры
ОСНОВНЫЕ ВИДЫ АРХИТЕКТУР РИС
В настоящее время общепризнанными архитектурными стилями считаются:
многоуровневые архитектукры

МНОГОУРОВНЕВАЯ АРХИТЕКТУРА
Базовая идея проста: компоненты распределяются по уровням, при этом компонент
МНОГОУРОВНЕВАЯ АРХИТЕКТУРА
Базовая идея проста: компоненты распределяются по уровням, при этом компонент
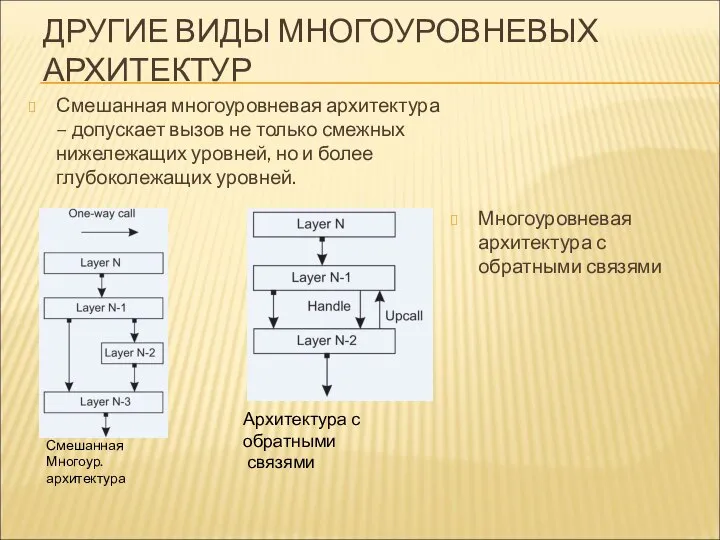
ДРУГИЕ ВИДЫ МНОГОУРОВНЕВЫХ АРХИТЕКТУР
Смешанная многоуровневая архитектура – допускает вызов не только
ДРУГИЕ ВИДЫ МНОГОУРОВНЕВЫХ АРХИТЕКТУР
Смешанная многоуровневая архитектура – допускает вызов не только
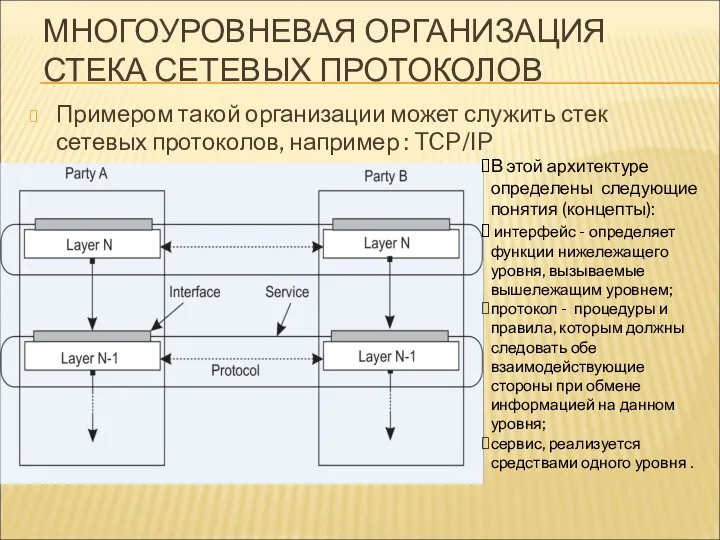
МНОГОУРОВНЕВАЯ ОРГАНИЗАЦИЯ СТЕКА СЕТЕВЫХ ПРОТОКОЛОВ
Примером такой организации может служить стек сетевых
МНОГОУРОВНЕВАЯ ОРГАНИЗАЦИЯ СТЕКА СЕТЕВЫХ ПРОТОКОЛОВ
Примером такой организации может служить стек сетевых
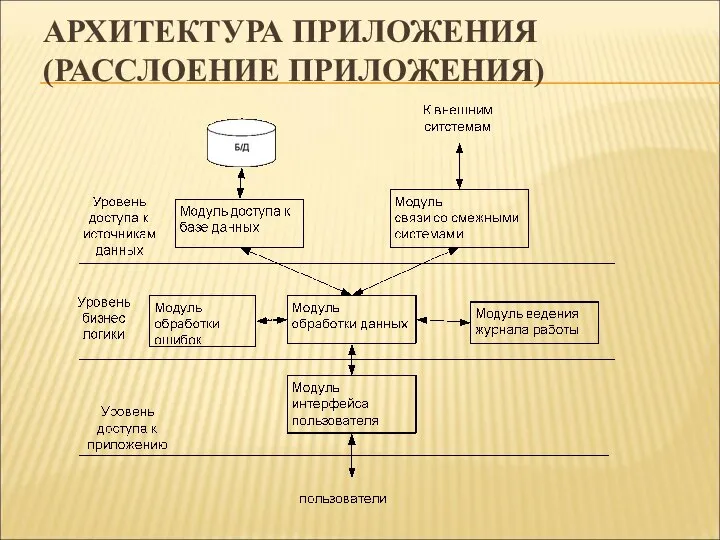
АРХИТЕКТУРА ПРИЛОЖЕНИЯ
(РАССЛОЕНИЕ ПРИЛОЖЕНИЯ)
АРХИТЕКТУРА ПРИЛОЖЕНИЯ
(РАССЛОЕНИЕ ПРИЛОЖЕНИЯ)
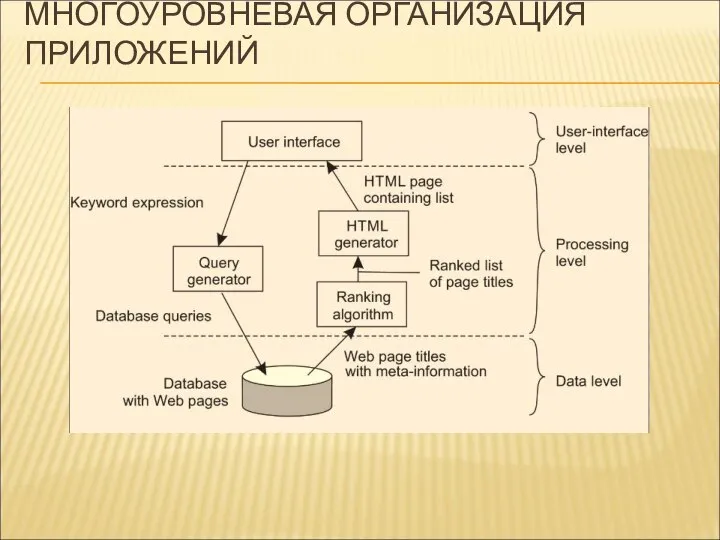
МНОГОУРОВНЕВАЯ ОРГАНИЗАЦИЯ ПРИЛОЖЕНИЙ
МНОГОУРОВНЕВАЯ ОРГАНИЗАЦИЯ ПРИЛОЖЕНИЙ
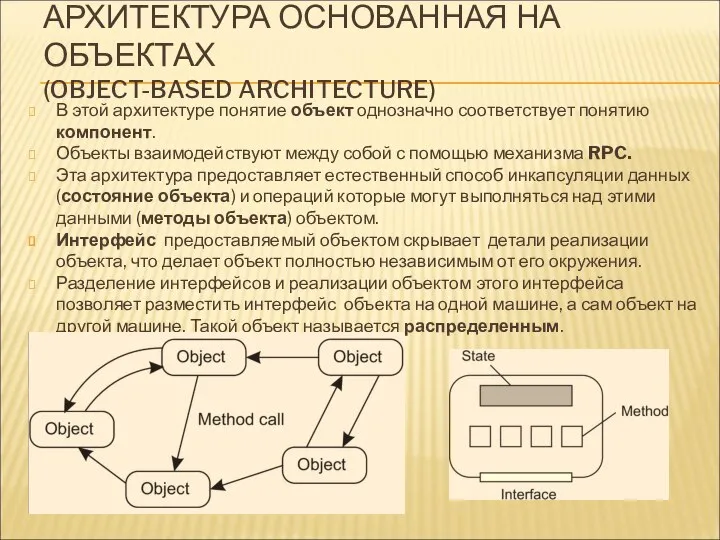
АРХИТЕКТУРА ОСНОВАННАЯ НА ОБЪЕКТАХ
(OBJECT-BASED ARCHITECTURE)
В этой архитектуре понятие объект однозначно соответствует
АРХИТЕКТУРА ОСНОВАННАЯ НА ОБЪЕКТАХ
(OBJECT-BASED ARCHITECTURE)
В этой архитектуре понятие объект однозначно соответствует
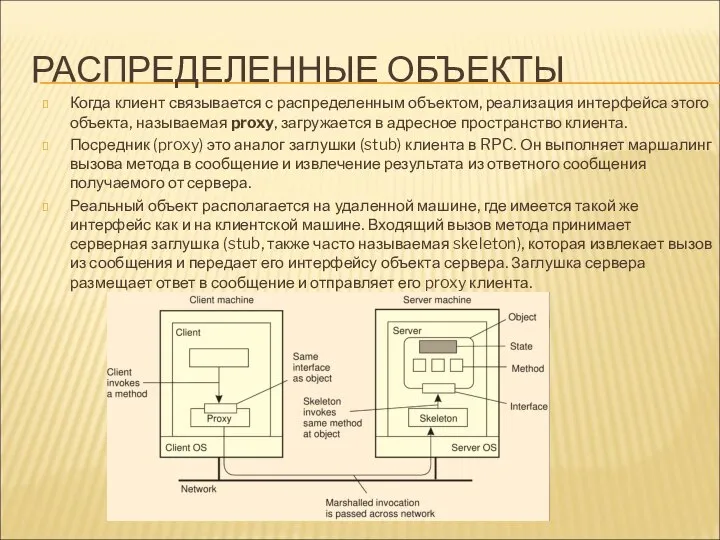
РАСПРЕДЕЛЕННЫЕ ОБЪЕКТЫ
Когда клиент связывается с распределенным объектом, реализация интерфейса этого объекта,
РАСПРЕДЕЛЕННЫЕ ОБЪЕКТЫ
Когда клиент связывается с распределенным объектом, реализация интерфейса этого объекта,

СЕРВИС
Архитектура распределенных объектов ее основе сформировать сервис как независимую программную единицу.
СЕРВИС
Архитектура распределенных объектов ее основе сформировать сервис как независимую программную единицу.

ОСНОВНЫЕ ПОНЯТИЯ СОА (1)
СOA – это способ описания требований и методология
ОСНОВНЫЕ ПОНЯТИЯ СОА (1)
СOA – это способ описания требований и методология

ОСНОВНЫЕ ПОНЯТИЯ СОА (2)
SOA описывается как совокупность сервисов, реализуемых в виде
ОСНОВНЫЕ ПОНЯТИЯ СОА (2)
SOA описывается как совокупность сервисов, реализуемых в виде
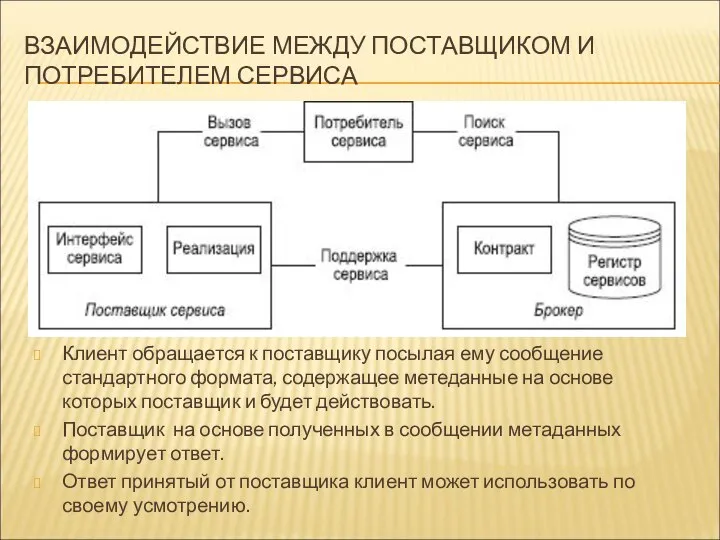
ВЗАИМОДЕЙСТВИЕ МЕЖДУ ПОСТАВЩИКОМ И ПОТРЕБИТЕЛЕМ СЕРВИСА
Клиент обращается к поставщику посылая ему
ВЗАИМОДЕЙСТВИЕ МЕЖДУ ПОСТАВЩИКОМ И ПОТРЕБИТЕЛЕМ СЕРВИСА
Клиент обращается к поставщику посылая ему
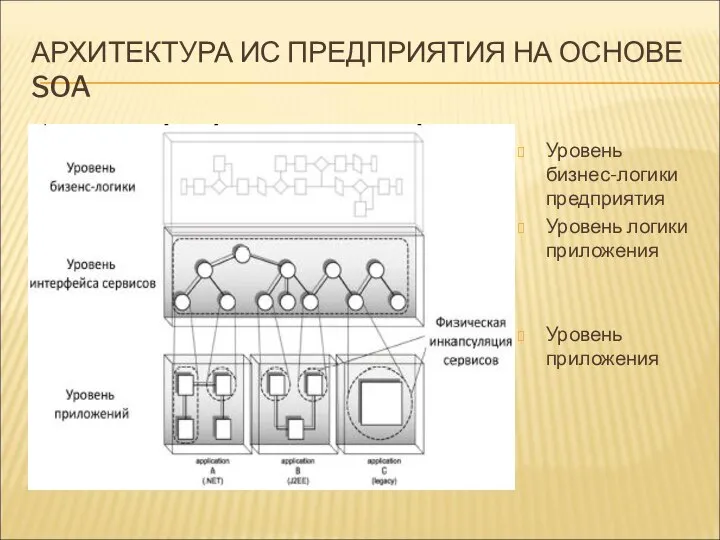
АРХИТЕКТУРА ИС ПРЕДПРИЯТИЯ НА ОСНОВЕ SOA
Уровень бизнес-логики предприятия
Уровень логики приложения
Уровень приложения
АРХИТЕКТУРА ИС ПРЕДПРИЯТИЯ НА ОСНОВЕ SOA
Уровень бизнес-логики предприятия
Уровень логики приложения
Уровень приложения
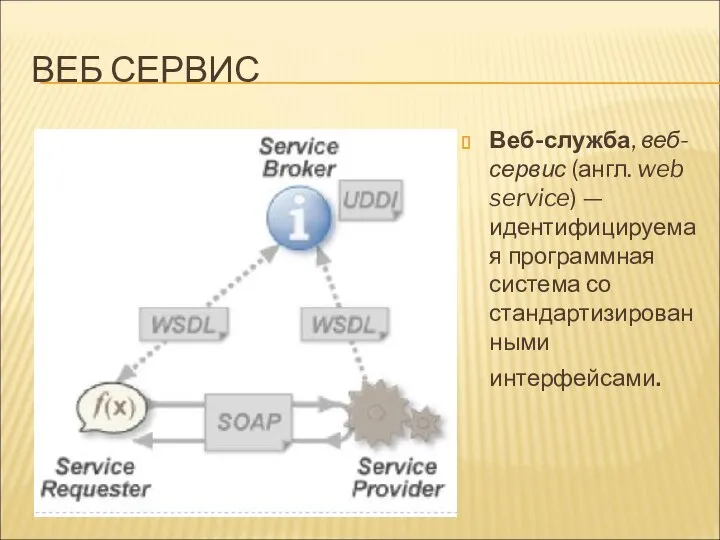
ВЕБ СЕРВИС
Веб-служба, веб-сервис (англ. web service) — идентифицируемая программная система со стандартизированными интерфейсами.
ВЕБ СЕРВИС
Веб-служба, веб-сервис (англ. web service) — идентифицируемая программная система со стандартизированными интерфейсами.
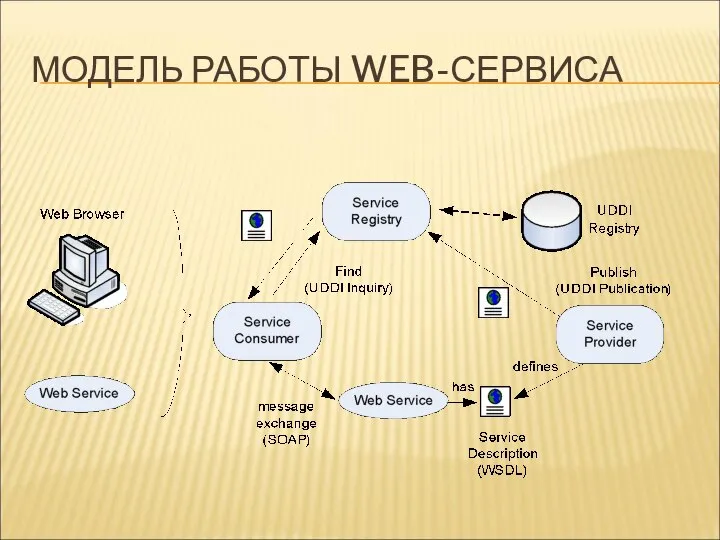
МОДЕЛЬ РАБОТЫ WEB-СЕРВИСА
МОДЕЛЬ РАБОТЫ WEB-СЕРВИСА
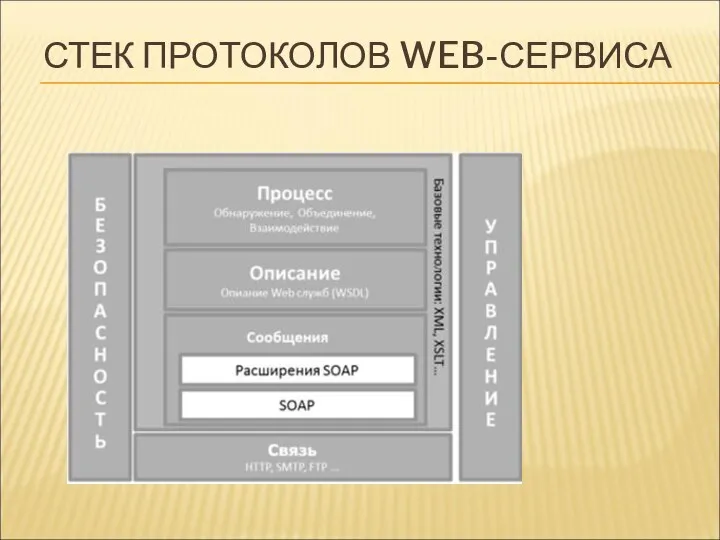
СТЕК ПРОТОКОЛОВ WEB-СЕРВИСА
СТЕК ПРОТОКОЛОВ WEB-СЕРВИСА

АРХИТЕКТУРА ОСНОВАННАЯ НА РЕСУРСАХ
Рост числа сервисов доступных через Web и создание
АРХИТЕКТУРА ОСНОВАННАЯ НА РЕСУРСАХ
Рост числа сервисов доступных через Web и создание
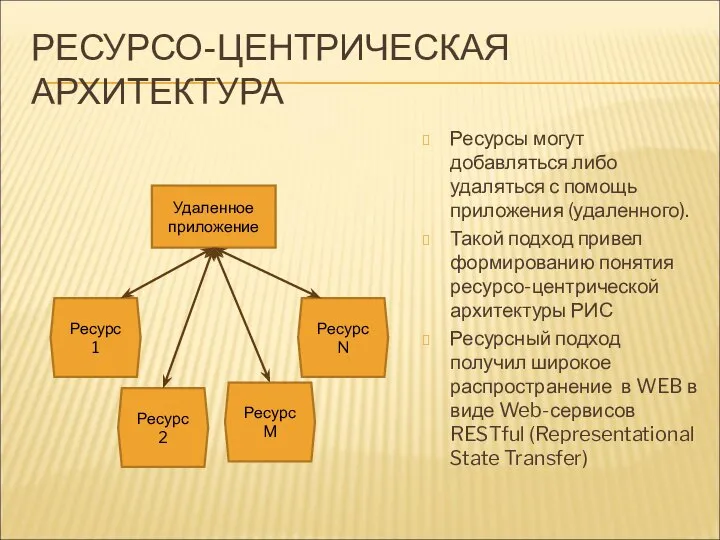
РЕСУРСО-ЦЕНТРИЧЕСКАЯ АРХИТЕКТУРА
Ресурсы могут добавляться либо удаляться с помощь приложения (удаленного).
Такой подход
РЕСУРСО-ЦЕНТРИЧЕСКАЯ АРХИТЕКТУРА
Ресурсы могут добавляться либо удаляться с помощь приложения (удаленного).
Такой подход

ПРИНЦИПЫ АРХИТЕКТУРЫ RESTFUL
Архитектура REST (Representational State Transfer) основана на четырех принципах
ПРИНЦИПЫ АРХИТЕКТУРЫ RESTFUL
Архитектура REST (Representational State Transfer) основана на четырех принципах

СРАВНЕНИЕ REST И SOAP/XML WEB-СЕРВИСОВ
RESTful архитектура стала популярна благодаря своей простоте.
SOAP
СРАВНЕНИЕ REST И SOAP/XML WEB-СЕРВИСОВ
RESTful архитектура стала популярна благодаря своей простоте.
SOAP
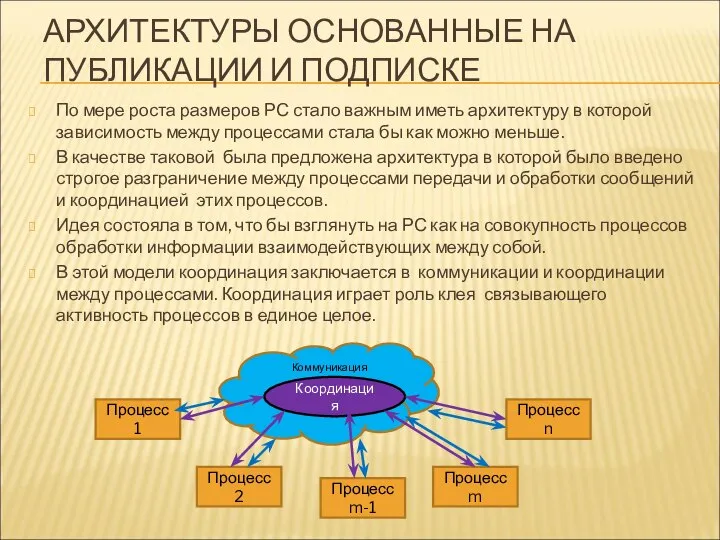
АРХИТЕКТУРЫ ОСНОВАННЫЕ НА ПУБЛИКАЦИИ И ПОДПИСКЕ
По мере роста размеров РС стало
АРХИТЕКТУРЫ ОСНОВАННЫЕ НА ПУБЛИКАЦИИ И ПОДПИСКЕ
По мере роста размеров РС стало

СПОСОБЫ КООРДИНАЦИИ
В зависимости то вида координации используемой в системе можно определить
СПОСОБЫ КООРДИНАЦИИ
В зависимости то вида координации используемой в системе можно определить

ВАРИАНТЫ АРХИТЕКТУР ПУБЛИКАЦИЯ/ПОДПИСКА
В зависимости от комбинации двух факторов координации различают следующие
ВАРИАНТЫ АРХИТЕКТУР ПУБЛИКАЦИЯ/ПОДПИСКА
В зависимости от комбинации двух факторов координации различают следующие
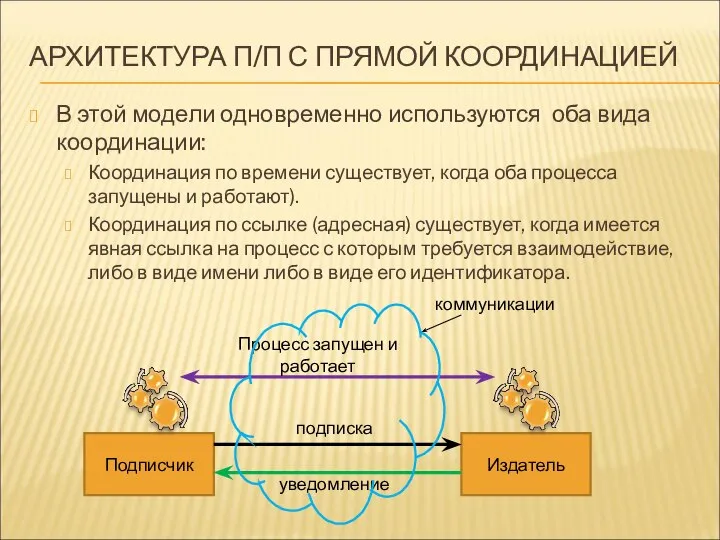
АРХИТЕКТУРА П/П С ПРЯМОЙ КООРДИНАЦИЕЙ
В этой модели одновременно используются оба вида
АРХИТЕКТУРА П/П С ПРЯМОЙ КООРДИНАЦИЕЙ
В этой модели одновременно используются оба вида
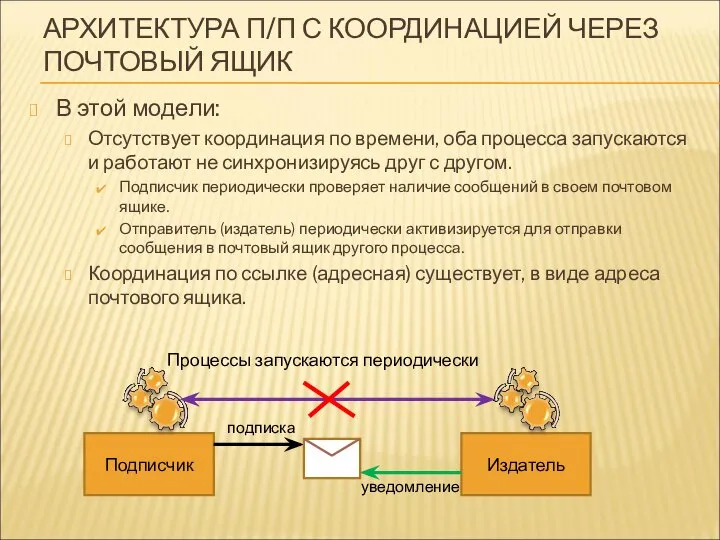
АРХИТЕКТУРА П/П С КООРДИНАЦИЕЙ ЧЕРЕЗ ПОЧТОВЫЙ ЯЩИК
В этой модели:
Отсутствует координация по
АРХИТЕКТУРА П/П С КООРДИНАЦИЕЙ ЧЕРЕЗ ПОЧТОВЫЙ ЯЩИК
В этой модели:
Отсутствует координация по
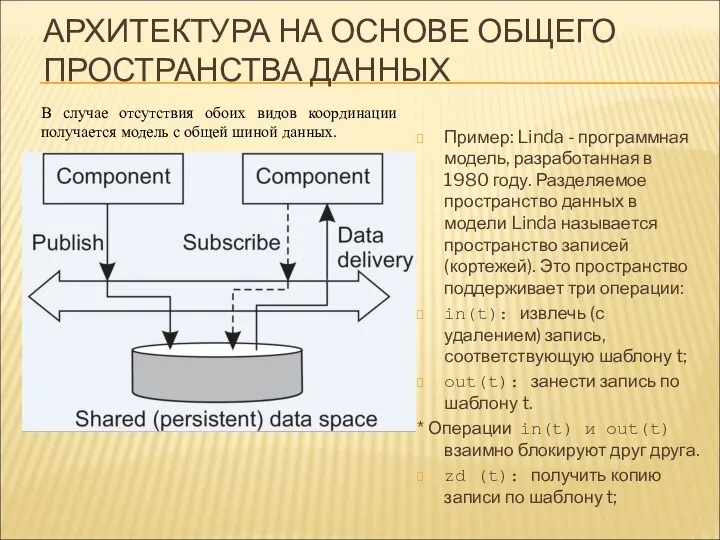
АРХИТЕКТУРА НА ОСНОВЕ ОБЩЕГО ПРОСТРАНСТВА ДАННЫХ
Пример: Linda - программная модель, разработанная
АРХИТЕКТУРА НА ОСНОВЕ ОБЩЕГО ПРОСТРАНСТВА ДАННЫХ
Пример: Linda - программная модель, разработанная
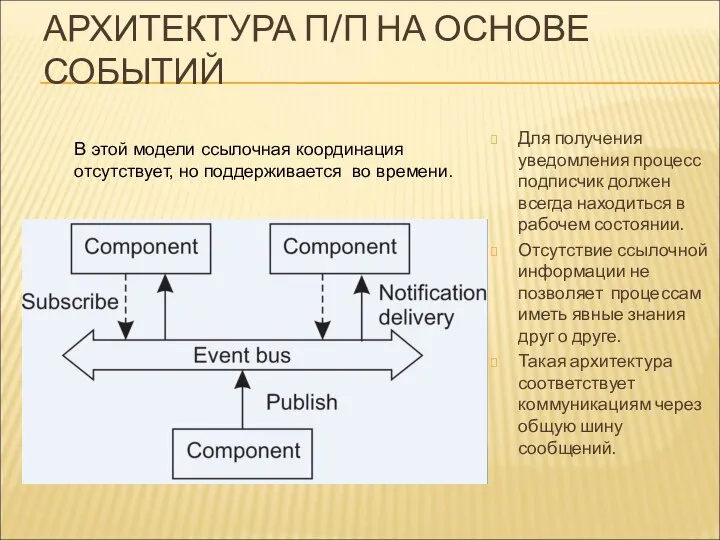
АРХИТЕКТУРА П/П НА ОСНОВЕ СОБЫТИЙ
Для получения уведомления процесс подписчик должен всегда
АРХИТЕКТУРА П/П НА ОСНОВЕ СОБЫТИЙ
Для получения уведомления процесс подписчик должен всегда

ВАРИАНТЫ АРХИТЕКТУРЫ П/П НА ОСНОВЕ СОБЫТИЙ
В зависимости от способа описания события
ВАРИАНТЫ АРХИТЕКТУРЫ П/П НА ОСНОВЕ СОБЫТИЙ
В зависимости от способа описания события

СИСТЕМА ПУБЛИКАЦИИ/ПОДПИСКИ ОСНОВАННАЯ НА ТЕМЕ
Событие описывается набором атрибутов – списком пар
СИСТЕМА ПУБЛИКАЦИИ/ПОДПИСКИ ОСНОВАННАЯ НА ТЕМЕ
Событие описывается набором атрибутов – списком пар

СИСТЕМЫ ПУБЛИКАЦИИ/ПОДПИСКИ ОСНОВАННЫЕ НА СОДЕРЖИМОМ (КОНТЕНТЕ)
В этом случае событие также
СИСТЕМЫ ПУБЛИКАЦИИ/ПОДПИСКИ ОСНОВАННЫЕ НА СОДЕРЖИМОМ (КОНТЕНТЕ)
В этом случае событие также
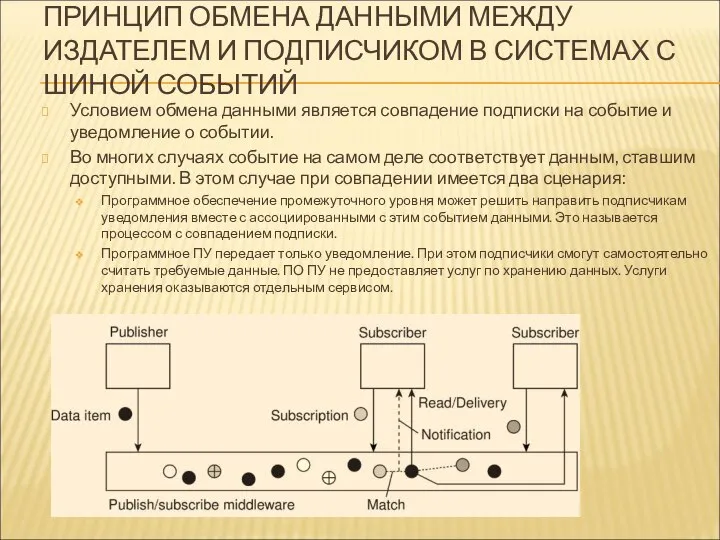
ПРИНЦИП ОБМЕНА ДАННЫМИ МЕЖДУ ИЗДАТЕЛЕМ И ПОДПИСЧИКОМ В СИСТЕМАХ С ШИНОЙ
ПРИНЦИП ОБМЕНА ДАННЫМИ МЕЖДУ ИЗДАТЕЛЕМ И ПОДПИСЧИКОМ В СИСТЕМАХ С ШИНОЙ

ОСНОВНАЯ ПРОБЛЕМА СИСТЕМ ПУБЛИКАЦИИ/ПОДПИСКИ
События могут легко запутать работу подписчиков. В
ОСНОВНАЯ ПРОБЛЕМА СИСТЕМ ПУБЛИКАЦИИ/ПОДПИСКИ
События могут легко запутать работу подписчиков. В

ОРГАНИЗАЦИЯ ПРОМЕЖУТОЧНОГО ПО (MIDLEWARE)
При организации ПО промежуточного уровня в системах основанных
ОРГАНИЗАЦИЯ ПРОМЕЖУТОЧНОГО ПО (MIDLEWARE)
При организации ПО промежуточного уровня в системах основанных
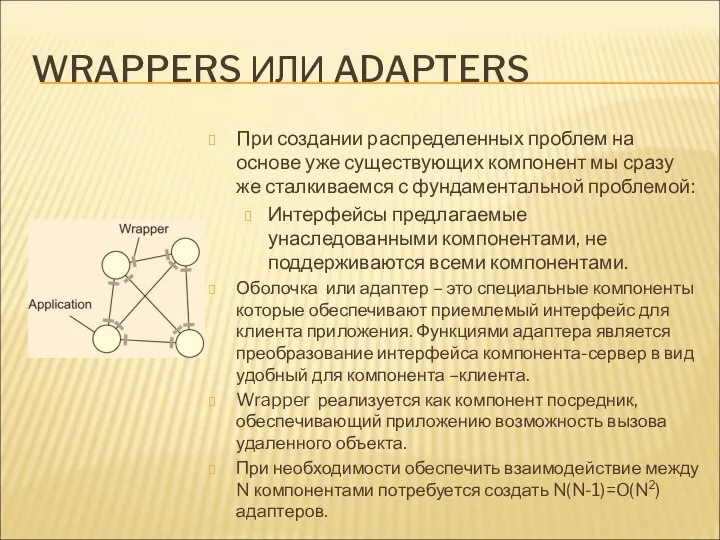
WRAPPERS ИЛИ ADAPTERS
При создании распределенных проблем на основе уже существующих компонент
WRAPPERS ИЛИ ADAPTERS
При создании распределенных проблем на основе уже существующих компонент
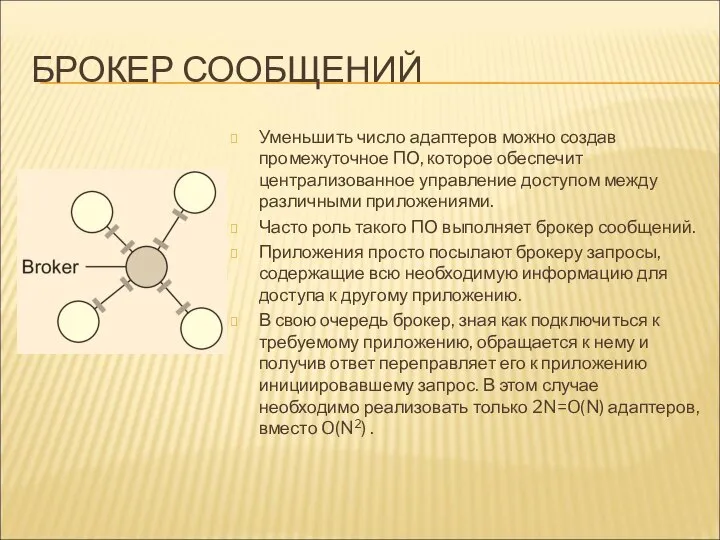
БРОКЕР СООБЩЕНИЙ
Уменьшить число адаптеров можно создав промежуточное ПО, которое обеспечит централизованное
БРОКЕР СООБЩЕНИЙ
Уменьшить число адаптеров можно создав промежуточное ПО, которое обеспечит централизованное
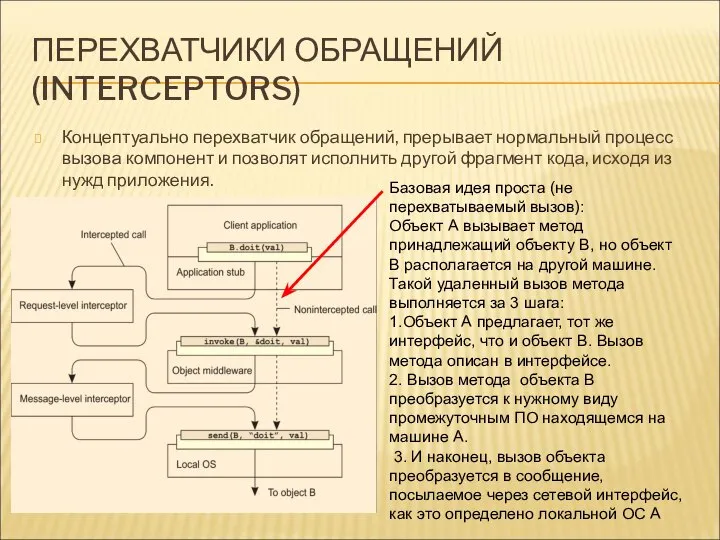
ПЕРЕХВАТЧИКИ ОБРАЩЕНИЙ (INTERCEPTORS)
Концептуально перехватчик обращений, прерывает нормальный процесс вызова компонент и
ПЕРЕХВАТЧИКИ ОБРАЩЕНИЙ (INTERCEPTORS)
Концептуально перехватчик обращений, прерывает нормальный процесс вызова компонент и
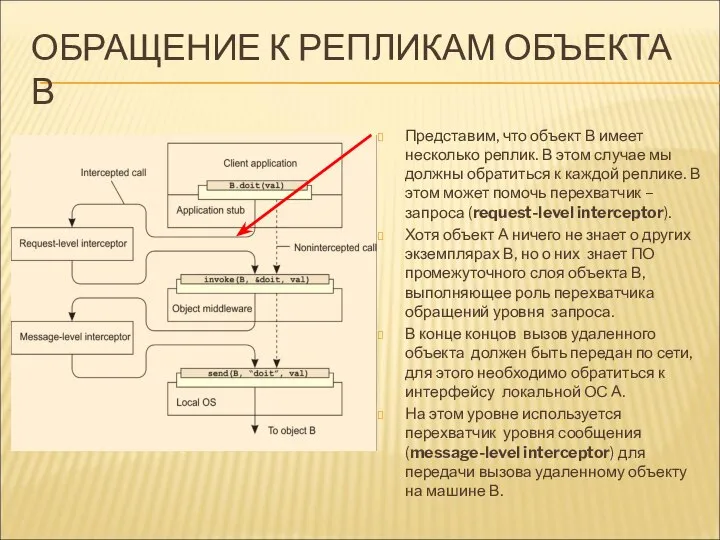
ОБРАЩЕНИЕ К РЕПЛИКАМ ОБЪЕКТА В
Представим, что объект В имеет несколько реплик.
ОБРАЩЕНИЕ К РЕПЛИКАМ ОБЪЕКТА В
Представим, что объект В имеет несколько реплик.
АДАПТИРУЕМОЕ ПО ПРОМЕЖУТОЧНОГО СЛОЯ
Необходимость в адаптируемом промежуточном ПО возникает из-за того,
АДАПТИРУЕМОЕ ПО ПРОМЕЖУТОЧНОГО СЛОЯ
Необходимость в адаптируемом промежуточном ПО возникает из-за того,
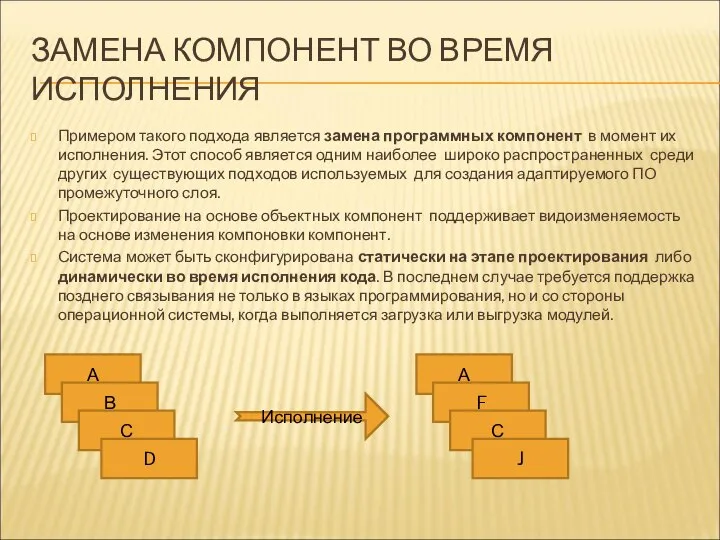
ЗАМЕНА КОМПОНЕНТ ВО ВРЕМЯ ИСПОЛНЕНИЯ
Примером такого подхода является замена программных компонент
ЗАМЕНА КОМПОНЕНТ ВО ВРЕМЯ ИСПОЛНЕНИЯ
Примером такого подхода является замена программных компонент

СИСТЕМНАЯ АРХИТЕКТУРА
СИСТЕМНАЯ АРХИТЕКТУРА

ЦЕНТРАЛИЗОВАННАЯ ОРГАНИЗАЦИЯ РС
ЦЕНТРАЛИЗОВАННАЯ ОРГАНИЗАЦИЯ РС

ВАРИАНТЫ АРХИТЕКТУРЫ КЛИЕНТ-СЕРВЕР
Простейшая организация предполагает наличие всего двух типов машин.
Клиентские машины,
ВАРИАНТЫ АРХИТЕКТУРЫ КЛИЕНТ-СЕРВЕР
Простейшая организация предполагает наличие всего двух типов машин.
Клиентские машины,
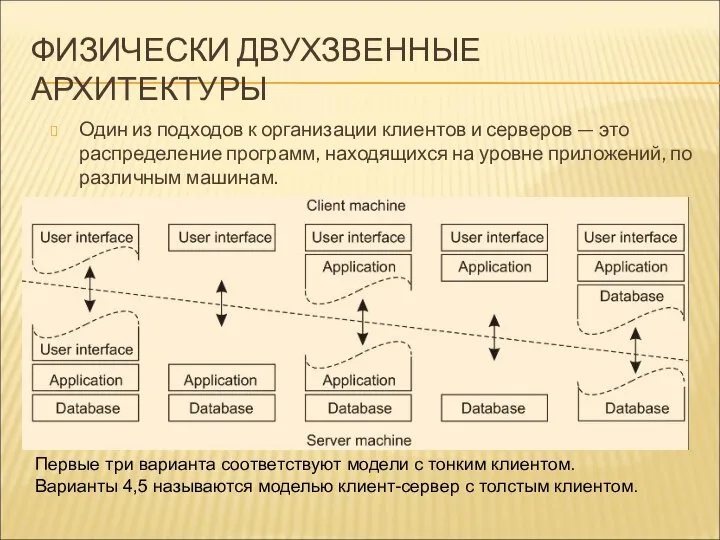
ФИЗИЧЕСКИ ДВУХЗВЕННЫЕ АРХИТЕКТУРЫ
Один из подходов к организации клиентов и серверов —
ФИЗИЧЕСКИ ДВУХЗВЕННЫЕ АРХИТЕКТУРЫ
Один из подходов к организации клиентов и серверов —

РАЗНОВИДНОСТИ
МОДЕЛИ КЛИЕНТ-СЕРВЕР
Обычно ПО хранения данных располагается на сервере (например, сервер базы
РАЗНОВИДНОСТИ
МОДЕЛИ КЛИЕНТ-СЕРВЕР
Обычно ПО хранения данных располагается на сервере (например, сервер базы
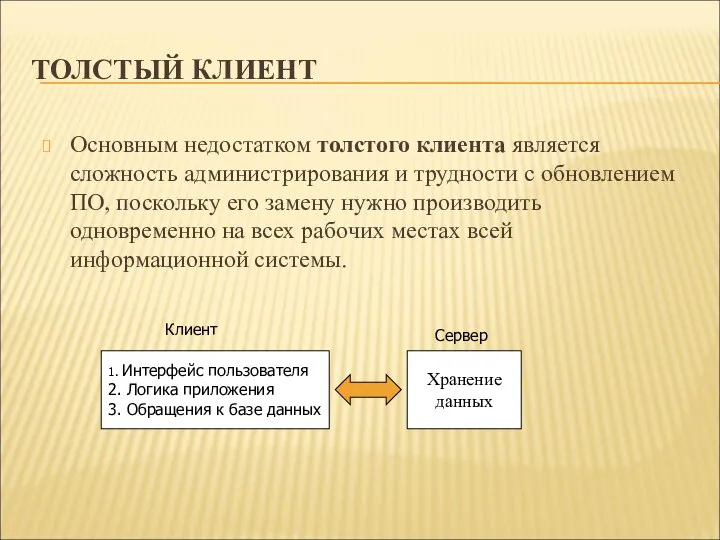
ТОЛСТЫЙ КЛИЕНТ
Основным недостатком толстого клиента является сложность администрирования и трудности с
ТОЛСТЫЙ КЛИЕНТ
Основным недостатком толстого клиента является сложность администрирования и трудности с

ТОНКИЙ КЛИЕНТ
В тонком клиенте этот недостаток устраняется, однако появляются большие сложности
ТОНКИЙ КЛИЕНТ
В тонком клиенте этот недостаток устраняется, однако появляются большие сложности
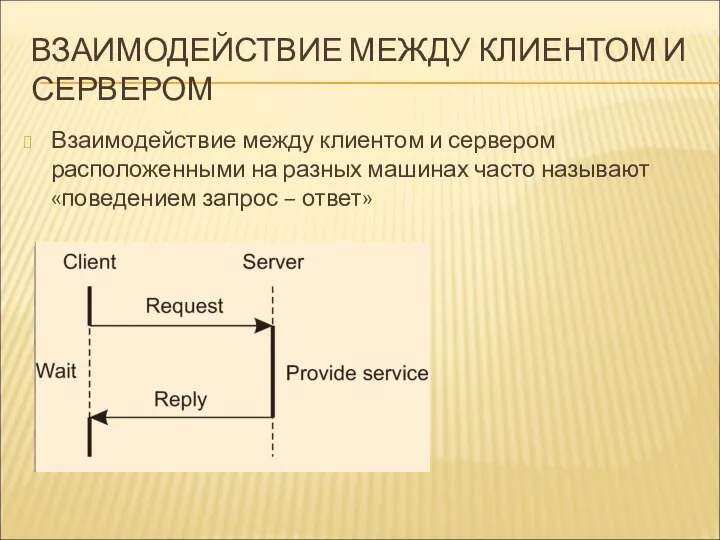
ВЗАИМОДЕЙСТВИЕ МЕЖДУ КЛИЕНТОМ И СЕРВЕРОМ
Взаимодействие между клиентом и сервером расположенными на
ВЗАИМОДЕЙСТВИЕ МЕЖДУ КЛИЕНТОМ И СЕРВЕРОМ
Взаимодействие между клиентом и сервером расположенными на
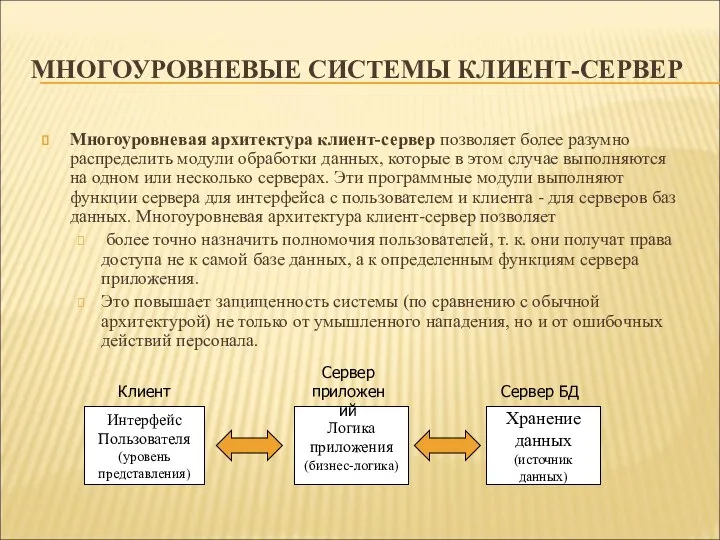
МНОГОУРОВНЕВЫЕ СИСТЕМЫ КЛИЕНТ-СЕРВЕР
Многоуровневая архитектура клиент-сервер позволяет более разумно распределить модули обработки
МНОГОУРОВНЕВЫЕ СИСТЕМЫ КЛИЕНТ-СЕРВЕР
Многоуровневая архитектура клиент-сервер позволяет более разумно распределить модули обработки
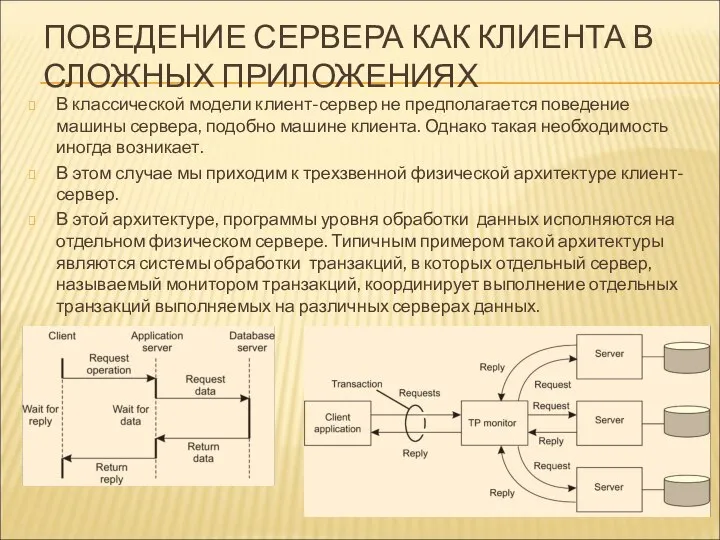
ПОВЕДЕНИЕ СЕРВЕРА КАК КЛИЕНТА В СЛОЖНЫХ ПРИЛОЖЕНИЯХ
В классической модели клиент-сервер не
ПОВЕДЕНИЕ СЕРВЕРА КАК КЛИЕНТА В СЛОЖНЫХ ПРИЛОЖЕНИЯХ
В классической модели клиент-сервер не
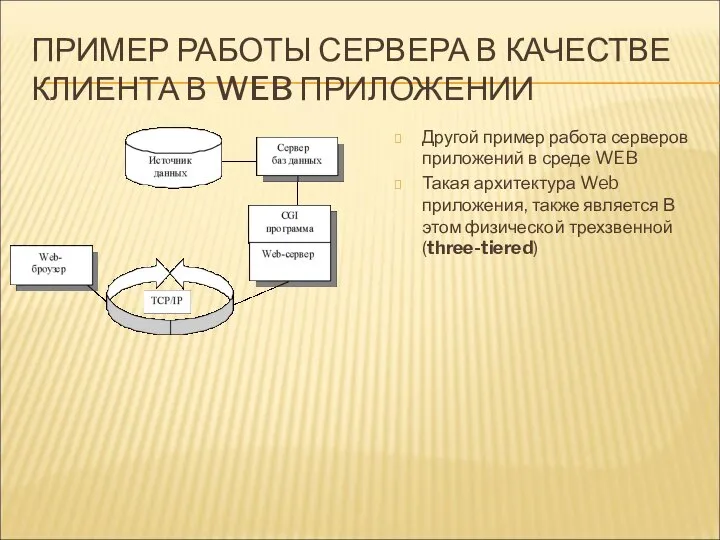
ПРИМЕР РАБОТЫ СЕРВЕРА В КАЧЕСТВЕ КЛИЕНТА В WEB ПРИЛОЖЕНИИ
Другой пример работа
ПРИМЕР РАБОТЫ СЕРВЕРА В КАЧЕСТВЕ КЛИЕНТА В WEB ПРИЛОЖЕНИИ
Другой пример работа
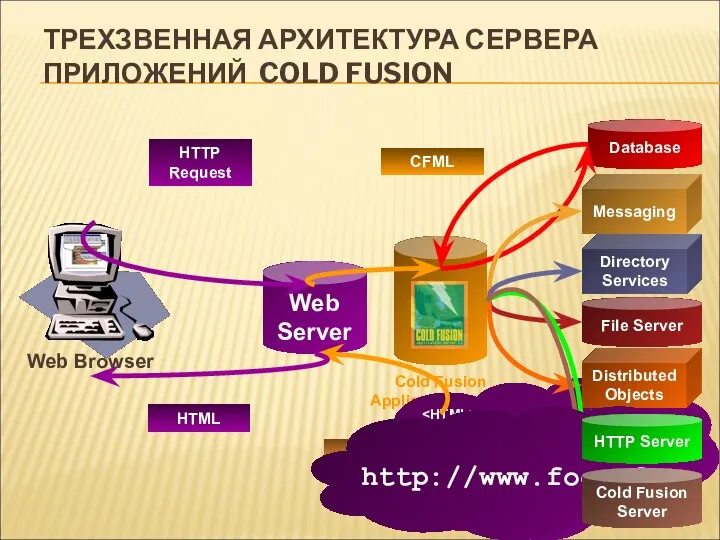
HTTP Request
CFML
HTML
HTML
Database
Messaging
Directory
Services
File Server
Distributed
Objects
ТРЕХЗВЕННАЯ АРХИТЕКТУРА СЕРВЕРА ПРИЛОЖЕНИЙ COLD FUSION
Cold Fusion
Server
HTTP Server
HTTP Request
CFML
HTML
HTML
Database
Messaging
Directory
Services
File Server
Distributed
Objects
ТРЕХЗВЕННАЯ АРХИТЕКТУРА СЕРВЕРА ПРИЛОЖЕНИЙ COLD FUSION
Cold Fusion
Server
HTTP Server

ДЕЦЕНТРАЛИЗОВАННАЯ ОРГАНИЗАЦИЯ РС:
СИСТЕМЫ PEER-TO-PEER (ОДНОРАНГОВЫЕ СИСТЕМЫ)
ДЕЦЕНТРАЛИЗОВАННАЯ ОРГАНИЗАЦИЯ РС:
СИСТЕМЫ PEER-TO-PEER (ОДНОРАНГОВЫЕ СИСТЕМЫ)
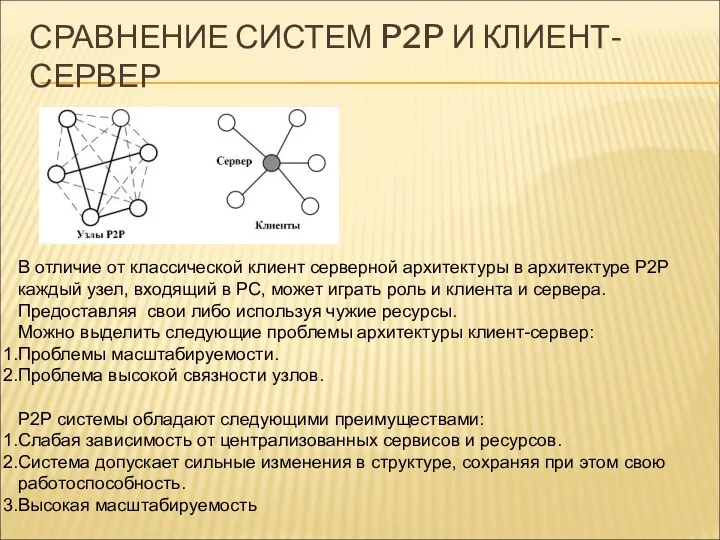
СРАВНЕНИЕ СИСТЕМ P2P И КЛИЕНТ-СЕРВЕР
В отличие от классической клиент серверной
СРАВНЕНИЕ СИСТЕМ P2P И КЛИЕНТ-СЕРВЕР
В отличие от классической клиент серверной
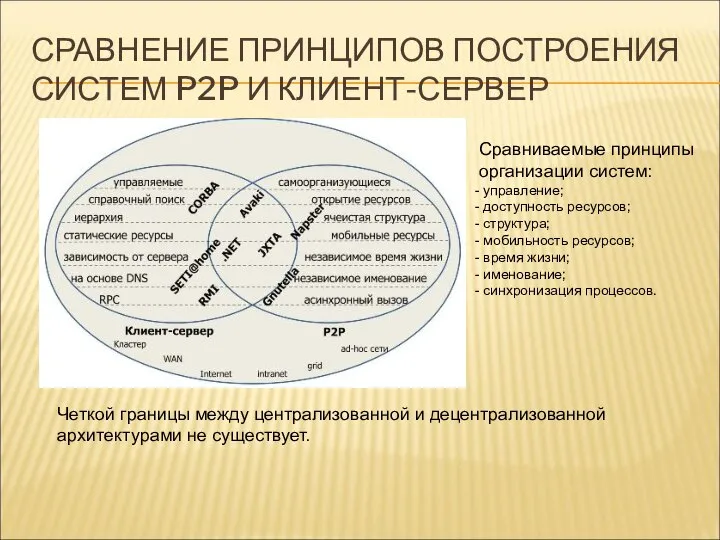
СРАВНЕНИЕ ПРИНЦИПОВ ПОСТРОЕНИЯ СИСТЕМ P2P И КЛИЕНТ-СЕРВЕР
Сравниваемые принципы организации систем:
СРАВНЕНИЕ ПРИНЦИПОВ ПОСТРОЕНИЯ СИСТЕМ P2P И КЛИЕНТ-СЕРВЕР
Сравниваемые принципы организации систем:

СПОСОБЫ РЕАЛИЗАЦИИ РАСПРЕДЕЛЕННОСТИ В СИСТЕМЕ
Различают два способа реализации распределенности:
Вертикальная распределенность.
Горизонтальная распределенность.
СПОСОБЫ РЕАЛИЗАЦИИ РАСПРЕДЕЛЕННОСТИ В СИСТЕМЕ
Различают два способа реализации распределенности:
Вертикальная распределенность.
Горизонтальная распределенность.
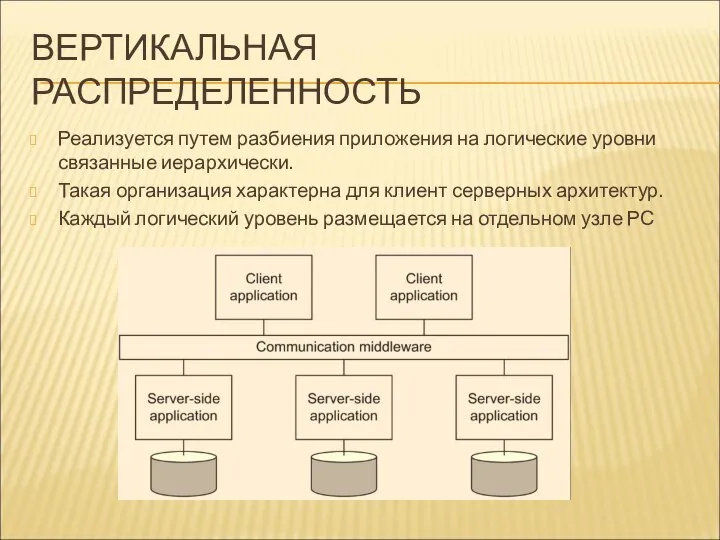
ВЕРТИКАЛЬНАЯ РАСПРЕДЕЛЕННОСТЬ
Реализуется путем разбиения приложения на логические уровни связанные иерархически.
Такая организация
ВЕРТИКАЛЬНАЯ РАСПРЕДЕЛЕННОСТЬ
Реализуется путем разбиения приложения на логические уровни связанные иерархически.
Такая организация

ГОРИЗОНТАЛЬНАЯ РАСПРЕДЕЛЕННОСТЬ
В этом случае клиент или сервер могут одновременно исполняться на
ГОРИЗОНТАЛЬНАЯ РАСПРЕДЕЛЕННОСТЬ
В этом случае клиент или сервер могут одновременно исполняться на

ЗАДАЧИ РЕШАЕМЫЕ С ПОМОЩЬЮ Р2Р СИСТЕМ (1)
Уменьшение/распределение затрат. Серверы централизованных систем,
ЗАДАЧИ РЕШАЕМЫЕ С ПОМОЩЬЮ Р2Р СИСТЕМ (1)
Уменьшение/распределение затрат. Серверы централизованных систем,

ЗАДАЧИ РЕШАЕМЫЕ С ПОМОЩЬЮ Р2Р СИСТЕМ (2)
Надежность сети определяется такими параметрами
ЗАДАЧИ РЕШАЕМЫЕ С ПОМОЩЬЮ Р2Р СИСТЕМ (2)
Надежность сети определяется такими параметрами

ПРИНЦИПЫ ПОСТРОЕНИЯ РС Р2Р
В распределенной системе Р2Р каждый узел участник знает
ПРИНЦИПЫ ПОСТРОЕНИЯ РС Р2Р
В распределенной системе Р2Р каждый узел участник знает

КЛАССИФИКАЦИЯ СИСТЕМ Р2Р
Системы Р2Р можно классифицировать по двум признакам:
По степени централизации.
По
КЛАССИФИКАЦИЯ СИСТЕМ Р2Р
Системы Р2Р можно классифицировать по двум признакам:
По степени централизации.
По

КЛАССИФИКАЦИЯ Р2Р СИСТЕМ ПО СТЕПЕНИ ИХ ЦЕНТРАЛИЗАЦИИ
КЛАССИФИКАЦИЯ Р2Р СИСТЕМ ПО СТЕПЕНИ ИХ ЦЕНТРАЛИЗАЦИИ
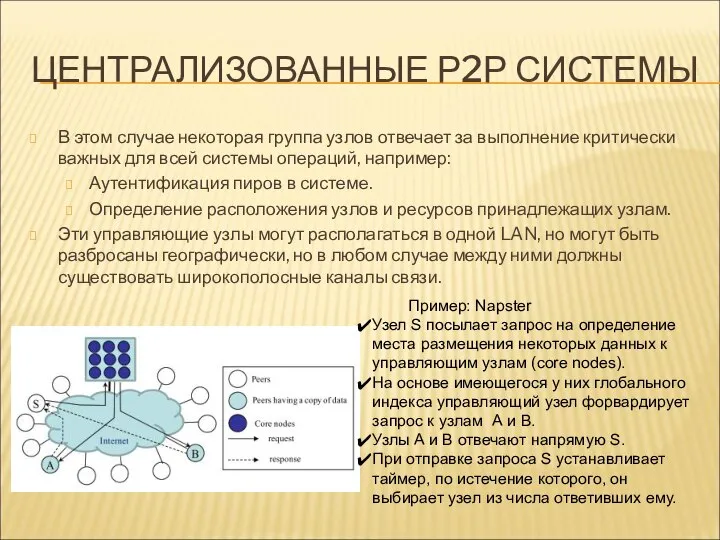
ЦЕНТРАЛИЗОВАННЫЕ Р2Р СИСТЕМЫ
В этом случае некоторая группа узлов отвечает за выполнение
ЦЕНТРАЛИЗОВАННЫЕ Р2Р СИСТЕМЫ
В этом случае некоторая группа узлов отвечает за выполнение

НЕДОСТАТКИ ЦЕНТРАЛИЗОВАННЫХ P2P СИСТЕМ
Управляющие сервера являются потенциальными точками отказа.
Такое решение является
НЕДОСТАТКИ ЦЕНТРАЛИЗОВАННЫХ P2P СИСТЕМ
Управляющие сервера являются потенциальными точками отказа.
Такое решение является

ДЕЦЕНТРАЛИЗОВАННЫЕ АРХИТЕКТУРЫ Р2Р СИСТЕМ
При очень большом числе пиров гибридные системы не
ДЕЦЕНТРАЛИЗОВАННЫЕ АРХИТЕКТУРЫ Р2Р СИСТЕМ
При очень большом числе пиров гибридные системы не

ПРИМЕР ДЕЦЕНТРАЛИЗОВАННОЙ P2P GNUTELLA
В системе Gnutella поиск и предоставление сервисов производится
ПРИМЕР ДЕЦЕНТРАЛИЗОВАННОЙ P2P GNUTELLA
В системе Gnutella поиск и предоставление сервисов производится

КЛАССИФИКАЦИЯ Р2Р СИСТЕМ ПО ИХ СТРУКТУРЕ
КЛАССИФИКАЦИЯ Р2Р СИСТЕМ ПО ИХ СТРУКТУРЕ

СТРУКТУРИРОВАННЫЕ Р2Р СИСТЕМЫ
Структура Р2р системы определяется структурой наложенной сети, которая может
СТРУКТУРИРОВАННЫЕ Р2Р СИСТЕМЫ
Структура Р2р системы определяется структурой наложенной сети, которая может

ИНДЕКС РЕСУРСА СТРУКТУРИРОВАННОЙ P2P СИСТЕМЫ
Характеристикой структурированной Р2Р системы является так называемый
ИНДЕКС РЕСУРСА СТРУКТУРИРОВАННОЙ P2P СИСТЕМЫ
Характеристикой структурированной Р2Р системы является так называемый

РАСПРЕДЕЛЕННАЯ ХЭШ ТАБЛИЦА (DISTRIBUTED HASH TABLE)
Каждому узлу структурированной P2P системы назначается
РАСПРЕДЕЛЕННАЯ ХЭШ ТАБЛИЦА (DISTRIBUTED HASH TABLE)
Каждому узлу структурированной P2P системы назначается

ПОИСК УЗЛА СТРУКТУРИРОВАННОЙ P2P СИСТЕМЫ
Для того чтобы найти узел, ассоциируемый с
ПОИСК УЗЛА СТРУКТУРИРОВАННОЙ P2P СИСТЕМЫ
Для того чтобы найти узел, ассоциируемый с

ПРИМЕР СТРУКТУРИРОВАННОЙ P2P СИСТЕМЫ - ГИПЕРКУБ
Примером простой P2P системы с ограниченным
ПРИМЕР СТРУКТУРИРОВАННОЙ P2P СИСТЕМЫ - ГИПЕРКУБ
Примером простой P2P системы с ограниченным
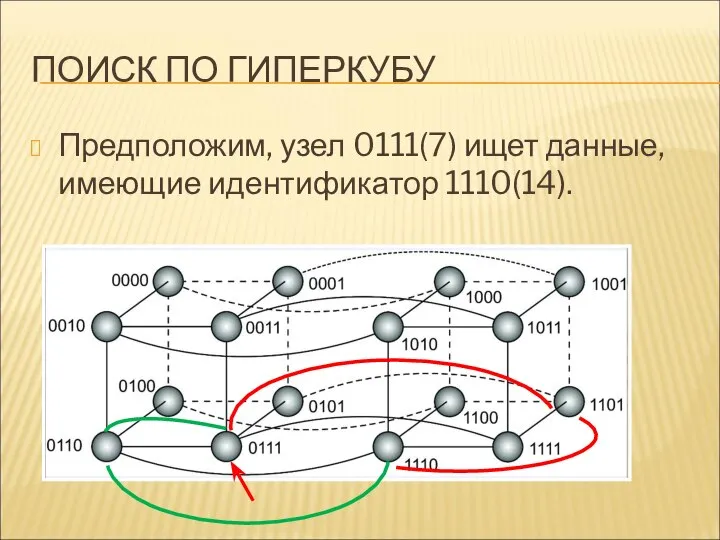
ПОИСК ПО ГИПЕРКУБУ
Предположим, узел 0111(7) ищет данные, имеющие идентификатор 1110(14).
ПОИСК ПО ГИПЕРКУБУ
Предположим, узел 0111(7) ищет данные, имеющие идентификатор 1110(14).
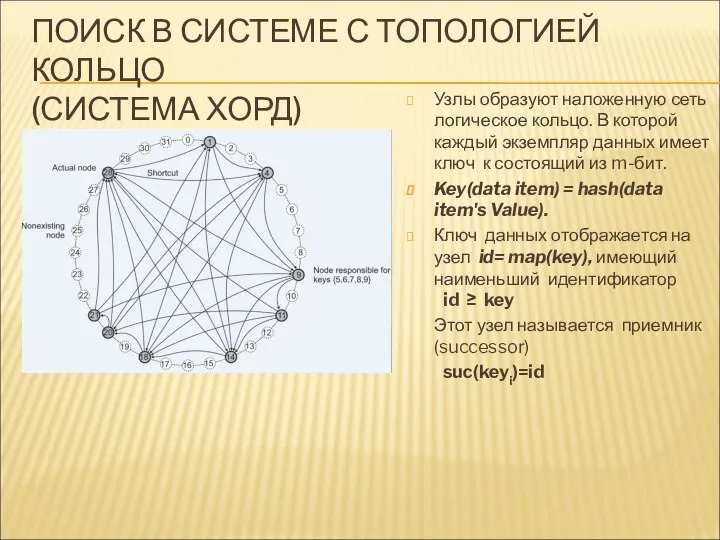
ПОИСК В СИСТЕМЕ С ТОПОЛОГИЕЙ КОЛЬЦО
(СИСТЕМА ХОРД)
Узлы образуют наложенную сеть логическое
ПОИСК В СИСТЕМЕ С ТОПОЛОГИЕЙ КОЛЬЦО
(СИСТЕМА ХОРД)
Узлы образуют наложенную сеть логическое
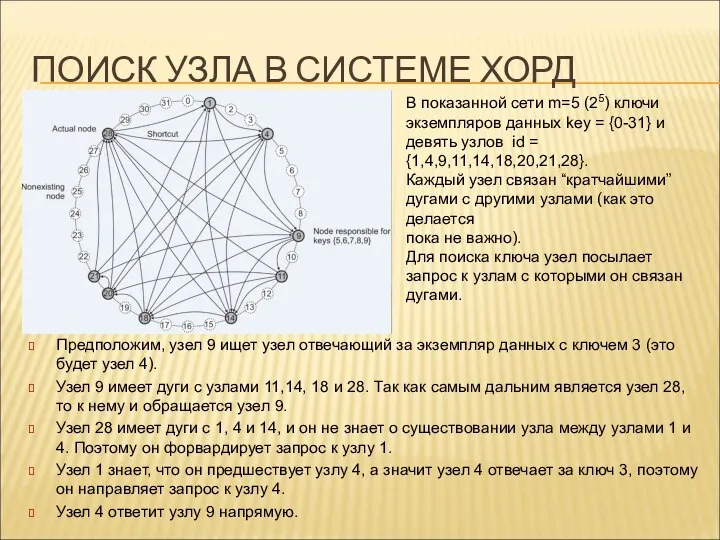
ПОИСК УЗЛА В СИСТЕМЕ ХОРД
Предположим, узел 9 ищет узел отвечающий
ПОИСК УЗЛА В СИСТЕМЕ ХОРД
Предположим, узел 9 ищет узел отвечающий
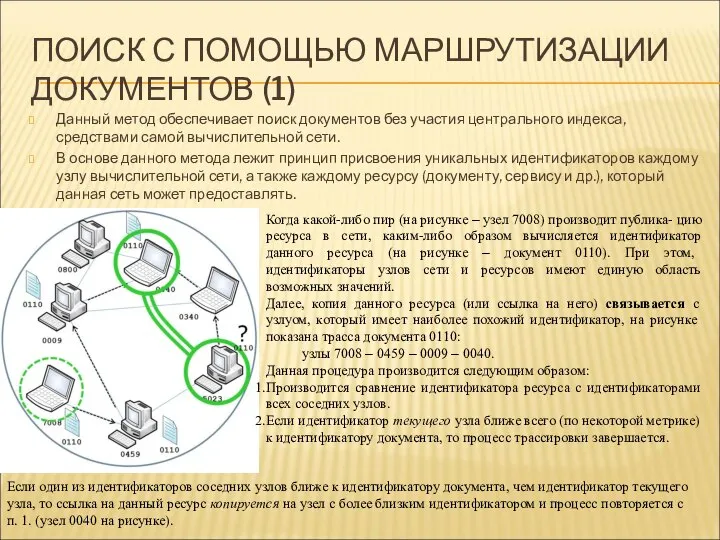
ПОИСК С ПОМОЩЬЮ МАРШРУТИЗАЦИИ ДОКУМЕНТОВ (1)
Данный метод обеспечивает поиск документов без
ПОИСК С ПОМОЩЬЮ МАРШРУТИЗАЦИИ ДОКУМЕНТОВ (1)
Данный метод обеспечивает поиск документов без
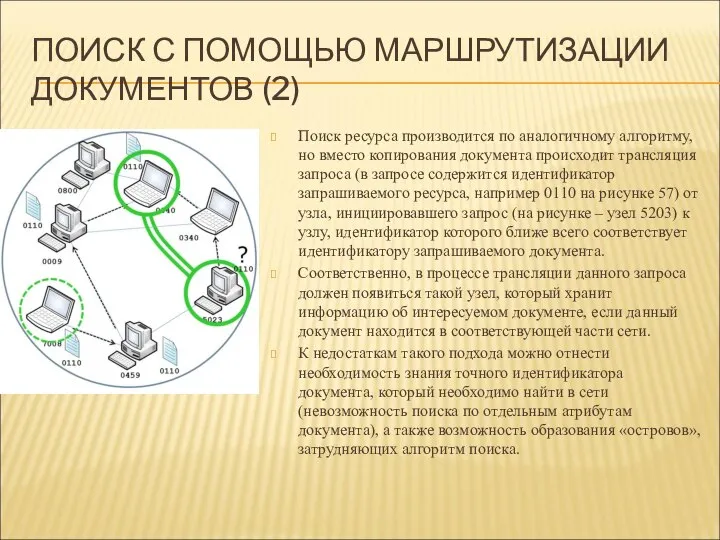
ПОИСК С ПОМОЩЬЮ МАРШРУТИЗАЦИИ ДОКУМЕНТОВ (2)
Поиск ресурса производится по аналогичному алгоритму,
ПОИСК С ПОМОЩЬЮ МАРШРУТИЗАЦИИ ДОКУМЕНТОВ (2)
Поиск ресурса производится по аналогичному алгоритму,

НЕСТРУКТУРИРОВАННЫЕ P2P СИСТЕМЫ
Они не имеют определенной топологии.
Каждый узел в такой системе
НЕСТРУКТУРИРОВАННЫЕ P2P СИСТЕМЫ
Они не имеют определенной топологии.
Каждый узел в такой системе

МЕТОД ЗАТОПЛЕНИЯ
Узел u посылает запросы ко всем известным ему соседям.
Если
МЕТОД ЗАТОПЛЕНИЯ
Узел u посылает запросы ко всем известным ему соседям.
Если

МЕТОД СЛУЧАЙНОГО БЛУЖДАНИЯ
Узел u просто опрашивает соседей выбирая их случайным образом.
МЕТОД СЛУЧАЙНОГО БЛУЖДАНИЯ
Узел u просто опрашивает соседей выбирая их случайным образом.

МЕТОД ПОИСКА ОСНОВАННЫЙ НА ПОЛИТИКЕ
Этот метод занимает промежуточное положение между методами
МЕТОД ПОИСКА ОСНОВАННЫЙ НА ПОЛИТИКЕ
Этот метод занимает промежуточное положение между методами

ИЕРАРХИЧЕСКИ ОРГАНИЗОВАННЫЕ Р2Р СИСТЕМЫ
В не структурированных системах по мере их роста
ИЕРАРХИЧЕСКИ ОРГАНИЗОВАННЫЕ Р2Р СИСТЕМЫ
В не структурированных системах по мере их роста
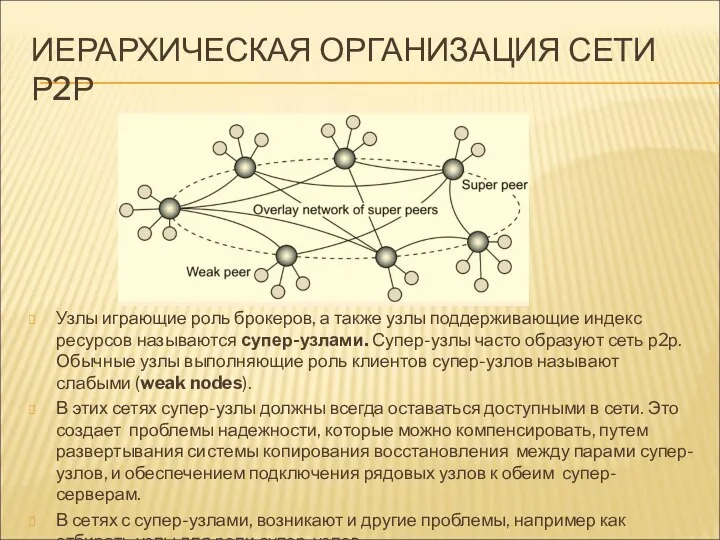
ИЕРАРХИЧЕСКАЯ ОРГАНИЗАЦИЯ СЕТИ Р2Р
Узлы играющие роль брокеров, а также узлы поддерживающие
ИЕРАРХИЧЕСКАЯ ОРГАНИЗАЦИЯ СЕТИ Р2Р
Узлы играющие роль брокеров, а также узлы поддерживающие

ИЕРАРХИЧЕСКАЯ Р2Р СИСТЕМА.
ПРИМЕР: SKYPE
Самой популярной на сегодняшний день службой Интернет-телефонии
ИЕРАРХИЧЕСКАЯ Р2Р СИСТЕМА.
ПРИМЕР: SKYPE
Самой популярной на сегодняшний день службой Интернет-телефонии

ГИБРИДНЫЕ АРХИТЕКТУРЫ Р2Р СИСТЕМ
ГИБРИДНЫЕ АРХИТЕКТУРЫ Р2Р СИСТЕМ

ГИБРИДНЫЕ АРХИТЕКТУРЫ Р2Р
Существует множество архитектур РС в которых успешно сочетаются архитектуры
ГИБРИДНЫЕ АРХИТЕКТУРЫ Р2Р
Существует множество архитектур РС в которых успешно сочетаются архитектуры
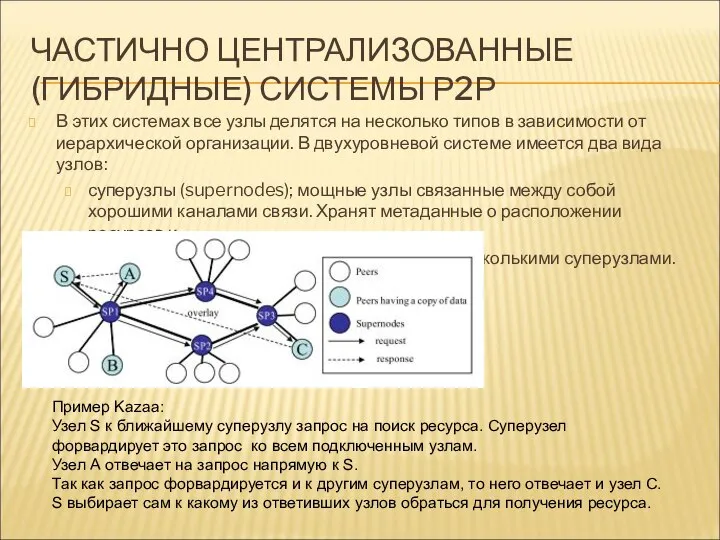
ЧАСТИЧНО ЦЕНТРАЛИЗОВАННЫЕ (ГИБРИДНЫЕ) СИСТЕМЫ Р2Р
В этих системах все узлы делятся на
ЧАСТИЧНО ЦЕНТРАЛИЗОВАННЫЕ (ГИБРИДНЫЕ) СИСТЕМЫ Р2Р
В этих системах все узлы делятся на
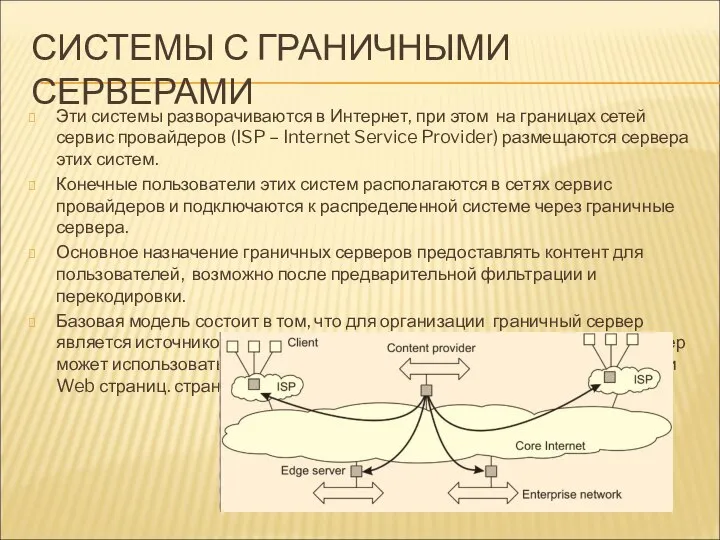
СИСТЕМЫ С ГРАНИЧНЫМИ СЕРВЕРАМИ
Эти системы разворачиваются в Интернет, при этом на
СИСТЕМЫ С ГРАНИЧНЫМИ СЕРВЕРАМИ
Эти системы разворачиваются в Интернет, при этом на
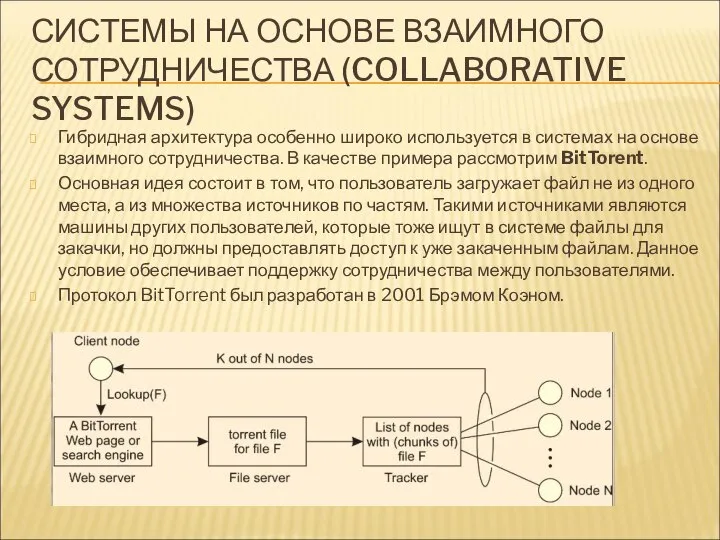
СИСТЕМЫ НА ОСНОВЕ ВЗАИМНОГО СОТРУДНИЧЕСТВА (COLLABORATIVE SYSTEMS)
Гибридная архитектура особенно широко используется
СИСТЕМЫ НА ОСНОВЕ ВЗАИМНОГО СОТРУДНИЧЕСТВА (COLLABORATIVE SYSTEMS)
Гибридная архитектура особенно широко используется

BITTORRENT
Если узел хочет опубликовать файл или набор файлов, то программа- клиент
BITTORRENT
Если узел хочет опубликовать файл или набор файлов, то программа- клиент

ПРИМЕНЕНИЕ СИСТЕМ P2P
Наибольшее распространение пиринговые системы получили при реализации сиситем предназначенных
ПРИМЕНЕНИЕ СИСТЕМ P2P
Наибольшее распространение пиринговые системы получили при реализации сиситем предназначенных

ДОСТОИНСТВА P2P СИСТЕМ
Можно выделить следующие основные преимущества пиринговых систем:
высокая масштабируемость, связанная
ДОСТОИНСТВА P2P СИСТЕМ
Можно выделить следующие основные преимущества пиринговых систем:
высокая масштабируемость, связанная
 Тестирование. По урок 15. Интеграционное тестирование
Тестирование. По урок 15. Интеграционное тестирование Особенности оформления письма-запроса как вида информационно-справочной документации
Особенности оформления письма-запроса как вида информационно-справочной документации Система электронного документооборота
Система электронного документооборота Исключения. Методы обработки исключений
Исключения. Методы обработки исключений Нормальная форма БД
Нормальная форма БД Виды компьютерных вирусов Подготовила: Жигалова Катя Проверила: Выпрева Вера Владимировна
Виды компьютерных вирусов Подготовила: Жигалова Катя Проверила: Выпрева Вера Владимировна Моделирование и оптимизация процессов и систем сервиса
Моделирование и оптимизация процессов и систем сервиса Методы оптимальных решений
Методы оптимальных решений Организация сети NGN/IMS микрорайона г. Новогрудок
Организация сети NGN/IMS микрорайона г. Новогрудок Конкурентная разведка. Разведывательный цикл (тема 2.1)
Конкурентная разведка. Разведывательный цикл (тема 2.1) Основные понятия Баз данных. Система управления базами данных Mіcrosoft Access и ее основные возможности
Основные понятия Баз данных. Система управления базами данных Mіcrosoft Access и ее основные возможности Принцип работы сред программирования. Интерпретаторы и компиляторы
Принцип работы сред программирования. Интерпретаторы и компиляторы Тест по информатике (3 класс)
Тест по информатике (3 класс) Массивы
Массивы Знакомство со средой программирования Раsсаl. Стандартные математические функции
Знакомство со средой программирования Раsсаl. Стандартные математические функции Тестирование программного обеспечения (Часть 1)
Тестирование программного обеспечения (Часть 1) Киберспорт, как массовая культура
Киберспорт, как массовая культура Презентация "Базы данных 7" - скачать презентации по Информатике
Презентация "Базы данных 7" - скачать презентации по Информатике Компьютерная графика 08/09/15
Компьютерная графика 08/09/15  Hegel and dialectics doing in software engineering
Hegel and dialectics doing in software engineering Алгоритм это выполнения команд последовательность
Алгоритм это выполнения команд последовательность АНГЛОЯЗЫЧНЫЙ ИНТЕРНЕТ Халина Евгения, Фасолько Светлана МОУ СОШ №12 Им. Сметанкина В. Н. 9 «А» класс г. Находка 2009г. Руководител
АНГЛОЯЗЫЧНЫЙ ИНТЕРНЕТ Халина Евгения, Фасолько Светлана МОУ СОШ №12 Им. Сметанкина В. Н. 9 «А» класс г. Находка 2009г. Руководител Понятие Интернет
Понятие Интернет Обеспечение безопасности информации в современных информационных системах (тема № 9)
Обеспечение безопасности информации в современных информационных системах (тема № 9) Информационные системы и основы баз данных. Лекция 5
Информационные системы и основы баз данных. Лекция 5 тема 1.1 - информационные системы
тема 1.1 - информационные системы Вирусы
Вирусы Урок №3. Формы представления данных (таблицы, формы, запросы, отчеты)
Урок №3. Формы представления данных (таблицы, формы, запросы, отчеты)