- Big Data

Содержание
- 2. Предпосылки появления Big Data 1 Аналитика данных является основным инструментом поиска новых знаний в массивах данных,
- 3. Источники Big Data Торговые сети Торговые сети регистрируют миллионы клиентских транзакций, пересылают их в хранилища данных,
- 4. Характеристики категории Big Data: 1) Volume — объем данных должен превышать 150 Гб в сутки. 2)
- 5. Пирамида аналитических решений Журнал ПЛАС. Технологии. А.Ю. Медников. Большие Данные и бизнес аналитика (plusworld.ru)
- 6. Термин «анализ данных» Анализ данных – широкое понятие. В общем смысле – это процесс: исследования, преобразования
- 7. Современное понятие анализа данных Концепция «модели от данных» требует тщательной подготовки данных – качество данных Современная
- 9. Аналитическая пирамида (Analytical stack), предложенная компанией Gartner
- 10. Данные, описывающие реальные объекты могут быть представлены в различных формах, измерены в различных шкалах и иметь
- 12. По характеру варьирования переменные делятся на: Дискретные данные являются значениями признака. С дискретными данными не могут
- 13. Непрерывные данные — это данные, которые могут принимать любые значения в некотором интервале. Над непрерывными данными
- 16. Особенности бизнес-данных, накопленных в компаниях
- 18. Методы сбора Получение из учетных систем: несложная операция, обычно учетные системы имеют развитые методы импорта/экспорта. Получение
- 21. Инструменты аналитики данных Статистические пакеты – хорошая математическая подготовка пользователей; проблемы больших объемов данных; необходимость использования
- 22. Направления развития вычислительной инфраструктуры компании Вертикальное масштабирование Приобретение более мощного компьютера, то есть добавление ресурсов на
- 23. Большие данные используют технологии распределенных вычислений: вычислительная нагрузка распределяется между некоторым количеством компьютеров-клиентов, которые работают под
- 24. MapReduce – модель распределенных вычислений, разработанная компанией Google, которая используется для параллельных вычислений над очень большими
- 25. После того, как мастер-узел получает от остальных машин сообщение о том, что обработка данных ими закончена
- 26. Hadoop – проект фонда Apache Software Foundation, свободно распространяемый набор утилит, библиотек и программный каркас для
- 27. Роль и место Big Data в аналитике данных Технологии Knowledge Discovery и Data Mining решают задачи
- 28. Для создания моделей Data Mining необходимы структурированные данные, но Big Data оперирует петабайтами данных неопределенной структуры.
- 30. Скачать презентацию

Предпосылки появления Big Data
1 Аналитика данных является основным инструментом поиска новых
Предпосылки появления Big Data
1 Аналитика данных является основным инструментом поиска новых

Источники Big Data
Торговые сети
Торговые сети регистрируют миллионы клиентских транзакций, пересылают их
Источники Big Data
Торговые сети
Торговые сети регистрируют миллионы клиентских транзакций, пересылают их

Характеристики категории Big Data:
1) Volume — объем данных должен превышать 150
Характеристики категории Big Data:
1) Volume — объем данных должен превышать 150

Пирамида аналитических решений
Журнал ПЛАС. Технологии. А.Ю. Медников. Большие Данные и бизнес
Пирамида аналитических решений
Журнал ПЛАС. Технологии. А.Ю. Медников. Большие Данные и бизнес

Термин «анализ данных»
Анализ данных – широкое понятие. В общем смысле –
Термин «анализ данных»
Анализ данных – широкое понятие. В общем смысле –

Современное понятие анализа данных
Концепция «модели от данных» требует тщательной подготовки данных
Современное понятие анализа данных
Концепция «модели от данных» требует тщательной подготовки данных


Аналитическая пирамида (Analytical stack), предложенная компанией Gartner
Аналитическая пирамида (Analytical stack), предложенная компанией Gartner

Данные, описывающие реальные объекты могут быть представлены в различных формах, измерены
Данные, описывающие реальные объекты могут быть представлены в различных формах, измерены


По характеру варьирования переменные делятся на:
Дискретные данные являются значениями признака.
По характеру варьирования переменные делятся на:
Дискретные данные являются значениями признака.

Непрерывные данные — это данные, которые могут принимать
любые значения в
Непрерывные данные — это данные, которые могут принимать
любые значения в
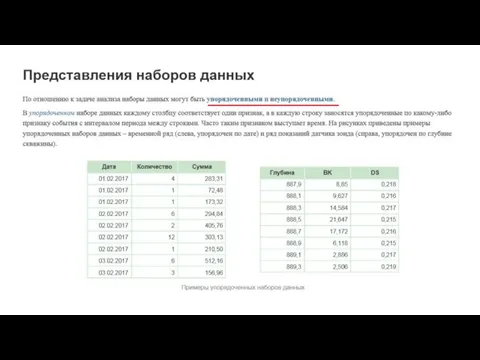
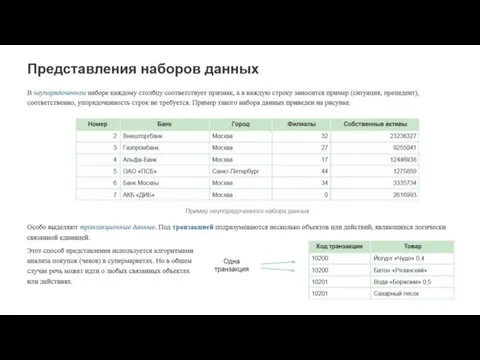

Особенности бизнес-данных, накопленных в компаниях
Особенности бизнес-данных, накопленных в компаниях


Методы сбора
Получение из учетных систем: несложная операция, обычно учетные системы имеют
Методы сбора
Получение из учетных систем: несложная операция, обычно учетные системы имеют
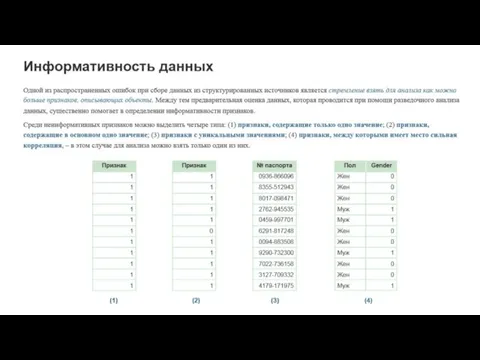
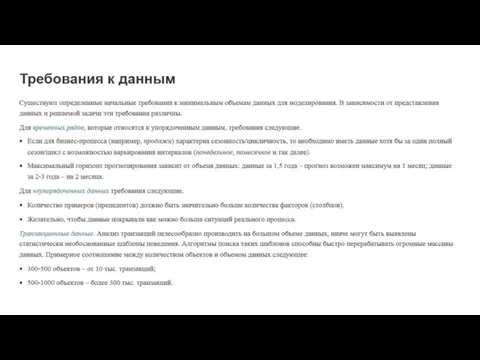

Инструменты аналитики данных
Статистические пакеты – хорошая математическая подготовка пользователей; проблемы больших
Инструменты аналитики данных
Статистические пакеты – хорошая математическая подготовка пользователей; проблемы больших

Направления развития вычислительной инфраструктуры компании
Вертикальное масштабирование
Приобретение более мощного компьютера, то есть
Направления развития вычислительной инфраструктуры компании
Вертикальное масштабирование
Приобретение более мощного компьютера, то есть
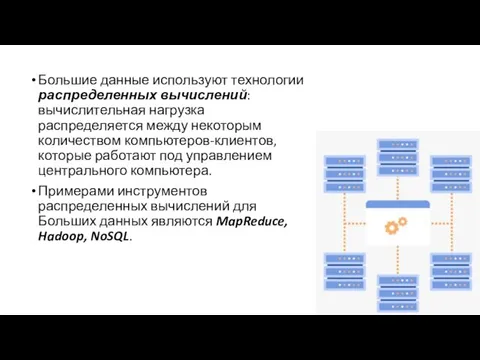
Большие данные используют технологии распределенных вычислений: вычислительная нагрузка распределяется между некоторым
Большие данные используют технологии распределенных вычислений: вычислительная нагрузка распределяется между некоторым

MapReduce – модель распределенных вычислений, разработанная компанией Google, которая используется для
MapReduce – модель распределенных вычислений, разработанная компанией Google, которая используется для

После того, как мастер-узел получает от остальных машин сообщение о том,
После того, как мастер-узел получает от остальных машин сообщение о том,

Hadoop – проект фонда Apache Software Foundation, свободно распространяемый набор утилит,
Hadoop – проект фонда Apache Software Foundation, свободно распространяемый набор утилит,
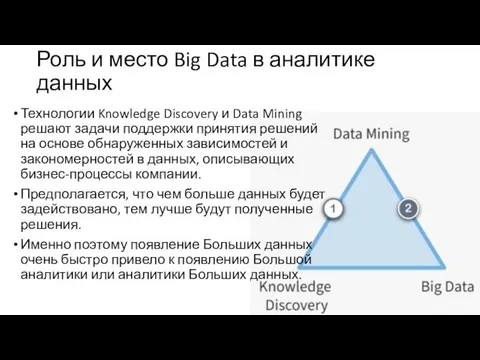
Роль и место Big Data в аналитике данных
Технологии Knowledge Discovery и
Роль и место Big Data в аналитике данных
Технологии Knowledge Discovery и

Для создания моделей Data Mining необходимы структурированные данные, но Big Data
Для создания моделей Data Mining необходимы структурированные данные, но Big Data
 Библиотечный фонд
Библиотечный фонд Разработка и реализация автоматизированной подсистемы документооборота деканата
Разработка и реализация автоматизированной подсистемы документооборота деканата Адресация в инфокоммуникационных сетях. Модель межсетевого взаимодействия – модель OSI. Промышленные сетевые
Адресация в инфокоммуникационных сетях. Модель межсетевого взаимодействия – модель OSI. Промышленные сетевые Презентация "Внешняя память компьютера" - скачать презентации по Информатике
Презентация "Внешняя память компьютера" - скачать презентации по Информатике Онлайн-обучение «Ирландия» Пример программы онлайн-обучения в туризме
Онлайн-обучение «Ирландия» Пример программы онлайн-обучения в туризме Введение в курс информатики
Введение в курс информатики Безопасный интернет
Безопасный интернет Огляд середовища VISUAL STUDIO та способи створення проектів
Огляд середовища VISUAL STUDIO та способи створення проектів Основы HTML. Разработка Web-сайта
Основы HTML. Разработка Web-сайта Компьютерные технологии мониторинга и управления разработкой нефтяных месторождений. (Лкция 16)
Компьютерные технологии мониторинга и управления разработкой нефтяных месторождений. (Лкция 16) Фотошоп. Цвет и управление цветовым пространством
Фотошоп. Цвет и управление цветовым пространством Лазерные принтеры
Лазерные принтеры Разновидности объектов и их классификация
Разновидности объектов и их классификация Лекция 2 Delphi
Лекция 2 Delphi  Презентация по информатике На тему: компьютерная мышь
Презентация по информатике На тему: компьютерная мышь Методы и технологии конструирования изделий. Инженерный анализ методом конечных элементов. (Лекция 6)
Методы и технологии конструирования изделий. Инженерный анализ методом конечных элементов. (Лекция 6) Создание шаблонов оформления презентаций Автор презентации – Караваева Е.Л.
Создание шаблонов оформления презентаций Автор презентации – Караваева Е.Л. Аттестационная работа. Методическая разработка по выполнению индивидуального проекта по информатике
Аттестационная работа. Методическая разработка по выполнению индивидуального проекта по информатике Феєрверки. Виконання алгоритмів
Феєрверки. Виконання алгоритмів Внешняя память ПК
Внешняя память ПК Построение модели управленческого учета.
Построение модели управленческого учета. Построение графиков и диаграмм
Построение графиков и диаграмм Протоколы и стеки протоколов
Протоколы и стеки протоколов Инструментальные средства разработки программ
Инструментальные средства разработки программ Текстовый язык автоматного программирования В. С. Гуров, М. А. Мазин, А. А. Шалыто
Текстовый язык автоматного программирования В. С. Гуров, М. А. Мазин, А. А. Шалыто Математические методы в программировании (ММвП)
Математические методы в программировании (ММвП) Информационные процессы в жизнедеятельности общества
Информационные процессы в жизнедеятельности общества Программирование. Подготовка к ЕГЭ. Часть 2
Программирование. Подготовка к ЕГЭ. Часть 2