- Биометрия. Метод Viola Jones

Содержание
- 2. Метод Viola Jones используются изображения в интегральном представлении, что позволяет вычислять быстро необходимые объекты; используются признаки
- 3. https://habrahabr.ru/post/135244/ https://habrahabr.ru/post/134857/ https://habrahabr.ru/post/133909/ https://habrahabr.ru/post/133826/
- 4. Метод Viola Jones. Основные принципы используются изображения в интегральном представлении, что позволяет вычислять быстро необходимые объекты;
- 5. Краткий алгоритм имеется изображение, на котором есть искомые объекты. Оно представлено двумерной матрицей пикселей размером w*h,
- 6. Интегральное представление изображений вейвлет-преобразования SURF SIFT рассчитывать суммарную яркость произвольного прямоугольника на изображении, причем какой бы
- 7. где I(i,j) — яркость пикселя исходного изображения. Каждый элемент матрицы L[x,y] представляет собой сумму пикселей в
- 8. S(ABCD) = L(A) + L(С) — L(B) — L(D)
- 9. Пример расчета
- 10. Признаки Хаара Признак— отображениеf: X => Df, где Df— множество допустимых значений признака. Если заданы признакиf1,…,fn,
- 11. типы в зависимости Признаки делятся на следующие типы в зависимости от множества Df: бинарный признак, Df
- 12. В стандартном методе Виолы – Джонса Вычисляемым значением такого признака будет F = X-Y, где X
- 13. В расширенном методе Виолы – Джонса
- 14. Сканирование окна есть исследуемое изображение, выбрано окно сканирования, выбраны используемые признаки; далее окно сканирования начинает последовательно
- 16. Используемая в алгоритме модель машинного обучения «Машинное обучение — это наука, изучающая компьютерные алгоритмы, автоматически улучшающиеся
- 17. Обучение классификатора в методе Виолы-Джонса Классифицировать объект — значит, указать номер (или наименование класса), к которому
- 18. Постановка классификации Есть X – множество, в котором хранится описание объектов, Y – конечное множество номеров,
- 19. Бустинг и разработка AdaBoost Бустинг — комплекс методов, способствующих повышению точности аналитических моделей. Эффективная модель, допускающая
- 20. Идея бустинга Роберт Шапир (Schapire) в конце 90-х годов построение цепочки (ансамбля) классификаторов, который называется каскадом,
- 21. Математическое объяснение Наряду с множествами X и Y вводится вспомогательное множество R, называемое пространством оценок. Рассматриваются
- 22. Структура алгоритмов классификации вычисляются оценки принадлежности объекта классам, решающее правило переводит эти оценки в номер класса.
- 23. Алгоритмическая композиция алгоритм a: X → Y вида a(x) = C(F(b1(x), . . . , bT
- 24. совместное применение нескольких критериев построено заданное количество базовых алгоритмов T; достигнута заданная точность на обучающей выборке;
- 25. AdaBoost (adaptive boosting – адаптированное улучшение) Йоав Фройнд (Freund) и Роберт Шапир (Schapire) в 1999, может
- 26. задача классификации на два класса, Y = {−1,+1}. К примеру, базовые алгоритмы также возвращают только два
- 27. Дано: Y = {−1,+1}, b1(x), . . . , bT (x) возвращают −1 и + 1,
- 28. непосредственно перед настройкой базового алгоритма наибольший вес накапливается у тех объектов, которые чаще оказывались трудными для
- 30. Плюсы AdaBoost хорошая обобщающая способность. В реальных задачах практически всегда строятся композиции, превосходящие по качеству базовые
- 31. Минусы AdaBoost: Бывает переобучение при наличии значительного уровня шума в данных. Экспоненциальная функция потерь слишком сильно
- 32. Принципы решающего дерева в алгоритме function Node = Обучение_Вершины( {(x,y)} ) { if {y} одинаковые return
- 33. Каскадная модель алгоритма Алгоритм бустинга для поиска лиц с моей точки зрения таков: 1. Определение слабых
- 34. Сложность обучения таких каскадов равна О(xyz), где применяется x этапов, y примеров и z признаков. Далее,
- 35. Для тренировки такого каскада потребуются следующие действия: 1. Задаются значения уровня ошибок для каждого этапа (предварительно
- 36. В более формальном виде алгоритм тренировки каскада: a) Пользователь задает значения f (максимально допустимый уровень ложных
- 37. 1. P. Viola and M.J. Jones, «Rapid Object Detection using a Boosted Cascade of Simple Features»,
- 38. https://habrahabr.ru/post/133909/
- 39. Улучшение контрастности между фоном и кровеносными сосудами G Выбор цветового канала
- 40. контрастно-ограниченное адаптивное выравнивание гистограммы (contrast limited adaptive histogram equalization – clahe)
- 41. Удаление фона при помощи average фильтра Маска сетчатки
- 42. автоматическое пороговое преобразование методом Otsu, медианный фильтр и фильтр по длине
- 43. Фильтр Габора Способен выделять прямые линии определённого размера и под определённым углом
- 44. применить фильтр Габора с различными углами наклона ядра рассчитать максимальный отклик каждого пикселя на серию фильтров
- 45. Удаление фона слева – исходное изображение, полученное при помощи алгоритма background exclusion, справа – результат применения
- 46. Пороговое преобразование интенсивности изображения слева – исходное изображение, полученное после перекрашивания пикселей в соответствии с параметром
- 47. Marwan D. Saleh, C. Eswaran, and Ahmed Mueen. An Automated Blood Vessel Segmentation Algorithm Using Histogram
- 48. Результат движения головы и глаза при сканировании сетчатки
- 49. Алгоритм, основанный на методе фазовой корреляции
- 50. Алгоритм, использующий углы Харриса
- 51. Алгоритм, основанный на поиске точек разветвления
- 52. Reddy B.S. and Chatterji B.N. An FFT-Based Technique for Translation, Rotation, and Scale-Invariant Image Registration //
- 53. Геометрия рук
- 54. Движения глаз фиксация глаза на определенной точке дисплея момент движения яблока при перемещении взгляда с одной
- 55. Neurotechnology http://www.neurotechnology.com/
- 56. Поведенческая биометрия
- 57. Биометрия по электрокардиограмме
- 58. Биометрия по почерку
- 59. Биометрия по походке
- 60. Биометрия по особенностям чтения
- 61. Биометрия по особенностям набора текста
- 62. Идентификация личности на основе данных о перемещениях (трекинга)
- 64. Скачать презентацию

Метод Viola Jones
используются изображения в интегральном представлении, что позволяет вычислять быстро
Метод Viola Jones
используются изображения в интегральном представлении, что позволяет вычислять быстро

https://habrahabr.ru/post/135244/
https://habrahabr.ru/post/134857/
https://habrahabr.ru/post/133909/
https://habrahabr.ru/post/133826/
https://habrahabr.ru/post/135244/
https://habrahabr.ru/post/134857/
https://habrahabr.ru/post/133909/
https://habrahabr.ru/post/133826/

Метод Viola Jones. Основные принципы
используются изображения в интегральном представлении, что позволяет
Метод Viola Jones. Основные принципы
используются изображения в интегральном представлении, что позволяет

Краткий алгоритм
имеется изображение, на котором есть искомые объекты. Оно представлено двумерной матрицей пикселей размером
Краткий алгоритм
имеется изображение, на котором есть искомые объекты. Оно представлено двумерной матрицей пикселей размером

Интегральное представление изображений
вейвлет-преобразования
SURF
SIFT
рассчитывать суммарную яркость произвольного прямоугольника на изображении, причем какой
Интегральное представление изображений
вейвлет-преобразования
SURF
SIFT
рассчитывать суммарную яркость произвольного прямоугольника на изображении, причем какой
![где I(i,j) — яркость пикселя исходного изображения. Каждый элемент матрицы L[x,y]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/545625/slide-6.jpg)
где I(i,j) — яркость пикселя исходного изображения.
Каждый элемент матрицы L[x,y] представляет

S(ABCD) = L(A) + L(С) — L(B) — L(D)
S(ABCD) = L(A) + L(С) — L(B) — L(D)

Пример расчета
Пример расчета

Признаки Хаара
Признак— отображениеf: X => Df, где Df— множество допустимых значений признака.
Если
Признаки Хаара
Признак— отображениеf: X => Df, где Df— множество допустимых значений признака.
Если

типы в зависимости
Признаки делятся на следующие типы в зависимости от множества Df:
бинарный
типы в зависимости
Признаки делятся на следующие типы в зависимости от множества Df:
бинарный

В стандартном методе Виолы – Джонса
Вычисляемым значением такого признака будет
F =
В стандартном методе Виолы – Джонса
Вычисляемым значением такого признака будет F =

В расширенном методе Виолы – Джонса
В расширенном методе Виолы – Джонса

Сканирование окна
есть исследуемое изображение, выбрано окно сканирования, выбраны используемые признаки;
далее окно
Сканирование окна
есть исследуемое изображение, выбрано окно сканирования, выбраны используемые признаки;
далее окно


Используемая в алгоритме модель машинного обучения
«Машинное обучение — это наука, изучающая
Используемая в алгоритме модель машинного обучения
«Машинное обучение — это наука, изучающая

Обучение классификатора в методе Виолы-Джонса
Классифицировать объект — значит, указать номер (или наименование
Обучение классификатора в методе Виолы-Джонса
Классифицировать объект — значит, указать номер (или наименование

Постановка классификации
Есть X – множество, в котором хранится описание объектов,
Y –
Постановка классификации
Есть X – множество, в котором хранится описание объектов,
Y –

Бустинг и разработка AdaBoost
Бустинг — комплекс методов, способствующих повышению точности аналитических
Бустинг и разработка AdaBoost
Бустинг — комплекс методов, способствующих повышению точности аналитических

Идея бустинга
Роберт Шапир (Schapire) в конце 90-х годов
построение цепочки (ансамбля) классификаторов, который называется каскадом,
Идея бустинга
Роберт Шапир (Schapire) в конце 90-х годов
построение цепочки (ансамбля) классификаторов, который называется каскадом,

Математическое объяснение
Наряду с множествами
X и Y
вводится вспомогательное множество R,
Математическое объяснение
Наряду с множествами
X и Y
вводится вспомогательное множество R,

Структура алгоритмов классификации
вычисляются оценки принадлежности объекта классам,
решающее правило переводит эти
Структура алгоритмов классификации
вычисляются оценки принадлежности объекта классам,
решающее правило переводит эти

Алгоритмическая композиция
алгоритм a: X → Y вида
a(x) = C(F(b1(x), . .
Алгоритмическая композиция
алгоритм a: X → Y вида a(x) = C(F(b1(x), . .

совместное применение нескольких критериев
построено заданное количество базовых алгоритмов T;
достигнута заданная точность
совместное применение нескольких критериев
построено заданное количество базовых алгоритмов T;
достигнута заданная точность

AdaBoost (adaptive boosting – адаптированное улучшение)
Йоав Фройнд (Freund) и Роберт Шапир (Schapire) в
AdaBoost (adaptive boosting – адаптированное улучшение)
Йоав Фройнд (Freund) и Роберт Шапир (Schapire) в

задача классификации на два класса, Y = {−1,+1}. К примеру, базовые
задача классификации на два класса, Y = {−1,+1}. К примеру, базовые

Дано:
Y = {−1,+1},
b1(x), . . . , bT (x) возвращают −1 и
Дано:
Y = {−1,+1},
b1(x), . . . , bT (x) возвращают −1 и

непосредственно перед настройкой базового алгоритма наибольший вес накапливается у тех объектов,
непосредственно перед настройкой базового алгоритма наибольший вес накапливается у тех объектов,


Плюсы AdaBoost
хорошая обобщающая способность. В реальных задачах практически всегда строятся композиции,
Плюсы AdaBoost
хорошая обобщающая способность. В реальных задачах практически всегда строятся композиции,

Минусы AdaBoost:
Бывает переобучение при наличии значительного уровня шума в данных. Экспоненциальная
Минусы AdaBoost:
Бывает переобучение при наличии значительного уровня шума в данных. Экспоненциальная

Принципы решающего дерева в алгоритме
function Node = Обучение_Вершины( {(x,y)} ) {
if
Принципы решающего дерева в алгоритме
function Node = Обучение_Вершины( {(x,y)} ) { if

Каскадная модель алгоритма
Алгоритм бустинга для поиска лиц с моей точки зрения
Каскадная модель алгоритма
Алгоритм бустинга для поиска лиц с моей точки зрения

Сложность обучения таких каскадов равна О(xyz), где применяется x этапов, y
Сложность обучения таких каскадов равна О(xyz), где применяется x этапов, y

Для тренировки такого каскада потребуются следующие действия:
1. Задаются значения уровня ошибок
Для тренировки такого каскада потребуются следующие действия: 1. Задаются значения уровня ошибок

В более формальном виде алгоритм тренировки каскада:
a) Пользователь задает значения f (максимально допустимый
В более формальном виде алгоритм тренировки каскада: a) Пользователь задает значения f (максимально допустимый

1. P. Viola and M.J. Jones, «Rapid Object Detection using a
1. P. Viola and M.J. Jones, «Rapid Object Detection using a

https://habrahabr.ru/post/133909/
https://habrahabr.ru/post/133909/

Улучшение контрастности между фоном и кровеносными сосудами
G
Выбор цветового канала
Улучшение контрастности между фоном и кровеносными сосудами
G
Выбор цветового канала

контрастно-ограниченное адаптивное выравнивание гистограммы
(contrast limited adaptive histogram equalization – clahe)
контрастно-ограниченное адаптивное выравнивание гистограммы
(contrast limited adaptive histogram equalization – clahe)

Удаление фона при помощи average фильтра
Маска сетчатки
Удаление фона при помощи average фильтра
Маска сетчатки

автоматическое пороговое преобразование методом Otsu, медианный фильтр и фильтр по длине
автоматическое пороговое преобразование методом Otsu, медианный фильтр и фильтр по длине

Фильтр Габора
Способен выделять прямые линии определённого размера и под определённым углом
Фильтр Габора
Способен выделять прямые линии определённого размера и под определённым углом
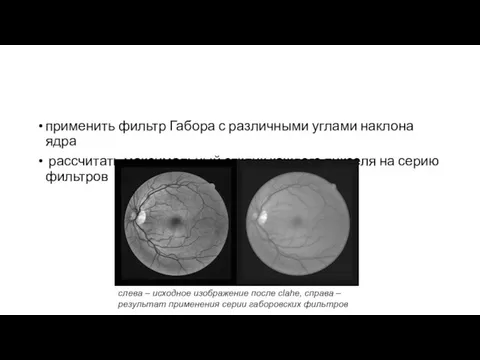
применить фильтр Габора с различными углами наклона ядра
рассчитать максимальный
применить фильтр Габора с различными углами наклона ядра
рассчитать максимальный

Удаление фона
слева – исходное изображение, полученное при помощи алгоритма background exclusion,
Удаление фона
слева – исходное изображение, полученное при помощи алгоритма background exclusion,

Пороговое преобразование интенсивности изображения
слева – исходное изображение, полученное после перекрашивания пикселей
Пороговое преобразование интенсивности изображения
слева – исходное изображение, полученное после перекрашивания пикселей

Marwan D. Saleh, C. Eswaran, and Ahmed Mueen. An Automated Blood
Marwan D. Saleh, C. Eswaran, and Ahmed Mueen. An Automated Blood
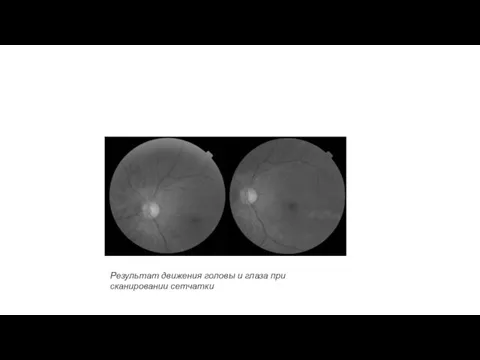
Результат движения головы и глаза при сканировании сетчатки
Результат движения головы и глаза при сканировании сетчатки

Алгоритм, основанный на методе фазовой корреляции
Алгоритм, основанный на методе фазовой корреляции

Алгоритм, использующий углы Харриса
Алгоритм, использующий углы Харриса

Алгоритм, основанный на поиске точек разветвления
Алгоритм, основанный на поиске точек разветвления

Reddy B.S. and Chatterji B.N. An FFT-Based Technique for Translation, Rotation,
Reddy B.S. and Chatterji B.N. An FFT-Based Technique for Translation, Rotation,

Геометрия рук
Геометрия рук

Движения глаз
фиксация глаза на определенной точке дисплея
момент движения яблока при
Движения глаз
фиксация глаза на определенной точке дисплея
момент движения яблока при
Neurotechnology
http://www.neurotechnology.com/
Neurotechnology
http://www.neurotechnology.com/

Поведенческая биометрия
Поведенческая биометрия

Биометрия по электрокардиограмме
Биометрия по электрокардиограмме

Биометрия по почерку
Биометрия по почерку

Биометрия по походке
Биометрия по походке

Биометрия по особенностям чтения
Биометрия по особенностям чтения

Биометрия по особенностям набора текста
Биометрия по особенностям набора текста

Идентификация личности на основе данных о перемещениях (трекинга)
Идентификация личности на основе данных о перемещениях (трекинга)
 Реляционные базы данных
Реляционные базы данных Обучение с применением дистанционных образовательных технологий
Обучение с применением дистанционных образовательных технологий Лінійний спосіб стиснення
Лінійний спосіб стиснення Проектирование и реализация защиты служб доступа к сети
Проектирование и реализация защиты служб доступа к сети Проект приложения: Повседневный помощник
Проект приложения: Повседневный помощник Популяризация детской игры среди детей и взрослых
Популяризация детской игры среди детей и взрослых Создание таблицы для ведения bounty
Создание таблицы для ведения bounty Эволючия ЭВМ
Эволючия ЭВМ Структурный подход проектирования ПО
Структурный подход проектирования ПО Технические и программные средства реализации информационных процессов
Технические и программные средства реализации информационных процессов Синхронизация обмена данными
Синхронизация обмена данными Корейские игры
Корейские игры Платформа. NET. Работа с методами. ООП в C #. Делегаты и события. Windows Forms. Элементы управления и их создание
Платформа. NET. Работа с методами. ООП в C #. Делегаты и события. Windows Forms. Элементы управления и их создание Операционные системы, среды и оболочки. Понятие операционной системы. Основные функции ОС
Операционные системы, среды и оболочки. Понятие операционной системы. Основные функции ОС У світі інформації
У світі інформації Всемирная Паутина. Что такое WWW (Информатика 7 Урок 3)
Всемирная Паутина. Что такое WWW (Информатика 7 Урок 3) Знакомство с электронными таблицами Microsoft Excel
Знакомство с электронными таблицами Microsoft Excel NeoTech Команда по сетевому и системному администрированию
NeoTech Команда по сетевому и системному администрированию Обзор оборудования и программного обеспечения АВВ
Обзор оборудования и программного обеспечения АВВ Сергей Брин: История успеха
Сергей Брин: История успеха АЛГОРИТМЫ
АЛГОРИТМЫ Профессия программист
Профессия программист Язык программирования C. Лекции
Язык программирования C. Лекции Аттестационная работа. Проектная деятельность в рамках изучения курса технологии Сайтостроение
Аттестационная работа. Проектная деятельность в рамках изучения курса технологии Сайтостроение Инструкция по работе в электронной образовательной среде
Инструкция по работе в электронной образовательной среде Создание базы данных персонала Арселормиттал Кривой Рог
Создание базы данных персонала Арселормиттал Кривой Рог Типи даних. Лекція 1-3
Типи даних. Лекція 1-3 Введение в базы данных
Введение в базы данных