- Хеширование. Виды хеш-функций

Содержание
- 2. Ключевые термины Хеширование – это специальный метод адресации данных для быстрого поиска нужной информации по ключам.
- 3. Ключевые термины Повторное хеширование – это поиск местоположения для очередного элемента таблицы с учетом шага перемещения.
- 4. 4
- 5. Функция, отображающая ключи элементов данных во множество целых чисел (индексы в таблице – хеш-таблица), называется функцией
- 6. Метод деления Исходными данными являются – некоторый целый ключ key и размер таблицы m. Результатом данной
- 7. Для m = 100 хеш-функция возвращает две младшие цифры ключа. 7
- 8. Аддитивный метод в котором ключом является символьная строка. В хеш-функции строка преобразуется в целое суммированием всех
- 9. Данный метод можно несколько модифицировать, получая результат, суммируя только первый и последний символы строки-ключа. int h(char
- 10. Метод середины квадрата в котором ключ возводится в квадрат (умножается сам на себя) и в качестве
- 11. Мультипликативный метод В мультипликативном методе дополнительно используется случайное действительное число r из интервала [0,1), тогда дробная
- 12. Две классические схемы – хеширование методом цепочек (со списками), или так называемое многомерное хеширование – chaining
- 13. Пример реализации метода цепочек при разрешении коллизий: на ключ 002 претендуют два значения, которые организуются в
- 14. В итоге имеем таблицу массива связных списков 14
- 15. При решении задач на практике необходимо подобрать хеш-функцию i = h(key), которая по возможности равномерно отображает
- 16. Пример реализации метода прямой адресации Исходными данными являются 7 записей (для простоты информационная часть состоит из
- 17. На основании исходных данных последовательно заполняем хеш-таблицу. Хеширование первых пяти ключей дает различные индексы (хеш-адреса): i
- 18. Реализация метода цепочек для предыдущего примера Объявляем структурный тип для элемента однонаправленного списка: struct zap {
- 19. Хеширование первых пяти ключей, как и в предыдущем случае, дает различные индексы (хеш-адреса): 9, 0, 6,
- 20. Хеш-таблица 20
- 21. Идеальной хеш-функцией является такая hash-функция, которая для любых двух неодинаковых ключей дает неодинаковые адреса. 21
- 22. Рассмотрим пример реализации несовершенной хеш-функции на языке TurboPascal. function hash (key : string[4]): integer; var f:
- 23. Разновидности методов разрешение коллизий 23
- 24. Разрешение коллизий при добавлении элементов методом цепочек 24
- 25. Разрешение коллизий при добавлении элементов методами открытой адресации В отличие от хэширования с цепочками, при открытой
- 26. 26
- 27. Линейное опробование сводится к последовательному перебору элементов таблицы с некоторым фиксированным шагом a=h(key) + c*i ,
- 28. Еще одна разновидность метода открытой адресации, которая называется двойным хешированием, основана на нелинейной адресации, достигаемой за
- 29. Вставка i = 0 a = h(key) + i*c Если t(a) = свободно или t(a) =
- 30. Циклический переход к началу таблицы 30
- 31. Рассмотрим данный способ на примере метода линейного опробования. При вычислении адреса очередного элемента можно ограничить адрес,
- 32. Вставка i = 0 a = ((h(key) + c*i) div n + (h(key) + c*i) mod
- 33. Алгоритм вставки Вставка i = 0 a = ((h(key) + c*i) div n + (h(key) +
- 34. Удаление i = 0 a = ((h(key) + c*i) div n + (h(key) + c*i) mod
- 35. Распределение коллизий в адресном пространстве таблицы 35
- 36. Пример генерации ключа из десяти латинских букв, первая из которых является большой, а остальные малыми. Пример
- 37. Генерация ключа из m символов c кодами в диапазоне от n1 до n4 (диапазон имеет разрыв
- 38. Пример: длина ключа 7 символов 3 большие латинские (коды 65-90) 2 цифры (коды 48-57) 2 малые
- 39. Известные Хэш-функции 1. CRC16, CRC32, CRC64 - эти Хэш-функции очень просты и применяются только для проверки
- 41. Скачать презентацию

Ключевые термины
Хеширование – это специальный метод адресации данных для быстрого поиска
Ключевые термины
Хеширование – это специальный метод адресации данных для быстрого поиска

Ключевые термины
Повторное хеширование – это поиск местоположения для очередного элемента таблицы
Ключевые термины
Повторное хеширование – это поиск местоположения для очередного элемента таблицы
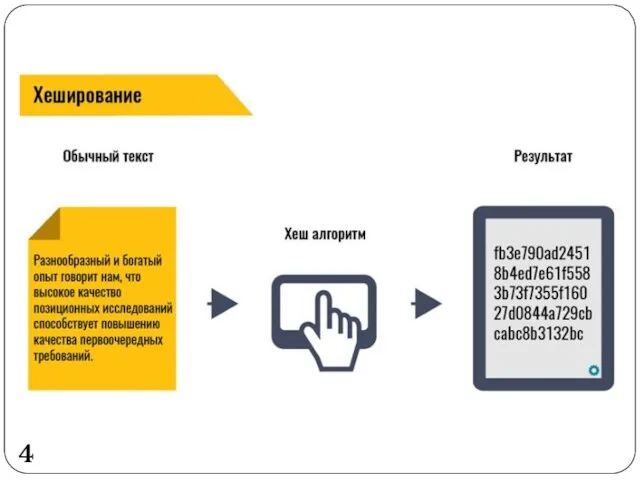
4
4
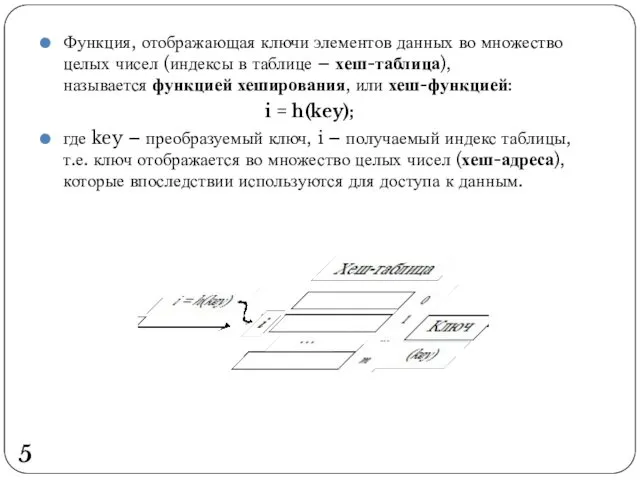
Функция, отображающая ключи элементов данных во множество целых чисел (индексы в
Функция, отображающая ключи элементов данных во множество целых чисел (индексы в

Метод деления
Исходными данными являются – некоторый целый ключ key и размер таблицы m. Результатом
Метод деления
Исходными данными являются – некоторый целый ключ key и размер таблицы m. Результатом

Для m = 100 хеш-функция возвращает две младшие цифры ключа.
7
Для m = 100 хеш-функция возвращает две младшие цифры ключа.
7

Аддитивный метод
в котором ключом является символьная строка. В хеш-функции строка преобразуется
Аддитивный метод
в котором ключом является символьная строка. В хеш-функции строка преобразуется

Данный метод можно несколько модифицировать, получая результат, суммируя только первый и
Данный метод можно несколько модифицировать, получая результат, суммируя только первый и

Метод середины квадрата
в котором ключ возводится в квадрат (умножается сам на
Метод середины квадрата
в котором ключ возводится в квадрат (умножается сам на

Мультипликативный метод
В мультипликативном методе дополнительно используется случайное действительное число r из интервала [0,1), тогда дробная
Мультипликативный метод
В мультипликативном методе дополнительно используется случайное действительное число r из интервала [0,1), тогда дробная

Две классические схемы
– хеширование методом цепочек (со списками), или так называемое
Две классические схемы
– хеширование методом цепочек (со списками), или так называемое
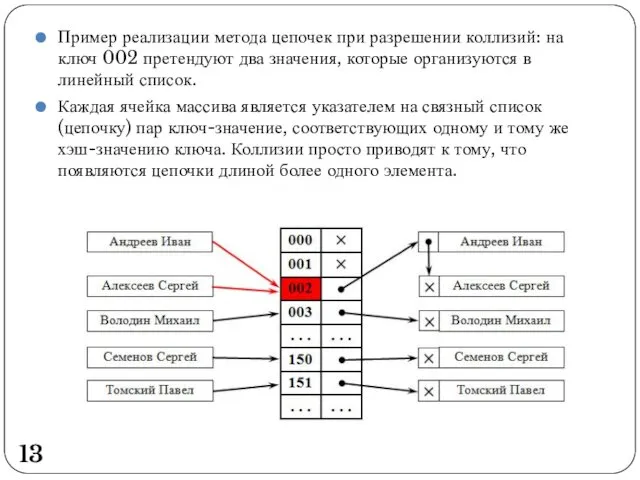
Пример реализации метода цепочек при разрешении коллизий: на ключ 002 претендуют
Пример реализации метода цепочек при разрешении коллизий: на ключ 002 претендуют

В итоге имеем таблицу массива связных списков
14
В итоге имеем таблицу массива связных списков
14

При решении задач на практике необходимо подобрать хеш-функцию i = h(key), которая по возможности
При решении задач на практике необходимо подобрать хеш-функцию i = h(key), которая по возможности

Пример реализации метода прямой адресации
Исходными данными являются 7 записей (для простоты
Пример реализации метода прямой адресации
Исходными данными являются 7 записей (для простоты

На основании исходных данных последовательно заполняем хеш-таблицу.
Хеширование первых пяти ключей дает
На основании исходных данных последовательно заполняем хеш-таблицу.
Хеширование первых пяти ключей дает

Реализация метода цепочек для предыдущего примера
Объявляем структурный тип для элемента однонаправленного списка:
struct
Реализация метода цепочек для предыдущего примера
Объявляем структурный тип для элемента однонаправленного списка:
struct

Хеширование первых пяти ключей, как и в предыдущем случае, дает различные
Хеширование первых пяти ключей, как и в предыдущем случае, дает различные
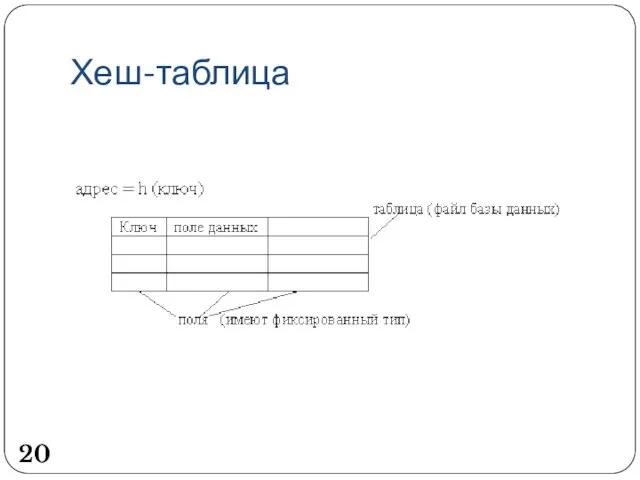
Хеш-таблица
20
Хеш-таблица
20

Идеальной хеш-функцией является такая hash-функция, которая для любых двух неодинаковых ключей
Идеальной хеш-функцией является такая hash-функция, которая для любых двух неодинаковых ключей

Рассмотрим пример реализации несовершенной хеш-функции на языке TurboPascal.
function hash (key
Рассмотрим пример реализации несовершенной хеш-функции на языке TurboPascal.
function hash (key

Разновидности методов разрешение коллизий
23
Разновидности методов разрешение коллизий
23

Разрешение коллизий при добавлении элементов методом цепочек
24
Разрешение коллизий при добавлении элементов методом цепочек
24
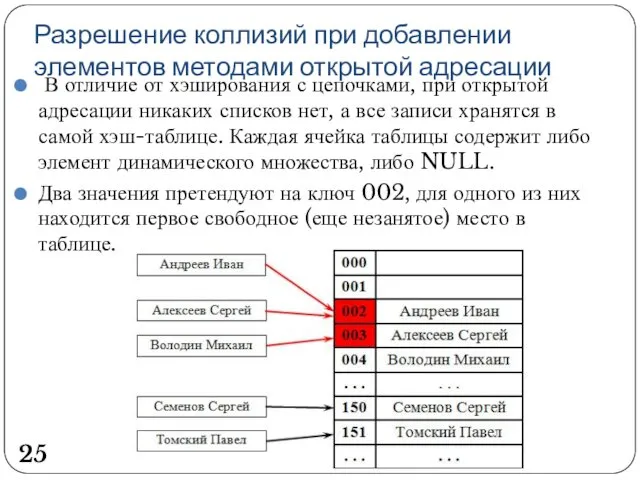
Разрешение коллизий при добавлении элементов методами открытой адресации
В отличие от
Разрешение коллизий при добавлении элементов методами открытой адресации
В отличие от
26
26

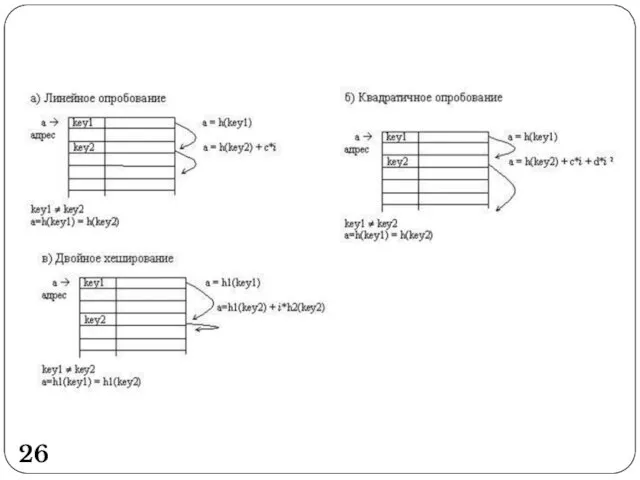
Линейное опробование сводится к последовательному перебору элементов таблицы с некоторым фиксированным
Линейное опробование сводится к последовательному перебору элементов таблицы с некоторым фиксированным

Еще одна разновидность метода открытой адресации, которая называется двойным хешированием, основана
Еще одна разновидность метода открытой адресации, которая называется двойным хешированием, основана

Вставка
i = 0
a = h(key) + i*c
Если t(a) = свободно или
Вставка
i = 0
a = h(key) + i*c
Если t(a) = свободно или

Циклический переход к началу таблицы
30
Циклический переход к началу таблицы
30

Рассмотрим данный способ на примере метода линейного опробования. При вычислении адреса
Рассмотрим данный способ на примере метода линейного опробования. При вычислении адреса

Вставка
i = 0
a = ((h(key) + c*i) div n + (h(key)
Вставка
i = 0
a = ((h(key) + c*i) div n + (h(key)

Алгоритм вставки
Вставка
i = 0
a = ((h(key) + c*i) div n +
Алгоритм вставки
Вставка
i = 0
a = ((h(key) + c*i) div n +

Удаление
i = 0
a = ((h(key) + c*i) div n + (h(key)
Удаление
i = 0
a = ((h(key) + c*i) div n + (h(key)
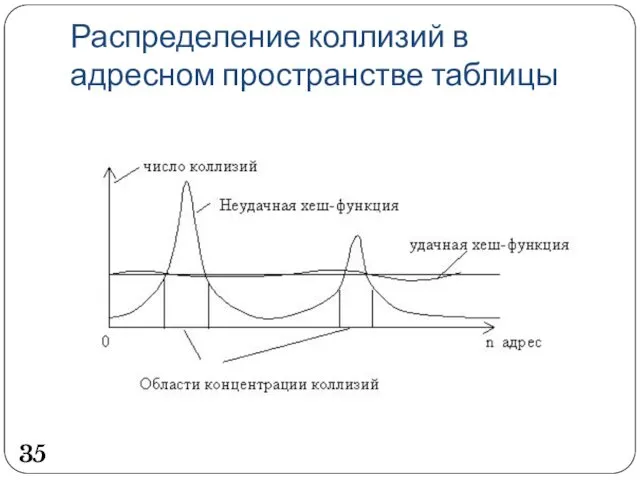
Распределение коллизий в адресном пространстве таблицы
35
Распределение коллизий в адресном пространстве таблицы
35

Пример генерации ключа из десяти латинских букв, первая из которых является
Пример генерации ключа из десяти латинских букв, первая из которых является

Генерация ключа из m символов c кодами
в диапазоне от n1 до
Генерация ключа из m символов c кодами в диапазоне от n1 до

Пример: длина ключа 7 символов
3 большие латинские (коды 65-90)
2 цифры (коды
Пример: длина ключа 7 символов
3 большие латинские (коды 65-90)
2 цифры (коды

Известные Хэш-функции
1. CRC16, CRC32, CRC64 - эти Хэш-функции очень просты и
Известные Хэш-функции
1. CRC16, CRC32, CRC64 - эти Хэш-функции очень просты и
 Бесконтактные платежи
Бесконтактные платежи Графовые модели программы. Алгоритм оптимизации информационного графа по ширине пи высоте. Лекция 4
Графовые модели программы. Алгоритм оптимизации информационного графа по ширине пи высоте. Лекция 4 Администрирование в OC Astra Linux
Администрирование в OC Astra Linux Файлы и файловая система
Файлы и файловая система Подготовка к итоговой контрольной. (6 класс)
Подготовка к итоговой контрольной. (6 класс) Классификация ПО по способу использования
Классификация ПО по способу использования Проектировка и разработка игры в жанре RPG
Проектировка и разработка игры в жанре RPG Создание Web-страниц на языке HTML
Создание Web-страниц на языке HTML Программирование с использованием строковых переменных
Программирование с использованием строковых переменных Информация и информационные процессы. 11 класс
Информация и информационные процессы. 11 класс Файлдық жүйелер мен ДҚБЖ арасындағы негізгі айырмашылық
Файлдық жүйелер мен ДҚБЖ арасындағы негізгі айырмашылық Роль информации в жизни общества
Роль информации в жизни общества Защита информации в телекоммуникационных системах
Защита информации в телекоммуникационных системах Безопасный интернет. Игра для 7 - 9-х классов
Безопасный интернет. Игра для 7 - 9-х классов Схема компьютера. Взаимодействие устройств компьютера
Схема компьютера. Взаимодействие устройств компьютера Программирование на языках высокого уровня
Программирование на языках высокого уровня Перевод чисел из одной позиционной системы в другую
Перевод чисел из одной позиционной системы в другую Разработка web-сайта для ООО Авангард
Разработка web-сайта для ООО Авангард Система условных знаков для представления информации
Система условных знаков для представления информации Главные правила классической типографики
Главные правила классической типографики Изображения в памяти компьютера
Изображения в памяти компьютера Коаксиальный кабель
Коаксиальный кабель Pascal ABC Модуль GraphABC
Pascal ABC Модуль GraphABC Презентация по информатике Информация и её свойства
Презентация по информатике Информация и её свойства  Измерение информации
Измерение информации Программа Figma
Программа Figma Презентация "Передача информации презентация 5 класс." - скачать презентации по Информатике
Презентация "Передача информации презентация 5 класс." - скачать презентации по Информатике Презентация "RHINO 5200" - скачать презентации по Информатике
Презентация "RHINO 5200" - скачать презентации по Информатике