- Извлечение фактов из текста. Математическая лингвистика

Содержание
- 2. Что такое компьютерная лингвистика? Компьютерная лингвистика изучает язык с позиции его использования в компьютерных системах.
- 3. Задачи компьютерной лингвистики: автоматическое составление словарей и грамматик; анализ естественно-языковых текстов; создание и использование текстовых корпусов;
- 4. Извлечение фактов (структурированной информации) из неструктурированного текста - Text Mining. С помощью этой технологии можно представлять
- 5. Где применяются технологии извлечения фактов? Яндекс – Почта, Новости, Карты и др. сервисы.
- 6. Где применяются технологии извлечения фактов?
- 7. Где применяются технологии извлечения фактов? В поисковых системах, например Google и Yandex, для сбора информации о
- 8. Пример извлечения фактов
- 9. Задача проекта: извлечение фактов из текстов для структурирования информации. Под «фактом» понимается набор извлеченных сущностей, связанных
- 10. Примеры неструктурированного текста: В 1771 году Карл Шееле получил плавиковую кислоту. В природе значимые скопления фтора
- 11. Получаем на выходе:
- 12. Инструменты для работы Томита-парсер — это инструмент для извлечения структурированных данных (фактов) из текста на естественном
- 13. Грамматика томита-парсера Так выглядит часть грамматики для томита-парсера (для извлечения места рождения человека): Born -> Verb
- 14. Грамматика томита-парсера Язык описания грамматик для томита-парсера построен на основе порождающих грамматик.
- 15. Источники: Блог Яндекса на Хабре http://habrahabr.ru/company/yandex/blog/219311/ http://habrahabr.ru/company/yandex/blog/205198/ Скриншоты с Яндекс Почты
- 17. Скачать презентацию

Что такое компьютерная лингвистика?
Компьютерная лингвистика изучает язык с позиции его использования
Что такое компьютерная лингвистика?
Компьютерная лингвистика изучает язык с позиции его использования

Задачи компьютерной лингвистики:
автоматическое составление словарей и грамматик;
анализ естественно-языковых текстов;
создание и использование
Задачи компьютерной лингвистики:
автоматическое составление словарей и грамматик;
анализ естественно-языковых текстов;
создание и использование

Извлечение фактов (структурированной информации) из неструктурированного текста - Text Mining.
С
Извлечение фактов (структурированной информации) из неструктурированного текста - Text Mining.
С
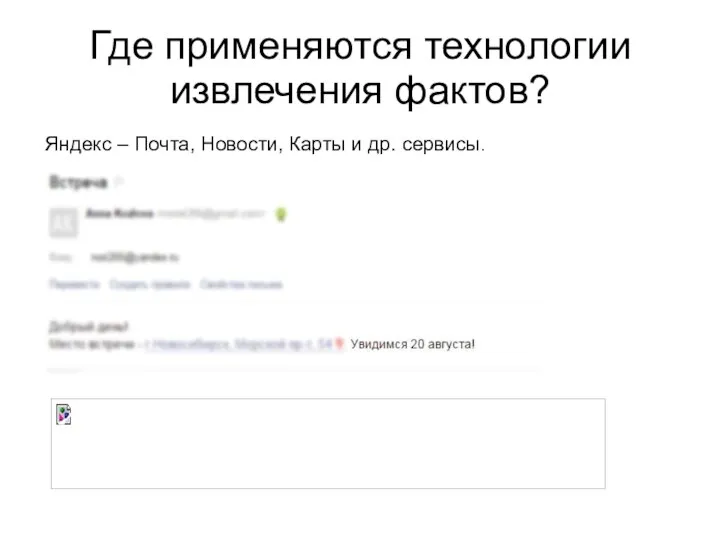
Где применяются технологии извлечения фактов?
Яндекс – Почта, Новости, Карты и др.
Где применяются технологии извлечения фактов?
Яндекс – Почта, Новости, Карты и др.
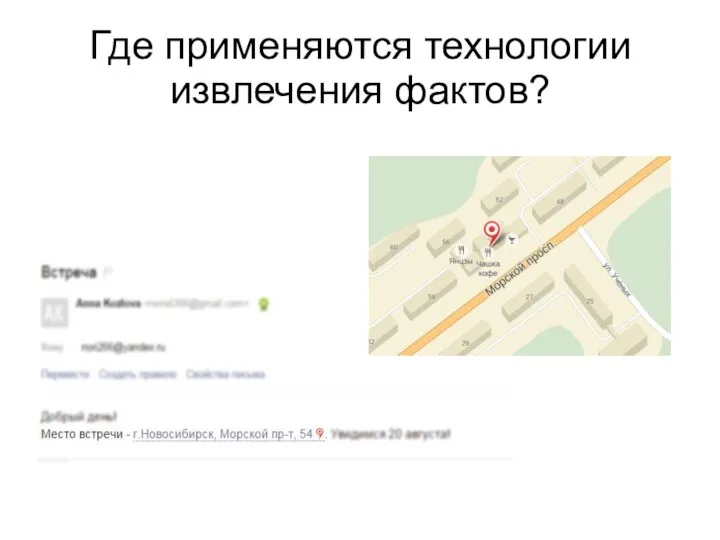
Где применяются технологии извлечения фактов?
Где применяются технологии извлечения фактов?

Где применяются технологии извлечения фактов?
В поисковых системах, например Google и Yandex,
Где применяются технологии извлечения фактов?
В поисковых системах, например Google и Yandex,
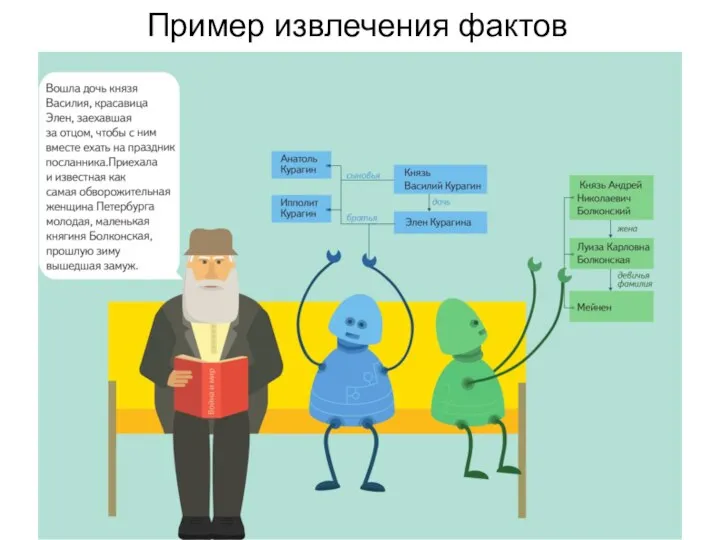
Пример извлечения фактов
Пример извлечения фактов

Задача проекта:
извлечение фактов из текстов для структурирования информации.
Под «фактом» понимается набор
Задача проекта:
извлечение фактов из текстов для структурирования информации.
Под «фактом» понимается набор

Примеры неструктурированного текста:
В 1771 году Карл Шееле получил плавиковую кислоту.
В природе
Примеры неструктурированного текста:
В 1771 году Карл Шееле получил плавиковую кислоту.
В природе
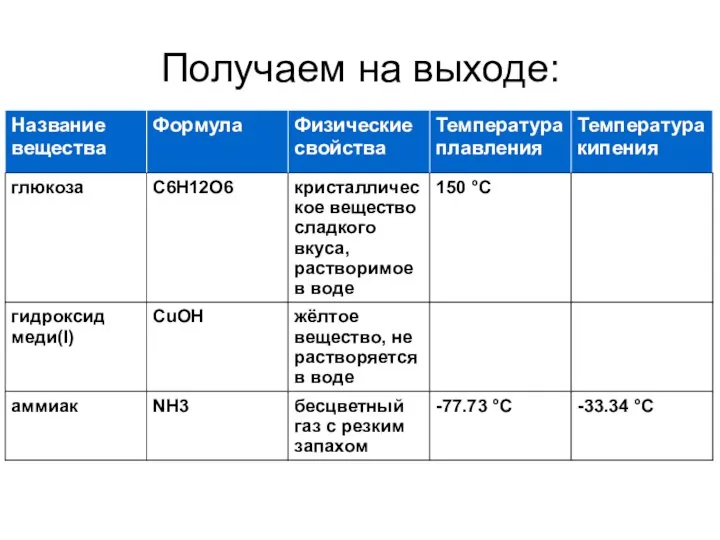
Получаем на выходе:
Получаем на выходе:

Инструменты для работы
Томита-парсер — это инструмент для извлечения структурированных данных (фактов)
Инструменты для работы
Томита-парсер — это инструмент для извлечения структурированных данных (фактов)

Грамматика томита-парсера
Так выглядит часть грамматики для томита-парсера (для извлечения места рождения
Грамматика томита-парсера
Так выглядит часть грамматики для томита-парсера (для извлечения места рождения
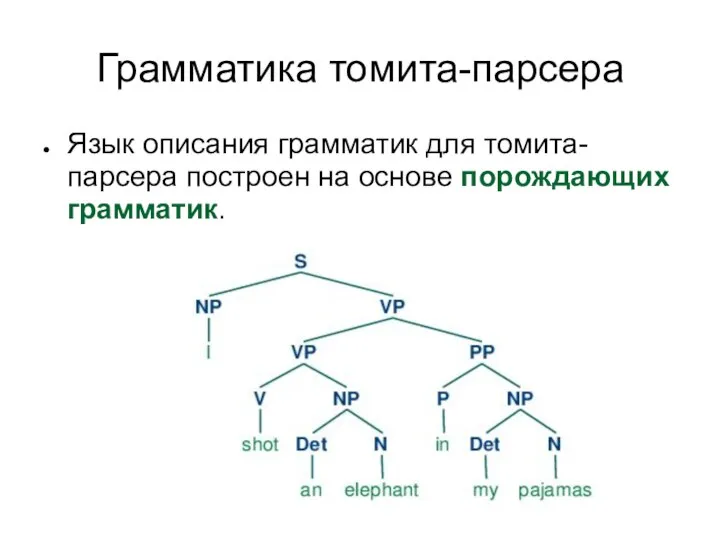
Грамматика томита-парсера
Язык описания грамматик для томита-парсера построен на основе порождающих грамматик.
Грамматика томита-парсера
Язык описания грамматик для томита-парсера построен на основе порождающих грамматик.

Источники:
Блог Яндекса на Хабре http://habrahabr.ru/company/yandex/blog/219311/
http://habrahabr.ru/company/yandex/blog/205198/
Скриншоты с Яндекс Почты
Источники:
Блог Яндекса на Хабре http://habrahabr.ru/company/yandex/blog/219311/
http://habrahabr.ru/company/yandex/blog/205198/
Скриншоты с Яндекс Почты
 Analysis and Design of Data Systems. Introduction to Relational Database Design (Lecture 14)
Analysis and Design of Data Systems. Introduction to Relational Database Design (Lecture 14) Урок 12 Тема: Наглядные формы представления информации.
Урок 12 Тема: Наглядные формы представления информации. Программирование на языке Python
Программирование на языке Python Перспективы использования машинного обучения для ИТ-проектов и стартапов
Перспективы использования машинного обучения для ИТ-проектов и стартапов Templates for pitch presentation
Templates for pitch presentation Использование информационных технологий в преподавании дисциплины “Электрические машины”
Использование информационных технологий в преподавании дисциплины “Электрические машины” Построение 3D модели и чертежа в редакторе
Построение 3D модели и чертежа в редакторе Презентация "Основные понятия " - скачать презентации по Информатике
Презентация "Основные понятия " - скачать презентации по Информатике Поняття про глобальну та локальну комп’ютерні мережі. Апаратне й програмне забезпечення мереж
Поняття про глобальну та локальну комп’ютерні мережі. Апаратне й програмне забезпечення мереж Основні концепції реляційної бази даних
Основні концепції реляційної бази даних Программные средства для создания графических файлов и анимации Учитель: Избасова А.Г.
Программные средства для создания графических файлов и анимации Учитель: Избасова А.Г. Введение в веб разработку
Введение в веб разработку Нейросеть на пальцах
Нейросеть на пальцах Управление предприятием
Управление предприятием Триггеры в презентации. Применение. Создание слайдов с триггерами
Триггеры в презентации. Применение. Создание слайдов с триггерами Кодирование числовой, текстовой и графической информации. Декодирование
Кодирование числовой, текстовой и графической информации. Декодирование Презентация на тему Microsoft Excel Электронные таблицы Microsoft Excel
Презентация на тему Microsoft Excel Электронные таблицы Microsoft Excel Web Technologies Basics
Web Technologies Basics Циклические алгоритмы
Циклические алгоритмы Цифрова економіка України: час діяти настав
Цифрова економіка України: час діяти настав Условная функция и логические выражения
Условная функция и логические выражения Разработка экспериментального образца ГНСС SDR
Разработка экспериментального образца ГНСС SDR Настройка компьютера при замедлении работы в играх и программных приложениях
Настройка компьютера при замедлении работы в играх и программных приложениях Технологии улучшают жизнь. Money Center
Технологии улучшают жизнь. Money Center Условия поиска и отбора информации, простые логические выражения
Условия поиска и отбора информации, простые логические выражения Использование технологий web 2.0. в корпоративном обучении
Использование технологий web 2.0. в корпоративном обучении Исследовательская работа Влияние социальных сетей на личность подростка и русский язык
Исследовательская работа Влияние социальных сетей на личность подростка и русский язык Регистрация или восстановление доступа к личному кабинету СК Согласие
Регистрация или восстановление доступа к личному кабинету СК Согласие