- Кодирование текстовой информации

Содержание
- 2. Двоичное кодирование в компьютере Вся информация, которую обрабатывает компьютер должна быть представлена двоичным кодом с помощью
- 3. Почему двоичное кодирование С точки зрения технической реализации использование двоичной системы счисления для кодирования информации оказалось
- 4. Двоичное кодирование текстовой информации Начиная с 60-х годов, компьютеры все больше стали использовать для обработки текстовой
- 5. 1 символ – 1 байт (8 бит) Для кодирования одного символа требуется один байт информации. Учитывая,
- 6. Двоичное кодирование текстовой информации Кодирование заключается в том, что каждому символу ставиться в соответствие уникальный двоичный
- 7. Таблица кодировки Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера (коды), называется
- 8. Таблица кодировки ASCII Стандартной в этой таблице является только первая половина, т.е. символы с номерами от
- 10. Таблица расширенного кода ASCII Кодировка Windows-1251 (CP1251)
- 12. Скачать презентацию

Двоичное кодирование в компьютере
Вся информация, которую обрабатывает компьютер должна быть представлена
Двоичное кодирование в компьютере
Вся информация, которую обрабатывает компьютер должна быть представлена

Почему двоичное кодирование
С точки зрения технической реализации использование двоичной системы счисления
Почему двоичное кодирование
С точки зрения технической реализации использование двоичной системы счисления

Двоичное кодирование текстовой информации
Начиная с 60-х годов, компьютеры все больше стали
Двоичное кодирование текстовой информации
Начиная с 60-х годов, компьютеры все больше стали

1 символ – 1 байт (8 бит)
Для кодирования одного символа требуется
1 символ – 1 байт (8 бит)
Для кодирования одного символа требуется

Двоичное кодирование текстовой информации
Кодирование заключается в том, что каждому символу ставиться
Двоичное кодирование текстовой информации
Кодирование заключается в том, что каждому символу ставиться

Таблица кодировки
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие
Таблица кодировки
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие

Таблица кодировки ASCII
Стандартной в этой таблице является только первая половина, т.е.
Таблица кодировки ASCII
Стандартной в этой таблице является только первая половина, т.е.
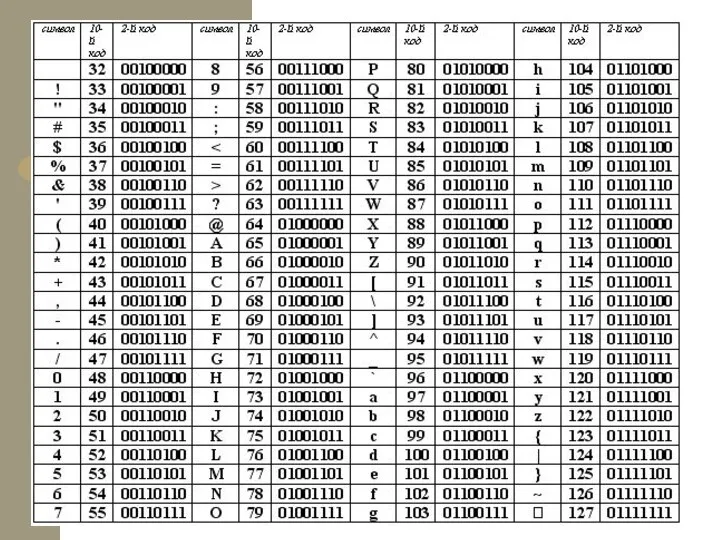
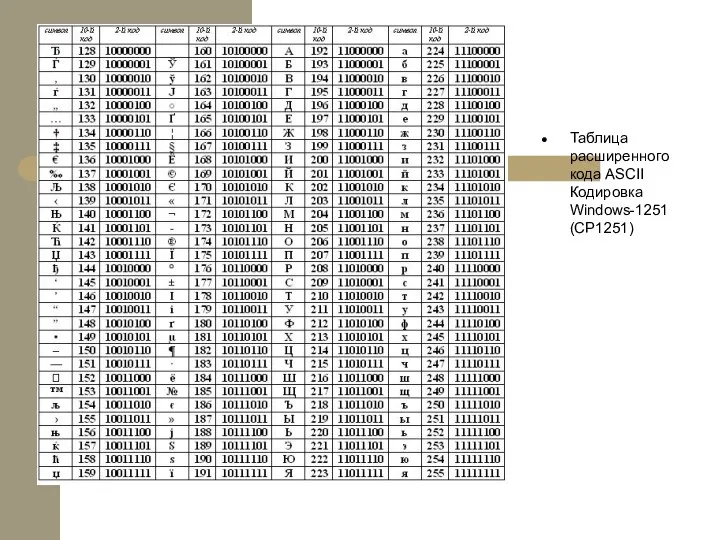
Таблица расширенного кода ASCII
Кодировка Windows-1251 (CP1251)
Таблица расширенного кода ASCII
Кодировка Windows-1251 (CP1251)
 Работа по ЭДО: памятка для клиента, работающего в отличных от системы СБИС
Работа по ЭДО: памятка для клиента, работающего в отличных от системы СБИС Типы алгоритмов. Линейный алгоритм
Типы алгоритмов. Линейный алгоритм Security Conception for GD
Security Conception for GD Чем опасен Интернет
Чем опасен Интернет Сценарии использования Системы
Сценарии использования Системы РАБОТА С ЭЛЕКТРОННОЙ ПОЧТОЙ В СЕТИ ИНТЕРНЕТ
РАБОТА С ЭЛЕКТРОННОЙ ПОЧТОЙ В СЕТИ ИНТЕРНЕТ Копия Kompyuternye_virusy_priznaki_zarazhenia
Копия Kompyuternye_virusy_priznaki_zarazhenia Возможности электронных таблиц
Возможности электронных таблиц Ветвление if-elif-else
Ветвление if-elif-else Язык программирования Java
Язык программирования Java Растровая и векторная графика
Растровая и векторная графика Mitrix Technology
Mitrix Technology Создание документов в текстовых редакторах
Создание документов в текстовых редакторах  С++ тілінің операторлары. Шартты оператор. Таңдау операторы
С++ тілінің операторлары. Шартты оператор. Таңдау операторы Презентация "История Apple Computer" - скачать презентации по Информатике
Презентация "История Apple Computer" - скачать презентации по Информатике Возможности использования Intel Perceptual Computing SDK в образовании (Лекция 3)
Возможности использования Intel Perceptual Computing SDK в образовании (Лекция 3) Устройства ввода и вывода информации
Устройства ввода и вывода информации Электронная цифровая подпись
Электронная цифровая подпись Режимы и способы обработки данных
Режимы и способы обработки данных Измерения аналоговых и цифровых сигналов. Платы расширения. Обмен сигналами с нестандартными устройствами. (Лекия 2)
Измерения аналоговых и цифровых сигналов. Платы расширения. Обмен сигналами с нестандартными устройствами. (Лекия 2) Человек и информация
Человек и информация Информация. Компьютер. Информатика. Цель: первичное понятие об информации, информатике и компьютере. познакомить учащихся с уч
Информация. Компьютер. Информатика. Цель: первичное понятие об информации, информатике и компьютере. познакомить учащихся с уч Бешков Андрей Microsoft
Бешков Андрей Microsoft  Информационные процессы. (10 класс)
Информационные процессы. (10 класс) Веб-интерфейсы программирования (API) для принятия управленческих решений
Веб-интерфейсы программирования (API) для принятия управленческих решений Регистрация на сайте ГТО
Регистрация на сайте ГТО Складові комп`ютерів та їх призначення
Складові комп`ютерів та їх призначення Презентация "Радиаторы и вентиляторы" - скачать презентации по Информатике
Презентация "Радиаторы и вентиляторы" - скачать презентации по Информатике