- Конвейерный процессор. Лекция №11

Содержание
- 2. 1. Принципы построения конвейерного процессора. Микропроцессоры выполняют миллионы и миллиарды команд в секунду, так что производительность
- 3. На рис. (а) приведена временная диаграмма однотактного без конвейерного процессора. По горизонтальной оси отложено время (в
- 4. В конвейерном процессоре, на рис. (b), длина самой медленной стадии определяется стадией доступа к памяти (Fetch-
- 5. 1.3. Абстрактное представление работающего конвейера Абстрактное представление работающего конвейера показывает продвижение команд по конвейеру. Каждая стадия
- 6. 2. Конвейерный тракт данных. Конвейерный тракт данных получим, разрезав однотактный тракт данных на пять стадий, разделенных
- 7. 3. Конвейерное устройство управления Конвейерный П использует те же управляющие сигналы, что и однотактный П, поэтому
- 8. 4. Конфликты и их разрешение. Процессор может читать и писать в регистровый файл RF за один
- 9. Однако, результат команды add вычисляется в АЛУ на третьем такте, а команде and он требуется лишь
- 10. Конфликты можно разделить на конфликты данных (data hazards – данные опасностей) и конфликты управления (control hazards
- 11. Пересылка данных через байпас необходима, если номер любого из регистров операндов команды, находящейся в стадии Execute,
- 12. У П появился блок обнаружения конфликтов (БОК) и два новых мультиплексора. БОК получает на свой вход
- 13. 4.2. Разрешение конфликтов данных приостановками конвейера. Например, команда lw не может прочитать данные раньше, чем в
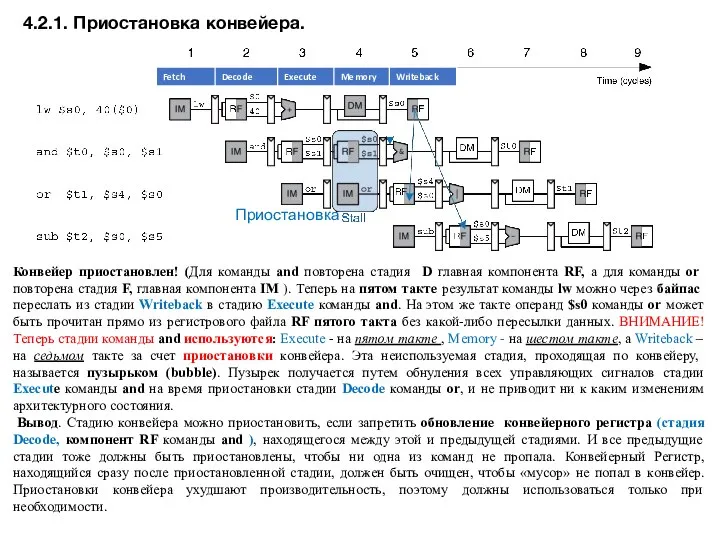
- 14. 4.2.1. Приостановка конвейера. Конвейер приостановлен! (Для команды and повторена стадия D главная компонента RF, а для
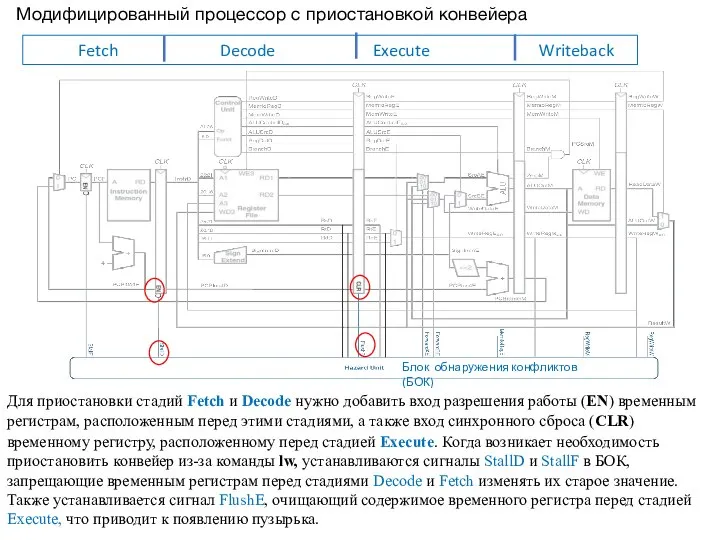
- 15. Модифицированный процессор с приостановкой конвейера Для приостановки стадий Fetch и Decode нужно добавить вход разрешения работы
- 16. 4.3. Разрешение конфликтов управления Выполнение команды beq приводит к конфликту управления: конвейерный процессор не знает, какую
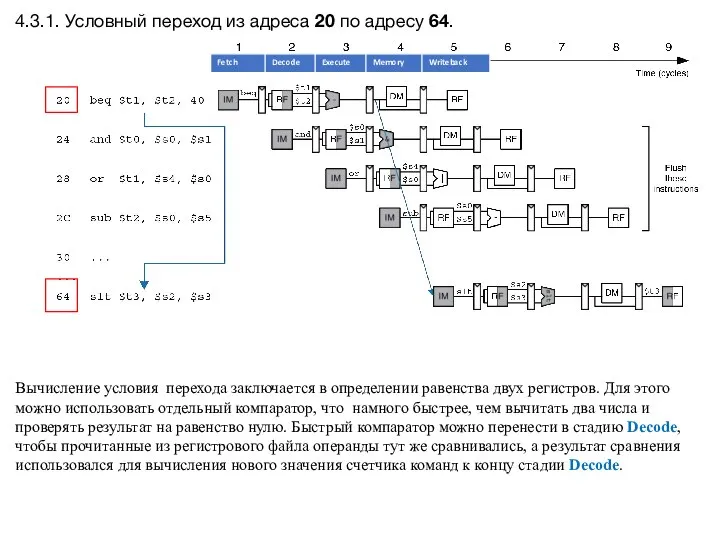
- 17. 4.3.1. Условный переход из адреса 20 по адресу 64. Вычисление условия перехода заключается в определении равенства
- 18. Конвейерный процессор с ранним вычислением условий переходов, способный разрешать конфликты управления. Вычисление условий перехода, происходит на
- 20. Скачать презентацию

1. Принципы построения конвейерного процессора.
Микропроцессоры выполняют миллионы и миллиарды команд в
1. Принципы построения конвейерного процессора.
Микропроцессоры выполняют миллионы и миллиарды команд в

На рис. (а) приведена временная диаграмма однотактного без конвейерного процессора. По
На рис. (а) приведена временная диаграмма однотактного без конвейерного процессора. По
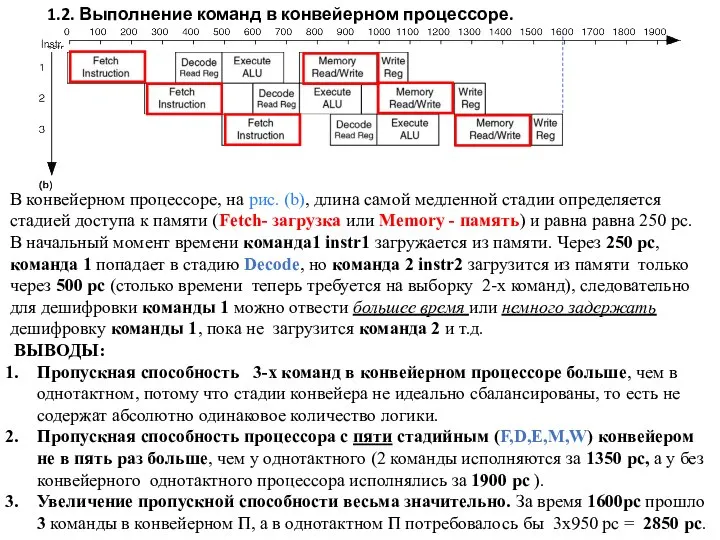
В конвейерном процессоре, на рис. (b), длина самой медленной стадии определяется
В конвейерном процессоре, на рис. (b), длина самой медленной стадии определяется
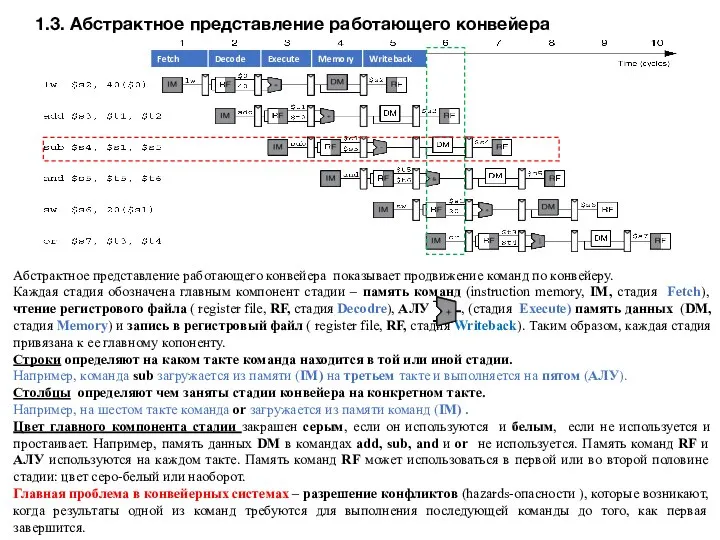
1.3. Абстрактное представление работающего конвейера
Абстрактное представление работающего конвейера показывает продвижение команд
1.3. Абстрактное представление работающего конвейера
Абстрактное представление работающего конвейера показывает продвижение команд
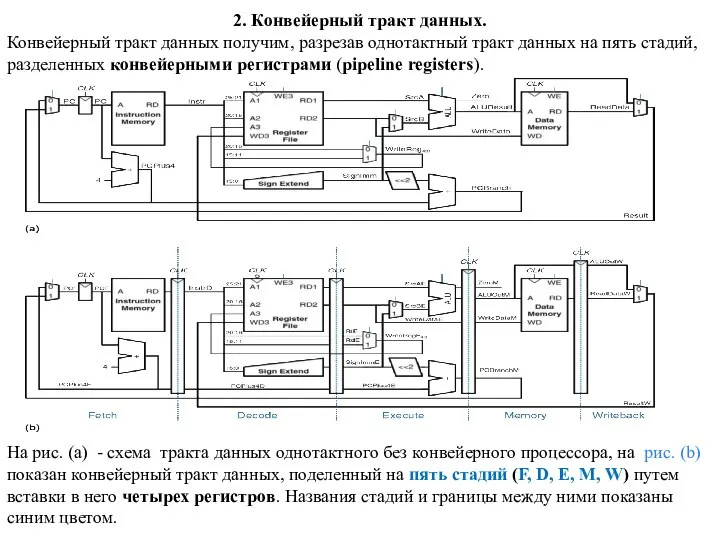
2. Конвейерный тракт данных.
Конвейерный тракт данных получим, разрезав однотактный тракт данных
2. Конвейерный тракт данных.
Конвейерный тракт данных получим, разрезав однотактный тракт данных
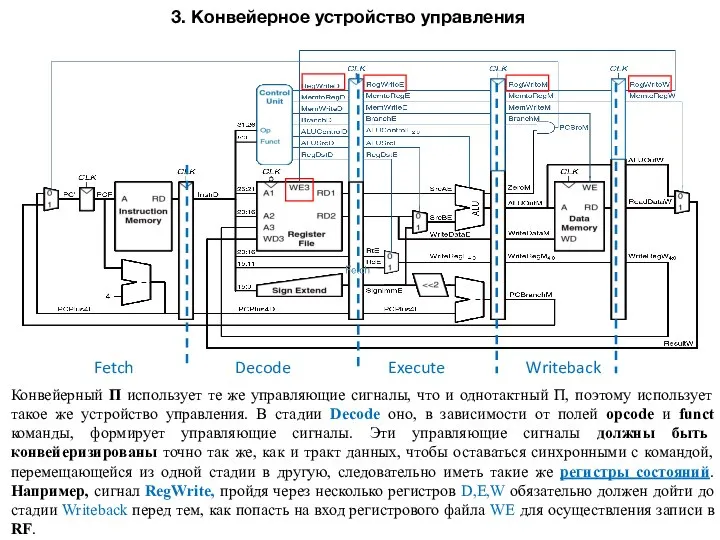
3. Конвейерное устройство управления
Конвейерный П использует те же управляющие сигналы, что
3. Конвейерное устройство управления
Конвейерный П использует те же управляющие сигналы, что
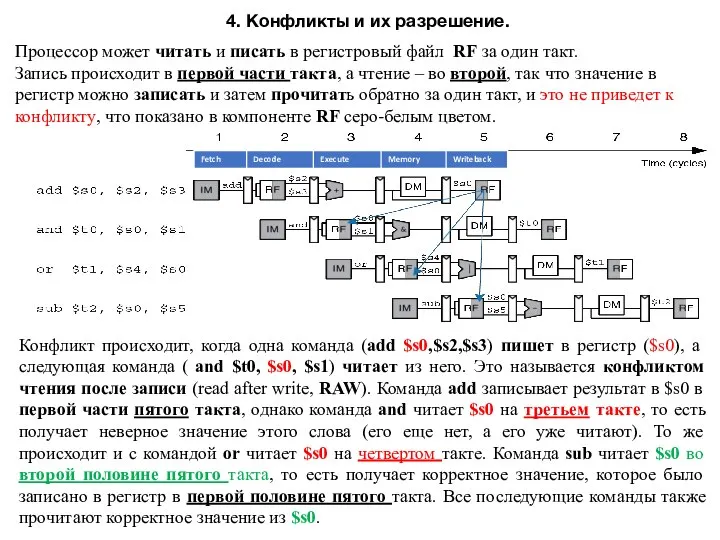
4. Конфликты и их разрешение.
Процессор может читать и писать в регистровый
4. Конфликты и их разрешение.
Процессор может читать и писать в регистровый
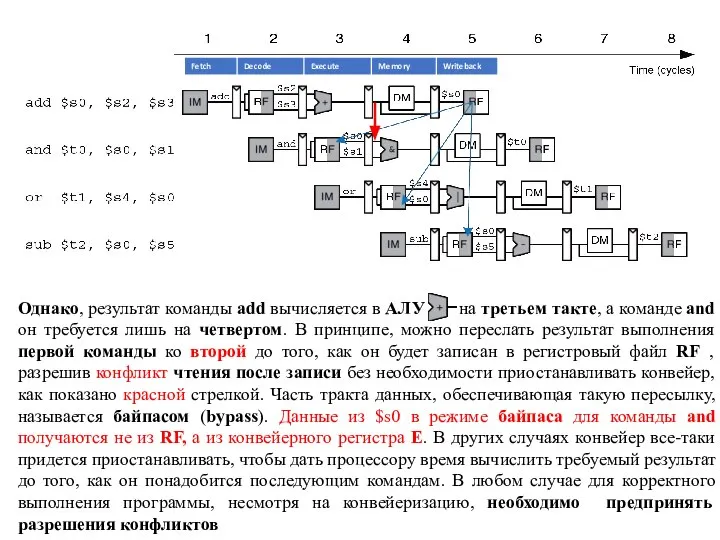
Однако, результат команды add вычисляется в АЛУ на третьем такте, а
Однако, результат команды add вычисляется в АЛУ на третьем такте, а

Конфликты можно разделить на конфликты данных (data hazards – данные опасностей)
Конфликты можно разделить на конфликты данных (data hazards – данные опасностей)
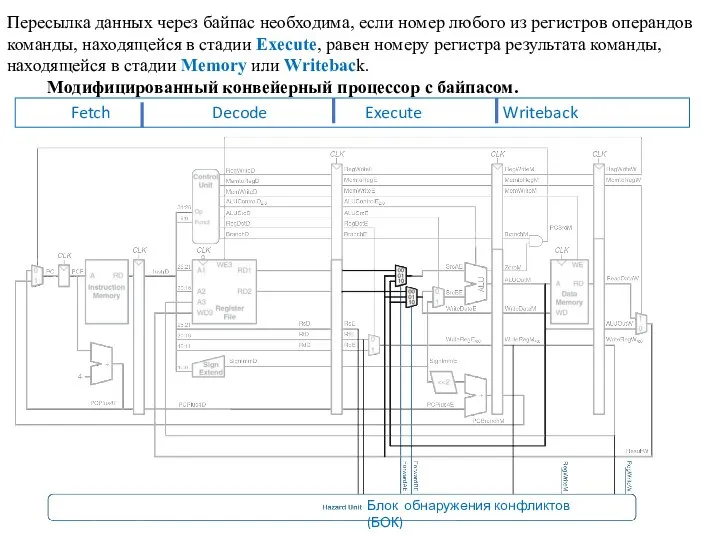
Пересылка данных через байпас необходима, если номер любого из регистров операндов
Пересылка данных через байпас необходима, если номер любого из регистров операндов

У П появился блок обнаружения конфликтов (БОК) и два новых мультиплексора.
БОК
У П появился блок обнаружения конфликтов (БОК) и два новых мультиплексора.
БОК
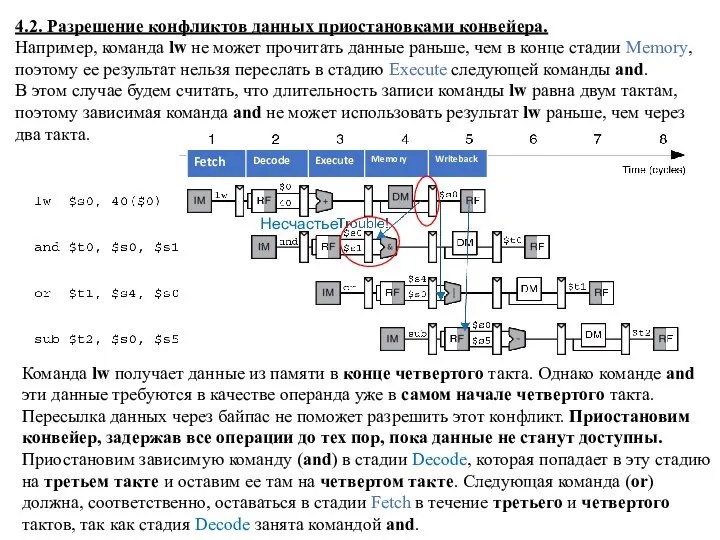
4.2. Разрешение конфликтов данных приостановками конвейера.
Например, команда lw не может прочитать
4.2. Разрешение конфликтов данных приостановками конвейера.
Например, команда lw не может прочитать
4.2.1. Приостановка конвейера.
Конвейер приостановлен! (Для команды and повторена стадия D главная
4.2.1. Приостановка конвейера.
Конвейер приостановлен! (Для команды and повторена стадия D главная
Модифицированный процессор с приостановкой конвейера
Для приостановки стадий Fetch и Decode нужно
Модифицированный процессор с приостановкой конвейера
Для приостановки стадий Fetch и Decode нужно

4.3. Разрешение конфликтов управления
Выполнение команды beq приводит к конфликту управления:
4.3. Разрешение конфликтов управления
Выполнение команды beq приводит к конфликту управления:
4.3.1. Условный переход из адреса 20 по адресу 64.
Вычисление условия перехода
4.3.1. Условный переход из адреса 20 по адресу 64.
Вычисление условия перехода

Конвейерный процессор с ранним вычислением условий переходов, способный разрешать конфликты управления.
Вычисление
Конвейерный процессор с ранним вычислением условий переходов, способный разрешать конфликты управления.
Вычисление
 Регистрация и авторизация на Яндекс.Маркет
Регистрация и авторизация на Яндекс.Маркет Intent'ы, IntentFilter'ы и BackStack Activity
Intent'ы, IntentFilter'ы и BackStack Activity 10 вопросов к викторине
10 вопросов к викторине «1С:Мясопереработка MES. Модуль для 1С:ERP». Группа компаний «Аверсон»
«1С:Мясопереработка MES. Модуль для 1С:ERP». Группа компаний «Аверсон» Способы записи алгоритмов
Способы записи алгоритмов Разработка макета WEB сайта на заданную тему
Разработка макета WEB сайта на заданную тему Профессиональная переподготовка Библиотечно-информационная деятельность. Библиотековедение
Профессиональная переподготовка Библиотечно-информационная деятельность. Библиотековедение Личностно-деятельностный подход в обучении информатике
Личностно-деятельностный подход в обучении информатике Автоматизация процессов разработки веб-приложения
Автоматизация процессов разработки веб-приложения Единое сообщество в социальных сетях «Движение Творца» (на примере соцсети Вконтакте) Основная цель: — создать «узел энергообм
Единое сообщество в социальных сетях «Движение Творца» (на примере соцсети Вконтакте) Основная цель: — создать «узел энергообм ИНФОРМАЦИЯ Виды информации
ИНФОРМАЦИЯ Виды информации Семантический архив 4.0
Семантический архив 4.0 Принципы построения операционных систем (ОС)
Принципы построения операционных систем (ОС) Презентация "Виртуальные музеи" - скачать презентации по Информатике
Презентация "Виртуальные музеи" - скачать презентации по Информатике Методы программирования. Алгоритмы сортировки. Пирамидальная сортировка. (Лекция 2)
Методы программирования. Алгоритмы сортировки. Пирамидальная сортировка. (Лекция 2) Разработка учителя информатики и ИКТ МОУ «Майская гимназия Белгородского района» Токарь Татьяны Васильевны
Разработка учителя информатики и ИКТ МОУ «Майская гимназия Белгородского района» Токарь Татьяны Васильевны Клиент-серверное взаимодействие мобильных приложений. Тема 14
Клиент-серверное взаимодействие мобильных приложений. Тема 14 Специализация Full Stack Web Development with Angular (Онлайн, Coursera, ENG, ОК)
Специализация Full Stack Web Development with Angular (Онлайн, Coursera, ENG, ОК) Развитие информационной компетенции учащихся средствами метода учебных проектов на уроках английского языка
Развитие информационной компетенции учащихся средствами метода учебных проектов на уроках английского языка Ақпараттық қауіпсіздік негіздері
Ақпараттық қауіпсіздік негіздері Табличная форма представления информации
Табличная форма представления информации Автоматизированная система управления (АСУ)
Автоматизированная система управления (АСУ) Video games
Video games Презентация "Типовая корпоративная сеть, понятие уязвимости и атаки - 3" - скачать презентации по Информатике
Презентация "Типовая корпоративная сеть, понятие уязвимости и атаки - 3" - скачать презентации по Информатике Модели коммуникации
Модели коммуникации Засоби масової інформації
Засоби масової інформації Купи продай. Искусство постосложения
Купи продай. Искусство постосложения Пригласительные Карина и Ефим 17.07.17
Пригласительные Карина и Ефим 17.07.17