- Криптографические хэш-функции

Содержание
- 2. Семейство алгоритмов SHA Семейство алгоритмов SHA (Secure Hash Algorithm) включает в себя 5 алгоритмов вычисления хэш-функции:
- 3. Между собой алгоритмы отличаются криптостойкостью, которая обеспечивается для хэшируемых данных, а также размерами блоков и слов
- 4. При описании алгоритма под термином слово понимается 32-битная последовательность (SHA-1, SHA-224, SHA-256), а под термином байт
- 5. Про циклический сдвиг пример и операции пример
- 7. Описание алгоритма.
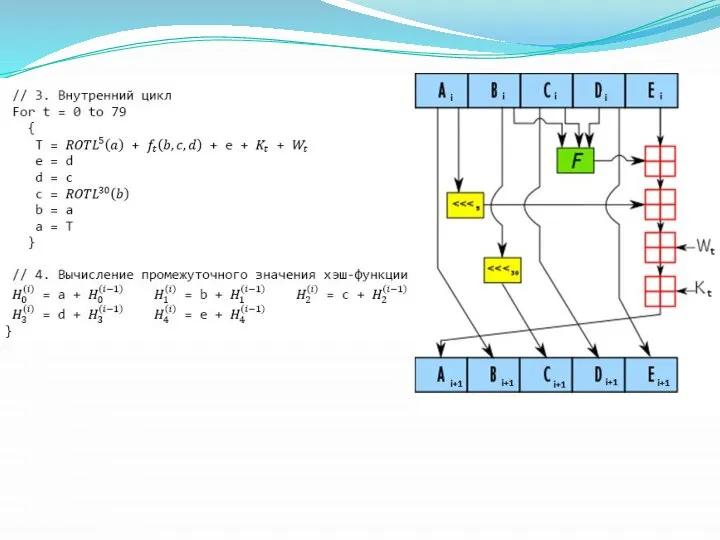
- 9. Дальнейшие шаги специфичны для каждого алгоритма Алгоритм SHA–1
- 12. Шаг 5. Результат. Результатом вычисления хэш-функции от всего сообщения является: ǁ — конкатенация- операция склеивания объектов
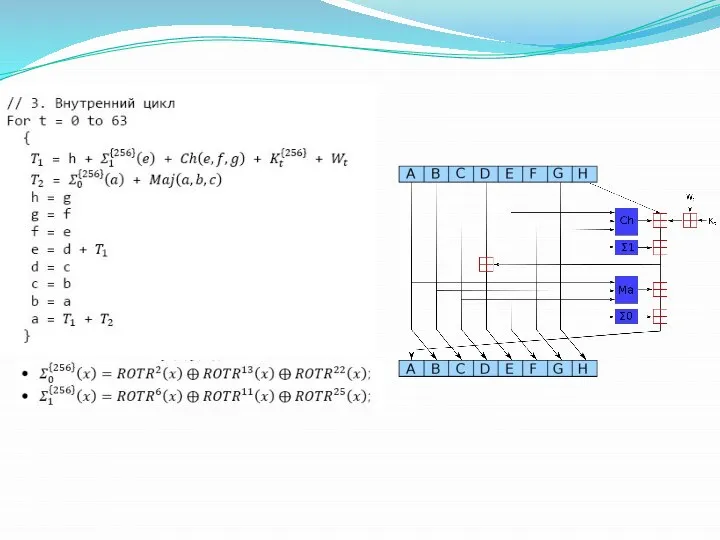
- 13. Алгоритм SHA–256
- 16. Примеры значений хэш-функции (в 16-ричном виде): SHA256 ("") = e3b0c442 98fc1c14 9afbf4c8 996fb924 27ae41e4 649b934c a495991b
- 17. MD4 - это однонаправленная хэш-функция, изобретенная Роном Ривестом. MD обозначает Message Digest (краткое изложение сообщения), алгоритм
- 18. Простота и компактность. MD4 проста, насколько это возможна, и не содержит больших структур данных или сложных
- 19. MD5 англ. Message Digest 5 – 128-битный алгоритм хеширования, разработанный профессором Рональдом Л. Ривестом из Массачусетского
- 20. 1. Выравнивание потока. В конец исходного сообщения, длиной L, дописывают единичный бит, затем необходимое число нулевых
- 21. Последовательность байт может быть интерпретирована как последовательность 32-битных слов, где каждая последовательная группа из 4 байт
- 22. 3. Инициализация буфера. Для вычислений инициализируются 4 переменных размером по 32 бита и задаются начальные значения
- 23. Шаг основного цикла вычисления хеша
- 24. В каждом раунде над переменными ABCD и блоком исходного текста Т в цикле (16 итераций) выполняются
- 25. 3) ki - целая часть константы, определяемой по формуле ki = 232 * | sin(i +
- 26. Величины, используемые на шаге цикла раунда Раундовые функции RF
- 28. Скачать презентацию

Семейство алгоритмов SHA
Семейство алгоритмов SHA (Secure Hash Algorithm) включает в себя
Семейство алгоритмов SHA
Семейство алгоритмов SHA (Secure Hash Algorithm) включает в себя
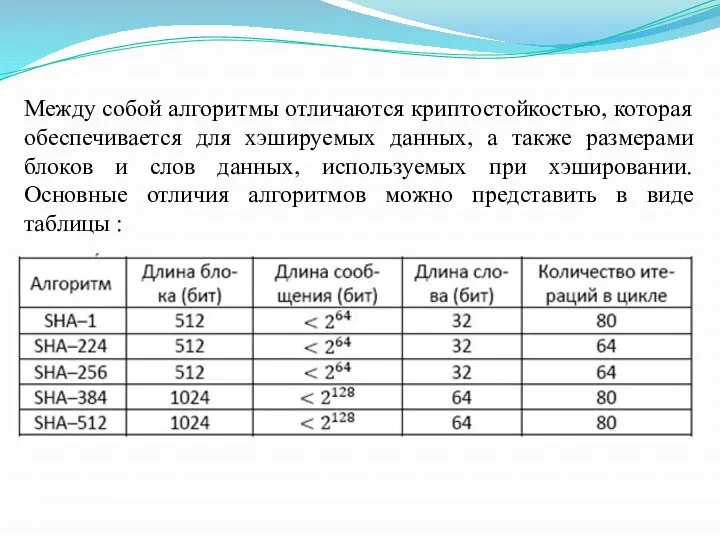
Между собой алгоритмы отличаются криптостойкостью, которая обеспечивается для хэшируемых данных, а
Между собой алгоритмы отличаются криптостойкостью, которая обеспечивается для хэшируемых данных, а

При описании алгоритма под термином слово понимается 32-битная последовательность (SHA-1, SHA-224,
При описании алгоритма под термином слово понимается 32-битная последовательность (SHA-1, SHA-224,

Про циклический сдвиг пример и операции пример
Про циклический сдвиг пример и операции пример


Описание алгоритма.
Описание алгоритма.


Дальнейшие шаги специфичны для каждого алгоритма
Алгоритм SHA–1
Дальнейшие шаги специфичны для каждого алгоритма
Алгоритм SHA–1


Шаг 5. Результат.
Результатом вычисления хэш-функции от всего сообщения является:
ǁ
Шаг 5. Результат.
Результатом вычисления хэш-функции от всего сообщения является:
ǁ

Алгоритм SHA–256
Алгоритм SHA–256


Примеры значений хэш-функции (в 16-ричном виде):
SHA256 ("") = e3b0c442 98fc1c14
Примеры значений хэш-функции (в 16-ричном виде):
SHA256 ("") = e3b0c442 98fc1c14

MD4 - это однонаправленная хэш-функция, изобретенная Роном Ривестом. MD обозначает Message
MD4 - это однонаправленная хэш-функция, изобретенная Роном Ривестом. MD обозначает Message

Простота и компактность. MD4 проста, насколько это возможна, и не содержит
Простота и компактность. MD4 проста, насколько это возможна, и не содержит

MD5
англ. Message Digest 5 – 128-битный алгоритм хеширования, разработанный профессором Рональдом
MD5
англ. Message Digest 5 – 128-битный алгоритм хеширования, разработанный профессором Рональдом

1. Выравнивание потока.
В конец исходного сообщения, длиной L, дописывают единичный
1. Выравнивание потока.
В конец исходного сообщения, длиной L, дописывают единичный

Последовательность байт может быть интерпретирована как последовательность 32-битных слов, где каждая
Последовательность байт может быть интерпретирована как последовательность 32-битных слов, где каждая

3. Инициализация буфера.
Для вычислений инициализируются 4 переменных размером по 32 бита
3. Инициализация буфера.
Для вычислений инициализируются 4 переменных размером по 32 бита
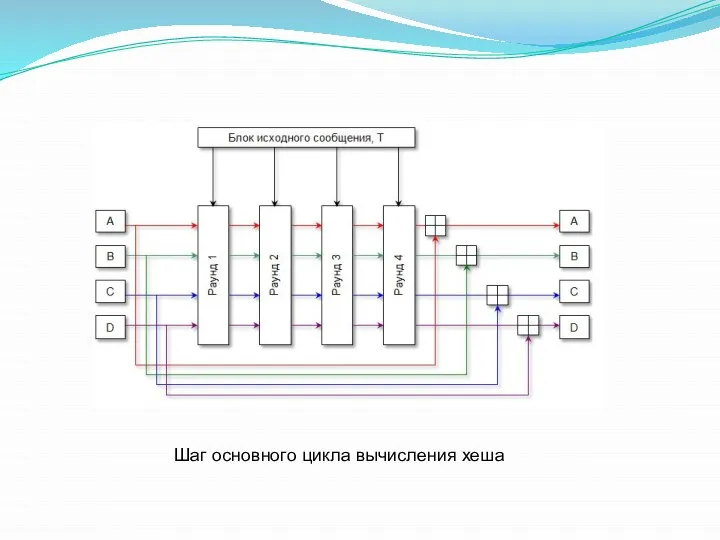
Шаг основного цикла вычисления хеша
Шаг основного цикла вычисления хеша
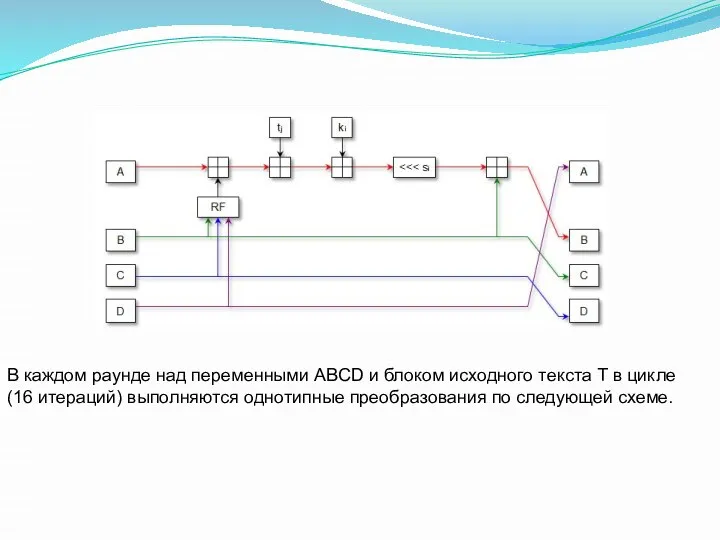
В каждом раунде над переменными ABCD и блоком исходного текста Т
В каждом раунде над переменными ABCD и блоком исходного текста Т

3) ki - целая часть константы, определяемой по формуле
ki = 232
3) ki - целая часть константы, определяемой по формуле
ki = 232
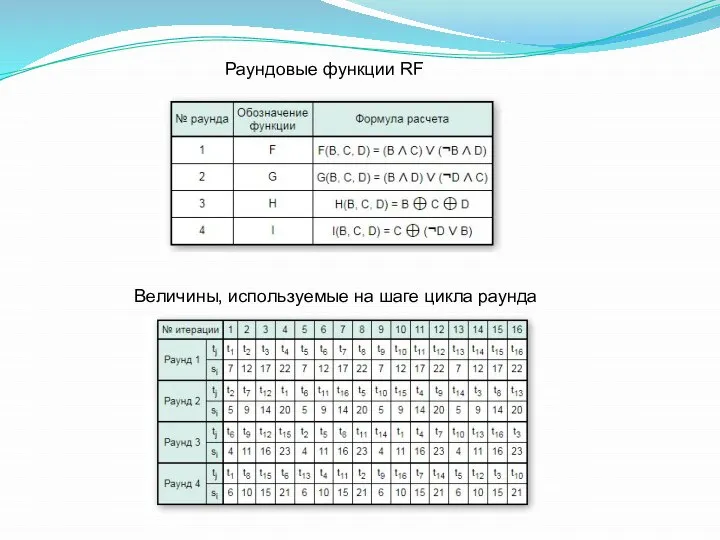
Величины, используемые на шаге цикла раунда
Раундовые функции RF
Величины, используемые на шаге цикла раунда
Раундовые функции RF
 Алгоритм. Свойства алгоритма. Исполнители
Алгоритм. Свойства алгоритма. Исполнители История счета и систем счисления
История счета и систем счисления Точки доступа Wi-Fi
Точки доступа Wi-Fi Konstanty_C
Konstanty_C Алфавит и словарь языка Паскаль Учитель информатики Абдулзагирова А.И.
Алфавит и словарь языка Паскаль Учитель информатики Абдулзагирова А.И. Модификатор Edit Poly. Общие сведения. Полигональное моделирование
Модификатор Edit Poly. Общие сведения. Полигональное моделирование Архитектура вычислительной сети. Модель OSI
Архитектура вычислительной сети. Модель OSI Обработка печатных изданий
Обработка печатных изданий Графический редактор PAINT
Графический редактор PAINT Endpoint Security and Analysis
Endpoint Security and Analysis Электронные таблицы
Электронные таблицы ПРЕЗЕНТАЦИЯ НА ТЕМУ «ВЫЧИСЛИТЕЛЬНАЯ ТЕХНИКА ЧЕТВЁРТОГО ПОКОЛЕНИЯ»
ПРЕЗЕНТАЦИЯ НА ТЕМУ «ВЫЧИСЛИТЕЛЬНАЯ ТЕХНИКА ЧЕТВЁРТОГО ПОКОЛЕНИЯ»  Кодирование звуковой информации. 9 класс
Кодирование звуковой информации. 9 класс Подключение к интернету
Подключение к интернету Файл и файловая система То, что маленький компьютер может сделать, имея большую программу, большой компьютер сделает малую, отсюд
Файл и файловая система То, что маленький компьютер может сделать, имея большую программу, большой компьютер сделает малую, отсюд Логическое программирование
Логическое программирование Компьютерные сети
Компьютерные сети Язык запросов SQL. Введение. (Лекция 6, 7)
Язык запросов SQL. Введение. (Лекция 6, 7) Презентация "Электронный учебник по Adobe Photoshop" - скачать презентации по Информатике
Презентация "Электронный учебник по Adobe Photoshop" - скачать презентации по Информатике Janito. Этапы разработки
Janito. Этапы разработки Turbo Pascal Степаненко Татьяна Николаевна учитель информатики МБОУ «Гимназии»
Turbo Pascal Степаненко Татьяна Николаевна учитель информатики МБОУ «Гимназии»  Электронный документ и файл. Подготовил работу Ученик 11 класса Б Джемалиев Эдиль. Проверила: Кардаш Светлана Ивановна
Электронный документ и файл. Подготовил работу Ученик 11 класса Б Джемалиев Эдиль. Проверила: Кардаш Светлана Ивановна  B×+ Disponible. Apoyo venta en Elementia
B×+ Disponible. Apoyo venta en Elementia Основы работы в векторном редакторе Corel Draw. Графические эффекты
Основы работы в векторном редакторе Corel Draw. Графические эффекты Протоколы маршрутизации
Протоколы маршрутизации Технология автоматизированной обработки текстовой информации
Технология автоматизированной обработки текстовой информации Функции тележурналистики
Функции тележурналистики Прибыль слов
Прибыль слов