- Микросхемы процессоров и шины

Содержание
- 2. Микросхемы процессоров Выводы микросхемы ЦП: адресные информационные управляющие Эти выводы связаны с соответствующими выводами на микросхемах
- 3. Микросхемы процессоров Вызов команды: ЦП посылает в память адрес этой команды по адресным выводам. Затем ЦП
- 4. Микросхемы процессоров Производительность ЦП определяется: числом адресных выводов m адресных выводов =>м/обратиться к 2^m ячеек памяти
- 5. Микросхемы процессоров Управляющие выводы позволяют регулировать и синхронизировать поток данных к процессору и от него, а
- 6. Микросхемы процессоров арбитраж шины [выводы арбитража нужны для регулировки потока информации в шине, т.е. для исключения
- 7. Микросхемы процессоров Цоколевка типичного ЦП. Цоколевка – значение сигналов на различных выводах Стрелками обозначены входные и
- 8. Компьютерные шины Шина – это несколько проводников, соединяющих несколько устройств: могут быть внутренними по отношению к
- 9. Компьютерные шины Компьютерная система с несколькими шинами Когда тип всех битов одинаков, например все адресные или
- 10. Компьютерные шины Протокол шины – правила о том, как работает шина и все устройства, связанные с
- 11. Компьютерные шины Как работают шины: некоторые устройства, соединенные с шиной, являются активными и могут инициировать передачу
- 12. Компьютерные шины Задающие устройства обычно связаны с шиной через микросхему, которая называется драйвером шины (является цифровым
- 13. Ширина шины Ширина (количество адресных линий) шины – самый очевидный параметр при проектировании. Чем больше адресных
- 14. Ширина шины Расширение адресной шины с течением времени 1 Мбайт памяти 16 Мбайт памяти
- 15. Ширина шины Пропускную способность шины можно увеличить двумя способами: сократить время цикла шины (сделать большее количество
- 16. Ширина шины Решение: мультиплексная шина. нет разделения на адресные и информационные линии Может быть, например, 32
- 17. Синхронизация шины В зависимости от их синхронизации Синхронная шина содержит линию, которая запускается кварцевым генератором: cигнал
- 18. Временная диаграмма процесса считывания на синхронной шине Задающий генератор на 100 МГц, который дает цикл шины
- 19. Временная диаграмма процесса считывания на синхронной шине Сочетание ограничений на TAD и TDS означает, что в
- 20. Синхронные шины (пример) Для чтения слова понадобится три цикла шины: 1. За время Т1 центральный процессор
- 21. Синхронные шины Plus: удобно использовать благодаря дискретным временным интервалам синхронную систему построить проще, чем асинхронную разработку
- 22. Асинхронные шины Работа асинхронной шины не привязывается к генератору. Когда задающее устройство устанавливает адрес, сигнал MREQ,
- 23. Асинхронные шины Сигнал SSYN сообщает задающему устройству, что данные доступны. Он фиксирует их, а затем сбрасывает
- 24. Асинхронные шины Набор таких взаимообусловленных сигналов называется полным квитированием: Установка сигнала MSYN. Установка сигнала SSYN в
- 25. Арбитраж шины Что происходит, когда задающим устройством шины становятся два или более устройств одновременно? [микросхемы вода-вывода,
- 26. Арбитраж шины Когда арбитр обнаруживает запрос шины, он устанавливает линию предоставления шины, которая последовательно связывает все
- 27. Арбитраж шины Каждое устройство связано с одним из уровней запроса шины, причем чем выше уровень приоритета,
- 28. Арбитраж шины Некоторые арбитры содержат третью линию, которая устанавливается, как только устройство принимает сигнал предоставления шины,
- 29. Арбитраж шины В системах, где память связана с главной шиной, ЦП должен конкурировать со всеми устройствами
- 30. Арбитраж шины Децентрализованный арбитраж шины Например, компьютер может содержать 16 приоритетных линий запроса шины. Когда устройству
- 31. Арбитраж шины Децентрализованный арбитраж шины (II): используются только три линии независимо от того, сколько устройств имеется
- 32. Арбитраж шины Когда шина не требуется ни одному из устройств, линия арбитража передает сигнал всем устройствам.
- 33. Принципы работы шины Передача блоками может быть более эффективна, чем последовательная передача информации, когда за раз
- 34. Принципы работы шины BLOCK – указывает, что запрашивается передача блока. В данном примере считывание блока из
- 35. Принципы работы шины Системы с двумя или несколькими ЦП на одной шине: в конкретный момент только
- 36. Принципы работы шины Цикл обработки прерываний: Когда центральный процессор командует устройству ввода-вывода произвести какое-то действие, он
- 37. Принципы работы шины До восьми контроллеров ввода-вывода могут быть непосредственно связаны с восемью входами IRx (Interrupt
- 38. Принципы работы шины Если ЦП способен обработать прерывание, он посылает микросхеме 8259А импульс через вывод INTA
- 39. Принципы работы шины Микросхема 8259А содержит несколько регистров, которые ЦП может считывать и записывать, используя обычные
- 40. Принципы работы шины При наличии более 8 устройств ввода-вывода, микросхемы 8259А могут соединяться каскадом. [все 8
- 41. Цоколевка процессора Core i7 Из 1155 контактов Core i7 для сигналов используются 447, для питания (с
- 42. Цоколевка процессора Core i7 =>Каналы памяти DDR № 1, № 2: используются для взаимодействия с DDR3-совместимой
- 43. Цоколевка процессора Core i7 Прерывания Core i7: может осуществлять тем же способом, что и 8088 (это
- 44. Цоколевка процессора Core i7 Группа сигналов тактовой частоты отвечает за определение частоты системной шины. Группа диагностических
- 45. Конвейерный режим шины памяти DDR3 процессора Core i7 Запросы к памяти состоят из трех этапов: Фаза
- 46. Конвейерный режим шины памяти DDR3 процессора Core i7 Идея работы: Динамическая память DDR3 состоит из нескольких
- 47. Конвейерный режим шины памяти DDR3 процессора Core i7 Core i7 выдает 3 обращения к трем разным
- 48. Конвейерный режим шины памяти DDR3 процессора Core i7 СК – управляет всей работой шины. CMD –
- 49. Конвейерный режим шины памяти DDR3 процессора Core i7 В нашем примере: => команда ACT должна предшествовать
- 50. Шина PCI PCI (Peripheral Component Interconnect — взаимодействие периферийных компонентов), [1990 г, компания Intel] Шина PCI
- 51. Шина PCI Платы PCI отличаются: потребляемой мощностью [cтарые компьютеры обычно используют напряжение 5 В, а новые
- 52. Шина PCI Структура шин в современной системе Core i7 Р67 предоставляет интерфейс к нескольким современным высокопроизводительным
- 53. Работа шины PCI Шины PCI являются синхронными Все транзакции в шине PCI осуществляются между задающим и
- 54. Арбитраж шины PCI REQ# – запрос шины GNT# – получение разрешения на доступ к шине. У
- 55. Арбитраж шины PCI Транзакции: шина предоставляется для одной транзакции [продолжительность транзакции теоретически не ограничена] между транзакциями
- 56. Обязательные сигналы шины PCI (32-разрядные сигналы)
- 57. Обязательные сигналы шины PCI (32-разрядные сигналы)
- 58. Обязательные сигналы шины PCI
- 59. Обязательные сигналы шины PCI
- 60. Транзакции на шине PCI Примеры 32-разрядных транзакций на шине PCI. Во время первых трех циклов происходит
- 62. Скачать презентацию

Микросхемы процессоров
Выводы микросхемы ЦП:
адресные
информационные
управляющие
Эти выводы связаны
Микросхемы процессоров
Выводы микросхемы ЦП:
адресные
информационные
управляющие
Эти выводы связаны

Микросхемы процессоров
Вызов команды:
ЦП посылает в память адрес этой команды по адресным
Микросхемы процессоров
Вызов команды:
ЦП посылает в память адрес этой команды по адресным

Микросхемы процессоров
Производительность ЦП определяется:
числом адресных выводов
m адресных выводов =>м/обратиться к
Микросхемы процессоров
Производительность ЦП определяется:
числом адресных выводов
m адресных выводов =>м/обратиться к

Микросхемы процессоров
Управляющие выводы позволяют регулировать и синхронизировать поток данных к процессору
Микросхемы процессоров
Управляющие выводы позволяют регулировать и синхронизировать поток данных к процессору

Микросхемы процессоров
арбитраж шины [выводы арбитража нужны для регулировки потока информации в
Микросхемы процессоров
арбитраж шины [выводы арбитража нужны для регулировки потока информации в

Микросхемы процессоров
Цоколевка типичного ЦП.
Цоколевка – значение сигналов на различных выводах
Стрелками
Микросхемы процессоров
Цоколевка типичного ЦП.
Цоколевка – значение сигналов на различных выводах
Стрелками

Компьютерные шины
Шина – это несколько проводников, соединяющих несколько устройств:
могут быть внутренними
Компьютерные шины
Шина – это несколько проводников, соединяющих несколько устройств:
могут быть внутренними

Компьютерные шины
Компьютерная система с несколькими шинами
Когда тип всех битов одинаков, например
Компьютерные шины
Компьютерная система с несколькими шинами
Когда тип всех битов одинаков, например

Компьютерные шины
Протокол шины – правила о том, как работает шина и
Компьютерные шины
Протокол шины – правила о том, как работает шина и

Компьютерные шины
Как работают шины: некоторые устройства, соединенные с шиной, являются активными
Компьютерные шины
Как работают шины: некоторые устройства, соединенные с шиной, являются активными

Компьютерные шины
Задающие устройства обычно связаны с шиной через микросхему, которая называется
Компьютерные шины
Задающие устройства обычно связаны с шиной через микросхему, которая называется

Ширина шины
Ширина (количество адресных линий) шины – самый очевидный параметр при
Ширина шины
Ширина (количество адресных линий) шины – самый очевидный параметр при

Ширина шины
Расширение адресной шины с течением времени
1 Мбайт памяти
16 Мбайт памяти
Ширина шины
Расширение адресной шины с течением времени
1 Мбайт памяти
16 Мбайт памяти

Ширина шины
Пропускную способность шины можно увеличить двумя способами:
сократить время цикла шины
Ширина шины
Пропускную способность шины можно увеличить двумя способами:
сократить время цикла шины

Ширина шины
Решение: мультиплексная шина.
нет разделения на адресные и информационные линии
Может
Ширина шины
Решение: мультиплексная шина.
нет разделения на адресные и информационные линии
Может

Синхронизация шины
В зависимости от их синхронизации
Синхронная шина содержит линию, которая запускается
Синхронизация шины
В зависимости от их синхронизации
Синхронная шина содержит линию, которая запускается

Временная диаграмма процесса считывания на синхронной шине
Задающий генератор на
100 МГц,
Временная диаграмма процесса считывания на синхронной шине
Задающий генератор на 100 МГц,

Временная диаграмма процесса считывания на синхронной шине
Сочетание ограничений на TAD и
Временная диаграмма процесса считывания на синхронной шине
Сочетание ограничений на TAD и

Синхронные шины (пример)
Для чтения слова понадобится три цикла шины:
1. За время
Синхронные шины (пример)
Для чтения слова понадобится три цикла шины:
1. За время

Синхронные шины
Plus:
удобно использовать благодаря дискретным временным интервалам
синхронную систему построить
Синхронные шины
Plus:
удобно использовать благодаря дискретным временным интервалам
синхронную систему построить

Асинхронные шины
Работа асинхронной шины не привязывается к генератору.
Когда задающее устройство
Асинхронные шины
Работа асинхронной шины не привязывается к генератору.
Когда задающее устройство

Асинхронные шины
Сигнал SSYN сообщает задающему устройству, что данные доступны. Он фиксирует
Асинхронные шины
Сигнал SSYN сообщает задающему устройству, что данные доступны. Он фиксирует

Асинхронные шины
Набор таких взаимообусловленных сигналов называется полным квитированием:
Установка сигнала MSYN.
Установка
Асинхронные шины
Набор таких взаимообусловленных сигналов называется полным квитированием:
Установка сигнала MSYN.
Установка

Арбитраж шины
Что происходит, когда задающим устройством шины становятся два или более
Арбитраж шины
Что происходит, когда задающим устройством шины становятся два или более

Арбитраж шины
Когда арбитр обнаруживает запрос шины, он устанавливает линию предоставления шины,
Арбитраж шины
Когда арбитр обнаруживает запрос шины, он устанавливает линию предоставления шины,

Арбитраж шины
Каждое устройство связано с одним из уровней запроса шины, причем
Арбитраж шины
Каждое устройство связано с одним из уровней запроса шины, причем

Арбитраж шины
Некоторые арбитры содержат третью линию, которая устанавливается, как только устройство
Арбитраж шины
Некоторые арбитры содержат третью линию, которая устанавливается, как только устройство

Арбитраж шины
В системах, где память связана с главной шиной, ЦП должен
Арбитраж шины
В системах, где память связана с главной шиной, ЦП должен

Арбитраж шины
Децентрализованный арбитраж шины
Например, компьютер может содержать 16 приоритетных линий запроса
Арбитраж шины
Децентрализованный арбитраж шины
Например, компьютер может содержать 16 приоритетных линий запроса

Арбитраж шины
Децентрализованный арбитраж шины (II): используются только три линии независимо от
Арбитраж шины
Децентрализованный арбитраж шины (II): используются только три линии независимо от

Арбитраж шины
Когда шина не требуется ни одному из устройств, линия арбитража
Арбитраж шины
Когда шина не требуется ни одному из устройств, линия арбитража

Принципы работы шины
Передача блоками может быть более эффективна, чем последовательная передача
Принципы работы шины
Передача блоками может быть более эффективна, чем последовательная передача

Принципы работы шины
BLOCK – указывает, что запрашивается передача блока.
В данном
Принципы работы шины
BLOCK – указывает, что запрашивается передача блока.
В данном

Принципы работы шины
Системы с двумя или несколькими ЦП на одной шине:
в
Принципы работы шины
Системы с двумя или несколькими ЦП на одной шине:
в

Принципы работы шины
Цикл обработки прерываний:
Когда центральный процессор командует устройству ввода-вывода произвести
Принципы работы шины
Цикл обработки прерываний:
Когда центральный процессор командует устройству ввода-вывода произвести

Принципы работы шины
До восьми контроллеров ввода-вывода могут быть непосредственно связаны с
Принципы работы шины
До восьми контроллеров ввода-вывода могут быть непосредственно связаны с

Принципы работы шины
Если ЦП способен обработать прерывание, он посылает микросхеме 8259А
Принципы работы шины
Если ЦП способен обработать прерывание, он посылает микросхеме 8259А

Принципы работы шины
Микросхема 8259А содержит несколько регистров, которые ЦП может считывать
Принципы работы шины
Микросхема 8259А содержит несколько регистров, которые ЦП может считывать

Принципы работы шины
При наличии более 8 устройств ввода-вывода, микросхемы 8259А могут
Принципы работы шины
При наличии более 8 устройств ввода-вывода, микросхемы 8259А могут

Цоколевка процессора Core i7
Из 1155 контактов Core i7 для сигналов используются
Цоколевка процессора Core i7
Из 1155 контактов Core i7 для сигналов используются

Цоколевка процессора Core i7
=>Каналы памяти DDR № 1, № 2: используются
Цоколевка процессора Core i7
=>Каналы памяти DDR № 1, № 2: используются

Цоколевка процессора Core i7
Прерывания Core i7:
может осуществлять тем же способом, что
Цоколевка процессора Core i7
Прерывания Core i7:
может осуществлять тем же способом, что

Цоколевка процессора Core i7
Группа сигналов тактовой частоты отвечает за определение частоты
Цоколевка процессора Core i7
Группа сигналов тактовой частоты отвечает за определение частоты

Конвейерный режим шины памяти DDR3 процессора Core i7
Запросы к памяти состоят
Конвейерный режим шины памяти DDR3 процессора Core i7
Запросы к памяти состоят

Конвейерный режим шины памяти DDR3 процессора Core i7
Идея работы:
Динамическая память
Конвейерный режим шины памяти DDR3 процессора Core i7
Идея работы:
Динамическая память

Конвейерный режим шины памяти DDR3 процессора Core i7
Core i7 выдает 3
Конвейерный режим шины памяти DDR3 процессора Core i7
Core i7 выдает 3

Конвейерный режим шины памяти DDR3 процессора Core i7
СК – управляет всей
Конвейерный режим шины памяти DDR3 процессора Core i7
СК – управляет всей

Конвейерный режим шины памяти DDR3 процессора Core i7
В нашем примере:
=> команда
Конвейерный режим шины памяти DDR3 процессора Core i7
В нашем примере:
=> команда
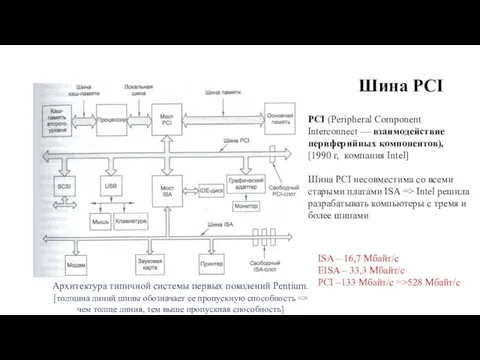
Шина PCI
PCI (Peripheral Component Interconnect — взаимодействие периферийных компонентов),
[1990 г, компания
Шина PCI
PCI (Peripheral Component Interconnect — взаимодействие периферийных компонентов),
[1990 г, компания

Шина PCI
Платы PCI отличаются:
потребляемой мощностью
[cтарые компьютеры обычно используют напряжение 5
Шина PCI
Платы PCI отличаются:
потребляемой мощностью
[cтарые компьютеры обычно используют напряжение 5

Шина PCI
Структура шин в современной системе Core i7
Р67 предоставляет интерфейс к
Шина PCI
Структура шин в современной системе Core i7
Р67 предоставляет интерфейс к

Работа шины PCI
Шины PCI являются синхронными
Все транзакции в шине PCI осуществляются
Работа шины PCI
Шины PCI являются синхронными
Все транзакции в шине PCI осуществляются

Арбитраж шины PCI
REQ# – запрос шины
GNT# – получение разрешения на доступ
Арбитраж шины PCI
REQ# – запрос шины
GNT# – получение разрешения на доступ

Арбитраж шины PCI
Транзакции:
шина предоставляется для одной транзакции
[продолжительность транзакции теоретически не ограничена]
Арбитраж шины PCI
Транзакции:
шина предоставляется для одной транзакции
[продолжительность транзакции теоретически не ограничена]
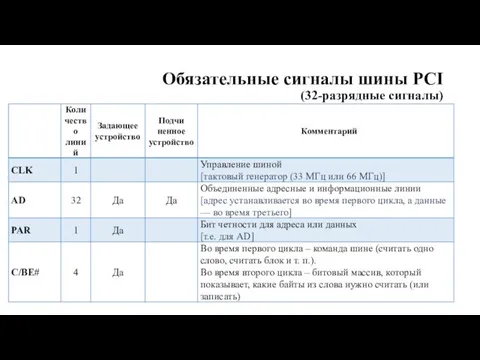
Обязательные сигналы шины PCI
(32-разрядные сигналы)
Обязательные сигналы шины PCI
(32-разрядные сигналы)
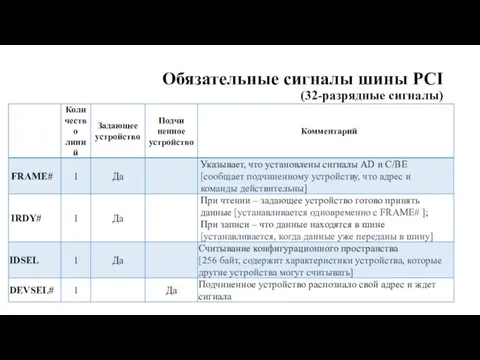
Обязательные сигналы шины PCI
(32-разрядные сигналы)
Обязательные сигналы шины PCI
(32-разрядные сигналы)
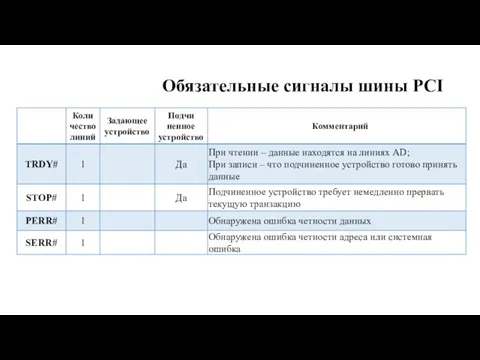
Обязательные сигналы шины PCI
Обязательные сигналы шины PCI
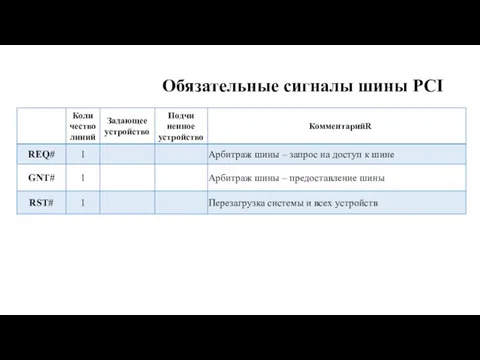
Обязательные сигналы шины PCI
Обязательные сигналы шины PCI
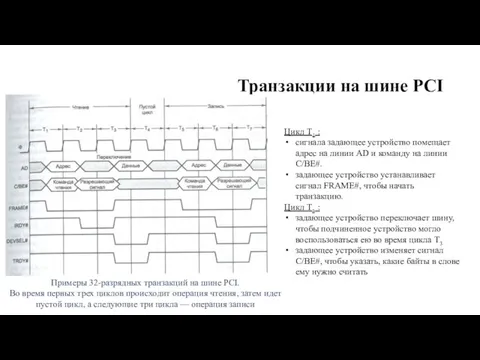
Транзакции на шине PCI
Примеры 32-разрядных транзакций на шине PCI.
Во время
Транзакции на шине PCI
Примеры 32-разрядных транзакций на шине PCI.
Во время
 КОМПЬЮТЕРНАЯ БЕЗОПАСНОСТЬ
КОМПЬЮТЕРНАЯ БЕЗОПАСНОСТЬ  Роберт Бончек
Роберт Бончек Папки и Файлы
Папки и Файлы Матрица смежности
Матрица смежности Free РРТ templates
Free РРТ templates Компьютерные вирусы: методы распространения, профилактика заражения
Компьютерные вирусы: методы распространения, профилактика заражения Текстовый редактор (процессор) Microsoft Word Основные возможности и назначение
Текстовый редактор (процессор) Microsoft Word Основные возможности и назначение  Минин Виктор Член Правления Союза ИТ-директоров России Сопредседатель комитета по информационной безопасности
Минин Виктор Член Правления Союза ИТ-директоров России Сопредседатель комитета по информационной безопасности Кодирование текстовой информации
Кодирование текстовой информации Презентация "Текстовый редактор MS Word (7 класс)" - скачать презентации по Информатике
Презентация "Текстовый редактор MS Word (7 класс)" - скачать презентации по Информатике Измерение информации (Алфавитный подход)
Измерение информации (Алфавитный подход) Векторная графика
Векторная графика Презентация "Логическая структура дисков" - скачать презентации по Информатике
Презентация "Логическая структура дисков" - скачать презентации по Информатике Всемирная паутина. Информация и информационные процессы
Всемирная паутина. Информация и информационные процессы Тестирование в мире IT
Тестирование в мире IT Основы HTML
Основы HTML Язык программирования Pascal
Язык программирования Pascal Развитие редакции 2.0 конфигурации 1С:Бухгалтерия государственного учреждения 8
Развитие редакции 2.0 конфигурации 1С:Бухгалтерия государственного учреждения 8 Компьютерные системы поддержки принятия решений
Компьютерные системы поддержки принятия решений Классификация ИС
Классификация ИС О котах
О котах Кодирование текстовой информации
Кодирование текстовой информации Единая информационная система. Электронный документооборот
Единая информационная система. Электронный документооборот Реализация дистанционного образования на базе технологий RoWeb и ЛиК
Реализация дистанционного образования на базе технологий RoWeb и ЛиК Самомассаж с применением шарика су -джок
Самомассаж с применением шарика су -джок Аттестационная работа. Программа внеурочной деятельности по информатике Информашка
Аттестационная работа. Программа внеурочной деятельности по информатике Информашка АЛГОРИТМЫ Способы представления алгоритмов
АЛГОРИТМЫ Способы представления алгоритмов Презентация "Пассивная система охлаждения" - скачать презентации по Информатике
Презентация "Пассивная система охлаждения" - скачать презентации по Информатике