- Modern IT Tools and Methods. Lecture 7 - Games

Содержание
- 2. Outline Optimal decisions α-β pruning Imperfect, real-time decisions
- 3. Games vs. search problems "Unpredictable" opponent ? specifying a move for every possible opponent reply Time
- 4. Game tree (2-player, deterministic, turns)
- 5. Minimax Perfect play for deterministic games Idea: choose move to position with highest minimax value =
- 6. Minimax algorithm
- 7. Properties of minimax Complete? Yes (if tree is finite) Optimal? Yes (against an optimal opponent) Time
- 8. α-β pruning example
- 9. α-β pruning example
- 10. α-β pruning example
- 11. α-β pruning example
- 12. α-β pruning example
- 13. Properties of α-β Pruning does not affect final result Good move ordering improves effectiveness of pruning
- 14. Why is it called α-β? α is the value of the best (i.e., highest-value) choice found
- 15. The α-β algorithm
- 16. The α-β algorithm
- 17. Resource limits Suppose we have 100 secs, explore 104 nodes/sec ? 106 nodes per move Standard
- 18. Evaluation functions For chess, typically linear weighted sum of features Eval(s) = w1 f1(s) + w2
- 19. Cutting off search MinimaxCutoff is identical to MinimaxValue except Terminal? is replaced by Cutoff? Utility is
- 20. Deterministic games in practice Checkers: Chinook ended 40-year-reign of human world champion Marion Tinsley in 1994.
- 22. Скачать презентацию

Outline
Optimal decisions
α-β pruning
Imperfect, real-time decisions
Outline
Optimal decisions
α-β pruning
Imperfect, real-time decisions

Games vs. search problems
"Unpredictable" opponent ? specifying a move for every
Games vs. search problems
"Unpredictable" opponent ? specifying a move for every
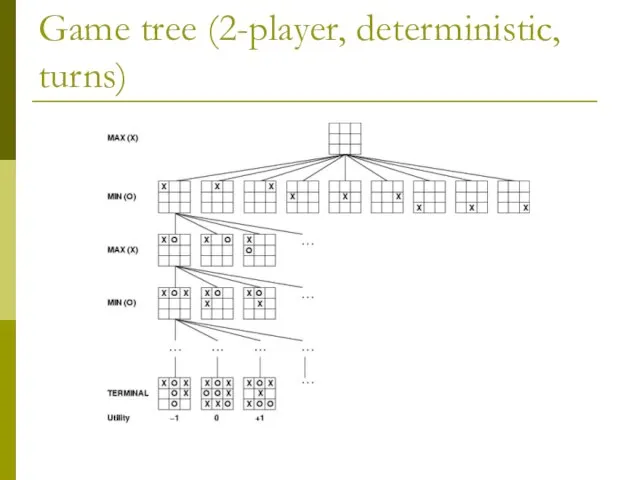
Game tree (2-player, deterministic, turns)
Game tree (2-player, deterministic, turns)
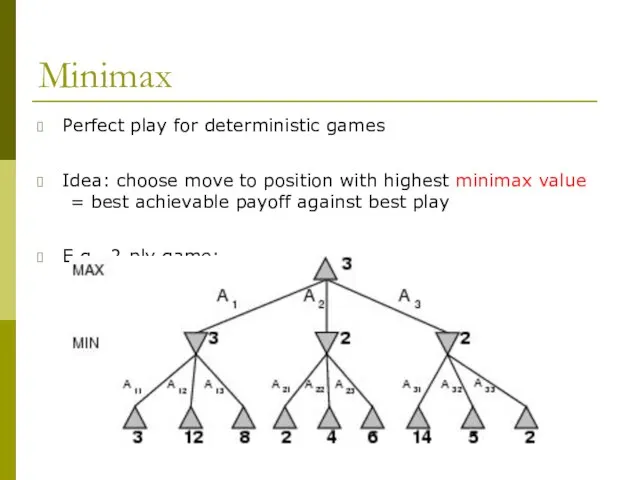
Minimax
Perfect play for deterministic games
Idea: choose move to position with highest
Minimax
Perfect play for deterministic games
Idea: choose move to position with highest

Minimax algorithm
Minimax algorithm

Properties of minimax
Complete? Yes (if tree is finite)
Optimal? Yes (against an
Properties of minimax
Complete? Yes (if tree is finite)
Optimal? Yes (against an
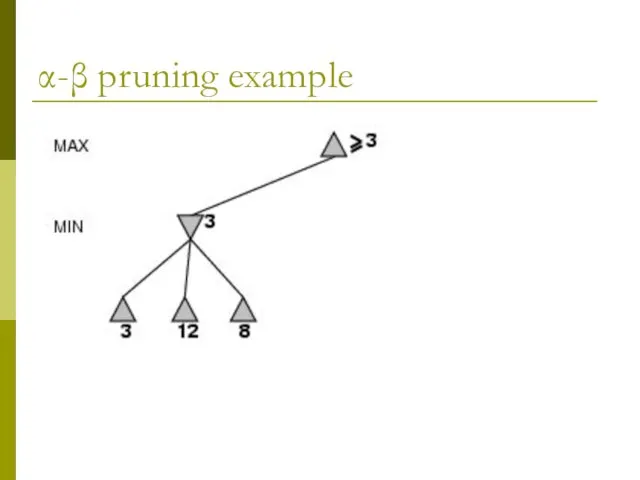
α-β pruning example
α-β pruning example
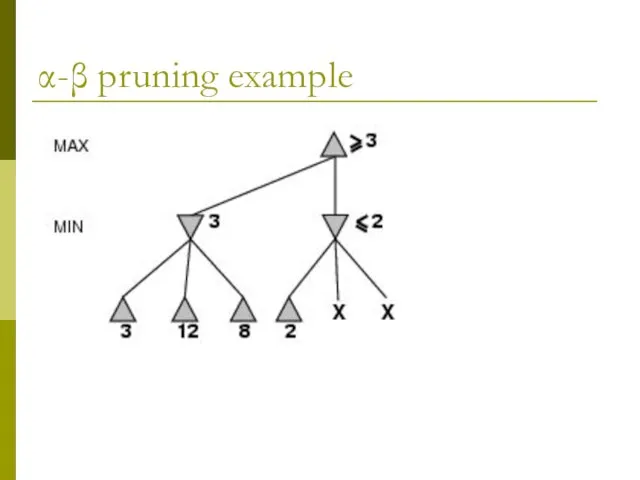
α-β pruning example
α-β pruning example
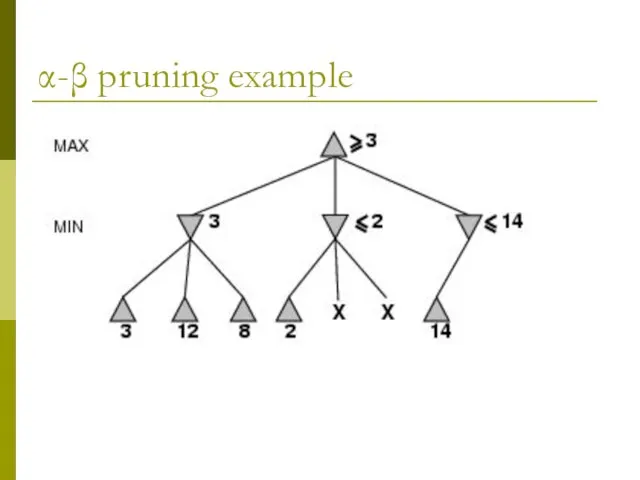
α-β pruning example
α-β pruning example
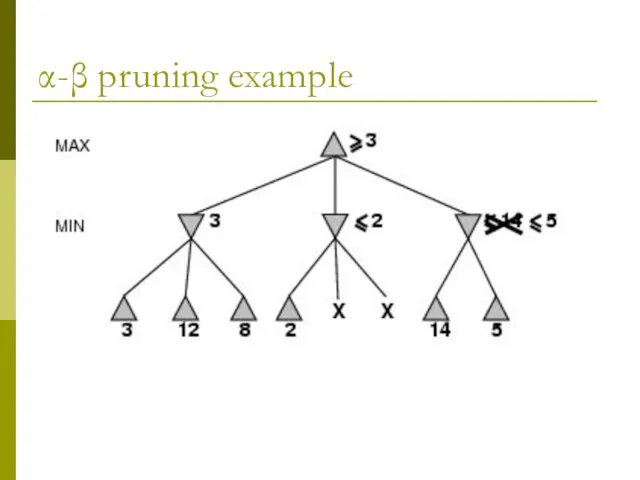
α-β pruning example
α-β pruning example
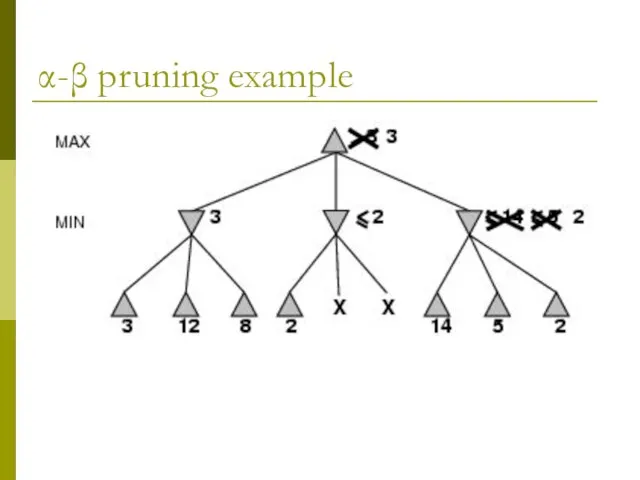
α-β pruning example
α-β pruning example

Properties of α-β
Pruning does not affect final result
Good move ordering improves
Properties of α-β
Pruning does not affect final result
Good move ordering improves
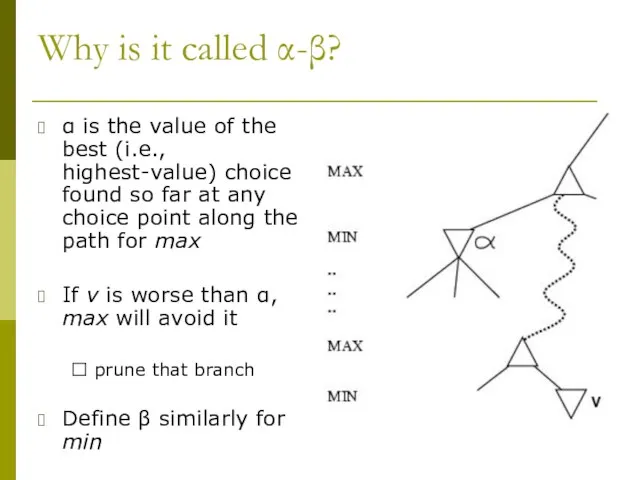
Why is it called α-β?
α is the value of the best
Why is it called α-β?
α is the value of the best

The α-β algorithm
The α-β algorithm

The α-β algorithm
The α-β algorithm

Resource limits
Suppose we have 100 secs, explore 104 nodes/sec
? 106 nodes
Resource limits
Suppose we have 100 secs, explore 104 nodes/sec ? 106 nodes

Evaluation functions
For chess, typically linear weighted sum of features
Eval(s) = w1
Evaluation functions
For chess, typically linear weighted sum of features
Eval(s) = w1

Cutting off search
MinimaxCutoff is identical to MinimaxValue except
Terminal? is replaced by
Cutting off search
MinimaxCutoff is identical to MinimaxValue except
Terminal? is replaced by

Deterministic games in practice
Checkers: Chinook ended 40-year-reign of human world champion
Deterministic games in practice
Checkers: Chinook ended 40-year-reign of human world champion
 Семинары по подготовке к Олимпиаде D-Link по сетевым технологиям
Семинары по подготовке к Олимпиаде D-Link по сетевым технологиям Создаем БД. Практические задания
Создаем БД. Практические задания Кодирование звуковой информации
Кодирование звуковой информации Алфавитный подход к измерению количества информации
Алфавитный подход к измерению количества информации Презентация по информатике Палитры цветов в системах цветопередачи RGB, CMYK и HSB
Презентация по информатике Палитры цветов в системах цветопередачи RGB, CMYK и HSB  Шифрование. Распределение ключа
Шифрование. Распределение ключа Программирование алгоритмов на языке Python. Работа с файлами
Программирование алгоритмов на языке Python. Работа с файлами Вещественный тип данных, указатели, функции
Вещественный тип данных, указатели, функции Компас 3D LT
Компас 3D LT Инструменты для разработки веб-сайтов
Инструменты для разработки веб-сайтов Компьютер – универсальная техническая система обработки информации
Компьютер – универсальная техническая система обработки информации Представление информации в форме таблиц
Представление информации в форме таблиц CMS системы (2 занятие)
CMS системы (2 занятие) Основные принципы построения операционных систем
Основные принципы построения операционных систем Архитектура Персонального компьютера
Архитектура Персонального компьютера  Основные понятия технологии проектирования информационных систем (ИС)
Основные понятия технологии проектирования информационных систем (ИС) Удивительный мир научных книг. Виталий Исаакович Рыдник Многоцветье спектров
Удивительный мир научных книг. Виталий Исаакович Рыдник Многоцветье спектров Основные понятия ACCESS. Назначения и возможности
Основные понятия ACCESS. Назначения и возможности Можно ли научиться играть на музыкальном инструменте, играя в музыкальные игры
Можно ли научиться играть на музыкальном инструменте, играя в музыкальные игры Лекция 2 ТИПЫ ДАННЫХ (ПРОСТЫЕ ТИПЫ)
Лекция 2 ТИПЫ ДАННЫХ (ПРОСТЫЕ ТИПЫ)  Циклические коды
Циклические коды Корпоративные информационные системы и проблемы интеграции информационной среды Лекция № почти последняя + Кузенкова Г.В.
Корпоративные информационные системы и проблемы интеграции информационной среды Лекция № почти последняя + Кузенкова Г.В.  Заполнение регистрационной анкеты
Заполнение регистрационной анкеты Выполнение алгоритмов компьютером
Выполнение алгоритмов компьютером Презентация "задачи компьютерной лингвистики" - скачать презентации по Информатике
Презентация "задачи компьютерной лингвистики" - скачать презентации по Информатике Информационный лабиринт. Игра
Информационный лабиринт. Игра Основные части вычислительной системы
Основные части вычислительной системы Презентация на тему Основы работы с файловым менеджером total comander
Презентация на тему Основы работы с файловым менеджером total comander