- Организация поиска. Хеширование

Содержание
- 2. Словарные операции поиск элемента х; добавление нового элемента х; удаление элемента х. Структуры данных для выполнения
- 3. Абстрактный тип данных: множество (set) Абстрактный тип данных: ассоциативный массив (map) Структуры данных на основе хеш-таблиц
- 4. Для простоты будем считать, что ключи являются целыми числами из диапазона [0, N). Обозначим через K
- 5. 1. Прямая адресация Если достаточно памяти для массива, число элементов которого равно числу всех возможных ключей,
- 6. размер таблицы с прямой адресацией не зависит от того, сколько элементов реально содержится в множестве; если
- 7. 2. Хеш-функция (англ. hash function) Введём некоторую функцию, называемую хеш-функцией, которая отображает множество ключей в некоторое
- 8. является вполне годной для практики хеш-функцией и часто применяется; любая пара различных ключей будет давать коллизию;
- 9. Велика ли вероятность коллизий? Пусть осуществляется хеширование для n различных ключей, т.е. мы строим вектор длины
- 11. или
- 12. Разработано несколько стратегий разрешения коллизий Разрешение коллизий методом цепочек (англ. separate chaining) Разрешение коллизий методом открытой
- 13. Разрешение коллизий методом цепочек (англ. separate chaining)
- 14. Хеш-функция h раскладывает исходные ключи x по корзинам (англ. bins, buckets) или слотам (англ. slots). ключ
- 15. Операция вставки элемента
- 16. Сначала вычисляется хеш-значение h(x) для ключа x, а затем происходит обращение к соответствующему связному списку. Если
- 17. Операция удаления элемента
- 18. Вычисляем сначала хеш-значение для ключа x: h(45)=5. В общем случае из односвязного списка удалить элемент из
- 19. Таким образом, производительность всей конструкции связана с таким параметром, как длина цепочки. ВНИМАНИЕ Даже если цепочка
- 20. Разрешение коллизий методом открытой адресации (англ. open addressing)
- 21. В линейном массиве хранятся непосредственно ключи, а не заголовки связных списков. В каждой ячейке массива разрешено
- 22. Последовательность проб (англ. probe sequence) Обозначим через h(x,i) номер ячейки в массиве, к которой следует обращаться
- 23. Для успешной работы алгоритмов поиска последовательность проб должна быть такой, чтобы в результате M проб все
- 24. Линейное пробирование Ячейки хеш-таблицы последовательно просматриваются с некоторым фиксированным интервалом c между ячейками: h(x, i) =
- 25. h(x,i)=(x+2·i) mod 10 Например, при x = 5, подставляя i от 0 до 9, будем получать
- 26. Теорема Для того чтобы в ходе M проб все ячейки таблицы оказались просмотренными по одному разу,
- 27. Доказательство. Воспользуемся сведениями из элементарной теории чисел. Докажем необходимость Пусть h(x, i) пробегает все значения от
- 28. Недостаток линейного пробирования проявляется в том, что на реальных данных часто образуются кластеры из занятых ячеек
- 29. Номер ячейки квадратично зависит от номера попытки, расстояние между ячейками с каждой итерацией увеличивается на константу
- 30. Двойное хеширование: h(x,i) = (h'(x) + h"(x) ·i) mod M Последовательность проб при работе с ключом
- 31. Операция вставки элемента
- 32. Перед вставкой ключа x выполняется поиск этого ключа. Если такой элемент x уже есть в таблице,
- 33. Например, при линейном пробировании: h(x,i) = (x+i) mod M, М=10 7, 29, 67, 38, 25, 27,
- 34. Операция поиска элемента Случай 1. Предположим, сначала что в таблице операция удаления элемента НЕ поддерживается.
- 35. Ячейки массива проверяются, в соответствии с той же функцией последовательности проб, которая использовалась при добавлении элементов
- 36. Операция поиска элемента Случай 2. Предположим, что в хеш-таблице поддерживается операция удаления элемента.
- 37. h(x,i)=(x+i) mod M, 7 29 25 67 38 27 18 M=10 Затем выполнили поиск элемента x=18.
- 38. h(x, i) = (x + i) mod M, 7 29 25 67 38 27 18 M=10
- 39. Недостатки открытой адресации
- 40. 1. Нетрудно видеть, что при разрешении коллизий методом открытой адресации наличие большого числа deleted-ячеек отрицательно сказывается
- 41. 2. Число хранимых ключей не может превышать размер хеш-массива (при заполнении на 70% производительность падает и
- 42. Преимущества открытой адресации
- 43. экономия памяти, если размер ключа невелик по сравнению с размером указателя в методе цепочек приходится хранить
- 44. Хеш-таблицы на практике Любой подход к реализации хеш-таблицы может работать достаточно быстро на реальных нагрузках. Время,
- 45. Критически важным показателем для хеш-таблицы является коэффициент заполнения— отношение числа ключей, которые хранятся в хеш-таблице, к
- 46. Реализация хеш-таблицы общего назначения обязана поддерживать операцию изменения размера. На практике часто используемым приёмом является автоматическое
- 47. Объединение хеш-значений Предположим, что координаты точек на плоскости хранятся в виде пар целых чисел (x,y), и
- 48. Пусть для простоты верхняя граница возможных значений хеш-функции не фиксирована (где-то дальше в реализации хеш будет
- 49. Хеширование строк. Полиномиальное хеширование
- 50. Предположим, что на вход поступает строка: S= ‘аbcdb’ → 1,2,3,4,2. Прямой полиномиальный хеш (хеширование слева направо)
- 53. 0 …
- 54. Так как хеш - это значение многочлена, то для многих строковых операций можно быстро пересчитывать хеш
- 57. Применение хеширования строк Т S Т Т
- 58. Проход по содержимому хеш-таблицы В процессе программирования может возникнуть необходимость выполнить обход всех элементов структуры данных
- 59. В большинстве реализаций проход по хеш-множествам выполняется в произвольном порядке, не гарантируется какой-либо отсортированности ключей. В
- 60. Хеш-таблицы в C++
- 61. Долгое время в языке C++ не было стандартных реализаций структур данных на основе хеш-таблиц. Контейнеры std::set
- 62. Наконец, в стандарте C++11 в STL официально были добавлены хеш-таблицы. Стандарт предусматривает четыре контейнера на основе
- 63. В качестве хеш-значения в C++ используется число типа size_t. Все хеш-контейнеры предоставляют метод rehash(), который позволяет
- 64. Рассмотрим более подробно реализацию в компиляторе GCC (GNU Compiler Collection) Пусть ключи добавляются в std::unordered_set по
- 65. Хеш-таблицы в JAVA
- 66. Коллекции HashSet и HashMap реализуются как хеш-таблицы, для разрешения коллизий используется метод цепочек. Для хеширования целых
- 67. В версии Java 8 разработчики озаботились вопросом устойчивости коллекций, использующих хеширование, к коллизиям. В исходном коде
- 68. Хеш-таблицы в PYTHON
- 69. Встроенный тип dict — ассоциативный массив, словарь —широко используется в языке. Он реализован в виде хеш-таблицы,
- 70. Криптографические хеш-функции В криптографии множество K возможных ключей бесконечно, и любой блок данных является ключом (в
- 71. За годы развития вычислительной техники сформировалась наука о том, как практически строить хеш-функции. Разработаны всевозможные правила
- 72. Универсальное хеширование (англ. universal hashing)
- 73. Добавить рандомизацию: внести элемент случайности, чтобы не было фиксированного «плохого» случая. Идея не брать какую-либо одну
- 75. p·(p-1) способ выбрать хеш-функцию из семейства добавление элемента – усреднённо O(1); поиск элемента – математичекое ожидание
- 76. Совершенное хеширование (англ. perfect hashing)
- 77. Пусть S — фактическое множество ключей в хеш-таблице, и у этого множества размер n, где n
- 78. Таким образом, подход заключается в построении хеш-функции, которая является: простой, т.е. достаточно константного объёма памяти, чтобы
- 79. Совершенное двухуровневое хеширование
- 80. Уровень 2 для каждой цепочки строится небольшая вторичная хеш-таблица, чтобы гарантировать отсутствие коллизий на этом уровне
- 81. Общие задачи в iRunner для закрепления навыков 0.5. Хеш-таблица (разрешение коллизий метом открытой адресации)
- 83. Скачать презентацию

Словарные операции
поиск элемента х;
добавление нового элемента х;
удаление элемента х.
Структуры данных
для
Словарные операции
поиск элемента х;
добавление нового элемента х;
удаление элемента х.
Структуры данных
для

Абстрактный тип данных: множество (set)
Абстрактный тип данных: ассоциативный массив (map)
Структуры данных
Абстрактный тип данных: множество (set)
Абстрактный тип данных: ассоциативный массив (map)
Структуры данных

Для простоты будем считать, что ключи являются целыми числами из диапазона
Для простоты будем считать, что ключи являются целыми числами из диапазона

1. Прямая адресация
Если достаточно памяти для массива, число элементов которого равно
1. Прямая адресация
Если достаточно памяти для массива, число элементов которого равно

размер таблицы с прямой адресацией не зависит от того, сколько элементов
размер таблицы с прямой адресацией не зависит от того, сколько элементов

2. Хеш-функция (англ. hash function)
Введём некоторую функцию, называемую хеш-функцией, которая отображает
2. Хеш-функция (англ. hash function)
Введём некоторую функцию, называемую хеш-функцией, которая отображает

является вполне годной для практики хеш-функцией и часто применяется;
любая пара различных
является вполне годной для практики хеш-функцией и часто применяется;
любая пара различных
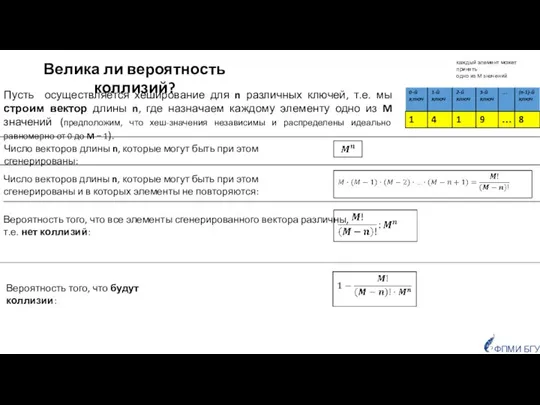
Велика ли вероятность коллизий?
Пусть осуществляется хеширование для n различных ключей, т.е.
Велика ли вероятность коллизий?
Пусть осуществляется хеширование для n различных ключей, т.е.


или
или

Разработано несколько стратегий разрешения коллизий
Разрешение коллизий методом цепочек
(англ. separate chaining)
Разработано несколько стратегий разрешения коллизий
Разрешение коллизий методом цепочек
(англ. separate chaining)

Разрешение коллизий методом цепочек
(англ. separate chaining)
Разрешение коллизий методом цепочек
(англ. separate chaining)
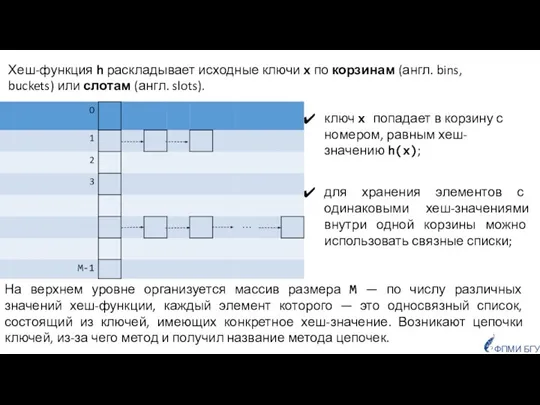
Хеш-функция h раскладывает исходные ключи x по корзинам (англ. bins, buckets)
Хеш-функция h раскладывает исходные ключи x по корзинам (англ. bins, buckets)

Операция вставки элемента
Операция вставки элемента

Сначала вычисляется хеш-значение h(x) для ключа x, а затем происходит обращение
Сначала вычисляется хеш-значение h(x) для ключа x, а затем происходит обращение

Операция удаления элемента
Операция удаления элемента

Вычисляем сначала хеш-значение для ключа x: h(45)=5.
В общем случае из
Вычисляем сначала хеш-значение для ключа x: h(45)=5.
В общем случае из

Таким образом, производительность всей конструкции связана с таким параметром, как длина
Таким образом, производительность всей конструкции связана с таким параметром, как длина

Разрешение коллизий методом открытой адресации
(англ. open addressing)
Разрешение коллизий методом открытой адресации
(англ. open addressing)

В линейном массиве хранятся непосредственно ключи, а не заголовки связных списков.
В
В линейном массиве хранятся непосредственно ключи, а не заголовки связных списков.
В

Последовательность проб
(англ. probe sequence)
Обозначим через h(x,i) номер ячейки в массиве,
Последовательность проб
(англ. probe sequence)
Обозначим через h(x,i) номер ячейки в массиве,

Для успешной работы алгоритмов поиска последовательность проб должна быть такой, чтобы
Для успешной работы алгоритмов поиска последовательность проб должна быть такой, чтобы

Линейное пробирование
Ячейки хеш-таблицы последовательно просматриваются с некоторым фиксированным интервалом c между
Линейное пробирование
Ячейки хеш-таблицы последовательно просматриваются с некоторым фиксированным интервалом c между

h(x,i)=(x+2·i) mod 10
Например, при x = 5, подставляя i от
h(x,i)=(x+2·i) mod 10
Например, при x = 5, подставляя i от

Теорема
Для того чтобы в ходе M проб все ячейки таблицы оказались
Теорема
Для того чтобы в ходе M проб все ячейки таблицы оказались

Доказательство.
Воспользуемся сведениями из элементарной теории чисел.
Докажем необходимость
Пусть h(x, i)
Доказательство.
Воспользуемся сведениями из элементарной теории чисел.
Докажем необходимость
Пусть h(x, i)

Недостаток линейного пробирования проявляется в том, что на реальных данных часто
Недостаток линейного пробирования проявляется в том, что на реальных данных часто

Номер ячейки квадратично зависит от номера попытки, расстояние между ячейками с
Номер ячейки квадратично зависит от номера попытки, расстояние между ячейками с

Двойное хеширование:
h(x,i) = (h'(x) + h"(x) ·i) mod M
Последовательность проб
Двойное хеширование:
h(x,i) = (h'(x) + h"(x) ·i) mod M
Последовательность проб

Операция вставки элемента
Операция вставки элемента

Перед вставкой ключа x выполняется поиск этого ключа.
Если такой элемент x
Перед вставкой ключа x выполняется поиск этого ключа.
Если такой элемент x
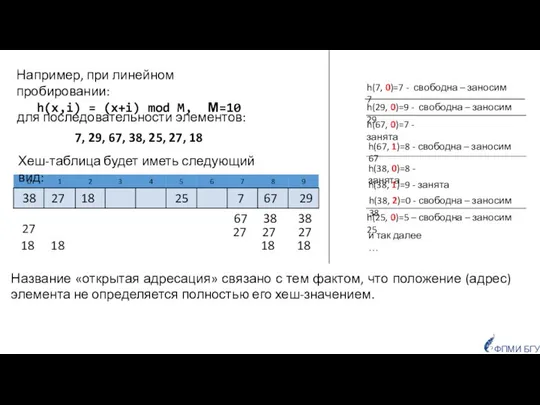
Например, при линейном пробировании:
h(x,i) = (x+i) mod M, М=10
7, 29, 67,
Например, при линейном пробировании:
h(x,i) = (x+i) mod M, М=10
7, 29, 67,

Операция поиска элемента
Случай 1.
Предположим, сначала что в таблице операция
Операция поиска элемента
Случай 1.
Предположим, сначала что в таблице операция

Ячейки массива проверяются, в соответствии с той же функцией последовательности проб,
Ячейки массива проверяются, в соответствии с той же функцией последовательности проб,

Операция поиска элемента
Случай 2.
Предположим, что в хеш-таблице поддерживается операция
Операция поиска элемента
Случай 2.
Предположим, что в хеш-таблице поддерживается операция

h(x,i)=(x+i) mod M,
7
29
25
67
38
27
18
M=10
Затем выполнили поиск
элемента x=18.
=18
=18
=18
=18
СТОП, элемента x=18 НЕТ
h(x,i)=(x+i) mod M,
7
29
25
67
38
27
18
M=10
Затем выполнили поиск
элемента x=18.
=18
=18
=18
=18
СТОП, элемента x=18 НЕТ

h(x, i) = (x + i) mod M,
7
29
25
67
38
27
18
M=10
=18
=18
=18
=18
Теперь при удалении
h(x, i) = (x + i) mod M,
7
29
25
67
38
27
18
M=10
=18
=18
=18
=18
Теперь при удалении

Недостатки
открытой адресации
Недостатки
открытой адресации

1. Нетрудно видеть, что при разрешении коллизий методом открытой адресации наличие
1. Нетрудно видеть, что при разрешении коллизий методом открытой адресации наличие

2. Число хранимых ключей не может превышать размер хеш-массива (при заполнении
2. Число хранимых ключей не может превышать размер хеш-массива (при заполнении

Преимущества
открытой адресации
Преимущества
открытой адресации

экономия памяти, если размер ключа невелик по сравнению с размером указателя
в
экономия памяти, если размер ключа невелик по сравнению с размером указателя
в

Хеш-таблицы на практике
Любой подход к реализации хеш-таблицы может работать достаточно быстро
Хеш-таблицы на практике
Любой подход к реализации хеш-таблицы может работать достаточно быстро

Критически важным показателем для хеш-таблицы является коэффициент заполнения— отношение числа ключей,
Критически важным показателем для хеш-таблицы является коэффициент заполнения— отношение числа ключей,

Реализация хеш-таблицы общего назначения обязана поддерживать операцию изменения размера.
На практике часто
Реализация хеш-таблицы общего назначения обязана поддерживать операцию изменения размера.
На практике часто

Объединение хеш-значений
Предположим, что координаты точек на плоскости хранятся в виде пар
Объединение хеш-значений
Предположим, что координаты точек на плоскости хранятся в виде пар

Пусть для простоты верхняя граница возможных значений хеш-функции не фиксирована (где-то
Пусть для простоты верхняя граница возможных значений хеш-функции не фиксирована (где-то

Хеширование строк.
Полиномиальное хеширование
Хеширование строк.
Полиномиальное хеширование

Предположим, что на вход поступает строка:
S= ‘аbcdb’ → 1,2,3,4,2.
Прямой полиномиальный хеш
Предположим, что на вход поступает строка:
S= ‘аbcdb’ → 1,2,3,4,2.
Прямой полиномиальный хеш



0
…
0
…

Так как хеш - это значение многочлена, то для многих строковых
Так как хеш - это значение многочлена, то для многих строковых



Применение хеширования строк
Т
S
Т
Т
Применение хеширования строк
Т
S
Т
Т

Проход по содержимому хеш-таблицы
В процессе программирования может возникнуть необходимость выполнить обход
Проход по содержимому хеш-таблицы
В процессе программирования может возникнуть необходимость выполнить обход

В большинстве реализаций проход по хеш-множествам выполняется в произвольном порядке, не
В большинстве реализаций проход по хеш-множествам выполняется в произвольном порядке, не

Хеш-таблицы в C++
Хеш-таблицы в C++

Долгое время в языке C++ не было стандартных реализаций структур данных
Долгое время в языке C++ не было стандартных реализаций структур данных

Наконец, в стандарте C++11 в STL официально были добавлены хеш-таблицы.
Стандарт
Наконец, в стандарте C++11 в STL официально были добавлены хеш-таблицы.
Стандарт

В качестве хеш-значения в C++ используется число типа size_t.
Все хеш-контейнеры предоставляют
В качестве хеш-значения в C++ используется число типа size_t.
Все хеш-контейнеры предоставляют

Рассмотрим более подробно реализацию в компиляторе GCC (GNU Compiler Collection)
Пусть
Рассмотрим более подробно реализацию в компиляторе GCC (GNU Compiler Collection)
Пусть

Хеш-таблицы в JAVA
Хеш-таблицы в JAVA

Коллекции HashSet и HashMap реализуются как хеш-таблицы, для разрешения коллизий используется
Коллекции HashSet и HashMap реализуются как хеш-таблицы, для разрешения коллизий используется

В версии Java 8
разработчики озаботились вопросом устойчивости коллекций, использующих хеширование,
В версии Java 8
разработчики озаботились вопросом устойчивости коллекций, использующих хеширование,

Хеш-таблицы в PYTHON
Хеш-таблицы в PYTHON

Встроенный тип dict — ассоциативный массив, словарь —широко используется в языке.
Он
Встроенный тип dict — ассоциативный массив, словарь —широко используется в языке.
Он

Криптографические хеш-функции
В криптографии множество K возможных ключей бесконечно, и любой
Криптографические хеш-функции
В криптографии множество K возможных ключей бесконечно, и любой

За годы развития вычислительной техники сформировалась наука о том, как практически
За годы развития вычислительной техники сформировалась наука о том, как практически

Универсальное хеширование
(англ. universal hashing)
Универсальное хеширование
(англ. universal hashing)

Добавить рандомизацию:
внести элемент случайности, чтобы не было фиксированного «плохого» случая.
Добавить рандомизацию:
внести элемент случайности, чтобы не было фиксированного «плохого» случая.


p·(p-1) способ выбрать хеш-функцию из семейства
добавление элемента – усреднённо O(1);
поиск
p·(p-1) способ выбрать хеш-функцию из семейства
добавление элемента – усреднённо O(1);
поиск

Совершенное хеширование
(англ. perfect hashing)
Совершенное хеширование
(англ. perfect hashing)

Пусть S — фактическое множество ключей в хеш-таблице, и у этого
Пусть S — фактическое множество ключей в хеш-таблице, и у этого

Таким образом, подход заключается в построении хеш-функции, которая является:
простой, т.е. достаточно
Таким образом, подход заключается в построении хеш-функции, которая является:
простой, т.е. достаточно

Совершенное двухуровневое хеширование
Совершенное двухуровневое хеширование
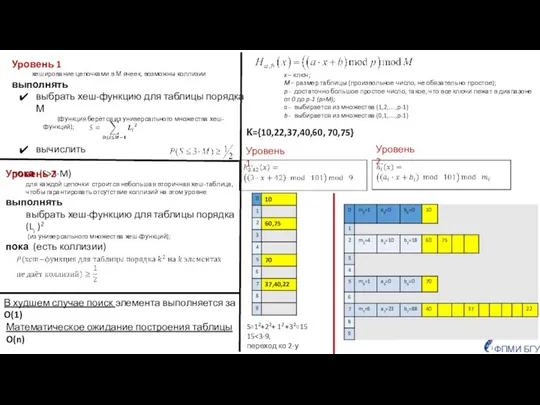
Уровень 2
для каждой цепочки строится небольшая вторичная хеш-таблица, чтобы гарантировать
Уровень 2
для каждой цепочки строится небольшая вторичная хеш-таблица, чтобы гарантировать

Общие задачи в iRunner для закрепления навыков
0.5. Хеш-таблица (разрешение коллизий
Общие задачи в iRunner для закрепления навыков
0.5. Хеш-таблица (разрешение коллизий
 Typografické zásady
Typografické zásady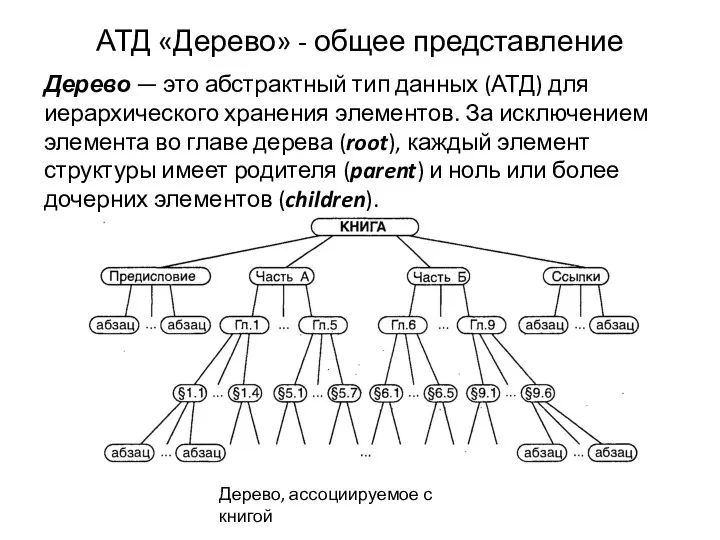 АТД дерево - общее представление
АТД дерево - общее представление Презентация "MSC.Mvision - 14-1" - скачать презентации по Информатике
Презентация "MSC.Mvision - 14-1" - скачать презентации по Информатике Новая система информирования студентов
Новая система информирования студентов Современные системы противоаварийной автоматики
Современные системы противоаварийной автоматики Понятие информационные систем. История развития баз данных
Понятие информационные систем. История развития баз данных Компьютерные вирусы
Компьютерные вирусы Защита от несанкционированного доступа к компьютерной информации. (Лекция 4)
Защита от несанкционированного доступа к компьютерной информации. (Лекция 4) Использование интерактивных методов и технологий обучения, организация игровой деятельности на уроках музыкального искусства
Использование интерактивных методов и технологий обучения, организация игровой деятельности на уроках музыкального искусства 1.Необходимость, ретроспектива, тенденции развития, классификация. 2-3. Ассоциативная обработка и параллелизм
1.Необходимость, ретроспектива, тенденции развития, классификация. 2-3. Ассоциативная обработка и параллелизм Пользовательский интерфейс
Пользовательский интерфейс Правила заполнения ежемесячной отчетности партнеров 1С по непродленным договорам 1С:ИТС
Правила заполнения ежемесячной отчетности партнеров 1С по непродленным договорам 1С:ИТС Общее понятие о компьютере. Своя игра
Общее понятие о компьютере. Своя игра Реляциялық МҚ жобалау жане жобалау кезеңдері
Реляциялық МҚ жобалау жане жобалау кезеңдері Создание запросов в СУБД Access
Создание запросов в СУБД Access Двоичное представление информации. Системы счисления
Двоичное представление информации. Системы счисления Мошенничество в сети. Виды мошенничества в интернете
Мошенничество в сети. Виды мошенничества в интернете Ур. 26 .Типы данных в языке
Ур. 26 .Типы данных в языке Основы информационных технологий
Основы информационных технологий Компьютерная игра Adventure time
Компьютерная игра Adventure time Обеспечение информационной безопасности дошкольников
Обеспечение информационной безопасности дошкольников Программное обеспечение ЭВМ
Программное обеспечение ЭВМ Секреты успешной работы с печатными изданиями
Секреты успешной работы с печатными изданиями Виртуальная реальность. За и против взрывного роста VR-рынка
Виртуальная реальность. За и против взрывного роста VR-рынка Нужен всем спору нет, безопасный интернет
Нужен всем спору нет, безопасный интернет Организационное собрание
Организационное собрание BIOS. Базовая система ввода-вывода
BIOS. Базовая система ввода-вывода ТРПО. Консоль. Консольное приложение
ТРПО. Консоль. Консольное приложение