- Распараллеливание на компьютерах с общей памятью

Содержание
- 2. Часть 3: Распараллеливание на компьютерах с общей памятью Средства программирования для компьютеров с общей памятью (OpenMP,
- 3. Средства программирования для компьютеров с общей памятью Компьютер с общей памятью (shared memory) Особенность: автоматический обмен
- 4. Средства программирования для компьютеров с общей памятью Основное средство программирования: OpenMP (система директив препроцессора, которые сообщают
- 5. Понятие потока Поток (нить, thread) – блок команд и данных для исполнения на одном из исполняющих
- 6. Понятие потока Нужно знать, что существуют механизмы, которые позволяют пытаться установить связь между реальными, виртуальными и
- 7. Уровни параллелизма 4 уровня Физический (ядра процессора) Виртуальный физический (гиперсрединг, hyperthreading) Системный Программный Инженер-программист всегда программирует
- 8. Упрощённая модель 2-процессорного сервера Физический уровень для 2-процессорного сервера ЯДРО ЯДРО ЯДРО КЭШ 1 КЭШ 1
- 9. Гиперсрединг обычно включён по умолчанию – выключайте, если можете для высокопроизводительных вычислений Виртуальный физический (hyperthreading) уровень
- 10. Операционная система имеет ограниченную видимость архитектуры Уровень операционной системы (тот же сервер) ЯДРО ЯДРО ЯДРО ЯДРО
- 11. Программа практически не видит архитектуры Уровень программы (тот же сервер) ЯДРО ЯДРО ЯДРО ЯДРО ПАМЯТЬ ЯДРО
- 12. Выключайте гиперсрединг в БИОСе по возможности Влияние гиперсрединга ЯДРО ЯДРО ЯДРО ЯДРО КЭШ 1 КЭШ 1
- 13. OS treats all HW threads as equal Влияние операционной системы (перетасовка) ЯДРО ЯДРО ЯДРО ЯДРО КЭШ
- 14. Операционная система видит все потоки как одинаковые Влияние неоднородной (NUMA) памяти ЯДРО ЯДРО ЯДРО ЯДРО КЭШ
- 15. КЭШ 1 Правильное распределение увеличивает производительность программы Влияние распределения потоков по ядрам 1 ЯДРО ЯДРО ЯДРО
- 16. Правильное распределение увеличивает производительность программы Влияние распределения потоков по ядрам 2 ЯДРО ЯДРО ЯДРО ЯДРО КЭШ
- 17. KMP_AFFINITY главный инструмент для привязки потоков друг к другу Инструменты Intel для решения проблем Компиляторы Intel
- 18. Работа с установками affinity KMP_AFFINITY=verbose Выдача OMP: Info #179: KMP_AFFINITY: 2 packages x 8 cores/pkg x
- 19. Рекомендации Если вы видите Неустойчивое время работы программы Плохую масштабируемость с N на 2N или с
- 20. Особенности параллельных программ Основа – обычная последовательная программа Дополнена директивами препроцессора, которые сообщают компилятору информацию о
- 21. Представление об управляющих конструкциях OpenMP Принцип работы: интерпретация куска программы как программы для многих потоков ...
- 22. Представление об управляющих конструкциях OpenMP Директивы компилятора: #pragma omp NAME [clause [clause]…] (Си) $OMP NAME [clause
- 23. Представление об управляющих конструкциях OpenMP Полезные функции void omp_set_num_threads(int num_threads); (Си) subroutine omp_set_num_threads(num_threads) (Фортран) integer num_threads
- 24. Представление об управляющих конструкциях OpenMP Полезные функции для продвинутого параллелизма void omp_init_lock(omp_lock_t *lock); void omp_init_nest_lock(omp_nest_lock_t *lock);
- 25. Представление об управляющих конструкциях OpenMP Пример OpenMP программы #pragma omp parallel for private(i) firstprivate(N) shared(a,b) lastprivate(j)
- 26. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 0) sum=0.0; for (int i=0; i {
- 27. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 1) sum=0.0; #pragma omp parallel for for
- 28. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 2) sum=0.0; #pragma omp parallel for for
- 29. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 3) sum=0.0; #pragma omp parallel for reduction(+:sum)
- 30. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 4) sum=0.0; #pragma omp parallel for reduction(+:sum)
- 31. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 5) sum=0.0; #pragma omp parallel for reduction(+:sum)
- 32. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 6) sum=0.0; #pragma omp parallel for reduction(+:sum)
- 33. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 7) sum=0.0; int M=32; #pragma omp parallel
- 34. Примеры простейших эффективных и неэффективных алгоритмов Скалярное произведение (Версия 8) #pragma omp parallel sections { #pragma
- 35. Примеры простейших эффективных и неэффективных алгоритмов Итог: Увы, но на другом компьютере результаты могут существенно отличаться
- 36. Синхронизация параллельных вычислений Простейшая конструкция синхронизации: barrier #pragma omp barrier !$omp barrier Исполнение параллельного кода присотанавливается
- 37. Синхронизация параллельных вычислений loop: #pragma omp parallel for shared(a,b) reduction(+:sum) for (int i=begin; i { sum+=a[i]*b[i];
- 38. Синхронизация параллельных вычислений Конструкции Single & Master #pragma omp single\master !$omp single\master Исполнение данной части кода
- 39. Синхронизация параллельных вычислений loop: #pragma omp parallel for shared(a,b) reduction(+:sum) for (int i=begin; i { sum+=a[i]*b[i];
- 40. Синхронизация параллельных вычислений Конструкция Critical #pragma omp critical !$omp critical Исполнение данной части кода происходит потоками
- 41. Синхронизация параллельных вычислений loop: #pragma omp parallel for shared(a,b) reduction(+:sum) for (int i=begin; i { sum+=a[i]*b[i];
- 42. Синхронизация параллельных вычислений Конструкция Flush #pragma omp flush !$omp flush Делает видимой всем часть памяти (переменные),
- 43. Немного об OpenMP 4.* OpenMP 4.0 – это ответ на вызов альтернативного стандарта OpenACC Дополнения, связанные
- 44. Резюме Компьютер с общей памятью является простейшим вариантом параллельного компьютера Компьютер с общей памятью исполняет потоки
- 46. Скачать презентацию

Часть 3: Распараллеливание на компьютерах с общей памятью
Средства программирования для компьютеров
Часть 3: Распараллеливание на компьютерах с общей памятью
Средства программирования для компьютеров

Средства программирования для компьютеров с общей памятью
Компьютер с общей памятью (shared
Средства программирования для компьютеров с общей памятью
Компьютер с общей памятью (shared

Средства программирования для компьютеров с общей памятью
Основное средство программирования: OpenMP (система
Средства программирования для компьютеров с общей памятью
Основное средство программирования: OpenMP (система

Понятие потока
Поток (нить, thread) – блок команд и данных для исполнения
Понятие потока
Поток (нить, thread) – блок команд и данных для исполнения

Понятие потока
Нужно знать, что существуют механизмы, которые позволяют пытаться установить связь
Понятие потока
Нужно знать, что существуют механизмы, которые позволяют пытаться установить связь

Уровни параллелизма
4 уровня
Физический (ядра процессора)
Виртуальный физический (гиперсрединг, hyperthreading)
Системный
Программный
Инженер-программист всегда программирует
Уровни параллелизма
4 уровня
Физический (ядра процессора)
Виртуальный физический (гиперсрединг, hyperthreading)
Системный
Программный
Инженер-программист всегда программирует
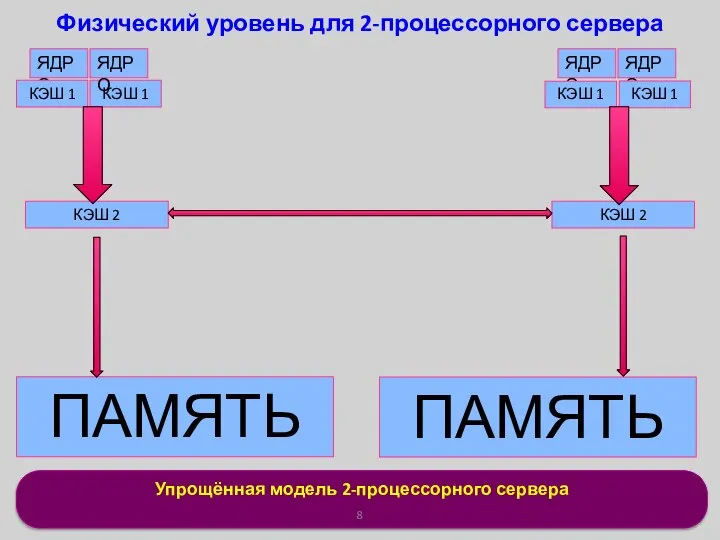
Упрощённая модель 2-процессорного сервера
Физический уровень для 2-процессорного сервера
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ 1
КЭШ 1
КЭШ
Упрощённая модель 2-процессорного сервера
Физический уровень для 2-процессорного сервера
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ 1
КЭШ 1
КЭШ
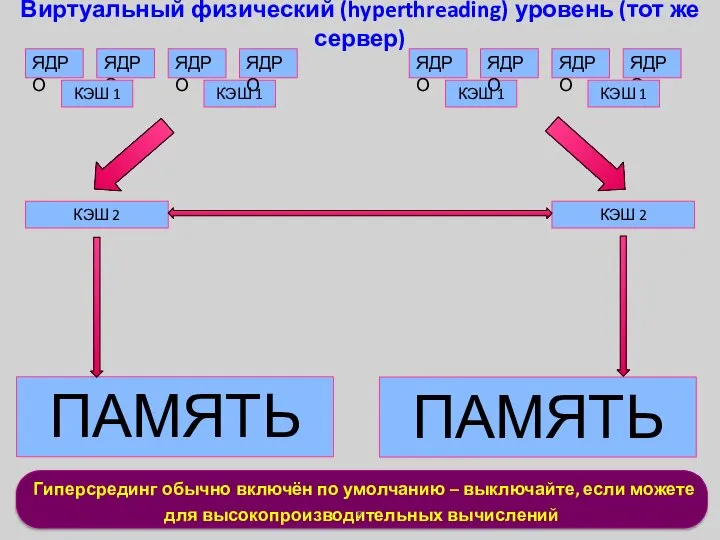
Гиперсрединг обычно включён по умолчанию – выключайте, если можете
для высокопроизводительных
Гиперсрединг обычно включён по умолчанию – выключайте, если можете
для высокопроизводительных
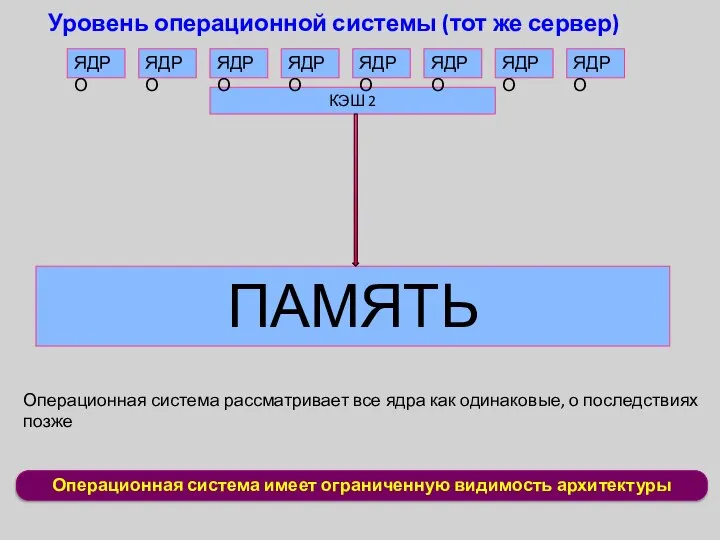
Операционная система имеет ограниченную видимость архитектуры
Уровень операционной системы (тот же сервер)
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ
Операционная система имеет ограниченную видимость архитектуры
Уровень операционной системы (тот же сервер)
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ

Программа практически не видит архитектуры
Уровень программы (тот же сервер)
ЯДРО
ЯДРО
ЯДРО
ЯДРО
ПАМЯТЬ
ЯДРО
ЯДРО
ЯДРО
ЯДРО
Наивная реализация алгоритма
Программа практически не видит архитектуры
Уровень программы (тот же сервер)
ЯДРО
ЯДРО
ЯДРО
ЯДРО
ПАМЯТЬ
ЯДРО
ЯДРО
ЯДРО
ЯДРО
Наивная реализация алгоритма
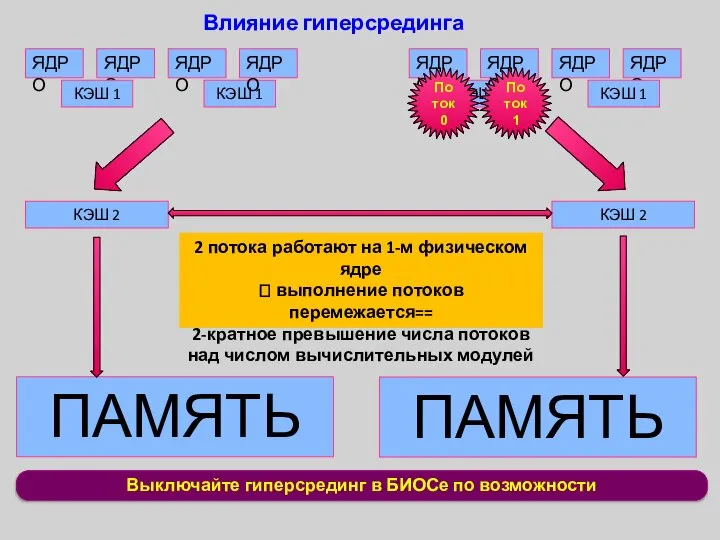
Выключайте гиперсрединг в БИОСе по возможности
Влияние гиперсрединга
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ 1
КЭШ 1
КЭШ 1
КЭШ
Выключайте гиперсрединг в БИОСе по возможности
Влияние гиперсрединга
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ 1
КЭШ 1
КЭШ 1
КЭШ
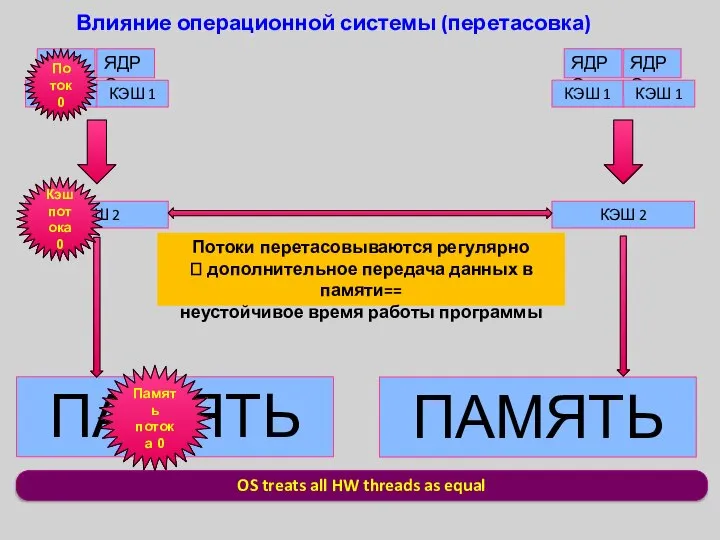
OS treats all HW threads as equal
Влияние операционной системы (перетасовка)
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ
OS treats all HW threads as equal
Влияние операционной системы (перетасовка)
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ
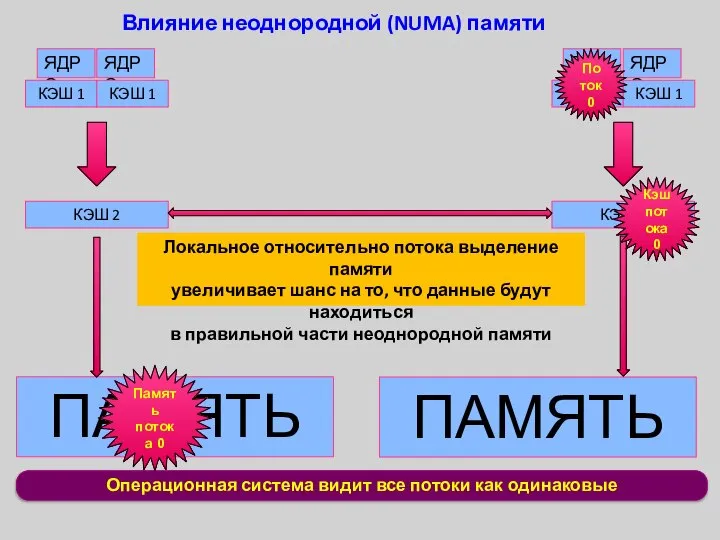
Операционная система видит все потоки как одинаковые
Влияние неоднородной (NUMA) памяти
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ
Операционная система видит все потоки как одинаковые
Влияние неоднородной (NUMA) памяти
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ
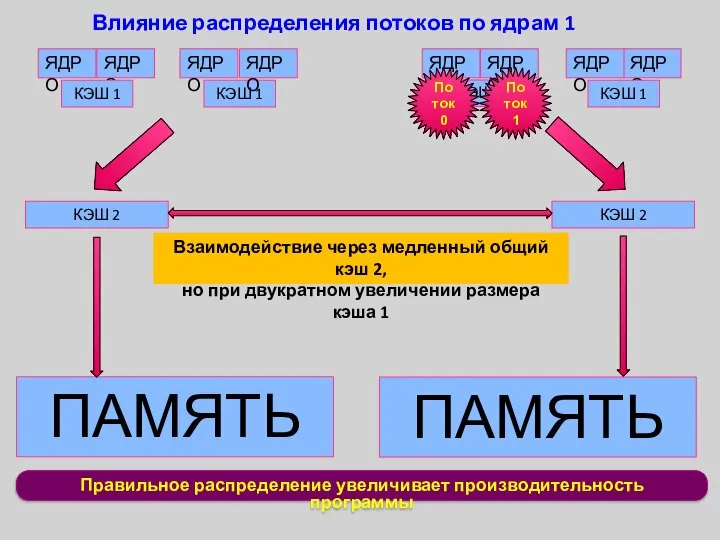
КЭШ 1
Правильное распределение увеличивает производительность программы
Влияние распределения потоков по ядрам 1
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ
КЭШ 1
Правильное распределение увеличивает производительность программы
Влияние распределения потоков по ядрам 1
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ
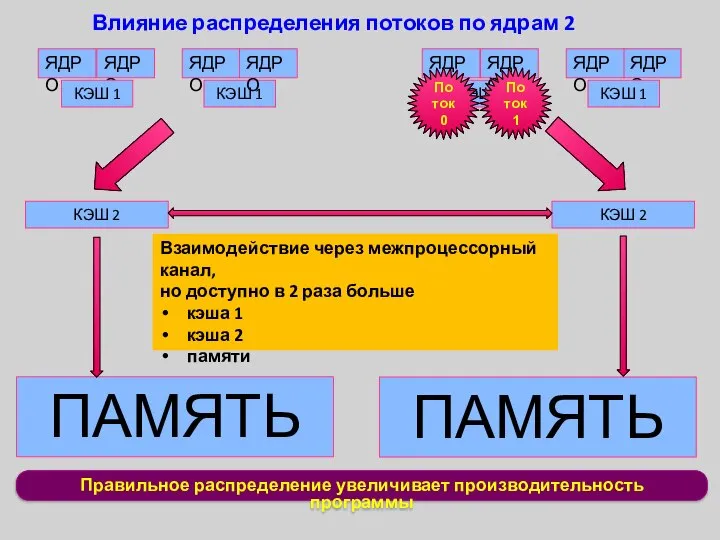
Правильное распределение увеличивает производительность программы
Влияние распределения потоков по ядрам 2
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ
Правильное распределение увеличивает производительность программы
Влияние распределения потоков по ядрам 2
ЯДРО
ЯДРО
ЯДРО
ЯДРО
КЭШ 1
КЭШ

KMP_AFFINITY главный инструмент для привязки потоков друг к другу
Инструменты Intel для
KMP_AFFINITY главный инструмент для привязки потоков друг к другу
Инструменты Intel для

Работа с установками affinity
KMP_AFFINITY=verbose
Выдача
OMP: Info #179: KMP_AFFINITY: 2 packages x 8
Работа с установками affinity
KMP_AFFINITY=verbose
Выдача
OMP: Info #179: KMP_AFFINITY: 2 packages x 8

Рекомендации
Если вы видите
Неустойчивое время работы программы
Плохую масштабируемость с N на 2N
Рекомендации
Если вы видите
Неустойчивое время работы программы
Плохую масштабируемость с N на 2N

Особенности параллельных программ
Основа – обычная последовательная программа
Дополнена директивами препроцессора, которые сообщают
Особенности параллельных программ
Основа – обычная последовательная программа
Дополнена директивами препроцессора, которые сообщают
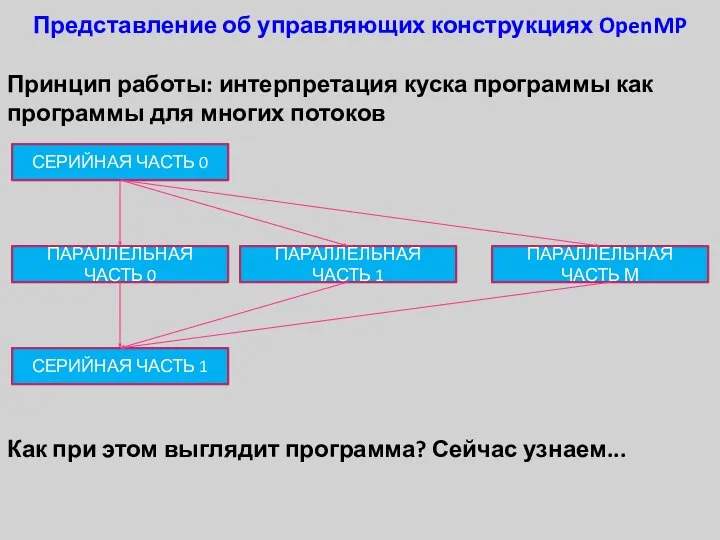
Представление об управляющих конструкциях OpenMP
Принцип работы: интерпретация куска программы как программы
Представление об управляющих конструкциях OpenMP
Принцип работы: интерпретация куска программы как программы

Представление об управляющих конструкциях OpenMP
Директивы компилятора:
#pragma omp NAME [clause [clause]…] (Си)
$OMP
Представление об управляющих конструкциях OpenMP
Директивы компилятора:
#pragma omp NAME [clause [clause]…] (Си)
$OMP

Представление об управляющих конструкциях OpenMP
Полезные функции
void omp_set_num_threads(int num_threads); (Си)
subroutine omp_set_num_threads(num_threads) (Фортран)
integer
Представление об управляющих конструкциях OpenMP
Полезные функции
void omp_set_num_threads(int num_threads); (Си)
subroutine omp_set_num_threads(num_threads) (Фортран)
integer

Представление об управляющих конструкциях OpenMP
Полезные функции для продвинутого параллелизма
void omp_init_lock(omp_lock_t *lock);
void
Представление об управляющих конструкциях OpenMP
Полезные функции для продвинутого параллелизма
void omp_init_lock(omp_lock_t *lock);
void

Представление об управляющих конструкциях OpenMP
Пример OpenMP программы
#pragma omp parallel for private(i)
Представление об управляющих конструкциях OpenMP
Пример OpenMP программы
#pragma omp parallel for private(i)

Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 0)
sum=0.0;
for (int
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 0)
sum=0.0;
for (int

Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 1)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 1)
sum=0.0;
#pragma omp parallel

Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 2)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 2)
sum=0.0;
#pragma omp parallel

Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 3)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 3)
sum=0.0;
#pragma omp parallel

Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 4)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 4)
sum=0.0;
#pragma omp parallel
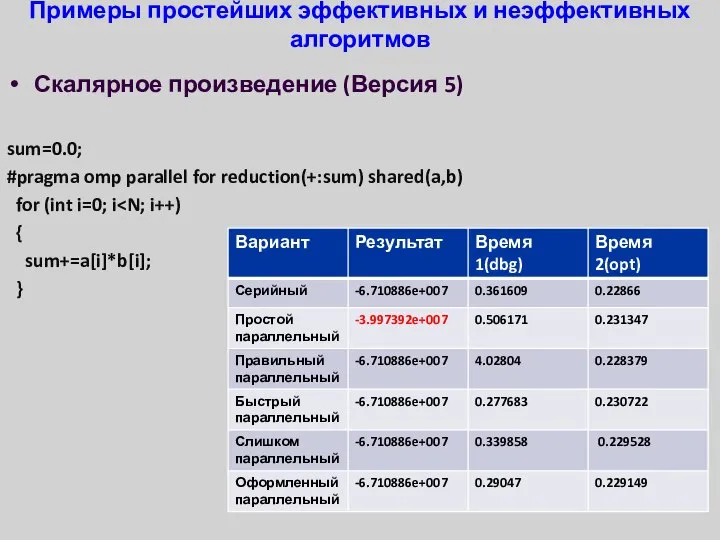
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 5)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 5)
sum=0.0;
#pragma omp parallel
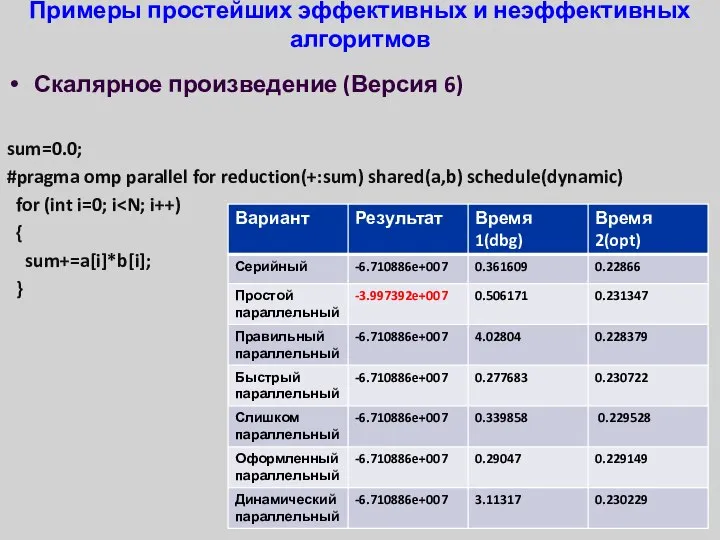
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 6)
sum=0.0;
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 6)
sum=0.0;
#pragma omp parallel
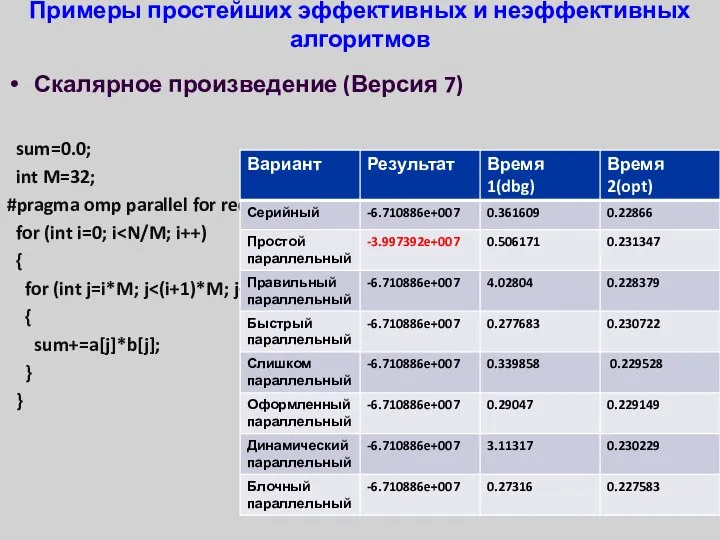
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 7)
sum=0.0;
int
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 7)
sum=0.0;
int
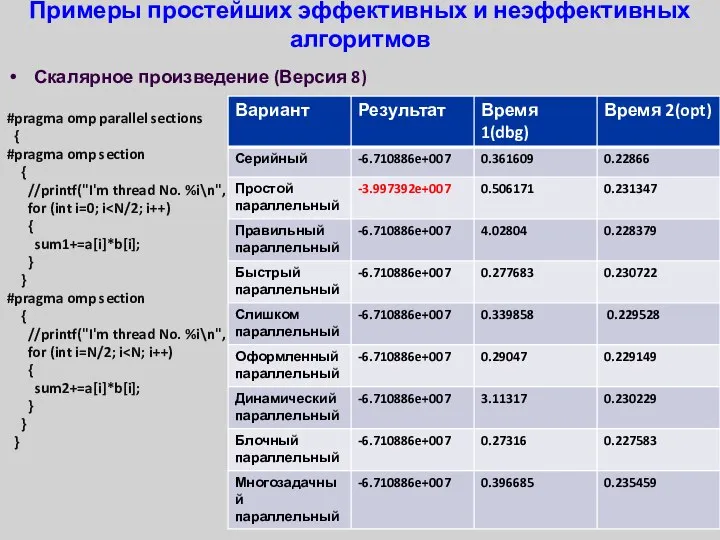
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 8)
#pragma omp parallel
Примеры простейших эффективных и неэффективных алгоритмов
Скалярное произведение (Версия 8)
#pragma omp parallel
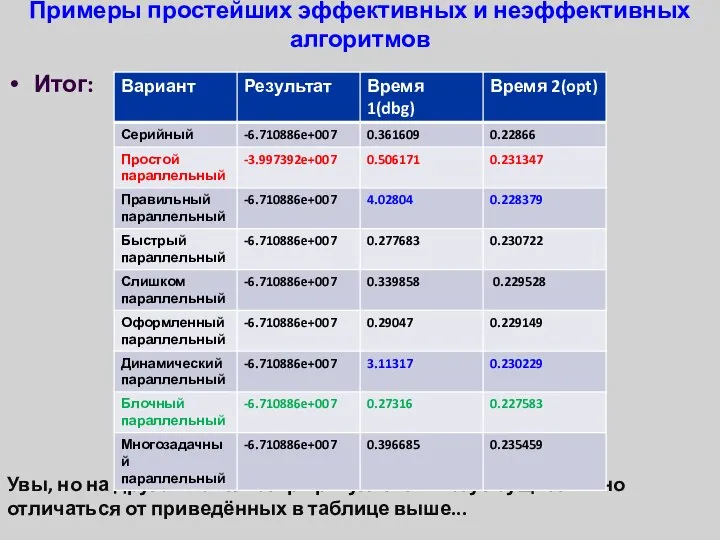
Примеры простейших эффективных и неэффективных алгоритмов
Итог:
Увы, но на другом компьютере результаты
Примеры простейших эффективных и неэффективных алгоритмов
Итог:
Увы, но на другом компьютере результаты

Синхронизация параллельных вычислений
Простейшая конструкция синхронизации: barrier
#pragma omp barrier
!$omp barrier
Исполнение параллельного кода
Синхронизация параллельных вычислений
Простейшая конструкция синхронизации: barrier
#pragma omp barrier
!$omp barrier
Исполнение параллельного кода
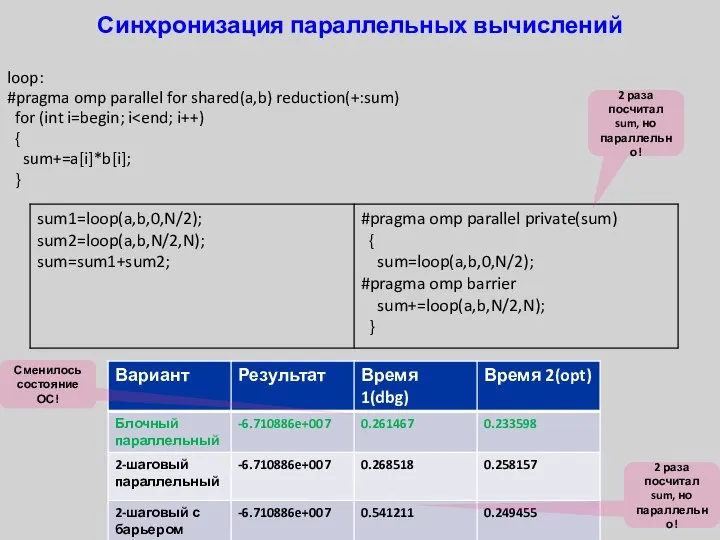
Синхронизация параллельных вычислений
loop:
#pragma omp parallel for shared(a,b) reduction(+:sum)
for (int i=begin;
Синхронизация параллельных вычислений
loop:
#pragma omp parallel for shared(a,b) reduction(+:sum)
for (int i=begin;

Синхронизация параллельных вычислений
Конструкции Single & Master
#pragma omp single\master
!$omp single\master
Исполнение данной части
Синхронизация параллельных вычислений
Конструкции Single & Master
#pragma omp single\master
!$omp single\master
Исполнение данной части
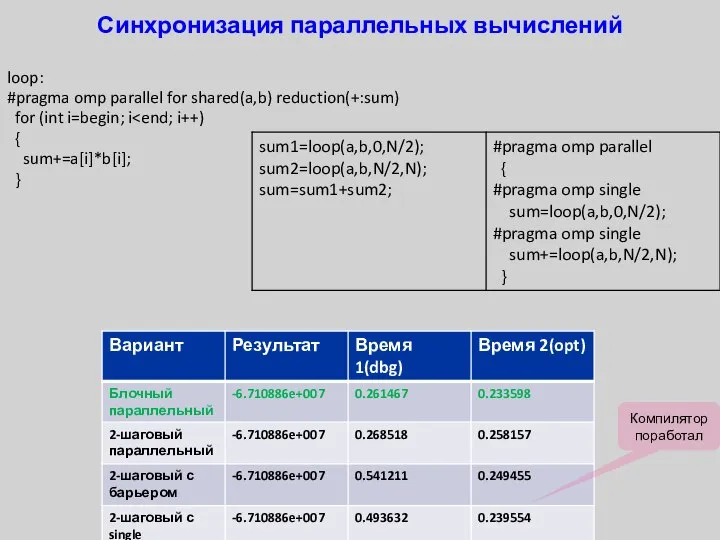
Синхронизация параллельных вычислений
loop:
#pragma omp parallel for shared(a,b) reduction(+:sum)
for (int i=begin;
Синхронизация параллельных вычислений
loop:
#pragma omp parallel for shared(a,b) reduction(+:sum)
for (int i=begin;

Синхронизация параллельных вычислений
Конструкция Critical
#pragma omp critical
!$omp critical
Исполнение данной части кода происходит
Синхронизация параллельных вычислений
Конструкция Critical
#pragma omp critical
!$omp critical
Исполнение данной части кода происходит
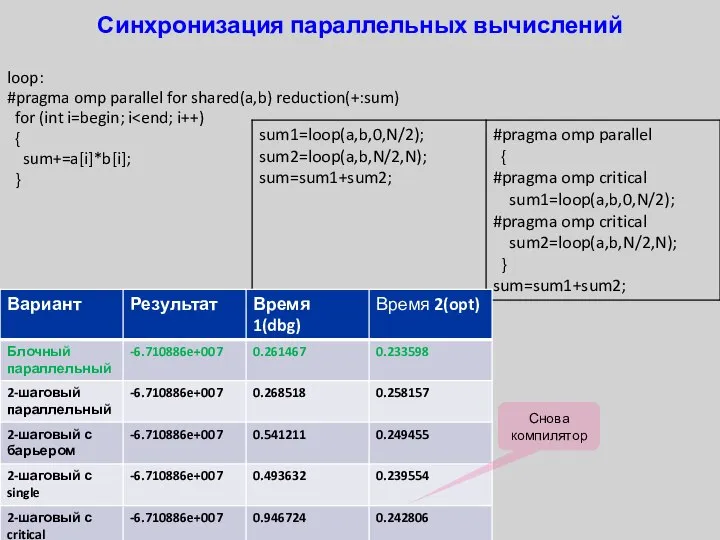
Синхронизация параллельных вычислений
loop:
#pragma omp parallel for shared(a,b) reduction(+:sum)
for (int i=begin;
Синхронизация параллельных вычислений
loop:
#pragma omp parallel for shared(a,b) reduction(+:sum)
for (int i=begin;

Синхронизация параллельных вычислений
Конструкция Flush
#pragma omp flush
!$omp flush
Делает видимой всем часть памяти
Синхронизация параллельных вычислений
Конструкция Flush
#pragma omp flush
!$omp flush
Делает видимой всем часть памяти

Немного об OpenMP 4.*
OpenMP 4.0 – это ответ на вызов альтернативного
Немного об OpenMP 4.*
OpenMP 4.0 – это ответ на вызов альтернативного

Резюме
Компьютер с общей памятью является простейшим вариантом параллельного компьютера
Компьютер с общей
Резюме
Компьютер с общей памятью является простейшим вариантом параллельного компьютера
Компьютер с общей
 Программы для работы с видео
Программы для работы с видео Презентация "Классификация моделей" - скачать презентации по Информатике
Презентация "Классификация моделей" - скачать презентации по Информатике Создай свою Игру и получи поток ВИП-Клиентов
Создай свою Игру и получи поток ВИП-Клиентов Компьютерные сети
Компьютерные сети Бесплатный тренинг Сергея Грань
Бесплатный тренинг Сергея Грань Работа с угрозами операционных систем
Работа с угрозами операционных систем Основы Dynamic HTML
Основы Dynamic HTML Алгоритмический Язык АЯ
Алгоритмический Язык АЯ Презентация по информатике по теме «Решение логических задач» для 5-9 классов Выполнила учитель информатики МОУ «Основная общеоб
Презентация по информатике по теме «Решение логических задач» для 5-9 классов Выполнила учитель информатики МОУ «Основная общеоб Обзор стека TCP/IP
Обзор стека TCP/IP Мобильный интернет: 3G, 4G, Wi-Fi
Мобильный интернет: 3G, 4G, Wi-Fi Редактирование, добавление и удаление записей в таблице СУБД MySQL
Редактирование, добавление и удаление записей в таблице СУБД MySQL Защита старшего поколения. Онлайн мошенничество
Защита старшего поколения. Онлайн мошенничество Создание Web-страниц на языке HTML
Создание Web-страниц на языке HTML Параллельное программирование с использованием OpenMP. Лекция 2
Параллельное программирование с использованием OpenMP. Лекция 2 Кибер-безопасность
Кибер-безопасность Работа в Microsoft Office Publisher Программа может широко использоваться для создания буклетов, издания школьной стенгазеты, приглашения и о
Работа в Microsoft Office Publisher Программа может широко использоваться для создания буклетов, издания школьной стенгазеты, приглашения и о КОМПЬЮТЕРНЫЕ СЕТИ ВИДЫ СЕТЕЙ, ИНТЕРНЕТ
КОМПЬЮТЕРНЫЕ СЕТИ ВИДЫ СЕТЕЙ, ИНТЕРНЕТ  Принципы уменьшения объема графических файлов
Принципы уменьшения объема графических файлов Раздел 12 Вынужденное перемещение
Раздел 12 Вынужденное перемещение  Дистанционные образовательные технологии
Дистанционные образовательные технологии Web-страницы и Web-сайты. Структура Web-страницы
Web-страницы и Web-сайты. Структура Web-страницы Оценка удобства использования пользовательского интерфейса
Оценка удобства использования пользовательского интерфейса LMS instrukcija
LMS instrukcija Профилактика кибербуллинга
Профилактика кибербуллинга Школьные вести. Газета № 47
Школьные вести. Газета № 47 Пирамидальная сортировка. Лекция 8
Пирамидальная сортировка. Лекция 8 Программирование на языках С/C++. Операторы
Программирование на языках С/C++. Операторы