- Технология OpenMP

Содержание
- 2. OpenMP - стандарт программного интерфейса приложений для параллельных систем с общей памятью. Поддерживает языки C, C++,
- 3. Модель программы в OpenMP Программа состоит из последовательных и параллельных секций. В начальный момент времени создается
- 4. Компоненты OpenMP Директивы компилятора - используются для создания потоков, распределения работы между потоками и их синхронизации.
- 5. Подключение Конфигурацию рекомендуется установить в release
- 7. Программа «Hello World» #include int main(int argc, char* argv[]) { #pragma omp parallel { printf("Hello World\n");
- 8. Директивы OpenMP #pragma omp задает границы параллельной секции программы. С данной директивой могут использоваться следующие операторы:
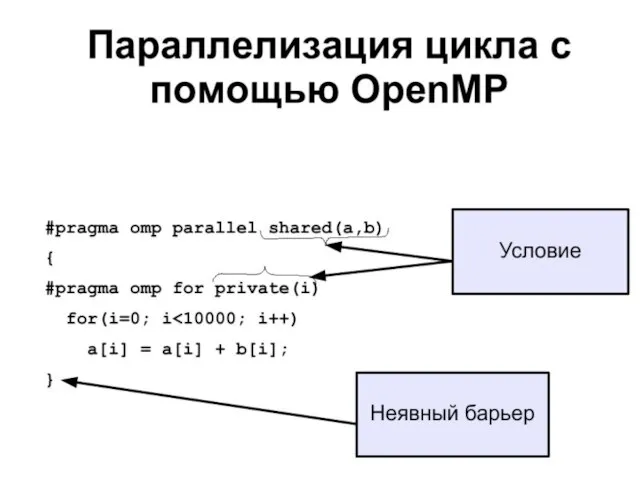
- 9. #pragma omp for Задает границы цикла, исполняемого в параллельном режиме. #pragma omp parallel { #pragma omp
- 11. #pragma omp parallel { for(int i = 1; i x[i] = (y[i-1] + y[i+1])/2; } //
- 12. При распараллеливании циклов вы должны убедиться в том, что итерации цикла не имеют зависимостей. Если цикл
- 13. Общие и частные данные Разрабатывая параллельные программы, вы должны понимать, какие данные являются общими (shared), а
- 16. Во-первых, частными являются индексы параллельных циклов for. Во-вторых, частными являются локальные переменные блоков параллельных регионов. В-третьих,
- 18. float sum = 10.0f; MatrixClass myMatrix; /*Переменная j по умолчанию не является частной, но явно сделана
- 19. Раздел private говорит о том, что для каждого потока должна быть создана частная копия каждой переменной
- 21. раздел reduction, но он принимает переменную и оператор. Поддерживаемые этим разделом операторы перечислены в таблице ,
- 22. Операторы раздела reduction
- 23. nowait - Отменяет барьерную синхронизацию при завершении выполнения параллельной секции. schedule - По умолчанию в OpenMP
- 28. Параллельная обработка в конструкциях, отличных от циклов OpenMP поддерживает параллелизм и на уровне функций. Этот механизм
- 30. void QuickSort (int numList[], int nLower, int nUpper) { if (nLower { // Разбиение интервала сортировки
- 31. Синхронизация Барьерная синхронизация. В некоторых ситуациях ее целесообразно выполнять наряду с неявной. Используется #pragma omp barrier.
- 37. В параллельных регионах часто встречаются блоки кода, доступ к которым желательно предоставлять только одному потоку, —
- 38. Функции OpenMP void omp_set_num_threads(int threads); Задает количество потоков (threads) при выполнении параллельных секций программы. int omp_get_num_threads(void);
- 39. int omp_get_num_procs(void); Возвращает количество процессоров, доступных в данный момент программе. int omp_in_parallel(void); Возвращает не ноль при
- 40. Переменные окружения OpenMP OMP_NUM_THREADS Задает количество нитей при выполнении параллельных секций программы. OMP_SCHEDULE Задает способ распределения
- 41. void omp_set_nested(int nested); Разрешает или запрещает вложенный параллелизм. По умолчанию вложенный параллелизм запрещен. int omp_get_nested(void); Определяет,
- 43. Скачать презентацию

OpenMP - стандарт программного интерфейса приложений для параллельных систем с общей
OpenMP - стандарт программного интерфейса приложений для параллельных систем с общей
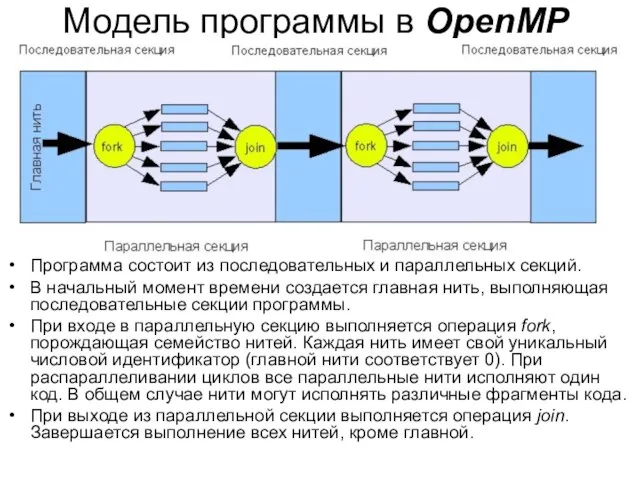
Модель программы в OpenMP
Программа состоит из последовательных и параллельных секций.
В начальный
Модель программы в OpenMP
Программа состоит из последовательных и параллельных секций.
В начальный

Компоненты OpenMP
Директивы компилятора - используются для создания потоков, распределения работы между
Компоненты OpenMP
Директивы компилятора - используются для создания потоков, распределения работы между
Подключение
Конфигурацию рекомендуется установить в release
Подключение
Конфигурацию рекомендуется установить в release

![Программа «Hello World» #include int main(int argc, char* argv[]) { #pragma](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/557895/slide-6.jpg)
Программа «Hello World»
#include
int main(int argc, char* argv[])
{
#pragma omp parallel
{
printf("Hello World\n");
}
return
Программа «Hello World»
#include
int main(int argc, char* argv[])
{
#pragma omp parallel
{
printf("Hello World\n");
}
return

Директивы OpenMP
#pragma omp задает границы параллельной секции программы. С данной директивой
Директивы OpenMP
#pragma omp задает границы параллельной секции программы. С данной директивой

#pragma omp for
Задает границы цикла, исполняемого в параллельном режиме.
#pragma omp
#pragma omp for
Задает границы цикла, исполняемого в параллельном режиме.
#pragma omp

![#pragma omp parallel { for(int i = 1; i x[i] =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/557895/slide-10.jpg)
#pragma omp parallel {
for(int i = 1; i < size;
#pragma omp parallel {
for(int i = 1; i < size;

При распараллеливании циклов вы должны убедиться в том, что итерации цикла не имеют зависимостей.
При распараллеливании циклов вы должны убедиться в том, что итерации цикла не имеют зависимостей.

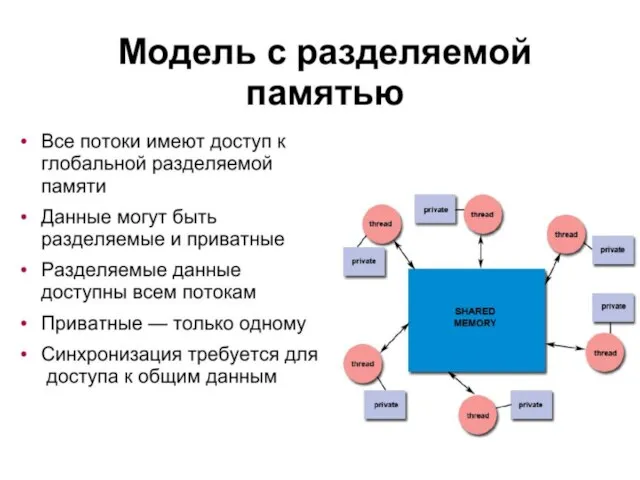
Общие и частные данные
Разрабатывая параллельные программы, вы должны понимать, какие данные являются общими
Общие и частные данные
Разрабатывая параллельные программы, вы должны понимать, какие данные являются общими


Во-первых, частными являются индексы параллельных циклов for.
Во-вторых, частными являются локальные
Во-первых, частными являются индексы параллельных циклов for.
Во-вторых, частными являются локальные

float sum = 10.0f;
MatrixClass myMatrix;
/*Переменная j по умолчанию не является частной, но явно
float sum = 10.0f;
MatrixClass myMatrix;
/*Переменная j по умолчанию не является частной, но явно

Раздел private говорит о том, что для каждого потока должна быть создана
Раздел private говорит о том, что для каждого потока должна быть создана


раздел reduction, но он принимает переменную и оператор. Поддерживаемые этим разделом операторы перечислены в таблице
раздел reduction, но он принимает переменную и оператор. Поддерживаемые этим разделом операторы перечислены в таблице
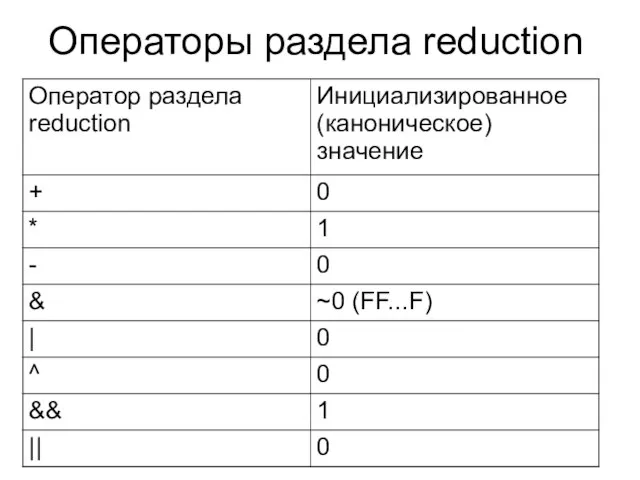
Операторы раздела reduction
Операторы раздела reduction

nowait - Отменяет барьерную синхронизацию при завершении выполнения параллельной секции.
schedule -
nowait - Отменяет барьерную синхронизацию при завершении выполнения параллельной секции.
schedule -





Параллельная обработка в конструкциях, отличных от циклов
OpenMP поддерживает параллелизм и на уровне функций. Этот механизм
Параллельная обработка в конструкциях, отличных от циклов
OpenMP поддерживает параллелизм и на уровне функций. Этот механизм

![void QuickSort (int numList[], int nLower, int nUpper) { if (nLower](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/557895/slide-29.jpg)
void QuickSort (int numList[], int nLower, int nUpper)
{
if (nLower
void QuickSort (int numList[], int nLower, int nUpper)
{
if (nLower

Синхронизация
Барьерная синхронизация. В некоторых ситуациях ее целесообразно выполнять наряду с неявной. Используется #pragma omp
Синхронизация
Барьерная синхронизация. В некоторых ситуациях ее целесообразно выполнять наряду с неявной. Используется #pragma omp






В параллельных регионах часто встречаются блоки кода, доступ к которым желательно предоставлять только
В параллельных регионах часто встречаются блоки кода, доступ к которым желательно предоставлять только

Функции OpenMP
void omp_set_num_threads(int threads);
Задает количество потоков (threads) при выполнении параллельных секций
Функции OpenMP
void omp_set_num_threads(int threads);
Задает количество потоков (threads) при выполнении параллельных секций

int omp_get_num_procs(void);
Возвращает количество процессоров, доступных в данный момент программе.
int
int omp_get_num_procs(void);
Возвращает количество процессоров, доступных в данный момент программе.
int

Переменные окружения OpenMP
OMP_NUM_THREADS
Задает количество нитей при выполнении параллельных секций программы.
OMP_SCHEDULE
Задает способ
Переменные окружения OpenMP
OMP_NUM_THREADS
Задает количество нитей при выполнении параллельных секций программы.
OMP_SCHEDULE
Задает способ

void omp_set_nested(int nested);
Разрешает или запрещает вложенный параллелизм. По умолчанию вложенный параллелизм
void omp_set_nested(int nested);
Разрешает или запрещает вложенный параллелизм. По умолчанию вложенный параллелизм
 Мастер-класс: Создание виртуальной экскурсии по музею образовательной организации
Мастер-класс: Создание виртуальной экскурсии по музею образовательной организации Языки программирования
Языки программирования Нейтрализация инсайдерских угроз функционированию программных компонентов на основе двухконтурной архитектуры безопасности
Нейтрализация инсайдерских угроз функционированию программных компонентов на основе двухконтурной архитектуры безопасности Электронные таблицы MS Excel
Электронные таблицы MS Excel Целесообразность создания и использования виртуальных компьютерных классов в процессе обучения
Целесообразность создания и использования виртуальных компьютерных классов в процессе обучения Обобщение темы «Базы данных» Решение заданий ЕГЭ то теме «Базы данных»
Обобщение темы «Базы данных» Решение заданий ЕГЭ то теме «Базы данных» Качество программного изделия
Качество программного изделия Сбалансированные деревья поиска
Сбалансированные деревья поиска Электронная библиотека издательства Юрайт
Электронная библиотека издательства Юрайт 1С-Отчетность за 9 месяцев, в центре внимания - 6-НДФЛ
1С-Отчетность за 9 месяцев, в центре внимания - 6-НДФЛ Система управління захистом персональних даних клієнтів банку
Система управління захистом персональних даних клієнтів банку Разработка интерфейса пользователя игрового сервера с дополнением datebase
Разработка интерфейса пользователя игрового сервера с дополнением datebase Форматирование текста
Форматирование текста Аттестационная работа. Применение метода учебных проектов при обучении информатики в начальных классах
Аттестационная работа. Применение метода учебных проектов при обучении информатики в начальных классах Язык программирования Python
Язык программирования Python Codecraft HTML. Атрибуты тегов
Codecraft HTML. Атрибуты тегов БазыДанных. Access2007
БазыДанных. Access2007 Системы счисления. Подготовка к ЕГЭ
Системы счисления. Подготовка к ЕГЭ Подготовлено: Всеволод Цуриков, www.2bzy.net Для команды TangoCamp, Киев
Подготовлено: Всеволод Цуриков, www.2bzy.net Для команды TangoCamp, Киев Васина Яна. Инстаграм
Васина Яна. Инстаграм ЭЛЕКТРОННЫЕ ТАБЛИЦЫ: Общие сведения
ЭЛЕКТРОННЫЕ ТАБЛИЦЫ: Общие сведения Решение примеров и задач на тему Технология анализа экономических данных
Решение примеров и задач на тему Технология анализа экономических данных Презентация "Пассивные системы охлаждения" - скачать презентации по Информатике
Презентация "Пассивные системы охлаждения" - скачать презентации по Информатике Межсетевой экран и его функции. Основные компоненты брандмауэра
Межсетевой экран и его функции. Основные компоненты брандмауэра Культура электронного общения
Культура электронного общения Основы алгоритмизации и программирования. Лекция 12
Основы алгоритмизации и программирования. Лекция 12 Алгоритмы. Понятие алгоритма
Алгоритмы. Понятие алгоритма Загрози та головні уразливості критичноважливих об’єктів інфраструктури провідних країн світу і України. (Тема 1.3)
Загрози та головні уразливості критичноважливих об’єктів інфраструктури провідних країн світу і України. (Тема 1.3)