- Тема 4. Сортировка массивов

Содержание
- 2. © С.В.Кухта, 2009 Постановка задачи сортировки Простые алгоритмы сортировки Быстрые алгоритмы сортировки Алгоритмы поиска Содержание
- 3. © С.В.Кухта, 2009 1. Постановка задачи сортировки
- 4. © С.В.Кухта, 2009 Эта Тема посвящена сугубо алгоритмической проблеме упорядочения данных. Необходимость отсортировать какие-либо величины возникает
- 5. © С.В.Кухта, 2009 Однако верно и обратное. Сколь бы хорошим и эффективным ни был выбранный вами
- 6. © С.В.Кухта, 2009 Методы упорядочения подразделяются на внутренние (обрабатывающие массивы) и внешние (занимающиеся только файлами). В
- 7. © С.В.Кухта, 2009 Под сортировкой последовательности понимают процесс перестановки элементов последовательности в определенном порядке: по возрастанию,
- 8. © С.В.Кухта, 2009 Основными требованиями к программе сортировки массива являются эффективность по времени и экономное использование
- 9. © С.В.Кухта, 2009 К простым внутренним сортировкам относят методы, сложность которых пропорциональна квадрату размерности входных данных.
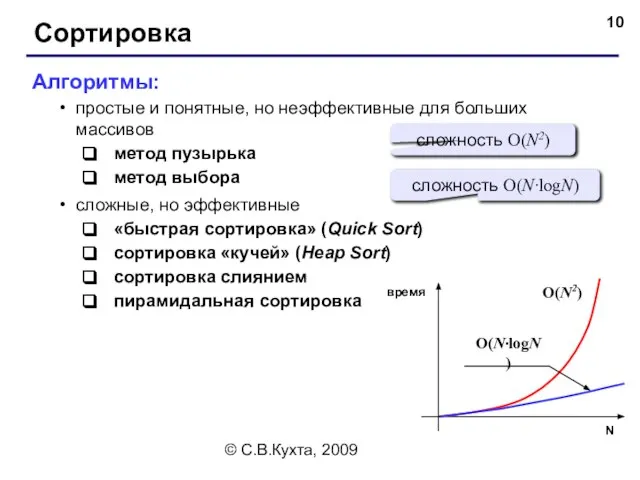
- 10. © С.В.Кухта, 2009 Сортировка Алгоритмы: простые и понятные, но неэффективные для больших массивов метод пузырька метод
- 11. © С.В.Кухта, 2009 Количество действий, необходимых для упорядочения некоторой последовательности данных, конечно же, зависит не только
- 12. © С.В.Кухта, 2009 Как правило, сложность алгоритмов подсчитывают раздельно по количеству сравнений и по количеству перемещений
- 13. © С.В.Кухта, 2009 2. Простые алгоритмы сортировки
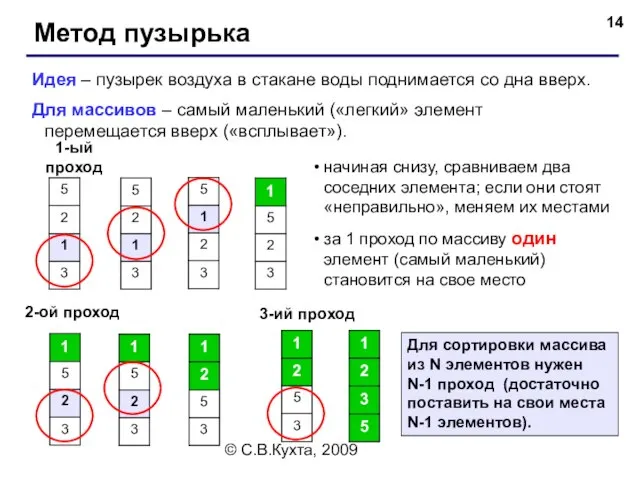
- 14. © С.В.Кухта, 2009 Метод пузырька Идея – пузырек воздуха в стакане воды поднимается со дна вверх.
- 15. © С.В.Кухта, 2009 Программа 1-ый проход: сравниваются пары A[N-1] и A[N], A[N-2] и A[N-1] … A[1]
- 16. © С.В.Кухта, 2009 Программа program qq; const N = 10; var A: array[1..N] of integer; i,
- 17. © С.В.Кухта, 2009 Внешний цикл выполнился n–1 раз. Внутренний цикл выполняется j раз (K = n–2,
- 18. © С.В.Кухта, 2009 Метод пузырька с флажком Идея – если при выполнении метода пузырька не было
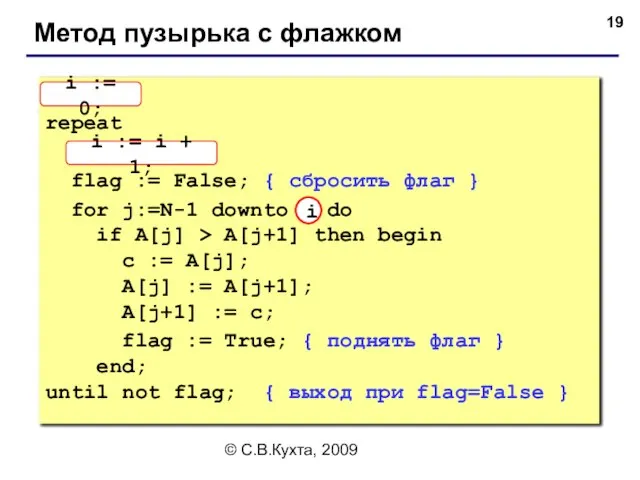
- 19. © С.В.Кухта, 2009 Метод пузырька с флажком i := 0; repeat i := i + 1;
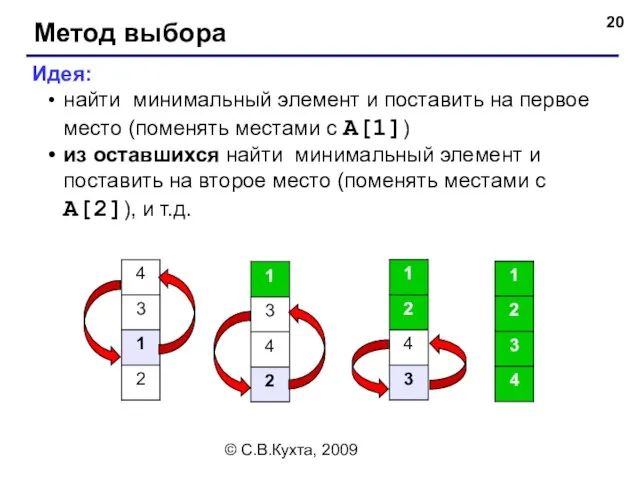
- 20. © С.В.Кухта, 2009 Метод выбора Идея: найти минимальный элемент и поставить на первое место (поменять местами
- 21. © С.В.Кухта, 2009 Метод выбора for i := 1 to N-1 do begin nMin = i
- 22. © С.В.Кухта, 2009 Самый простой способ сортировки, который приходит в голову, - это упорядочение данных по
- 23. © С.В.Кухта, 2009 Алгоритм ПрВст Первый элемент записать "не раздумывая". Пока не закончится последовательность вводимых данных,
- 24. © С.В.Кухта, 2009 Фрагмент программы: Сортировка простыми вставками for i:= 2 to N do if a[i-1]>a[i]
- 25. © С.В.Кухта, 2009 Чтобы сократить количество сравнений, производимых нашей программой, дополним сортируемый массив нулевой компонентой (это
- 26. © С.В.Кухта, 2009 Фрагмент программы: for i:= 2 to N do if a[i-1]>a[i] then begin a[0]:=
- 27. © С.В.Кухта, 2009 Эффективность алгоритма. Понятно, что для этой сортировки наилучшим будет случай, когда на вход
- 28. © С.В.Кухта, 2009 Пример сортировки. Предположим, что нужно отсортировать следующий набор чисел: 5 3 4 3
- 29. © С.В.Кухта, 2009 Сортировку простыми вставками можно немного улучшить: поиск "подходящего места" в упорядоченной последовательности можно
- 30. © С.В.Кухта, 2009 Пусть, к примеру, нужно найти место для элемента 7 в таком массиве: [2
- 31. © С.В.Кухта, 2009 Давайте договоримся, что новой "серединой" последовательности всегда будет становиться левый центральный элемент. Это
- 32. © С.В.Кухта, 2009 Если бы в той же самой последовательности нужно было найти позицию не для
- 33. © С.В.Кухта, 2009 Из приведенных примеров уже видно, что поиск ведется до тех пор, пока левая
- 34. © С.В.Кухта, 2009 Будет ли такой алгоритм универсальным? Давайте проверим, что же произойдет, если мы станем
- 35. © С.В.Кухта, 2009 Добавим число 21 в последовательность. 2 4 6 8 10 [12 14 16
- 36. © С.В.Кухта, 2009 Фрагмент программы: for i:= 2 to n do if a[i-1]>a[i] then begin x:=
- 37. © С.В.Кухта, 2009 Эффективность алгоритма. Теперь на каждом шаге выполняется не N, а log2N проверок, что
- 38. © С.В.Кухта, 2009 3. Быстрые алгоритмы сортировки
- 39. © С.В.Кухта, 2009 В отличие от простых сортировок, имеющих сложность O(N2), к улучшенным сортировкам относятся алгоритмы
- 40. © С.В.Кухта, 2009 Эта сортировка базируется на уже известном нам алгоритме простых вставок. Смысл ее состоит
- 41. © С.В.Кухта, 2009 Сортировку Шелла придумал Дональд Л. Шелл. Ее необычность состоит в том, что она
- 42. © С.В.Кухта, 2009 Сортирует элементы массива А[1..n] следующим образом: на первом шаге упорядочиваются элементы n/2 пар
- 43. © С.В.Кухта, 2009 На рис. а изображены восемь подсписков, по два элемента в каждом, в которых
- 44. © С.В.Кухта, 2009 На рис. б мы видим уже четыре подсписка по четыре элемента в каждом:
- 45. © С.В.Кухта, 2009 На рис. в показаны два подсписка, состоящие из элементов с нечетными и четными
- 46. © С.В.Кухта, 2009 На рис. г мы вновь возвращаемся к одному списку. Сортировка Шелла
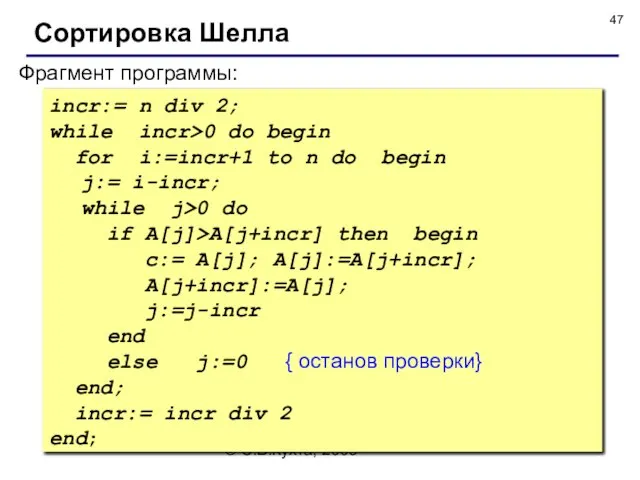
- 47. © С.В.Кухта, 2009 Фрагмент программы: incr:= n div 2; while incr>0 do begin for i:=incr+1 to
- 48. © С.В.Кухта, 2009 Полный анализ сортировки Шелла чрезвычайно сложен, и мы не собираемся на нем останавливаться.
- 49. © С.В.Кухта, 2009 Попытаемся теперь усовершенствовать другой рассмотренный выше простой алгоритм: сортировку простым выбором. Р.Флойд предложил
- 50. © С.В.Кухта, 2009 Для начала необходимо перестроить исходный массив так, чтобы он превратился в пирамиду, где
- 51. © С.В.Кухта, 2009 Итак, будем рассматривать наш линейный массив как пирамидальную структуру: Видно, что любой элемент
- 52. © С.В.Кухта, 2009 Начнем процесс просеивания "снизу". Половина элементов (с ((N div 2)+1)-го по N-й) являются
- 53. © С.В.Кухта, 2009 Фрагмент программы алгоритма просеивания: for i:= (N div 2)downto 1 do begin j:=i;
- 54. © С.В.Кухта, 2009 Пример результата просеивания Возьмем массив [1,7,5,4,9,8,12,11,2,10,3,6] (N = 12). Его исходное состояние таково
- 55. © С.В.Кухта, 2009 перестановка не требуется Пирамидальная сортировка: просеивание
- 56. © С.В.Кухта, 2009 перестановка элементов 9 и 10 Пирамидальная сортировка: просеивание
- 57. © С.В.Кухта, 2009 перестановка элементов 4 и 11 Пирамидальная сортировка: просеивание
- 58. © С.В.Кухта, 2009 перестановка элементов 5 и 12 элемент 5 сыновей не имеет, проверка вниз не
- 59. © С.В.Кухта, 2009 перестановка элементов 7 и 11 производится проверка тройки элементов 7, 4 и 2;
- 60. © С.В.Кухта, 2009 производится проверка тройки элементов 1, 8 и 5; требуется перестановка 1 и 8
- 61. © С.В.Кухта, 2009 Итак, мы превратили исходный массив в пирамиду: в любой тройке a[i], a[2*i] и
- 62. © С.В.Кухта, 2009 Для того чтобы отсортировать массив методом Пирамиды, необходимо выполнить такую последовательность действий: 0-й
- 63. © С.В.Кухта, 2009 Часть программы, реализующая нулевой шаг алгоритма, приведена в пункте "Просеивание", поэтому здесь приведена
- 64. © С.В.Кухта, 2009 Продолжим сортировку массива, для которого мы уже построили пирамиду: [12, 11, 8, 7,
- 65. © С.В.Кухта, 2009 1) Меняем местами a[1] и a[12]: [1, 11, 8, 7, 10, 6, 5,
- 66. © С.В.Кухта, 2009 5) Меняем местами a[1] и a[10]: [1, 9, 8, 7, 3, 6, 5,
- 67. © С.В.Кухта, 2009 5) Меняем местами a[1] и a[10]: [1, 9, 8, 7, 3, 6, 5,
- 68. © С.В.Кухта, 2009 9) Меняем местами a[1] и a[8]: [1, 7, 6, 4, 3, 2, 5],
- 69. © С.В.Кухта, 2009 13) Меняем местами a[1] и a[6]: [2, 4, 5, 1, 3], 6, 7,
- 70. © С.В.Кухта, 2009 19) Меняем местами a[1] и a[3]: [2, 1], 3, 4, 5, 6, 7,
- 71. © С.В.Кухта, 2009 Эффективность алгоритма Пирамидальная сортировка хорошо работает с большими массивами, однако на маленьких примерах
- 72. © С.В.Кухта, 2009 «Быстрая сортировка» (Quick Sort) Идея – более эффективно переставлять элементы, расположенные дальше друг
- 73. © С.В.Кухта, 2009 «Быстрая сортировка» (Quick Sort) Медиана – такое значение X, что слева и справа
- 74. © С.В.Кухта, 2009 «Быстрая сортировка» (Quick Sort)
- 75. © С.В.Кухта, 2009 «Быстрая сортировка» (Quick Sort) procedure QSort ( first, last: integer); var L, R,
- 76. © С.В.Кухта, 2009 «Быстрая сортировка» (Quick Sort) program qq; const N = 10; var A: array[1..N]
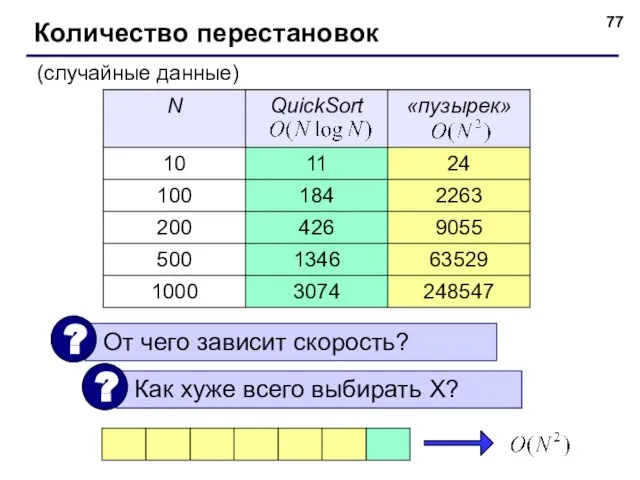
- 77. © С.В.Кухта, 2009 Количество перестановок (случайные данные)
- 78. © С.В.Кухта, 2009 4. Поиск в массиве
- 79. © С.В.Кухта, 2009 Поиск в массиве Задача – найти в массиве элемент, равный X, или установить,
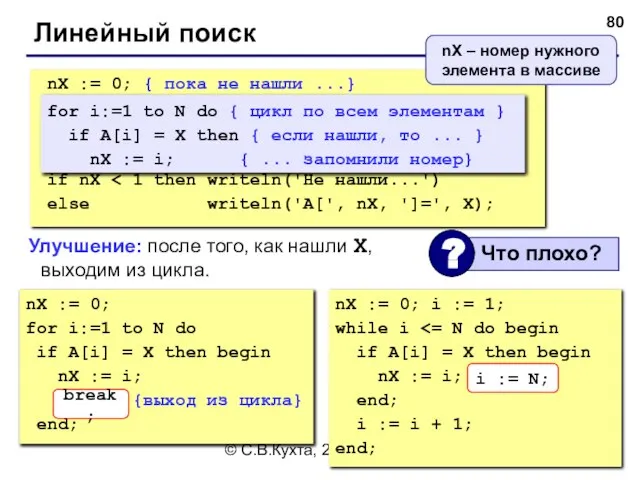
- 80. © С.В.Кухта, 2009 Линейный поиск nX := 0; for i:=1 to N do if A[i] =
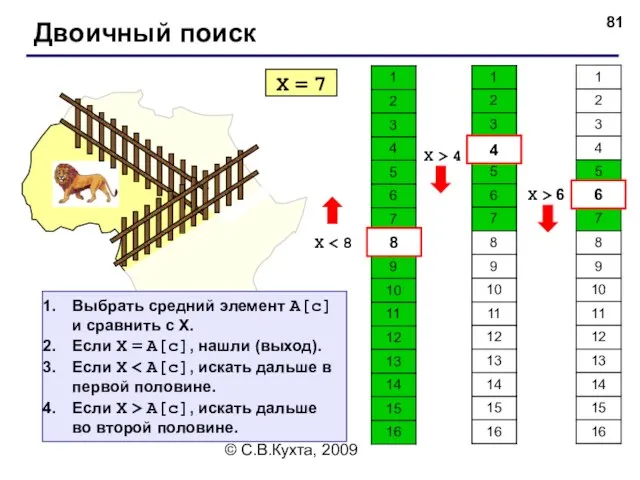
- 81. © С.В.Кухта, 2009 Двоичный поиск X = 7 X 8 4 X > 4 6 X
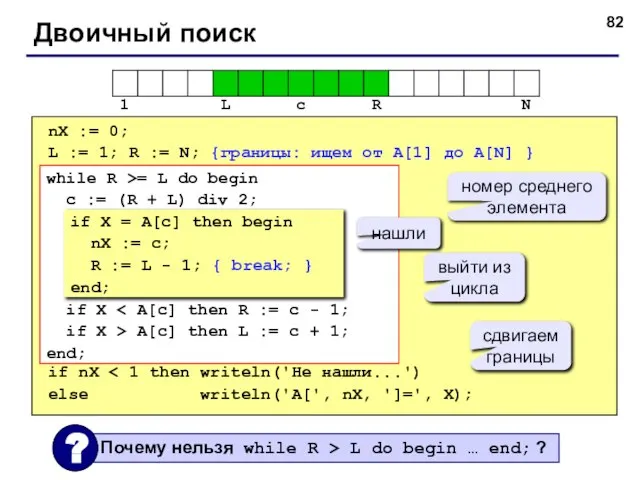
- 82. © С.В.Кухта, 2009 Двоичный поиск nX := 0; L := 1; R := N; {границы: ищем
- 84. Скачать презентацию

© С.В.Кухта, 2009
Постановка задачи сортировки
Простые алгоритмы сортировки
Быстрые алгоритмы сортировки
Алгоритмы поиска
Содержание
© С.В.Кухта, 2009
Постановка задачи сортировки
Простые алгоритмы сортировки
Быстрые алгоритмы сортировки
Алгоритмы поиска
Содержание

© С.В.Кухта, 2009
1. Постановка задачи сортировки
© С.В.Кухта, 2009
1. Постановка задачи сортировки

© С.В.Кухта, 2009
Эта Тема посвящена сугубо алгоритмической проблеме упорядочения данных.
Необходимость отсортировать
© С.В.Кухта, 2009
Эта Тема посвящена сугубо алгоритмической проблеме упорядочения данных.
Необходимость отсортировать

© С.В.Кухта, 2009
Однако верно и обратное. Сколь бы хорошим и эффективным
© С.В.Кухта, 2009
Однако верно и обратное. Сколь бы хорошим и эффективным

© С.В.Кухта, 2009
Методы упорядочения подразделяются на
внутренние (обрабатывающие массивы)
и внешние
© С.В.Кухта, 2009
Методы упорядочения подразделяются на
внутренние (обрабатывающие массивы)
и внешние

© С.В.Кухта, 2009
Под сортировкой последовательности понимают процесс перестановки элементов последовательности в
© С.В.Кухта, 2009
Под сортировкой последовательности понимают процесс перестановки элементов последовательности в

© С.В.Кухта, 2009
Основными требованиями к программе сортировки массива являются эффективность по
© С.В.Кухта, 2009
Основными требованиями к программе сортировки массива являются эффективность по

© С.В.Кухта, 2009
К простым внутренним сортировкам относят методы, сложность которых пропорциональна
© С.В.Кухта, 2009
К простым внутренним сортировкам относят методы, сложность которых пропорциональна
© С.В.Кухта, 2009
Сортировка
Алгоритмы:
простые и понятные, но неэффективные для больших массивов
метод пузырька
метод
© С.В.Кухта, 2009
Сортировка
Алгоритмы:
простые и понятные, но неэффективные для больших массивов
метод пузырька
метод

© С.В.Кухта, 2009
Количество действий, необходимых для упорядочения некоторой последовательности данных, конечно
© С.В.Кухта, 2009
Количество действий, необходимых для упорядочения некоторой последовательности данных, конечно

© С.В.Кухта, 2009
Как правило, сложность алгоритмов подсчитывают раздельно по количеству сравнений
© С.В.Кухта, 2009
Как правило, сложность алгоритмов подсчитывают раздельно по количеству сравнений

© С.В.Кухта, 2009
2. Простые алгоритмы сортировки
© С.В.Кухта, 2009
2. Простые алгоритмы сортировки
© С.В.Кухта, 2009
Метод пузырька
Идея – пузырек воздуха в стакане воды поднимается
© С.В.Кухта, 2009
Метод пузырька
Идея – пузырек воздуха в стакане воды поднимается
![© С.В.Кухта, 2009 Программа 1-ый проход: сравниваются пары A[N-1] и A[N],](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/568585/slide-14.jpg)
© С.В.Кухта, 2009
Программа
1-ый проход:
сравниваются пары
A[N-1] и A[N], A[N-2] и A[N-1]
© С.В.Кухта, 2009
Программа
1-ый проход:
сравниваются пары
A[N-1] и A[N], A[N-2] и A[N-1]

© С.В.Кухта, 2009
Программа
program qq;
const N = 10;
var A: array[1..N] of integer;
© С.В.Кухта, 2009
Программа
program qq;
const N = 10;
var A: array[1..N] of integer;

© С.В.Кухта, 2009
Внешний цикл выполнился n–1 раз. Внутренний цикл выполняется j
© С.В.Кухта, 2009
Внешний цикл выполнился n–1 раз. Внутренний цикл выполняется j

© С.В.Кухта, 2009
Метод пузырька с флажком
Идея – если при выполнении метода
© С.В.Кухта, 2009
Метод пузырька с флажком
Идея – если при выполнении метода
© С.В.Кухта, 2009
Метод пузырька с флажком
i := 0;
repeat
i := i
© С.В.Кухта, 2009
Метод пузырька с флажком
i := 0;
repeat
i := i
© С.В.Кухта, 2009
Метод выбора
Идея:
найти минимальный элемент и поставить на первое место
© С.В.Кухта, 2009
Метод выбора
Идея:
найти минимальный элемент и поставить на первое место

© С.В.Кухта, 2009
Метод выбора
for i := 1 to N-1 do begin
© С.В.Кухта, 2009
Метод выбора
for i := 1 to N-1 do begin

© С.В.Кухта, 2009
Самый простой способ сортировки, который приходит в голову, -
© С.В.Кухта, 2009
Самый простой способ сортировки, который приходит в голову, -

© С.В.Кухта, 2009
Алгоритм ПрВст
Первый элемент записать "не раздумывая".
Пока не закончится
© С.В.Кухта, 2009
Алгоритм ПрВст
Первый элемент записать "не раздумывая".
Пока не закончится

© С.В.Кухта, 2009
Фрагмент программы:
Сортировка простыми вставками
for i:= 2 to N do
© С.В.Кухта, 2009
Фрагмент программы:
Сортировка простыми вставками
for i:= 2 to N do

© С.В.Кухта, 2009
Чтобы сократить количество сравнений, производимых нашей программой, дополним сортируемый
© С.В.Кухта, 2009
Чтобы сократить количество сравнений, производимых нашей программой, дополним сортируемый

© С.В.Кухта, 2009
Фрагмент программы:
for i:= 2 to N do
if
© С.В.Кухта, 2009
Фрагмент программы:
for i:= 2 to N do
if

© С.В.Кухта, 2009
Эффективность алгоритма.
Понятно, что для этой сортировки наилучшим будет случай,
© С.В.Кухта, 2009
Эффективность алгоритма.
Понятно, что для этой сортировки наилучшим будет случай,

© С.В.Кухта, 2009
Пример сортировки.
Предположим, что нужно отсортировать следующий набор чисел:
5 3
© С.В.Кухта, 2009
Пример сортировки.
Предположим, что нужно отсортировать следующий набор чисел:
5 3

© С.В.Кухта, 2009
Сортировку простыми вставками можно немного улучшить:
поиск "подходящего места"
© С.В.Кухта, 2009
Сортировку простыми вставками можно немного улучшить:
поиск "подходящего места"

© С.В.Кухта, 2009
Пусть, к примеру, нужно найти место для элемента 7
© С.В.Кухта, 2009
Пусть, к примеру, нужно найти место для элемента 7

© С.В.Кухта, 2009
Давайте договоримся, что новой "серединой" последовательности всегда будет становиться
© С.В.Кухта, 2009
Давайте договоримся, что новой "серединой" последовательности всегда будет становиться

© С.В.Кухта, 2009
Если бы в той же самой последовательности нужно было
© С.В.Кухта, 2009
Если бы в той же самой последовательности нужно было

© С.В.Кухта, 2009
Из приведенных примеров уже видно, что поиск ведется до
© С.В.Кухта, 2009
Из приведенных примеров уже видно, что поиск ведется до

© С.В.Кухта, 2009
Будет ли такой алгоритм универсальным?
Давайте проверим, что же
© С.В.Кухта, 2009
Будет ли такой алгоритм универсальным?
Давайте проверим, что же

© С.В.Кухта, 2009
Добавим число 21 в последовательность.
2 4 6 8
© С.В.Кухта, 2009
Добавим число 21 в последовательность.
2 4 6 8

© С.В.Кухта, 2009
Фрагмент программы:
for i:= 2 to n do
if
© С.В.Кухта, 2009
Фрагмент программы:
for i:= 2 to n do
if

© С.В.Кухта, 2009
Эффективность алгоритма.
Теперь на каждом шаге выполняется не N, а
© С.В.Кухта, 2009
Эффективность алгоритма.
Теперь на каждом шаге выполняется не N, а

© С.В.Кухта, 2009
3. Быстрые алгоритмы сортировки
© С.В.Кухта, 2009
3. Быстрые алгоритмы сортировки

© С.В.Кухта, 2009
В отличие от простых сортировок, имеющих сложность O(N2), к
© С.В.Кухта, 2009
В отличие от простых сортировок, имеющих сложность O(N2), к

© С.В.Кухта, 2009
Эта сортировка базируется на уже известном нам алгоритме простых
© С.В.Кухта, 2009
Эта сортировка базируется на уже известном нам алгоритме простых

© С.В.Кухта, 2009
Сортировку Шелла придумал Дональд Л. Шелл.
Ее необычность состоит
© С.В.Кухта, 2009
Сортировку Шелла придумал Дональд Л. Шелл.
Ее необычность состоит
![© С.В.Кухта, 2009 Сортирует элементы массива А[1..n] следующим образом: на первом](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/568585/slide-41.jpg)
© С.В.Кухта, 2009
Сортирует элементы массива А[1..n] следующим образом:
на первом шаге упорядочиваются
© С.В.Кухта, 2009
Сортирует элементы массива А[1..n] следующим образом:
на первом шаге упорядочиваются
© С.В.Кухта, 2009
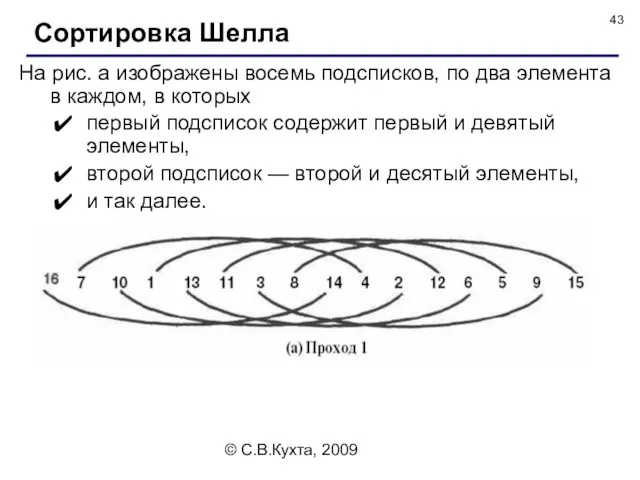
На рис. а изображены восемь подсписков, по два элемента
© С.В.Кухта, 2009
На рис. а изображены восемь подсписков, по два элемента
© С.В.Кухта, 2009
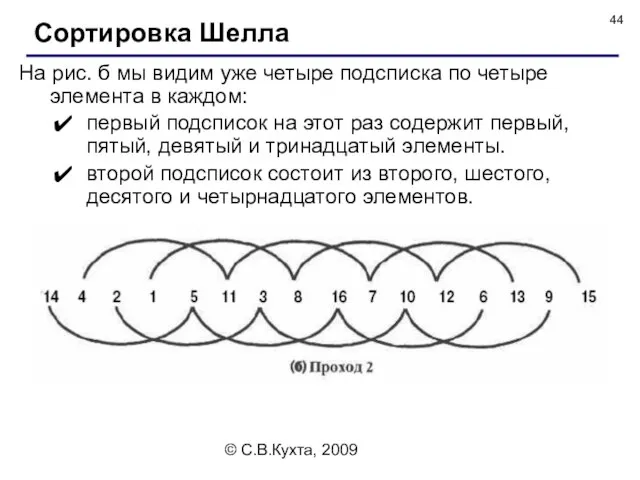
На рис. б мы видим уже четыре подсписка по
© С.В.Кухта, 2009
На рис. б мы видим уже четыре подсписка по
© С.В.Кухта, 2009
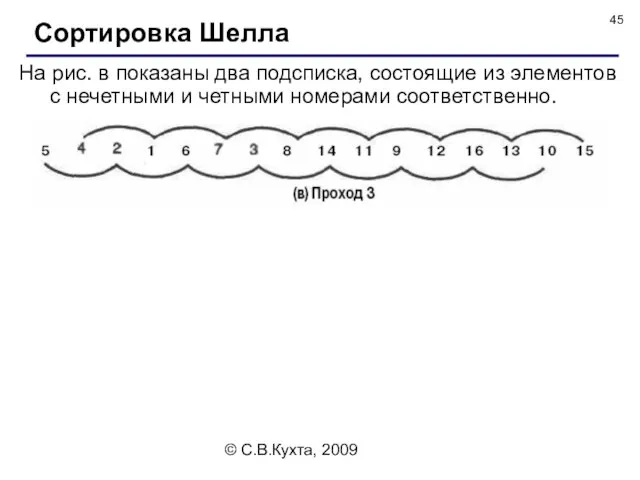
На рис. в показаны два подсписка, состоящие из элементов
© С.В.Кухта, 2009
На рис. в показаны два подсписка, состоящие из элементов
© С.В.Кухта, 2009
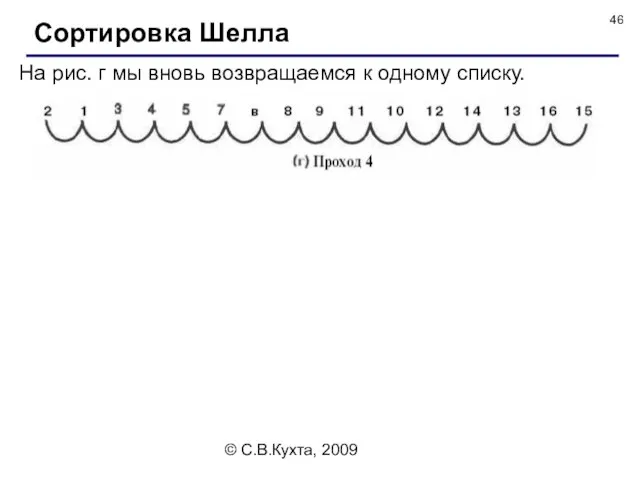
На рис. г мы вновь возвращаемся к одному списку.
Сортировка
© С.В.Кухта, 2009
На рис. г мы вновь возвращаемся к одному списку.
Сортировка
© С.В.Кухта, 2009
Фрагмент программы:
incr:= n div 2;
while incr>0 do begin
© С.В.Кухта, 2009
Фрагмент программы:
incr:= n div 2;
while incr>0 do begin

© С.В.Кухта, 2009
Полный анализ сортировки Шелла чрезвычайно сложен, и мы не
© С.В.Кухта, 2009
Полный анализ сортировки Шелла чрезвычайно сложен, и мы не

© С.В.Кухта, 2009
Попытаемся теперь усовершенствовать другой рассмотренный выше простой алгоритм: сортировку
© С.В.Кухта, 2009
Попытаемся теперь усовершенствовать другой рассмотренный выше простой алгоритм: сортировку

© С.В.Кухта, 2009
Для начала необходимо перестроить исходный массив так, чтобы он
© С.В.Кухта, 2009
Для начала необходимо перестроить исходный массив так, чтобы он

© С.В.Кухта, 2009
Итак, будем рассматривать наш линейный массив как пирамидальную структуру:
© С.В.Кухта, 2009
Итак, будем рассматривать наш линейный массив как пирамидальную структуру:

© С.В.Кухта, 2009
Начнем процесс просеивания "снизу". Половина элементов (с ((N div
© С.В.Кухта, 2009
Начнем процесс просеивания "снизу". Половина элементов (с ((N div

© С.В.Кухта, 2009
Фрагмент программы алгоритма просеивания:
for i:= (N div 2)downto 1
© С.В.Кухта, 2009
Фрагмент программы алгоритма просеивания:
for i:= (N div 2)downto 1
![© С.В.Кухта, 2009 Пример результата просеивания Возьмем массив [1,7,5,4,9,8,12,11,2,10,3,6] (N =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/568585/slide-53.jpg)
© С.В.Кухта, 2009
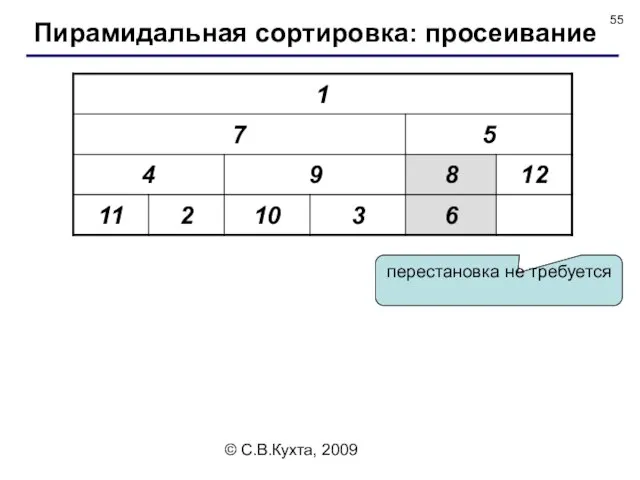
Пример результата просеивания
Возьмем массив [1,7,5,4,9,8,12,11,2,10,3,6] (N = 12).
Его исходное
© С.В.Кухта, 2009
Пример результата просеивания
Возьмем массив [1,7,5,4,9,8,12,11,2,10,3,6] (N = 12).
Его исходное
© С.В.Кухта, 2009
перестановка не требуется
Пирамидальная сортировка: просеивание
© С.В.Кухта, 2009
перестановка не требуется
Пирамидальная сортировка: просеивание
© С.В.Кухта, 2009
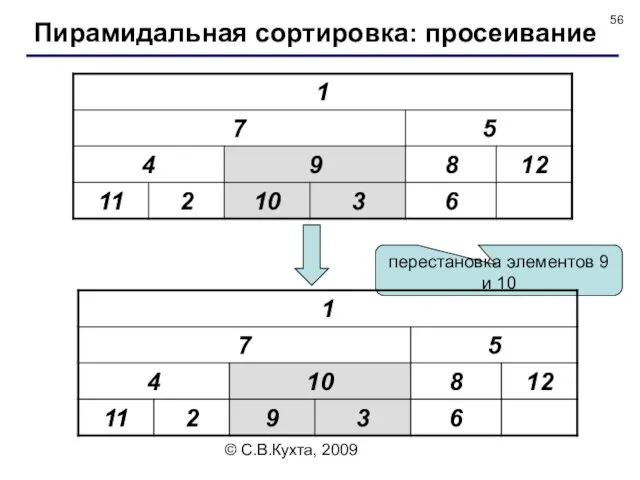
перестановка элементов 9 и 10
Пирамидальная сортировка: просеивание
© С.В.Кухта, 2009
перестановка элементов 9 и 10
Пирамидальная сортировка: просеивание
© С.В.Кухта, 2009
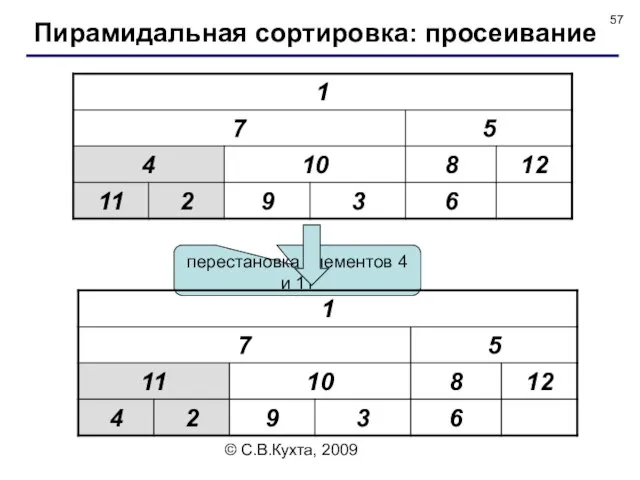
перестановка элементов 4 и 11
Пирамидальная сортировка: просеивание
© С.В.Кухта, 2009
перестановка элементов 4 и 11
Пирамидальная сортировка: просеивание
© С.В.Кухта, 2009
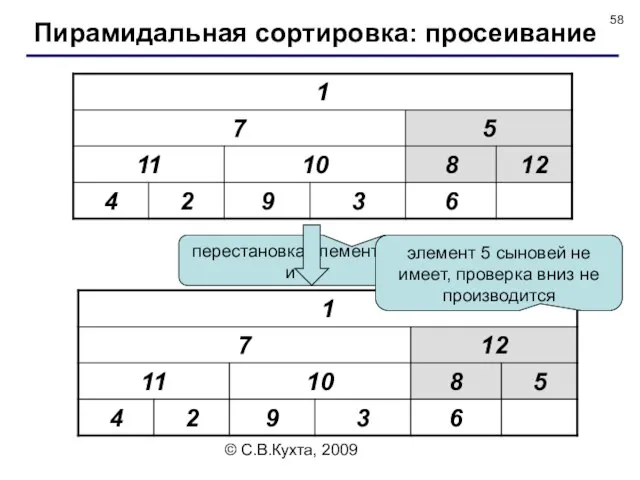
перестановка элементов 5 и 12
элемент 5 сыновей не имеет,
© С.В.Кухта, 2009
перестановка элементов 5 и 12
элемент 5 сыновей не имеет,
© С.В.Кухта, 2009
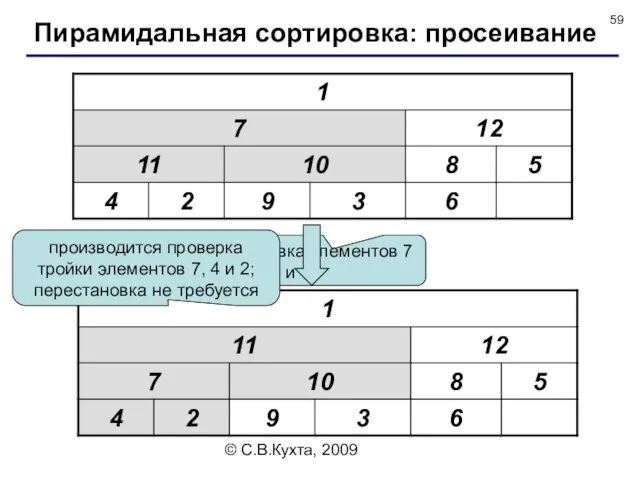
перестановка элементов 7 и 11
производится проверка тройки элементов 7,
© С.В.Кухта, 2009
перестановка элементов 7 и 11
производится проверка тройки элементов 7,
© С.В.Кухта, 2009
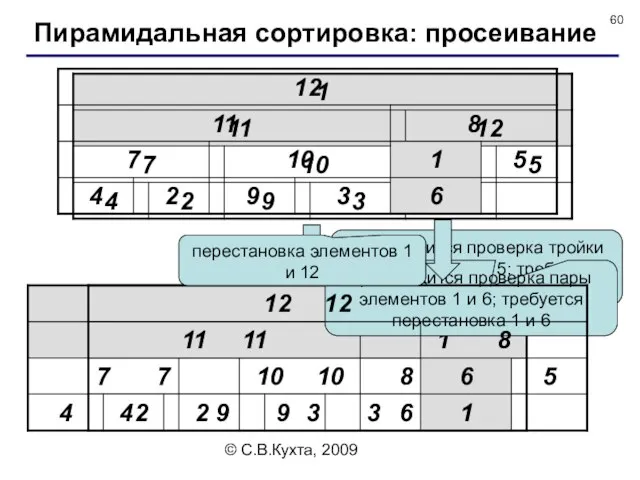
производится проверка тройки элементов 1, 8 и 5; требуется
© С.В.Кухта, 2009
производится проверка тройки элементов 1, 8 и 5; требуется

© С.В.Кухта, 2009
Итак, мы превратили исходный массив в пирамиду:
в любой тройке
© С.В.Кухта, 2009
Итак, мы превратили исходный массив в пирамиду:
в любой тройке

© С.В.Кухта, 2009
Для того чтобы отсортировать массив методом Пирамиды, необходимо выполнить
© С.В.Кухта, 2009
Для того чтобы отсортировать массив методом Пирамиды, необходимо выполнить

© С.В.Кухта, 2009
Часть программы, реализующая нулевой шаг алгоритма, приведена в пункте
© С.В.Кухта, 2009
Часть программы, реализующая нулевой шаг алгоритма, приведена в пункте

© С.В.Кухта, 2009
Продолжим сортировку массива, для которого мы уже построили пирамиду:
© С.В.Кухта, 2009
Продолжим сортировку массива, для которого мы уже построили пирамиду:
![© С.В.Кухта, 2009 1) Меняем местами a[1] и a[12]: [1, 11,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/568585/slide-64.jpg)
© С.В.Кухта, 2009
1) Меняем местами a[1] и a[12]:
[1, 11, 8,
© С.В.Кухта, 2009
1) Меняем местами a[1] и a[12]:
[1, 11, 8,
![© С.В.Кухта, 2009 5) Меняем местами a[1] и a[10]: [1, 9,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/568585/slide-65.jpg)
© С.В.Кухта, 2009
5) Меняем местами a[1] и a[10]:
[1, 9, 8, 7,
© С.В.Кухта, 2009
5) Меняем местами a[1] и a[10]:
[1, 9, 8, 7,
![© С.В.Кухта, 2009 5) Меняем местами a[1] и a[10]: [1, 9,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/568585/slide-66.jpg)
© С.В.Кухта, 2009
5) Меняем местами a[1] и a[10]:
[1, 9, 8, 7,
© С.В.Кухта, 2009
5) Меняем местами a[1] и a[10]:
[1, 9, 8, 7,
![© С.В.Кухта, 2009 9) Меняем местами a[1] и a[8]: [1, 7,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/568585/slide-67.jpg)
© С.В.Кухта, 2009
9) Меняем местами a[1] и a[8]:
[1, 7, 6, 4,
© С.В.Кухта, 2009
9) Меняем местами a[1] и a[8]:
[1, 7, 6, 4,
![© С.В.Кухта, 2009 13) Меняем местами a[1] и a[6]: [2, 4,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/568585/slide-68.jpg)
© С.В.Кухта, 2009
13) Меняем местами a[1] и a[6]:
[2, 4, 5, 1,
© С.В.Кухта, 2009
13) Меняем местами a[1] и a[6]:
[2, 4, 5, 1,
![© С.В.Кухта, 2009 19) Меняем местами a[1] и a[3]: [2, 1],](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/568585/slide-69.jpg)
© С.В.Кухта, 2009
19) Меняем местами a[1] и a[3]:
[2, 1], 3, 4,
© С.В.Кухта, 2009
19) Меняем местами a[1] и a[3]:
[2, 1], 3, 4,

© С.В.Кухта, 2009
Эффективность алгоритма
Пирамидальная сортировка хорошо работает с большими массивами,
© С.В.Кухта, 2009
Эффективность алгоритма
Пирамидальная сортировка хорошо работает с большими массивами,

© С.В.Кухта, 2009
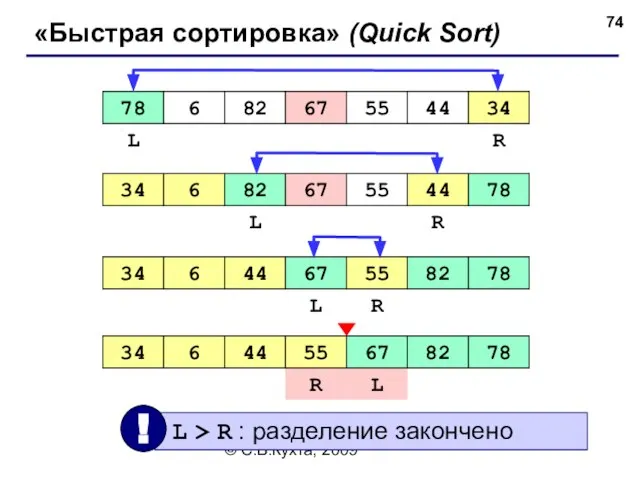
«Быстрая сортировка» (Quick Sort)
Идея – более эффективно переставлять элементы,
© С.В.Кухта, 2009
«Быстрая сортировка» (Quick Sort)
Идея – более эффективно переставлять элементы,

© С.В.Кухта, 2009
«Быстрая сортировка» (Quick Sort)
Медиана – такое значение X, что
© С.В.Кухта, 2009
«Быстрая сортировка» (Quick Sort)
Медиана – такое значение X, что
© С.В.Кухта, 2009
«Быстрая сортировка» (Quick Sort)
© С.В.Кухта, 2009
«Быстрая сортировка» (Quick Sort)

© С.В.Кухта, 2009
«Быстрая сортировка» (Quick Sort)
procedure QSort ( first, last: integer);
var
© С.В.Кухта, 2009
«Быстрая сортировка» (Quick Sort)
procedure QSort ( first, last: integer);
var

© С.В.Кухта, 2009
«Быстрая сортировка» (Quick Sort)
program qq;
const N = 10;
var A:
© С.В.Кухта, 2009
«Быстрая сортировка» (Quick Sort)
program qq;
const N = 10;
var A:
© С.В.Кухта, 2009
Количество перестановок
(случайные данные)
© С.В.Кухта, 2009
Количество перестановок
(случайные данные)

© С.В.Кухта, 2009
4. Поиск в массиве
© С.В.Кухта, 2009
4. Поиск в массиве

© С.В.Кухта, 2009
Поиск в массиве
Задача – найти в массиве элемент, равный
© С.В.Кухта, 2009
Поиск в массиве
Задача – найти в массиве элемент, равный
© С.В.Кухта, 2009
Линейный поиск
nX := 0;
for i:=1 to N do
if
© С.В.Кухта, 2009
Линейный поиск
nX := 0;
for i:=1 to N do
if
© С.В.Кухта, 2009
Двоичный поиск
X = 7
X < 8
8
4
X > 4
6
X >
© С.В.Кухта, 2009
Двоичный поиск
X = 7
X < 8
8
4
X > 4
6
X >
© С.В.Кухта, 2009
Двоичный поиск
nX := 0;
L := 1;
© С.В.Кухта, 2009
Двоичный поиск
nX := 0;
L := 1;
 Презентация "Эмигранты и аборигены цифрового мира" - скачать презентации по Информатике
Презентация "Эмигранты и аборигены цифрового мира" - скачать презентации по Информатике Организация сети передачи данных по энергосетям с применением PLC технологии
Организация сети передачи данных по энергосетям с применением PLC технологии Подходы к измерению информации
Подходы к измерению информации Сжатие информации
Сжатие информации Technical Notification HDV130 and HDV100 upgrade to Firmware V02.081
Technical Notification HDV130 and HDV100 upgrade to Firmware V02.081 Польза и вред интернета для учащихся и дошкольников
Польза и вред интернета для учащихся и дошкольников Установка редактора Sublime Text3
Установка редактора Sublime Text3 Применение электронных ресурсов при проведении уроков информатики
Применение электронных ресурсов при проведении уроков информатики Киберспорт в жизни школьников
Киберспорт в жизни школьников Ввод–вывод с квитированием по прерыванию
Ввод–вывод с квитированием по прерыванию Опыт внедрения подсистемы кадрового учета и расчета заработной платы в 1С:ERP Управление предприятием 2
Опыт внедрения подсистемы кадрового учета и расчета заработной платы в 1С:ERP Управление предприятием 2 Reveal the halloween picture (game)
Reveal the halloween picture (game) Найти корни квадратного уравнения Ax2+Bx+C=0
Найти корни квадратного уравнения Ax2+Bx+C=0 Информатика
Информатика Початки алгоритмізації та процедурного програмування. Циклічні програми
Початки алгоритмізації та процедурного програмування. Циклічні програми Презентация "Повторение" - скачать презентации по Информатике
Презентация "Повторение" - скачать презентации по Информатике Базы данных. Лекция 7
Базы данных. Лекция 7 История развития информационных технологий
История развития информационных технологий Язык описания данных ORACLE. Типы данных ORACLE. Таблицы. Представления
Язык описания данных ORACLE. Типы данных ORACLE. Таблицы. Представления Электронный сертификат – новый механизм обеспечения техническими средствами реабилитации
Электронный сертификат – новый механизм обеспечения техническими средствами реабилитации Коммерческое предложение по разработке корпоративного сайта для ООО Империя Строй
Коммерческое предложение по разработке корпоративного сайта для ООО Империя Строй Схемы программ (часть 1)
Схемы программ (часть 1) Компьютерные коммуникации
Компьютерные коммуникации Советы новичку: как пробиться в геймдев и пройти испытательный срок
Советы новичку: как пробиться в геймдев и пройти испытательный срок Файл и файловая система. Решение задач
Файл и файловая система. Решение задач Александр Шаповал Microsoft
Александр Шаповал Microsoft  Ввод и обработка цифровой информации
Ввод и обработка цифровой информации История развития ЭВМ
История развития ЭВМ