- Язык определения данных (DDL). Команды CREATE, ALTER, DROP. Создание таблиц БД

Содержание
- 2. Внутренний язык СУБД для работы с данными состоит из 2-х частей: языка определения данных (DDL- Data
- 3. Язык определения данных используется для создания, изменения и удаления объектов базы данных. Язык управления данными служит
- 4. Язык DDL позволяет описывать таблицы БД и связи между ними. Результатом компиляции DDL-операторов является набор таблиц,
- 5. Использование языка DDL в процессе работы позволяет сделать структуру реляционной БД динамической. (С течением времени БД
- 6. Операторы DDL можно использовать как в интерактивном, так и в программном SQL. Если программе или пользователю
- 7. Язык DML содержит набор операторов для манипулирования данными: вставки в БД новых сведений; модификации сведений; извлечение
- 8. DDL базируется на трёх командах SQL. CREATE – позволяет определить и создать объект БД; DROP -
- 9. Создание БД С помощью операторов DDL можно: создать новую БД, определить структуру новой таблицы и создать
- 10. В MS SQL SERVER существует оператор CREATE DATABASE, который является частью языка определения данных и служит
- 11. Создание базы данных – это процесс указания имени базы, определения размеров и размещения файлов базы данных
- 12. Если в процессе использования базы данных планируется размещение её на нескольких дисках, то в этом случае
- 13. Синтаксис CREATE DATABASE имя_базы_данных [ON [PRIMARY] (NAME=логическое_имя_файла, FILENAME=‘физическое_имя_файла’ [, SIZE=размер] [, MAXSIZE=максимальный размер] [, FILEGROWTH=шаг_приращения_размера]) [,
- 14. При создании базы данных можно указать следующие параметры: · PRIMARY указывает файлы основной группы файлов, которая
- 15. FILENAME – задаёт физическое имя и путь к файлу. SIZE – задает минимальный (начальный) размер файла.
- 16. MAXSIZE – указывает максимальный размер файла. Если размер не указан, то файл будет увеличиваться до полного
- 17. FOR RESTORE – задаёт восстановление системы по журналу транзакций в случае её сбоя. Имеется в виду
- 18. Создание таблиц БД Таблицы создаются командой CREATE TABLE. Эта команда создает пустую таблицу, не содержащую записей.
- 19. Синтаксис команды CREATE TABLE следующий: CREATE TABLE ( [( )], ( [( )]), …).
- 20. Пробелы не могут быть частью имени таблицы или любого другого создаваемого объекта, поэтому для разделения слов,
- 21. Значение длины поля зависит от типа данных. Если его не указывать, то СУБД сама назначает значение
- 22. Пример: CREATE TABLE STUDENTS (NOM_ZACH INTEGER, SFAM CHAR (20), SNAME CHAR (10), STIP DECIMAL)
- 23. Числовые типы Tочные числовые типы К категории точных числовых типов в SQL относятся те типы, значения
- 24. с плавающей запятой: float (от -1.79E + 308 до 1.79E + 308) и real (от -3.40E
- 25. DECIMAL [(точность[,масштаб])] Параметр точность указывает максимальное количество цифр вводимых данных этого типа (до и после десятичной
- 26. Строковые типы В SQL Server предусмотрены две дублирующих разновидности полей для представления текстовых данных: поля Unicode
- 27. Всего в SQL Server предусмотрены следующие типы для текстовых данных: ∙ char/nchar - строковые данные фиксированной
- 28. При использовании типа Char значения длиной короче заданной дополняются пробелами до указанной длины. Максимальное значение длины
- 29. Если необходимо ввести значения большой длины можно использовать ключевое слово мах, что позволяет определять столбцы до
- 30. datetime (8 байт, точность до 3,33 миллисекунд); smalldatetime (4 байта, точность до минуты). В большинстве приложений
- 31. Тип данных UNIQUEIDENTIFIER используется для хранения глобальных уникальных идентификационных номеров.
- 32. SQL_VARIANT - Служит для хранения значений разных типов одновременно, таких как числовые значения, строки и даты.
- 33. Логический тип данных - хранит значения вида true/false (единица/ноль). В SQL Server он представлен типом данных
- 34. DATEDIFF ( datepart , startdate , enddate )─ возвращает интервал времени, прошедшего между двумя временными отметками
- 36. В ряде случаев функцию DATEPART можно заменить более простыми функциями. DAY ( date ) - целочисленное
- 38. Пользовательские типы данных. Могут использоваться при определении какого-либо специфического или часто употребляемого формата. Создание пользовательского типа
- 39. EXEC sp_addtype dt, DATETIME, 'NULL' Удаление пользовательского типа данных происходит в результате выполнения процедуры sp_droptype type
- 40. CREATE TYPE SSN FROM varchar(10) NOT NULL ;
- 41. Получение информации о типах данных Получить список всех типов данных, включая пользовательские, можно из системной таблицы
- 42. Преобразование типов Для выполнения преобразований SQL Server содержит функции CONVERT и CAST, с помощью которых значения
- 43. Пример: SELECT ‘сегодня ‘ + CONVERT(VARCHAR(11),GETDATE()) CAST('1977.01.07‘ AS Datetime)
- 44. Оновные функции – поиск подстроки CHARINDEX (expressionToFind ,expressionToSearch[ , start_location ] ) - вырезка SUBSTRING (
- 45. Временные таблицы Временные таблицы похожи на обычные, однако они не предназначены для постоянного хранения данных. Они
- 46. В SQL Server существуют два типа временных таблиц: локальные и глобальные. Локальные временные таблицы доступны лишь
- 47. Создание ограничений
- 48. Декларативные ограничения при создании таблиц При создании таблиц могут быть заданы декларативные ограничения целостности атрибутов: значения
- 49. Например, на значение стипендии может быть наложено ограничение (стипендия должна находиться в пределах от 500 до
- 50. Возраст сотрудника должен быть не менее 18 лет: BIRTH_DAY DATE CHECK(DATEDIFF(YEAR,GETDATE(),BIRTH_DAY)>=18)
- 51. При создании ограничений необходимо учитывать следующее: ограничение, определенное для одного поля может ссылаться только на это
- 52. ограничения DEFAULT должны быть ограничениями на уровне поля; ограничения CHECK на уровне поля могут ссылаться только
- 55. Часто для поля или группы полей требуется реализовать ограничение, связанное c уникальностью значений. В этом случае
- 56. Ограничение PRIMARY KEY действует аналогично UNIQUE, но для таблицы должен быть определен только один первичный ключ,
- 57. PRIMARY KEY(NOM_ZACH, PKOD)
- 58. Ссылочная целостность
- 61. Таблица USP подчинена двум другим таблицам: SUBJECTS и STUDENTS. При этом таблица USP связана с таблицей
- 62. Для моделирования этих связей должны быть определены два внешних ключа (FOREIGN KEY) для полей NOM_ZACH и
- 63. Ключ FOREIGN KEY ограничивает значения, которые можно ввести в БД так, чтобы заставить внешний и родительский
- 64. Создадим таблицу USP с полем NOM_ZACH, и PKOD определенными в качестве внешних ключей: CREATE TABLE USP
- 65. Используя ограничения FOREIGN KEY, можно не указывать список полей родительского ключа, если родительский ключ имеет ограничение
- 66. В соответствии со стандартом, изменение или удаление значений родительского ключа не допускается. Это означает, что нельзя
- 68. При необходимости изменить или удалить текущее ссылочное значение родительского ключа существует следующие возможности: 1. Запретить изменения
- 69. Итак, изменения в родительском ключе можно разделить на ограниченные (NO ACTION), каскадируемые (CASCADE), пустые (SET NULL)
- 70. Предположим, что есть необходимость в изменении номера зачетной книжки, причем оценки должны сохраниться у этого же
- 71. CREATE TABLE USP (NOM_ZACH INTEGER NOT NULL, PKOD INTEGER, TNUM INTEGER, UDATE DATE , MARK INTEGER,
- 72. Если данные о студенте удаляются, удаление их должно быть выполнено сначала в подчинённой (USP), а затем
- 74. Изменение таблиц Изменение таблицы осуществляется командой ALTER TABLE. Чаще всего с помощью этой команды добавляют поля
- 75. Пример показывает добавление столбца, который допускает значения NULL В новом столбце в каждой строке будет значение
- 76. Новое поле станет последним по порядку в таблице. Допускается добавление сразу нескольких полей. Они должны быть
- 77. В таблицу могут быть добавлены и новые ограничения с помощью команды ADD CONSTRAINT . Имя ограничения
- 78. Примеры: 1. Для добавления ограничения, задающего значение по умолчанию: ALTER TABLE USP ADD CONSTRAINT Def_Mark DEFAULT
- 79. Для получения информации об ограничениях используется системная процедура sp_helpconstraint имя_таблицы или sp_help имя ограничения.
- 80. Удаление столбцов и ограничений Из созданной таблицы можно удалить столбцы или ограничения. При удалении ограничений следует
- 81. Разрешение и запрет ограничений С помощью команды ALTER TABLE с предложениями ENABLE и DISABLE можно разрешать
- 82. Модификация столбцов Иногда при создании таблиц делают неверные предположения относительно типа данных, которые собираются хранить в
- 83. Удаление таблиц Удаление таблиц выполняется с помощью команды DROP TABLE. Для того чтобы иметь возможность удалить
- 84. Создание индексов Индекс - упорядоченный список полей или групп полей в таблице. Таблицы могут иметь огромное
- 85. С помощью индексов осуществляется доступ к данным наиболее оптимальным способом. В индексы следует включать поля, к
- 86. Если создан индекс по первичному ключу, а затем необходимо найти строку с данными, Server сначала найдет
- 87. Индекс может быть создан на большинстве столбцов таблицы или представления. Исключением, являются столбцы с типами данных
- 88. Индекс состоит из набора страниц, узлов индекса, которые организованы в виде древовидной структуры — сбалансированного дерева.
- 90. Когда формируется запрос на индексированный столбец, подсистема запросов начинает идти сверху от корневого узла и постепенно
- 91. Листья индекса могут содержать как сами данные таблицы, так и просто указатель на строки с данными
- 92. Кластеризованный индекс Кластеризованный индекс хранит реальные строки данных в листьях индекса. Важной характеристикой кластеризованного индекса является
- 93. Некластеризованный индекс В отличие от кластеризованного индекса, листья некластеризованного индекса содержат только те столбцы (ключевые), по
- 94. Содержание указателя на данные зависит от способа хранения данных: кластеризованная таблица или куча. Если указатель ссылается
- 96. Для создания индекса используется оператор CREATE INDEX. Синтаксис: CREATE INDEX имя_индекса ON таблица (поле[, …n])
- 97. Таблица, для которой создаётся индекс, должна уже существовать и содержать имена индексируемых полей. При этом имя
- 98. Для создания уникальных (не содержащих повторяющихся значений) индексов используется ключевое слово UNIQUE в операторе CREATE INDEX
- 99. Для удаления индекса используется команда DROP INDEX имя индекса Чтобы изменить индекс таблицы, необходимо удалить его
- 100. Использование опции Clustered index позволяет произвести так называемое кластерное индексирование, в результате чего будут отсортированы данные
- 101. Для повышения быстродействия кластерный индекс следует создавать раньше некластерных индексов. По умолчанию создается некластерный индекс.
- 102. Проектирование индексов Индексы могут улучить производительность системы, т.к. они обеспечивают подсистему запросов быстрым путем для нахождения
- 103. Рекомендации при планировании стратегии индексирования Для таблиц которые часто обновляются следует использовать как можно меньше индексов.
- 104. Создавать индексы на небольших таблицах не имеет смысла, т.к. возможно использование поиска по индексу может занять
- 105. Последовательность создания таблиц
- 107. Скачать презентацию

Внутренний язык СУБД для работы с данными состоит из 2-х
Внутренний язык СУБД для работы с данными состоит из 2-х

Язык определения данных используется для создания, изменения и удаления объектов
Язык определения данных используется для создания, изменения и удаления объектов

Язык DDL позволяет описывать таблицы БД и связи между ними. Результатом
Язык DDL позволяет описывать таблицы БД и связи между ними. Результатом

Использование языка DDL в процессе работы позволяет сделать структуру реляционной
Использование языка DDL в процессе работы позволяет сделать структуру реляционной

Операторы DDL можно использовать как в интерактивном, так и в
Операторы DDL можно использовать как в интерактивном, так и в

Язык DML содержит набор операторов для манипулирования данными:
вставки в БД
Язык DML содержит набор операторов для манипулирования данными:
вставки в БД

DDL базируется на трёх командах SQL.
CREATE – позволяет определить и создать
DDL базируется на трёх командах SQL.
CREATE – позволяет определить и создать

Создание БД
С помощью операторов DDL можно:
создать новую БД,
определить структуру новой таблицы
Создание БД
С помощью операторов DDL можно:
создать новую БД,
определить структуру новой таблицы

В MS SQL SERVER существует оператор CREATE DATABASE, который является
В MS SQL SERVER существует оператор CREATE DATABASE, который является

Создание базы данных – это процесс указания имени базы, определения
Создание базы данных – это процесс указания имени базы, определения

Если в процессе использования базы данных планируется размещение её на
Если в процессе использования базы данных планируется размещение её на
![Синтаксис CREATE DATABASE имя_базы_данных [ON [PRIMARY] (NAME=логическое_имя_файла, FILENAME=‘физическое_имя_файла’ [, SIZE=размер] [,](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/597284/slide-12.jpg)
Синтаксис
CREATE DATABASE имя_базы_данных
[ON
[PRIMARY] (NAME=логическое_имя_файла,
FILENAME=‘физическое_имя_файла’
[, SIZE=размер]
[,
Синтаксис
CREATE DATABASE имя_базы_данных
[ON
[PRIMARY] (NAME=логическое_имя_файла,
FILENAME=‘физическое_имя_файла’
[, SIZE=размер]
[,

При создании базы данных можно указать следующие параметры:
· PRIMARY указывает
При создании базы данных можно указать следующие параметры:
· PRIMARY указывает

FILENAME – задаёт физическое имя и путь к файлу.
SIZE –
FILENAME – задаёт физическое имя и путь к файлу.
SIZE –

MAXSIZE – указывает максимальный размер файла. Если размер не указан, то
MAXSIZE – указывает максимальный размер файла. Если размер не указан, то

FOR RESTORE – задаёт восстановление системы по журналу транзакций в случае
FOR RESTORE – задаёт восстановление системы по журналу транзакций в случае

Создание таблиц БД
Таблицы создаются командой CREATE TABLE.
Эта команда
Создание таблиц БД
Таблицы создаются командой CREATE TABLE.
Эта команда
![Синтаксис команды CREATE TABLE следующий: CREATE TABLE ( [( )], ( [( )]), …).](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/597284/slide-18.jpg)
Синтаксис команды CREATE TABLE следующий:
CREATE TABLE <имя таблицы>
(<имя поля1> <тип
Синтаксис команды CREATE TABLE следующий:
CREATE TABLE <имя таблицы>
(<имя поля1> <тип

Пробелы не могут быть частью имени таблицы или любого другого
Пробелы не могут быть частью имени таблицы или любого другого

Значение длины поля зависит от типа данных.
Если его не
Значение длины поля зависит от типа данных.
Если его не

Пример:
CREATE TABLE STUDENTS
(NOM_ZACH INTEGER,
SFAM CHAR (20),
SNAME CHAR (10),
STIP
Пример:
CREATE TABLE STUDENTS
(NOM_ZACH INTEGER,
SFAM CHAR (20),
SNAME CHAR (10),
STIP

Числовые типы
Tочные числовые типы
К категории точных числовых типов в SQL относятся
Числовые типы
Tочные числовые типы
К категории точных числовых типов в SQL относятся

с плавающей запятой:
float (от -1.79E + 308 до 1.79E +
с плавающей запятой:
float (от -1.79E + 308 до 1.79E +
![DECIMAL [(точность[,масштаб])] Параметр точность указывает максимальное количество цифр вводимых данных этого](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/597284/slide-24.jpg)
DECIMAL [(точность[,масштаб])] Параметр точность указывает максимальное количество цифр вводимых данных этого
DECIMAL [(точность[,масштаб])] Параметр точность указывает максимальное количество цифр вводимых данных этого

Строковые типы
В SQL Server предусмотрены две дублирующих разновидности полей для представления
Строковые типы
В SQL Server предусмотрены две дублирующих разновидности полей для представления

Всего в SQL Server предусмотрены следующие типы для текстовых данных:
∙ char/nchar
Всего в SQL Server предусмотрены следующие типы для текстовых данных:
∙ char/nchar

При использовании типа Char значения длиной короче заданной дополняются пробелами до
При использовании типа Char значения длиной короче заданной дополняются пробелами до

Если необходимо ввести значения большой длины можно использовать ключевое слово мах,
Если необходимо ввести значения большой длины можно использовать ключевое слово мах,

datetime (8 байт, точность до 3,33 миллисекунд);
smalldatetime (4 байта, точность
datetime (8 байт, точность до 3,33 миллисекунд);
smalldatetime (4 байта, точность

Тип данных UNIQUEIDENTIFIER используется для хранения глобальных уникальных идентификационных номеров.
Тип данных UNIQUEIDENTIFIER используется для хранения глобальных уникальных идентификационных номеров.

SQL_VARIANT -
Служит для хранения значений разных типов одновременно, таких как
SQL_VARIANT -
Служит для хранения значений разных типов одновременно, таких как

Логический тип данных - хранит значения вида true/false (единица/ноль).
В SQL
Логический тип данных - хранит значения вида true/false (единица/ноль).
В SQL

DATEDIFF ( datepart , startdate , enddate )─ возвращает интервал
DATEDIFF ( datepart , startdate , enddate )─ возвращает интервал


В ряде случаев функцию DATEPART можно заменить более простыми функциями.
DAY
В ряде случаев функцию DATEPART можно заменить более простыми функциями.
DAY


Пользовательские типы данных.
Могут использоваться при определении какого-либо специфического или часто
Пользовательские типы данных.
Могут использоваться при определении какого-либо специфического или часто

EXEC sp_addtype dt, DATETIME, 'NULL'
Удаление пользовательского типа данных происходит в
EXEC sp_addtype dt, DATETIME, 'NULL'
Удаление пользовательского типа данных происходит в

CREATE TYPE SSN
FROM varchar(10) NOT NULL ;
CREATE TYPE SSN
FROM varchar(10) NOT NULL ;

Получение информации о типах данных
Получить список всех типов данных, включая пользовательские,
Получение информации о типах данных
Получить список всех типов данных, включая пользовательские,

Преобразование типов
Для выполнения преобразований SQL Server содержит функции CONVERT и CAST,
Преобразование типов
Для выполнения преобразований SQL Server содержит функции CONVERT и CAST,

Пример:
SELECT ‘сегодня ‘ + CONVERT(VARCHAR(11),GETDATE())
CAST('1977.01.07‘ AS Datetime)
Пример:
SELECT ‘сегодня ‘ + CONVERT(VARCHAR(11),GETDATE())
CAST('1977.01.07‘ AS Datetime)
![Оновные функции – поиск подстроки CHARINDEX (expressionToFind ,expressionToSearch[ , start_location ]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/597284/slide-43.jpg)
Оновные функции
– поиск подстроки
CHARINDEX (expressionToFind ,expressionToSearch[ , start_location ] )
- вырезка
Оновные функции
– поиск подстроки
CHARINDEX (expressionToFind ,expressionToSearch[ , start_location ] )
- вырезка

Временные таблицы
Временные таблицы похожи на обычные, однако они не
Временные таблицы
Временные таблицы похожи на обычные, однако они не

В SQL Server существуют два типа временных таблиц: локальные и
В SQL Server существуют два типа временных таблиц: локальные и

Создание ограничений
Создание ограничений

Декларативные ограничения при создании таблиц
При создании таблиц могут быть заданы
Декларативные ограничения при создании таблиц
При создании таблиц могут быть заданы

Например, на значение стипендии может быть наложено ограничение (стипендия должна
Например, на значение стипендии может быть наложено ограничение (стипендия должна

Возраст сотрудника должен быть
не менее 18 лет:
BIRTH_DAY DATE CHECK(DATEDIFF(YEAR,GETDATE(),BIRTH_DAY)>=18)
Возраст сотрудника должен быть
не менее 18 лет:
BIRTH_DAY DATE CHECK(DATEDIFF(YEAR,GETDATE(),BIRTH_DAY)>=18)

При создании ограничений необходимо учитывать следующее:
ограничение, определенное для одного поля может
При создании ограничений необходимо учитывать следующее:
ограничение, определенное для одного поля может

ограничения DEFAULT должны быть ограничениями на уровне поля;
ограничения CHECK на
ограничения DEFAULT должны быть ограничениями на уровне поля;
ограничения CHECK на



Часто для поля или группы полей требуется реализовать ограничение, связанное
Часто для поля или группы полей требуется реализовать ограничение, связанное

Ограничение PRIMARY KEY действует аналогично UNIQUE, но для таблицы должен
Ограничение PRIMARY KEY действует аналогично UNIQUE, но для таблицы должен

PRIMARY KEY(NOM_ZACH, PKOD)
PRIMARY KEY(NOM_ZACH, PKOD)

Ссылочная целостность
Ссылочная целостность



Таблица USP подчинена двум другим таблицам: SUBJECTS и STUDENTS. При
Таблица USP подчинена двум другим таблицам: SUBJECTS и STUDENTS. При

Для моделирования этих связей должны быть определены два внешних ключа (FOREIGN
Для моделирования этих связей должны быть определены два внешних ключа (FOREIGN

Ключ FOREIGN KEY ограничивает значения, которые можно ввести в БД
Ключ FOREIGN KEY ограничивает значения, которые можно ввести в БД

Создадим таблицу USP с полем NOM_ZACH, и PKOD определенными в качестве
Создадим таблицу USP с полем NOM_ZACH, и PKOD определенными в качестве

Используя ограничения FOREIGN KEY, можно не указывать список полей родительского
Используя ограничения FOREIGN KEY, можно не указывать список полей родительского

В соответствии со стандартом, изменение или удаление значений родительского ключа
В соответствии со стандартом, изменение или удаление значений родительского ключа


При необходимости изменить или удалить текущее ссылочное значение родительского ключа
При необходимости изменить или удалить текущее ссылочное значение родительского ключа

Итак, изменения в родительском ключе можно разделить на
ограниченные (NO ACTION),
Итак, изменения в родительском ключе можно разделить на
ограниченные (NO ACTION),

Предположим, что есть необходимость в изменении номера зачетной книжки, причем
Предположим, что есть необходимость в изменении номера зачетной книжки, причем

CREATE TABLE USP
(NOM_ZACH INTEGER NOT NULL,
PKOD INTEGER,
TNUM INTEGER,
CREATE TABLE USP
(NOM_ZACH INTEGER NOT NULL,
PKOD INTEGER,
TNUM INTEGER,

Если данные о студенте удаляются, удаление их должно быть выполнено
Если данные о студенте удаляются, удаление их должно быть выполнено


Изменение таблиц
Изменение таблицы осуществляется командой ALTER TABLE.
Чаще всего
Изменение таблиц
Изменение таблицы осуществляется командой ALTER TABLE.
Чаще всего

Пример показывает добавление столбца, который допускает значения NULL В новом столбце

Новое поле станет последним по порядку в таблице. Допускается добавление
Новое поле станет последним по порядку в таблице. Допускается добавление

В таблицу могут быть добавлены и новые ограничения с помощью
В таблицу могут быть добавлены и новые ограничения с помощью

Примеры:
1. Для добавления ограничения, задающего значение по умолчанию:
ALTER TABLE USP
1. Для добавления ограничения, задающего значение по умолчанию:
ALTER TABLE USP

Для получения информации об ограничениях используется системная
процедура
sp_helpconstraint
Для получения информации об ограничениях используется системная
процедура
sp_helpconstraint

Удаление столбцов и ограничений
Из созданной таблицы можно удалить столбцы или
Удаление столбцов и ограничений
Из созданной таблицы можно удалить столбцы или

Разрешение и запрет ограничений
С помощью команды ALTER TABLE с предложениями
Разрешение и запрет ограничений
С помощью команды ALTER TABLE с предложениями

Модификация столбцов
Иногда при создании таблиц делают неверные предположения относительно типа
Модификация столбцов
Иногда при создании таблиц делают неверные предположения относительно типа

Удаление таблиц
Удаление таблиц выполняется с помощью команды DROP TABLE.
Удаление таблиц
Удаление таблиц выполняется с помощью команды DROP TABLE.

Создание индексов
Индекс - упорядоченный список полей или групп полей в
Создание индексов
Индекс - упорядоченный список полей или групп полей в

С помощью индексов осуществляется доступ к данным наиболее оптимальным способом.
С помощью индексов осуществляется доступ к данным наиболее оптимальным способом.

Если создан индекс по первичному ключу, а затем необходимо найти
Если создан индекс по первичному ключу, а затем необходимо найти

Индекс может быть создан на большинстве столбцов таблицы или представления.
Индекс может быть создан на большинстве столбцов таблицы или представления.

Индекс состоит из набора страниц, узлов индекса, которые организованы в
Индекс состоит из набора страниц, узлов индекса, которые организованы в


Когда формируется запрос на индексированный столбец, подсистема запросов начинает идти
Когда формируется запрос на индексированный столбец, подсистема запросов начинает идти

Листья индекса могут содержать как сами данные таблицы, так и
Листья индекса могут содержать как сами данные таблицы, так и

Кластеризованный индекс
Кластеризованный индекс хранит реальные строки данных в листьях индекса.
Кластеризованный индекс
Кластеризованный индекс хранит реальные строки данных в листьях индекса.

Некластеризованный индекс
В отличие от кластеризованного индекса, листья некластеризованного индекса содержат
Некластеризованный индекс
В отличие от кластеризованного индекса, листья некластеризованного индекса содержат

Содержание указателя на данные зависит от способа хранения данных: кластеризованная
Содержание указателя на данные зависит от способа хранения данных: кластеризованная
![Для создания индекса используется оператор CREATE INDEX. Синтаксис: CREATE INDEX имя_индекса ON таблица (поле[, …n])](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/597284/slide-95.jpg)
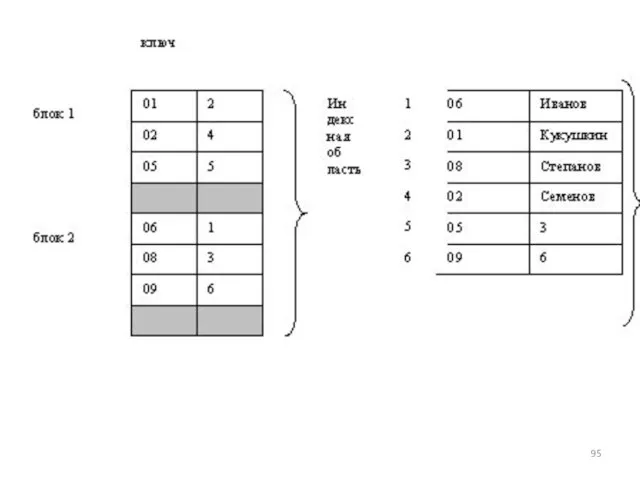
Для создания индекса используется оператор CREATE INDEX.
Синтаксис:
CREATE INDEX имя_индекса ON таблица
Для создания индекса используется оператор CREATE INDEX.
Синтаксис:
CREATE INDEX имя_индекса ON таблица

Таблица, для которой создаётся индекс, должна уже существовать и содержать
Таблица, для которой создаётся индекс, должна уже существовать и содержать

Для создания уникальных (не содержащих повторяющихся значений) индексов используется ключевое
Для создания уникальных (не содержащих повторяющихся значений) индексов используется ключевое

Для удаления индекса используется команда
DROP INDEX имя индекса
Чтобы изменить индекс
Для удаления индекса используется команда
DROP INDEX имя индекса
Чтобы изменить индекс

Использование опции Clustered index позволяет произвести так называемое кластерное индексирование, в

Для повышения быстродействия кластерный индекс следует создавать раньше некластерных индексов.
По
По

Проектирование индексов
Индексы могут улучить производительность системы, т.к. они обеспечивают подсистему
Проектирование индексов
Индексы могут улучить производительность системы, т.к. они обеспечивают подсистему

Рекомендации при планировании стратегии индексирования
Для таблиц которые часто обновляются следует использовать
Рекомендации при планировании стратегии индексирования
Для таблиц которые часто обновляются следует использовать

Создавать индексы на небольших таблицах не имеет смысла, т.к. возможно
Создавать индексы на небольших таблицах не имеет смысла, т.к. возможно

Последовательность создания таблиц
Последовательность создания таблиц
 История вычислительной техники
История вычислительной техники  Организация ввода и вывода данных при разработке программ в языке Паскаль
Организация ввода и вывода данных при разработке программ в языке Паскаль Создание архивов с помощью программы WinRAR
Создание архивов с помощью программы WinRAR Автоматизация компрессорной станции
Автоматизация компрессорной станции Коды и кодирование
Коды и кодирование Аппаратное обеспечение ПК (Hardware)
Аппаратное обеспечение ПК (Hardware) Объектные привилегии
Объектные привилегии Исключительные ситуации
Исключительные ситуации Разбор задач 3-го этапа республиканской олимпиады по информатике 2018 года
Разбор задач 3-го этапа республиканской олимпиады по информатике 2018 года C# Start
C# Start Формирование бюджетных заявок с применением нормативного метода расчета расходов
Формирование бюджетных заявок с применением нормативного метода расчета расходов Презентация на тему Основная позиция пальцев на клавиатуре
Презентация на тему Основная позиция пальцев на клавиатуре Персональные данные
Персональные данные Процессы программной инженерии Реализация и изменение процессов (Часть 2)
Процессы программной инженерии Реализация и изменение процессов (Часть 2) 1С:Управление автотранспортом Проф. Презентация отраслевого решения
1С:Управление автотранспортом Проф. Презентация отраслевого решения Двоичное кодирование звука. Представление видеоинформации
Двоичное кодирование звука. Представление видеоинформации Внешняя память
Внешняя память Формально об инъекциях. Модель инъекции. Критерий защищённости от атак инъекций
Формально об инъекциях. Модель инъекции. Критерий защищённости от атак инъекций Кодування і декодування повідомлень. (Урок 6)
Кодування і декодування повідомлень. (Урок 6) Беспроводные сети
Беспроводные сети Информатика в системе образования. Человек осваивал вещество, чтобы жить, осваивал энергию, чтобы жить цивилизованно, осваивает и
Информатика в системе образования. Человек осваивал вещество, чтобы жить, осваивал энергию, чтобы жить цивилизованно, осваивает и Автоматизация информационно-библиотечной деятельности
Автоматизация информационно-библиотечной деятельности Учитель информатики Трифонова Татьяна Викторовна г.Октябрьск ТЕКСТОВЫЕ РЕДАКТОРЫ И ПРОЦЕССОРЫ 10-11 кл
Учитель информатики Трифонова Татьяна Викторовна г.Октябрьск ТЕКСТОВЫЕ РЕДАКТОРЫ И ПРОЦЕССОРЫ 10-11 кл  Программирование на языке Паскаль
Программирование на языке Паскаль Огляд середовища VISUAL STUDIO та способи створення проектів
Огляд середовища VISUAL STUDIO та способи створення проектів Электронные таблицы
Электронные таблицы Регистрации в программе Основы здорового питания
Регистрации в программе Основы здорового питания Программная модель микропроцессора INTEL 8080, регистры, форматы и системы команд, методы адресации
Программная модель микропроцессора INTEL 8080, регистры, форматы и системы команд, методы адресации