- Компьютерная лингвистика

Содержание
- 2. План 1. Машинный перевод 2. Информационный поиск 3. Извлечение информации 4. Диалоги и чат-боты 5. Анализ
- 3. Тема 1. Машинный перевод 2. Информационный поиск 3. Извлечение информации 4. Диалоги и чат-боты 5. Анализ
- 4. Появление научного перевода Письмо американского математика Уоррена Уивера Норберту Винеру: «Когда я вижу текст на русском
- 5. Перевод как дешифровка Подсчитывается частота взаимной встречаемости элементов текста. Статистически значимые отклонения от случайности позволяют найти
- 6. Основные подходы к машинному переводу 1. Перевод на основе правил (rule-based machine translation – RBMT) работает
- 7. Автоматизированный перевод computer-aided translation – CAT Текст переводится человеком, использующим разные компьютерные технологии
- 8. Гибридный перевод 1 этап – перевод при помощи словарей и грамматик Time flies like an arrow
- 9. Модель постредактирования PROMT: корпус состоит из предложений, переведённых системой с помощью правил, в соответствие которым поставлены
- 10. Методы оценки качества перевода 1. Экспертная оценка 2. Автоматическая оценка
- 11. Экспертная оценка 1. Не менее 4 экспертов оценивают перевод каждого предложения по полноте (точности) и гладкости
- 12. Автоматическая оценка Сравнение с эталоном, выполненным или отредактированным вручную: совпадение n-грамм. Метрики автоматической оценки: BLEU, NIST,
- 13. Некоторые системы машинного перевода Systran (США, Франция, Корея) Logos, OpenLogos (США, Германия) PROMT (Россия) Linguatec (Германия)
- 14. Тема 1. Машинный перевод 2. Информационный поиск 3. Извлечение информации 4. Диалоги и чат-боты 5. Анализ
- 15. Информационная потребность представление пользователя о том, что он хочет найти
- 16. Поисковый запрос формулировка информационной потребности. Информация для поиска представлена в коллекции документов. Совпадающие части запроса и
- 17. Классический алгоритм поиска 1. Обработка текста документа. Морфологический анализатор, синтаксический анализатор, получение последовательности графов – деревьев
- 18. Индекс
- 19. Проблемы информационного поиска Семантико-синтаксический анализатор, распознающий анафору, эллипсис и т.п. Распознавание цели запроса Анализ текстов запросов
- 20. Виды запросов Информационные (расстояние до Марса, всё о кроликах) Навигационные (оф сайт фк зенит) Транзакционные (цель
- 21. Критерии качества поисковой системы Релевантность: документы, нужные пользователю Точность – доля релевантных документов в числе всех
- 22. Факторы ранжирования Способы численного представления характеристик документа и запроса, важных для качества поиска. Текстовые (доля слов
- 23. Алгоритм ранжирования машинное обучение на основании экспертной оценки по шкале релевантности документов, полученных по запросу
- 24. Стандартные лингвистические модули 1. Лемматизатор. Распознавание языка. Сведение словоформ к лексеме, обработка имён собственных. 2. Модуль
- 25. Модули расширения Синонимы. [купить картошку недорого]/[купить картофель дешево], но [пирожное картошка]/[пирожное картофель]. Классы условной эквивалентности: Словообразовательные
- 26. Построение модулей расширения Тезаурус Лингвистические модели (дериватемы, алгоритмы транслитерации и т.п.) Статистические модели (встречаемость в одном
- 27. Фильтры расширения Контекст. [hugo] = только [хьюго] в [hugo boss]/но = [хьюго]/[гюго] в [victor hugo] Регион.
- 28. Фильтры расстояния [Владимир Даль]/[Владимир Иванович Даль] [Владимир всматривался в даль]
- 29. Генерация динамических сниппетов построение с учётом запроса короткой аннотации документа, чтобы пользователь мог решить, стоит ли
- 30. Тема 1. Машинный перевод 2. Информационный поиск 3. Извлечение информации 4. Диалоги и чат-боты 5. Анализ
- 31. Задачи извлечения Связаны с получением конкретных ответов на вопросы и включают определение 1) именованных сущностей (В
- 32. Событие фиксированный набор сущностей и отношений между ними, может иметь несколько синонимичных шаблонов: Яндекс купил Кинопоиск
- 33. Задача распознавания именованных сущностей 1) нахождение в тексте упоминания сущности; 2) однозначное указание на объект или
- 34. Извлечение информации из фрагмента текста Современный [СПбГУ] в [России] – преемник [Академического университета], который был учреждён
- 35. Сущности и категории
- 36. Зависимость категории от контекста Россия отказалась от американского мяса. Россельхознадзор вводит временные ограничения на поставки продукции
- 37. Неоднозначность идентификации – Толстому подражаете, – сказал Рудольфи. – Кому именно из Толстых? – спросил я.
- 38. Анафора и кореферентность Грамоте обучил [Михайла Ломоносова] [дьячок местной Дмитровской церкви С.Н Сабельников]. «Вратами учёности», по
- 39. Знания о мире Аня подарила Маше конфеты, потому что у неё был день рождения. Аня подарила
- 40. Идентификаторы для разрешения кореферентности «Евгений Онегин» стал одним из самых значительных произведений А.С. Пушкина. Евгений Онегин
- 41. Тема 1. Машинный перевод 2. Информационный поиск 3. Извлечение информации 4. Диалоги и чат-боты 5. Анализ
- 42. Тест Тьюринга Английский математик Алан Тьюринг в 1950 году предположил, что к 2000 году качество имитации
- 43. Моделирование диалога (интеракционная социолингвистика) Порядок обмена репликами Общий контекст для собеседников Структура диалога (установление, поддержание, прерывание
- 44. Модули диалоговых систем Распознавание речи Понимание языка Диалоговый менеджмент Генерация естественного языка Синтез речи
- 45. Модуль понимания естественного языка Задача: семантическое представление входного текста Знания о мире: базы знаний, пополняемые алгоритмами
- 46. Диалоговый менеджер центральная составляющая диалоговых систем, которая координирует деятельность других компонентов. Задачи: обновление контекста диалога на
- 47. Модуль генерации естественного языка Планирование документа Микропланирование Поверхностная реализация.
- 48. Планирование документа Определение содержания Структурирование дискурса
- 49. Микропланирование Лексикализация Аггрегация (определение информации для одного предложения) Генерация отсылочных выражений.
- 50. Поверхностная реализация Построение грамматически правильных предложений Конвертация текста в запрашиваемый формат
- 51. Чат-боты Siri (Apple) Maluuba (Android) Robin (Android) Iris (Android) Vlingo (Android) Skyvi (Android) Voice Mate (LG)
- 52. Artificial Intelligence Markup Language (AIML) тег, который начинает и заканчивает документ тег, обозначающий элемент в базе
- 53. Вопросно-ответные системы IBM Watson – медицинское консультирование Модуль контентной аналитики DEEPQA с машинным обучением на основе
- 54. Тема 1. Машинный перевод 2. Информационный поиск 3. Извлечение информации 4. Диалоги и чат-боты 5. Анализ
- 55. Анализ тональности определение эмоциональной окраски сообщений. Sentiment analysis – сентимент-анализ, анализ мнений, анализ эмоциональной составляющей сообщений.
- 56. Корпус текстов Блоги, социальные сети, твиты, отзывы в интернет-магазинах (UGC – User Generated Content). Webometric Analyst
- 57. Анализ тональности 1) субъект тональности (кто? – турист) 2) объект тональности (о чём? – отель) 3)
- 58. Подходы к анализу тональности 1) правила (русский язык) 2) машинное обучение (английский язык)
- 59. Правила Используются шаблоны, описывающие предметную область По этим шаблонам из текстов извлекаются n-граммы Пример правила: Если
- 60. NRC Word-Emotion Association Lexicon
- 61. NRC Hashtag Sentiment Lexicon
- 62. Разработка словарей НКРЯ (ev: posit, ev: neg) Перевод списков слов с другого языка, Пополнение списков при
- 63. Вычисление тональности слова (SO – sentiment orientation) PMI = log2 P(слово А около слова В)/Р(слово А)*Р(слово
- 64. Тезаурусы с разметкой эмоциональной составляющей SenticNet SentiWordNet WordNet-Affect RussNet
- 65. Программы определения тональности текста Stanford Live Demo SentiStrength LIWC
- 66. Оценка качества работы алгоритмов Полнота – отношение верно приписанных тональностей к общему числу тональностей (приписанных и
- 67. Тема 1. Машинный перевод 2. Информационный поиск 3. Извлечение информации 4. Диалоги и чат-боты 5. Анализ
- 68. Принцип квантитативной лингвистики Экспонент – означающее Денотат – означаемое Денотат «дерево» – экспоненты рус. дерево, англ.
- 69. Методика определения языка, на котором написан текст Зная частотность букв для каждого языка, мы можем определить,
- 70. Проблема дешифровки текста на неизвестном языке 1) статистика букв 2) система письма 3) языковые структуры 4)
- 71. Типологические индексы Дж. Гринберга 1. Индекс синтеза. Сколько в среднем морфем в слове данного языка. Syn=M/W,
- 72. Языки разных морфологических типов
- 73. Стилеметрия количественное исследование стилей текстов, написанных разными писателями в разных жанрах.
- 74. Предсказание популярности новых книг и сценариев Университет Стоуни Брук (США) 1) статистика скачивания книг разных жанров
- 75. Лингвистические параметры 1) лексика: униграммы и биграммы 2) части речи: распределение слов в текстах по частям
- 76. Результат 84% - максимальная популярность жанра «Приключения». Алгоритм может быть доработан для оценки и прогнозирования успешности
- 77. Глоттохронология Два языка развиваются из праязыка независимо друг от друга. Можно вычислить долю совпадающих слов в
- 78. Доля совпадения между языками Корневая глоттохронология Этимологическая статистика Лексикостатистическая классификация
- 79. Частотные словари Лемматизация словоформ Общая частота – число употреблений на млн слов корпуса Ранг леммы или
- 80. Квантитативная морфология
- 81. Выводы 1) квантитативные исследования позволяют выяснить, как язык используется в разных сферах коммуникации 2) частотные характеристики
- 83. Скачать презентацию

План
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ
План
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ

Тема
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ
Тема
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ

Появление научного перевода
Письмо американского математика Уоррена Уивера Норберту Винеру: «Когда я
Появление научного перевода
Письмо американского математика Уоррена Уивера Норберту Винеру: «Когда я

Перевод как дешифровка
Подсчитывается частота взаимной встречаемости элементов текста. Статистически значимые отклонения
Перевод как дешифровка
Подсчитывается частота взаимной встречаемости элементов текста. Статистически значимые отклонения

Основные подходы
к машинному переводу
1. Перевод на основе правил (rule-based machine
Основные подходы
к машинному переводу
1. Перевод на основе правил (rule-based machine

Автоматизированный перевод
computer-aided translation – CAT
Текст переводится человеком, использующим разные компьютерные
Автоматизированный перевод
computer-aided translation – CAT
Текст переводится человеком, использующим разные компьютерные

Гибридный перевод
1 этап – перевод при помощи словарей и грамматик
Гибридный перевод
1 этап – перевод при помощи словарей и грамматик

Модель постредактирования
PROMT: корпус состоит из предложений, переведённых системой с помощью правил,
Модель постредактирования
PROMT: корпус состоит из предложений, переведённых системой с помощью правил,

Методы оценки качества перевода
1. Экспертная оценка
2. Автоматическая оценка
Методы оценки качества перевода
1. Экспертная оценка
2. Автоматическая оценка

Экспертная оценка
1. Не менее 4 экспертов оценивают перевод каждого предложения по
Экспертная оценка
1. Не менее 4 экспертов оценивают перевод каждого предложения по

Автоматическая оценка
Сравнение с эталоном, выполненным или отредактированным вручную: совпадение n-грамм.
Метрики автоматической
Автоматическая оценка
Сравнение с эталоном, выполненным или отредактированным вручную: совпадение n-грамм.
Метрики автоматической

Некоторые системы
машинного перевода
Systran (США, Франция, Корея)
Logos, OpenLogos (США, Германия)
PROMT
Некоторые системы
машинного перевода
Systran (США, Франция, Корея)
Logos, OpenLogos (США, Германия)
PROMT

Тема
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ
Тема
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ

Информационная потребность
представление пользователя о том, что он хочет найти
Информационная потребность
представление пользователя о том, что он хочет найти

Поисковый запрос
формулировка информационной потребности.
Информация для поиска представлена в коллекции документов. Совпадающие
Поисковый запрос
формулировка информационной потребности.
Информация для поиска представлена в коллекции документов. Совпадающие

Классический алгоритм поиска
1. Обработка текста документа. Морфологический анализатор, синтаксический анализатор, получение
Классический алгоритм поиска
1. Обработка текста документа. Морфологический анализатор, синтаксический анализатор, получение
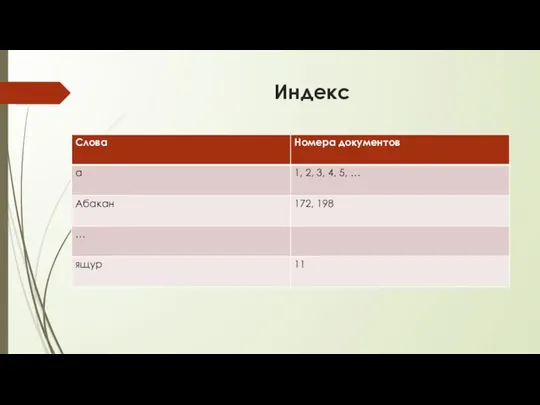
Индекс
Индекс

Проблемы
информационного поиска
Семантико-синтаксический анализатор, распознающий анафору, эллипсис и т.п.
Распознавание цели запроса
Анализ
Проблемы
информационного поиска
Семантико-синтаксический анализатор, распознающий анафору, эллипсис и т.п.
Распознавание цели запроса
Анализ

Виды запросов
Информационные (расстояние до Марса, всё о кроликах)
Навигационные (оф сайт фк
Виды запросов
Информационные (расстояние до Марса, всё о кроликах)
Навигационные (оф сайт фк

Критерии качества
поисковой системы
Релевантность: документы, нужные пользователю
Точность – доля релевантных документов
Критерии качества
поисковой системы
Релевантность: документы, нужные пользователю
Точность – доля релевантных документов

Факторы ранжирования
Способы численного представления характеристик документа и запроса, важных для качества
Факторы ранжирования
Способы численного представления характеристик документа и запроса, важных для качества

Алгоритм ранжирования
машинное обучение на основании экспертной оценки по шкале релевантности документов,
Алгоритм ранжирования
машинное обучение на основании экспертной оценки по шкале релевантности документов,

Стандартные лингвистические модули
1. Лемматизатор. Распознавание языка. Сведение словоформ к лексеме, обработка
Стандартные лингвистические модули
1. Лемматизатор. Распознавание языка. Сведение словоформ к лексеме, обработка
![Модули расширения Синонимы. [купить картошку недорого]/[купить картофель дешево], но [пирожное картошка]/[пирожное](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/707241/slide-24.jpg)
Модули расширения
Синонимы. [купить картошку недорого]/[купить картофель дешево], но [пирожное картошка]/[пирожное картофель].
Классы
Модули расширения
Синонимы. [купить картошку недорого]/[купить картофель дешево], но [пирожное картошка]/[пирожное картофель].
Классы

Построение модулей расширения
Тезаурус
Лингвистические модели (дериватемы, алгоритмы транслитерации и т.п.)
Статистические модели (встречаемость
Построение модулей расширения
Тезаурус
Лингвистические модели (дериватемы, алгоритмы транслитерации и т.п.)
Статистические модели (встречаемость
![Фильтры расширения Контекст. [hugo] = только [хьюго] в [hugo boss]/но =](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/707241/slide-26.jpg)
Фильтры расширения
Контекст. [hugo] = только [хьюго] в [hugo boss]/но = [хьюго]/[гюго]
Фильтры расширения
Контекст. [hugo] = только [хьюго] в [hugo boss]/но = [хьюго]/[гюго]
![Фильтры расстояния [Владимир Даль]/[Владимир Иванович Даль] [Владимир всматривался в даль]](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/707241/slide-27.jpg)
Фильтры расстояния
[Владимир Даль]/[Владимир Иванович Даль]
[Владимир всматривался в даль]
Фильтры расстояния
[Владимир Даль]/[Владимир Иванович Даль]
[Владимир всматривался в даль]

Генерация динамических сниппетов
построение с учётом запроса короткой аннотации документа, чтобы пользователь
Генерация динамических сниппетов
построение с учётом запроса короткой аннотации документа, чтобы пользователь

Тема
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ
Тема
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ

Задачи извлечения
Связаны с получением конкретных ответов на вопросы и включают определение
1)
Задачи извлечения
Связаны с получением конкретных ответов на вопросы и включают определение
1)

Событие
фиксированный набор сущностей и отношений между ними, может иметь несколько синонимичных
Событие
фиксированный набор сущностей и отношений между ними, может иметь несколько синонимичных

Задача распознавания
именованных сущностей
1) нахождение в тексте упоминания сущности;
2) однозначное указание
Задача распознавания
именованных сущностей
1) нахождение в тексте упоминания сущности;
2) однозначное указание
![Извлечение информации из фрагмента текста Современный [СПбГУ] в [России] – преемник](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/707241/slide-33.jpg)
Извлечение информации
из фрагмента текста
Современный [СПбГУ] в [России] – преемник [Академического
Извлечение информации
из фрагмента текста
Современный [СПбГУ] в [России] – преемник [Академического

Сущности и категории
Сущности и категории

Зависимость категории
от контекста
Россия отказалась от американского мяса. Россельхознадзор вводит временные
Зависимость категории
от контекста
Россия отказалась от американского мяса. Россельхознадзор вводит временные

Неоднозначность идентификации
– Толстому подражаете, – сказал Рудольфи.
– Кому именно из
Неоднозначность идентификации
– Толстому подражаете, – сказал Рудольфи.
– Кому именно из
![Анафора и кореферентность Грамоте обучил [Михайла Ломоносова] [дьячок местной Дмитровской церкви](/_ipx/f_webp&q_80&fit_contain&s_1440x1080/imagesDir/jpg/707241/slide-37.jpg)
Анафора и кореферентность
Грамоте обучил [Михайла Ломоносова] [дьячок местной Дмитровской церкви С.Н
Анафора и кореферентность
Грамоте обучил [Михайла Ломоносова] [дьячок местной Дмитровской церкви С.Н

Знания о мире
Аня подарила Маше конфеты, потому что у неё был
Знания о мире
Аня подарила Маше конфеты, потому что у неё был

Идентификаторы для разрешения кореферентности
«Евгений Онегин» стал одним из самых значительных произведений
Идентификаторы для разрешения кореферентности
«Евгений Онегин» стал одним из самых значительных произведений

Тема
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ
Тема
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ

Тест Тьюринга
Английский математик Алан Тьюринг в 1950 году предположил, что к
Тест Тьюринга
Английский математик Алан Тьюринг в 1950 году предположил, что к

Моделирование диалога (интеракционная социолингвистика)
Порядок обмена репликами
Общий контекст для собеседников
Структура диалога (установление,
Моделирование диалога (интеракционная социолингвистика)
Порядок обмена репликами
Общий контекст для собеседников
Структура диалога (установление,

Модули диалоговых систем
Распознавание речи
Понимание языка
Диалоговый менеджмент
Генерация естественного языка
Синтез речи
Модули диалоговых систем
Распознавание речи
Понимание языка
Диалоговый менеджмент
Генерация естественного языка
Синтез речи

Модуль понимания
естественного языка
Задача: семантическое представление входного текста
Знания о мире: базы
Модуль понимания
естественного языка
Задача: семантическое представление входного текста
Знания о мире: базы

Диалоговый менеджер
центральная составляющая диалоговых систем, которая координирует деятельность других компонентов.
Задачи:
обновление контекста
Диалоговый менеджер
центральная составляющая диалоговых систем, которая координирует деятельность других компонентов.
Задачи:
обновление контекста

Модуль генерации
естественного языка
Планирование документа
Микропланирование
Поверхностная реализация.
Модуль генерации
естественного языка
Планирование документа
Микропланирование
Поверхностная реализация.

Планирование документа
Определение содержания
Структурирование дискурса
Планирование документа
Определение содержания
Структурирование дискурса

Микропланирование
Лексикализация
Аггрегация (определение информации для одного предложения)
Генерация отсылочных выражений.
Микропланирование
Лексикализация
Аггрегация (определение информации для одного предложения)
Генерация отсылочных выражений.

Поверхностная реализация
Построение грамматически правильных предложений
Конвертация текста в запрашиваемый формат
Поверхностная реализация
Построение грамматически правильных предложений
Конвертация текста в запрашиваемый формат

Чат-боты
Siri (Apple)
Maluuba (Android)
Robin (Android)
Iris (Android)
Vlingo (Android)
Skyvi (Android)
Voice Mate (LG)
S-Voice (Samsung)
Google Now
Cortana
Чат-боты
Siri (Apple)
Maluuba (Android)
Robin (Android)
Iris (Android)
Vlingo (Android)
Skyvi (Android)
Voice Mate (LG)
S-Voice (Samsung)
Google Now
Cortana

Artificial Intelligence Markup Language (AIML)
тег, который начинает и заканчивает документ
Artificial Intelligence Markup Language (AIML)

Вопросно-ответные системы
IBM Watson – медицинское консультирование
Модуль контентной аналитики DEEPQA с машинным
Вопросно-ответные системы
IBM Watson – медицинское консультирование
Модуль контентной аналитики DEEPQA с машинным

Тема
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ
Тема
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ

Анализ тональности
определение эмоциональной окраски сообщений.
Sentiment analysis – сентимент-анализ, анализ мнений, анализ
Анализ тональности
определение эмоциональной окраски сообщений.
Sentiment analysis – сентимент-анализ, анализ мнений, анализ

Корпус текстов
Блоги, социальные сети, твиты, отзывы в интернет-магазинах (UGC – User
Корпус текстов
Блоги, социальные сети, твиты, отзывы в интернет-магазинах (UGC – User

Анализ тональности
1) субъект тональности (кто? – турист)
2) объект тональности (о чём?
Анализ тональности
1) субъект тональности (кто? – турист)
2) объект тональности (о чём?
Подходы к анализу тональности
1) правила (русский язык)
2) машинное обучение (английский язык)
Подходы к анализу тональности
1) правила (русский язык)
2) машинное обучение (английский язык)

Правила
Используются шаблоны, описывающие предметную область
По этим шаблонам из текстов извлекаются n-граммы
Пример
Правила
Используются шаблоны, описывающие предметную область
По этим шаблонам из текстов извлекаются n-граммы
Пример
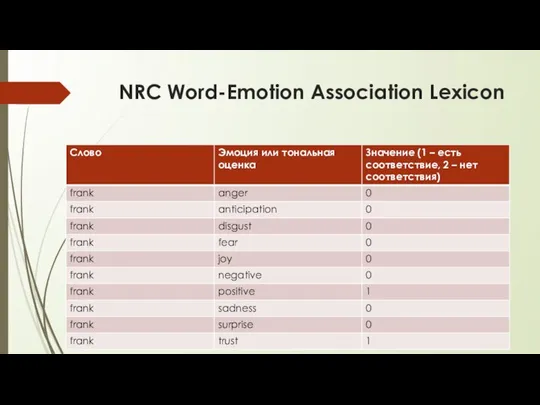
NRC Word-Emotion Association Lexicon
NRC Word-Emotion Association Lexicon
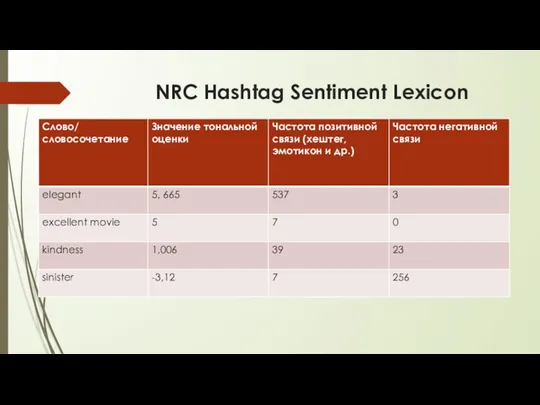
NRC Hashtag Sentiment Lexicon
NRC Hashtag Sentiment Lexicon

Разработка словарей
НКРЯ (ev: posit, ev: neg)
Перевод списков слов с другого языка,
Разработка словарей
НКРЯ (ev: posit, ev: neg)
Перевод списков слов с другого языка,

Вычисление тональности слова
(SO – sentiment orientation)
PMI = log2 P(слово А
Вычисление тональности слова
(SO – sentiment orientation)
PMI = log2 P(слово А

Тезаурусы с разметкой эмоциональной составляющей
SenticNet
SentiWordNet
WordNet-Affect
RussNet
Тезаурусы с разметкой эмоциональной составляющей
SenticNet
SentiWordNet
WordNet-Affect
RussNet

Программы определения тональности текста
Stanford Live Demo
SentiStrength
LIWC
Программы определения тональности текста
Stanford Live Demo
SentiStrength
LIWC

Оценка качества работы алгоритмов
Полнота – отношение верно приписанных тональностей к общему
Оценка качества работы алгоритмов
Полнота – отношение верно приписанных тональностей к общему

Тема
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ
Тема
1. Машинный перевод
2. Информационный поиск
3. Извлечение информации
4. Диалоги и чат-боты
5. Анализ

Принцип квантитативной лингвистики
Экспонент – означающее
Денотат – означаемое
Денотат «дерево» – экспоненты рус.
Принцип квантитативной лингвистики
Экспонент – означающее
Денотат – означаемое
Денотат «дерево» – экспоненты рус.

Методика определения языка,
на котором написан текст
Зная частотность букв для каждого
Методика определения языка,
на котором написан текст
Зная частотность букв для каждого

Проблема дешифровки текста
на неизвестном языке
1) статистика букв
2) система письма
3) языковые
Проблема дешифровки текста
на неизвестном языке
1) статистика букв
2) система письма
3) языковые

Типологические индексы
Дж. Гринберга
1. Индекс синтеза. Сколько в среднем морфем в
Типологические индексы
Дж. Гринберга
1. Индекс синтеза. Сколько в среднем морфем в
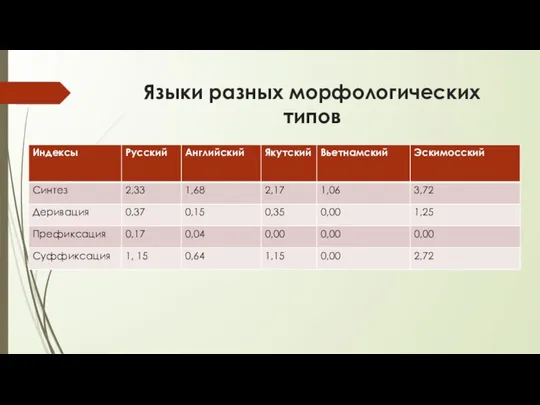
Языки разных морфологических типов
Языки разных морфологических типов

Стилеметрия
количественное исследование стилей текстов, написанных разными писателями в разных жанрах.
Стилеметрия
количественное исследование стилей текстов, написанных разными писателями в разных жанрах.

Предсказание популярности новых книг и сценариев
Университет Стоуни Брук (США)
1) статистика скачивания
Предсказание популярности новых книг и сценариев
Университет Стоуни Брук (США)
1) статистика скачивания

Лингвистические параметры
1) лексика: униграммы и биграммы
2) части речи: распределение слов в
Лингвистические параметры
1) лексика: униграммы и биграммы
2) части речи: распределение слов в

Результат
84% - максимальная популярность жанра «Приключения».
Алгоритм может быть доработан для оценки
Результат
84% - максимальная популярность жанра «Приключения».
Алгоритм может быть доработан для оценки

Глоттохронология
Два языка развиваются из праязыка независимо друг от друга.
Можно вычислить долю
Глоттохронология
Два языка развиваются из праязыка независимо друг от друга.
Можно вычислить долю

Доля совпадения между языками
Корневая глоттохронология
Этимологическая статистика
Лексикостатистическая классификация
Доля совпадения между языками
Корневая глоттохронология
Этимологическая статистика
Лексикостатистическая классификация

Частотные словари
Лемматизация словоформ
Общая частота – число употреблений на млн слов корпуса
Ранг
Частотные словари
Лемматизация словоформ
Общая частота – число употреблений на млн слов корпуса
Ранг
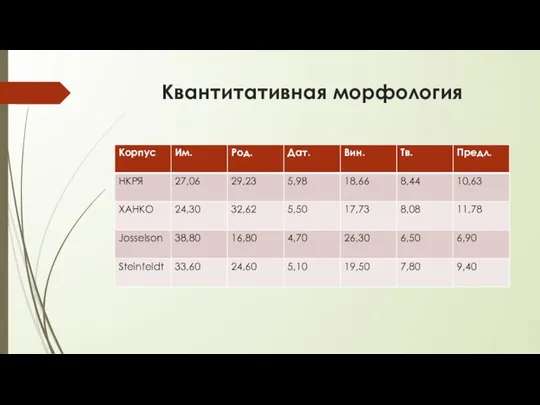
Квантитативная морфология
Квантитативная морфология

Выводы
1) квантитативные исследования позволяют выяснить, как язык используется в разных сферах
Выводы
1) квантитативные исследования позволяют выяснить, как язык используется в разных сферах
 Сочинение о себе. 自称认识
Сочинение о себе. 自称认识 Латинский язык
Латинский язык Языки Д.Толкина
Языки Д.Толкина Историческая фонетика
Историческая фонетика Теоретическая грамматика английского языка. Морфологическая типология языков
Теоретическая грамматика английского языка. Морфологическая типология языков Vladislav 学生
Vladislav 学生 Les boules de neige
Les boules de neige Komparatiivi. Сравнительная степень
Komparatiivi. Сравнительная степень Китайский язык. Иероглифическая письменность. Урок 2
Китайский язык. Иероглифическая письменность. Урок 2 Лекция 1. Понятие стиля
Лекция 1. Понятие стиля Естественные доказательства
Естественные доказательства Чачаяс - игрушки
Чачаяс - игрушки Искусство японской каллиграфии
Искусство японской каллиграфии Les sports
Les sports Хангыль
Хангыль Genele umane
Genele umane Иероглифика. Элементы иероглифов
Иероглифика. Элементы иероглифов Моделирование синтаксиса
Моделирование синтаксиса Болгарские переводчики и словари
Болгарские переводчики и словари Сходства и различия словообразования русского, английского и латинского языков
Сходства и различия словообразования русского, английского и латинского языков Взаимодействие языков
Взаимодействие языков Узагальнення вивченого у 5 класі
Узагальнення вивченого у 5 класі Первые уроки иврита
Первые уроки иврита Предлоги (часть 3)
Предлоги (часть 3) 고 있다
고 있다 Semasiology
Semasiology Futur Simple Простое будущее время
Futur Simple Простое будущее время Français de Belguique
Français de Belguique